
25 Pertanyaan & Jawaban Wawancara Pembelajaran Mesin – Regresi Linier
Diterbitkan: 2022-09-08Ini adalah praktik umum untuk menguji calon ilmu data pada algoritme pembelajaran mesin yang umum digunakan dalam wawancara. Algoritme konvensional ini adalah regresi linier, regresi logistik, pengelompokan, pohon keputusan, dll. Ilmuwan data diharapkan memiliki pengetahuan mendalam tentang algoritme ini.
Kami berkonsultasi dengan manajer perekrutan dan ilmuwan data dari berbagai organisasi untuk mengetahui tentang pertanyaan umum ML yang mereka ajukan dalam sebuah wawancara. Berdasarkan umpan balik mereka yang luas, serangkaian pertanyaan dan jawaban disiapkan untuk membantu calon ilmuwan data dalam percakapan mereka. Pertanyaan wawancara Regresi Linier adalah yang paling umum dalam wawancara Pembelajaran Mesin. T&J tentang algoritme ini akan diberikan dalam rangkaian empat posting blog.
Kursus Pembelajaran Mesin Terbaik & Kursus AI Online
| Master of Science dalam Pembelajaran Mesin & AI dari LJMU | Program Pascasarjana Eksekutif dalam Pembelajaran Mesin & AI dari IIITB | |
| Program Sertifikat Tingkat Lanjut dalam Pembelajaran Mesin & NLP dari IIITB | Program Sertifikat Tingkat Lanjut dalam Pembelajaran Mesin & Pembelajaran Mendalam dari IIITB | Program Pascasarjana Eksekutif dalam Ilmu Data & Pembelajaran Mesin dari University of Maryland |
| Untuk Jelajahi semua kursus kami, kunjungi halaman kami di bawah ini. | ||
| Kursus Pembelajaran Mesin | ||
Setiap posting blog akan mencakup topik berikut: -
- Regresi linier
- Regresi logistik
- Kekelompokan
- Pohon Keputusan dan Pertanyaan yang berkaitan dengan semua algoritma
Mari kita mulai dengan regresi linier!
1. Apa itu regresi linier?
Secara sederhana, regresi linier adalah metode untuk menemukan garis lurus terbaik yang sesuai dengan data yang diberikan, yaitu menemukan hubungan linier terbaik antara variabel independen dan dependen.
Dalam istilah teknis, regresi linier adalah algoritme pembelajaran mesin yang menemukan hubungan linier-fit terbaik pada data apa pun, antara variabel independen dan dependen. Hal ini sebagian besar dilakukan dengan Metode Jumlah Residu Kuadrat.
Keterampilan Pembelajaran Mesin yang Dibutuhkan
| Kursus Kecerdasan Buatan | Kursus Tablo |
| Kursus NLP | Kursus Pembelajaran Mendalam |

2. Nyatakan asumsi dalam model regresi linier.
Ada tiga asumsi utama dalam model regresi linier:
- Asumsi tentang bentuk model:
Diasumsikan bahwa terdapat hubungan linier antara variabel terikat dan variabel bebas. Hal ini dikenal sebagai 'asumsi linearitas'. - Asumsi tentang residu:
- Asumsi normalitas: Diasumsikan bahwa suku kesalahan, (i) , terdistribusi normal.
- Asumsi rata-rata nol: Diasumsikan bahwa residu memiliki nilai rata-rata nol.
- Asumsi varians konstan: Diasumsikan bahwa suku-suku residual memiliki varians yang sama (tetapi tidak diketahui), 2 Asumsi ini juga dikenal sebagai asumsi homogenitas atau homoskedastisitas.
- Asumsi kesalahan independen: Diasumsikan bahwa suku-suku residual saling bebas, yaitu kovarians berpasangannya adalah nol.
- Asumsi tentang penduga:
- Variabel bebas diukur tanpa kesalahan.
- Variabel bebas adalah bebas linier satu sama lain, yaitu tidak ada multikolinearitas dalam data.
Penjelasan:
- Ini cukup jelas.
- Jika residual tidak terdistribusi normal, keacakannya hilang, yang menunjukkan bahwa model tidak mampu menjelaskan hubungan dalam data.
Juga, rata-rata residu harus nol.
Y (i)i = 0 + 1 x (i) + (i)
Ini adalah asumsi model linier, di mana adalah suku sisa.
E(Y) = E( 0 + 1 x (i) + (i) )
= E( 0 + 1 x (i) + (i) )
Jika ekspektasi (mean) residual, E(ε (i) ), adalah nol, ekspektasi variabel target dan model menjadi sama, yang merupakan salah satu target model.
Residu (juga dikenal sebagai istilah kesalahan) harus independen. Artinya tidak ada korelasi antara residual dan nilai prediksi, atau antara residual itu sendiri. Jika ada korelasi, ini menyiratkan bahwa ada beberapa hubungan yang tidak dapat diidentifikasi oleh model regresi. - Jika variabel bebas tidak bebas linier satu sama lain, keunikan solusi kuadrat terkecil (atau solusi persamaan normal) hilang.
