
Cara Memilih Metode Pemilihan Fitur untuk Pembelajaran Mesin
Diterbitkan: 2021-06-22Daftar isi
Pengenalan Seleksi Fitur
Banyak fitur yang digunakan oleh model pembelajaran mesin yang hanya beberapa di antaranya yang penting. Ada pengurangan akurasi model jika fitur yang tidak perlu digunakan untuk melatih model data. Selanjutnya, terjadi peningkatan kompleksitas model dan penurunan kemampuan Generalisasi sehingga menghasilkan model yang bias. Pepatah "terkadang lebih sedikit lebih baik" cocok dengan konsep pembelajaran mesin. Masalah telah dihadapi oleh banyak pengguna di mana mereka merasa sulit untuk mengidentifikasi kumpulan fitur yang relevan dari data mereka dan mengabaikan semua kumpulan fitur yang tidak relevan. Fitur yang kurang penting disebut agar tidak berkontribusi pada variabel target.
Oleh karena itu, salah satu proses penting adalah pemilihan fitur dalam pembelajaran mesin . Tujuannya adalah untuk memilih kumpulan fitur terbaik untuk pengembangan model pembelajaran mesin. Ada dampak besar pada kinerja model dengan pemilihan fitur. Seiring dengan pembersihan data, pemilihan fitur harus menjadi langkah pertama dalam desain model.
Pemilihan fitur dalam Pembelajaran Mesin dapat diringkas sebagai:
- Pemilihan otomatis atau manual dari fitur-fitur yang berkontribusi paling besar terhadap variabel prediksi atau output.
- Kehadiran fitur yang tidak relevan dapat menyebabkan penurunan akurasi model karena akan belajar dari fitur yang tidak relevan.
Manfaat Pemilihan Fitur
- Mengurangi overfitting data: jumlah data yang lebih sedikit menyebabkan redundansi yang lebih rendah. Oleh karena itu ada lebih sedikit peluang untuk membuat keputusan tentang kebisingan.
- Meningkatkan akurasi model: dengan lebih sedikit kemungkinan data menyesatkan, akurasi model meningkat.
- Waktu pelatihan berkurang: penghapusan fitur yang tidak relevan mengurangi kompleksitas algoritme karena hanya ada lebih sedikit titik data. Oleh karena itu, algoritma melatih lebih cepat.
- Kompleksitas model berkurang dengan interpretasi data yang lebih baik.
Metode pemilihan fitur yang diawasi dan tidak diawasi
Tujuan utama dari algoritma seleksi fitur adalah untuk memilih satu set fitur terbaik untuk pengembangan model. Metode pemilihan fitur dalam pembelajaran mesin dapat diklasifikasikan menjadi metode terawasi dan tidak terawasi.
- Metode terawasi: metode terawasi digunakan untuk pemilihan fitur dari data berlabel dan juga digunakan untuk klasifikasi fitur yang relevan. Oleh karena itu, ada peningkatan efisiensi model yang dibangun.
- Metode tanpa pengawasan : metode pemilihan fitur ini digunakan untuk data yang tidak berlabel.
Daftar Metode Di Bawah Metode yang Diawasi
Metode pemilihan fitur yang diawasi dalam pembelajaran mesin dapat diklasifikasikan menjadi:

1. Metode Pembungkus
Jenis algoritma seleksi fitur mengevaluasi proses kinerja fitur berdasarkan hasil algoritma. Juga dikenal sebagai algoritma serakah, itu melatih algoritma menggunakan subset fitur secara iteratif. Kriteria penghentian biasanya ditentukan oleh orang yang melatih algoritme. Penambahan dan penghapusan fitur dalam model dilakukan berdasarkan pelatihan model sebelumnya. Semua jenis algoritma pembelajaran dapat diterapkan dalam strategi pencarian ini. Model lebih akurat dibandingkan dengan metode filter.
