
Deteksi Berita Palsu dalam Pembelajaran Mesin [Dijelaskan dengan Contoh Pengkodean]
Diterbitkan: 2021-02-08Berita palsu adalah salah satu isu terbesar di era internet dan media sosial saat ini. Meskipun merupakan berkah bahwa berita mengalir dari satu sudut dunia ke sudut lain dalam hitungan beberapa jam, juga menyakitkan melihat banyak orang dan kelompok menyebarkan berita palsu.
Teknik Machine Learning menggunakan Natural Language Processing dan Deep Learning dapat digunakan untuk mengatasi masalah ini sampai batas tertentu. Kami akan membangun model Deteksi Berita Palsu menggunakan Machine Learning dalam tutorial ini.
Pada akhir artikel ini, Anda akan mengetahui hal-hal berikut:
- Menangani data teks
- Teknik pemrosesan NLP
- Hitung vektorisasi & TF-IDF
- Membuat prediksi dan mengklasifikasikan teks berita
Bergabunglah dengan kursus AI & ML online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karir Anda.
Daftar isi
Data & Masalah
Kami akan menggunakan data tantangan Berita Palsu Kaggle untuk membuat pengklasifikasi. Dataset terdiri dari 4 fitur dan 1 target biner. 4 fitur tersebut adalah sebagai berikut:
- id : id unik untuk artikel berita
- title : judul artikel berita
- penulis : penulis artikel berita
- teks : teks artikel; bisa jadi tidak lengkap
Dan targetnya adalah "label" yang berisi nilai biner 0s dan 1s. Dimana 0 berarti sumber berita terpercaya, atau dengan kata lain Bukan Palsu. 1 berarti bahwa itu adalah berita yang berpotensi palsu dan tidak dapat diandalkan. Dataset yang kami miliki terdiri dari 20800 instance. Mari kita selami.

Pra-Pemrosesan & Pembersihan Data
| impor panda sebagai pd df=pd.read_csv( 'berita palsu/kereta.csv' ) df.head() |
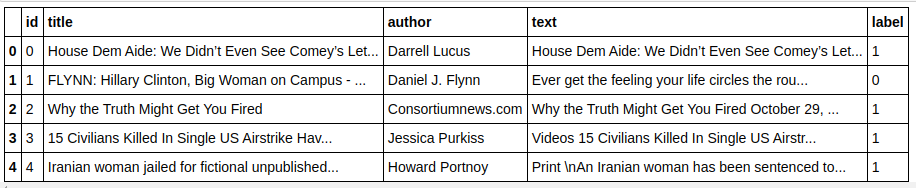
| X=df.drop( 'label' ,axis= 1 ) # Fitur y=df[ 'label' ] # Target |
Kita perlu menghapus instance dengan data yang hilang sekarang.
| df=df.dropna() |
![]()
Seperti yang bisa kita lihat, itu menjatuhkan semua instance dengan data yang hilang.
| pesan=df.copy() pesan.reset_index(di tempat= Benar ) pesan.head( 10 ) |
Mari kita lihat datanya sekali.
| pesan['teks'][6] |

Seperti yang kita lihat, ada kebutuhan untuk melakukan langkah-langkah berikut:
- Menghapus stopwords: Ada banyak kata yang tidak menambah nilai pada teks apa pun, apa pun datanya. Misalnya, “I”, “a”, “am”, dll. Kata-kata ini tidak memiliki nilai informasi dan karenanya dapat dihapus untuk mengurangi ukuran corpus kita sehingga kita hanya dapat fokus pada kata/token yang bernilai sebenarnya .
- Stemming kata-kata: Stemming dan Lemmatization adalah teknik untuk mengurangi kata-kata ke batang atau akarnya. Keuntungan utama dari langkah ini adalah untuk mengurangi ukuran kosakata. Misalnya, kata-kata seperti Play, Playing, Played akan dikurangi menjadi "Play". Stemming hanya memotong kata menjadi kata terpendek dan tidak mempertimbangkan aspek gramatikal teks. Lemmatisasi, di sisi lain, mempertimbangkan tata bahasa juga dan karenanya menghasilkan hasil yang jauh lebih baik. Namun, Lemmatization biasanya lebih lambat daripada stemming karena perlu mengacu pada kamus dan mempertimbangkan aspek tata bahasa.
