
Konversi Gambar Ke Teks Dengan React Dan Tesseract.js (OCR)
Diterbitkan: 2022-03-10Data adalah tulang punggung setiap aplikasi perangkat lunak karena tujuan utama dari sebuah aplikasi adalah untuk memecahkan masalah manusia. Untuk memecahkan masalah manusia, perlu memiliki beberapa informasi tentang mereka.
Informasi tersebut direpresentasikan sebagai data, terutama melalui komputasi. Di web, data sebagian besar dikumpulkan dalam bentuk teks, gambar, video, dan banyak lagi. Terkadang, gambar mengandung teks penting yang dimaksudkan untuk diproses untuk mencapai tujuan tertentu. Gambar-gambar ini sebagian besar diproses secara manual karena tidak ada cara untuk memprosesnya secara terprogram.
Ketidakmampuan untuk mengekstrak teks dari gambar adalah batasan pemrosesan data yang saya alami secara langsung di perusahaan terakhir saya. Kami perlu memproses kartu hadiah yang dipindai dan kami harus melakukannya secara manual karena kami tidak dapat mengekstrak teks dari gambar.
Ada departemen yang disebut "Operasi" di dalam perusahaan yang bertanggung jawab untuk mengonfirmasi kartu hadiah secara manual dan mengkredit akun pengguna. Meskipun kami memiliki situs web tempat pengguna terhubung dengan kami, pemrosesan kartu hadiah dilakukan secara manual di belakang layar.
Pada saat itu, website kami dibangun terutama dengan PHP (Laravel) untuk backend dan JavaScript (jQuery dan Vue) untuk frontend. Tumpukan teknis kami cukup baik untuk bekerja dengan Tesseract.js asalkan masalah ini dianggap penting oleh manajemen.
Saya bersedia untuk memecahkan masalah tetapi tidak perlu untuk memecahkan masalah dilihat dari sudut pandang bisnis atau manajemen. Setelah meninggalkan perusahaan, saya memutuskan untuk melakukan riset dan mencoba mencari solusi yang memungkinkan. Akhirnya, saya menemukan OCR.
Apa itu OCR?
OCR adalah singkatan dari "Pengenalan Karakter Optik" atau "Pembaca Karakter Optik". Digunakan untuk mengekstrak teks dari gambar.
Evolusi OCR dapat ditelusuri ke beberapa penemuan tetapi Optophone, "Gismo", pemindai flatbed CCD, Newton MesssagePad dan Tesseract adalah penemuan utama yang membawa pengenalan karakter ke tingkat kegunaan yang lain.
Jadi, mengapa menggunakan OCR? Nah, Optical Character Recognition memecahkan banyak masalah, salah satunya memicu saya untuk menulis artikel ini. Saya menyadari kemampuan untuk mengekstrak teks dari gambar memastikan banyak kemungkinan seperti:
- Peraturan
Setiap organisasi perlu mengatur aktivitas pengguna karena beberapa alasan. Peraturan tersebut dapat digunakan untuk melindungi hak pengguna dan mengamankan mereka dari ancaman atau penipuan.
Mengekstrak teks dari gambar memungkinkan organisasi untuk memproses informasi tekstual pada gambar untuk regulasi, terutama ketika gambar dipasok oleh beberapa pengguna.
Misalnya, regulasi seperti Facebook tentang jumlah teks pada gambar yang digunakan untuk iklan dapat dicapai dengan OCR. Selain itu, menyembunyikan konten sensitif di Twitter juga dimungkinkan oleh OCR. - Kemampuan pencarian
Pencarian adalah salah satu kegiatan yang paling umum, terutama di internet. Algoritma pencarian sebagian besar didasarkan pada manipulasi teks. Dengan Pengenalan Karakter Optik, dimungkinkan untuk mengenali karakter pada gambar dan menggunakannya untuk memberikan hasil gambar yang relevan kepada pengguna. Singkatnya, gambar dan video sekarang dapat dicari dengan bantuan OCR. - Aksesibilitas
Memiliki teks pada gambar selalu menjadi tantangan untuk aksesibilitas dan merupakan aturan praktis untuk memiliki sedikit teks pada gambar. Dengan OCR, pembaca layar dapat memiliki akses ke teks pada gambar untuk memberikan pengalaman yang diperlukan bagi penggunanya. - Otomatisasi Pemrosesan Data Pemrosesan data sebagian besar otomatis untuk skala. Adanya teks pada gambar merupakan keterbatasan dalam pengolahan data karena teks tidak dapat diproses kecuali secara manual. Optical Character Recognition (OCR) memungkinkan untuk mengekstrak teks pada gambar secara terprogram, sehingga memastikan otomatisasi pemrosesan data terutama jika berkaitan dengan pemrosesan teks pada gambar.
