
Keturunan Gradien dalam Pembelajaran Mesin: Bagaimana Cara Kerjanya?
Diterbitkan: 2021-01-28Daftar isi
pengantar
Salah satu bagian terpenting dari Machine Learning adalah optimalisasi algoritmenya. Hampir semua algoritme dalam Pembelajaran Mesin memiliki algoritme pengoptimalan di basisnya yang bertindak sebagai inti dari algoritme. Seperti yang kita semua tahu, pengoptimalan adalah tujuan akhir dari algoritma apa pun bahkan dengan peristiwa kehidupan nyata atau ketika berhadapan dengan produk berbasis teknologi di pasar.
Saat ini banyak sekali algoritma optimasi yang digunakan di beberapa aplikasi seperti face recognition, self-driving car, market-based analysis, dll. Begitu pula dalam Machine Learning, algoritma optimasi tersebut memegang peranan penting. Salah satu algoritma optimasi yang banyak digunakan adalah Algoritma Gradient Descent yang akan kita bahas dalam artikel ini.
Apa itu Gradient Descent?
Dalam Machine Learning, algoritma Gradient Descent adalah salah satu algoritma yang paling banyak digunakan, namun membuat kebanyakan pendatang baru tercengang. Secara matematis, Gradient Descent adalah algoritma optimasi iteratif orde pertama yang digunakan untuk mencari minimum lokal dari fungsi terdiferensiasi. Secara sederhana, algoritma Gradient Descent ini digunakan untuk mencari nilai parameter fungsi (atau koefisien) yang digunakan untuk meminimalkan fungsi biaya serendah mungkin. Fungsi biaya digunakan untuk mengukur kesalahan antara nilai yang diprediksi dan nilai sebenarnya dari model Pembelajaran Mesin yang dibangun.
Intuisi Keturunan Gradien
Pertimbangkan mangkuk besar yang biasanya Anda gunakan untuk menyimpan buah-buahan atau makan sereal. Mangkuk ini akan menjadi fungsi biaya (f).
Sekarang, koordinat acak pada setiap bagian permukaan mangkuk akan menjadi nilai koefisien fungsi biaya saat ini. Bagian bawah mangkuk adalah himpunan koefisien terbaik dan merupakan fungsi minimum.
Di sini, tujuannya adalah untuk menghitung nilai koefisien yang berbeda dengan setiap iterasi, mengevaluasi biaya dan memilih koefisien yang memiliki nilai fungsi biaya yang lebih baik (nilai yang lebih rendah). Pada beberapa iterasi, akan ditemukan bahwa bagian bawah mangkuk memiliki koefisien terbaik untuk meminimalkan fungsi biaya.

Dengan cara ini, algoritma Gradient Descent berfungsi untuk menghasilkan biaya minimum.
Bergabunglah dengan Kursus Pembelajaran Mesin online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
Prosedur Penurunan Gradien
Proses penurunan gradien ini dimulai dengan mengalokasikan nilai awalnya ke koefisien fungsi biaya. Ini bisa berupa nilai yang mendekati 0 atau nilai acak kecil.
koefisien = 0,0
Selanjutnya, biaya koefisien diperoleh dengan menerapkannya pada fungsi biaya dan menghitung biayanya.
biaya = f(koefisien)
Kemudian, turunan dari fungsi biaya dihitung. Turunan dari fungsi biaya ini diperoleh dengan konsep matematika kalkulus diferensial. Ini memberi kita kemiringan fungsi pada titik tertentu di mana turunannya dihitung. Kemiringan ini diperlukan untuk mengetahui ke arah mana koefisien akan dipindahkan pada iterasi berikutnya untuk mendapatkan nilai biaya yang lebih rendah. Hal ini dilakukan dengan mengamati tanda turunan yang dihitung.
delta = turunan(biaya)
Setelah kita mengetahui arah mana yang menurun dari turunan yang dihitung, kita perlu memperbarui nilai koefisien. Untuk ini, parameter dikenal sebagai parameter pembelajaran, alpha (α) digunakan. Ini digunakan untuk mengontrol sejauh mana koefisien dapat berubah dengan setiap pembaruan.
koefisien = koefisien – (alfa * delta)
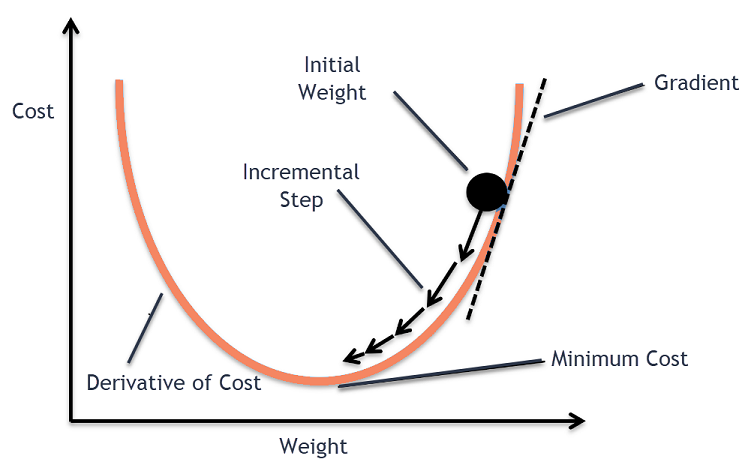
Sumber
Dengan cara ini, proses ini diulang sampai biaya koefisien sama dengan 0,0 atau cukup dekat dengan nol. Ini adalah prosedur untuk algoritma penurunan gradien.
