
Penurunan Gradien dalam Regresi Logistik [Dijelaskan untuk Pemula]
Diterbitkan: 2021-01-08Pada artikel ini, kita akan membahas Algoritma Gradient Descent yang sangat populer dalam Regresi Logistik. Kita akan melihat apa itu Regresi Logistik, kemudian secara bertahap beralih ke Persamaan untuk Regresi Logistik, Fungsi Biayanya, dan akhirnya Algoritma Gradien Descent.
Daftar isi
Apa itu Regresi Logistik?
Regresi Logistik hanyalah algoritme klasifikasi yang digunakan untuk memprediksi kategori diskrit, seperti memprediksi apakah email adalah 'spam' atau 'bukan spam'; memprediksi apakah angka yang diberikan adalah '9' atau 'bukan 9' dll. Sekarang, dengan melihat namanya, Anda pasti berpikir, mengapa dinamai Regresi?
Pasalnya, ide Regresi Logistik dikembangkan dengan mengutak-atik beberapa elemen dasar Algoritma Regresi Linier yang digunakan dalam masalah regresi.
Regresi Logistik juga dapat diterapkan pada masalah klasifikasi Multi-Class (lebih dari dua kelas). Meskipun, disarankan untuk menggunakan algoritma ini hanya untuk Masalah Klasifikasi Biner.
Fungsi Sigmoid
Masalah klasifikasi bukan masalah Fungsi Linier. Keluaran dibatasi pada nilai diskrit tertentu, misalnya 0 dan 1 untuk masalah klasifikasi biner. Tidak masuk akal bagi fungsi linier untuk memprediksi nilai keluaran kita lebih besar dari 1, atau lebih kecil dari 0. Jadi kita memerlukan fungsi yang tepat untuk mewakili nilai keluaran kita.
Fungsi Sigmoid memecahkan masalah kita. Juga dikenal sebagai Fungsi Logistik, ini adalah fungsi berbentuk S yang memetakan bilangan real apa pun ke interval (0,1), membuatnya sangat berguna dalam mengubah fungsi acak apa pun menjadi fungsi berbasis klasifikasi. Fungsi Sigmoid terlihat seperti ini:

Fungsi Sigmoid
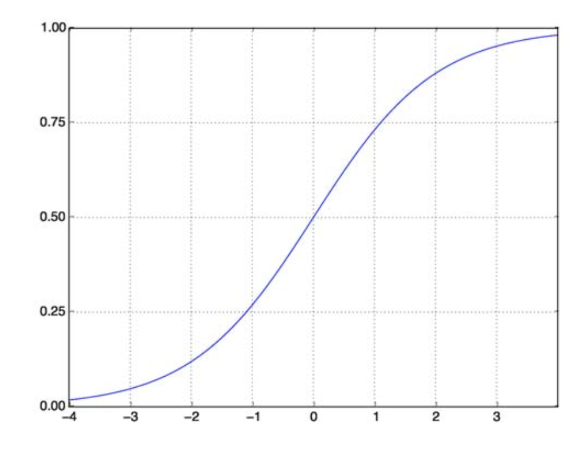
sumber
Sekarang bentuk matematis dari fungsi sigmoid untuk vektor berparameter dan vektor input X adalah:
(z) = 11+exp(-z) di mana z = TX
(z) akan memberi kita probabilitas bahwa outputnya adalah 1. Seperti yang kita ketahui bersama, nilai probabilitas berkisar dari 0 hingga 1. Sekarang, ini bukan output yang kita inginkan untuk masalah klasifikasi berbasis diskrit (0 dan 1 saja) kita . Jadi sekarang kita dapat membandingkan probabilitas yang diprediksi dengan 0,5. Jika probabilitas > 0,5, kita memiliki y=1. Demikian pula, jika probabilitasnya < 0,5, kita memiliki y=0.
