
Klasifikasi Gambar di CNN: Semua yang Perlu Anda Ketahui
Diterbitkan: 2021-02-25Daftar isi
pengantar
Saat menelusuri umpan Facebook, pernahkah Anda bertanya-tanya bagaimana orang-orang di foto grup diberi label secara otomatis oleh perangkat lunak Facebook? Di balik setiap antarmuka pengguna interaktif Facebook yang Anda lihat, ada algoritma kompleks dan kuat yang digunakan untuk mengenali dan memberi label pada setiap gambar yang kami unggah ke platform media sosial. Dengan setiap gambar kami, kami hanya membantu meningkatkan efisiensi algoritme. Ya, Klasifikasi Gambar adalah salah satu algoritma yang paling banyak digunakan di mana kita melihat penerapan Kecerdasan Buatan.
Belakangan ini, Convolutional Neural Networks (CNN) telah menjadi salah satu pendukung terkuat Deep Learning. Salah satu aplikasi populer dari Jaringan Konvolusi ini adalah Klasifikasi Gambar. Dalam tutorial ini, kita akan membahas dasar-dasar Convolutional Neural Networks, melihat berbagai lapisan yang terlibat dalam membangun model CNN dan akhirnya memvisualisasikan contoh tugas Klasifikasi Gambar.
Klasifikasi Gambar
Sebelum kita masuk ke detail Deep Learning dan Convolutional Neural Networks, mari kita pahami dasar-dasar Klasifikasi Gambar. Secara umum, Klasifikasi Gambar didefinisikan sebagai tugas di mana kami memberikan gambar sebagai input ke model yang dibangun menggunakan algoritma tertentu yang menghasilkan kelas atau probabilitas kelas tempat gambar tersebut berada. Proses di mana kami memberi label gambar ke kelas tertentu disebut Pembelajaran Terbimbing.
Ada perbedaan besar antara cara kita melihat gambar dan cara mesin (komputer) melihat gambar yang sama. Bagi kami, kami dapat memvisualisasikan gambar dan mengkarakterisasinya berdasarkan warna dan ukuran. Di sisi lain, bagi mesin, yang bisa dilihat hanyalah angka. Angka-angka yang terlihat disebut piksel.
Setiap piksel memiliki nilai antara 0 dan 255. Oleh karena itu, dengan data numerik ini, mesin memerlukan beberapa langkah pra-pemrosesan untuk memperoleh beberapa pola atau fitur khusus yang membedakan satu gambar dari gambar lainnya. Convolutional Neural Networks membantu kami membangun algoritme yang mampu menurunkan pola tertentu dari gambar.
Apa yang Kita Lihat Vs Apa yang Dilihat Komputer
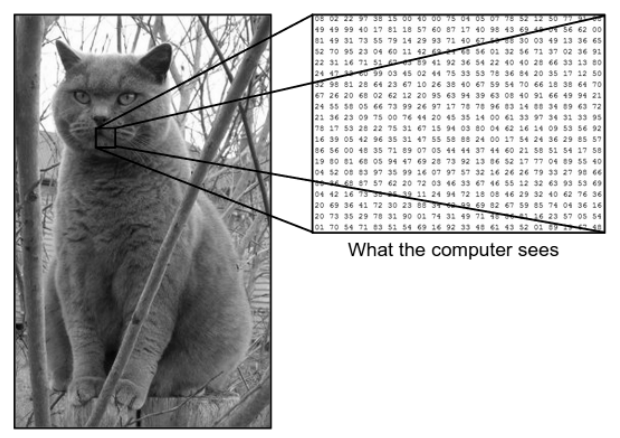 Sumber – Perbedaan antara Komputer dan Mata Manusia
Sumber – Perbedaan antara Komputer dan Mata Manusia

Pembelajaran Mendalam untuk Klasifikasi Gambar
Sekarang setelah kita memahami apa itu Klasifikasi Gambar, sekarang mari kita lihat bagaimana kita dapat mengimplementasikannya menggunakan Kecerdasan Buatan. Untuk ini, kami menggunakan metode Deep Learning yang populer. Deep Learning adalah bagian dari Artificial Intelligence yang memanfaatkan kumpulan data gambar besar untuk mengenali dan memperoleh pola dari berbagai gambar untuk membedakan antara berbagai kelas yang ada dalam kumpulan data gambar.
