
HTTP/3: Peningkatan Kinerja (Bagian 2)
Diterbitkan: 2022-03-10Selamat datang kembali di seri ini tentang protokol HTTP/3 baru. Di bagian 1, kami melihat mengapa sebenarnya kami membutuhkan HTTP/3 dan protokol QUIC yang mendasarinya, dan apa fitur baru utamanya.
Di bagian kedua ini, kami akan memperbesar peningkatan kinerja yang dibawa oleh QUIC dan HTTP/3 ke tabel untuk memuat halaman web. Namun, kami juga agak skeptis terhadap dampak yang dapat kami harapkan dari fitur-fitur baru ini dalam praktiknya.
Seperti yang akan kita lihat, QUIC dan HTTP/3 memang memiliki potensi kinerja web yang hebat, tetapi terutama untuk pengguna di jaringan yang lambat . Jika pengunjung rata-rata Anda berada di jaringan kabel atau seluler yang cepat, mereka mungkin tidak akan mendapat banyak manfaat dari protokol baru. Namun, perhatikan bahwa bahkan di negara dan wilayah dengan uplink yang biasanya cepat, 1% hingga 10% audiens Anda yang paling lambat (disebut persentil ke- 99 atau ke-90) masih berpotensi mendapatkan banyak keuntungan. Ini karena HTTP/3 dan QUIC terutama membantu menangani masalah yang agak jarang namun berpotensi berdampak tinggi yang dapat muncul di Internet saat ini.
Bagian ini sedikit lebih teknis daripada yang pertama, meskipun membongkar sebagian besar hal-hal yang sangat dalam ke sumber luar, dengan fokus menjelaskan mengapa hal-hal ini penting bagi pengembang web rata-rata.
- Bagian 1: Sejarah HTTP/3 Dan Konsep Inti
Artikel ini ditujukan untuk orang-orang yang baru mengenal HTTP/3 dan protokol secara umum, dan terutama membahas dasar-dasarnya. - Bagian 2: Fitur Kinerja HTTP/3
Yang ini lebih mendalam dan teknis. Orang yang sudah tahu dasar-dasarnya bisa mulai dari sini. - Bagian 3: Opsi Penerapan HTTP/3 Praktis
Artikel ketiga dalam seri ini menjelaskan tantangan yang terlibat dalam penerapan dan pengujian HTTP/3 sendiri. Ini merinci bagaimana dan jika Anda harus mengubah halaman web dan sumber daya Anda juga.
Dasar tentang Kecepatan
Membahas kinerja dan "kecepatan" dapat dengan cepat menjadi rumit, karena banyak aspek mendasar yang berkontribusi pada pemuatan halaman web "lambat". Karena kita berurusan dengan protokol jaringan di sini, kita terutama akan melihat aspek jaringan, di mana dua yang paling penting: latency dan bandwidth.
Latensi dapat secara kasar didefinisikan sebagai waktu yang diperlukan untuk mengirim paket dari titik A (misalnya, klien) ke titik B (server) . Secara fisik dibatasi oleh kecepatan cahaya atau, secara praktis, seberapa cepat sinyal dapat merambat melalui kabel atau di udara terbuka. Ini berarti bahwa latensi sering kali bergantung pada jarak fisik dunia nyata antara A dan B.
Di bumi, ini berarti bahwa latensi tipikal secara konseptual kecil, antara sekitar 10 dan 200 milidetik. Namun, ini hanya satu cara: Respons terhadap paket juga perlu dikembalikan. Latensi dua arah sering disebut round-trip time (RTT) .
Karena fitur seperti kontrol kemacetan (lihat di bawah), kita akan sering membutuhkan beberapa perjalanan pulang pergi untuk memuat bahkan satu file. Dengan demikian, bahkan latensi rendah kurang dari 50 milidetik dapat menambah penundaan yang cukup besar. Ini adalah salah satu alasan utama mengapa jaringan pengiriman konten (CDN) ada: Mereka menempatkan server secara fisik lebih dekat ke pengguna akhir untuk mengurangi latensi, dan dengan demikian menunda, sebanyak mungkin.
Bandwidth, kemudian, secara kasar dapat dikatakan sebagai jumlah paket yang dapat dikirim pada saat yang sama . Ini sedikit lebih sulit untuk dijelaskan, karena tergantung pada sifat fisik medium (misalnya, frekuensi gelombang radio yang digunakan), jumlah pengguna di jaringan, dan juga perangkat yang menghubungkan subjaringan yang berbeda (karena mereka biasanya hanya dapat memproses sejumlah paket per detik).
Sebuah metafora yang sering digunakan adalah pipa yang digunakan untuk mengangkut air. Panjang pipa adalah latency, sedangkan lebar pipa adalah bandwidth. Namun, di Internet, kami biasanya memiliki rangkaian panjang pipa yang terhubung , beberapa di antaranya bisa lebih lebar dari yang lain (mengakibatkan apa yang disebut kemacetan di tautan tersempit). Dengan demikian, bandwidth ujung ke ujung antara titik A dan B sering dibatasi oleh subbagian paling lambat.
Sementara pemahaman yang sempurna tentang konsep-konsep ini tidak diperlukan untuk sisa posting ini, memiliki definisi tingkat tinggi yang umum akan baik. Untuk info lebih lanjut, saya sarankan untuk membaca bab luar biasa Ilya Grigorik tentang latency dan bandwidth dalam bukunya High Performance Browser Networking .
Kontrol Kemacetan
Salah satu aspek kinerja adalah tentang seberapa efisien protokol transport dapat menggunakan bandwidth penuh (fisik) jaringan (yaitu kira-kira, berapa banyak paket per detik yang dapat dikirim atau diterima). Hal ini pada gilirannya mempengaruhi seberapa cepat sumber daya halaman dapat diunduh. Beberapa mengklaim bahwa QUIC entah bagaimana melakukan ini jauh lebih baik daripada TCP, tapi itu tidak benar.
Tahukah kamu?
Sambungan TCP, misalnya, tidak hanya mulai mengirim data dengan bandwidth penuh, karena ini dapat mengakibatkan kelebihan beban (atau kemacetan) jaringan. Ini karena, seperti yang kami katakan, setiap tautan jaringan hanya memiliki sejumlah data tertentu yang dapat diproses (secara fisik) setiap detik. Berikan lagi dan tidak ada pilihan selain membuang paket yang berlebihan, yang menyebabkan hilangnya paket .
Seperti yang dibahas di bagian 1, untuk protokol yang andal seperti TCP, satu-satunya cara untuk memulihkan dari kehilangan paket adalah dengan mentransmisikan ulang salinan data baru, yang memerlukan satu kali perjalanan pulang pergi. Khususnya pada jaringan latensi tinggi (misalnya, dengan RTT lebih dari 50 milidetik), kehilangan paket dapat sangat memengaruhi kinerja.
Masalah lain adalah kami tidak tahu di muka berapa bandwidth maksimum . Ini sering kali tergantung pada hambatan di suatu tempat di koneksi ujung ke ujung, tetapi kami tidak dapat memprediksi atau mengetahui di mana ini akan terjadi. Internet juga tidak memiliki mekanisme (belum) untuk memberi sinyal kapasitas tautan kembali ke titik akhir.
Selain itu, bahkan jika kami mengetahui bandwidth fisik yang tersedia, itu tidak berarti kami dapat menggunakan semuanya sendiri. Beberapa pengguna biasanya aktif di jaringan secara bersamaan, yang masing-masing membutuhkan bagian yang adil dari bandwidth yang tersedia.
Dengan demikian, koneksi tidak mengetahui berapa banyak bandwidth yang dapat digunakan dengan aman atau wajar di awal, dan bandwidth ini dapat berubah saat pengguna bergabung, keluar, dan menggunakan jaringan. Untuk mengatasi masalah ini, TCP akan terus mencoba untuk menemukan bandwidth yang tersedia dari waktu ke waktu dengan menggunakan mekanisme yang disebut kontrol kongesti .
Pada awal koneksi, ia hanya mengirim beberapa paket (dalam praktiknya, berkisar antara 10 dan 100 paket, atau sekitar 14 dan 140 KB data) dan menunggu satu perjalanan pulang pergi hingga penerima mengirimkan kembali pemberitahuan atas paket-paket ini. Jika semuanya diakui, ini berarti jaringan dapat menangani kecepatan pengiriman itu, dan kita dapat mencoba mengulangi prosesnya tetapi dengan lebih banyak data (dalam praktiknya, kecepatan pengiriman biasanya berlipat ganda pada setiap iterasi).
Dengan cara ini, kecepatan kirim terus meningkat hingga beberapa paket tidak dikenali (yang menunjukkan kehilangan paket dan kemacetan jaringan). Fase pertama ini biasanya disebut "mulai lambat". Setelah mendeteksi kehilangan paket, TCP mengurangi kecepatan kirim, dan (setelah beberapa saat) mulai meningkatkan kecepatan pengiriman lagi, meskipun dalam peningkatan (jauh) lebih kecil. Logika pengurangan-lalu-tumbuh ini diulang untuk setiap kehilangan paket sesudahnya. Akhirnya, ini berarti TCP akan terus-menerus mencoba mencapai pembagian bandwidth yang ideal dan adil. Mekanisme ini diilustrasikan pada gambar 1.
