
Bagaimana Menerapkan Klasifikasi dalam Pembelajaran Mesin?
Diterbitkan: 2021-03-12Penerapan Machine Learning di berbagai bidang telah meningkat pesat dalam beberapa tahun terakhir, dan terus berlanjut. Salah satu tugas model Machine Learning yang paling populer adalah mengenali objek dan memisahkannya ke dalam kelas yang ditentukan.
Ini adalah metode Klasifikasi yang merupakan salah satu aplikasi Machine Learning yang paling populer. Klasifikasi digunakan untuk memisahkan sejumlah besar data menjadi satu set nilai diskrit yang mungkin biner seperti 0/1, Ya/Tidak, atau multi-kelas seperti hewan, mobil, burung, dll.
Pada artikel berikut, kita akan memahami konsep Klasifikasi dalam Pembelajaran Mesin, jenis Data yang terlibat, dan melihat beberapa algoritma Klasifikasi paling populer yang digunakan dalam Pembelajaran Mesin untuk mengklasifikasikan beberapa data.
Daftar isi
Apa itu Pembelajaran Terawasi?
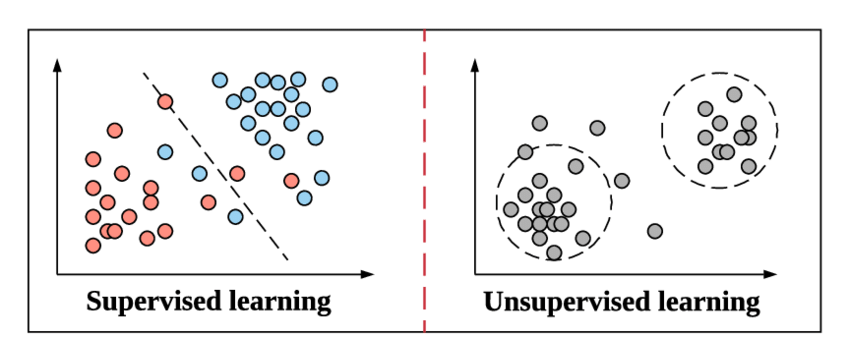
Saat kita bersiap untuk menyelami konsep Klasifikasi dan jenisnya, mari kita segera menyegarkan diri kita dengan apa yang dimaksud dengan Pembelajaran Terawasi dan perbedaannya dengan metode Pembelajaran Tanpa Pengawasan lainnya dalam Pembelajaran Mesin.
Mari kita pahami ini dengan mengambil contoh sederhana dari kelas Fisika kita di SMA. Misalkan ada masalah sederhana yang melibatkan metode baru. Jika kita dihadapkan pada sebuah pertanyaan dimana kita harus menyelesaikannya dengan menggunakan metode yang sama, bukankah kita semua akan mengacu pada sebuah contoh soal dengan metode yang sama dan mencoba menyelesaikannya. Setelah kita yakin dengan metode itu, kita tidak perlu merujuknya lagi dan terus menyelesaikannya.
Sumber

Ini adalah cara yang sama di mana Pembelajaran Terawasi bekerja dalam Pembelajaran Mesin. Ia belajar melalui contoh. Untuk membuatnya lebih sederhana, dalam Supervised Learning, seluruh data diberi label yang sesuai dan karenanya selama proses pelatihan, model Machine Learning terlihat membandingkan outputnya untuk data tertentu dengan output sebenarnya dari data yang sama dan mencoba untuk meminimalkan kesalahan antara nilai label yang diprediksi dan nyata.
Algoritma Klasifikasi yang akan kita lalui dalam artikel ini mengikuti metode Pembelajaran Terawasi ini—misalnya, Deteksi Spam dan Pengenalan Objek.
Pembelajaran Tanpa Pengawasan adalah langkah di atas di mana data tidak diberi labelnya. Terserah tanggung jawab dan efisiensi model Pembelajaran Mesin untuk mendapatkan pola dari data dan memberikan output. Algoritma pengelompokan mengikuti metode Pembelajaran Tanpa Pengawasan ini.
