
Apa itu Analisis Data Eksplorasi dengan Python? Belajar Dari Awal
Diterbitkan: 2021-03-04Analisis Data Eksplorasi atau EDA, singkatnya, terdiri dari hampir 70% Proyek Ilmu Data. EDA adalah proses eksplorasi data dengan menggunakan berbagai alat analisis untuk mendapatkan statistik inferensial dari data. Eksplorasi ini dilakukan baik dengan melihat angka biasa atau dengan memplot grafik dan grafik dari berbagai jenis.
Setiap grafik atau bagan menggambarkan cerita yang berbeda dan sudut ke data yang sama. Untuk sebagian besar analisis data dan bagian pembersihan, Pandas adalah alat yang paling banyak digunakan. Untuk visualisasi dan plotting grafik/chart, plotting library seperti Matplotlib, Seaborn dan Plotly digunakan.
EDA sangat perlu dilakukan karena membuat data mengaku kepada Anda. Seorang Data Scientist yang melakukan EDA dengan sangat baik tahu banyak tentang data dan karenanya model yang akan mereka bangun secara otomatis akan lebih baik daripada Data Scientist yang tidak melakukan EDA dengan baik.
Pada akhir tutorial ini, Anda akan mengetahui hal berikut:
- Memeriksa ikhtisar dasar data
- Memeriksa statistik deskriptif data
- Memanipulasi nama kolom dan tipe data
- Menangani nilai yang hilang & baris duplikat
- Analisis Bivariat
Daftar isi
Ikhtisar Dasar Data
Kami akan menggunakan Cars Dataset untuk tutorial ini yang dapat diunduh dari Kaggle. Langkah pertama untuk hampir semua kumpulan data adalah mengimpornya dan memeriksa ikhtisar dasarnya – bentuknya, kolom, jenis kolom, 5 baris teratas, dll. Langkah ini memberi Anda gambaran singkat tentang data yang akan Anda kerjakan. Mari kita lihat bagaimana melakukan ini dengan Python.
| # Mengimpor perpustakaan yang diperlukan impor panda sebagai pd impor numpy sebagai np impor seaborn sebagai sns #visualization impor matplotlib.pyplot sebagai plt #visualization %matplotlib sebaris sns.set(kode_warna= Benar ) |
Kepala & Ekor Data
| data = pd.read_csv( “jalur/dataset.csv” ) # Periksa 5 baris teratas dari kerangka data data.head() |
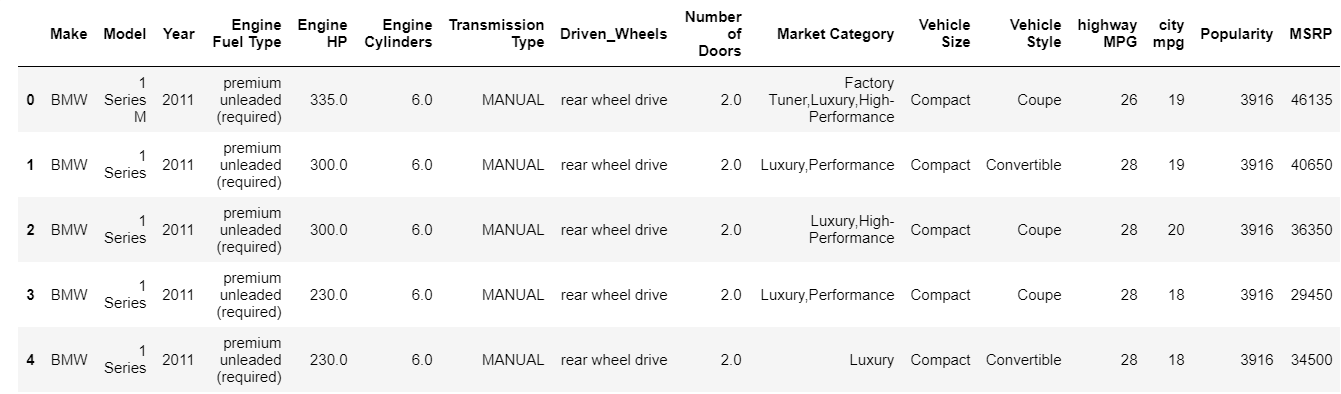
Fungsi kepala mencetak 5 indeks teratas dari bingkai data secara default. Anda juga dapat menentukan berapa banyak indeks teratas yang perlu Anda lihat melewati nilai itu ke kepala. Mencetak kepala secara instan memberi kita gambaran sekilas tentang jenis data yang kita miliki, jenis fitur apa yang ada, dan nilai apa yang dikandungnya. Tentu saja, ini tidak menceritakan keseluruhan cerita tentang data, tetapi ini memberi Anda gambaran singkat tentang data tersebut. Anda juga dapat mencetak bagian bawah bingkai data dengan menggunakan fungsi ekor.