- Menghapus semuanya selain nilai alfabet: Nilai non-abjad tidak banyak berguna di sini sehingga dapat dihapus. Namun, Anda dapat menjelajahi lebih jauh untuk melihat apakah kehadiran numerik atau jenis data lainnya berdampak pada target.
- Huruf kecil kata-kata: Huruf kecil kata-kata untuk mengurangi kosakata.
- Tokenize kalimat: Menghasilkan token dari kalimat.
| dari sklearn.feature_extraction.text impor CountVectorizer, TfidfVectorizer, HashingVectorizer dari nltk.corpus mengimpor stopwords dari nltk.stem.porter impor PorterStemmer impor ulang ps = PorterStemmer() corpus = [] for i in range(0, len(messages)): ulasan = re.sub('[^a-zA-Z]', ' ', pesan['teks'][i]) ulasan = ulasan.lower() ulasan = ulasan.split() review = [ps.stem(word) untuk kata di review jika bukan kata di stopwords.words('english')] review = ' '.join(review) corpus.append(ulasan) |
Mari kita lihat corpus kita sekarang.
| tubuh[ 3 ] |
![]()
Seperti yang bisa kita lihat, kata-kata itu sekarang berasal dari kata dasar.
Vektorisasi TF-IDF
Sekarang kita perlu membuat vektorisasi kata-kata menjadi data numerik yang juga disebut vektorisasi. Cara termudah untuk membuat vektor adalah dengan menggunakan Bag of Words. Tetapi Bag of Words membuat matriks yang jarang dan karenanya ada banyak memori pemrosesan yang dibutuhkan. Selain itu, BoW tidak mempertimbangkan frekuensi kata yang menjadikannya algoritma yang buruk.
TF-IDF (Frekuensi Term – Frekuensi Dokumen Terbalik) adalah cara lain untuk membuat vektor kata yang mempertimbangkan frekuensi kata. Misalnya, kata-kata umum seperti “kami”, “milik kami”, “yang” ada di setiap dokumen/instance sehingga nilai BoW akan terlalu tinggi dan karenanya menyesatkan. Ini akan mengarah pada model yang buruk. TF-IDF adalah perkalian dari Term Frequency dan Inverse Document Frequency.
Term Frequency memperhitungkan frekuensi kata dalam dokumen dan Inverse Document Frequency memperhitungkan kata-kata yang ada di seluruh corpus. Kata-kata yang ada di seluruh korpus telah berkurang pentingnya karena nilai IDF jauh lebih rendah. Kata-kata yang ada secara khusus dalam satu dokumen memiliki nilai IDF yang tinggi yang membuat nilai TF-IDF total menjadi tinggi.
| ## TFi df Vectorizer dari sklearn.feature_extraction.text impor TfidfVectorizer tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=messages[ 'label' ] |
Pada kode di atas, kita mengimpor TF-IDF Vectorizer dari modul ekstraksi fitur Sklearn. Kami membuat objeknya dengan melewatkan max_features sebagai 5000 dan ngram_range sebagai (1,3). Parameter max_features menentukan jumlah maksimum vektor fitur yang ingin kita buat dan parameter ngram_range mendefinisikan kombinasi ngram yang ingin kita sertakan. Dalam kasus kami, kami akan mendapatkan 3 kombinasi dari 1 kata, 2 kata, dan 3 kata. Mari kita lihat beberapa fitur yang dibuat.

| tfidf_v.get_feature_names()[: 20 ] |

Seperti yang bisa kita lihat, ada beberapa jenis kombinasi yang terbentuk. Ada nama fitur dengan 1 token, 2 token, dan juga dengan 3 token.