Apa itu Klasifikasi?
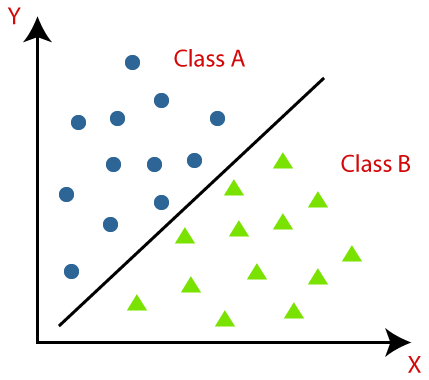
Klasifikasi didefinisikan sebagai mengenali, memahami, dan mengelompokkan objek atau data ke dalam kelas yang telah ditentukan sebelumnya. Dengan mengkategorikan data sebelum proses pelatihan model Machine Learning, kita dapat menggunakan berbagai algoritma klasifikasi untuk mengklasifikasikan data ke dalam beberapa kelas. Tidak seperti Regresi, masalah klasifikasi adalah ketika variabel keluaran adalah kategori, seperti "Ya" atau "Tidak" atau "Penyakit" atau "Tidak Ada Penyakit".
Dalam sebagian besar masalah Pembelajaran Mesin, setelah set data dimuat ke program, sebelum pelatihan, pisahkan set data menjadi set pelatihan dan set pengujian dengan rasio tetap (Biasanya 70% set pelatihan dan 30% set pengujian). Proses pemisahan ini memungkinkan model untuk melakukan backpropagation di mana ia mencoba untuk memperbaiki kesalahannya dari nilai prediksi terhadap nilai sebenarnya dengan beberapa pendekatan matematis.
Demikian pula, sebelum kita memulai Klasifikasi, dataset pelatihan dibuat. Algoritma Klasifikasi menjalani pelatihan saat menguji dataset uji dengan setiap iterasi, yang dikenal sebagai epoch.
Sumber
Salah satu aplikasi Algoritma Klasifikasi yang paling umum adalah memfilter email apakah itu "spam" atau "non-spam." Singkatnya, kita dapat mendefinisikan Klasifikasi dalam Pembelajaran Mesin sebagai bentuk "Pengenalan Pola" di mana algoritma yang diterapkan pada data pelatihan ini digunakan untuk mengekstrak beberapa pola dari data (Seperti kata atau urutan angka yang serupa, sentimen, dll. .).
Klasifikasi adalah proses mengkategorikan satu set data yang diberikan ke dalam kelas; itu dapat dilakukan pada data terstruktur atau tidak terstruktur. Ini dimulai dengan memprediksi kelas dari titik data yang diberikan. Kelas-kelas ini juga disebut sebagai variabel keluaran, label target, dll. Beberapa algoritma memiliki fungsi matematika bawaan untuk memperkirakan fungsi pemetaan dari variabel titik data input ke kelas target keluaran. Tujuan utama klasifikasi adalah untuk mengidentifikasi kelas/kategori mana data baru akan masuk.
Jenis-Jenis Algoritma Klasifikasi dalam Pembelajaran Mesin
Bergantung pada jenis data di mana Algoritma Klasifikasi diterapkan, ada dua kategori besar algoritma, model Linier dan Non-linier.
Model Linier
- Regresi logistik
- Mendukung Mesin Vektor (SVM)
Model Non-Linear
- Klasifikasi K-Nearest Neighbors (KNN)
- SVM kernel
- Klasifikasi Naive Bayes
- Klasifikasi Pohon Keputusan
- Klasifikasi Hutan Acak
Pada artikel ini, kita akan membahas secara singkat konsep di balik masing-masing algoritma yang disebutkan di atas.
Evaluasi Model Klasifikasi dalam Pembelajaran Mesin
Sebelum kita beralih ke konsep algoritme yang disebutkan di atas, kita harus memahami bagaimana kita dapat mengevaluasi model Pembelajaran Mesin yang dibangun di atas algoritme ini. Sangat penting untuk mengevaluasi model kami untuk akurasi pada set pelatihan dan set pengujian.