| # Cetak 10 baris terakhir dari kerangka data data.ekor( 10 ) |
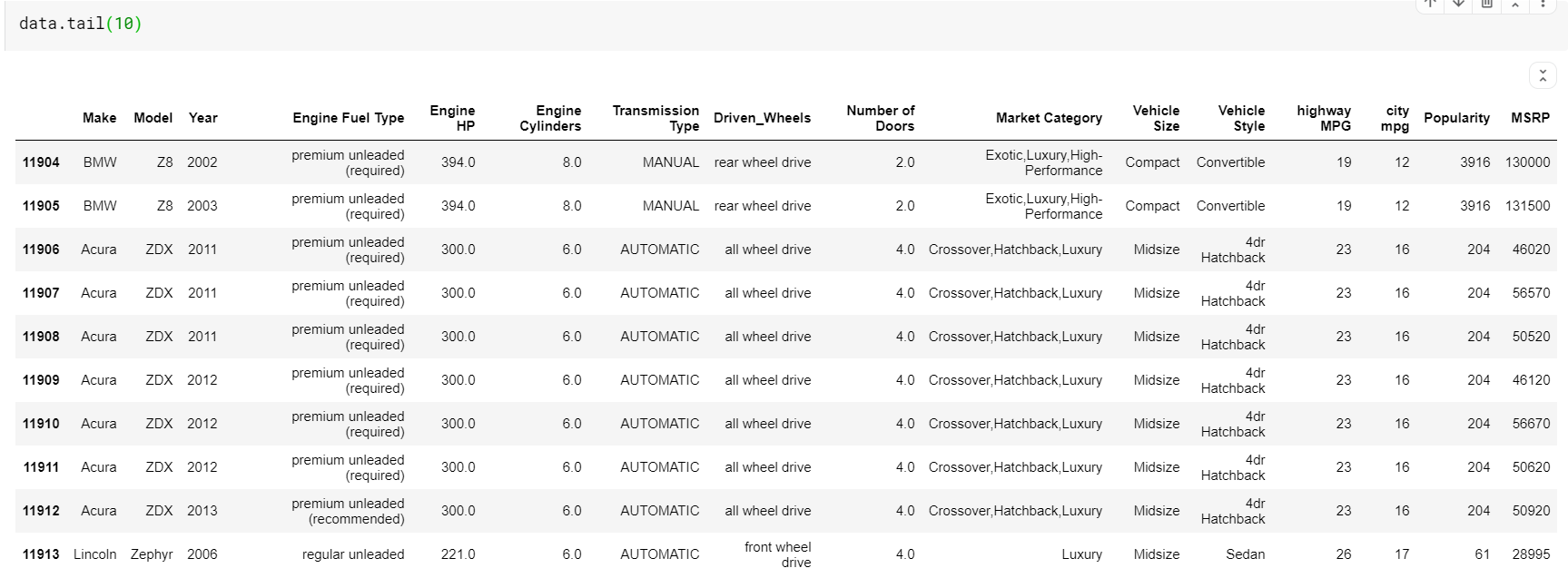
Satu hal yang perlu diperhatikan di sini adalah bahwa kedua fungsi-kepala dan ekor memberi kita indeks atas atau bawah. Tetapi baris atas atau bawah tidak selalu merupakan pratinjau data yang baik. Jadi, Anda juga dapat mencetak sejumlah baris yang diambil sampelnya secara acak dari kumpulan data menggunakan fungsi sample().