Teknik yang digunakan dalam metode Wrapper adalah:
- Seleksi maju: Proses seleksi maju adalah proses berulang di mana fitur baru yang meningkatkan model ditambahkan setelah setiap iterasi. Ini dimulai dengan serangkaian fitur yang kosong. Iterasi berlanjut dan berhenti hingga fitur ditambahkan yang tidak lebih meningkatkan kinerja model.
- Seleksi/eliminasi mundur: Proses adalah proses berulang yang dimulai dengan semua fitur. Setelah setiap iterasi, fitur dengan signifikansi terkecil akan dihapus dari kumpulan fitur awal. Kriteria penghentian untuk iterasi adalah ketika kinerja model tidak meningkat lebih lanjut dengan penghapusan fitur. Algoritma ini diimplementasikan dalam paket mlxtend.
- Eliminasi dua arah : Kedua metode seleksi maju dan teknik eliminasi mundur diterapkan secara bersamaan dalam metode eliminasi dua arah untuk mencapai satu solusi unik.
- Seleksi fitur lengkap: Ini juga dikenal sebagai pendekatan brute force untuk evaluasi subset fitur. Satu set kemungkinan subset dibuat dan algoritma pembelajaran dibangun untuk setiap subset. Subset tersebut dipilih yang modelnya memberikan kinerja terbaik.
- Penghapusan Fitur Rekursif (RFE): Metode ini disebut serakah karena memilih fitur dengan secara rekursif mempertimbangkan kumpulan fitur yang lebih kecil dan lebih kecil. Seperangkat fitur awal digunakan untuk melatih penaksir dan kepentingannya diperoleh menggunakan atribut_fitur_penting. Kemudian diikuti dengan penghapusan fitur yang paling tidak penting dengan hanya menyisakan sejumlah fitur yang diperlukan. Algoritma diimplementasikan dalam paket scikit-learn.
Gambar 4: Contoh kode yang menunjukkan teknik eliminasi fitur rekursif
2. Metode tersemat
Metode pemilihan fitur yang disematkan dalam pembelajaran mesin memiliki keunggulan tertentu dibandingkan metode filter dan pembungkus dengan menyertakan interaksi fitur dan juga mempertahankan biaya komputasi yang wajar. Teknik yang digunakan dalam metode tertanam adalah:
- Regularisasi: Overfitting data dihindari oleh model dengan menambahkan penalti ke parameter model. Koefisien ditambahkan dengan penalti yang menghasilkan beberapa koefisien menjadi nol. Oleh karena itu fitur-fitur yang memiliki koefisien nol dihapus dari kumpulan fitur. Pendekatan seleksi fitur menggunakan Lasso (regularisasi L1) dan jaring Elastis (regularisasi L1 dan L2).
- SMLR (Sparse Multinomial Logistic Regression): Algoritme menerapkan regularisasi sparse oleh ARD prior (Penentuan relevansi otomatis) untuk regresi logistik multinasional klasik. Regularisasi ini memperkirakan pentingnya setiap fitur dan memangkas dimensi yang tidak berguna untuk prediksi. Implementasi algoritma dilakukan di SMLR.
- ARD (Automatic Relevance Determination Regression): Algoritme akan menggeser bobot koefisien menuju nol dan didasarkan pada Regresi Bayesian Ridge. Algoritma tersebut dapat diimplementasikan dalam scikit-learn.
- Kepentingan Hutan Acak: Algoritme pemilihan fitur ini adalah agregasi dari sejumlah pohon tertentu. Strategi berbasis pohon dalam algoritme ini diurutkan berdasarkan peningkatan ketidakmurnian sebuah node atau penurunan ketidakmurnian (Gini impurity). Ujung pohon terdiri dari simpul dengan penurunan pengotor paling sedikit dan awal pohon terdiri dari simpul dengan penurunan pengotor terbesar. Oleh karena itu, fitur-fitur penting dapat dipilih melalui pemangkasan pohon di bawah simpul tertentu.