Rugi Lintas Entropi atau Rugi Log
Ini adalah jenis pertama dari fungsi kerugian yang akan kita gunakan dalam mengevaluasi kinerja pengklasifikasi yang outputnya antara 0 dan 1. Ini banyak digunakan untuk model Klasifikasi Biner. Rumus Log Loss diberikan oleh,
Rugi Log = -((1 – y) * log(1 – yhat) + y * log(yhat))
Dimana itu adalah nilai prediksi, dan y adalah nilai sebenarnya.
Matriks Kebingungan
Confusion matrix adalah matriks NXN, di mana N adalah jumlah kelas yang diprediksi. Matriks konfusi memberi kita matriks/tabel sebagai keluaran dan menjelaskan kinerja model. Ini terdiri dari hasil prediksi dalam bentuk matriks dari mana kita dapat memperoleh beberapa metrik kinerja untuk mengevaluasi model Klasifikasi. Itu berbentuk,
| Positif Sebenarnya | Negatif Sebenarnya | |
| Diprediksi Positif | Benar Positif | Positif Palsu |
| Prediksi Negatif | Negatif Palsu | Benar Negatif |
Beberapa metrik kinerja yang dapat diturunkan dari tabel di atas diberikan di bawah ini.
1.Akurasi – proporsi jumlah total prediksi yang benar.
2. Nilai Prediktif atau Presisi Positif – proporsi kasus positif yang diidentifikasi dengan benar.
3. Nilai Prediktif Negatif – proporsi kasus negatif yang diidentifikasi dengan benar.
4. Sensitivitas atau Penarikan Kembali – proporsi kasus positif aktual yang diidentifikasi dengan benar.
5. Spesifisitas – proporsi kasus negatif aktual yang diidentifikasi dengan benar.
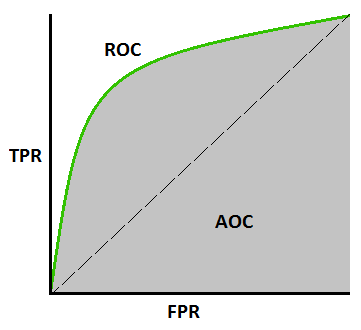
Kurva AUC-ROC –
Ini adalah metrik kurva penting lainnya yang mengevaluasi model Pembelajaran Mesin apa pun. Kurva ROC adalah singkatan dari Receiver Operating Characteristics Curve, dan AUC adalah singkatan dari Area Under the Curve. Kurva ROC diplot dengan TPR dan FPR, dimana TPR (True Positive Rate) pada sumbu Y dan FPR (False Positive Rate) pada sumbu X. Ini menunjukkan kinerja model klasifikasi pada ambang batas yang berbeda.
Sumber
1. Regresi Logistik
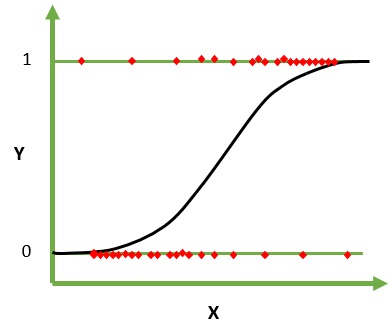
Regresi Logistik adalah algoritma pembelajaran mesin untuk Klasifikasi. Dalam algoritma ini, probabilitas yang menggambarkan kemungkinan hasil percobaan tunggal dimodelkan menggunakan fungsi logistik. Ini mengasumsikan variabel input numerik dan memiliki distribusi Gaussian (kurva lonceng).
Fungsi logistik, juga disebut fungsi sigmoid, pada awalnya digunakan oleh ahli statistik untuk menggambarkan pertumbuhan populasi dalam ekologi. Fungsi sigmoid adalah fungsi matematika yang digunakan untuk memetakan nilai prediksi ke probabilitas. Regresi Logistik memiliki kurva berbentuk S dan dapat mengambil nilai antara 0 dan 1 tetapi tidak pernah tepat pada batas tersebut.