Tantangan utama yang dihadapi Deep Learning adalah bahwa untuk database yang besar, dibutuhkan waktu yang sangat lama dan biaya komputasi yang tinggi. Namun, Convolutional Neural Networks, yang merupakan jenis algoritma Deep Learning mengatasi masalah ini dengan baik.
Jaringan Saraf Konvolusional
Dalam Deep Learning, Convolutional Neural Networks adalah kelas Deep Neural Networks yang banyak digunakan dalam citra visual. Mereka adalah arsitektur khusus Jaringan Syaraf Tiruan (JST) yang diusulkan pada tahun 1998 oleh Yann LeCunn. Convolutional Neural Networks terdiri dari dua bagian.
Bagian pertama terdiri dari lapisan Convolutional dan lapisan Pooling di mana proses ekstraksi fitur utama berlangsung. Pada bagian kedua, lapisan Terhubung Penuh dan Padat melakukan beberapa transformasi non-linier pada fitur yang diekstraksi dan bertindak sebagai bagian pengklasifikasi. Pelajari CNN untuk klasifikasi gambar.
Perhatikan contoh gambar yang ditunjukkan di atas tentang apa yang dilihat manusia dan mesin. Seperti yang kita lihat, komputer melihat array piksel. Misalnya jika ukuran gambar jika 500x500, maka ukuran array akan menjadi 500x500x3. Di sini, 500 singkatan untuk setiap tinggi dan lebar, 3 singkatan saluran RGB di mana setiap saluran warna diwakili oleh larik terpisah. Intensitas piksel bervariasi dari 0 hingga 255.
Sekarang untuk Klasifikasi Gambar, komputer akan mencari fitur di tingkat dasar. Menurut kita sebagai manusia, ciri-ciri tingkat dasar kucing ini adalah telinga, hidung, dan kumisnya. Sedangkan untuk komputer, fitur tingkat dasar ini adalah lengkungan dan batas. Dengan cara ini dengan menggunakan beberapa lapisan yang berbeda seperti lapisan Convolutional dan lapisan Pooling, komputer mengekstrak fitur tingkat dasar dari gambar.
Dalam model Convolutional Neural Network, terdapat beberapa jenis lapisan seperti –
- Lapisan Masukan
- Lapisan Konvolusi
- Lapisan Pengumpulan
- Lapisan Terhubung Sepenuhnya
- Lapisan Keluaran
- Fungsi Aktivasi
Mari kita membahas masing-masing lapisan secara singkat sebelum kita masuk ke penerapannya di Klasifikasi Gambar.
Lapisan Masukan
Dari namanya, kita memahami bahwa ini adalah lapisan di mana gambar input akan dimasukkan ke dalam model CNN. Tergantung pada kebutuhan kita, kita dapat membentuk kembali gambar ke ukuran yang berbeda seperti (28,28,3)
Lapisan Konvolusi
Kemudian muncul lapisan terpenting yang terdiri dari filter (juga dikenal sebagai kernel) dengan ukuran tetap. Operasi matematika Konvolusi dilakukan antara gambar input dan filter. Ini adalah tahap di mana sebagian besar fitur dasar seperti tepi tajam dan kurva diekstraksi dari gambar dan karenanya lapisan ini juga dikenal sebagai lapisan ekstraktor fitur.
Lapisan Pengumpulan
Setelah melakukan operasi konvolusi, kami melakukan operasi Pooling. Ini juga dikenal sebagai downsampling di mana volume spasial gambar dikurangi. Misalnya, jika kita melakukan operasi Pooling dengan langkah 2 pada gambar dengan dimensi 28x28, maka ukuran gambar dikurangi menjadi 14x14, itu akan dikurangi menjadi setengah dari ukuran aslinya.
Lapisan Terhubung Sepenuhnya
Fully Connected Layer (FC) ditempatkan tepat sebelum keluaran klasifikasi akhir dari model CNN. Lapisan ini digunakan untuk meratakan hasil sebelum mengklasifikasikan. Ini melibatkan beberapa bias, bobot dan neuron. Melampirkan lapisan FC sebelum klasifikasi menghasilkan vektor N-dimensi di mana N adalah sejumlah kelas di mana model harus memilih kelas.