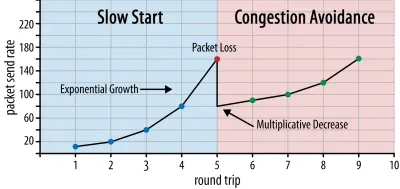
Ini adalah penjelasan yang sangat disederhanakan tentang pengendalian kemacetan. Dalam praktiknya, banyak faktor lain yang berperan, seperti bufferbloat, fluktuasi RTT karena kemacetan, dan fakta bahwa banyak pengirim serentak perlu mendapatkan bagian bandwidth yang adil. Dengan demikian, ada banyak algoritma kontrol kemacetan yang berbeda, dan banyak yang masih ditemukan hari ini, dengan tidak ada yang berkinerja optimal di semua situasi.
Sementara kontrol kemacetan TCP membuatnya kuat, itu juga berarti perlu beberapa saat untuk mencapai tingkat pengiriman yang optimal , tergantung pada RTT dan bandwidth aktual yang tersedia. Untuk pemuatan halaman web, pendekatan mulai lambat ini juga dapat memengaruhi metrik seperti cat konten pertama, karena hanya sejumlah kecil data (puluhan hingga beberapa ratus KB) yang dapat ditransfer dalam beberapa perjalanan pulang pergi pertama. (Anda mungkin pernah mendengar rekomendasi untuk menyimpan data penting Anda agar lebih kecil dari 14 KB.)
Memilih pendekatan yang lebih agresif dapat menghasilkan hasil yang lebih baik pada jaringan dengan bandwidth tinggi dan latensi tinggi, terutama jika Anda tidak peduli dengan kehilangan paket sesekali. Di sinilah saya kembali melihat banyak salah tafsir tentang cara kerja QUIC.
Seperti yang dibahas di bagian 1, QUIC, secara teori, lebih sedikit menderita kehilangan paket (dan pemblokiran head-of-line (HOL) terkait) karena QUIC menangani kehilangan paket pada setiap aliran byte sumber daya secara independen. Selain itu, QUIC berjalan di atas User Datagram Protocol (UDP), yang, tidak seperti TCP, tidak memiliki fitur kontrol kemacetan bawaan; ini memungkinkan Anda untuk mencoba mengirim dengan kecepatan berapa pun yang Anda inginkan dan tidak mentransmisi ulang data yang hilang.
Hal ini menyebabkan banyak artikel mengklaim bahwa QUIC juga tidak menggunakan kontrol kemacetan, bahwa QUIC malah dapat mulai mengirim data dengan kecepatan yang jauh lebih tinggi melalui UDP (mengandalkan penghapusan pemblokiran HOL untuk menangani kehilangan paket), itulah sebabnya QUIC jauh lebih cepat daripada TCP.
Kenyataannya, tidak ada yang lebih jauh dari kebenaran: QUIC sebenarnya menggunakan teknik manajemen bandwidth yang sangat mirip dengan TCP . Itu juga dimulai dengan tingkat pengiriman yang lebih rendah dan tumbuh dari waktu ke waktu, menggunakan pengakuan sebagai mekanisme kunci untuk mengukur kapasitas jaringan. Ini (antara lain) karena QUIC harus dapat diandalkan agar berguna untuk sesuatu seperti HTTP, karena harus adil untuk koneksi QUIC (dan TCP!) lainnya, dan karena penghapusan pemblokiran HOL tidak benar-benar membantu mengatasi kehilangan paket dengan baik (seperti yang akan kita lihat di bawah).
Namun, itu tidak berarti bahwa QUIC tidak bisa (sedikit) lebih pintar tentang cara mengelola bandwidth daripada TCP. Ini terutama karena QUIC lebih fleksibel dan lebih mudah dikembangkan daripada TCP . Seperti yang telah kami katakan, algoritme kontrol kemacetan masih sangat berkembang saat ini, dan kami mungkin perlu, misalnya, menyesuaikan berbagai hal untuk mendapatkan hasil maksimal dari 5G.
Namun, TCP biasanya diimplementasikan dalam kernel (OS') sistem operasi, lingkungan yang aman dan lebih terbatas, yang bagi sebagian besar OS bahkan bukan open source. Dengan demikian, penyetelan logika kemacetan biasanya hanya dilakukan oleh beberapa pengembang tertentu, dan evolusinya lambat.
Sebaliknya, sebagian besar implementasi QUIC saat ini dilakukan di "ruang pengguna" (tempat kami biasanya menjalankan aplikasi asli) dan dibuat open source, secara eksplisit untuk mendorong eksperimen oleh kumpulan pengembang yang jauh lebih luas (seperti yang telah ditunjukkan, misalnya, oleh Facebook ).
Contoh konkret lainnya adalah usulan perpanjangan frekuensi pengakuan tertunda untuk QUIC. Sementara, secara default, QUIC mengirimkan pengakuan untuk setiap 2 paket yang diterima, ekstensi ini memungkinkan titik akhir untuk mengakui, misalnya, setiap 10 paket sebagai gantinya. Hal ini telah terbukti memberikan keuntungan kecepatan yang besar pada satelit dan jaringan bandwidth yang sangat tinggi, karena overhead transmisi paket pengakuan diturunkan. Menambahkan ekstensi semacam itu untuk TCP akan membutuhkan waktu lama untuk diadopsi, sedangkan untuk QUIC jauh lebih mudah untuk diterapkan.
Dengan demikian, kita dapat berharap bahwa fleksibilitas QUIC akan menghasilkan lebih banyak eksperimen dan algoritma kontrol kemacetan yang lebih baik dari waktu ke waktu, yang pada gilirannya juga dapat di-backport ke TCP untuk meningkatkannya juga.
Tahukah kamu?
QUIC Recovery RFC 9002 resmi menentukan penggunaan algoritma kontrol kemacetan NewReno. Meskipun pendekatan ini kuat, itu juga agak ketinggalan jaman dan tidak digunakan secara luas dalam praktik lagi. Jadi, mengapa ada di QUIC RFC? Alasan pertama adalah ketika QUIC dimulai, NewReno adalah algoritma kontrol kemacetan terbaru yang distandarisasi. Algoritma yang lebih maju, seperti BBR dan CUBIC, masih belum terstandarisasi atau baru saja menjadi RFC.
Alasan kedua adalah bahwa NewReno adalah pengaturan yang relatif sederhana. Karena algoritme memerlukan beberapa penyesuaian untuk menangani perbedaan QUIC dari TCP, lebih mudah untuk menjelaskan perubahan tersebut pada algoritme yang lebih sederhana. Dengan demikian, RFC 9002 harus dibaca lebih sebagai "cara mengadaptasi algoritma kontrol kemacetan ke QUIC", daripada "ini adalah hal yang harus Anda gunakan untuk QUIC". Memang, sebagian besar implementasi QUIC tingkat produksi telah membuat implementasi kustom dari Cubic dan BBR.
Perlu diulangi bahwa algoritme kontrol kemacetan tidak spesifik untuk TCP atau QUIC ; mereka dapat digunakan oleh salah satu protokol, dan harapannya adalah bahwa kemajuan dalam QUIC pada akhirnya akan menemukan jalan mereka ke tumpukan TCP juga.
Tahukah kamu?
Perhatikan bahwa, di samping kontrol kemacetan adalah konsep terkait yang disebut kontrol aliran. Kedua fitur ini sering dikacaukan dalam TCP, karena keduanya dikatakan menggunakan "jendela TCP" , meskipun sebenarnya ada dua jendela: jendela kemacetan dan jendela penerimaan TCP. Kontrol aliran, bagaimanapun, berperan jauh lebih sedikit untuk kasus penggunaan pemuatan halaman web yang kami minati, jadi kami akan melewatkannya di sini. Informasi lebih mendalam tersedia.
Apa Artinya Semua?
QUIC masih terikat oleh hukum fisika dan kebutuhan untuk bersikap baik kepada pengirim lain di Internet. Ini berarti bahwa itu tidak akan secara ajaib mengunduh sumber daya situs web Anda lebih cepat daripada TCP. Namun, fleksibilitas QUIC berarti bahwa bereksperimen dengan algoritme kontrol kemacetan baru akan menjadi lebih mudah, yang seharusnya meningkatkan hal-hal di masa depan untuk TCP dan QUIC.
Pengaturan Koneksi 0-RTT
Aspek kinerja kedua adalah tentang berapa banyak perjalanan pulang pergi yang diperlukan sebelum Anda dapat mengirim data HTTP yang berguna (misalnya, sumber daya halaman) pada koneksi baru. Beberapa mengklaim bahwa QUIC dua atau bahkan tiga perjalanan pulang pergi lebih cepat daripada TCP + TLS, tetapi kita akan melihat bahwa itu benar-benar hanya satu.
Tahukah kamu?
Seperti yang telah kami katakan di bagian 1, koneksi biasanya melakukan satu (TCP) atau dua (TCP + TLS) jabat tangan sebelum permintaan dan respons HTTP dapat dipertukarkan. Jabat tangan ini bertukar parameter awal yang perlu diketahui klien dan server untuk, misalnya, mengenkripsi data.
