
Primer GraphQL: Evolusi Desain API (Bagian 2)
Diterbitkan: 2022-03-10Di Bagian 1 kita melihat bagaimana API telah berevolusi selama beberapa dekade terakhir dan bagaimana masing-masing memberi jalan ke yang berikutnya. Kami juga berbicara tentang beberapa kelemahan khusus menggunakan REST untuk pengembangan klien seluler. Dalam artikel ini, saya ingin melihat ke mana arah desain API klien seluler — dengan penekanan khusus pada GraphQL.
Tentu saja, ada banyak orang, perusahaan, dan proyek yang telah mencoba mengatasi kekurangan REST selama bertahun-tahun: HAL, Swagger/OpenAPI, OData JSON API, dan lusinan proyek yang lebih kecil atau internal lainnya semuanya berusaha untuk menertibkan dunia REST tanpa spesifikasi. Daripada mengambil dunia apa adanya dan mengusulkan peningkatan bertahap, atau mencoba mengumpulkan cukup banyak bagian yang berbeda untuk membuat REST menjadi apa yang saya butuhkan, saya ingin mencoba eksperimen pemikiran. Mengingat pemahaman tentang teknik yang telah dan belum berhasil di masa lalu, saya ingin menggunakan batasan hari ini dan bahasa kami yang jauh lebih ekspresif untuk mencoba dan membuat sketsa API yang kami inginkan. Mari bekerja dari pengalaman pengembang ke belakang daripada implementasi ke depan (saya melihat Anda SQL).
Lalu Lintas HTTP Minimal
Kami tahu biaya setiap permintaan jaringan (HTTP/1) tinggi pada beberapa ukuran mulai dari latensi hingga masa pakai baterai. Idealnya, klien API baru kami akan membutuhkan cara untuk meminta semua data yang mereka butuhkan dalam perjalanan pulang pergi sesedikit mungkin.
Muatan Minimal
Kami juga tahu bahwa klien rata-rata dibatasi sumber daya, dalam bandwidth, CPU, dan memori, jadi tujuan kami seharusnya hanya mengirim informasi yang dibutuhkan klien kami. Untuk melakukan ini, kita mungkin memerlukan cara bagi klien untuk meminta potongan data tertentu.
Dapat Dibaca Manusia
Kami belajar dari hari-hari SOAP bahwa API tidak mudah untuk berinteraksi, orang akan meringis saat menyebutkannya. Tim teknik ingin menggunakan alat yang sama yang telah kami andalkan selama bertahun-tahun seperti curl , wget dan Charles serta tab jaringan browser kami.
Kaya Perkakas
Hal lain yang kami pelajari dari XML-RPC dan SOAP adalah bahwa kontrak klien/server dan sistem tipe, khususnya, sangat berguna. Jika memungkinkan, API baru apa pun akan memiliki format yang ringan seperti JSON atau YAML dengan kemampuan introspeksi kontrak yang lebih terstruktur dan aman untuk tipe.
Pelestarian Penalaran Lokal
Selama bertahun-tahun, kami telah menyepakati beberapa prinsip panduan tentang cara mengatur basis kode besar - yang utama adalah "pemisahan masalah". Sayangnya untuk sebagian besar proyek, ini cenderung rusak dalam bentuk lapisan akses data terpusat. Jika memungkinkan, bagian aplikasi yang berbeda harus memiliki opsi untuk mengelola kebutuhan datanya sendiri bersama dengan fungsi lainnya.
Karena kita sedang merancang API yang berpusat pada klien, mari kita mulai dengan tampilan mengambil data dalam API seperti ini. Jika kita tahu bahwa kita perlu melakukan perjalanan bolak-balik minimal dan bahwa kita harus dapat memfilter bidang yang tidak kita inginkan, kita memerlukan cara untuk melintasi kumpulan data yang besar dan hanya meminta bagian-bagiannya yang berguna bagi kami. Bahasa kueri sepertinya cocok di sini.
Kami tidak perlu mengajukan pertanyaan tentang data kami dengan cara yang sama seperti yang Anda lakukan dengan database, jadi bahasa imperatif seperti SQL sepertinya merupakan alat yang salah. Sebenarnya, tujuan utama kami adalah untuk melintasi hubungan yang sudah ada sebelumnya dan membatasi bidang yang seharusnya dapat kami lakukan dengan sesuatu yang relatif sederhana dan deklaratif. Industri ini telah menetapkan JSON untuk data non-biner dengan cukup baik, jadi mari kita mulai dengan bahasa kueri deklaratif seperti JSON. Kami harus dapat menjelaskan data yang kami butuhkan, dan server harus mengembalikan JSON yang berisi bidang tersebut.

