
Tes Serpihan: Menyingkirkan Mimpi Buruk Yang Hidup Dalam Pengujian
Diterbitkan: 2022-03-10Ada sebuah dongeng yang banyak saya pikirkan akhir-akhir ini. Fabel itu diceritakan kepada saya sebagai seorang anak. Ini disebut "Anak Laki-Laki Yang Menangis Serigala" oleh Aesop. Ini tentang seorang anak laki-laki yang menggembalakan domba di desanya. Dia bosan dan berpura-pura bahwa serigala menyerang kawanan, memanggil penduduk desa untuk membantu - hanya bagi mereka untuk kecewa menyadari bahwa itu adalah alarm palsu dan meninggalkan anak itu sendirian. Kemudian, ketika serigala benar-benar muncul dan anak laki-laki itu meminta bantuan, penduduk desa percaya itu adalah alarm palsu lain dan tidak datang untuk menyelamatkan, dan domba akhirnya dimakan oleh serigala.
Moral dari cerita ini paling baik diringkas oleh penulisnya sendiri:
"Seorang pembohong tidak akan dipercaya, bahkan ketika dia mengatakan yang sebenarnya."
Seekor serigala menyerang domba, dan anak laki-laki itu berteriak minta tolong, tetapi setelah banyak kebohongan, tidak ada yang percaya padanya lagi. Moral ini dapat diterapkan untuk pengujian: Kisah Aesop adalah alegori yang bagus untuk pola yang cocok yang saya temukan: tes tidak stabil yang gagal memberikan nilai apa pun.
Pengujian Front-End: Mengapa Harus Mengganggu?
Sebagian besar hari saya dihabiskan untuk pengujian front-end. Jadi seharusnya tidak mengejutkan Anda bahwa contoh kode dalam artikel ini sebagian besar berasal dari tes front-end yang saya temukan dalam pekerjaan saya. Namun, dalam banyak kasus, mereka dapat dengan mudah diterjemahkan ke bahasa lain dan diterapkan ke kerangka kerja lain. Jadi, saya harap artikel ini bermanfaat bagi Anda — keahlian apa pun yang Anda miliki.
Perlu diingat apa artinya pengujian front-end. Pada intinya, pengujian front-end adalah serangkaian praktik untuk menguji UI aplikasi web, termasuk fungsinya.
Memulai sebagai insinyur penjaminan kualitas, saya tahu sakitnya pengujian manual tanpa akhir dari daftar periksa tepat sebelum rilis. Jadi, selain tujuan untuk memastikan bahwa aplikasi tetap bebas dari kesalahan selama pembaruan berturut-turut, saya berusaha untuk meringankan beban kerja pengujian yang disebabkan oleh tugas-tugas rutin yang sebenarnya tidak membutuhkan manusia. Sekarang, sebagai pengembang, saya menemukan topik ini masih relevan, terutama karena saya mencoba membantu pengguna dan rekan kerja secara langsung. Dan ada satu masalah dengan pengujian khususnya yang telah memberi kita mimpi buruk.
Ilmu Tes Terkelupas
Tes serpihan adalah tes yang gagal menghasilkan hasil yang sama setiap kali analisis yang sama dijalankan. Bangunan hanya akan gagal sesekali: Satu kali akan berlalu, lain kali gagal, waktu berikutnya berlalu lagi, tanpa ada perubahan apa pun pada bangunan yang telah dibuat.
Ketika saya mengingat mimpi buruk pengujian saya, satu kasus khusus muncul di pikiran saya. Itu dalam tes UI. Kami membuat kotak kombo bergaya khusus (yaitu daftar yang dapat dipilih dengan bidang input):
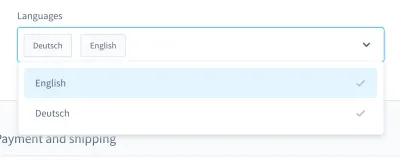
Dengan kotak kombo ini, Anda dapat mencari produk dan memilih satu atau beberapa hasil. Berhari-hari, tes ini berjalan dengan baik, tetapi pada titik tertentu, segalanya berubah. Di salah satu dari sekitar sepuluh build dalam sistem continuous integration (CI) kami, pengujian untuk mencari dan memilih produk dalam kotak kombo ini gagal.