Fungsi Biaya
Sekarang setelah kita memiliki prediksi terpisah, sekarang saatnya untuk memeriksa apakah prediksi kita memang benar atau tidak. Untuk melakukan itu, kami memiliki Fungsi Biaya. Fungsi Biaya hanyalah penjumlahan dari semua kesalahan yang dibuat dalam prediksi di seluruh kumpulan data. Tentu saja, kita tidak dapat menggunakan Fungsi Biaya yang digunakan dalam Regresi Linier. Jadi Fungsi Biaya baru untuk Regresi Logistik adalah:
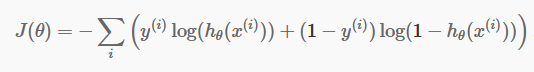 sumber
sumber
Jangan takut dengan persamaan. Hal ini sangat sederhana. Untuk setiap iterasi i , itu menghitung kesalahan yang kami buat dalam prediksi kami, dan kemudian menambahkan semua kesalahan untuk mendefinisikan Fungsi Biaya J() kami.
Dua suku di dalam kurung sebenarnya untuk dua kasus: y=0 dan y=1. Ketika y=0, suku pertama hilang, dan yang tersisa hanya suku kedua. Demikian pula, ketika y=1, suku kedua hilang, dan yang tersisa hanya suku pertama.
Algoritma Keturunan Gradien
Kami telah berhasil menghitung Fungsi Biaya kami. Tapi kita perlu meminimalkan kerugian untuk membuat algoritma prediksi yang baik. Untuk melakukan itu, kita memiliki Gradient Descent Algorithm.
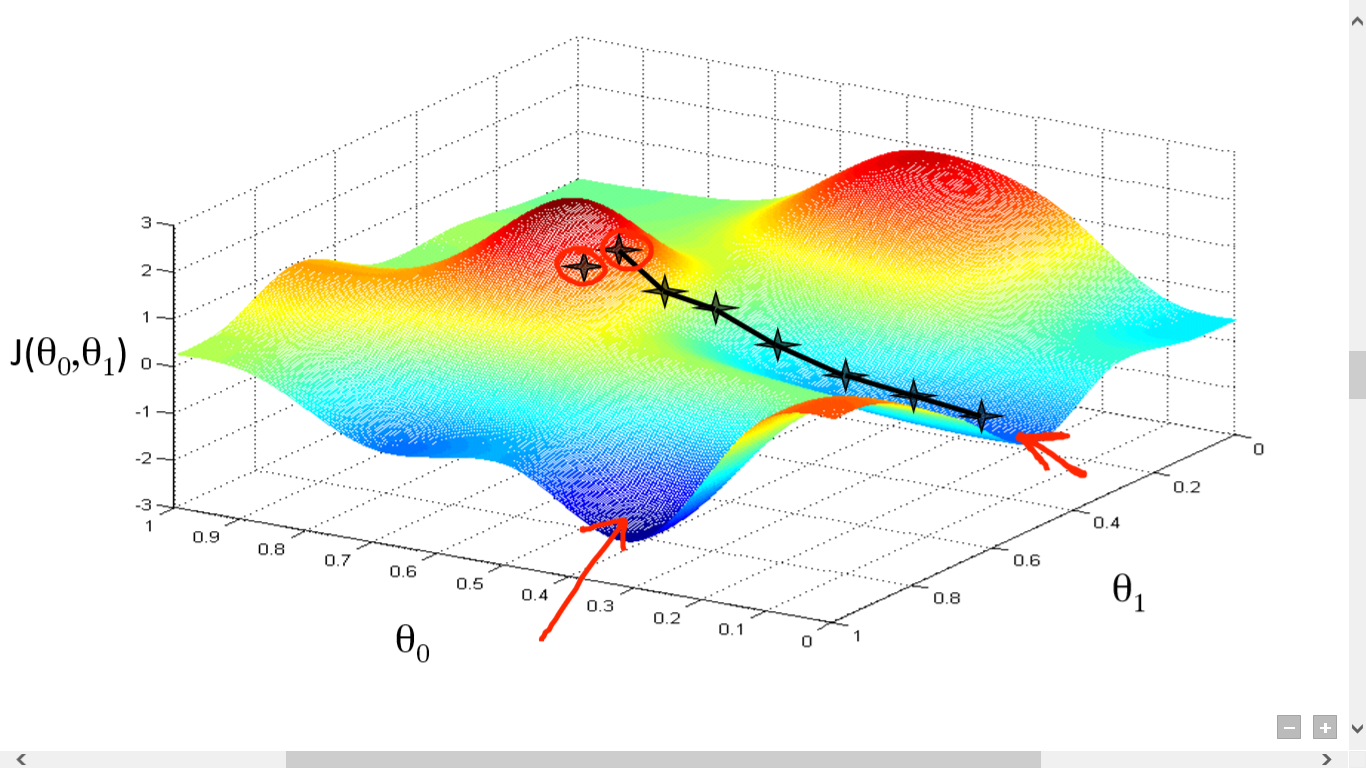 sumber
sumber
Di sini kita telah memplot grafik antara J() dan . Tujuan kami adalah menemukan titik terdalam (global minimum) dari fungsi ini. Sekarang titik terdalam adalah di mana J() adalah minimum.