| # Cetak 5 baris acak data.contoh( 5 ) |
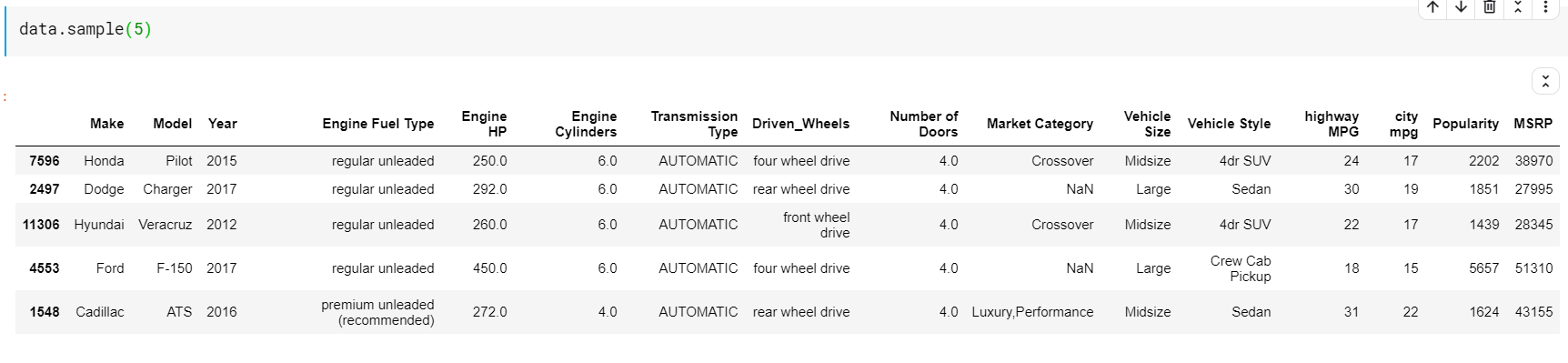
Statistik deskriptif
Selanjutnya, mari kita periksa statistik deskriptif dari kumpulan data. Statistik deskriptif terdiri dari segala sesuatu yang "menggambarkan" kumpulan data. Kami memeriksa bentuk bingkai data, semua kolom apa yang ada, semua fitur numerik dan kategoris apa yang ada. Kita juga akan melihat bagaimana melakukan semua ini dalam fungsi sederhana.
Membentuk
| # Mengecek bentuk dataframe (mxn) # m=jumlah baris # n=jumlah kolom data.shape |

Seperti yang kita lihat, bingkai data ini berisi 11.914 baris dan 16 kolom.
kolom
| # Cetak nama kolom data.columns |
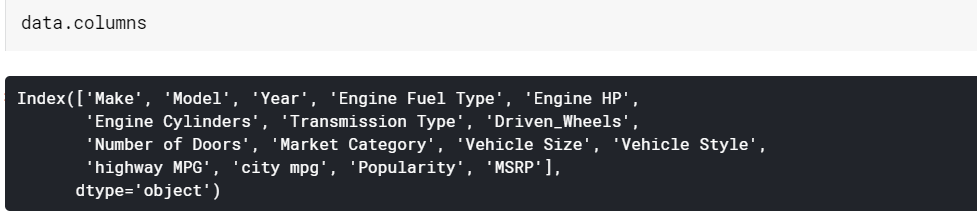
Informasi kerangka data
| # Cetak tipe data kolom dan jumlah nilai yang tidak hilang data.info() |
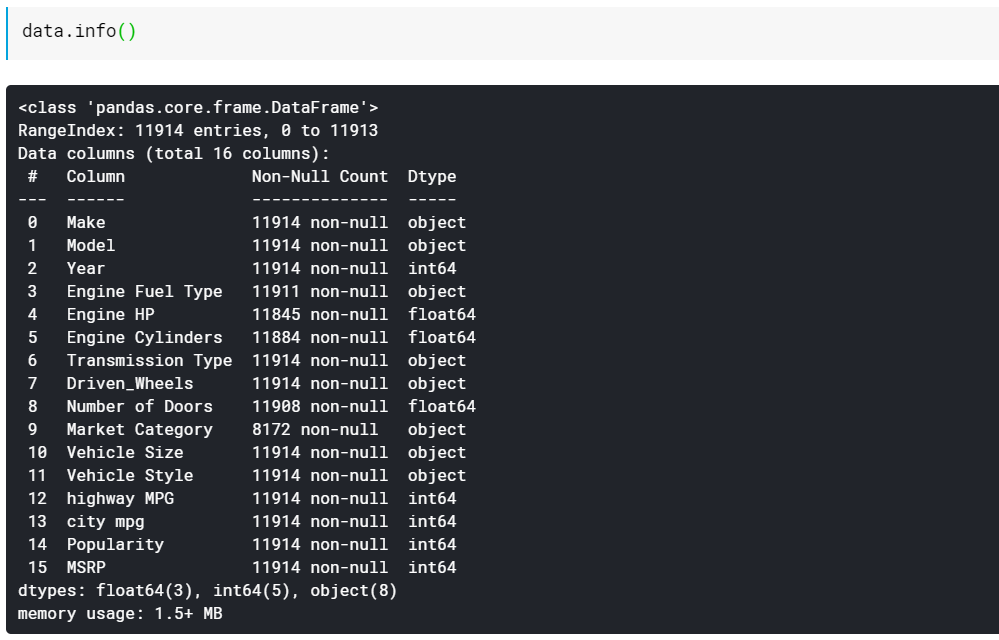
Seperti yang Anda lihat, fungsi info() memberi kita semua kolom, berapa banyak nilai non-null atau non-missing yang ada di kolom tersebut dan terakhir tipe data kolom tersebut. Ini adalah cara cepat yang bagus untuk melihat semua fitur numerik dan semuanya berbasis kategori/teks. Juga, kami sekarang memiliki informasi tentang apa yang semua kolom memiliki nilai yang hilang. Kita akan melihat bagaimana bekerja dengan nilai-nilai yang hilang nanti.
Memanipulasi Nama Kolom dan Tipe Data
Memeriksa dan memanipulasi setiap kolom dengan hati-hati sangat penting dalam EDA. Kita perlu melihat semua jenis konten yang berisi kolom/fitur dan apa yang panda membaca tipe datanya. Tipe data numerik sebagian besar adalah int64 atau float64. Fitur berbasis teks atau kategoris diberi tipe data 'objek'.