Seperti yang dapat Anda lihat pada gambar 2 di bawah, setiap jabat tangan individu membutuhkan setidaknya satu perjalanan pulang pergi (TCP + TLS 1.3, (b)) dan terkadang dua (TLS 1.2 dan sebelumnya (a)). Ini tidak efisien, karena kami memerlukan setidaknya dua perjalanan pulang pergi dari waktu tunggu jabat tangan (overhead) sebelum kami dapat mengirim permintaan HTTP pertama kami, yang berarti menunggu setidaknya tiga perjalanan bolak-balik untuk data respons HTTP pertama (panah merah kembali) yang akan datang in. Pada jaringan yang lambat, ini dapat berarti overhead 100 hingga 200 milidetik.
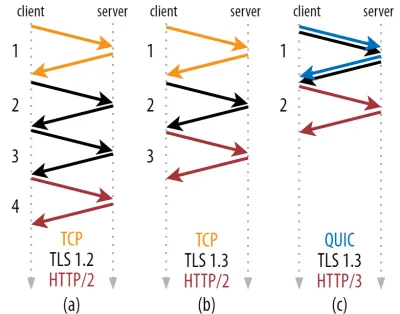
Anda mungkin bertanya-tanya mengapa jabat tangan TCP + TLS tidak dapat digabungkan begitu saja, dilakukan dalam perjalanan pulang pergi yang sama. Meskipun ini secara konseptual mungkin (QUIC melakukan hal itu), hal-hal pada awalnya tidak dirancang seperti ini, karena kita harus dapat menggunakan TCP dengan dan tanpa TLS di atas. Dengan kata lain, TCP sama sekali tidak mendukung pengiriman barang non-TCP selama jabat tangan. Ada upaya untuk menambahkan ini dengan ekstensi TCP Fast Open; namun, seperti yang dibahas di bagian 1, ini ternyata sulit untuk diterapkan dalam skala besar.
Untungnya, QUIC dirancang dengan mempertimbangkan TLS sejak awal, dan dengan demikian menggabungkan jabat tangan transportasi dan kriptografis dalam satu mekanisme. Ini berarti bahwa jabat tangan QUIC hanya akan membutuhkan total satu perjalanan pulang pergi, yaitu satu perjalanan pulang pergi kurang dari TCP + TLS 1.3 (lihat gambar 2c di atas).
Anda mungkin bingung, karena Anda mungkin pernah membaca bahwa QUIC dua atau bahkan tiga perjalanan pulang pergi lebih cepat dari TCP, bukan hanya satu. Ini karena sebagian besar artikel hanya mempertimbangkan kasus terburuk (TCP + TLS 1.2, (a)), tidak menyebutkan bahwa TCP + TLS 1.3 modern juga "hanya" mengambil dua perjalanan pulang pergi ((b) jarang ditampilkan). Sementara peningkatan kecepatan satu perjalanan pulang pergi itu bagus, itu tidak luar biasa. Terutama pada jaringan yang cepat (misalnya, RTT kurang dari 50 milidetik), ini hampir tidak terlihat , meskipun jaringan yang lambat dan koneksi ke server yang jauh akan sedikit lebih menguntungkan.
Selanjutnya, Anda mungkin bertanya-tanya mengapa kita harus menunggu jabat tangan sama sekali. Mengapa kami tidak dapat mengirim permintaan HTTP di perjalanan pulang pergi pertama? Ini terutama karena, jika kami melakukannya, maka permintaan pertama itu akan dikirim tidak terenkripsi , dapat dibaca oleh penyadap mana pun di kabel, yang jelas tidak bagus untuk privasi dan keamanan. Dengan demikian, kita perlu menunggu jabat tangan kriptografis selesai sebelum mengirim permintaan HTTP pertama. Atau kita?
Di sinilah trik pintar digunakan dalam praktik. Kami tahu bahwa pengguna sering mengunjungi kembali halaman web dalam waktu singkat setelah kunjungan pertama mereka. Dengan demikian, kita dapat menggunakan koneksi terenkripsi awal untuk bootstrap koneksi kedua di masa mendatang. Sederhananya, kadang-kadang selama masa pakainya, koneksi pertama digunakan untuk mengomunikasikan parameter kriptografi baru dengan aman antara klien dan server. Parameter ini kemudian dapat digunakan untuk mengenkripsi koneksi kedua dari awal, tanpa harus menunggu jabat tangan TLS lengkap selesai. Pendekatan ini disebut “sesi dimulai kembali” .
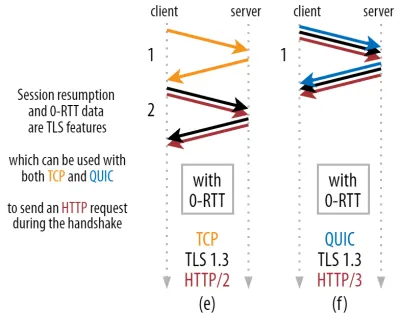
Ini memungkinkan pengoptimalan yang kuat: Kami sekarang dapat dengan aman mengirim permintaan HTTP pertama kami bersama dengan jabat tangan QUIC/TLS, menghemat perjalanan pulang pergi lainnya ! Adapun TLS 1.3, ini secara efektif menghilangkan waktu tunggu jabat tangan TLS. Metode ini sering disebut 0-RTT (walaupun, tentu saja, masih diperlukan satu perjalanan pulang pergi agar data respons HTTP mulai tiba).
Baik dimulainya kembali sesi dan 0-RTT, sekali lagi, adalah hal-hal yang sering saya lihat salah dijelaskan sebagai fitur khusus QUIC. Pada kenyataannya, ini sebenarnya adalah fitur TLS yang sudah ada dalam beberapa bentuk di TLS 1.2 dan sekarang sepenuhnya dikembangkan di TLS 1.3.
Dengan kata lain, seperti yang Anda lihat pada gambar 3 di bawah, kita bisa mendapatkan manfaat kinerja dari fitur-fitur ini melalui TCP (dan dengan demikian juga HTTP/2 dan bahkan HTTP/1.1) juga! Kami melihat bahwa bahkan dengan 0-RTT, QUIC masih hanya satu perjalanan pulang pergi lebih cepat daripada tumpukan TCP + TLS 1.3 yang berfungsi optimal. Klaim bahwa QUIC tiga perjalanan pulang pergi lebih cepat berasal dari membandingkan gambar 2 (a) dengan gambar 3 (f), yang, seperti yang telah kita lihat, tidak benar-benar adil.
Bagian terburuknya adalah ketika menggunakan 0-RTT, QUIC bahkan tidak dapat benar-benar menggunakan perjalanan pulang pergi yang diperoleh dengan baik karena keamanan. Untuk memahami ini, kita perlu memahami salah satu alasan mengapa jabat tangan TCP ada. Pertama, ini memungkinkan klien untuk memastikan bahwa server benar-benar tersedia di alamat IP yang diberikan sebelum mengirimkannya data lapisan yang lebih tinggi.
Kedua, dan yang terpenting di sini, ini memungkinkan server untuk memastikan bahwa klien yang membuka koneksi sebenarnya adalah siapa dan di mana mereka mengatakan sebelum mengirimnya data. Jika Anda ingat bagaimana kami mendefinisikan koneksi dengan 4-tupel di bagian 1, Anda akan tahu bahwa klien terutama diidentifikasi oleh alamat IP-nya. Dan ini masalahnya: alamat IP bisa dipalsukan !
Misalkan penyerang meminta file yang sangat besar melalui HTTP melalui QUIC 0-RTT. Namun, mereka memalsukan alamat IP mereka, membuatnya tampak seperti permintaan 0-RTT berasal dari komputer korban mereka. Hal ini ditunjukkan pada gambar 4 di bawah ini. Server QUIC tidak memiliki cara untuk mendeteksi apakah IP tersebut palsu, karena ini adalah paket pertama yang dilihat dari klien tersebut.

Jika server kemudian mulai mengirim file besar kembali ke IP palsu, itu bisa berakhir dengan membebani bandwidth jaringan korban (terutama jika penyerang melakukan banyak permintaan palsu ini secara paralel). Perhatikan bahwa respons QUIC akan dijatuhkan oleh korban, karena tidak mengharapkan data masuk, tetapi itu tidak masalah: Jaringan mereka masih perlu memproses paket!
Ini disebut refleksi, atau amplifikasi, serangan , dan ini adalah cara signifikan yang dilakukan peretas untuk mengeksekusi serangan penolakan layanan (DDoS) terdistribusi. Perhatikan bahwa ini tidak terjadi ketika 0-RTT melalui TCP + TLS digunakan, justru karena jabat tangan TCP harus diselesaikan terlebih dahulu sebelum permintaan 0-RTT dikirim bersama dengan jabat tangan TLS.
Dengan demikian, QUIC harus konservatif dalam membalas permintaan 0-RTT, membatasi berapa banyak data yang dikirim sebagai tanggapan hingga klien diverifikasi sebagai klien nyata dan bukan korban. Untuk QUIC, jumlah data ini telah diatur ke tiga kali jumlah yang diterima dari klien.
Dengan kata lain, QUIC memiliki "faktor amplifikasi" maksimum tiga, yang ditentukan sebagai pertukaran yang dapat diterima antara kegunaan kinerja dan risiko keamanan (terutama dibandingkan dengan beberapa insiden yang memiliki faktor amplifikasi lebih dari 51.000 kali). Karena klien biasanya pertama kali mengirim hanya satu hingga dua paket, balasan 0-RTT server QUIC akan dibatasi hanya 4 hingga 6 KB (termasuk overhead QUIC dan TLS lainnya!), yang agak kurang mengesankan.