3. Metode filter
Metode diterapkan selama langkah-langkah pra-pemrosesan. Metodenya cukup cepat dan murah dan bekerja paling baik dalam menghilangkan fitur duplikat, berkorelasi, dan berlebihan. Alih-alih menerapkan metode pembelajaran yang diawasi, pentingnya fitur dievaluasi berdasarkan karakteristik yang melekat pada mereka. Biaya komputasi algoritma lebih rendah dibandingkan dengan metode pembungkus seleksi fitur. Namun, jika data yang cukup tidak ada untuk mendapatkan korelasi statistik antara fitur, hasilnya mungkin lebih buruk daripada metode pembungkus. Oleh karena itu, algoritme digunakan pada data berdimensi tinggi, yang akan menghasilkan biaya komputasi yang lebih tinggi jika metode pembungkus diterapkan.

Teknik yang digunakan dalam metode Filter adalah :
- Information Gain : Information gain mengacu pada seberapa banyak informasi yang diperoleh dari fitur untuk mengidentifikasi nilai target. Kemudian mengukur pengurangan nilai entropi. Perolehan informasi dari setiap atribut dihitung dengan mempertimbangkan nilai target untuk pemilihan fitur.
- Uji Chi-kuadrat : Metode Chi-kuadrat (X 2 ) umumnya digunakan untuk menguji hubungan antara dua variabel kategori. Tes ini digunakan untuk mengidentifikasi apakah ada perbedaan yang signifikan antara nilai yang diamati dari atribut yang berbeda dari dataset dengan nilai yang diharapkan. Hipotesis nol menyatakan bahwa tidak ada hubungan antara dua variabel.
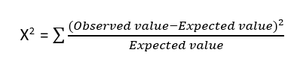
Sumber
Rumus untuk uji Chi-kuadrat
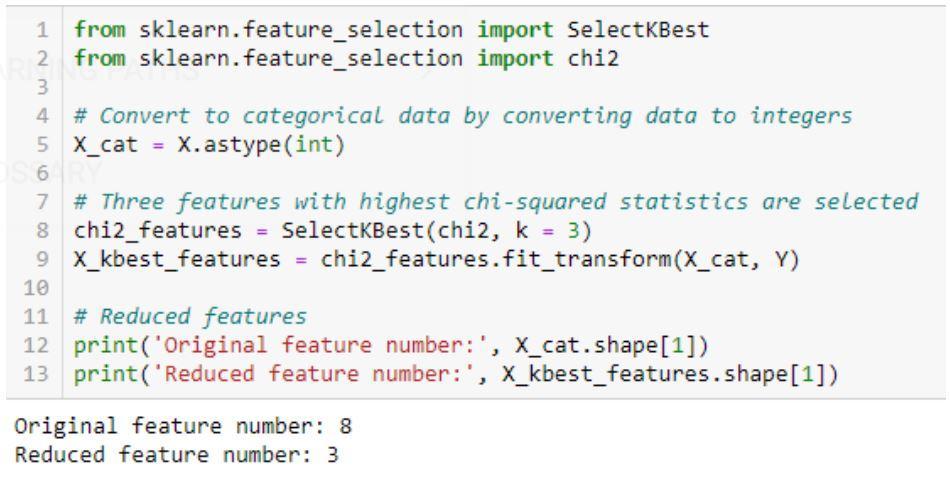
Implementasi algoritma Chi-Squared: sklearn, scipy
Contoh kode untuk uji Chi-kuadrat
Sumber
- CFS (Pemilihan fitur berbasis korelasi): Metode berikut “ Implementasi CFS (Pemilihan fitur berbasis korelasi): scikit-feature
Bergabunglah dengan Kursus AI & ML online dari Universitas top Dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
- FCBF (Filter berbasis korelasi cepat): Dibandingkan dengan metode Relief dan CFS yang disebutkan di atas, metode FCBF lebih cepat dan efisien. Awalnya, perhitungan Ketidakpastian Simetris dilakukan untuk semua fitur. Dengan menggunakan kriteria ini, fitur-fitur tersebut kemudian disortir dan fitur-fitur yang berlebihan dihapus.