Fitur berbasis tanggal-waktu ditetapkan Ada kalanya Panda tidak memahami tipe data fitur. Dalam kasus seperti itu, itu hanya dengan malas memberinya tipe data 'objek'. Kita dapat menentukan tipe data kolom secara eksplisit saat membaca data dengan read_csv.
Memilih Kolom Kategoris dan Numerik
| # Tambahkan semua kolom kategoris dan numerik ke daftar terpisah categorical = data.select_dtypes( 'objek' ).columns numerik = data.select_dtypes( 'angka' ).columns |


Di sini tipe yang kita lewati sebagai 'angka' memilih semua kolom dengan tipe data yang memiliki jenis angka apa pun- baik itu int64 atau float64.
Mengganti Nama Kolom
| # Mengganti nama kolom nama data = data.rename(columns={ “Mesin HP” : “HP” , “Silinder Mesin” : “Silinder” , “Jenis Transmisi” : “Transmisi” , “Driven_Wheels” : “Mode Berkendara” , “jalan raya MPG” : “MPG-H” , “MSRP” : “Harga” }) data.head( 5 ) |

Fungsi rename hanya mengambil kamus dengan nama kolom yang akan diganti namanya dan nama barunya.
Menangani Nilai yang Hilang dan Baris Duplikat
Nilai yang hilang adalah salah satu masalah/perbedaan paling umum dalam kumpulan data kehidupan nyata. Menangani nilai yang hilang itu sendiri merupakan topik yang luas karena ada banyak cara untuk melakukannya. Beberapa cara adalah cara yang lebih umum, dan beberapa lebih spesifik untuk kumpulan data yang mungkin dihadapi.