Selain itu, masalah keamanan lainnya dapat menyebabkan, misalnya, "serangan putar ulang", yang membatasi jenis permintaan HTTP yang dapat Anda lakukan. Misalnya, Cloudflare hanya mengizinkan permintaan HTTP GET tanpa parameter kueri di 0-RTT. Ini membatasi kegunaan 0-RTT bahkan lebih.
Untungnya, QUIC memiliki opsi untuk membuatnya sedikit lebih baik. Misalnya, server dapat memeriksa apakah 0-RTT berasal dari IP yang sebelumnya memiliki koneksi yang valid. Namun, itu hanya berfungsi jika klien tetap berada di jaringan yang sama (agak membatasi fitur migrasi koneksi QUIC). Dan bahkan jika berhasil, respons QUIC masih dibatasi oleh logika slow-start pengontrol kemacetan yang telah kita bahas di atas; jadi, tidak ada peningkatan kecepatan ekstra besar selain satu perjalanan pulang pergi yang disimpan.
Tahukah kamu?
Sangat menarik untuk dicatat bahwa batas amplifikasi tiga kali QUIC juga diperhitungkan untuk proses jabat tangan non-0-RTT yang normal pada gambar 2c. Ini bisa menjadi masalah jika, misalnya, sertifikat TLS server terlalu besar untuk muat di dalam 4 hingga 6 KB. Dalam hal ini, itu harus dipecah, dengan potongan kedua harus menunggu perjalanan putaran kedua dikirim (setelah pengakuan dari beberapa paket pertama masuk, menunjukkan bahwa IP klien tidak dipalsukan). Dalam hal ini, jabat tangan QUIC mungkin masih berakhir dengan melakukan dua perjalanan pulang pergi , sama dengan TCP + TLS! Inilah sebabnya mengapa untuk QUIC, teknik seperti kompresi sertifikat akan menjadi sangat penting.
Tahukah kamu?
Bisa jadi pengaturan lanjutan tertentu mampu mengurangi masalah ini cukup untuk membuat 0-RTT lebih berguna. Misalnya, server dapat mengingat berapa banyak bandwidth yang tersedia klien terakhir kali dilihat, sehingga tidak terlalu dibatasi oleh kontrol kemacetan yang mulai lambat untuk menghubungkan kembali klien (non-spoofed). Ini telah diselidiki di dunia akademis, dan bahkan ada perpanjangan yang diusulkan di QUIC untuk melakukan ini. Beberapa perusahaan sudah melakukan hal semacam ini untuk mempercepat TCP juga.
Pilihan lain adalah meminta klien mengirim lebih dari satu atau dua paket (misalnya, mengirim 7 paket lagi dengan bantalan), sehingga batas tiga kali diterjemahkan menjadi respons 12 hingga 14 KB yang lebih menarik, bahkan setelah migrasi koneksi. Saya telah menulis tentang ini di salah satu makalah saya.
Terakhir, server QUIC (berperilaku buruk) juga dapat dengan sengaja meningkatkan batas tiga kali lipat jika mereka merasa aman untuk melakukannya atau jika mereka tidak peduli dengan potensi masalah keamanan (bagaimanapun juga, tidak ada polisi protokol yang mencegah hal ini).
Apa artinya itu semua?
Pengaturan koneksi QUIC yang lebih cepat dengan 0-RTT benar-benar lebih merupakan optimasi mikro daripada fitur baru yang revolusioner. Dibandingkan dengan pengaturan TCP + TLS 1.3 yang canggih, ini akan menghemat maksimum satu perjalanan pulang pergi. Jumlah data yang sebenarnya dapat dikirim pada putaran pertama juga dibatasi oleh sejumlah pertimbangan keamanan.
Dengan demikian, fitur ini sebagian besar akan bersinar baik jika pengguna Anda berada di jaringan dengan latensi yang sangat tinggi (misalnya, jaringan satelit dengan RTT lebih dari 200 milidetik) atau jika Anda biasanya tidak mengirim banyak data. Beberapa contoh yang terakhir adalah situs web yang sangat di-cache, serta aplikasi satu halaman yang secara berkala mengambil pembaruan kecil melalui API dan protokol lain seperti DNS-over-QUIC. Salah satu alasan Google melihat hasil 0-RTT yang sangat baik untuk QUIC adalah karena ia mengujinya di halaman pencarian yang sudah sangat dioptimalkan, di mana respons kuerinya cukup kecil.
Dalam kasus lain, Anda hanya akan mendapatkan beberapa puluh milidetik , bahkan lebih sedikit jika Anda sudah menggunakan CDN (yang seharusnya Anda lakukan jika Anda peduli dengan kinerja!).
Migrasi Koneksi
Fitur kinerja ketiga membuat QUIC lebih cepat saat mentransfer antar jaringan, dengan menjaga koneksi yang ada tetap utuh . Meskipun ini memang berhasil, jenis perubahan jaringan ini tidak terlalu sering terjadi dan koneksi masih perlu mengatur ulang kecepatan pengirimannya.
Seperti yang dibahas di bagian 1, ID koneksi (CID) QUIC memungkinkannya melakukan migrasi koneksi saat berpindah jaringan . Kami mengilustrasikan ini dengan klien yang berpindah dari jaringan Wi-Fi ke 4G saat melakukan pengunduhan file besar. Pada TCP, unduhan itu mungkin harus dibatalkan, sedangkan untuk QUIC mungkin berlanjut.
Namun, pertama-tama, pertimbangkan seberapa sering jenis skenario itu benar-benar terjadi. Anda mungkin berpikir ini juga terjadi saat berpindah di antara titik akses Wi-Fi di dalam gedung atau di antara menara seluler saat berada di jalan. Namun, dalam pengaturan tersebut (jika dilakukan dengan benar), perangkat Anda biasanya akan menjaga IP-nya tetap utuh, karena transisi antara stasiun pangkalan nirkabel dilakukan pada lapisan protokol yang lebih rendah. Dengan demikian, itu hanya terjadi ketika Anda berpindah di antara jaringan yang sama sekali berbeda , yang menurut saya tidak sering terjadi.
Kedua, kami dapat menanyakan apakah ini juga berfungsi untuk kasus penggunaan lain selain unduhan file besar dan konferensi video langsung dan streaming. Jika Anda memuat halaman web pada saat yang tepat untuk berpindah jaringan, Anda mungkin harus meminta kembali beberapa sumber daya (nanti).
Namun, memuat halaman biasanya memakan waktu dalam hitungan detik, sehingga bertepatan dengan peralihan jaringan juga tidak akan menjadi hal yang biasa. Selain itu, untuk kasus penggunaan di mana hal ini menjadi masalah yang mendesak, mitigasi lain biasanya sudah ada . Misalnya, server yang menawarkan unduhan file besar dapat mendukung permintaan rentang HTTP untuk memungkinkan unduhan yang dapat dilanjutkan.
Karena biasanya ada waktu tumpang tindih antara jaringan 1 berhenti dan jaringan 2 tersedia, aplikasi video dapat membuka banyak sambungan (1 per jaringan), menyinkronkannya sebelum jaringan lama hilang sepenuhnya. Pengguna masih akan melihat pengalih, tetapi tidak akan menghapus umpan video sepenuhnya.
Ketiga, tidak ada jaminan bahwa jaringan baru akan memiliki bandwidth yang tersedia sebanyak yang lama. Dengan demikian, meskipun koneksi konseptual tetap utuh, server QUIC tidak dapat terus mengirimkan data dengan kecepatan tinggi. Alih-alih, untuk menghindari kelebihan beban jaringan baru, ia perlu mengatur ulang (atau setidaknya menurunkan) laju pengiriman dan memulai lagi dalam fase mulai lambat pengontrol kemacetan.
Karena kecepatan pengiriman awal ini biasanya terlalu rendah untuk benar-benar mendukung hal-hal seperti streaming video, Anda akan melihat beberapa penurunan kualitas atau gangguan, bahkan pada QUIC. Di satu sisi, migrasi koneksi lebih tentang mencegah churn konteks koneksi dan overhead di server daripada tentang meningkatkan kinerja.
Tahukah kamu?
Perhatikan bahwa, seperti yang dibahas untuk 0-RTT di atas, kami dapat merancang beberapa teknik lanjutan untuk meningkatkan migrasi koneksi. Misalnya, kita dapat, sekali lagi, mencoba mengingat berapa banyak bandwidth yang tersedia pada jaringan tertentu terakhir kali dan mencoba untuk meningkatkan lebih cepat ke tingkat itu untuk migrasi baru. Selain itu, kami dapat membayangkan tidak hanya beralih antar jaringan, tetapi menggunakan keduanya secara bersamaan. Konsep ini disebut multipath , dan kami membahasnya secara lebih rinci di bawah ini.
Sejauh ini, kami terutama berbicara tentang migrasi koneksi aktif, di mana pengguna berpindah di antara jaringan yang berbeda. Namun, ada juga kasus migrasi koneksi pasif, di mana jaringan tertentu sendiri mengubah parameter. Contoh yang baik dari ini adalah rebinding terjemahan alamat jaringan (NAT). Meskipun pembahasan lengkap tentang NAT berada di luar cakupan artikel ini, ini terutama berarti bahwa nomor port koneksi dapat berubah kapan saja, tanpa peringatan. Ini juga lebih sering terjadi untuk UDP daripada TCP di sebagian besar router.