Lapisan Keluaran
Akhirnya, Output Layer terdiri dari label yang sebagian besar dikodekan dengan menggunakan metode pengkodean satu-panas.
Fungsi Aktivasi
Fungsi Aktivasi ini adalah inti dari setiap model Jaringan Saraf Konvolusi. Fungsi-fungsi ini digunakan untuk menentukan output dari jaringan saraf. Singkatnya, ini menentukan apakah neuron tertentu harus diaktifkan ("dipecat") atau tidak. Ini biasanya fungsi non-linier yang dilakukan pada sinyal input. Output yang diubah ini kemudian dikirim sebagai input ke lapisan neuron berikutnya. Ada beberapa fungsi aktivasi seperti Sigmoid, ReLU, Leaky ReLU, TanH dan Softmax.
Arsitektur CNN Dasar
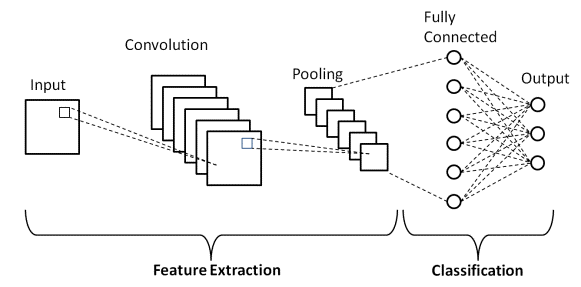
Sumber : Arsitektur CNN Dasar
Seperti yang didefinisikan sebelumnya, diagram yang ditampilkan di atas adalah arsitektur dasar dari model Jaringan Saraf Konvolusi. Sekarang setelah kita siap dengan dasar-dasar Klasifikasi Gambar dan CNN, sekarang mari kita selami penerapannya dengan masalah waktu nyata. Pelajari lebih lanjut tentang arsitektur CNN dasar.
Implementasi Jaringan Saraf Konvolusi
Sekarang setelah kita memahami dasar-dasar Klasifikasi Gambar dan Jaringan Saraf Konvolusi, mari kita visualisasikan penerapannya di TensorFlow/Keras dengan pengkodean Python. Dalam hal ini, kita akan membangun Model Jaringan Syaraf Tiruan sederhana dengan Arsitektur LeNet Dasar, melatih model pada set pelatihan & set uji dan akhirnya mendapatkan akurasi model pada data set uji.
Set Masalah
Dalam artikel ini untuk membangun dan melatih Model Jaringan Saraf Konvolusi, kita akan menggunakan dataset Fashion MNIST yang terkenal. MNIST adalah singkatan dari Institut Standar dan Teknologi Nasional yang Dimodifikasi. Fashion-MNIST adalah kumpulan data gambar artikel Zalando—terdiri dari kumpulan pelatihan 60.000 contoh dan kumpulan uji 10.000 contoh. Setiap contoh adalah gambar skala abu-abu 28x28, terkait dengan label dari 10 kelas.

Setiap contoh pelatihan dan pengujian ditetapkan ke salah satu label berikut:
0 – T-shirt/atas
1 – Celana
2 – Pullover
3 – Gaun
4 – Mantel
5 – Sandal
6 – Kemeja
7 – Sepatu Kets
8 – Tas
9 – Sepatu Bot Semata Kaki
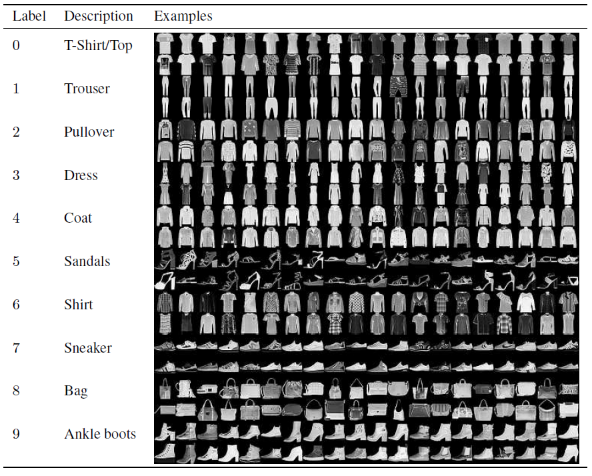
Sumber : Fashion MNIST Dataset Images
Kode Program
Langkah 1 – Mengimpor Perpustakaan
Langkah pertama untuk membangun model Deep Learning apa pun adalah mengimpor perpustakaan yang diperlukan untuk program tersebut. Dalam contoh kami, karena kami menggunakan kerangka kerja TensorFlow, kami akan mengimpor perpustakaan Keras dan juga perpustakaan penting lainnya seperti nomor untuk perhitungan dan matplotlib untuk memplot plot.