Memeriksa Nilai yang Hilang
| # Memeriksa nilai yang hilang data.isnull().jumlah() |
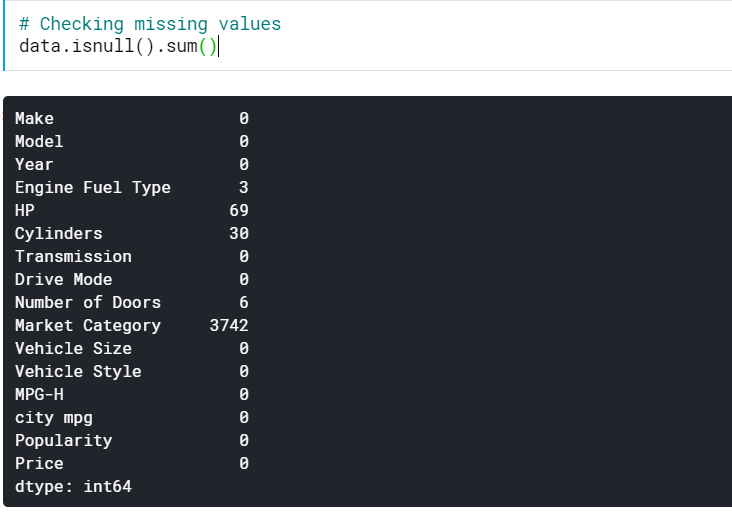
Ini memberi kita jumlah nilai yang hilang di semua kolom. Kita juga bisa melihat persentase nilai yang hilang.
| # Persentase nilai yang hilang data.isnull().mean()* 100 |
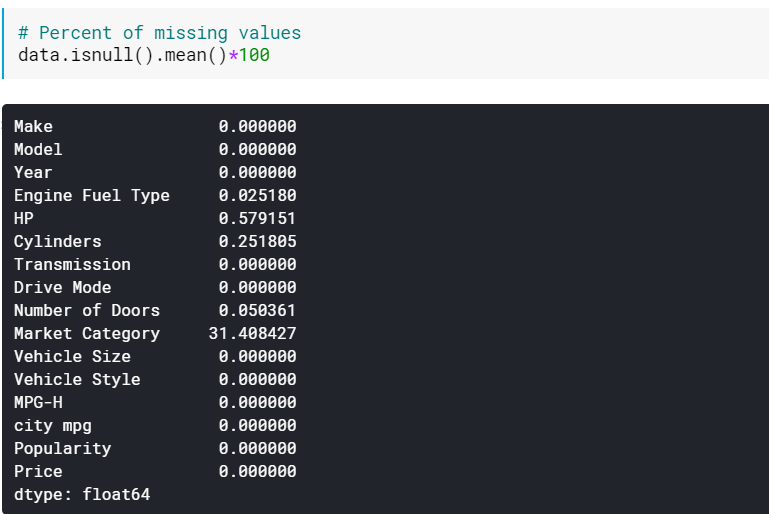
Memeriksa persentase mungkin berguna ketika ada banyak kolom yang memiliki nilai yang hilang. Dalam kasus seperti itu, kolom dengan banyak nilai yang hilang (misalnya, >60% hilang) dapat dibuang begitu saja.
Menghitung Nilai yang Hilang
| #Menghitung nilai yang hilang dari kolom numerik dengan rata-rata data[numerik] = data[numerik].fillna(data[numerik].mean().iloc[ 0 ]) #Menghitung nilai yang hilang dari kolom kategoris berdasarkan mode data[kategorikal] = data[kategorikal].isian(data[kategorikal].mode().iloc[ 0 ]) |
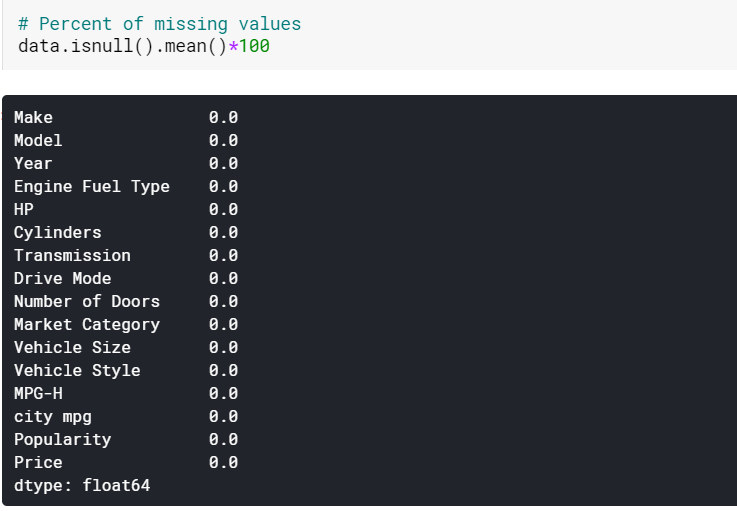
Di sini kita cukup menghitung nilai yang hilang di kolom numerik dengan cara masing-masing dan nilai di kolom kategoris dengan modenya. Dan seperti yang bisa kita lihat, tidak ada nilai yang hilang sekarang.