Jika ini terjadi, QUIC CID tidak akan berubah, dan sebagian besar implementasi akan mengasumsikan bahwa pengguna masih berada di jaringan fisik yang sama dan dengan demikian tidak akan mereset jendela kemacetan atau parameter lainnya. QUIC juga menyertakan beberapa fitur seperti PING dan indikator batas waktu untuk mencegah hal ini terjadi, karena ini biasanya terjadi untuk koneksi yang lama tidak digunakan.
Kami membahas di bagian 1 bahwa QUIC tidak hanya menggunakan satu CID untuk alasan keamanan. Sebaliknya, itu mengubah CID saat melakukan migrasi aktif. Dalam praktiknya, ini bahkan lebih rumit, karena klien dan server memiliki daftar CID yang terpisah, (disebut CID sumber dan tujuan dalam RFC QUIC). Hal ini diilustrasikan pada gambar 5 di bawah ini.
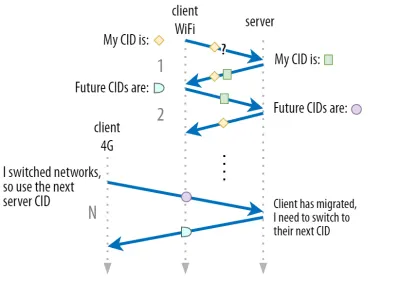
Hal ini dilakukan untuk memungkinkan setiap titik akhir memilih format dan konten CID-nya sendiri , yang pada gilirannya sangat penting untuk memungkinkan perutean lanjutan dan logika penyeimbangan beban. Dengan migrasi koneksi, penyeimbang beban tidak bisa lagi hanya melihat 4-tupel untuk mengidentifikasi koneksi dan mengirimkannya ke server back-end yang benar. Namun, jika semua koneksi QUIC menggunakan CID acak, ini akan sangat meningkatkan kebutuhan memori pada penyeimbang beban, karena itu perlu menyimpan pemetaan CID ke server back-end. Selain itu, ini masih tidak akan berfungsi dengan migrasi koneksi, karena CID berubah menjadi nilai acak baru.
Oleh karena itu, server back-end QUIC yang ditempatkan di belakang load balancer harus memiliki format CID yang dapat diprediksi , sehingga load balancer dapat memperoleh server back-end yang benar dari CID, bahkan setelah migrasi. Beberapa opsi untuk melakukan ini dijelaskan dalam dokumen yang diusulkan IETF. Untuk memungkinkan ini semua, server harus dapat memilih CID mereka sendiri, yang tidak mungkin jika inisiator koneksi (yang, untuk QUIC, selalu klien) memilih CID. Inilah sebabnya mengapa ada pemisahan antara CID klien dan server di QUIC.

Apa artinya itu semua?
Dengan demikian, migrasi koneksi adalah fitur situasional. Tes awal oleh Google, misalnya, menunjukkan peningkatan persentase rendah untuk kasus penggunaannya. Banyak implementasi QUIC yang belum mengimplementasikan fitur ini. Bahkan mereka yang melakukannya biasanya akan membatasinya untuk klien dan aplikasi seluler dan bukan padanan desktop mereka. Beberapa orang bahkan berpendapat bahwa fitur tersebut tidak diperlukan, karena membuka koneksi baru dengan 0-RTT seharusnya memiliki properti kinerja yang serupa dalam banyak kasus.
Namun, tergantung pada kasus penggunaan atau profil pengguna Anda, itu bisa berdampak besar. Jika situs web atau aplikasi Anda paling sering digunakan saat bepergian (misalnya, sesuatu seperti Uber atau Google Maps), maka Anda mungkin akan mendapat manfaat lebih banyak daripada jika pengguna Anda biasanya duduk di belakang meja. Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
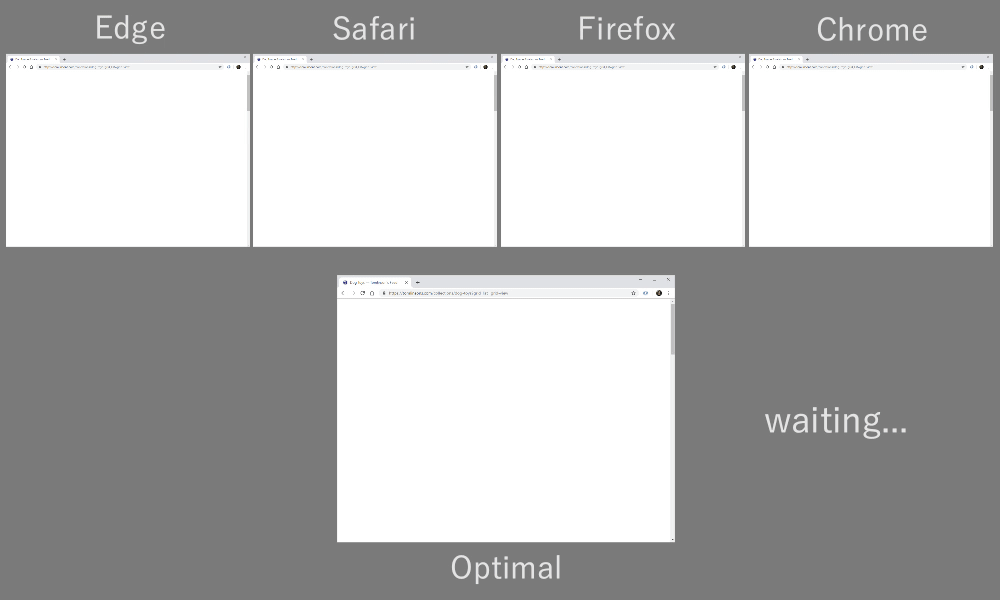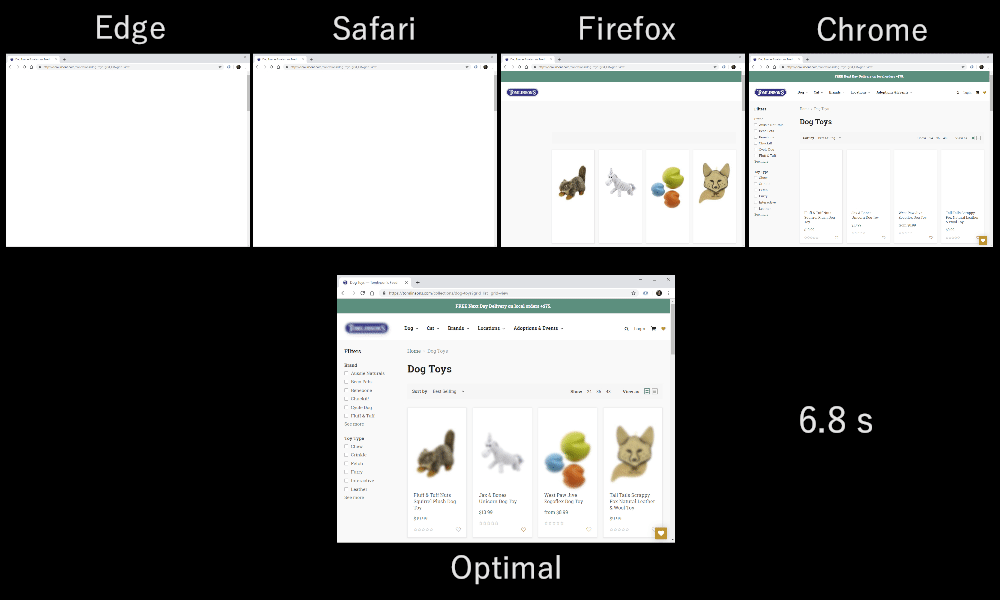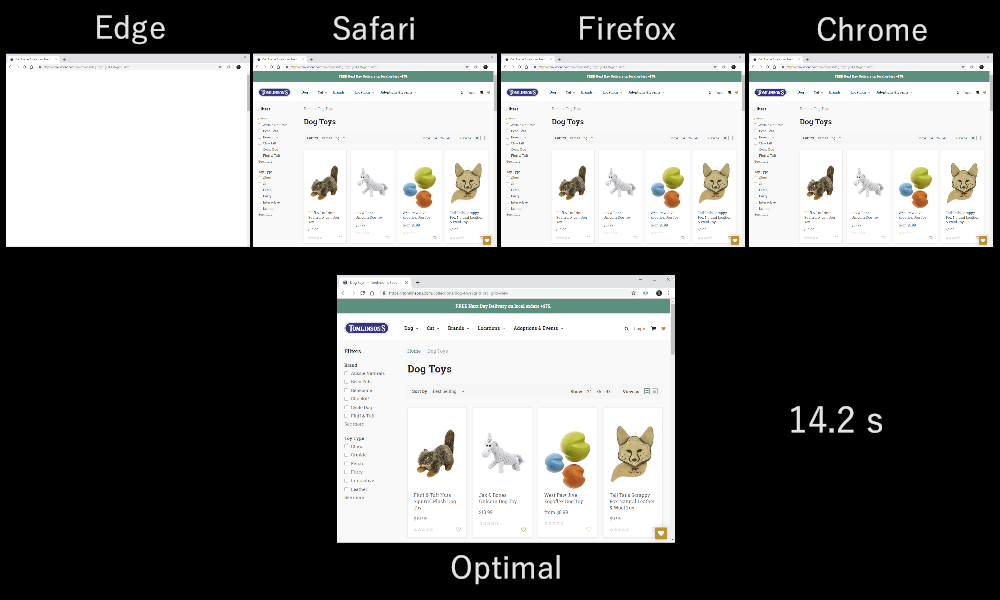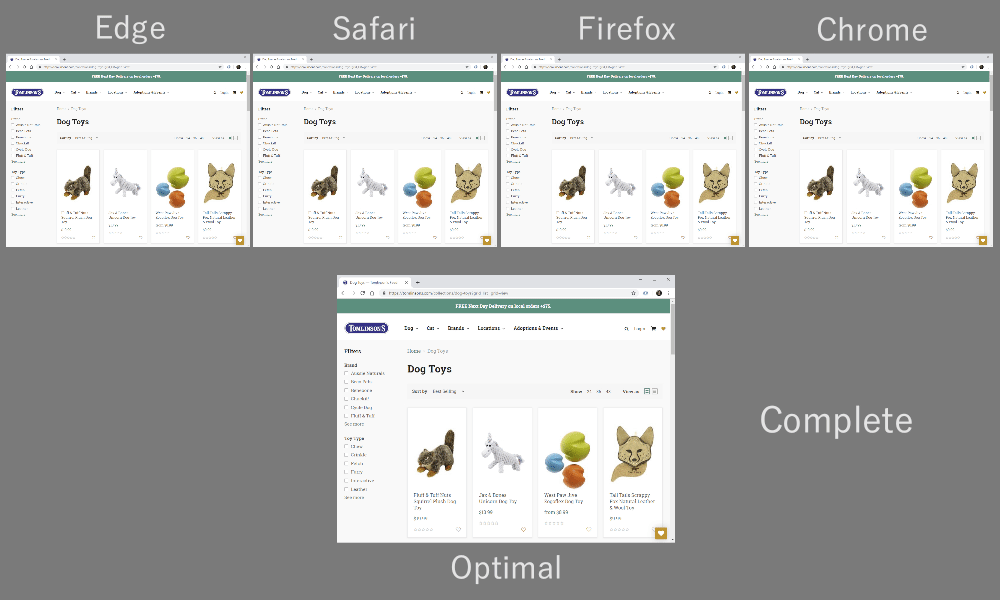
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
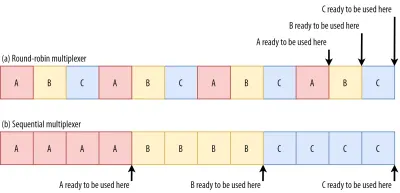
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
And it gets worse. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
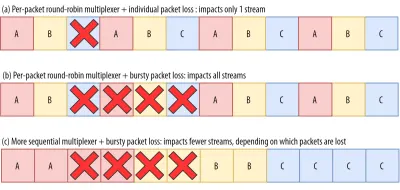
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
Apa artinya itu semua?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
Kinerja UDP dan TLS
Aspek kinerja kelima dari QUIC dan HTTP/3 adalah tentang seberapa efisien dan kinerjanya mereka benar-benar dapat membuat dan mengirim paket di jaringan. Kita akan melihat bahwa penggunaan UDP dan enkripsi berat oleh QUIC dapat membuatnya sedikit lebih lambat daripada TCP (tetapi semuanya membaik).
Pertama, kita telah membahas bahwa penggunaan UDP oleh QUIC lebih tentang fleksibilitas dan kemampuan penerapan daripada tentang kinerja. Hal ini lebih dibuktikan dengan fakta bahwa, hingga saat ini, pengiriman paket QUIC melalui UDP biasanya jauh lebih lambat daripada pengiriman paket TCP. Ini sebagian karena di mana dan bagaimana protokol ini biasanya diterapkan (lihat gambar 9 di bawah).
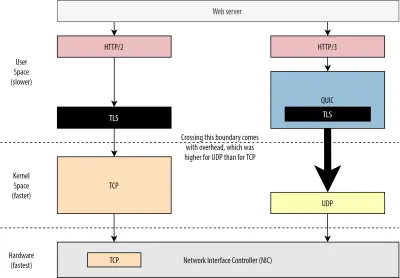