Bahasa kueri deklaratif memenuhi persyaratan untuk muatan minimal dan lalu lintas HTTP minimal, tetapi ada manfaat lain yang akan membantu kami dengan tujuan desain kami yang lain. Banyak bahasa deklaratif, query dan lainnya, dapat dimanipulasi secara efisien seolah-olah mereka adalah data. Jika kami mendesain dengan hati-hati, bahasa kueri kami akan memungkinkan pengembang untuk memisahkan permintaan besar dan menggabungkannya kembali dengan cara apa pun yang masuk akal untuk proyek mereka. Menggunakan bahasa kueri seperti ini akan membantu kita bergerak menuju tujuan akhir Pelestarian Penalaran Lokal.
Ada banyak hal menarik yang dapat Anda lakukan setelah kueri Anda menjadi "data". Misalnya, Anda dapat mencegat semua permintaan dan mengelompokkannya mirip dengan cara DOM Virtual mengelompokkan pembaruan DOM, Anda juga dapat menggunakan kompiler untuk mengekstrak kueri kecil pada waktu pembuatan untuk melakukan pra-cache data atau Anda dapat membangun sistem cache yang canggih seperti Apollo Cache.
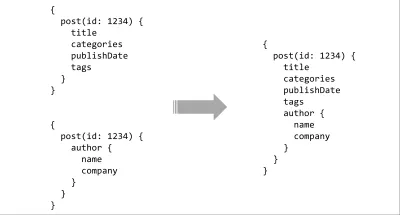
Item terakhir pada daftar keinginan API adalah perkakas. Kami sudah mendapatkan beberapa dari ini dengan menggunakan bahasa kueri, tetapi kekuatan sebenarnya datang ketika Anda memasangkannya dengan sistem tipe. Dengan skema yang diketik sederhana di server, ada kemungkinan hampir tak terbatas untuk perkakas yang kaya. Kueri dapat dianalisis dan divalidasi secara statis berdasarkan kontrak, integrasi IDE dapat memberikan petunjuk atau pelengkapan otomatis, kompiler dapat membuat pengoptimalan waktu pembuatan untuk kueri, atau beberapa skema dapat digabungkan untuk membentuk permukaan API yang berdekatan.

Merancang API yang memasangkan bahasa kueri dan sistem tipe mungkin terdengar seperti proposal yang dramatis tetapi orang telah bereksperimen dengan ini, dalam berbagai bentuk, selama bertahun-tahun. XML-RPC mendorong tanggapan yang diketik di pertengahan 90-an dan penggantinya, SOAP, mendominasi selama bertahun-tahun! Baru-baru ini, ada hal-hal seperti abstraksi MongoDB Meteor, Horizon RethinkDB (RIP), Falcor Netflix yang luar biasa yang telah mereka gunakan untuk Netflix.com selama bertahun-tahun dan terakhir ada GraphQL Facebook. Untuk sisa esai ini, saya akan fokus pada GraphQL karena, sementara proyek lain seperti Falcor melakukan hal serupa, mindshare komunitas tampaknya sangat mendukungnya.
Apa itu GraphQL?
Pertama, saya harus mengatakan bahwa saya berbohong sedikit. API yang kami buat di atas adalah GraphQL. GraphQL hanyalah sistem tipe untuk data Anda, bahasa kueri untuk melintasinya - sisanya hanyalah detail. Di GraphQL, Anda menggambarkan data Anda sebagai grafik interkoneksi, dan klien Anda meminta secara khusus subset data yang dibutuhkannya. Ada banyak pembicaraan dan tulisan tentang semua hal luar biasa yang dimungkinkan oleh GraphQL, tetapi konsep intinya sangat mudah diatur dan tidak rumit.
Untuk membuat konsep ini lebih konkret, dan untuk membantu mengilustrasikan bagaimana GraphQL mencoba mengatasi beberapa masalah di Bagian 1, sisa posting ini akan membangun API GraphQL yang dapat memberi daya pada blog di Bagian 1 dari seri ini. Sebelum masuk ke kode, ada beberapa hal tentang GraphQL yang perlu diingat.
