
Analisis Data Eksplorasi dengan Python: Apa yang Perlu Anda Ketahui?
Diterbitkan: 2021-03-12Analisis Data Eksplorasi (EDA) adalah praktik yang sangat umum dan penting yang diikuti oleh semua ilmuwan data. Ini adalah proses melihat tabel dan tabel data dari sudut yang berbeda untuk memahaminya sepenuhnya. Memperoleh pemahaman yang baik tentang data membantu kami membersihkan dan meringkasnya, yang kemudian memunculkan wawasan dan tren yang sebelumnya tidak jelas.
EDA tidak memiliki seperangkat aturan inti yang harus diikuti seperti dalam 'analisis data', misalnya. Orang yang baru mengenal bidang ini selalu cenderung bingung antara dua istilah yang sebagian besar mirip tetapi berbeda dalam tujuannya. Tidak seperti EDA, analisis data lebih condong ke arah penerapan probabilitas dan metode statistik untuk mengungkap fakta dan hubungan di antara varian yang berbeda.
Kembali, tidak ada cara yang benar atau salah untuk melakukan EDA. Ini bervariasi dari orang ke orang, namun ada beberapa pedoman utama yang umum diikuti yang tercantum di bawah ini.
- Menangani nilai yang hilang: Nilai nol dapat dilihat ketika semua data mungkin tidak tersedia atau direkam selama pengumpulan.
- Menghapus data duplikat: Penting untuk mencegah overfitting atau bias yang dibuat selama pelatihan algoritme pembelajaran mesin menggunakan rekaman data berulang
- Menangani outlier: Pencilan adalah catatan yang secara drastis berbeda dari data lainnya dan tidak mengikuti tren. Ini dapat muncul karena pengecualian atau ketidakakuratan tertentu selama pengumpulan data
- Penskalaan dan normalisasi: Ini hanya dilakukan untuk variabel data numerik. Sebagian besar waktu variabel sangat berbeda dalam jangkauan dan skala yang membuat sulit untuk membandingkan mereka dan menemukan korelasi.
- Analisis univariat dan Bivariat: Analisis univariat biasanya dilakukan dengan melihat bagaimana satu variabel mempengaruhi variabel target. Analisis bivariat dilakukan antara 2 variabel apa saja, bisa numerik atau kategorik atau keduanya.
Kita akan melihat bagaimana beberapa di antaranya diimplementasikan menggunakan kumpulan data 'Resiko Default Kredit Rumah' yang sangat terkenal yang tersedia di Kaggle di sini . Data tersebut berisi informasi tentang pemohon pinjaman pada saat mengajukan pinjaman. Ini berisi dua jenis skenario:
- Klien dengan kesulitan pembayaran : dia memiliki keterlambatan pembayaran lebih dari X hari
pada setidaknya salah satu angsuran Y pertama dari pinjaman dalam sampel kami,
- Semua kasus lain : Semua kasus lain ketika pembayaran dibayar tepat waktu.
Kami hanya akan mengerjakan file data aplikasi untuk artikel ini.
Terkait: Ide & Topik Proyek Python untuk Pemula
Daftar isi
Melihat Data
app_data = pd.read_csv( 'application_data.csv' )
aplikasi_data.info()
Setelah membaca data aplikasi, kita menggunakan fungsi info() untuk mendapatkan gambaran singkat tentang data yang akan kita tangani. Output di bawah ini memberi tahu kami bahwa kami memiliki sekitar 300.000 catatan pinjaman dengan 122 variabel. Dari jumlah tersebut, ada 16 variabel kategorikal dan sisanya numerik.
<kelas 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entri, 0 hingga 307510
Kolom: 122 entri, SK_ID_CURR hingga AMT_REQ_CREDIT_BUREAU_YEAR
dtypes: float64(65), int64(41), objek(16)
penggunaan memori: 286.2+ MB
Itu selalu merupakan praktik yang baik untuk menangani dan menganalisis data numerik dan kategoris secara terpisah.
categorical = app_data.select_dtypes(termasuk = objek).kolom
app_data[categorical].apply(pd.Series.nunique, axis = 0)
Melihat hanya pada fitur kategoris di bawah ini, kita melihat bahwa kebanyakan dari mereka hanya memiliki beberapa kategori yang membuatnya lebih mudah untuk dianalisis menggunakan plot sederhana.