Seperti dibahas di atas, TCP dan UDP biasanya diimplementasikan langsung di kernel cepat OS. Sebaliknya, implementasi TLS dan QUIC sebagian besar berada di ruang pengguna yang lebih lambat (perhatikan bahwa ini tidak benar-benar diperlukan untuk QUIC — sebagian besar dilakukan karena jauh lebih fleksibel). Ini membuat QUIC sudah sedikit lebih lambat dari TCP.
Selain itu, saat mengirim data dari perangkat lunak ruang pengguna kami (misalnya, browser dan server web), kami perlu meneruskan data ini ke kernel OS , yang kemudian menggunakan TCP atau UDP untuk benar-benar meletakkannya di jaringan. Melewati data ini dilakukan dengan menggunakan API kernel (panggilan sistem), yang melibatkan sejumlah overhead tertentu per panggilan API. Untuk TCP, overhead ini jauh lebih rendah daripada UDP.
Ini sebagian besar karena, secara historis, TCP telah digunakan lebih banyak daripada UDP. Dengan demikian, seiring waktu, banyak pengoptimalan ditambahkan ke implementasi TCP dan API kernel untuk mengurangi pengiriman dan penerimaan paket seminimal mungkin. Banyak pengontrol antarmuka jaringan (NIC) bahkan memiliki fitur pembongkaran perangkat keras bawaan untuk TCP. UDP, bagaimanapun, tidak seberuntung itu, karena penggunaannya yang lebih terbatas tidak membenarkan investasi dalam pengoptimalan tambahan. Dalam lima tahun terakhir, untungnya ini telah berubah, dan sebagian besar OS telah menambahkan opsi yang dioptimalkan untuk UDP juga.
Kedua, QUIC memiliki banyak overhead karena mengenkripsi setiap paket satu per satu . Ini lebih lambat daripada menggunakan TLS melalui TCP, karena di sana Anda dapat mengenkripsi paket dalam potongan (hingga sekitar 16 KB atau 11 paket sekaligus), yang lebih efisien. Ini adalah trade-off sadar yang dibuat di QUIC, karena enkripsi massal dapat menyebabkan bentuk pemblokiran HoL sendiri.
Tidak seperti poin pertama, di mana kita dapat menambahkan API tambahan untuk membuat UDP (dan dengan demikian QUIC) lebih cepat, di sini, QUIC akan selalu memiliki kelemahan yang melekat pada TCP + TLS. Namun, ini juga cukup mudah dikelola dalam praktiknya dengan, misalnya, pustaka enkripsi yang dioptimalkan dan metode cerdas yang memungkinkan header paket QUIC dienkripsi secara massal.
Akibatnya, sementara versi QUIC Google yang paling awal masih dua kali lebih lambat dari TCP + TLS, banyak hal telah membaik sejak itu. Misalnya, dalam pengujian baru-baru ini, tumpukan QUIC Microsoft yang sangat dioptimalkan mampu mendapatkan 7,85 Gbps, dibandingkan dengan 11,85 Gbps untuk TCP + TLS pada sistem yang sama (jadi di sini, QUIC sekitar 66% secepat TCP + TLS).
Ini dengan pembaruan Windows terbaru, yang membuat UDP lebih cepat (untuk perbandingan penuh, throughput UDP pada sistem itu adalah 19,5 Gbps). Versi paling optimal dari tumpukan QUIC Google saat ini sekitar 20% lebih lambat dari TCP + TLS. Tes sebelumnya oleh Fastly pada sistem yang kurang canggih dan dengan beberapa trik bahkan mengklaim kinerja yang sama (sekitar 450 Mbps), menunjukkan bahwa tergantung pada kasus penggunaan, QUIC pasti dapat bersaing dengan TCP.
Namun, meskipun QUIC dua kali lebih lambat dari TCP + TLS, itu tidak terlalu buruk. Pertama, pemrosesan QUIC dan TCP + TLS biasanya bukan hal terberat yang terjadi di server, karena logika lain (misalnya, HTTP, caching, proxy, dll.) juga perlu dijalankan. Dengan demikian, Anda sebenarnya tidak memerlukan server dua kali lebih banyak untuk menjalankan QUIC (meskipun agak tidak jelas seberapa besar dampaknya di pusat data nyata, karena tidak ada perusahaan besar yang merilis data tentang ini).
Kedua, masih banyak peluang untuk mengoptimalkan implementasi QUIC di masa mendatang. Misalnya, seiring waktu, beberapa implementasi QUIC akan (sebagian) pindah ke kernel OS (seperti TCP) atau melewatinya (beberapa sudah melakukannya, seperti MsQuic dan Quant). Kami juga dapat mengharapkan perangkat keras khusus QUIC akan tersedia.
Namun, kemungkinan akan ada beberapa kasus penggunaan di mana TCP + TLS akan tetap menjadi opsi yang disukai. Misalnya, Netflix telah mengindikasikan bahwa ia mungkin tidak akan pindah ke QUIC dalam waktu dekat, setelah banyak berinvestasi dalam pengaturan FreeBSD khusus untuk mengalirkan videonya melalui TCP + TLS.
Demikian pula, Facebook telah mengatakan bahwa QUIC mungkin akan digunakan terutama antara pengguna akhir dan tepi CDN , tetapi tidak antara pusat data atau antara node tepi dan server asal, karena overhead yang lebih besar. Secara umum, skenario bandwidth yang sangat tinggi mungkin akan terus mendukung TCP + TLS, terutama dalam beberapa tahun ke depan.