- Digitalisasi Bahan Cetakan
Semuanya serba digital dan masih banyak dokumen yang harus didigitalkan. Cek, sertifikat, dan dokumen fisik lainnya sekarang dapat didigitalkan dengan menggunakan Optical Character Recognition.
Mengetahui semua kegunaan di atas memperdalam minat saya, jadi saya memutuskan untuk melangkah lebih jauh dengan mengajukan pertanyaan:
“Bagaimana saya bisa menggunakan OCR di web, terutama di aplikasi React?”
Pertanyaan itu membawa saya ke Tesseract.js.
Apa itu Tesseract.js?
Tesseract.js adalah perpustakaan JavaScript yang mengkompilasi Tesseract asli dari C ke JavaScript WebAssembly sehingga membuat OCR dapat diakses di browser. Mesin Tesseract.js awalnya ditulis dalam ASM.js dan kemudian di-porting ke WebAssembly tetapi ASM.js masih berfungsi sebagai cadangan dalam beberapa kasus ketika WebAssembly tidak didukung.
Seperti yang dinyatakan di situs web Tesseract.js, ini mendukung lebih dari 100 bahasa , orientasi teks otomatis dan deteksi skrip, antarmuka sederhana untuk membaca paragraf, kata, dan kotak pembatas karakter.
Tesseract adalah mesin pengenalan karakter optik untuk berbagai sistem operasi. Ini adalah perangkat lunak gratis, dirilis di bawah Lisensi Apache. Hewlett-Packard mengembangkan Tesseract sebagai perangkat lunak berpemilik pada 1980-an. Ini dirilis sebagai open source pada tahun 2005 dan pengembangannya telah disponsori oleh Google sejak tahun 2006.
Versi terbaru, versi 4, Tesseract dirilis pada Oktober 2018 dan berisi mesin OCR baru yang menggunakan sistem jaringan saraf berdasarkan Long Short-Term Memory (LSTM) dan dimaksudkan untuk menghasilkan hasil yang lebih akurat.
Memahami API Tesseract
Untuk benar-benar memahami cara kerja Tesseract, kita perlu memecah beberapa API dan komponennya. Menurut dokumentasi Tesseract.js, ada dua cara untuk menggunakannya. Di bawah ini adalah pendekatan pertama dan pemecahannya:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } Metode yang recognize mengambil gambar sebagai argumen pertamanya, bahasa (yang bisa berlipat ganda) sebagai argumen kedua dan { logger: m => console.log(me) } sebagai argumen terakhirnya. Format gambar yang didukung oleh Tesseract adalah jpg, png, bmp dan pbm yang hanya dapat diberikan sebagai elemen (img, video atau kanvas), objek file ( <input> ), objek blob, jalur atau URL ke gambar dan gambar yang dikodekan base64 . (Baca di sini untuk informasi lebih lanjut tentang semua format gambar yang dapat ditangani Tesseract.)
Bahasa disediakan sebagai string seperti eng . Tanda + dapat digunakan untuk menggabungkan beberapa bahasa seperti pada eng+chi_tra . Argumen bahasa digunakan untuk menentukan data bahasa terlatih yang akan digunakan dalam pemrosesan gambar.
Catatan : Anda akan menemukan semua bahasa yang tersedia dan kodenya di sini.