Membuat Dataframe
| ## Bagi dataset menjadi Latih dan Uji dari sklearn.model_selection impor train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, kolom=tfidf_v.get_feature_names()) jumlah_df.head() |
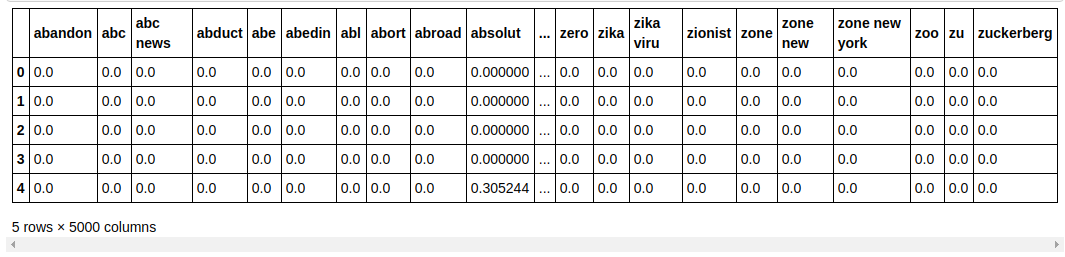
Kami membagi kumpulan data menjadi pelatihan dan pengujian sehingga kami dapat menguji kinerja model pada data yang tidak terlihat. Kami kemudian membuat Dataframe baru yang berisi vektor fitur baru di dalamnya.
Pemodelan & Penyetelan
Algoritma NB Multinomial
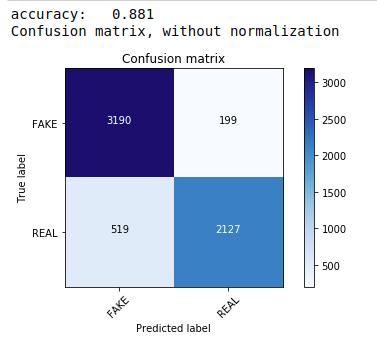
Pertama, kami menggunakan teorema Multinomial Naive Bayes yang merupakan algoritma paling umum dan termudah yang disukai untuk klasifikasi data teks. Kami cocok pada data pelatihan dan memprediksi pada data uji. Kemudian kami menghitung & memplot matriks konfusi dan mendapatkan akurasi 88,1%.
| dari sklearn.naive_bayes impor MultinomialNB dari metrik impor sklearn impor numpy sebagai np impor itertools dari sklearn.metrics impor plot_confusion_matrix classifier=MultinomialNB() classifier.fit(X_train, y_train) pred = classifier.predict(X_test) skor = metrics.accuracy_score(y_test, pred) print( "akurasi: %0.3f" % skor) cm = metrics.confusion_matrix(y_test, pred) plot_confusion_matrix(cm, class=[ 'PALSU' , 'NYATA' ]) |
Pengklasifikasi Multinomial dengan Penyetelan Hyperparameter
MultinomialNB memiliki parameter alpha yang dapat disetel lebih lanjut. Oleh karena itu kami menjalankan loop untuk mencoba beberapa pengklasifikasi MultinomialNB dengan nilai alfa yang berbeda dan memeriksa skor akurasinya. Dan kami memeriksa apakah skor saat ini lebih dari skor sebelumnya. Jika ya, maka kami menetapkan pengklasifikasi sebagai yang sekarang.
| skor_sebelumnya= 0 untuk alpha di np.arange( 0 , 1 , 0.1 ): sub_classifier=MultinomialNB(alfa=alfa) sub_classifier.fit(X_train,y_train) y_pred=sub_classifier.predict(X_test) skor = metrics.accuracy_score(y_test, y_pred) jika skor> skor_sebelumnya: classifier=sub_classifier print( “Alpha: {}, Skor : {}” .format(alpha,score)) |
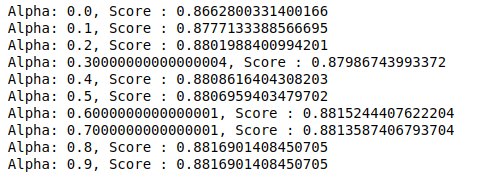
Oleh karena itu kita dapat melihat bahwa nilai alpha 0,9 atau 0,8 memberikan skor akurasi tertinggi.