Ketidakpastian Simetris= perolehan informasi dari x | y dibagi dengan jumlah entropi mereka. Implementasi FCBF: skfeature
- Skor Fischer: Jatah Fischer (FIR) didefinisikan sebagai jarak antara rata-rata sampel untuk setiap kelas per fitur dibagi dengan variansnya. Setiap fitur dipilih secara independen sesuai dengan skor mereka di bawah kriteria Fisher. Ini mengarah ke serangkaian fitur yang tidak optimal. Skor Fisher yang lebih besar menunjukkan fitur yang dipilih lebih baik.
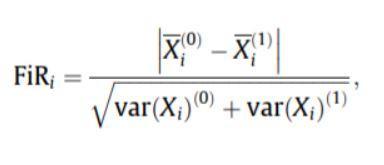
Sumber
Rumus untuk skor Fischer
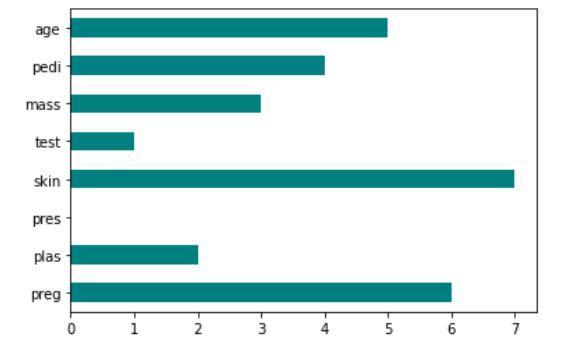
Implementasi skor Fisher: scikit-feature
Output dari kode yang menunjukkan teknik skor Fisher
Sumber
Koefisien Korelasi Pearson: Ini adalah ukuran untuk mengukur hubungan antara dua variabel kontinu. Nilai koefisien korelasi berkisar antara -1 sampai 1 yang menentukan arah hubungan antar variabel.
- Variance Threshold: Fitur yang variansnya tidak memenuhi ambang tertentu akan dihapus. Fitur yang memiliki varian nol dihilangkan melalui metode ini. Asumsi yang dipertimbangkan adalah bahwa fitur varians yang lebih tinggi cenderung mengandung lebih banyak informasi.
Gambar 15: Contoh kode yang menunjukkan penerapan ambang Variance
- Mean Absolute Difference (MAD): Metode menghitung mean absolute
selisih dari nilai rata-rata.
Contoh kode dan outputnya yang menunjukkan penerapan Mean Absolute Difference (MAD)
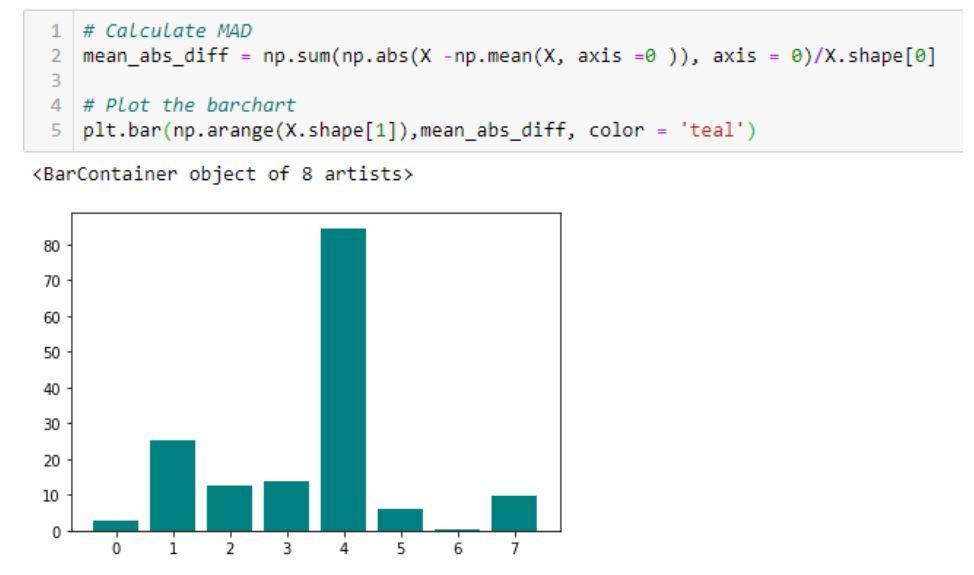
Sumber
- Rasio Dispersi: Rasio dispersi didefinisikan sebagai rasio mean Aritmatika (AM) dengan mean Geometrik (GM) untuk fitur tertentu. Nilainya berkisar dari +1 hingga sebagai AM GM untuk fitur tertentu.