{ logger: m => console.log(m) } sangat berguna untuk mendapatkan informasi tentang kemajuan suatu gambar yang sedang diproses. Properti logger mengambil fungsi yang akan dipanggil beberapa kali saat Tesseract memproses gambar. Parameter ke fungsi logger harus berupa objek dengan workerId , jobId , status dan progress sebagai propertinya:
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress adalah angka antara 0 dan 1, dan dalam persentase untuk menunjukkan kemajuan proses pengenalan gambar.
Tesseract secara otomatis menghasilkan objek sebagai parameter untuk fungsi logger tetapi juga dapat diberikan secara manual. Saat proses pengenalan berlangsung, properti objek logger diperbarui setiap kali fungsi dipanggil . Jadi, ini dapat digunakan untuk menampilkan bilah kemajuan konversi, mengubah beberapa bagian dari aplikasi, atau digunakan untuk mencapai hasil yang diinginkan.
result pada kode di atas merupakan hasil dari proses pengenalan citra. Setiap properti result memiliki properti bbox sebagai koordinat x/y kotak pembatasnya.
Berikut adalah sifat-sifat objek result , arti atau kegunaannya:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: Semua teks yang dikenali sebagai string. -
lines: Sebuah larik dari setiap baris teks yang dikenali. -
words-kata : Sebuah array dari setiap kata yang dikenal. -
symbols: Sebuah array dari masing-masing karakter yang dikenali. -
paragraphs: Array dari setiap paragraf yang dikenali. Kita akan membahas "kepercayaan diri" nanti dalam tulisan ini.
Tesseract juga dapat digunakan secara lebih imperatif seperti pada:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();Pendekatan ini terkait dengan pendekatan pertama tetapi dengan implementasi yang berbeda.
createWorker(options) membuat pekerja web atau proses anak simpul yang membuat pekerja Tesseract. Pekerja membantu mengatur mesin Tesseract OCR. Metode load() memuat skrip inti Tesseract, loadLanguage() memuat bahasa apa pun yang disertakan sebagai string, initialize() memastikan Tesseract sepenuhnya siap digunakan dan kemudian metode pengenalan digunakan untuk memproses gambar yang disediakan. Metode terminasi() menghentikan pekerja dan membersihkan semuanya.
Catatan : Silakan periksa dokumentasi API Tesseract untuk informasi lebih lanjut.
Sekarang, kita harus membangun sesuatu untuk benar-benar melihat seberapa efektif Tesseract.js.
Apa yang Akan Kita Bangun?
Kami akan membuat pengekstrak PIN kartu hadiah karena mengekstrak PIN dari kartu hadiah adalah masalah yang menyebabkan petualangan penulisan ini.
Kami akan membangun aplikasi sederhana yang mengekstrak PIN dari kartu hadiah yang dipindai . Saat saya mulai membuat ekstraktor pin kartu hadiah sederhana, saya akan memandu Anda melalui beberapa tantangan yang saya hadapi di sepanjang garis, solusi yang saya berikan, dan kesimpulan saya berdasarkan pengalaman saya.
- Buka kode sumber →
Di bawah ini adalah gambar yang akan kita gunakan untuk pengujian karena memiliki beberapa sifat realistis yang mungkin terjadi di dunia nyata.

Kami akan mengekstrak AQUX-QWMB6L-R6JAU dari kartu. Jadi, mari kita mulai.
Pemasangan React Dan Tesseract
Ada pertanyaan yang harus diperhatikan sebelum menginstal React dan Tesseract.js dan pertanyaannya adalah, mengapa menggunakan React dengan Tesseract? Secara praktis, kita dapat menggunakan Tesseract dengan JavaScript Vanilla, pustaka atau kerangka kerja JavaScript apa pun seperti React, Vue, dan Angular.
Menggunakan Bereaksi dalam hal ini adalah preferensi pribadi. Awalnya, saya ingin menggunakan Vue tetapi saya memutuskan untuk menggunakan React karena saya lebih mengenal React daripada Vue.
Sekarang, mari kita lanjutkan dengan instalasi.
Untuk menginstal React dengan create-react-app, Anda harus menjalankan kode di bawah ini:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jsatau
npm install tesseract.jsSaya memutuskan untuk menggunakan benang untuk menginstal Tesseract.js karena saya tidak dapat menginstal Tesseract dengan npm tetapi benang menyelesaikan pekerjaan tanpa stres. Anda dapat menggunakan npm tetapi saya sarankan menginstal Tesseract dengan benang menilai dari pengalaman saya.
