
Pengklasifikasi KNN Untuk Pembelajaran Mesin: Semua yang Perlu Anda Ketahui
Diterbitkan: 2021-09-28Ingat saat kecerdasan buatan (AI) hanya sebuah konsep yang terbatas pada novel dan film fiksi ilmiah? Berkat kemajuan teknologi, AI adalah sesuatu yang kita jalani setiap hari. Dari Alexa dan Siri yang siap membantu kami dan menelepon ke platform OTT "memilih sendiri" film yang ingin kami tonton, AI hampir menjadi urutan hari ini dan ada di sini untuk mengatakan di masa mendatang.
Ini semua dimungkinkan berkat algoritme ML tingkat lanjut. Hari ini, kita akan berbicara tentang salah satu algoritma ML yang berguna, K-NN Classifier.
Sebuah cabang dari AI dan ilmu komputer, pembelajaran mesin menggunakan data dan algoritme untuk meniru pemahaman manusia sambil secara bertahap meningkatkan akurasi algoritme. Pembelajaran mesin melibatkan algoritme pelatihan untuk membuat prediksi atau klasifikasi dan menggali wawasan utama yang mendorong pengambilan keputusan strategis dalam bisnis dan aplikasi.
Algoritma KNN (k-nearest tetangga) adalah algoritma pembelajaran mesin terawasi mendasar yang digunakan untuk memecahkan pernyataan masalah regresi dan klasifikasi. Jadi, mari selami untuk mengetahui lebih banyak tentang K-NN Classifier.
Daftar isi
Pembelajaran Mesin Diawasi vs Tidak Diawasi
Pembelajaran terawasi dan tidak terawasi adalah dua pendekatan ilmu data dasar, dan penting untuk mengetahui perbedaannya sebelum kita masuk ke detail KNN.
Pembelajaran yang diawasi adalah pendekatan pembelajaran mesin yang menggunakan kumpulan data berlabel untuk membantu memprediksi hasil. Kumpulan data tersebut dirancang untuk "mengawasi" atau melatih algoritme untuk memprediksi hasil atau mengklasifikasikan data secara akurat. Oleh karena itu, input dan output berlabel memungkinkan model untuk belajar dari waktu ke waktu sambil meningkatkan akurasinya.

Pembelajaran yang diawasi melibatkan dua jenis masalah – klasifikasi dan regresi. Dalam masalah klasifikasi , algoritma mengalokasikan data uji ke dalam kategori diskrit, seperti memisahkan kucing dari anjing.
Contoh nyata yang signifikan adalah mengklasifikasikan email spam ke dalam folder yang terpisah dari kotak masuk Anda. Di sisi lain, metode regresi pembelajaran terawasi melatih algoritma untuk memahami hubungan antara variabel independen dan dependen. Ini menggunakan titik data yang berbeda untuk memprediksi nilai numerik, seperti memproyeksikan pendapatan penjualan untuk bisnis.
Pembelajaran tanpa pengawasan , sebaliknya, menggunakan algoritme pembelajaran mesin untuk analisis dan pengelompokan kumpulan data yang tidak berlabel. Dengan demikian, tidak perlu campur tangan manusia ("tanpa pengawasan") agar algoritme dapat mengidentifikasi pola tersembunyi dalam data.
Model pembelajaran tanpa pengawasan memiliki tiga aplikasi utama – asosiasi, pengelompokan, dan pengurangan dimensi. Namun, kami tidak akan membahas detailnya karena di luar cakupan diskusi kami.
K-Tetangga Terdekat (KNN)
Algoritma K-Nearest Neighbor atau KNN merupakan algoritma machine learning yang berbasis model supervised learning. Algoritma K-NN bekerja dengan mengasumsikan bahwa hal-hal serupa ada dekat satu sama lain. Oleh karena itu, algoritma K-NN menggunakan kesamaan fitur antara titik data baru dan titik dalam set pelatihan (kasus yang tersedia) untuk memprediksi nilai titik data baru. Intinya, algoritma K-NN memberikan nilai ke titik data terbaru berdasarkan seberapa miripnya dengan titik-titik di set pelatihan. Algoritma K-NN menemukan aplikasi dalam masalah klasifikasi dan regresi tetapi terutama digunakan untuk masalah klasifikasi.
Berikut adalah contoh untuk memahami K-NN Classifier.