Sumber
Regresi Logistik terutama digunakan untuk memprediksi hasil biner seperti Ya/Tidak dan Lulus/Gagal. Variabel bebas dapat berupa kategorikal atau numerik, tetapi variabel terikat selalu kategoris. Rumus untuk Regresi Logistik diberikan oleh,
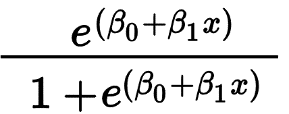
Dimana e mewakili kurva berbentuk S yang memiliki nilai antara 0 dan 1.
2. Mendukung Mesin Vektor
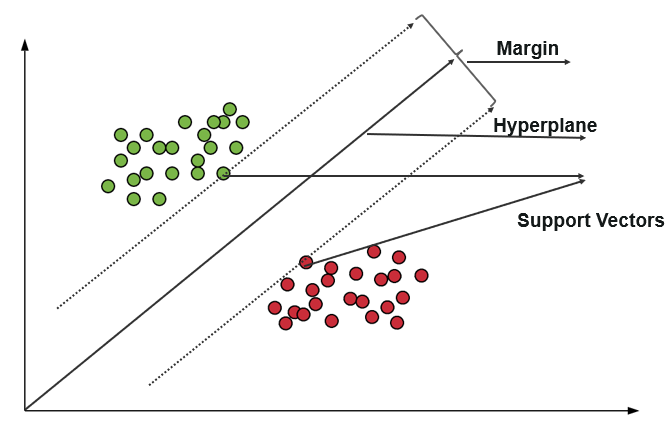
Mesin vektor pendukung (SVM) menggunakan algoritme untuk melatih dan mengklasifikasikan data dalam derajat polaritas, membawanya ke tingkat di luar prediksi X/Y. Dalam SVM, garis yang digunakan untuk memisahkan kelas disebut sebagai Hyperplane. Titik data di kedua sisi Hyperplane yang paling dekat dengan Hyperplane disebut Support Vectors yang digunakan untuk memplot garis batas.
Mesin Vektor Pendukung dalam Klasifikasi ini mewakili data pelatihan sebagai titik data dalam ruang di mana banyak kategori dipisahkan ke dalam kategori Hyperplane. Ketika sebuah titik baru masuk, itu diklasifikasikan dengan memprediksi ke dalam kategori mana mereka termasuk dan termasuk dalam ruang tertentu.
Sumber
Tujuan utama dari mesin Support Vector adalah untuk memaksimalkan margin antara dua Support Vectors.
Bergabunglah dengan kursus ML online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
3. Klasifikasi K-Nearest Neighbors (KNN)
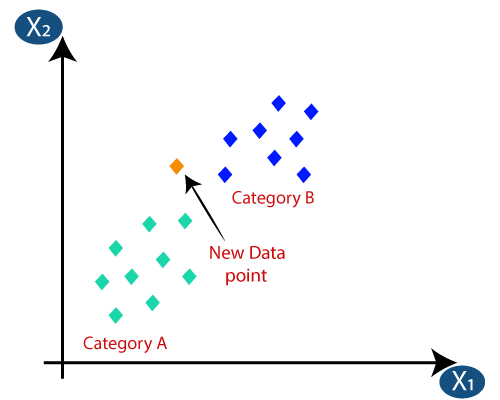
KNN Classification adalah salah satu algoritma Klasifikasi yang paling sederhana, namun sangat banyak digunakan karena efisiensinya yang tinggi dan kemudahan penggunaannya. Dalam metode ini, seluruh dataset disimpan di mesin pada awalnya. Kemudian, nilai – k dipilih, yang mewakili jumlah tetangga. Dengan cara ini, ketika titik data baru ditambahkan ke dataset, dibutuhkan suara mayoritas dari k label kelas tetangga terdekat ke titik data baru tersebut. Dengan suara ini, titik data baru ditambahkan ke kelas tertentu dengan suara tertinggi.