Sekarang, mari kita mulai server pengembangan kita dengan menjalankan kode di bawah ini:
yarn startatau
npm startSetelah menjalankan yarn start atau npm start, browser default Anda akan membuka halaman web yang terlihat seperti di bawah ini:

Anda juga dapat menavigasi ke localhost:3000 di browser asalkan halaman tidak diluncurkan secara otomatis.
Setelah menginstal React dan Tesseract.js, apa selanjutnya?
Menyiapkan Formulir Unggah
Dalam hal ini, kita akan menyesuaikan halaman beranda (App.js) yang baru saja kita lihat di browser untuk memuat formulir yang kita butuhkan:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App Bagian dari kode di atas yang perlu kita perhatikan saat ini adalah fungsi handleChange .
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } Dalam fungsinya, URL.createObjectURL mengambil file yang dipilih melalui event.target.files[0] dan membuat URL referensi yang dapat digunakan dengan tag HTML seperti img, audio, dan video. Kami menggunakan setImagePath untuk menambahkan URL ke status. Sekarang, URL sekarang dapat diakses dengan imagePath .
<img src={imagePath} className="App-logo" alt="image"/> Kami menyetel atribut src gambar ke {imagePath} untuk mempratinjaunya di browser sebelum memprosesnya.
Mengonversi Gambar Terpilih Menjadi Teks
Karena kita telah mengambil jalur ke gambar yang dipilih, kita dapat meneruskan jalur gambar ke Tesseract.js untuk mengekstrak teks darinya.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default AppKami menambahkan fungsi "handleClick" ke "App.js dan berisi Tesseract.js API yang mengambil jalur ke gambar yang dipilih. Tesseract.js mengambil "imagePath", "bahasa", "objek pengaturan".
Tombol di bawah ini ditambahkan ke formulir untuk memanggil "handClick" yang memicu konversi gambar-ke-teks setiap kali tombol diklik.
<button onClick={handleClick} style={{height:50}}> convert to text</button>Ketika pemrosesan berhasil, kami mengakses "keyakinan" dan "teks" dari hasilnya. Kemudian, kami menambahkan "teks" ke negara dengan "setText(teks)".
Dengan menambahkan <p> {text} </p> , kami menampilkan teks yang diekstraksi.
Jelas bahwa "teks" diekstraksi dari gambar tetapi apa itu kepercayaan diri?
Keyakinan menunjukkan seberapa akurat konversi tersebut. Tingkat kepercayaan adalah antara 1 sampai 100. 1 berarti yang terburuk sementara 100 berarti yang terbaik dalam hal akurasi. Ini juga dapat digunakan untuk menentukan apakah teks yang diekstraksi harus diterima sebagai akurat atau tidak.
Lalu pertanyaannya adalah faktor apa saja yang dapat mempengaruhi tingkat kepercayaan atau akurasi dari keseluruhan konversi? Sebagian besar dipengaruhi oleh tiga faktor utama — kualitas dan sifat dokumen yang digunakan, kualitas pindaian yang dibuat dari dokumen, dan kemampuan pemrosesan mesin Tesseract.
Sekarang, mari tambahkan kode di bawah ini ke "App.css" untuk sedikit menata aplikasi.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }Berikut adalah hasil tes pertama saya:
Hasil Di Firefox
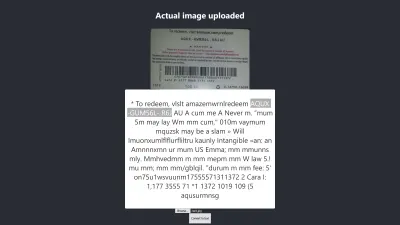
Tingkat kepercayaan dari hasil di atas adalah 64. Perlu dicatat bahwa gambar kartu hadiah berwarna gelap dan itu pasti mempengaruhi hasil yang kita dapatkan.