Tangkapan layar dari kegagalan menunjukkan daftar hasil yang tidak difilter, meskipun pencarian telah berhasil:
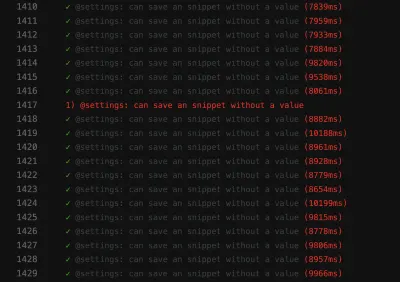
Tes yang tidak stabil seperti ini dapat memblokir pipeline penerapan berkelanjutan , membuat pengiriman fitur lebih lambat dari yang seharusnya. Selain itu, uji serpihan bermasalah karena tidak deterministik lagi — membuatnya tidak berguna. Lagi pula, Anda tidak akan mempercayai seseorang seperti Anda mempercayai pembohong.
Selain itu, tes terkelupas mahal untuk diperbaiki , seringkali membutuhkan berjam-jam atau bahkan berhari-hari untuk men-debug. Meskipun pengujian ujung-ke-ujung lebih rentan terhadap serpihan, saya telah mengalaminya dalam semua jenis pengujian: pengujian unit, pengujian fungsional, pengujian ujung-ke-ujung, dan segala sesuatu di antaranya.
Masalah signifikan lainnya dengan tes yang tidak stabil adalah sikap yang mereka berikan kepada kami para pengembang. Ketika saya mulai bekerja dalam otomatisasi pengujian, saya sering mendengar pengembang mengatakan ini sebagai tanggapan atas pengujian yang gagal:
“Ahh, bangunan itu. Tidak apa-apa, mulai saja lagi. Pada akhirnya akan berlalu, suatu saat nanti.”
Ini adalah bendera merah besar bagi saya . Ini menunjukkan kepada saya bahwa kesalahan dalam pembuatan tidak akan dianggap serius. Ada asumsi bahwa tes yang tidak stabil bukanlah bug yang sebenarnya, tetapi “hanya” tidak stabil, tanpa perlu diurus atau bahkan di-debug. Toh nanti ujiannya lulus lagi, kan? Tidak! Jika komit seperti itu digabungkan, dalam kasus terburuk kami akan memiliki tes serpihan baru di produk.
Penyebab
Jadi, tes serpihan bermasalah. Apa yang harus kita lakukan terhadap mereka? Nah, jika kita tahu masalahnya, kita bisa merancang strategi tandingan.
Saya sering menemukan penyebab dalam kehidupan sehari-hari. Mereka dapat ditemukan di dalam tes itu sendiri . Tes mungkin ditulis secara suboptimal, memiliki asumsi yang salah, atau mengandung praktik buruk. Namun, tidak hanya itu. Tes terkelupas bisa menjadi indikasi sesuatu yang jauh lebih buruk.
Di bagian berikut, kita akan membahas yang paling umum yang pernah saya temui.
1. Penyebab Sisi Uji
Di dunia yang ideal, status awal aplikasi Anda harus murni dan 100% dapat diprediksi. Pada kenyataannya, Anda tidak pernah tahu apakah ID yang Anda gunakan dalam pengujian akan selalu sama.
Mari kita periksa dua contoh kegagalan tunggal di pihak saya. Kesalahan nomor satu adalah menggunakan ID di perlengkapan pengujian saya:
{ "id": "f1d2554b0ce847cd82f3ac9bd1c0dfca", "name": "Variant product", }Kesalahan nomor dua adalah mencari pemilih unik untuk digunakan dalam pengujian UI dan berpikir, “Oke, ID ini sepertinya unik. Aku akan menggunakannya.”
<!-- This is a text field I took from a project I worked on --> <input type="text" />Namun, jika saya menjalankan pengujian pada instalasi lain atau, kemudian, pada beberapa build di CI, maka pengujian tersebut mungkin gagal. Aplikasi kita akan menghasilkan ID baru, mengubahnya di antara build. Jadi, kemungkinan penyebab pertama dapat ditemukan di ID yang di-hardcode .
Penyebab kedua dapat muncul dari data demo yang dihasilkan secara acak (atau sebaliknya). Tentu, Anda mungkin berpikir bahwa "cacat" ini dapat dibenarkan — lagi pula, pembuatan datanya acak — tetapi pikirkan tentang men-debug data ini. Sangat sulit untuk melihat apakah ada bug dalam pengujian itu sendiri atau dalam data demo.