Tahukah kamu?
Mengoptimalkan tumpukan jaringan adalah lubang kelinci yang dalam dan teknis di mana hal di atas hanya menggores permukaan (dan melewatkan banyak nuansa). Jika Anda cukup berani atau jika Anda ingin tahu istilah sepertiGRO/GSO,SO_TXTIME, kernel bypass, dansendmmsg()danrecvmmsg()artinya, saya dapat merekomendasikan beberapa artikel bagus tentang mengoptimalkan QUIC oleh Cloudflare dan Fastly, juga sebagai panduan kode ekstensif oleh Microsoft, dan pembicaraan mendalam dari Cisco. Akhirnya, seorang insinyur Google memberikan keynote yang sangat menarik tentang mengoptimalkan implementasi QUIC mereka dari waktu ke waktu.
Apa artinya itu semua?
Penggunaan khusus QUIC atas protokol UDP dan TLS secara historis membuatnya jauh lebih lambat daripada TCP + TLS. Namun, seiring berjalannya waktu, beberapa perbaikan telah dilakukan (dan akan terus dilaksanakan) yang telah menutup celah tersebut. Anda mungkin tidak akan melihat perbedaan ini dalam kasus penggunaan umum pemuatan halaman web, tetapi mereka mungkin membuat Anda sakit kepala jika Anda mempertahankan kumpulan server yang besar.
Fitur HTTP/3
Sampai sekarang, kami terutama berbicara tentang fitur kinerja baru di QUIC versus TCP. Namun, bagaimana dengan HTTP/3 versus HTTP/2? Seperti yang dibahas di bagian 1, HTTP/3 benar-benar HTTP/2-over-QUIC , dan dengan demikian, tidak ada fitur baru yang nyata dan besar yang diperkenalkan di versi baru. Ini tidak seperti perpindahan dari HTTP/1.1 ke HTTP/2, yang jauh lebih besar dan memperkenalkan fitur-fitur baru seperti kompresi header, prioritas aliran, dan server push. Semua fitur ini masih dalam HTTP/3, tetapi ada beberapa perbedaan penting dalam cara penerapannya.
Ini sebagian besar karena cara kerja penghapusan pemblokiran HoL oleh QUIC. Seperti yang telah kita diskusikan, kerugian pada aliran B tidak lagi menyiratkan bahwa aliran A dan C harus menunggu transmisi ulang B, seperti yang mereka lakukan pada TCP. Dengan demikian, jika A, B, dan C masing-masing mengirim paket QUIC dalam urutan itu, data mereka mungkin dikirim ke (dan diproses oleh) browser sebagai A, C, B! Dengan kata lain, tidak seperti TCP, QUIC tidak lagi sepenuhnya dipesan di berbagai aliran!
Ini adalah masalah untuk HTTP/2, yang sangat bergantung pada urutan ketat TCP dalam desain banyak fiturnya, yang menggunakan pesan kontrol khusus yang diselingi dengan potongan data. Di QUIC, pesan kontrol ini mungkin tiba (dan diterapkan) dalam urutan apa pun, bahkan berpotensi membuat fitur melakukan kebalikan dari apa yang dimaksudkan! Detail teknis, sekali lagi, tidak diperlukan untuk artikel ini, tetapi paruh pertama makalah ini akan memberi Anda gambaran tentang betapa rumitnya hal ini.
Dengan demikian, mekanisme internal dan implementasi fitur harus diubah untuk HTTP/3. Contoh nyata adalah kompresi header HTTP , yang menurunkan overhead dari header HTTP besar yang berulang (misalnya, cookie dan string agen pengguna). Di HTTP/2, ini dilakukan menggunakan pengaturan HPACK, sedangkan untuk HTTP/3 ini telah dikerjakan ulang ke QPACK yang lebih kompleks. Kedua sistem memberikan fitur yang sama (yaitu kompresi header) tetapi dengan cara yang sangat berbeda. Beberapa diskusi teknis dan diagram yang mendalam tentang topik ini dapat ditemukan di blog Litespeed.
Hal serupa berlaku untuk fitur prioritas yang mendorong logika multiplexing aliran dan yang telah kita bahas secara singkat di atas. Di HTTP/2, ini diimplementasikan menggunakan pengaturan "pohon dependensi" yang kompleks, yang secara eksplisit mencoba memodelkan semua sumber daya halaman dan keterkaitannya (informasi lebih lanjut ada dalam pembicaraan "Panduan Utama untuk Prioritas Sumber Daya HTTP"). Menggunakan sistem ini secara langsung melalui QUIC akan menyebabkan beberapa tata letak pohon yang berpotensi sangat salah, karena menambahkan setiap sumber daya ke pohon akan menjadi pesan kontrol yang terpisah.
Selain itu, pendekatan ini ternyata tidak perlu rumit, yang menyebabkan banyak bug implementasi dan inefisiensi dan kinerja di bawah standar di banyak server. Kedua masalah tersebut telah menyebabkan sistem prioritas didesain ulang untuk HTTP/3 dengan cara yang lebih sederhana. Penyiapan yang lebih mudah ini membuat beberapa skenario lanjutan sulit atau tidak mungkin diterapkan (misalnya, mem-proxy lalu lintas dari beberapa klien pada satu koneksi), tetapi masih memungkinkan berbagai opsi untuk pengoptimalan pemuatan halaman web.
Sementara, sekali lagi, kedua pendekatan memberikan fitur dasar yang sama (pemandu aliran multiplexing), harapannya adalah bahwa penyetelan HTTP/3 yang lebih mudah akan membuat lebih sedikit bug implementasi.
Akhirnya, ada server Push . Fitur ini memungkinkan server mengirim respons HTTP tanpa menunggu permintaan eksplisit terlebih dahulu. Secara teori, ini bisa memberikan keuntungan kinerja yang sangat baik. Namun, dalam praktiknya, ternyata sulit digunakan dengan benar dan diterapkan secara tidak konsisten. Akibatnya, itu mungkin bahkan akan dihapus dari Google Chrome.
Terlepas dari semua ini, itu masih didefinisikan sebagai fitur di HTTP/3 (walaupun beberapa implementasi mendukungnya). Sementara cara kerja internalnya tidak berubah sebanyak dua fitur sebelumnya, itu juga telah disesuaikan untuk mengatasi pemesanan non-deterministik QUIC. Sayangnya, ini tidak akan banyak membantu untuk memecahkan beberapa masalah lama.
Apa artinya itu semua?
Seperti yang telah kami katakan sebelumnya, sebagian besar potensi HTTP/3 berasal dari QUIC yang mendasarinya, bukan HTTP/3 itu sendiri. Sementara implementasi internal protokol sangat berbeda dari HTTP/2, fitur kinerja tingkat tinggi dan bagaimana mereka dapat dan harus digunakan tetap sama.
Perkembangan Masa Depan yang Harus Diwaspadai
Dalam seri ini, saya secara teratur menyoroti bahwa evolusi yang lebih cepat dan fleksibilitas yang lebih tinggi adalah aspek inti dari QUIC (dan, dengan ekstensi, HTTP/3). Dengan demikian, tidak mengherankan bahwa orang-orang sudah mengerjakan ekstensi baru dan aplikasi protokol. Tercantum di bawah ini adalah yang utama yang mungkin akan Anda temui di suatu tempat di telepon:
Koreksi kesalahan maju
Tujuan teknik ini, sekali lagi, untuk meningkatkan ketahanan QUIC terhadap kehilangan paket . Ini dilakukan dengan mengirimkan salinan data yang berlebihan (meskipun dikodekan dan dikompresi dengan cerdas sehingga tidak terlalu besar). Kemudian, jika sebuah paket hilang tetapi data yang berlebihan tiba, transmisi ulang tidak lagi diperlukan.
Ini pada awalnya adalah bagian dari Google QUIC (dan salah satu alasan mengapa orang mengatakan QUIC baik terhadap kehilangan paket), tetapi tidak termasuk dalam QUIC versi 1 standar karena dampak kinerjanya belum terbukti. Namun, para peneliti sekarang melakukan eksperimen aktif dengannya, dan Anda dapat membantu mereka dengan menggunakan aplikasi Eksperimen Unduhan PQUIC-FEC.QUIC multijalur
Kami sebelumnya telah membahas migrasi koneksi dan bagaimana hal itu dapat membantu saat berpindah dari, katakanlah, Wi-Fi ke seluler. Namun, bukankah itu juga menyiratkan bahwa kita mungkin menggunakan Wi-Fi dan seluler secara bersamaan ? Secara bersamaan menggunakan kedua jaringan akan memberi kami lebih banyak bandwidth yang tersedia dan peningkatan ketahanan! Itulah konsep utama di balik multipath.