NAME_CONTRACT_TYPE 2
KODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAMA_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
DARURAT_MODE 2
tipe d: int64
Sekarang untuk fitur numerik, metode description() memberi kita statistik data kita:
angka= app_data.describe()
numerik = angka. kolom
angka
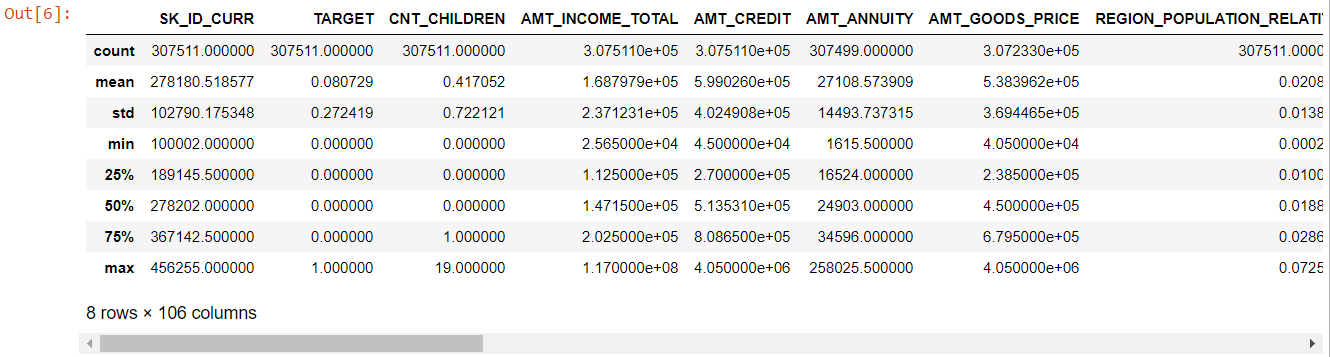
Melihat seluruh tabel, terbukti bahwa:
- hari_kelahiran negatif: usia pelamar (dalam hari) relatif terhadap hari aplikasi
- days_employed memiliki outlier (nilai maks adalah sekitar 100 tahun) (635243)
- amt_annuity- berarti jauh lebih kecil dari nilai maks
Jadi sekarang kita tahu fitur mana yang harus dianalisis lebih lanjut.
Data Hilang
Kita dapat membuat plot titik dari semua fitur yang memiliki nilai yang hilang dengan memplot % data yang hilang di sepanjang sumbu Y.
hilang = pd.DataFrame( (app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.figure(ukuran gambar = (16,5))
ax = sns.pointplot('indeks', 0, data = hilang)

plt.xticks(rotasi = 90, ukuran font = 7)
plt.title("Persentase Nilai yang Hilang")
plt.ylabel(“PERCENTAGE”)
plt.tampilkan()
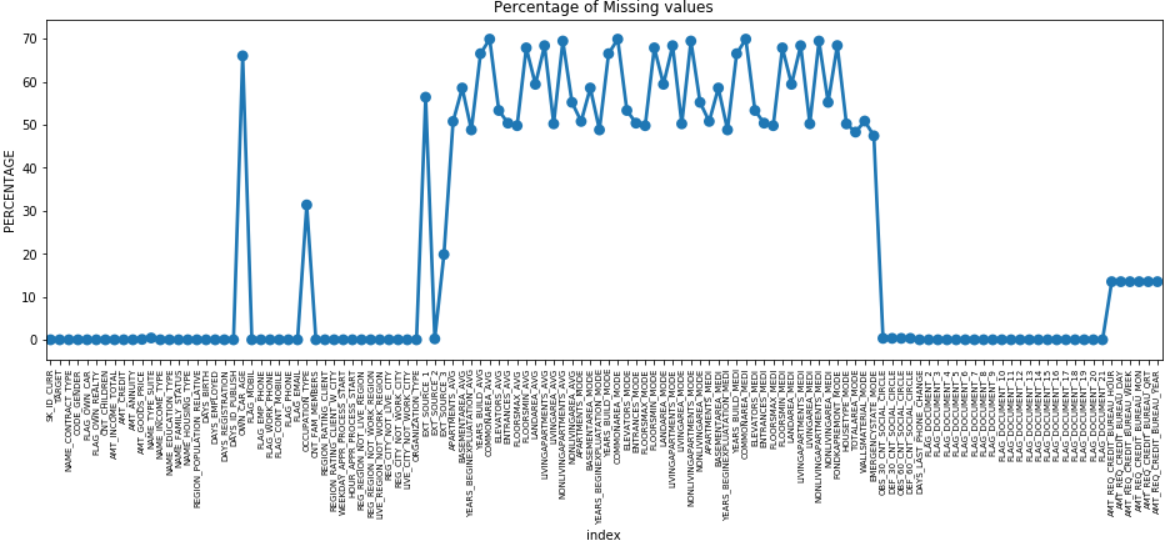
Banyak kolom memiliki banyak data yang hilang (30-70%), beberapa memiliki sedikit data yang hilang (13-19%) dan banyak kolom juga tidak memiliki data yang hilang sama sekali. Sebenarnya tidak perlu mengubah dataset ketika Anda hanya perlu melakukan EDA. Namun, untuk melanjutkan pra-pemrosesan data, kita harus tahu cara menangani nilai yang hilang.