Selanjutnya adalah penyebab sisi pengujian yang telah saya perjuangkan berkali-kali: tes dengan cross-dependencies . Beberapa tes mungkin tidak dapat berjalan secara independen atau dalam urutan acak, yang menimbulkan masalah. Selain itu, tes sebelumnya dapat mengganggu tes berikutnya. Skenario ini dapat menyebabkan tes terkelupas dengan memperkenalkan efek samping.
Namun, jangan lupa bahwa tes adalah tentang asumsi yang menantang. Apa yang terjadi jika asumsi Anda salah sejak awal? Saya sering mengalami ini, favorit saya adalah asumsi yang salah tentang waktu.
Salah satu contohnya adalah penggunaan waktu tunggu yang tidak akurat, terutama dalam pengujian UI — misalnya, dengan menggunakan waktu tunggu yang tetap . Baris berikut diambil dari tes Nightwatch.js.
// Please never do that unless you have a very good reason! // Waits for 1 second browser.pause(1000);Asumsi lain yang salah berkaitan dengan waktu itu sendiri. Saya pernah menemukan bahwa tes PHPUnit yang terkelupas hanya gagal di build malam kami. Setelah beberapa debugging, saya menemukan bahwa pergeseran waktu antara kemarin dan hari ini adalah penyebabnya. Contoh bagus lainnya adalah kegagalan karena zona waktu .
Asumsi yang salah tidak berhenti di situ. Kita juga dapat memiliki asumsi yang salah tentang urutan data . Bayangkan sebuah kisi atau daftar yang berisi banyak entri dengan informasi, seperti daftar mata uang:
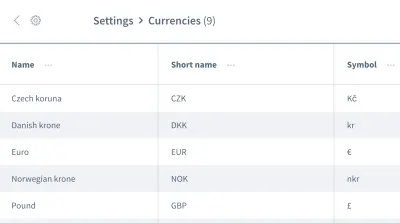
Kami ingin bekerja dengan informasi entri pertama, mata uang "koruna Ceko". Bisakah Anda yakin bahwa aplikasi Anda akan selalu menempatkan potongan data ini sebagai entri pertama setiap kali pengujian Anda dijalankan? Mungkinkah "Euro" atau mata uang lain akan menjadi entri pertama pada beberapa kesempatan?
Jangan berasumsi bahwa data Anda akan datang dalam urutan yang Anda butuhkan. Mirip dengan ID yang di-hardcode, pesanan dapat berubah antar build, tergantung pada desain aplikasi.
2. Penyebab Sisi Lingkungan
Kategori penyebab berikutnya berkaitan dengan segala sesuatu di luar pengujian Anda. Secara khusus, kita berbicara tentang lingkungan tempat pengujian dijalankan, dependensi terkait CI dan buruh pelabuhan di luar pengujian Anda — semua hal yang hampir tidak dapat Anda pengaruhi, setidaknya dalam peran Anda sebagai penguji.
Penyebab sisi lingkungan yang umum adalah kebocoran sumber daya : Seringkali ini adalah aplikasi yang sedang dimuat, menyebabkan waktu pemuatan yang bervariasi atau perilaku yang tidak terduga. Tes besar dapat dengan mudah menyebabkan kebocoran, memakan banyak memori. Masalah umum lainnya adalah kurangnya pembersihan .
Ketidakcocokan antara dependensi memberi saya mimpi buruk pada khususnya. Satu mimpi buruk terjadi ketika saya bekerja dengan Nightwatch.js untuk pengujian UI. Nightwatch.js menggunakan WebDriver, yang tentu saja bergantung pada Chrome. Saat Chrome mempercepat pembaruan, ada masalah dengan kompatibilitas: Chrome, WebDriver, dan Nightwatch.js sendiri tidak lagi bekerja bersama, yang menyebabkan pembangunan kami gagal dari waktu ke waktu.
Berbicara tentang dependensi : Penyebutan terhormat berlaku untuk masalah npm apa pun, seperti izin yang hilang atau npm sedang down. Semua itu saya alami dalam mengamati CI.