Dua hal yang diperlukan untuk menemukan titik terdalam:
- Derivatif – untuk menemukan arah langkah selanjutnya.
- (Laju Pembelajaran) – besarnya langkah selanjutnya
Idenya adalah Anda pertama-tama memilih titik acak dari fungsi tersebut. Maka Anda perlu menghitung turunan dari J()wrt . Ini akan menunjuk ke arah minimum lokal. Sekarang kalikan gradien yang dihasilkan dengan Learning Rate. Tingkat Pembelajaran tidak memiliki nilai tetap, dan harus diputuskan berdasarkan masalah.
Sekarang, Anda perlu mengurangi hasilnya untuk mendapatkan file .
Pembaruan ini harus dilakukan secara bersamaan untuk setiap (i) .
Lakukan langkah-langkah ini berulang kali hingga Anda mencapai minimum lokal atau global. Dengan mencapai minimum global, Anda telah mencapai kerugian serendah mungkin dalam prediksi Anda.
Mengambil turunan itu sederhana. Hanya kalkulus dasar yang harus Anda lakukan di sekolah menengah Anda sudah cukup. Masalah utama adalah dengan Learning Rate(). Mengambil tingkat belajar yang baik adalah penting dan seringkali sulit.
Jika Anda mengambil kecepatan belajar yang sangat kecil, setiap langkah akan menjadi terlalu kecil, dan karenanya Anda akan menghabiskan banyak waktu untuk mencapai minimum lokal.
Sekarang, jika Anda cenderung mengambil nilai kecepatan belajar yang besar, Anda akan melampaui batas minimum dan tidak akan pernah bertemu lagi. Tidak ada aturan khusus untuk kecepatan belajar yang sempurna.

Anda perlu mengubahnya untuk menyiapkan model terbaik.
Persamaan untuk Gradient Descent adalah:
Ulangi sampai konvergen:
Jadi kita dapat meringkas Algoritma Gradient Descent sebagai:
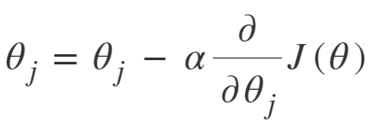
- Mulai dengan acak
- Ulangi sampai konvergensi:
- Hitung Gradien
- Memperbarui
- Kembali
Algoritma Penurunan Gradien Stokastik
Sekarang, Gradient Descent Algorithm adalah algoritma yang bagus untuk meminimalkan Cost Function, terutama untuk data kecil hingga menengah. Tetapi ketika kita harus berurusan dengan kumpulan data yang lebih besar, Algoritma Gradient Descent ternyata lambat dalam komputasi. Alasannya sederhana: perlu menghitung gradien, dan memperbarui nilai secara bersamaan untuk setiap parameter, dan itu juga untuk setiap contoh pelatihan.
Jadi pikirkan tentang semua perhitungan itu! Ini sangat besar, dan karenanya ada kebutuhan untuk Algoritma Gradient Descent yang sedikit dimodifikasi, yaitu – Stochastic Gradient Descent Algorithm (SGD).
Satu-satunya perbedaan yang dimiliki SGD dengan Normal Gradient Descent adalah bahwa, dalam SGD, kita tidak menangani seluruh instance pelatihan pada satu waktu. Dalam SGD, kami menghitung gradien fungsi biaya hanya untuk satu contoh acak pada setiap iterasi.
Sekarang, melakukan hal itu mengurangi waktu yang dibutuhkan untuk perhitungan dengan margin yang sangat besar terutama untuk kumpulan data yang besar. Jalur yang ditempuh oleh SGD sangat serampangan dan bising (walaupun jalur yang bising dapat memberikan kita kesempatan untuk mencapai global minima).
Tapi tidak apa-apa, karena kita tidak perlu khawatir dengan jalur yang diambil.
Kita hanya perlu mencapai kerugian minimal pada waktu yang lebih cepat.