Untuk fitur dengan nilai yang kurang hilang, kita dapat menggunakan regresi untuk memprediksi nilai yang hilang atau mengisi dengan rata-rata nilai yang ada, tergantung pada fitur tersebut. Dan untuk fitur dengan jumlah nilai yang hilang sangat tinggi, lebih baik untuk menghapus kolom tersebut karena kolom tersebut memberikan wawasan yang sangat sedikit tentang analisis.
Ketidakseimbangan Data
Dalam kumpulan data ini, para pelanggar pinjaman diidentifikasi menggunakan variabel biner 'TARGET'.
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91.927118
1 8.072882
Nama: TARGET, dtype: float64
Kami melihat data tersebut sangat tidak seimbang dengan rasio 92:8. Sebagian besar pinjaman dilunasi tepat waktu (target = 0). Jadi, setiap kali ada ketidakseimbangan yang begitu besar, lebih baik mengambil fitur dan membandingkannya dengan variabel target (analisis bertarget) untuk menentukan kategori apa dalam fitur tersebut yang cenderung gagal membayar pinjaman lebih banyak daripada yang lain.
Di bawah ini adalah beberapa contoh grafik yang dapat dibuat menggunakan pustaka python seaborn dan fungsi sederhana yang ditentukan pengguna.
Jenis kelamin
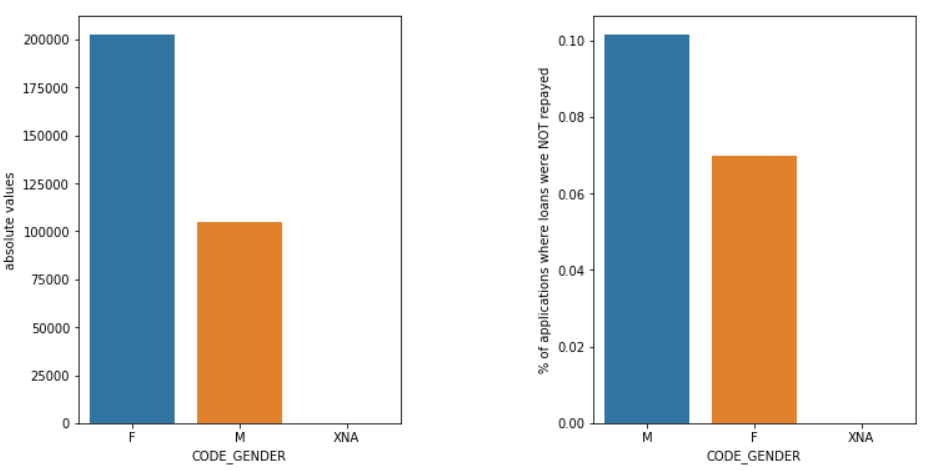
Laki-laki (L) memiliki peluang gagal bayar lebih tinggi dibandingkan dengan perempuan (P), meskipun jumlah pelamar perempuan hampir dua kali lebih banyak. Jadi perempuan lebih dapat diandalkan daripada laki-laki untuk membayar kembali pinjaman mereka.
Jenis Pendidikan
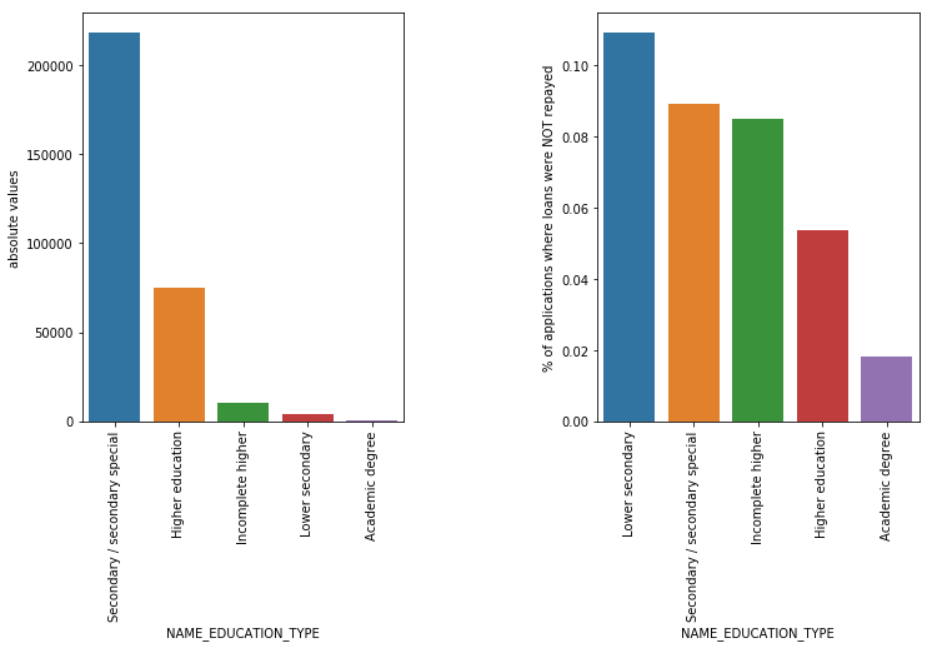
Meskipun sebagian besar pinjaman pelajar adalah untuk pendidikan menengah atau pendidikan tinggi mereka, pinjaman pendidikan menengah bawahlah yang paling berisiko bagi perusahaan diikuti oleh sekolah menengah.