Bergabunglah dengan Kursus Kecerdasan Buatan online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
3. Apa itu rekayasa fitur? Bagaimana Anda menerapkannya dalam proses pemodelan?
Rekayasa fitur adalah proses mengubah data mentah menjadi fitur yang lebih mewakili masalah mendasar ke model prediktif
, menghasilkan akurasi model yang lebih baik pada data yang tidak terlihat.
Dalam istilah awam, rekayasa fitur berarti pengembangan fitur baru yang dapat membantu Anda memahami dan memodelkan masalah dengan cara yang lebih baik. Rekayasa fitur terdiri dari dua jenis — didorong oleh bisnis dan didorong oleh data. Rekayasa fitur berbasis bisnis berkisar pada penyertaan fitur dari sudut pandang bisnis. Tugas di sini adalah mengubah variabel bisnis menjadi fitur masalah. Dalam hal rekayasa fitur berbasis data, fitur yang Anda tambahkan tidak memiliki interpretasi fisik yang signifikan, tetapi fitur tersebut membantu model dalam prediksi variabel target.
FYI: Kursus nlp gratis!
Untuk menerapkan rekayasa fitur, seseorang harus sepenuhnya mengenal kumpulan data. Ini melibatkan mengetahui apa data yang diberikan, apa artinya, apa fitur mentahnya, dll. Anda juga harus memiliki gagasan yang jelas tentang masalahnya, seperti faktor apa yang memengaruhi variabel target, apa interpretasi fisik variabel tersebut. , dll.
4. Apa gunanya regularisasi? Jelaskan regularisasi L1 dan L2.
Regularisasi adalah teknik yang digunakan untuk mengatasi masalah overfitting model. Ketika model yang sangat kompleks diimplementasikan pada data pelatihan, model tersebut menjadi overfit. Kadang-kadang, model sederhana mungkin tidak dapat menggeneralisasi data dan model kompleks yang berlebihan. Untuk mengatasi masalah ini, regularisasi digunakan.
Regularisasi tidak lain adalah menambahkan suku-suku koefisien (betas) pada fungsi biaya sehingga suku-suku tersebut dikenai sanksi dan kecil besarnya. Ini pada dasarnya membantu dalam menangkap tren dalam data dan pada saat yang sama mencegah overfitting dengan tidak membiarkan model menjadi terlalu kompleks.
- Regularisasi L1 atau LASSO: Di sini, nilai absolut dari koefisien ditambahkan ke fungsi biaya. Hal ini dapat dilihat pada persamaan berikut; bagian yang disorot sesuai dengan regularisasi L1 atau LASSO. Teknik regularisasi ini memberikan hasil yang jarang, yang mengarah pada pemilihan fitur juga.
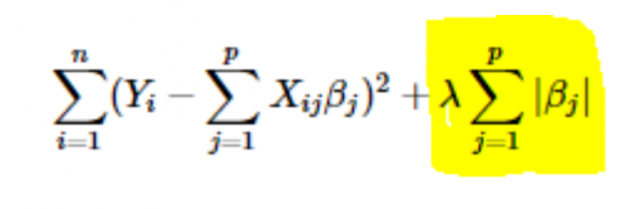
- Regularisasi L2 atau Ridge: Di sini, kuadrat koefisien ditambahkan ke fungsi biaya. Ini dapat dilihat pada persamaan berikut, di mana bagian yang disorot sesuai dengan regularisasi L2 atau Ridge.
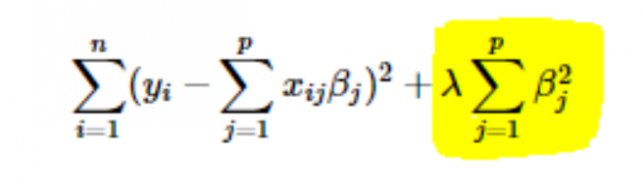
5. Bagaimana cara memilih nilai parameter learning rate (α)?
Memilih nilai tingkat pembelajaran adalah bisnis yang rumit. Jika nilainya terlalu kecil, algoritma penurunan gradien membutuhkan waktu lama untuk konvergen ke solusi optimal. Di sisi lain, jika nilai learning rate tinggi, penurunan gradien akan melampaui solusi optimal dan kemungkinan besar tidak akan pernah konvergen ke solusi optimal.