Sumber
4. Kernel SVM
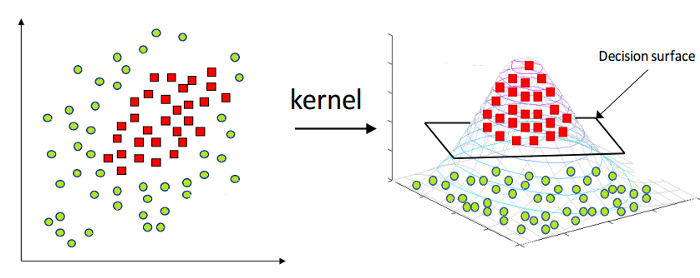
Seperti disebutkan di atas, Mesin Vektor Dukungan Linier hanya dapat diterapkan pada data linier saja. Namun, semua data di dunia tidak dapat dipisahkan secara linier. Oleh karena itu, kita perlu mengembangkan Support Vector Machine untuk memperhitungkan data yang juga tidak dapat dipisahkan secara linier. Inilah trik Kernel, juga dikenal sebagai Kernel Support Vector Machine atau Kernel SVM.
Di Kernel SVM, kami memilih kernel seperti RBF atau Kernel Gaussian. Semua titik data dipetakan ke dimensi yang lebih tinggi, di mana mereka menjadi dapat dipisahkan secara linier. Dengan cara ini, kita dapat membuat batas keputusan antara kelas yang berbeda dari dataset.
Sumber
Oleh karena itu, dengan cara ini, menggunakan konsep dasar Support Vector Machines, kita dapat merancang SVM Kernel untuk non-linear.
5. Klasifikasi Naive Bayes
Klasifikasi Naive Bayes berakar pada Teorema Bayes, dengan asumsi bahwa semua variabel independen (fitur) dari kumpulan data adalah independen. Mereka memiliki kepentingan yang sama dalam memprediksi hasil. Asumsi Teorema Bayes ini memberi nama- 'Naif'. Ini digunakan untuk berbagai tugas, seperti penyaringan spam dan area klasifikasi teks lainnya. Naive Bayes menghitung kemungkinan apakah suatu titik data termasuk dalam kategori tertentu atau tidak.
Rumus Klasifikasi Naive Bayes diberikan oleh,
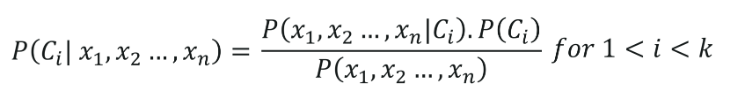
6. Klasifikasi Pohon Keputusan
Pohon keputusan adalah algoritma pembelajaran terawasi yang sempurna untuk masalah klasifikasi, karena dapat mengurutkan kelas pada tingkat yang tepat. Ini beroperasi dalam bentuk diagram alur di mana ia memisahkan titik data di setiap level. Struktur terakhir terlihat seperti pohon dengan simpul dan daun.

Sumber
Sebuah node keputusan akan memiliki dua atau lebih cabang, dan daun mewakili klasifikasi atau keputusan. Dalam contoh Pohon Keputusan di atas, dengan mengajukan beberapa pertanyaan, diagram alur dibuat, yang membantu kita memecahkan masalah sederhana dalam memprediksi apakah akan pergi ke pasar atau tidak.
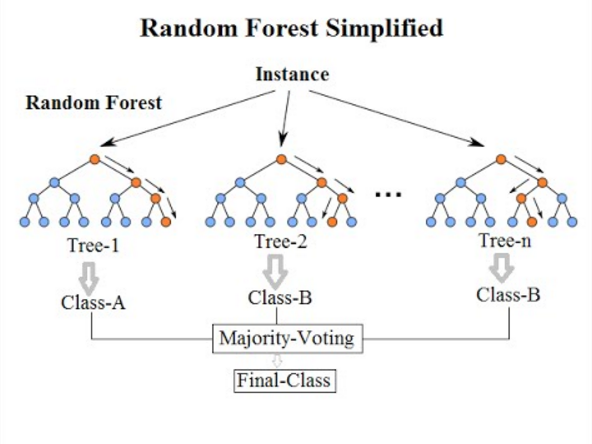
7. Klasifikasi Hutan Acak
Datang ke Algoritma Klasifikasi terakhir dari daftar ini, Hutan Acak hanyalah perpanjangan dari Algoritma Pohon Keputusan. A Random Forest adalah metode pembelajaran ensemble dengan beberapa Pohon Keputusan. Ia bekerja dengan cara yang sama seperti Pohon Keputusan.