Jenis-Jenis Algoritma Penurunan Gradien
Di zaman modern, ada tiga tipe dasar Gradient Descent yang digunakan dalam pembelajaran mesin modern dan algoritma pembelajaran mendalam. Perbedaan utama antara masing-masing dari 3 jenis ini adalah biaya komputasi dan efisiensinya. Tergantung pada jumlah data yang digunakan, kompleksitas waktu, dan akurasi, berikut ini adalah tiga jenisnya.
- Keturunan Gradien Batch
- Penurunan Gradien Stokastik
- Keturunan Gradien Batch Mini
Keturunan Gradien Batch
Ini adalah versi pertama dan dasar dari algoritma Gradient Descent di mana seluruh dataset digunakan sekaligus untuk menghitung fungsi biaya dan gradiennya. Karena seluruh kumpulan data digunakan dalam sekali jalan untuk satu pembaruan, penghitungan gradien dalam jenis ini bisa sangat lambat dan tidak mungkin dilakukan dengan kumpulan data yang berada di luar kapasitas memori perangkat.
Jadi, algoritma Batch Gradient Descent ini hanya digunakan untuk kumpulan data yang lebih kecil dan ketika jumlah contoh pelatihan banyak, batch gradient descent tidak disukai. Sebagai gantinya, algoritma Stochastic dan Mini Batch Gradient Descent digunakan.
Penurunan Gradien Stokastik
Ini adalah jenis lain dari algoritma penurunan gradien di mana hanya satu contoh pelatihan yang diproses per iterasi. Dalam hal ini, langkah pertama adalah mengacak seluruh dataset pelatihan. Kemudian, hanya satu contoh pelatihan yang digunakan untuk memperbarui koefisien. Ini berbeda dengan Batch Gradient Descent di mana parameter (koefisien) diperbarui hanya ketika semua contoh pelatihan dievaluasi.

Stochastic Gradient Descent (SGD) memiliki keuntungan bahwa jenis pembaruan yang sering ini memberikan tingkat peningkatan yang terperinci. Namun, dalam kasus tertentu, ini mungkin menjadi mahal secara komputasi karena hanya memproses satu contoh setiap iterasi yang dapat menyebabkan jumlah iterasi menjadi sangat besar.
Keturunan Gradien Batch Mini
Ini adalah algoritma yang dikembangkan baru-baru ini yang lebih cepat daripada algoritma Batch dan Stochastic Gradient Descent. Ini sebagian besar lebih disukai karena merupakan kombinasi dari kedua algoritma yang disebutkan sebelumnya. Dalam hal ini, ia memisahkan set pelatihan menjadi beberapa batch mini dan melakukan pembaruan untuk masing-masing batch ini setelah menghitung gradien batch tersebut (seperti dalam SGD).
Umumnya, ukuran batch bervariasi antara 30 hingga 500 tetapi tidak ada ukuran tetap karena bervariasi untuk aplikasi yang berbeda. Oleh karena itu, bahkan jika ada kumpulan data pelatihan yang sangat besar, algoritma ini memprosesnya dalam batch mini 'b'. Dengan demikian, sangat cocok untuk kumpulan data besar dengan jumlah iterasi yang lebih sedikit.
Jika 'm' adalah jumlah contoh pelatihan, maka jika b==m Mini Batch Gradient Descent akan mirip dengan algoritma Batch Gradient Descent.
Varian Keturunan Gradien dalam Pembelajaran Mesin
Dengan dasar Gradient Descent ini, ada beberapa algoritma lain yang dikembangkan dari ini. Beberapa di antaranya dirangkum di bawah ini.