Dalam hal kesalahan dalam pengujian UI karena masalah lingkungan, perlu diingat bahwa Anda memerlukan seluruh tumpukan aplikasi agar dapat berjalan. Semakin banyak hal yang terlibat, semakin besar potensi kesalahan . Oleh karena itu, pengujian JavaScript adalah pengujian yang paling sulit untuk distabilkan dalam pengembangan web, karena mencakup sejumlah besar kode.
3. Penyebab Sisi Produk
Last but not least, kita benar-benar harus berhati-hati dengan area ketiga ini — area dengan bug yang sebenarnya. Saya sedang berbicara tentang penyebab sisi produk dari kerapuhan. Salah satu contoh yang paling terkenal adalah kondisi balapan dalam sebuah aplikasi. Ketika ini terjadi, bug perlu diperbaiki pada produk, bukan pada pengujian! Mencoba memperbaiki tes atau lingkungan tidak akan berguna dalam kasus ini.
Cara Untuk Melawan Flakiness
Kami telah mengidentifikasi tiga penyebab flakiness. Kita bisa membangun strategi tandingan kita di sini! Tentu saja, Anda sudah mendapatkan banyak hal dengan mengingat tiga penyebab ketika Anda menghadapi tes yang tidak stabil. Anda sudah tahu apa yang harus dicari dan bagaimana meningkatkan tes. Namun, selain itu, ada beberapa strategi yang akan membantu kami merancang, menulis, dan men-debug pengujian, dan kami akan membahasnya bersama di bagian berikut.
Fokus Pada Tim Anda
Tim Anda bisa dibilang merupakan faktor terpenting . Sebagai langkah pertama, akui bahwa Anda memiliki masalah dengan tes yang tidak stabil. Mendapatkan komitmen seluruh tim sangat penting! Kemudian, sebagai sebuah tim, Anda perlu memutuskan bagaimana menangani tes yang tidak stabil.
Selama bertahun-tahun saya bekerja di bidang teknologi, saya menemukan empat strategi yang digunakan oleh tim untuk melawan kerapuhan:

- Tidak melakukan apa-apa dan menerima hasil tes yang terkelupas.
Tentu saja, strategi ini bukanlah solusi sama sekali. Tes tidak akan menghasilkan nilai karena Anda tidak dapat mempercayainya lagi — bahkan jika Anda menerima kerapuhannya. Jadi kita bisa melewatkan yang satu ini dengan cukup cepat. - Coba lagi tes sampai lulus.
Strategi ini umum di awal karir saya, menghasilkan respons yang saya sebutkan sebelumnya. Ada beberapa penerimaan dengan mencoba ulang tes sampai mereka lulus. Strategi ini tidak memerlukan debugging, tetapi malas. Selain menyembunyikan gejala masalah, ini akan lebih memperlambat rangkaian pengujian Anda, yang membuat solusi tidak dapat dijalankan. Namun, mungkin ada beberapa pengecualian untuk aturan ini, yang akan saya jelaskan nanti. - Hapus dan lupakan tes.
Yang ini cukup jelas: Cukup hapus tes yang tidak stabil, sehingga tidak mengganggu rangkaian pengujian Anda lagi. Tentu, ini akan menghemat uang Anda karena Anda tidak perlu men-debug dan memperbaiki tes lagi. Tapi itu datang dengan mengorbankan sedikit cakupan pengujian dan kehilangan perbaikan bug potensial. Tes ada karena suatu alasan! Jangan menembak utusan dengan menghapus tes. - Karantina dan perbaiki.
Saya paling sukses dengan strategi ini. Dalam hal ini, kita akan melewatkan tes untuk sementara, dan rangkaian tes terus-menerus mengingatkan kita bahwa tes telah dilewati. Untuk memastikan perbaikan tidak terlewatkan, kami akan menjadwalkan tiket untuk sprint berikutnya. Pengingat bot juga berfungsi dengan baik. Setelah masalah yang menyebabkan kerapuhan telah diperbaiki, kami akan mengintegrasikan (yaitu unskip) pengujian lagi. Sayangnya, kami akan kehilangan cakupan untuk sementara, tetapi akan kembali dengan perbaikan, jadi ini tidak akan lama.
Strategi ini membantu kami menangani masalah pengujian di tingkat alur kerja, dan saya bukan satu-satunya yang mengalaminya. Dalam artikelnya, Sam Saffron sampai pada kesimpulan serupa. Tetapi dalam pekerjaan kita sehari-hari, mereka membantu kita sampai batas tertentu. Jadi, bagaimana kita melanjutkan ketika tugas seperti itu datang kepada kita?