Sumber
Algoritma Hutan Acak adalah kemajuan dari Algoritma Pohon Keputusan yang ada, yang mengalami masalah besar " overfitting ". Itu juga dianggap lebih cepat dan lebih akurat dibandingkan dengan Algoritma Pohon Keputusan.
Baca Juga: Ide & Topik Proyek Pembelajaran Mesin
Kesimpulan
Jadi, dalam artikel tentang Metode Pembelajaran Mesin untuk Klasifikasi ini, kami telah memahami dasar-dasar Klasifikasi dan Pembelajaran Terawasi, Jenis dan metrik Evaluasi model Klasifikasi dan akhirnya, ringkasan semua model Klasifikasi yang paling umum digunakan Pembelajaran Mesin.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat Program PG Eksekutif IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT -B Status Alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Q1. Algoritma apa yang paling sering digunakan dalam pembelajaran mesin?
Pembelajaran mesin menggunakan banyak algoritme berbeda, yang secara luas dapat diklasifikasikan menjadi tiga jenis utama – algoritme pembelajaran yang diawasi, algoritme pembelajaran tanpa pengawasan, dan algoritme pembelajaran penguatan. Sekarang, untuk mempersempit dan menyebutkan beberapa algoritma yang paling umum digunakan, yang harus disebutkan adalah regresi linier, regresi logistik, SVM, pohon keputusan, algoritma hutan acak, kNN, teori Naive Bayes, K-Means, pengurangan dimensi, dan algoritma peningkatan gradien. Algoritme XGBoost, GBM, LightGBM, dan CatBoost pantas disebutkan secara khusus dalam algoritme peningkatan gradien. Algoritma ini dapat diterapkan untuk memecahkan hampir semua jenis masalah data.
Q2. Apa itu klasifikasi dan regresi dalam pembelajaran mesin?
Algoritma klasifikasi dan regresi banyak digunakan dalam pembelajaran mesin. Namun, ada banyak perbedaan di antara mereka, yang pada akhirnya menentukan penggunaan atau tujuannya. Perbedaan utama adalah bahwa sementara algoritma klasifikasi digunakan untuk mengklasifikasikan atau memprediksi nilai-nilai diskrit seperti laki-laki-perempuan atau benar-salah, algoritma regresi digunakan untuk meramalkan non-diskrit, nilai-nilai kontinu seperti gaji, usia, harga, dll Pohon keputusan, hutan acak, Kernel SVM, dan regresi logistik adalah beberapa algoritme klasifikasi yang paling umum, sedangkan regresi linier sederhana dan berganda, regresi vektor pendukung, regresi polinomial, dan regresi pohon keputusan adalah beberapa algoritme regresi paling populer yang digunakan dalam pembelajaran mesin.
Q3. Apa prasyarat untuk mempelajari pembelajaran mesin?
Untuk memulai pembelajaran mesin, Anda tidak perlu menjadi ahli matematika atau programmer ahli. Namun, mengingat luasnya bidang ini, mungkin terasa menakutkan ketika Anda baru saja akan memulai perjalanan pembelajaran mesin Anda. Dalam kasus seperti itu, mengetahui prasyarat dapat membantu Anda memulai dengan mulus. Prasyarat pada dasarnya adalah keterampilan inti yang perlu Anda peroleh untuk memahami konsep pembelajaran mesin. Jadi pertama dan terpenting, pastikan Anda mempelajari cara membuat kode menggunakan Python. Selanjutnya, pemahaman dasar statistik dan matematika, terutama aljabar linier dan kalkulus multivariabel, akan menjadi keuntungan tambahan.