Untuk mengatasi masalah ini, Anda dapat mencoba nilai alfa yang berbeda pada rentang nilai dan memplot biaya vs jumlah iterasi. Kemudian, berdasarkan grafik, nilai yang sesuai dengan grafik yang menunjukkan penurunan cepat dapat dipilih. 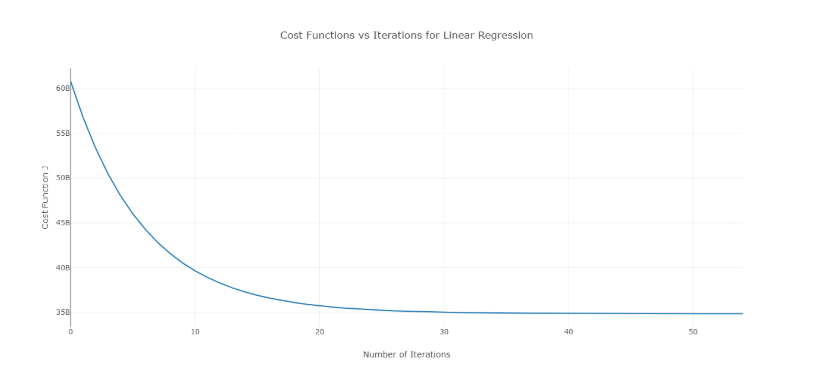
Grafik di atas adalah kurva biaya ideal vs jumlah iterasi. Perhatikan bahwa biaya awalnya menurun dengan meningkatnya jumlah iterasi, tetapi setelah iterasi tertentu, penurunan gradien menyatu dan biaya tidak berkurang lagi.
Jika Anda melihat bahwa biaya meningkat dengan jumlah iterasi, parameter kecepatan belajar Anda tinggi dan perlu dikurangi.
6. Bagaimana cara memilih nilai parameter regularisasi (λ)?
Memilih parameter regularisasi adalah bisnis yang rumit. Jika nilai terlalu tinggi, itu akan menyebabkan nilai koefisien regresi yang sangat kecil , yang akan menyebabkan model underfitting (bias tinggi – varians rendah). Sebaliknya, jika nilai adalah 0 (sangat kecil), model akan cenderung overfit pada data latih (bias rendah – varians tinggi).
Tidak ada cara yang tepat untuk memilih nilai . Yang dapat Anda lakukan adalah memiliki sub-sampel data dan menjalankan algoritme beberapa kali pada set yang berbeda. Di sini, orang tersebut harus memutuskan berapa banyak varians yang dapat ditoleransi. Setelah pengguna puas dengan varians, nilai tersebut dapat dipilih untuk dataset lengkap.
Satu hal yang perlu diperhatikan adalah bahwa nilai yang dipilih di sini optimal untuk subset tersebut, bukan untuk seluruh data pelatihan.
7. Bisakah kita menggunakan regresi linier untuk analisis deret waktu?
Seseorang dapat menggunakan regresi linier untuk analisis deret waktu, tetapi hasilnya tidak menjanjikan. Jadi, umumnya tidak disarankan untuk melakukannya. Alasan di balik ini adalah-
- Data deret waktu sebagian besar digunakan untuk prediksi masa depan, tetapi regresi linier jarang memberikan hasil yang baik untuk prediksi masa depan karena tidak dimaksudkan untuk ekstrapolasi.
- Sebagian besar, data deret waktu memiliki pola, seperti pada jam sibuk, musim perayaan, dll., yang kemungkinan besar akan diperlakukan sebagai outlier dalam analisis regresi linier.
8. Berapakah nilai jumlah residual dari regresi linier yang mendekati? Membenarkan.
Jawab Jumlah residual dari regresi linier adalah 0. Regresi linier bekerja dengan asumsi bahwa kesalahan (residual) berdistribusi normal dengan rata-rata 0, yaitu
Y = T X +
Di sini, Y adalah target atau variabel dependen,
adalah vektor dari koefisien regresi,
X adalah matriks fitur yang berisi semua fitur sebagai kolom,
adalah suku sisa sehingga ~ N(0,σ 2 ).
Jadi, jumlah semua residual adalah nilai yang diharapkan dari residual dikalikan jumlah total titik data. Karena ekspektasi residual adalah 0, jumlah semua suku residual adalah nol.
Catatan : N(μ,σ 2 ) adalah notasi standar untuk distribusi normal yang memiliki mean dan simpangan baku 2 .
9. Bagaimana pengaruh multikolinearitas terhadap regresi linier?
Ans Multikolinearitas terjadi ketika beberapa variabel independen sangat berkorelasi (positif atau negatif) satu sama lain. Multikolinearitas ini menimbulkan masalah karena bertentangan dengan asumsi dasar regresi linier. Adanya multikolinearitas tidak mempengaruhi kemampuan prediksi model. Jadi, jika Anda hanya ingin prediksi, keberadaan multikolinearitas tidak mempengaruhi output Anda. Namun, jika Anda ingin menarik beberapa wawasan dari model dan menerapkannya, katakanlah, beberapa model bisnis, itu dapat menyebabkan masalah.
Salah satu masalah utama yang disebabkan oleh multikolinearitas adalah bahwa hal itu mengarah pada interpretasi yang salah dan memberikan wawasan yang salah. Koefisien regresi linier menunjukkan perubahan rata-rata dalam nilai target jika fitur diubah satu unit. Jadi, jika ada multikolinearitas, hal ini tidak berlaku karena mengubah satu fitur akan menyebabkan perubahan pada variabel berkorelasi dan perubahan konsekuen pada variabel target. Ini mengarah pada pemahaman yang salah dan dapat menghasilkan hasil yang berbahaya bagi bisnis.