Jauhkan Tes Terisolasi
Saat merencanakan kasus dan struktur pengujian Anda, selalu jaga agar pengujian Anda tetap terisolasi dari pengujian lain, sehingga pengujian tersebut dapat dijalankan dalam urutan yang independen atau acak. Langkah yang paling penting adalah mengembalikan instalasi yang bersih di antara pengujian . Selain itu, hanya uji alur kerja yang ingin Anda uji, dan buat data tiruan hanya untuk pengujian itu sendiri. Keuntungan lain dari jalan pintas ini adalah akan meningkatkan kinerja pengujian . Jika Anda mengikuti poin-poin ini, tidak ada efek samping dari tes lain atau data sisa yang akan menghalangi.
Contoh di bawah ini diambil dari pengujian UI platform e-niaga, dan berhubungan dengan login pelanggan di etalase toko. (Tes ini ditulis dalam JavaScript, menggunakan kerangka kerja Cypress.)
// File: customer-login.spec.js let customer = {}; beforeEach(() => { // Set application to clean state cy.setInitialState() .then(() => { // Create test data for the test specifically return cy.setFixture('customer'); }) }): Langkah pertama adalah mengatur ulang aplikasi ke instalasi bersih. Ini dilakukan sebagai langkah pertama di hook beforeEach siklus hidup untuk memastikan bahwa reset dijalankan pada setiap kesempatan. Setelah itu, data pengujian dibuat khusus untuk pengujian — untuk kasus pengujian ini, pelanggan akan dibuat melalui perintah khusus. Selanjutnya, kita bisa mulai dengan satu alur kerja yang ingin kita uji: login pelanggan.
Optimalkan Lebih Lanjut Struktur Tes
Kami dapat membuat beberapa penyesuaian kecil lainnya untuk membuat struktur pengujian kami lebih stabil. Yang pertama cukup sederhana: Mulailah dengan tes yang lebih kecil. Seperti yang dikatakan sebelumnya, semakin banyak Anda melakukan tes, semakin banyak yang bisa salah. Buat tes sesederhana mungkin , dan hindari banyak logika di masing-masing tes.
Saat tidak mengasumsikan urutan data (misalnya, saat menangani urutan entri dalam daftar dalam pengujian UI), kita dapat merancang pengujian agar berfungsi secara independen dari urutan apa pun. Untuk mengembalikan contoh grid dengan informasi di dalamnya, kita tidak akan menggunakan pseudo-selector atau CSS lain yang memiliki ketergantungan kuat pada urutan. Alih-alih pemilih nth-child(3) , kita bisa menggunakan teks atau hal lain yang urutannya tidak penting. Misalnya, kita bisa menggunakan pernyataan seperti, "Temukan saya elemen dengan string teks yang satu ini di tabel ini".
Tunggu! Percobaan Ulang Terkadang OK?
Mencoba ulang tes adalah topik yang kontroversial, dan memang seharusnya begitu. Saya masih menganggapnya sebagai anti-pola jika tes dicoba ulang secara membabi buta sampai berhasil. Namun, ada pengecualian penting: Saat Anda tidak dapat mengontrol kesalahan, mencoba lagi dapat menjadi pilihan terakhir (misalnya, untuk mengecualikan kesalahan dari dependensi eksternal). Dalam hal ini, kami tidak dapat memengaruhi sumber kesalahan. Namun, berhati-hatilah saat melakukan ini: Jangan menjadi buta terhadap kerapuhan saat mencoba ulang tes, dan gunakan notifikasi untuk mengingatkan Anda saat tes dilewati.
Contoh berikut adalah salah satu yang saya gunakan di CI kami dengan GitLab. Lingkungan lain mungkin memiliki sintaks yang berbeda untuk mencapai percobaan ulang, tetapi ini akan memberi Anda gambaran:
test: script: rspec retry: max: 2 when: runner_system_failureDalam contoh ini, kami mengonfigurasi berapa banyak percobaan ulang yang harus dilakukan jika pekerjaan gagal. Yang menarik adalah kemungkinan untuk mencoba kembali jika ada kesalahan pada sistem runner (misalnya, pengaturan pekerjaan gagal). Kami memilih untuk mencoba kembali pekerjaan kami hanya jika sesuatu dalam pengaturan buruh pelabuhan gagal.