Jika Anda melihat lebih dekat pada gambar di atas, Anda akan melihat pin dari kartu hampir akurat dalam teks yang diekstraksi. Itu tidak akurat karena kartu hadiahnya tidak terlalu jelas.
Oh tunggu! Seperti apa tampilannya di Chrome?
Hasil Di Chrome
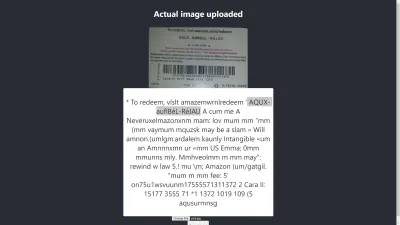
Ah! Hasilnya bahkan lebih buruk di Chrome. Tapi kenapa hasil di Chrome berbeda dengan Mozilla Firefox? Peramban yang berbeda menangani gambar dan profil warnanya secara berbeda. Artinya, gambar dapat dirender secara berbeda tergantung pada browser . Dengan menyediakan image.data yang telah dirender sebelumnya ke Tesseract, kemungkinan akan menghasilkan hasil yang berbeda di browser yang berbeda karena image.data yang berbeda dipasok ke Tesseract tergantung pada browser yang digunakan. Memproses gambar sebelumnya, seperti yang akan kita lihat nanti di artikel ini, akan membantu mencapai hasil yang konsisten.
Kita harus lebih akurat sehingga kita bisa yakin bahwa kita mendapatkan atau memberikan informasi yang benar. Jadi kita harus mengambilnya sedikit lebih jauh.
Mari kita coba lebih untuk melihat apakah kita dapat mencapai tujuan pada akhirnya.
Menguji Akurasi
Ada banyak faktor yang memengaruhi konversi gambar ke teks dengan Tesseract.js. Sebagian besar faktor ini berkisar pada sifat gambar yang ingin kita proses dan sisanya tergantung pada bagaimana mesin Tesseract menangani konversi.
Secara internal, Tesseract memroses gambar sebelum konversi OCR yang sebenarnya tetapi tidak selalu memberikan hasil yang akurat.
Sebagai solusinya, kami dapat melakukan praproses gambar untuk mencapai konversi yang akurat. Kita bisa binarise, invert, dilate, deskew, atau rescale image untuk memprosesnya terlebih dahulu untuk Tesseract.js.
Pra-pemrosesan gambar adalah banyak pekerjaan atau bidang yang luas sendiri. Untungnya, P5.js telah menyediakan semua teknik preprocessing gambar yang ingin kita gunakan. Alih-alih menemukan kembali roda atau menggunakan seluruh perpustakaan hanya karena kita ingin menggunakan sebagian kecil darinya, saya telah menyalin yang kita butuhkan. Semua teknik preprocessing gambar termasuk dalam preprocess.js.
Apa itu Binarisasi?
Binarisasi adalah konversi piksel gambar menjadi hitam atau putih. Kami ingin binerisasi kartu hadiah sebelumnya untuk memeriksa apakah akurasinya akan lebih baik atau tidak.
Sebelumnya, kami mengekstrak beberapa teks dari kartu hadiah tetapi PIN target tidak seakurat yang kami inginkan. Sehingga perlu dicari cara lain untuk mendapatkan hasil yang akurat.
Sekarang, kami ingin binerisasi kartu hadiah , yaitu kami ingin mengubah pikselnya menjadi hitam putih sehingga kami dapat melihat apakah tingkat akurasi yang lebih baik dapat dicapai atau tidak.
Fungsi di bawah ini akan digunakan untuk binerisasi dan disertakan dalam file terpisah bernama preprocess.js.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImageApa yang dilakukan kode di atas?
Kami memperkenalkan kanvas untuk menampung data gambar untuk menerapkan beberapa filter, untuk melakukan pra-proses gambar, sebelum meneruskannya ke Tesseract untuk konversi.
Fungsi preprocessImage pertama terletak di preprocess.js dan menyiapkan kanvas untuk digunakan dengan mendapatkan pikselnya. Fungsi thresholdFilter binarizes gambar dengan mengkonversi piksel menjadi hitam atau putih .