GraphQL Adalah Spec (Bukan Implementasi)
GraphQL hanyalah sebuah spesifikasi. Ini mendefinisikan sistem tipe bersama dengan bahasa kueri sederhana, dan hanya itu. Hal pertama yang keluar dari ini adalah bahwa GraphQL tidak, dengan cara apa pun, terikat pada bahasa tertentu. Ada lebih dari dua lusin implementasi dalam segala hal mulai dari Haskell hingga C++ di mana JavaScript hanya satu. Tak lama setelah spesifikasi diumumkan, Facebook merilis implementasi referensi dalam JavaScript tetapi, karena mereka tidak menggunakannya secara internal, implementasi dalam bahasa seperti Go dan Clojure bisa menjadi lebih baik atau lebih cepat.
Spesifikasi GraphQL Tidak Menyebutkan Klien Atau Data
Jika Anda membaca spesifikasinya, Anda akan melihat bahwa ada dua hal yang tidak ada. Pertama, di luar bahasa kueri, tidak disebutkan tentang integrasi klien. Alat-alat seperti Apollo, Relay, Loka dan sejenisnya dimungkinkan karena desain GraphQL, tetapi mereka sama sekali bukan bagian dari atau diperlukan untuk menggunakannya. Kedua, tidak disebutkan tentang lapisan data tertentu. Server GraphQL yang sama dapat, dan sering kali, mengambil data dari kumpulan sumber yang heterogen. Itu dapat meminta data yang di-cache dari Redis, melakukan pencarian alamat dari USPS API dan memanggil layanan mikro berbasis protobuff dan klien tidak akan pernah tahu bedanya.
Pengungkapan Kompleksitas Progresif
GraphQL, bagi banyak orang, telah mencapai persimpangan kekuatan dan kesederhanaan yang langka. Itu melakukan pekerjaan yang fantastis untuk membuat hal-hal sederhana menjadi sederhana dan hal-hal sulit menjadi mungkin. Menjalankan server dan menyajikan data yang diketik melalui HTTP dapat berupa beberapa baris kode dalam hampir semua bahasa yang dapat Anda bayangkan.
Misalnya, server GraphQL dapat membungkus REST API yang ada, dan kliennya bisa mendapatkan data dengan permintaan GET reguler seperti halnya Anda berinteraksi dengan layanan lain. Anda dapat melihat demonya di sini. Atau, jika proyek memerlukan seperangkat alat yang lebih canggih, GraphQL dapat digunakan untuk melakukan hal-hal seperti autentikasi tingkat bidang, langganan pub/sub, atau kueri yang telah dikompilasi/cache.
Aplikasi Contoh
Tujuan dari contoh ini adalah untuk mendemonstrasikan kekuatan dan kesederhanaan GraphQL dalam ~70 baris JavaScript, bukan untuk menulis tutorial ekstensif. Saya tidak akan membahas terlalu banyak detail tentang sintaks dan semantik tetapi semua kode di sini dapat dijalankan, dan ada tautan ke versi proyek yang dapat diunduh di akhir artikel. Jika setelah melalui ini, Anda ingin menggali lebih dalam, saya memiliki koleksi sumber daya di blog saya yang akan membantu Anda membangun layanan yang lebih besar dan lebih kuat.
Untuk demo, saya akan menggunakan JavaScript, tetapi langkah-langkahnya sangat mirip dalam bahasa apa pun. Mari kita mulai dengan beberapa contoh data menggunakan Mocky.io yang menakjubkan.
Penulis
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }Postingan
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] Langkah pertama adalah membuat proyek baru dengan express dan middleware express-graphql .

bash npm init -y && npm install --save graphql express express-graphql Dan untuk membuat file index.js dengan server ekspres.
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); Untuk mulai bekerja dengan GraphQL, kita bisa mulai dengan memodelkan data di REST API. Dalam file baru bernama schema.js tambahkan berikut ini:
const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); Kode di atas memetakan tipe dalam respons JSON API kami ke tipe GraphQL. GraphQLObjectType sesuai dengan JavaScript Object , GraphQLString sesuai dengan JavaScript String dan seterusnya. Satu tipe khusus yang perlu diperhatikan adalah GraphQLSchema pada beberapa baris terakhir. GraphQLSchema adalah ekspor tingkat akar dari GraphQL — titik awal kueri untuk melintasi grafik. Dalam contoh dasar ini, kami hanya mendefinisikan query ; di sinilah Anda akan menentukan mutasi (tulisan) dan langganan.