Perhatikan bahwa ini akan mencoba ulang seluruh pekerjaan saat dipicu. Jika Anda hanya ingin mencoba kembali pengujian yang salah, maka Anda harus mencari fitur dalam kerangka pengujian Anda untuk mendukung ini. Di bawah ini adalah contoh dari Cypress, yang telah mendukung percobaan ulang satu pengujian sejak versi 5:
{ "retries": { // Configure retry attempts for 'cypress run` "runMode": 2, // Configure retry attempts for 'cypress open` "openMode": 2, } } Anda dapat mengaktifkan percobaan ulang di file konfigurasi Cypress, cypress.json . Di sana, Anda dapat menentukan upaya coba lagi dalam runner uji dan mode tanpa kepala.
Menggunakan Waktu Tunggu Dinamis
Poin ini penting untuk semua jenis pengujian, tetapi terutama pengujian UI. Saya tidak bisa cukup menekankan ini: Jangan pernah menggunakan waktu tunggu yang tetap — setidaknya bukan tanpa alasan yang sangat bagus. Jika Anda melakukannya, pertimbangkan kemungkinan hasilnya. Dalam kasus terbaik, Anda akan memilih waktu tunggu yang terlalu lama, membuat rangkaian pengujian lebih lambat dari yang seharusnya. Dalam kasus terburuk, Anda tidak akan menunggu cukup lama, sehingga tes tidak akan dilanjutkan karena aplikasi belum siap, menyebabkan tes gagal dengan cara yang tidak stabil. Dalam pengalaman saya, ini adalah penyebab paling umum dari tes terkelupas.
Sebaliknya, gunakan waktu tunggu yang dinamis. Ada banyak cara untuk melakukannya, tetapi Cypress menanganinya dengan sangat baik.
Semua perintah Cypress memiliki metode menunggu implisit: Perintah tersebut telah memeriksa apakah elemen tempat perintah sedang diterapkan ada di DOM untuk waktu yang ditentukan — menunjuk ke kemampuan mencoba ulang Cypress. Namun, itu hanya memeriksa keberadaan , dan tidak lebih. Jadi saya sarankan untuk melangkah lebih jauh — menunggu perubahan apa pun di situs web atau UI aplikasi Anda yang juga akan dilihat oleh pengguna sebenarnya, seperti perubahan pada UI itu sendiri atau dalam animasi.
Contoh ini menggunakan waktu tunggu eksplisit pada elemen dengan pemilih .offcanvas . Pengujian hanya akan dilanjutkan jika elemen terlihat hingga batas waktu yang ditentukan, yang dapat Anda konfigurasikan:
// Wait for changes in UI (until element is visible) cy.get(#element).should('be.visible'); Kemungkinan lain yang rapi di Cypress untuk menunggu dinamis adalah fitur jaringannya. Ya, kita bisa menunggu permintaan terjadi dan hasil tanggapan mereka. Saya sering menggunakan penantian seperti ini. Pada contoh di bawah ini, kami mendefinisikan permintaan untuk menunggu, menggunakan perintah wait untuk menunggu respons, dan menegaskan kode statusnya:
// File: checkout-info.spec.js // Define request to wait for cy.intercept({ url: '/widgets/customer/info', method: 'GET' }).as('checkoutAvailable'); // Imagine other test steps here... // Assert the response's status code of the request cy.wait('@checkoutAvailable').its('response.statusCode') .should('equal', 200);Dengan cara ini, kami dapat menunggu selama yang dibutuhkan aplikasi kami, membuat pengujian lebih stabil dan tidak mudah pecah karena kebocoran sumber daya atau masalah lingkungan lainnya.
Men-debug Tes Flaky
Kita sekarang tahu bagaimana mencegah tes yang tidak stabil berdasarkan desain. Tetapi bagaimana jika Anda sudah berurusan dengan tes yang tidak stabil? Bagaimana Anda bisa menyingkirkannya?
Ketika saya sedang debugging, menempatkan tes cacat dalam satu lingkaran banyak membantu saya dalam mengungkap kerapuhan. Misalnya, jika Anda menjalankan pengujian 50 kali, dan selalu lolos, maka Anda dapat lebih yakin bahwa pengujian tersebut stabil — mungkin perbaikan Anda berhasil. Jika tidak, Anda setidaknya bisa mendapatkan lebih banyak wawasan tentang tes serpihan.