#TensorFlow – Mengimpor Perpustakaan
impor numpy sebagai np
impor matplotlib.pyplot sebagai plt
%matplotlib sebaris
impor tensorflow sebagai tf
dari tensorflow impor Keras
Langkah 2 – Mendapatkan dan Memisahkan Dataset
Setelah kami mengimpor perpustakaan, langkah selanjutnya adalah mengunduh kumpulan data dan membagi kumpulan data Fashion MNIST menjadi masing-masing 60.000 data pelatihan dan 10.000 data uji. Untungnya, keras memberi kita fungsi yang telah ditentukan sebelumnya untuk mengimpor dataset Fashion MNIST dan kita dapat membaginya di baris berikutnya menggunakan baris kode sederhana yang dapat dipahami sendiri.
#TensorFlow – Mendapatkan dan Memisahkan Dataset
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
Langkah 3 – Memvisualisasikan Data
Karena kumpulan data diunduh bersama dengan gambar dan label yang sesuai, untuk membuatnya lebih jelas bagi pengguna, selalu disarankan untuk melihat data sehingga kita dapat memahami jenis data yang sedang kita tangani untuk membangun Convolutional Neural Model Jaringan yang sesuai. Di sini, dengan blok kode sederhana yang diberikan di bawah ini, kita akan memvisualisasikan 3 gambar pertama dari dataset pelatihan yang diacak secara acak.
#TensorFlow – Memvisualisasikan Data
def imshowTensorFlow(img):
plt.imshow(img, cmap='abu-abu')
print(“Label:”, img[0])
imshowTensorFlow(train_images_tf[0])
Label: 9 Label: 0 Label: 3
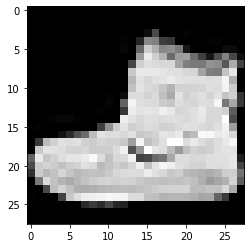


Gambar yang diberikan di atas dan labelnya dapat diverifikasi dengan label yang diberikan dalam detail dataset Fashion MNIST di atas. Dari sini, kami menyimpulkan bahwa gambar data kami adalah gambar skala abu-abu dengan tinggi 28 piksel dan lebar 28 piksel.
Oleh karena itu, model dapat dibangun dengan ukuran input (28,28,1), di mana 1 adalah gambar skala abu-abu.
Langkah 4 – Membangun Model
Seperti disebutkan di atas, dalam artikel ini kita akan membangun Convolutional Neural Network sederhana dengan arsitektur LeNet. LeNet adalah struktur jaringan saraf convolutional yang diusulkan oleh Yann LeCun et al. pada tahun 1989. Secara umum, LeNet mengacu pada LeNet-5 dan merupakan Jaringan Neural Convolutional sederhana.