Cara yang sangat efektif untuk menangani multikolinearitas adalah penggunaan VIF (Variance Inflation Factor). Semakin tinggi nilai VIF untuk suatu fitur, maka semakin linier pula korelasi fitur tersebut. Cukup hapus fitur dengan nilai VIF yang sangat tinggi dan latih kembali model pada kumpulan data yang tersisa.
10. Apa bentuk normal (persamaan) dari regresi linier? Kapan itu lebih disukai daripada metode penurunan gradien?
Persamaan normal untuk regresi linier adalah —
=(X T X) -1 . X T Y
Di sini, Y=β T X adalah model untuk regresi linier,
Y adalah target atau variabel terikat,
adalah vektor koefisien regresi, yang diperoleh dengan menggunakan persamaan normal,
X adalah matriks fitur yang berisi semua fitur sebagai kolom.
Perhatikan di sini bahwa kolom pertama dalam matriks X terdiri dari semua 1s. Ini untuk memasukkan nilai offset untuk garis regresi.
Perbandingan antara penurunan gradien dan persamaan normal:
| Keturunan Gradien | Persamaan Normal |
| Membutuhkan penyetelan hyper-parameter untuk alfa (parameter pembelajaran) | Tidak perlu seperti itu |
| Ini adalah proses berulang | Ini adalah proses non-iteratif |
| O(kn 2 ) kompleksitas waktu | O(n 3 ) kompleksitas waktu karena evaluasi X T X |
| Lebih disukai ketika n sangat besar | Menjadi sangat lambat untuk nilai n . yang besar |
Di sini, ' k ' adalah jumlah maksimum iterasi untuk penurunan gradien, dan ' n ' adalah jumlah total titik data dalam set pelatihan.
Jelas, jika kita memiliki data pelatihan yang besar, persamaan normal tidak disukai untuk digunakan. Untuk nilai ' n ' yang kecil, persamaan normal lebih cepat daripada penurunan gradien.
Apa itu Pembelajaran Mesin dan Mengapa itu penting
11. Anda menjalankan regresi pada subset data yang berbeda, dan di setiap subset, nilai beta untuk variabel tertentu sangat bervariasi. Apa yang bisa menjadi masalah di sini?
Kasus ini menyiratkan bahwa dataset bersifat heterogen. Jadi, untuk mengatasi masalah ini, dataset harus dikelompokkan menjadi subset yang berbeda, dan kemudian model terpisah harus dibangun untuk setiap cluster. Cara lain untuk mengatasi masalah ini adalah dengan menggunakan model non-parametrik, seperti pohon keputusan, yang dapat menangani data heterogen dengan cukup efisien.

12. Regresi linier Anda tidak berjalan dan menyampaikan bahwa ada jumlah tak terbatas dari perkiraan terbaik untuk koefisien regresi. Apa yang bisa salah?
Kondisi ini muncul ketika ada korelasi yang sempurna (positif atau negatif) antara beberapa variabel. Dalam hal ini, tidak ada nilai unik untuk koefisien, dan karenanya, kondisi yang diberikan muncul.
13. Apa yang dimaksud dengan Adjusted R 2 ? Apa bedanya dengan R2 ?
Adjusted R 2 , sama seperti R 2 , adalah perwakilan dari jumlah titik yang terletak di sekitar garis regresi. Artinya, ini menunjukkan seberapa baik model tersebut cocok dengan data pelatihan. Rumus untuk R 2 . yang disesuaikan adalah -
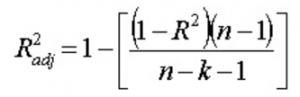
Di sini, n adalah jumlah titik data, dan k adalah jumlah fitur.
Salah satu kelemahan dari R 2 adalah akan selalu bertambah dengan adanya penambahan fitur baru, apakah fitur baru tersebut bermanfaat atau tidak. R 2 . yang disesuaikan mengatasi kelemahan ini. Nilai R2 yang disesuaikan meningkat hanya jika fitur yang baru ditambahkan memainkan peran penting dalam model.
14. Bagaimana Anda menginterpretasikan kurva nilai sisa vs nilai pas?
Plot nilai residual vs pas digunakan untuk melihat apakah nilai prediksi dan residual memiliki korelasi atau tidak. Jika residu terdistribusi secara normal, dengan rata-rata di sekitar nilai yang dipasang dan varians yang konstan, model kami berfungsi dengan baik; jika tidak, ada beberapa masalah dengan model.
Masalah paling umum yang dapat ditemukan saat melatih model pada rentang dataset yang besar adalah heteroskedastisitas (ini dijelaskan dalam jawaban di bawah). Adanya heteroskedastisitas dapat dengan mudah dilihat dengan memplot kurva nilai residual vs nilai pas.