Keturunan Gradien Vanila
Ini adalah salah satu bentuk paling sederhana dari Teknik Keturunan Gradien. Nama vanilla berarti murni atau tanpa pemalsuan apapun. Dalam hal ini, langkah-langkah kecil diambil ke arah minima dengan menghitung gradien fungsi biaya. Mirip dengan algoritma yang disebutkan di atas, aturan pembaruan diberikan oleh,
koefisien = koefisien – (alfa * delta)
Penurunan Gradien dengan Momentum
Dalam hal ini, algoritmanya sedemikian rupa sehingga kita mengetahui langkah-langkah sebelumnya sebelum mengambil langkah berikutnya. Ini dilakukan dengan memperkenalkan istilah baru yang merupakan produk dari pembaruan sebelumnya dan konstanta yang dikenal sebagai momentum. Dalam hal ini, aturan pembaruan bobot diberikan oleh,
pembaruan = alfa * delta
kecepatan = pembaruan_sebelumnya * momentum
koefisien = koefisien + kecepatan – pembaruan
ADGRAD
Istilah ADAGRAD adalah singkatan dari Adaptive Gradient Algorithm. Seperti namanya, ia menggunakan teknik adaptif untuk memperbarui bobot. Algoritma ini lebih cocok untuk data yang jarang. Pengoptimalan ini mengubah kecepatan pembelajarannya sehubungan dengan frekuensi pembaruan parameter selama pelatihan. Misalnya, parameter yang memiliki gradien lebih tinggi dibuat memiliki kecepatan belajar yang lebih lambat sehingga kita tidak akan melampaui nilai minimum. Demikian pula, gradien yang lebih rendah memiliki tingkat pembelajaran yang lebih cepat untuk dilatih lebih cepat.
ADAM
Namun algoritma optimasi adaptif lain yang berakar pada algoritma Gradient Descent adalah ADAM yang merupakan singkatan dari Adaptive Moment Estimation. Ini adalah kombinasi dari ADAGRAD dan SGD dengan algoritma Momentum. Itu dibangun dari algoritma ADAGRAD dan dibangun lebih jauh ke bawah. Secara sederhana ADAM = ADAGRAD + Momentum.
Dengan cara ini, ada beberapa varian lain dari Gradient Descent Algorithms yang telah dikembangkan dan sedang dikembangkan di dunia seperti AMSGrad, ADAMax.
Kesimpulan
Pada artikel ini, kita telah melihat algoritma di balik salah satu algoritma optimasi yang paling umum digunakan dalam Machine Learning, yaitu Algoritma Gradient Descent beserta jenis dan variannya yang telah dikembangkan.
upGrad menyediakan Program PG Eksekutif dalam Pembelajaran Mesin & AI dan Magister Sains dalam Pembelajaran Mesin & AI yang dapat memandu Anda dalam membangun karier. Kursus-kursus ini akan menjelaskan perlunya Pembelajaran Mesin dan langkah-langkah lebih lanjut untuk mengumpulkan pengetahuan dalam domain ini yang mencakup beragam konsep mulai dari Gradient Descent dalam Machine Learning.
Dimana Gradient Descent Algorithm dapat berkontribusi secara maksimal?
Pengoptimalan dalam algoritme pembelajaran mesin apa pun bersifat inkremental untuk kemurnian algoritme. Gradient Descent Algorithm membantu meminimalkan kesalahan fungsi biaya dan meningkatkan parameter algoritme. Meskipun algoritma Gradient Descent digunakan secara luas dalam Machine Learning dan Deep Learning, efektivitasnya dapat ditentukan oleh jumlah data, jumlah iterasi dan akurasi yang disukai, dan jumlah waktu yang tersedia. Untuk kumpulan data skala kecil, Batch Gradient Descent adalah optimal. Stochastic Gradient Descent (SGD) terbukti lebih efisien untuk set data yang lebih detail dan ekstensif. Sebaliknya, Mini Batch Gradient Descent digunakan untuk pengoptimalan yang lebih cepat.
Apa saja tantangan yang dihadapi dalam gradient descent?
Gradient Descent lebih disukai untuk mengoptimalkan model pembelajaran mesin untuk mengurangi fungsi biaya. Namun, ia juga memiliki kekurangan. Misalkan Gradien berkurang karena fungsi output minimum dari lapisan model. Dalam hal ini, iterasi tidak akan seefektif model tidak akan melatih ulang sepenuhnya, memperbarui bobot dan biasnya. Terkadang gradien kesalahan mengakumulasi banyak bobot dan bias untuk menjaga iterasi tetap diperbarui. Namun, gradien ini menjadi terlalu besar untuk dikelola dan disebut gradien meledak. Persyaratan infrastruktur, keseimbangan tingkat pembelajaran, momentum perlu ditangani.
Apakah penurunan gradien selalu konvergen?
Konvergensi adalah ketika algoritma penurunan gradien berhasil meminimalkan fungsi biayanya ke tingkat yang optimal. Gradient Descent Algorithm mencoba meminimalkan cost function melalui parameter-parameter algoritma. Namun, ia dapat mendarat di salah satu titik optimal dan belum tentu titik yang memiliki titik optimal global atau lokal. Salah satu alasan untuk tidak memiliki konvergensi yang optimal adalah ukuran langkah. Ukuran langkah yang lebih signifikan menghasilkan lebih banyak osilasi dan mungkin menyimpang dari optimal global. Oleh karena itu, penurunan gradien mungkin tidak selalu menyatu pada fitur terbaik, tetapi tetap berada pada titik fitur terdekat.