Mari kita panggil preprocessImage untuk melihat apakah teks yang diekstrak dari kartu hadiah sebelumnya bisa lebih akurat.
Pada saat kami memperbarui App.js, seharusnya sekarang terlihat seperti kode ini:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default AppPertama, kita harus mengimpor "preprocessImage" dari "preprocess.js" dengan kode di bawah ini:
import preprocessImage from './preprocess'; Kemudian, kami menambahkan tag kanvas ke formulir. Kami menetapkan atribut ref dari kanvas dan tag img masing-masing ke { canvasRef } dan { imageRef } . Referensi digunakan untuk mengakses kanvas dan gambar dari komponen Aplikasi. Kami mendapatkan kanvas dan gambar dengan "useRef" seperti pada:
const canvasRef = useRef(null); const imageRef = useRef(null);Di bagian kode ini, kami menggabungkan gambar ke kanvas karena kami hanya dapat memproses kanvas sebelumnya di JavaScript. Kami kemudian mengonversinya menjadi URL data dengan "jpeg" sebagai format gambarnya.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");“dataUrl” diteruskan ke Tesseract sebagai gambar yang akan diproses.
Sekarang, mari kita periksa apakah teks yang diekstraksi akan lebih akurat.
Tes #2

Gambar di atas menunjukkan hasilnya di Firefox. Jelas bahwa bagian gelap dari gambar telah diubah menjadi putih tetapi pra-pemrosesan gambar tidak menghasilkan hasil yang lebih akurat. Ini bahkan lebih buruk.
Konversi pertama hanya memiliki dua karakter yang salah tetapi yang ini memiliki empat karakter yang salah. Saya bahkan mencoba mengubah tingkat ambang batas tetapi tidak berhasil. Kami tidak mendapatkan hasil yang lebih baik bukan karena binarisasi itu buruk tetapi karena binarisasi gambar tidak memperbaiki sifat gambar dengan cara yang sesuai untuk mesin Tesseract.
Mari kita periksa seperti apa tampilannya di Chrome:

Kami mendapatkan hasil yang sama.
Setelah mendapatkan hasil yang lebih buruk dengan melakukan binarisasi pada citra, perlu dilakukan pengecekan terhadap teknik preprocessing citra lainnya untuk melihat apakah kita dapat menyelesaikan masalah tersebut atau tidak. Jadi, kita akan mencoba dilatasi, inversi, dan pengaburan selanjutnya.
Mari kita dapatkan kode untuk masing-masing teknik dari P5.js seperti yang digunakan oleh artikel ini. Kami akan menambahkan teknik pemrosesan gambar ke preprocess.js dan menggunakannya satu per satu. Penting untuk memahami setiap teknik preprocessing gambar yang ingin kita gunakan sebelum menggunakannya, jadi kita akan membahasnya terlebih dahulu.
Apa itu Dilatasi?
Dilasi adalah menambahkan piksel ke batas objek dalam gambar untuk membuatnya lebih lebar, lebih besar, atau lebih terbuka. Teknik "dilatasi" digunakan untuk memproses gambar sebelumnya untuk meningkatkan kecerahan objek pada gambar. Kami membutuhkan fungsi untuk memperbesar gambar menggunakan JavaScript, sehingga cuplikan kode untuk memperbesar gambar ditambahkan ke preprocess.js.
Apa Itu Buram?
Blurring adalah menghaluskan warna gambar dengan mengurangi ketajamannya. Terkadang, gambar memiliki titik/tambalan kecil. Untuk menghapus tambalan itu, kita bisa mengaburkan gambar. Cuplikan kode untuk memburamkan gambar disertakan dalam preprocess.js.
Apa itu Inversi?
Inversi adalah mengubah area terang dari suatu gambar menjadi warna gelap dan area gelap menjadi warna terang. Misalnya, jika suatu gambar memiliki latar belakang hitam dan latar depan putih, kita dapat membalikkannya sehingga latar belakangnya menjadi putih dan latar depannya menjadi hitam. Kami juga telah menambahkan cuplikan kode untuk membalikkan gambar ke preprocess.js.