15. Apa itu heteroskedastisitas? Apa akibatnya, dan bagaimana cara mengatasinya?
Sebuah variabel acak dikatakan heteroskedastis ketika subpopulasi yang berbeda memiliki variabilitas yang berbeda (standar deviasi).
Adanya heteroskedastisitas menimbulkan masalah tertentu dalam analisis regresi karena asumsi mengatakan bahwa istilah kesalahan tidak berkorelasi dan, karenanya, variansnya konstan. Adanya heteroskedastisitas sering terlihat dalam bentuk sebaran berbentuk kerucut untuk nilai residual vs nilai pas.
Salah satu asumsi dasar regresi linier adalah tidak adanya heteroskedastisitas dalam data. Akibat pelanggaran asumsi, estimator Ordinary Least Squares (OLS) bukanlah Penaksir Tak Bias Linier Terbaik (BLUE). Oleh karena itu, mereka tidak memberikan varians terkecil dari Penaksir Tidak Bias Linier (LUEs) lainnya.
Tidak ada prosedur tetap untuk mengatasi heteroskedastisitas. Namun, ada beberapa cara yang dapat menyebabkan pengurangan heteroskedastisitas. Mereka -
- Logaritma data: Sebuah seri yang meningkat secara eksponensial sering menghasilkan peningkatan variabilitas. Hal ini dapat diatasi dengan menggunakan transformasi log.
- Menggunakan regresi linier berbobot: Di sini, metode OLS diterapkan pada nilai pembobotan X dan Y. Salah satu caranya adalah dengan melampirkan bobot yang berhubungan langsung dengan besarnya variabel dependen.
16. Apa itu VIF? Bagaimana cara menghitungnya?
Variance Inflation Factor (VIF) digunakan untuk memeriksa adanya multikolinearitas dalam suatu dataset. Itu dihitung sebagai-
Di sini, VIF j adalah nilai VIF untuk variabel ke -j ,
Rj 2 adalah nilai R2 dari model ketika variabel tersebut diregresi terhadap semua variabel independen lainnya.
Jika nilai VIF tinggi untuk suatu variabel, itu berarti bahwa R 2 nilai model yang sesuai tinggi, yaitu variabel independen lainnya mampu menjelaskan variabel tersebut. Secara sederhana, variabel tersebut bergantung secara linier pada beberapa variabel lain.
17. Bagaimana Anda tahu bahwa regresi linier cocok untuk data apa pun?
Untuk melihat apakah regresi linier cocok untuk data apa pun, plot pencar dapat digunakan. Jika hubungan terlihat linier, kita dapat menggunakan model linier. Tetapi jika tidak demikian, kita harus menerapkan beberapa transformasi untuk membuat hubungan menjadi linier. Memplot plot pencar mudah dalam kasus regresi linier sederhana atau univariat. Tetapi dalam kasus regresi linier multivariat, plot sebar berpasangan dua dimensi, plot berputar, dan grafik dinamis dapat diplot.
18. Bagaimana pengujian hipotesis digunakan dalam regresi linier?
Pengujian hipotesis dapat dilakukan dalam regresi linier untuk tujuan sebagai berikut:
- Untuk memeriksa apakah sebuah prediktor signifikan untuk prediksi variabel target. Dua metode umum untuk ini adalah -
- Dengan menggunakan nilai-p:
Jika p-value suatu variabel lebih besar dari batas tertentu (biasanya 0,05), variabel tersebut tidak signifikan dalam prediksi variabel target. - Dengan memeriksa nilai koefisien regresi:
Jika nilai koefisien regresi yang sesuai dengan sebuah prediktor adalah nol, variabel tersebut tidak signifikan dalam prediksi variabel target dan tidak memiliki hubungan linier dengannya.
- Dengan menggunakan nilai-p:
- Untuk memeriksa apakah koefisien regresi yang dihitung merupakan penduga yang baik dari koefisien sebenarnya.
19. Jelaskan penurunan gradien sehubungan dengan regresi linier.
Penurunan gradien adalah algoritma optimasi. Dalam regresi linier, digunakan untuk mengoptimalkan fungsi biaya dan menemukan nilai s (penduga) yang sesuai dengan nilai optimal dari fungsi biaya.