Rasio dispersi yang lebih tinggi menyiratkan nilai Ri yang lebih tinggi dan oleh karena itu fitur yang lebih relevan. Sebaliknya, ketika Ri mendekati 1, ini menunjukkan fitur relevansi rendah.
- Saling Ketergantungan: Metode ini digunakan untuk mengukur ketergantungan timbal balik antara dua variabel. Informasi yang diperoleh dari satu variabel dapat digunakan untuk memperoleh informasi untuk variabel lainnya.
- Skor Laplacian: Data dari kelas yang sama seringkali berdekatan. Pentingnya suatu fitur dapat dinilai dari kekuatan pelestarian lokalitasnya. Skor Laplacian untuk setiap fitur dihitung. Nilai terkecil menentukan dimensi penting. Implementasi skor Laplacian: scikit-feature.
Kesimpulan
Pemilihan fitur dalam proses pembelajaran mesin dapat diringkas sebagai salah satu langkah penting menuju pengembangan model pembelajaran mesin apa pun. Proses algoritma seleksi fitur mengarah pada pengurangan dimensi data dengan menghilangkan fitur yang tidak relevan atau penting untuk model yang sedang dipertimbangkan. Fitur yang relevan dapat mempercepat waktu pelatihan model yang menghasilkan kinerja tinggi.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat Program PG Eksekutif IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT -B Status Alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Bagaimana metode filter berbeda dari metode pembungkus?
Metode wrapper membantu mengukur seberapa membantu fitur berdasarkan kinerja classifier. Metode filter, di sisi lain, menilai kualitas intrinsik fitur menggunakan statistik univariat daripada kinerja validasi silang, menyiratkan bahwa mereka menilai relevansi fitur. Akibatnya, metode pembungkus lebih efektif karena mengoptimalkan kinerja pengklasifikasi. Namun, karena proses pembelajaran yang berulang dan validasi silang, teknik wrapper secara komputasi lebih mahal daripada metode filter.
Apa yang dimaksud dengan Sequential Forward Selection dalam Machine Learning?
Ini semacam pemilihan fitur berurutan, meskipun jauh lebih mahal daripada pemilihan filter. Ini adalah teknik pencarian serakah yang secara iteratif memilih fitur berdasarkan kinerja pengklasifikasi untuk menemukan subset fitur yang ideal. Ini dimulai dengan subset fitur kosong dan terus menambahkan satu fitur di setiap putaran. Fitur yang satu ini dipilih dari kumpulan semua fitur yang tidak ada dalam subset fitur kami, dan fitur inilah yang menghasilkan performa pengklasifikasi terbaik saat digabungkan dengan fitur lainnya.
Apa batasan penggunaan metode filter untuk pemilihan fitur?
Pendekatan filter secara komputasi lebih murah daripada metode pemilihan fitur pembungkus dan tertanam, tetapi memiliki beberapa kelemahan. Dalam kasus pendekatan univariat, strategi ini sering mengabaikan interdependensi fitur saat memilih fitur dan mengevaluasi setiap fitur secara independen. Jika dibandingkan dengan dua metode pemilihan fitur lainnya, ini terkadang menghasilkan kinerja komputasi yang buruk.