Sumber
Pada gambar di atas, nilai inputnya adalah makhluk yang memiliki kemiripan dengan kucing dan anjing. Namun, kami ingin mengklasifikasikannya menjadi kucing atau anjing. Jadi, kita dapat menggunakan algoritma K-NN untuk klasifikasi ini. Model K-NN akan menemukan kesamaan antara kumpulan data baru (input) dengan gambar kucing dan anjing yang tersedia (kumpulan data pelatihan). Selanjutnya, model akan menempatkan titik data baru dalam kategori kucing atau anjing berdasarkan fitur yang paling mirip.
Demikian juga, kategori A (titik hijau) dan kategori B (titik oranye) memiliki contoh grafis di atas. Kami juga memiliki titik data baru (titik biru) yang akan termasuk dalam salah satu kategori. Kami dapat menyelesaikan masalah klasifikasi ini menggunakan algoritma K-NN dan mengidentifikasi kategori titik data baru.
Mendefinisikan Properti Algoritma K-NN
Dua properti berikut paling baik mendefinisikan algoritma K-NN:
- Ini adalah algoritma pembelajaran malas karena alih-alih belajar dari set pelatihan segera, algoritma K-NN menyimpan dataset dan melatih dari dataset pada saat klasifikasi.
- K-NN juga merupakan algoritma non-parametrik , artinya tidak membuat asumsi tentang data yang mendasarinya.
Kerja Algoritma K-NN
Sekarang, mari kita lihat langkah-langkah berikut untuk memahami cara kerja algoritma K-NN.
Langkah 1: Muat data pelatihan dan pengujian.
Langkah 2: Pilih titik data terdekat, yaitu nilai K.
Langkah 3: Hitung jarak K jumlah tetangga (jarak antara setiap baris data latih dan data uji). Metode Euclidean paling umum digunakan untuk menghitung jarak.
Langkah 4: Ambil K tetangga terdekat berdasarkan jarak Euclidean yang dihitung.
Langkah 5: Di antara K tetangga terdekat, hitung jumlah titik data di setiap kategori.
Langkah 6: Berikan poin data baru ke kategori yang jumlah tetangganya maksimum.
Langkah 7: Akhir. Modelnya sekarang sudah siap.
Bergabunglah dengan kursus Kecerdasan Buatan online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
Memilih nilai K
K adalah parameter kritis dalam algoritma K-NN. Oleh karena itu, kita perlu mengingat beberapa poin sebelum kita memutuskan nilai K.
Menggunakan kurva kesalahan adalah metode umum untuk menentukan nilai K. Gambar di bawah menunjukkan kurva kesalahan untuk nilai K yang berbeda untuk data pengujian dan pelatihan.


Sumber
Dalam contoh grafik di atas, kesalahan kereta adalah nol pada K=1 dalam data pelatihan karena tetangga terdekat ke titik itu adalah titik itu sendiri. Namun, kesalahan pengujian tinggi bahkan pada nilai K yang rendah. Ini disebut varians tinggi atau overfitting data. Kesalahan pengujian berkurang ketika kita meningkatkan nilai K. Tetapi setelah nilai K tertentu, kita melihat bahwa kesalahan pengujian meningkat lagi, yang disebut bias atau underfitting. Dengan demikian, kesalahan data pengujian awalnya tinggi karena varians, kemudian menurun dan stabil, dan dengan peningkatan lebih lanjut dalam nilai K, kesalahan pengujian kembali meningkat karena bias.
Oleh karena itu, nilai K di mana kesalahan uji stabil dan rendah diambil sebagai nilai K yang optimal. Mengingat kurva kesalahan di atas, K=8 adalah nilai optimal.
Contoh Memahami Cara Kerja Algoritma K-NN
Pertimbangkan dataset yang telah diplot sebagai berikut:

Sumber
Katakanlah ada titik data baru (titik hitam) di (60,60) yang harus kita klasifikasikan ke dalam kelas ungu atau merah. Kita akan menggunakan K=3, artinya titik data baru akan menemukan tiga titik data terdekat, dua di kelas merah dan satu di kelas ungu.
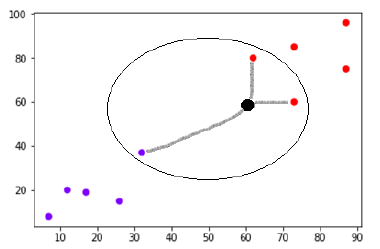
Sumber
Tetangga terdekat ditentukan dengan menghitung jarak Euclidean antara dua titik. Berikut ilustrasi untuk menunjukkan bagaimana perhitungan dilakukan.

Sumber
Sekarang, karena dua (dari tiga) tetangga terdekat dari titik data baru (titik hitam) terletak di kelas merah, titik data baru juga akan ditugaskan ke kelas merah.
Bergabunglah dengan Kursus Pembelajaran Mesin online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
K-NN sebagai Classifier (Implementasi dengan Python)
Sekarang setelah kita memiliki penjelasan yang disederhanakan tentang algoritma K-NN, mari kita lanjutkan penerapan algoritma K-NN dengan Python. Kami hanya akan fokus pada K-NN Classifier.
Langkah 1: Impor paket Python yang diperlukan.