Selanjutnya, kita akan menambahkan skema ke server ekspres kita di file index.js . Untuk melakukan ini, kami akan menambahkan middleware express-graphql dan meneruskannya ke skema.
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); Pada titik ini, meskipun kami tidak mengembalikan data apa pun, kami memiliki server GraphQL yang berfungsi yang menyediakan skemanya kepada klien. Untuk mempermudah memulai aplikasi, kami juga akan menambahkan skrip awal ke package.json .
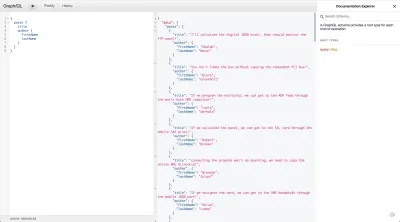
"scripts": { "start": "nodemon index.js" }, Menjalankan proyek dan membuka https://localhost:5000/ akan menampilkan penjelajah data bernama GraphiQL. GraphiQL akan dimuat secara default selama header HTTP Accept tidak disetel ke application/json . Memanggil URL yang sama ini dengan fetch atau cURL menggunakan application/json akan mengembalikan hasil JSON. Jangan ragu untuk bermain-main dengan dokumentasi bawaan dan menulis kueri.

Satu-satunya hal yang harus dilakukan untuk menyelesaikan server adalah mentransfer data yang mendasarinya ke dalam skema. Untuk melakukan ini, kita perlu mendefinisikan fungsi resolve . Di GraphQL, kueri dijalankan dari atas ke bawah memanggil fungsi resolve saat melintasi pohon. Misalnya, untuk kueri berikut:
query homepage { posts { title } } GraphQL pertama-tama akan memanggil posts.resolve(parentData) lalu posts.title.resolve(parentData) . Mari kita mulai dengan mendefinisikan resolver pada daftar posting blog kita.
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); Saya menggunakan paket isomorphic-fetch di sini untuk membuat permintaan HTTP karena ini menunjukkan dengan baik cara mengembalikan Janji dari resolver, tetapi Anda dapat menggunakan apa pun yang Anda suka. Fungsi ini akan mengembalikan larik Postingan ke tipe Blog. Fungsi penyelesaian default untuk implementasi JavaScript GraphQL adalah parentData.<fieldName> . Misalnya, resolver default untuk bidang nama Penulis adalah:
rawAuthorObject => rawAuthorObject.namePenyelesai penggantian tunggal ini harus menyediakan data untuk seluruh objek posting. Kami masih perlu mendefinisikan resolver untuk Penulis tetapi jika Anda menjalankan kueri untuk mengambil data yang diperlukan untuk beranda, Anda akan melihatnya berfungsi.
Karena atribut penulis di API posting kami hanyalah ID penulis, ketika GraphQL mencari Objek yang mendefinisikan nama dan perusahaan dan menemukan sebuah String, itu hanya akan mengembalikan null . Untuk memasang Author, kita perlu mengubah skema Postingan kita agar terlihat seperti berikut:
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });Sekarang, kami memiliki server GraphQL yang berfungsi penuh yang membungkus REST API. Sumber lengkap dapat diunduh dari tautan Github ini, atau dijalankan dari landasan peluncuran GraphQL ini.
Anda mungkin bertanya-tanya tentang perkakas yang perlu Anda gunakan untuk menggunakan titik akhir GraphQL seperti ini. Ada banyak pilihan seperti Relay dan Apollo tetapi untuk memulai, saya pikir pendekatan sederhana adalah yang terbaik. Jika Anda sering bermain-main dengan GraphiQL, Anda mungkin memperhatikan bahwa ia memiliki URL yang panjang. URL ini hanyalah versi enkode URI dari kueri Anda. Untuk membuat kueri GraphQL dalam JavaScript, Anda dapat melakukan sesuatu seperti ini:
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Atau, jika mau, Anda dapat menyalin tempel URL langsung dari GraphiQL seperti ini:
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepageKarena kami memiliki titik akhir GraphQL dan cara menggunakannya, kami dapat membandingkannya dengan RESTish API kami. Kode yang perlu kami tulis untuk mengambil data kami menggunakan RESTish API terlihat seperti ini:
Menggunakan API RESTish
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };Menggunakan API GraphQL
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Singkatnya, kami telah menggunakan GraphQL untuk:
- Kurangi sembilan permintaan (daftar posting, empat posting blog dan penulis setiap posting).