Sekali lagi, ini adalah sesuatu yang bereksperimen dengan Google tetapi tidak berhasil masuk ke QUIC versi 1 karena kompleksitasnya yang melekat. Namun, para peneliti telah menunjukkan potensinya yang tinggi, dan mungkin membuatnya menjadi QUIC versi 2. Perhatikan bahwa multipath TCP juga ada, tetapi butuh hampir satu dekade untuk dapat digunakan secara praktis.Data tidak dapat diandalkan melalui QUIC dan HTTP/3
Seperti yang telah kita lihat, QUIC adalah protokol yang sepenuhnya dapat diandalkan. Namun, karena berjalan di atas UDP, yang tidak dapat diandalkan, kami dapat menambahkan fitur ke QUIC untuk juga mengirim data yang tidak dapat diandalkan. Ini diuraikan dalam ekstensi datagram yang diusulkan. Anda tentu saja tidak ingin menggunakan ini untuk mengirim sumber daya halaman web, tetapi mungkin berguna untuk hal-hal seperti game dan streaming video langsung. Dengan cara ini, pengguna akan mendapatkan semua manfaat UDP tetapi dengan enkripsi tingkat QUIC dan kontrol kemacetan (opsional).WebTransportasi
Browser tidak mengekspos TCP atau UDP ke JavaScript secara langsung, terutama karena masalah keamanan. Sebaliknya, kita harus mengandalkan API tingkat HTTP seperti Fetch dan protokol WebSocket dan WebRTC yang agak lebih fleksibel. Yang terbaru dalam rangkaian opsi ini disebut WebTransport, yang terutama memungkinkan Anda untuk menggunakan HTTP/3 (dan, dengan ekstensi, QUIC) dengan cara yang lebih rendah (meskipun juga dapat kembali ke TCP dan HTTP/2 jika diperlukan ).
Yang terpenting, ini akan mencakup kemampuan untuk menggunakan data yang tidak dapat diandalkan melalui HTTP/3 (lihat poin sebelumnya), yang seharusnya membuat hal-hal seperti bermain game sedikit lebih mudah untuk diterapkan di browser. Untuk panggilan API (JSON) normal, Anda tentu saja masih menggunakan Fetch, yang juga akan secara otomatis menggunakan HTTP/3 jika memungkinkan. WebTransport masih dalam diskusi berat saat ini, jadi belum jelas seperti apa nantinya. Dari browser, hanya Chromium yang saat ini sedang mengerjakan implementasi konsep bukti publik.Streaming video DASH dan HLS
Untuk video tidak langsung (pikirkan YouTube dan Netflix), browser biasanya menggunakan protokol Dynamic Adaptive Streaming melalui HTTP (DASH) atau HTTP Live Streaming (HLS). Keduanya pada dasarnya berarti Anda menyandikan video Anda menjadi potongan-potongan yang lebih kecil (2 hingga 10 detik) dan tingkat kualitas yang berbeda (720p, 1080p, 4K, dll.).
Saat runtime, browser memperkirakan kualitas tertinggi yang dapat ditangani jaringan Anda (atau yang paling optimal untuk kasus penggunaan tertentu), dan browser meminta file yang relevan dari server melalui HTTP. Karena browser tidak memiliki akses langsung ke tumpukan TCP (seperti yang biasanya diterapkan di kernel), terkadang browser membuat beberapa kesalahan dalam perkiraan ini, atau perlu beberapa saat untuk bereaksi terhadap perubahan kondisi jaringan (mengakibatkan video terhenti) .
Karena QUIC diimplementasikan sebagai bagian dari browser, ini dapat ditingkatkan sedikit, dengan memberikan akses estimator streaming ke informasi protokol tingkat rendah (seperti tingkat kehilangan, perkiraan bandwidth, dll.). Peneliti lain telah bereksperimen dengan mencampurkan data yang dapat diandalkan dan tidak dapat diandalkan untuk streaming video juga, dengan beberapa hasil yang menjanjikan.Protokol selain HTTP/3
Dengan QUIC menjadi protokol transport tujuan umum, kita dapat mengharapkan banyak protokol lapisan aplikasi yang sekarang berjalan di atas TCP untuk dijalankan di atas QUIC juga. Beberapa pekerjaan yang sedang berlangsung termasuk DNS-over-QUIC, SMB-over-QUIC, dan bahkan SSH-over-QUIC. Karena protokol ini biasanya memiliki persyaratan yang sangat berbeda dari HTTP dan pemuatan halaman web, peningkatan kinerja QUIC yang telah kita diskusikan mungkin bekerja lebih baik untuk protokol ini.
Apa artinya itu semua?
QUIC versi 1 hanyalah permulaan . Banyak fitur berorientasi kinerja tingkat lanjut yang telah dicoba Google sebelumnya tidak berhasil masuk ke iterasi pertama ini. Namun, tujuannya adalah untuk mengembangkan protokol dengan cepat, memperkenalkan ekstensi dan fitur baru pada frekuensi tinggi. Dengan demikian, seiring waktu, QUIC (dan HTTP/3) seharusnya menjadi lebih cepat dan lebih fleksibel daripada TCP (dan HTTP/2).
Kesimpulan
Di bagian kedua dari seri ini, kita telah membahas banyak fitur dan aspek kinerja yang berbeda dari HTTP/3 dan terutama QUIC. Kami telah melihat bahwa sementara sebagian besar fitur ini tampak sangat berdampak, dalam praktiknya mereka mungkin tidak melakukan banyak hal untuk rata-rata pengguna dalam kasus penggunaan pemuatan halaman web yang telah kami pertimbangkan.
Misalnya, kita telah melihat bahwa penggunaan UDP oleh QUIC tidak berarti bahwa ia dapat tiba-tiba menggunakan lebih banyak bandwidth daripada TCP, juga tidak berarti ia dapat mengunduh sumber daya Anda lebih cepat. Fitur 0-RTT yang sering dipuji benar-benar merupakan optimasi mikro yang menghemat satu perjalanan pulang pergi, di mana Anda dapat mengirim sekitar 5 KB (dalam kasus terburuk).
Penghapusan pemblokiran HoL tidak berfungsi dengan baik jika ada paket yang hilang secara tiba-tiba atau saat Anda memuat sumber pemblokiran render. Migrasi koneksi sangat situasional, dan HTTP/3 tidak memiliki fitur baru utama yang dapat membuatnya lebih cepat daripada HTTP/2.
Karena itu, Anda mungkin mengharapkan saya untuk merekomendasikan agar Anda melewatkan HTTP/3 dan QUIC. Kenapa repot, kan? Namun, saya pasti tidak akan melakukan hal seperti itu! Meskipun protokol baru ini mungkin tidak banyak membantu pengguna di jaringan cepat (perkotaan), fitur-fitur baru ini tentu berpotensi sangat berdampak bagi pengguna yang sangat mobile dan orang-orang di jaringan yang lambat.
Bahkan di pasar Barat seperti Belgia saya sendiri, di mana kami umumnya memiliki perangkat cepat dan akses ke jaringan seluler berkecepatan tinggi, situasi ini dapat memengaruhi 1% hingga bahkan 10% dari basis pengguna Anda, tergantung pada produk Anda. Contohnya adalah seseorang di kereta berusaha mati-matian untuk mencari informasi penting di situs web Anda, tetapi harus menunggu 45 detik untuk memuatnya. Saya tentu tahu saya pernah berada dalam situasi itu, berharap seseorang telah mengerahkan QUIC untuk mengeluarkan saya darinya.
Namun, ada negara dan wilayah lain di mana keadaan masih jauh lebih buruk. Di sana, rata-rata pengguna mungkin terlihat lebih seperti 10% paling lambat di Belgia, dan 1% paling lambat mungkin tidak akan pernah melihat halaman yang dimuat sama sekali. Di banyak bagian dunia, kinerja web merupakan masalah aksesibilitas dan inklusivitas.
Inilah sebabnya mengapa kita tidak boleh hanya menguji halaman kita pada perangkat keras kita sendiri (tetapi juga menggunakan layanan seperti Webpagetest) dan juga mengapa Anda harus menggunakan QUIC dan HTTP/3 . Terutama jika pengguna Anda sering berpindah-pindah atau tidak mungkin memiliki akses ke jaringan seluler yang cepat, protokol baru ini mungkin akan membuat perbedaan besar, bahkan jika Anda tidak terlalu memperhatikan MacBook Pro kabel Anda. Untuk detail lebih lanjut, saya sangat merekomendasikan posting Fastly tentang masalah ini.
Jika itu tidak sepenuhnya meyakinkan Anda, pertimbangkan bahwa QUIC dan HTTP/3 akan terus berkembang dan menjadi lebih cepat di tahun-tahun mendatang. Mendapatkan beberapa pengalaman awal dengan protokol akan membuahkan hasil, memungkinkan Anda untuk menuai manfaat dari fitur-fitur baru sesegera mungkin. Selain itu, QUIC menerapkan praktik terbaik keamanan dan privasi di latar belakang, yang menguntungkan semua pengguna di mana saja.
Akhirnya yakin? Kemudian lanjutkan ke bagian 3 dari seri untuk membaca tentang bagaimana Anda dapat menggunakan protokol baru dalam praktik.
- Bagian 1: Sejarah HTTP/3 Dan Konsep Inti
Artikel ini ditujukan untuk orang-orang yang baru mengenal HTTP/3 dan protokol secara umum, dan terutama membahas dasar-dasarnya. - Bagian 2: Fitur Kinerja HTTP/3
Yang ini lebih mendalam dan teknis. Orang yang sudah tahu dasar-dasarnya bisa mulai dari sini. - Bagian 3: Opsi Penerapan HTTP/3 Praktis
Artikel ketiga dalam seri ini menjelaskan tantangan yang terlibat dalam penerapan dan pengujian HTTP/3 sendiri. Ini merinci bagaimana dan jika Anda harus mengubah halaman web dan sumber daya Anda juga.