Menafsirkan Hasil
Sekarang mari kita lihat apa arti dari nilai koefisien classifier ini. Pertama-tama kita akan menyimpan semua nama fitur di variabel lain.
| ## Nama tempat makan G et F nama_fitur = cv.get_fitur_nama() |
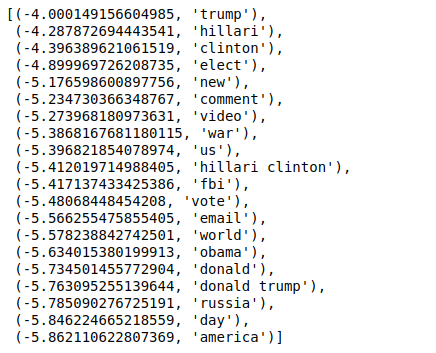
Sekarang, ketika kami mengurutkan nilai dalam urutan terbalik, kami mendapatkan nilai dengan nilai minimum -4. Ini menunjukkan kata-kata yang paling nyata atau paling tidak palsu.
| ### Paling nyata diurutkan(zip(classifier.coef_[ 0 ], nama_fitur), reverse= Benar )[: 20 ] |
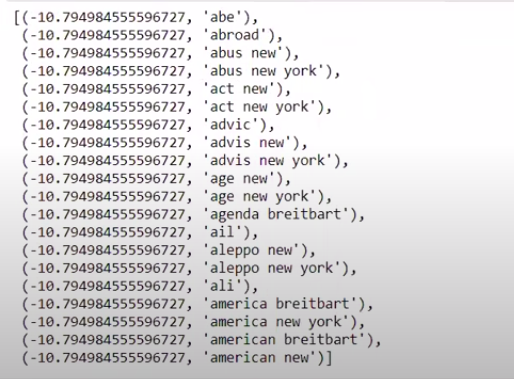
Saat kami mengurutkan nilai dalam urutan yang tidak terbalik, kami mendapatkan nilai dengan nilai minimum -10. Ini menunjukkan kata-kata yang paling tidak nyata atau paling palsu.
| ### Paling nyata diurutkan(zip(classifier.coef_[ 0 ], nama_fitur))[: 20 ] |
Kesimpulan
Dalam tutorial ini, kami hanya menggunakan algoritma ML tetapi Anda juga menggunakan metode jaringan saraf lainnya. Selain itu, untuk memvektorisasi data teks, kami menggunakan vektorizer TF-IDF. Ada lebih banyak vectorizer seperti Count Vectorizer, Hashing Vectorizer, dll. Juga yang bisa lebih baik dalam melakukan pekerjaan. Cobalah dan bereksperimen dengan algoritme dan teknik lain untuk melihat apakah Anda dapat menghasilkan hasil yang lebih baik atau tidak.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat Program PG Eksekutif IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT -B Status Alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Mengapa perlu mendeteksi berita palsu?
Dalam kondisi mereka saat ini, platform media sosial sangat kuat dan berharga karena memungkinkan pengguna untuk berdiskusi dan bertukar pikiran serta memperdebatkan topik seperti demokrasi, pendidikan, dan kesehatan. Namun, entitas tertentu memanfaatkan platform tersebut dengan buruk, untuk keuntungan moneter dalam beberapa keadaan dan untuk menghasilkan sudut pandang berprasangka, mengubah pola pikir, dan menyebarkan sindiran atau kekonyolan pada orang lain. Berita palsu adalah istilah untuk fenomena ini. Maraknya posting item online yang tidak sesuai dengan kenyataan telah menghasilkan banyak masalah di bidang politik, olahraga, kesehatan, sains, dan bidang lainnya.
Perusahaan mana yang paling banyak menggunakan deteksi berita palsu?
Deteksi berita palsu digunakan pada platform seperti media sosial dan situs web berita. Raksasa media sosial seperti Facebook, Instagram, dan Twitter rentan terhadap berita palsu karena mayoritas penggunanya mengandalkan mereka sebagai sumber berita harian untuk mendapatkan informasi terkini. Teknik pendeteksian palsu juga digunakan oleh perusahaan media untuk mengetahui keaslian informasi yang mereka miliki. Email adalah media lain di mana individu dapat menerima berita, yang membuatnya sulit untuk mengidentifikasi dan memverifikasi kebenarannya. Hoax, spam, dan junk mail terkenal karena dikirim melalui email. Akibatnya, sebagian besar platform email menggunakan deteksi berita palsu untuk mengidentifikasi spam dan junk mail.