Penurunan gradien bekerja seperti bola yang menggelinding ke bawah grafik (mengabaikan inersia). Bola bergerak sepanjang arah gradien terbesar dan berhenti pada permukaan datar (minima). 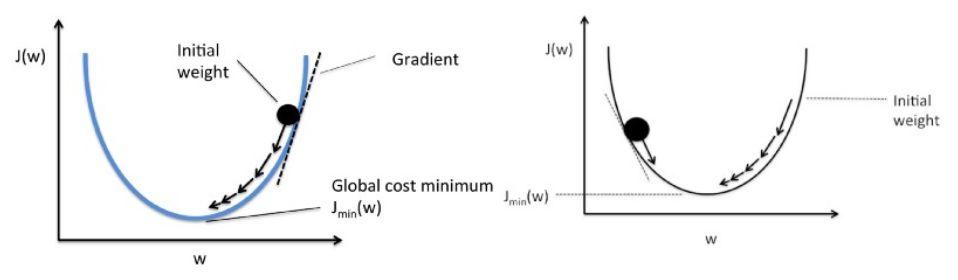
Secara matematis, tujuan penurunan gradien untuk regresi linier adalah untuk menemukan solusi dari
ArgMin J(Θ 0 ,Θ 1 ), di mana J( 0 ,Θ 1 ) adalah fungsi biaya dari regresi linier. Ini diberikan oleh - 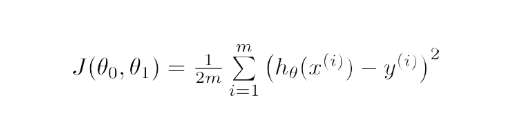
Di sini, h adalah model hipotesis linier, h=Θ 0 + 1 x, y adalah output sebenarnya, dan m adalah jumlah titik data dalam set pelatihan.
Gradient Descent dimulai dengan solusi acak, dan kemudian berdasarkan arah gradien, solusi diperbarui ke nilai baru di mana fungsi biaya memiliki nilai yang lebih rendah.
Pembaruannya adalah:
Ulangi sampai konvergen 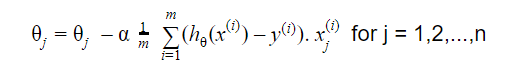
20. Bagaimana Anda menginterpretasikan model regresi linier?
Model regresi linier cukup mudah untuk diinterpretasikan. Modelnya berbentuk seperti berikut: 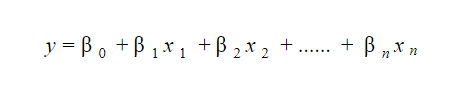
Arti penting dari model ini terletak pada kenyataan bahwa seseorang dapat dengan mudah menafsirkan dan memahami perubahan marjinal dan konsekuensinya. Misalnya, jika nilai x 0 bertambah 1 satuan, dengan menjaga variabel lain tetap konstan, total kenaikan nilai y akan menjadi i . Secara matematis, suku intersep ( 0 ) adalah respons ketika semua suku prediktor diset ke nol atau tidak dipertimbangkan.
6 Teknik Pembelajaran Mesin Ini Meningkatkan Layanan Kesehatan
21. Apa itu regresi kuat?
Sebuah model regresi harus kuat di alam. Ini berarti bahwa dengan perubahan dalam beberapa pengamatan, model tidak akan berubah secara drastis. Juga, seharusnya tidak terlalu terpengaruh oleh outlier.
Model regresi dengan OLS (Ordinary Least Squares) cukup sensitif terhadap outlier. Untuk mengatasi masalah ini, kita dapat menggunakan metode WLS (Weighted Least Squares) untuk menentukan estimator dari koefisien regresi. Di sini, lebih sedikit bobot yang diberikan pada outlier atau poin leverage yang tinggi dalam fitting, membuat poin ini kurang berdampak.
22. Grafik mana yang disarankan untuk diamati sebelum pemasangan model?
Sebelum memasang model, kita harus mengetahui data dengan baik, seperti apa tren, distribusi, skewness, dll. dalam variabel. Grafik seperti histogram, plot kotak, dan plot titik dapat digunakan untuk mengamati distribusi variabel. Selain itu, kita juga harus menganalisis apa hubungan antara variabel dependen dan independen. Ini dapat dilakukan dengan plot pencar (dalam kasus masalah univariat), plot berputar, plot dinamis, dll.
23. Apa yang dimaksud dengan model linier umum?
Model linier tergeneralisasi merupakan turunan dari model regresi linier biasa. GLM lebih fleksibel dalam hal residual dan dapat digunakan di mana regresi linier tampaknya tidak sesuai. GLM memungkinkan distribusi residual menjadi selain distribusi normal. Ini menggeneralisasi regresi linier dengan memungkinkan model linier untuk menghubungkan ke variabel target menggunakan fungsi penghubung. Estimasi model dilakukan dengan menggunakan metode estimasi kemungkinan maksimum.
24. Jelaskan trade-off bias-varians.
Bias mengacu pada perbedaan antara nilai yang diprediksi oleh model dan nilai sebenarnya. Ini adalah kesalahan. Salah satu tujuan dari algoritma ML adalah memiliki bias yang rendah.
Varians mengacu pada sensitivitas model terhadap fluktuasi kecil dalam set data pelatihan. Tujuan lain dari algoritma ML adalah memiliki varians yang rendah.
Untuk kumpulan data yang tidak sepenuhnya linier, tidak mungkin memiliki bias dan varians yang rendah pada saat yang bersamaan. Model garis lurus akan memiliki varians rendah tetapi bias tinggi, sedangkan polinomial derajat tinggi akan memiliki bias rendah tetapi varians tinggi.