Setelah menambahkan dilate , invertColors , dan blurARGB ke “preprocess.js”, sekarang kita dapat menggunakannya untuk mempraproses gambar. Untuk menggunakannya, kita perlu memperbarui fungsi "preprocessImage" awal di preprocess.js:
preprocessImage(...) sekarang terlihat seperti ini:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } Dalam preprocessImage di atas, kami menerapkan empat teknik preprocessing ke sebuah gambar: blurARGB() untuk menghilangkan titik-titik pada gambar, dilate() untuk meningkatkan kecerahan gambar, invertColors() untuk mengganti warna latar depan dan latar belakang gambar dan thresholdFilter() untuk mengubah gambar menjadi hitam putih yang lebih cocok untuk konversi Tesseract.
thresholdFilter() mengambil image.data dan level sebagai parameternya. level digunakan untuk mengatur seberapa putih atau hitam gambar yang seharusnya. Kami menentukan level thresholdFilter dan radius blurRGB dengan trial and error karena kami tidak yakin seberapa putih, gelap atau halus gambar yang seharusnya untuk Tesseract untuk menghasilkan hasil yang bagus.
Tes # 3
Berikut adalah hasil baru setelah menerapkan empat teknik:

Gambar di atas mewakili hasil yang kami dapatkan di Chrome dan Firefox.
Ups! Hasilnya mengerikan.
Daripada menggunakan keempat teknik tersebut, mengapa kita tidak menggunakan dua saja sekaligus?
Ya! Kita cukup menggunakan teknik invertColors dan thresholdFilter untuk mengubah gambar menjadi hitam putih, dan mengganti latar depan dan latar belakang gambar. Tapi bagaimana kita tahu apa dan teknik apa yang harus digabungkan? Kami tahu apa yang harus digabungkan berdasarkan sifat gambar yang ingin kami praproses.
Misalnya, gambar digital harus diubah menjadi hitam putih, dan gambar dengan tambalan harus diburamkan untuk menghilangkan titik/tambalan. Yang benar-benar penting adalah memahami untuk apa masing-masing teknik digunakan.
Untuk menggunakan invertColors dan thresholdFilter , kita perlu mengomentari blurARGB dan dilate preprocessImage :
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }Tes #4
Sekarang, inilah hasil baru:

Hasilnya masih lebih buruk daripada yang tanpa preprocessing. Setelah menyesuaikan masing-masing teknik untuk gambar ini dan beberapa gambar lainnya, saya sampai pada kesimpulan bahwa gambar dengan sifat yang berbeda memerlukan teknik praproses yang berbeda.
Singkatnya, menggunakan Tesseract.js tanpa pra-pemrosesan gambar menghasilkan hasil terbaik untuk kartu hadiah di atas. Semua eksperimen lain dengan pra-pemrosesan gambar menghasilkan hasil yang kurang akurat.
Isu
Awalnya, saya ingin mengekstrak PIN dari kartu hadiah Amazon mana pun, tetapi saya tidak dapat mencapainya karena tidak ada gunanya mencocokkan PIN yang tidak konsisten untuk mendapatkan hasil yang konsisten. Meskipun dimungkinkan untuk memproses sebuah gambar untuk mendapatkan PIN yang akurat, namun pra-pemrosesan tersebut akan menjadi tidak konsisten pada saat gambar lain dengan sifat yang berbeda digunakan.
Hasil Terbaik Dihasilkan
Gambar di bawah menunjukkan hasil terbaik yang dihasilkan oleh eksperimen.
Tes #5

Teks pada gambar dan yang diekstraksi benar-benar sama. Konversi memiliki akurasi 100%. Saya mencoba mereproduksi hasilnya tetapi saya hanya dapat mereproduksinya saat menggunakan gambar dengan sifat yang serupa.
Observasi Dan Pelajaran
- Beberapa gambar yang tidak diproses sebelumnya dapat memberikan hasil yang berbeda di browser yang berbeda . Klaim ini terbukti dalam tes pertama. Hasil di Firefox berbeda dengan yang ada di Chrome. Namun, gambar pra-pemrosesan membantu mencapai hasil yang konsisten dalam pengujian lain.