- Kurangi jumlah data yang dikirim dengan persentase yang signifikan.
- Gunakan alat pengembang yang luar biasa untuk membuat kueri kami.
- Tulis kode yang jauh lebih bersih di klien kami.
Cacat Di GraphQL
Sementara saya percaya hype dibenarkan, tidak ada peluru perak, dan sehebat GraphQL, itu bukan tanpa kekurangan.
Integritas data
GraphQL terkadang tampak seperti alat yang dibuat khusus untuk data yang baik. Ini sering berfungsi paling baik sebagai semacam gateway, menyatukan layanan yang berbeda atau tabel yang sangat dinormalisasi. Jika data yang kembali dari layanan yang Anda konsumsi berantakan dan tidak terstruktur, menambahkan jalur transformasi data di bawah GraphQL dapat menjadi tantangan nyata. Cakupan fungsi penyelesaian GraphQL hanya datanya sendiri dan data turunannya. Jika tugas orkestrasi memerlukan akses ke data di saudara atau induk di pohon, itu bisa sangat menantang.
Penanganan Kesalahan yang Kompleks
Permintaan GraphQL dapat menjalankan jumlah kueri yang berubah-ubah, dan setiap kueri dapat mencapai jumlah layanan yang berubah-ubah. Jika ada bagian dari permintaan yang gagal, alih-alih gagal seluruh permintaan, GraphQL, secara default, mengembalikan sebagian data. Data parsial kemungkinan merupakan pilihan yang tepat secara teknis, dan bisa sangat berguna dan efisien. Kekurangannya adalah penanganan kesalahan tidak lagi sesederhana memeriksa kode status HTTP. Perilaku ini dapat dimatikan, tetapi lebih sering daripada tidak, klien berakhir dengan kasus kesalahan yang lebih canggih.
Cache
Meskipun sering kali merupakan ide yang baik untuk menggunakan kueri GraphQL statis, untuk organisasi seperti Github yang mengizinkan kueri arbitrer, caching jaringan dengan alat standar seperti Varnish atau Fastly tidak lagi dapat dilakukan.
Biaya CPU Tinggi
Mengurai, memvalidasi, dan memeriksa jenis kueri adalah proses terikat CPU yang dapat menyebabkan masalah kinerja dalam bahasa utas tunggal seperti JavaScript.
Ini hanya masalah untuk evaluasi kueri runtime.
Pikiran Penutup
Fitur GraphQL bukanlah sebuah revolusi — beberapa di antaranya telah ada selama hampir 30 tahun. Apa yang membuat GraphQL kuat adalah bahwa tingkat pemolesan, integrasi, dan kemudahan penggunaan membuatnya lebih dari sekadar jumlah bagian-bagiannya.
Banyak hal yang diselesaikan GraphQL, dengan usaha dan disiplin, dapat dicapai dengan menggunakan REST atau RPC, tetapi GraphQL membawa API canggih ke sejumlah besar proyek yang mungkin tidak memiliki waktu, sumber daya, atau alat untuk melakukannya sendiri. Juga benar bahwa GraphQL bukan peluru perak, tetapi kekurangannya cenderung kecil dan dipahami dengan baik. Sebagai seseorang yang telah membangun server GraphQL yang cukup rumit, saya dapat dengan mudah mengatakan bahwa manfaatnya lebih besar daripada biayanya.
Esai ini difokuskan hampir seluruhnya pada mengapa GraphQL ada dan masalah yang dipecahkannya. Jika ini telah menggelitik minat Anda untuk mempelajari lebih lanjut tentang semantik dan cara menggunakannya, saya mendorong Anda untuk belajar dengan cara apa pun yang paling cocok untuk Anda apakah itu blog, youtube atau hanya membaca sumbernya (Cara GraphQL sangat bagus).
Jika Anda menikmati artikel ini (atau jika Anda membencinya) dan ingin memberi saya umpan balik, silakan temukan saya di Twitter sebagai @ebaerbaerbaer atau LinkedIn di ericjbaer.