Jadi kita dapat meringkas Algoritma Gradient Descent sebagai:
- Ulangi sampai konvergensi:
- Pilih titik data tunggal ' i'
- Hitung Gradien di atas satu titik itu
- Memperbarui
- Kembali
Algoritma Penurunan Gradien Batch Mini
Mini-Batch Gradient Descent adalah sedikit modifikasi lain dari Gradient Descent Algorithm. Itu agak di antara Keturunan Gradien Normal dan Keturunan Gradien Stokastik.
Mini-Batch Gradient Descent hanya mengambil batch yang lebih kecil dari seluruh dataset, dan kemudian meminimalkan kerugian di dalamnya.
Proses ini lebih efisien daripada kedua Algoritma Gradient Descent di atas. Sekarang ukuran batch tentu saja bisa apa saja yang Anda inginkan.
Tetapi para peneliti telah menunjukkan bahwa lebih baik jika Anda menyimpannya dalam 1 hingga 100, dengan 32 menjadi ukuran batch terbaik.
Oleh karena itu ukuran batch = 32 tetap default di sebagian besar kerangka kerja.
- Ulangi sampai konvergensi:
- Pilih sekumpulan titik data ' b '
- Hitung Gradien di atas batch itu
- Memperbarui
- Kembali
Kesimpulan
Sekarang Anda memiliki pemahaman teoretis tentang Regresi Logistik. Anda telah belajar bagaimana merepresentasikan fungsi logistik secara matematis. Anda tahu bagaimana mengukur kesalahan yang diprediksi menggunakan Fungsi Biaya.
Anda juga tahu bagaimana Anda dapat meminimalkan kerugian ini menggunakan Gradient Descent Algorithm.
Akhirnya, Anda tahu variasi Algoritma Keturunan Gradien mana yang harus Anda pilih untuk masalah Anda. upGrad memberikan Diploma PG dalam Pembelajaran Mesin dan AI dan Magister Sains dalam Pembelajaran Mesin & AI yang dapat memandu Anda dalam membangun karier. Kursus-kursus ini akan menjelaskan perlunya Pembelajaran Mesin dan langkah-langkah lebih lanjut untuk mengumpulkan pengetahuan dalam domain ini yang mencakup beragam konsep mulai dari algoritme penurunan gradien hingga Neural Networks.
Apa itu algoritma penurunan gradien?
Gradient descent adalah algoritma optimasi untuk mencari minimum suatu fungsi. Misalkan Anda ingin mencari fungsi minimum f(x) antara dua titik (a, b) dan (c, d) pada grafik y = f(x). Kemudian penurunan gradien melibatkan tiga langkah: (1) memilih titik di tengah antara dua titik akhir, (2) menghitung gradien f(x) (3) bergerak ke arah yang berlawanan dengan gradien, yaitu dari (c, d) ke (a, b). Cara untuk memikirkan hal ini adalah bahwa algoritme menemukan kemiringan fungsi pada suatu titik dan kemudian bergerak ke arah yang berlawanan dengan kemiringan tersebut.
Apa itu fungsi sigmoid?
Fungsi sigmoid, atau kurva sigmoid, adalah jenis fungsi matematika yang tidak linier dan bentuknya sangat mirip dengan huruf S (oleh karena itu namanya). Ini digunakan dalam riset operasi, statistik, dan disiplin lain untuk memodelkan bentuk-bentuk tertentu dari pertumbuhan bernilai nyata. Ini juga digunakan dalam berbagai aplikasi dalam ilmu komputer dan teknik, terutama di bidang yang terkait dengan jaringan saraf dan kecerdasan buatan. Fungsi sigmoid digunakan sebagai bagian dari input untuk memperkuat algoritma pembelajaran, yang didasarkan pada jaringan saraf tiruan.
Apa itu Stochastic Gradient Descent Algorithm?
Stochastic Gradient Descent adalah salah satu variasi populer dari algoritma Gradient Descent klasik untuk menemukan minimum lokal dari fungsi tersebut. Algoritme secara acak memilih arah di mana fungsi akan pergi berikutnya untuk meminimalkan nilai dan arah diulang sampai minimum lokal tercapai. Tujuannya adalah dengan mengulangi proses ini secara terus menerus, algoritme akan konvergen ke minimum global atau lokal dari fungsi tersebut.