Baca Juga: Karir di Ilmu Data
Kesimpulan
Analisis seperti yang terlihat di atas dilakukan secara luas dalam analisis risiko di perbankan dan layanan keuangan. Dengan cara ini arsip data dapat digunakan untuk meminimalkan risiko kehilangan uang saat meminjamkan kepada pelanggan. Cakupan EDA di semua sektor lain tidak terbatas dan harus digunakan secara luas.
Jika Anda penasaran untuk belajar tentang ilmu data, lihat PG Eksekutif IIIT-B & upGrad dalam Ilmu Data yang dibuat untuk para profesional yang bekerja dan menawarkan 10+ studi kasus & proyek, lokakarya praktis, bimbingan dengan pakar industri, 1- on-1 dengan mentor industri, 400+ jam pembelajaran dan bantuan pekerjaan dengan perusahaan-perusahaan top.
Analisis Data Eksplorasi dianggap sebagai tingkat awal saat Anda mulai memodelkan data Anda. Ini adalah teknik yang cukup mendalam untuk menganalisis praktik terbaik untuk memodelkan data Anda. Anda akan dapat mengekstrak plot visual, grafik, dan laporan dari data untuk mendapatkan pemahaman yang lengkap tentangnya. Pencilan dirujuk ke anomali atau sedikit perbedaan dalam data Anda. Itu bisa terjadi selama pengumpulan data. Ada 4 cara di mana kita dapat mendeteksi outlier dalam kumpulan data. Cara-cara tersebut adalah sebagai berikut: Tidak seperti analisis data, tidak ada aturan dan regulasi yang keras dan cepat yang harus diikuti untuk EDA. Seseorang tidak dapat mengatakan bahwa ini adalah metode yang benar atau metode yang salah untuk melakukan EDA. Pemula sering salah paham dan bingung antara EDA dan analisis data.Mengapa Analisis Data Eksplorasi (EDA) diperlukan?
EDA melibatkan langkah-langkah tertentu untuk menganalisis data secara lengkap termasuk menurunkan hasil statistik, menemukan nilai data yang hilang, menangani entri data yang salah, dan akhirnya menyimpulkan berbagai plot dan grafik.
Tujuan utama dari analisis ini adalah untuk memastikan bahwa kumpulan data yang Anda gunakan cocok untuk mulai menerapkan algoritma pemodelan. Itulah alasan mengapa ini adalah langkah pertama yang harus Anda lakukan pada data Anda sebelum pindah ke tahap pemodelan. Apa itu outlier dan bagaimana cara mengatasinya?
1. Boxplot - Boxplot adalah metode untuk mendeteksi outlier dimana kita memisahkan data melalui kuartilnya.
2. Scatterplot - Sebuah scatter plot menampilkan data dari 2 variabel berupa kumpulan titik-titik yang ditandai pada bidang kartesius. Nilai satu variabel mewakili sumbu horizontal (x-ais) dan nilai variabel lainnya mewakili sumbu vertikal (sumbu y).
3. Z-score - Saat menghitung Z-score, kami mencari titik yang jauh dari pusat dan menganggapnya sebagai outlier.
4. InterQuartile Range (IQR) - InterQuartile Range atau IQR adalah perbedaan antara kuartil atas dan bawah atau kuartil 75 dan 25, sering disebut sebagai dispersi statistik. Apa pedoman untuk melakukan EDA?
Namun, ada beberapa pedoman yang umum dilakukan:
1. Menangani nilai yang hilang
2. Menghapus data duplikat
3. Menangani outlier
4. Penskalaan dan normalisasi
5. Analisis univariat dan bivariat