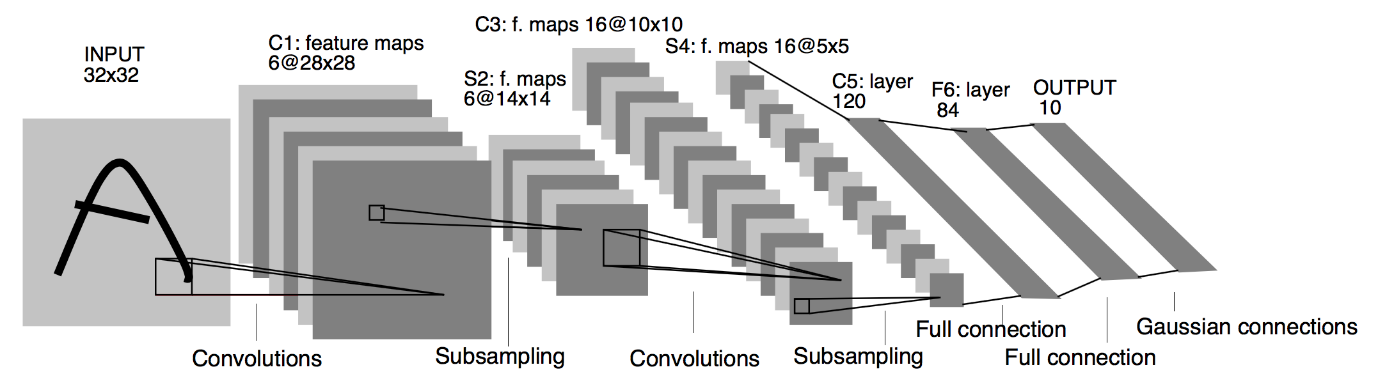
Sumber : Arsitektur LeNet
Dari diagram Arsitektur Model CNN LeNet yang diberikan di atas, kita melihat bahwa ada 5+2 lapisan. Lapisan pertama dan kedua adalah lapisan Convolutional diikuti oleh lapisan Pooling. Sekali lagi, lapisan ketiga dan keempat terdiri dari lapisan Convolutional dan lapisan Pooling. Sebagai hasil dari operasi ini, ukuran gambar input dari 28×28 berkurang menjadi 7×7.
Lapisan kelima dari Model LeNet adalah Lapisan Terhubung Penuh yang meratakan keluaran lapisan sebelumnya. Diikuti oleh dua lapisan Dense, lapisan keluaran akhir dari model CNN terdiri dari fungsi aktivasi Softmax dengan 10 unit. Fungsi Softmax memprediksi probabilitas kelas untuk masing-masing dari 10 kelas dari dataset Fashion MNIST.
#TensorFlow – Membangun Model
model = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1), filter=6, kernel_size=5, strides=1, padding=”sama”, activation=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Conv2D(16, kernel_size=5, strides=1, padding=”sama”, activation=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(120, aktivasi=tf.nn.relu),
keras.layers.Dense(84, activation=tf.nn.relu),
keras.layers.Dense(10, aktivasi=tf.nn.softmax)
])
Langkah 5 – Ringkasan Model
Setelah lapisan model LeNet diselesaikan, kita dapat melanjutkan untuk mengkompilasi model dan melihat versi ringkasan dari model CNN yang dirancang.
#TensorFlow – Ringkasan Model
model.compile(loss=keras.losses.categorical_crossentropy,
pengoptimal = 'adam',
metrik=['aku'])
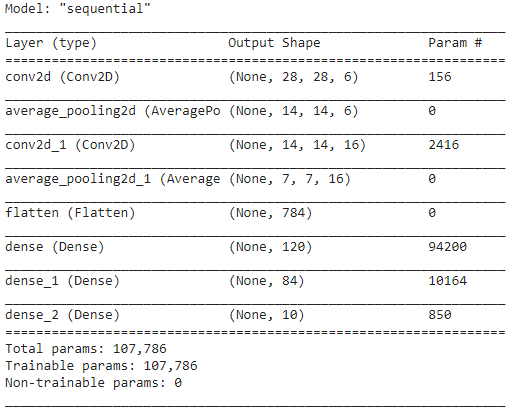
model.ringkasan()
Dalam hal ini, karena hasil akhir memiliki lebih dari 2 kelas (10 kelas), kami menggunakan crossentropy kategoris sebagai fungsi kerugian dan Adam Optimizer untuk model yang kami buat. Ringkasan model diberikan di bawah ini.