Tidak ada jalan keluar dari hubungan antara bias dan varians dalam pembelajaran mesin.
- Mengurangi bias meningkatkan varians.
- Mengurangi varians meningkatkan bias.
Jadi, ada trade-off antara keduanya; spesialis ML harus memutuskan, berdasarkan masalah yang ditetapkan, seberapa besar bias dan varians yang dapat ditoleransi. Berdasarkan ini, model akhir dibangun.
25. Bagaimana kurva belajar membantu menciptakan model yang lebih baik?
Kurva pembelajaran memberikan indikasi adanya overfitting atau underfitting.
Dalam kurva belajar, kesalahan pelatihan dan kesalahan validasi silang diplot terhadap jumlah titik data pelatihan. Kurva pembelajaran yang khas terlihat seperti ini: 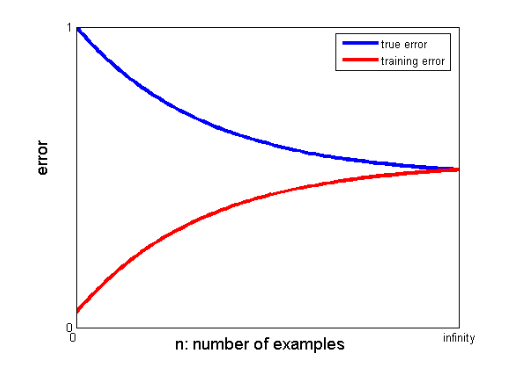
Jika kesalahan pelatihan dan kesalahan sebenarnya (kesalahan validasi silang) bertemu ke nilai yang sama dan nilai kesalahan yang sesuai tinggi, ini menunjukkan bahwa model tersebut kurang cocok dan menderita bias tinggi.
Wawancara Pembelajaran Mesin dan Cara Menguasainya
Wawancara Pembelajaran Mesin dapat bervariasi sesuai dengan jenis atau kategorinya, misalnya beberapa perekrut mengajukan banyak pertanyaan wawancara Regresi Linier . Saat menjalani peran wawancara Insinyur Pembelajaran Mesin, mereka dapat berspesialisasi dalam kategori seperti Pengodean, Penelitian, Studi Kasus, Manajemen Proyek, Presentasi, Desain Sistem, dan Statistik. Kami akan fokus pada jenis kategori yang paling umum dan bagaimana mempersiapkannya.
- Pengkodean
Pengkodean dan pemrograman adalah komponen penting dari wawancara pembelajaran mesin dan sering digunakan untuk menyaring pelamar. Untuk melakukannya dengan baik dalam wawancara ini, Anda harus memiliki kemampuan pemrograman yang solid. Wawancara pengkodean biasanya berlangsung selama 45 hingga 60 menit dan hanya terdiri dari dua pertanyaan. Pewawancara mengajukan topik dan mengantisipasi bahwa pelamar akan membahasnya dalam waktu sesingkat mungkin.
Bagaimana mempersiapkan – Anda dapat mempersiapkan wawancara ini dengan memiliki pemahaman yang baik tentang struktur data, kompleksitas waktu dan ruang, keterampilan manajemen, dan kemampuan untuk memahami dan menyelesaikan masalah. upGrad memiliki kursus rekayasa perangkat lunak yang hebat yang dapat membantu Anda meningkatkan keterampilan pengkodean dan menguasai wawancara itu.
2. Pembelajaran Mesin
Pemahaman Anda tentang pembelajaran mesin akan dievaluasi melalui wawancara. Lapisan convolutional, jaringan saraf berulang, jaringan musuh generatif, pengenalan suara, dan topik lainnya dapat dicakup tergantung pada kebutuhan pekerjaan.
Bagaimana mempersiapkan – Untuk dapat menguasai wawancara ini, Anda harus memastikan bahwa Anda memiliki pemahaman menyeluruh tentang peran dan tanggung jawab pekerjaan. Ini akan membantu Anda mengidentifikasi spesifikasi ML yang harus Anda pelajari. Namun, jika Anda tidak menemukan spesifikasi apa pun, Anda harus sangat memahami dasar-dasarnya. Kursus mendalam tentang ML yang disediakan upGrad dapat membantu Anda dalam hal itu. Anda juga dapat mempelajari artikel terbaru tentang ML dan AI untuk memahami tren terbaru mereka dan Anda dapat menggabungkannya secara teratur.
3. Pemutaran
Wawancara ini agak informal dan biasanya salah satu poin awal wawancara. Seorang calon majikan sering menanganinya. Tujuan utama wawancara ini adalah untuk memberikan pelamar rasa bisnis, peran, dan tugas. Dalam suasana yang lebih informal, kandidat juga ditanyai tentang masa lalu mereka untuk menentukan apakah bidang yang mereka minati cocok dengan posisi tersebut.
Bagaimana mempersiapkan – Ini adalah bagian yang sangat non-teknis dari wawancara. Semua ini diperlukan adalah kejujuran Anda dan dasar-dasar spesialisasi Anda dalam Pembelajaran Mesin.