Sumber
Langkah 2: Unduh dataset iris dari UCI Machine Learning Repository. Tautan webnya adalah “https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data”
Langkah 3: Tetapkan nama kolom ke kumpulan data.

Sumber
Langkah 4: Baca dataset ke Pandas DataFrame.

Sumber
Langkah 5: Pra-pemrosesan data dilakukan dengan menggunakan baris skrip berikut.

Sumber
Langkah 6: Bagi dataset menjadi test dan train split. Kode di bawah ini akan membagi dataset menjadi 40% data pengujian dan 60% data pelatihan.

Sumber
Langkah 7: Penskalaan data dilakukan sebagai berikut:

Sumber
Langkah 8: Latih model menggunakan kelas sklearn KNeighborsClassifier.

Sumber
Langkah 9: Buat prediksi menggunakan skrip berikut:

Sumber
Langkah 10: Cetak hasilnya.

Sumber
Keluaran:

Sumber
Apa selanjutnya? Mendaftar untuk Program Sertifikat Tingkat Lanjut dalam Pembelajaran Mesin dari IIT Madras dan upGrad
Misalkan Anda bercita-cita menjadi Ilmuwan Data atau Profesional Pembelajaran Mesin yang terampil. Dalam hal ini, Kursus Sertifikasi Lanjutan dalam Pembelajaran Mesin dan Cloud dari IIT Madras dan upGrad hanya untuk Anda!
Program online 12 bulan dirancang khusus untuk para profesional yang bekerja yang ingin menguasai konsep dalam Pembelajaran Mesin, Pemrosesan Data Besar, Manajemen Data, Pergudangan Data, Cloud, dan penerapan model Pembelajaran Mesin.
Berikut adalah beberapa sorotan kursus untuk memberi Anda gambaran yang lebih baik tentang apa yang ditawarkan program ini:
- Sertifikasi bergengsi yang diterima secara global dari IIT Madras
- 500+ jam pembelajaran, 20+ studi kasus dan proyek, 25+ sesi bimbingan industri, 8+ tugas pengkodean
- Cakupan komprehensif dari 7 bahasa dan alat pemrograman
- 4 minggu proyek batu penjuru industri
- Lokakarya praktis
- Jaringan peer-to-peer offline
Daftar hari ini untuk mempelajari lebih lanjut tentang program ini!
Kesimpulan
Seiring waktu, Big Data terus berkembang, dan kecerdasan buatan semakin terjalin dengan kehidupan kita. Akibatnya, ada peningkatan tajam dalam permintaan profesional ilmu data yang dapat memanfaatkan kekuatan model pembelajaran mesin untuk mengumpulkan wawasan data dan meningkatkan proses bisnis penting dan, secara umum, dunia kita. Tak ayal, bidang kecerdasan buatan dan machine learning memang terlihat menjanjikan. Dengan upGrad , Anda dapat yakin bahwa karier Anda dalam pembelajaran mesin dan cloud sangat bermanfaat!
Mengapa K-NN merupakan pengklasifikasi yang baik?
Keuntungan utama K-NN dibandingkan algoritma pembelajaran mesin lainnya adalah kita dapat dengan mudah menggunakan K-NN untuk klasifikasi multikelas. Dengan demikian, K-NN adalah algoritma terbaik jika kita perlu mengklasifikasikan data menjadi lebih dari dua kategori atau jika data terdiri lebih dari dua label. Selain itu, sangat ideal untuk data non-linier dan memiliki akurasi yang relatif tinggi.
Apa batasan dari algoritma K-NN?
Algoritma K-NN bekerja dengan menghitung jarak antar titik data. Oleh karena itu, cukup jelas bahwa ini adalah algoritma yang relatif lebih memakan waktu dan akan membutuhkan lebih banyak waktu untuk mengklasifikasikan dalam beberapa kasus. Oleh karena itu, sebaiknya tidak menggunakan terlalu banyak titik data saat menggunakan K-NN untuk klasifikasi multiclass. Keterbatasan lainnya termasuk penyimpanan memori yang tinggi dan kepekaan terhadap fitur yang tidak relevan.
Apa aplikasi dunia nyata K-NN?
K-NN memiliki beberapa kasus penggunaan nyata dalam pembelajaran mesin, seperti deteksi tulisan tangan, pengenalan suara, pengenalan video, dan pengenalan gambar. Di perbankan, K-NN digunakan untuk memprediksi apakah seseorang memenuhi syarat untuk mendapatkan pinjaman berdasarkan apakah mereka memiliki karakteristik yang mirip dengan mangkir. Dalam politik, K-NN dapat digunakan untuk mengklasifikasikan calon pemilih ke dalam kelas yang berbeda seperti “akan memilih partai X” atau “akan memilih partai Y”, dll.