Langkah 6 – Melatih Model
Akhirnya, kita sampai pada bagian di mana kita memulai proses pelatihan model CNN LeNet. Pertama, kami membentuk kembali set data pelatihan dan menormalkannya ke nilai yang lebih kecil dengan membaginya dengan 255.0 untuk mengurangi biaya komputasi. Kemudian label pelatihan dikonversi dari vektor kelas integer ke matriks kelas biner. Misalnya, label 3 diubah menjadi [0, 0, 0, 1, 0, 0, 0, 0, 0]
#TensorFlow – Melatih Model
train_images_tensorflow = (train_images_tf / 255.0).reshape(train_images_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28 ,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
Pada akhir pelatihan setelah 30 epoch, kami memperoleh akurasi dan kerugian pelatihan akhir sebagai,
Zaman 30/30
1875/1875 [==============================] – 4s 2ms/langkah – kerugian: 0,0421 – acc: 0,9850
Akurasi Pelatihan: 98.294997215271 %
Kerugian Pelatihan: 0,04584110900759697
Langkah 7 – Memprediksi Hasil
Akhirnya, setelah kami selesai dengan proses pelatihan model CNN, kami akan menyesuaikan model yang sama pada dataset uji dan memprediksi keakuratan 10.000 gambar uji.
#TensorFlow – Membandingkan Hasil
prediksi = model.predict(test_images_tensorflow)
benar = 0
untuk saya, pred di enumerate(prediksi):
if np.argmax(pred) == test_labels_tf[i]:
benar += 1
print('Uji Akurasi model pada {} gambar uji: {}% dengan TensorFlow'.format(test_images_tf.shape[0],100 * correct/test_images_tf.shape[0]))
Output yang kita dapatkan adalah,
Uji Akurasi model pada 10.000 gambar uji: 90,67% dengan TensorFlow
Dengan ini, kami mengakhiri program untuk membangun Model Klasifikasi Gambar dengan Jaringan Saraf Konvolusi.
Baca Juga: Ide Proyek Pembelajaran Mesin
Kesimpulan
Oleh karena itu, dalam tutorial implementasi Image Classification di CNN ini, kita telah memahami konsep dasar di balik Image Classification, Convolutional Neural Networks beserta implementasinya dalam bahasa pemrograman Python dengan framework TensorFlow.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT- B Status alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Model CNN mana yang dianggap paling optimal untuk klasifikasi citra?
Model CNN terbaik untuk klasifikasi gambar adalah VGG-16, yang merupakan singkatan dari Very Deep Convolutional Networks for Large-Scale Image Recognition. VGG, yang dirancang sebagai CNN yang mendalam, mengungguli baseline pada berbagai tugas dan kumpulan data di luar ImageNet. Fitur pembeda model adalah bahwa ketika sedang dibuat, lebih banyak perhatian ditempatkan pada penggabungan lapisan konvolusi yang sangat baik daripada berfokus pada penambahan sejumlah besar parameter hiper. Ini memiliki total 16 lapisan, 5 blok, dan setiap blok memiliki lapisan penyatuan maksimum, menjadikannya jaringan yang cukup besar.
Apa kerugian menggunakan model CNN untuk klasifikasi gambar?
Dalam hal klasifikasi gambar, model CNN sangat sukses. Namun, ada beberapa kelemahan menggunakan CNN. Jika gambar yang akan diidentifikasi miring atau diputar, model CNN memiliki masalah dalam mengidentifikasi gambar secara akurat. Ketika CNN memvisualisasikan gambar, tidak ada representasi internal dari komponen dan koneksi bagian-keseluruhannya. Selanjutnya, jika model CNN yang akan digunakan mencakup banyak convolutional layer, proses klasifikasi akan memakan waktu yang lama.
Mengapa penggunaan model CNN lebih diutamakan daripada ANN untuk data citra sebagai input?
Dengan menggabungkan filter atau transformasi, CNN dapat mempelajari banyak lapisan representasi fitur untuk setiap gambar yang diberikan sebagai input. Overfitting berkurang karena jumlah parameter yang dipelajari jaringan di CNN secara substansial lebih kecil daripada di jaringan saraf multilayer. Saat menggunakan JST, jaringan saraf dapat mempelajari representasi fitur tunggal dari gambar, tetapi, dalam kasus gambar yang kompleks, JST akan gagal memberikan visualisasi atau klasifikasi yang lebih baik karena tidak dapat mempelajari dependensi piksel yang ada dalam gambar input.