4. Desain Sistem
Wawancara semacam itu menguji kemampuan seseorang untuk menciptakan solusi yang sepenuhnya terukur dari awal hingga akhir. Mayoritas insinyur begitu sibuk dengan masalah sehingga mereka sering mengabaikan gambaran yang lebih luas. Wawancara desain sistem membutuhkan pemahaman tentang banyak elemen yang digabungkan untuk menghasilkan solusi. Elemen-elemen ini termasuk tata letak front-end, penyeimbang beban, cache, dan banyak lagi. Sistem end-to-end yang efektif dan terukur lebih mudah untuk dikembangkan ketika masalah ini dipahami dengan baik.
Bagaimana mempersiapkan – Memahami konsep dan komponen proyek desain sistem. Gunakan contoh kehidupan nyata untuk menjelaskan struktur kepada pewawancara Anda untuk pemahaman yang lebih baik tentang proyek tersebut.
Blog Pembelajaran Mesin dan Kecerdasan Buatan Populer
| IoT: Sejarah, Sekarang & Masa Depan | Tutorial Pembelajaran Mesin: Belajar ML | Apa itu Algoritma? Sederhana & Mudah |
| Gaji Insinyur Robotika di India : Semua Peran | Sehari dalam Kehidupan Seorang Insinyur Pembelajaran Mesin: Apa yang mereka lakukan? | Apa itu IoT (Internet of Things) |
| Permutasi vs Kombinasi: Perbedaan antara Permutasi dan Kombinasi | 7 Tren Teratas dalam Kecerdasan Buatan & Pembelajaran Mesin | Pembelajaran Mesin dengan R: Semua yang Perlu Anda Ketahui |
Jika ada kesenjangan yang signifikan antara nilai-nilai konvergen dari pelatihan dan kesalahan validasi silang, yaitu kesalahan validasi silang secara signifikan lebih tinggi daripada kesalahan pelatihan, ini menunjukkan bahwa model tersebut terlalu cocok dengan data pelatihan dan menderita varians yang tinggi. .
Insinyur Pembelajaran Mesin: Mitos vs. Realitas
Itulah akhir dari bagian pertama dari seri ini. Tunggu bagian selanjutnya dari seri yang terdiri dari pertanyaan berdasarkan Regresi Logistik . Jangan ragu untuk memposting komentar Anda.
Ditulis bersama oleh – Ojas Agarwal
Anda dapat memeriksa Program PG Eksekutif kami di Machine Learning & AI , yang menyediakan lokakarya praktis, mentor industri satu-ke-satu, 12 studi kasus dan tugas, status Alumni IIIT-B, dan banyak lagi.
Apa yang Anda pahami tentang regularisasi?
Regularisasi merupakan salah satu strategi untuk mengatasi masalah model overfitting. Overfitting terjadi ketika model yang rumit diterapkan pada data pelatihan. Model dasar mungkin tidak dapat menggeneralisasi data pada waktu tertentu, dan model yang rumit mungkin terlalu sesuai dengan data. Regularisasi digunakan untuk mengatasi masalah ini. Regularisasi adalah proses penambahan suku-suku koefisien (beta) pada masalah minimisasi sedemikian rupa sehingga suku-suku tersebut dikenai sanksi dan memiliki besaran yang sederhana. Ini pada dasarnya membantu dalam mengidentifikasi pola data sekaligus mencegah overfitting dengan mencegah model menjadi terlalu kompleks.
Apa yang Anda pahami tentang rekayasa fitur?
Proses mengubah data asli menjadi fitur yang lebih menggambarkan masalah mendasar ke model prediktif, menghasilkan akurasi model yang ditingkatkan pada data yang tidak terlihat, dikenal sebagai rekayasa fitur. Dalam istilah awam, rekayasa fitur mengacu pada pembuatan fitur tambahan yang dapat membantu dalam pemahaman dan pemodelan masalah yang lebih baik. Ada dua jenis rekayasa fitur: berbasis bisnis dan berbasis data. Penggabungan fitur dari sudut pandang komersial adalah fokus dari rekayasa fitur yang digerakkan oleh bisnis.
Apa tradeoff bias-varians?
Kesenjangan antara model - nilai prediksi dan nilai aktual disebut sebagai bias. Ini sebuah kesalahan. Bias rendah adalah salah satu tujuan dari algoritma ML. Kerentanan model terhadap perubahan kecil dalam kumpulan data pelatihan disebut sebagai varians. Varians rendah adalah tujuan lain dari algoritma ML. Tidak mungkin memiliki bias rendah dan varians rendah dalam kumpulan data yang tidak linier sempurna. Varians model garis lurus rendah, tetapi biasnya besar, sedangkan varians polinomial derajat tinggi rendah, tetapi biasnya tinggi. Dalam pembelajaran mesin, hubungan antara bias dan variasi tidak dapat dihindari.