// Use in build Lodash to repeat the test 100 times Cypress._.times(100, (k) => { it(`typing hello ${k + 1} / 100`, () => { // Write your test steps in here }) }) Mendapatkan lebih banyak wawasan tentang tes serpihan ini sangat sulit di CI. Untuk mendapatkan bantuan, lihat apakah kerangka kerja pengujian Anda dapat memperoleh lebih banyak informasi tentang build. Dalam hal pengujian front-end, Anda biasanya dapat menggunakan console.log dalam pengujian Anda:
it('should be a Vue.JS component', () => { // Mock component by a method defined before const wrapper = createWrapper(); // Print out the component's html console.log(wrapper.html()); expect(wrapper.isVueInstance()).toBe(true); }) Contoh ini diambil dari pengujian unit Jest di mana saya menggunakan console.log untuk mendapatkan output HTML dari komponen yang diuji. Jika Anda menggunakan kemungkinan logging ini di test runner Cypress, Anda bahkan dapat memeriksa output di alat pengembang pilihan Anda. Selain itu, ketika berbicara tentang Cypress di CI, Anda dapat memeriksa output ini di log CI Anda dengan menggunakan sebuah plugin.
Selalu lihat fitur kerangka pengujian Anda untuk mendapatkan dukungan dengan logging. Dalam pengujian UI, sebagian besar kerangka kerja menyediakan fitur tangkapan layar — setidaknya jika gagal, tangkapan layar akan diambil secara otomatis. Beberapa kerangka kerja bahkan menyediakan perekaman video , yang dapat sangat membantu dalam mendapatkan wawasan tentang apa yang terjadi dalam pengujian Anda.
Lawan Mimpi Buruk Flakiness!
Sangat penting untuk terus mencari tes yang tidak stabil, baik dengan mencegahnya sejak awal atau dengan men-debug dan memperbaikinya segera setelah terjadi. Kami perlu menganggapnya serius, karena mereka dapat mengisyaratkan masalah dalam aplikasi Anda.
Melihat Bendera Merah
Mencegah tes terkelupas di tempat pertama adalah yang terbaik, tentu saja. Untuk rekap cepat, berikut adalah beberapa tanda bahaya:
- Tesnya besar dan mengandung banyak logika.
- Pengujian mencakup banyak kode (misalnya, dalam pengujian UI).
- Tes ini menggunakan waktu tunggu yang tetap.
- Tes tergantung pada tes sebelumnya.
- Pengujian menegaskan data yang tidak 100% dapat diprediksi, seperti penggunaan ID, waktu, atau data demo, terutama yang dihasilkan secara acak.
Jika Anda mengingat petunjuk dan strategi dari artikel ini, Anda dapat mencegah tes yang tidak stabil sebelum itu terjadi. Dan jika mereka datang, Anda akan tahu cara men-debug dan memperbaikinya.
Langkah-langkah ini benar-benar membantu saya mendapatkan kembali kepercayaan diri dalam rangkaian pengujian kami. Test suite kami tampaknya stabil saat ini. Mungkin ada masalah di masa depan — tidak ada yang 100% sempurna. Pengetahuan ini dan strategi-strategi ini akan membantu saya menghadapinya. Dengan demikian, saya akan tumbuh percaya diri dengan kemampuan saya untuk melawan mimpi buruk ujian yang rapuh itu .
Saya harap saya dapat meringankan setidaknya beberapa rasa sakit dan kekhawatiran Anda tentang kerapuhan!
Bacaan lebih lanjut
Jika Anda ingin mempelajari lebih lanjut tentang topik ini, berikut adalah beberapa sumber dan artikel yang rapi, yang banyak membantu saya:
- Artikel tentang "serpihan," Cypress.io
- “Mencoba Ulang Tes Anda Sebenarnya Adalah Hal yang Baik (Jika Pendekatan Anda Benar),” Filip Hric, Cypress.io
- “Uji Flakiness: Metode untuk Mengidentifikasi dan Mengatasi Tes Flaky,” Jason Palmer, Spotify R&D Engineering
- “Pengujian Tidak Stabil di Google dan Bagaimana Kami Menguranginya,” John Micco, Blog Pengujian Google