- Warna hitam pada latar belakang putih cenderung memberikan hasil yang mudah diatur. Gambar di bawah ini adalah contoh hasil yang akurat tanpa preprocessing apapun . Saya juga bisa mendapatkan tingkat akurasi yang sama dengan memproses gambar sebelumnya, tetapi saya membutuhkan banyak penyesuaian yang sebenarnya tidak perlu.
Konversi ini 100% akurat.
- Sebuah teks dengan ukuran font yang besar cenderung lebih akurat.
- Font dengan tepi melengkung cenderung membingungkan Tesseract. Hasil terbaik yang saya dapatkan dicapai ketika saya menggunakan Arial (font).
- OCR saat ini tidak cukup baik untuk mengotomatisasi konversi gambar-ke-teks, terutama ketika tingkat akurasi lebih dari 80% diperlukan. Namun, ini dapat digunakan untuk membuat pemrosesan manual teks pada gambar menjadi tidak terlalu menegangkan dengan mengekstraksi teks untuk koreksi manual.
- OCR saat ini tidak cukup baik untuk menyampaikan informasi yang berguna kepada pembaca layar untuk aksesibilitas . Memberikan informasi yang tidak akurat ke pembaca layar dapat dengan mudah menyesatkan atau mengalihkan perhatian pengguna.
- OCR sangat menjanjikan karena jaringan saraf memungkinkan untuk dipelajari dan ditingkatkan. Pembelajaran mendalam akan menjadikan OCR sebagai pengubah permainan dalam waktu dekat .
- Mengambil keputusan dengan percaya diri. Skor kepercayaan dapat digunakan untuk membuat keputusan yang dapat sangat memengaruhi aplikasi kita. Skor kepercayaan dapat digunakan untuk menentukan apakah akan menerima atau menolak suatu hasil. Dari pengalaman dan eksperimen saya, saya menyadari bahwa skor kepercayaan diri di bawah 90 tidak terlalu berguna. Jika saya hanya perlu mengekstrak beberapa pin dari teks, saya akan mengharapkan skor kepercayaan antara 75 dan 100, dan apa pun di bawah 75 akan ditolak .
Jika saya berurusan dengan teks tanpa perlu mengekstrak bagian apa pun darinya, saya pasti akan menerima skor kepercayaan antara 90 hingga 100 tetapi menolak skor apa pun di bawah itu. Misalnya, akurasi 90 ke atas akan diharapkan jika saya ingin mendigitalkan dokumen seperti cek, draf bersejarah, atau kapan pun salinan persisnya diperlukan. Tetapi skor antara 75 dan 90 dapat diterima jika salinan persisnya tidak penting seperti mendapatkan PIN dari kartu hadiah. Singkatnya, skor kepercayaan membantu dalam membuat keputusan yang memengaruhi aplikasi kami.
Kesimpulan
Mengingat keterbatasan pemrosesan data yang disebabkan oleh teks pada gambar dan kerugian yang terkait dengannya, Optical Character Recognition (OCR) adalah teknologi yang berguna untuk digunakan. Meskipun OCR memiliki keterbatasan, namun sangat menjanjikan karena penggunaan jaringan saraf.
Seiring waktu, OCR akan mengatasi sebagian besar keterbatasannya dengan bantuan pembelajaran mendalam, tetapi sebelum itu, pendekatan yang disorot dalam artikel ini dapat digunakan untuk menangani ekstraksi teks dari gambar, setidaknya, untuk mengurangi kesulitan dan kerugian yang terkait dengan manual pemrosesan — terutama dari sudut pandang bisnis.
Sekarang giliran Anda untuk mencoba OCR untuk mengekstrak teks dari gambar. Semoga beruntung!
Bacaan lebih lanjut
- P5.js
- Pra-Pemrosesan di OCR
- Meningkatkan kualitas keluaran
- Menggunakan JavaScript untuk Memproses Gambar untuk OCR
- OCR di browser dengan Tesseract.js
- Sejarah Singkat Pengenalan Karakter Optik
- Masa Depan OCR adalah Pembelajaran Mendalam
- Garis Waktu Pengenalan Karakter Optik