Harap dicatat bahwa ini adalah cara paling primitif untuk memasukkan nilai dan tidak berfungsi dalam kasus kehidupan nyata di mana cara yang lebih canggih dikembangkan, misalnya, interpolasi, KNN, dll.
Menangani Baris Duplikat
| # Jatuhkan baris duplikat data.drop_duplicates(inplace= True ) |
Ini hanya menjatuhkan baris duplikat.
Lihat: Ide & Topik Proyek Python
Analisis Bivariat
Sekarang mari kita lihat bagaimana mendapatkan lebih banyak wawasan dengan melakukan analisis bivariat. Bivariat berarti analisis yang terdiri dari 2 variabel atau fitur. Ada berbagai jenis plot yang tersedia untuk berbagai jenis fitur.
Untuk Numerik – Numerik
- Plot sebar
- Plot garis
- Peta panas untuk korelasi
Untuk Kategori-Numerik
- Grafik batang
- Plot biola
- plot kawanan
Untuk Kategoris-Kategoris
- Grafik batang
- plot titik
Peta Panas untuk Korelasi
| # Memeriksa korelasi antar variabel. plt.figure(figsize=( 15 , 10 )) c= data.corr() sns.heatmap(c,cmap= “BrBG” ,annot= Benar ) |
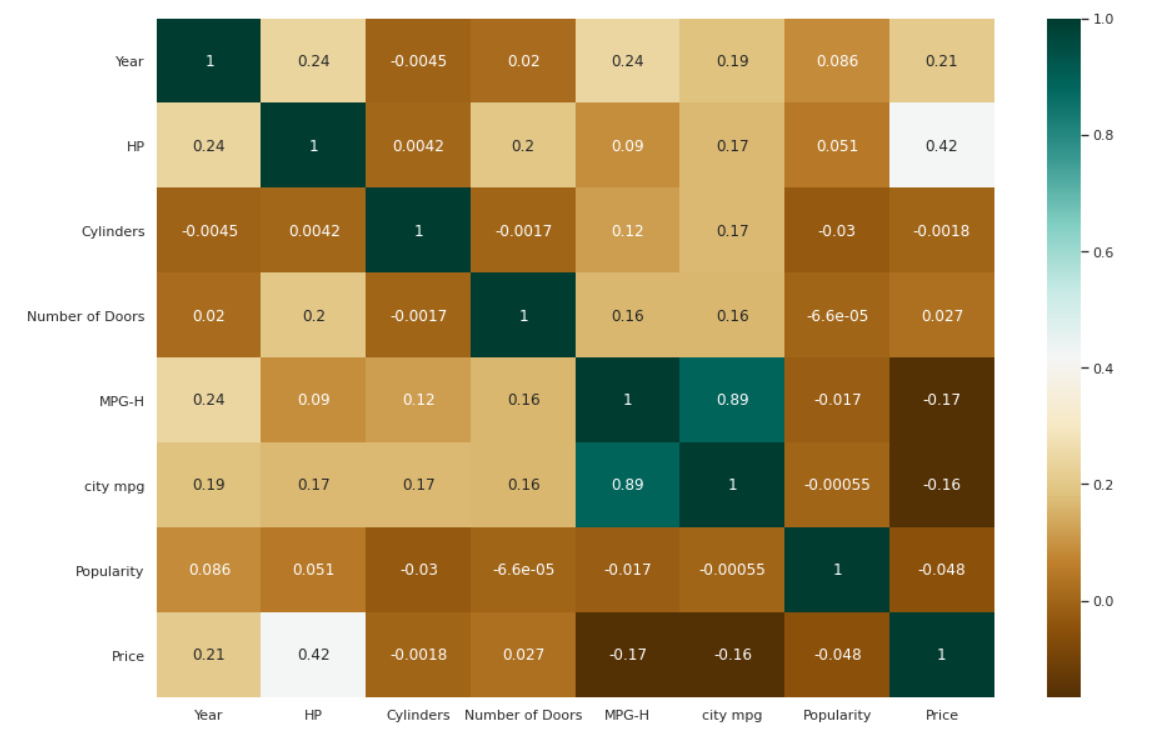
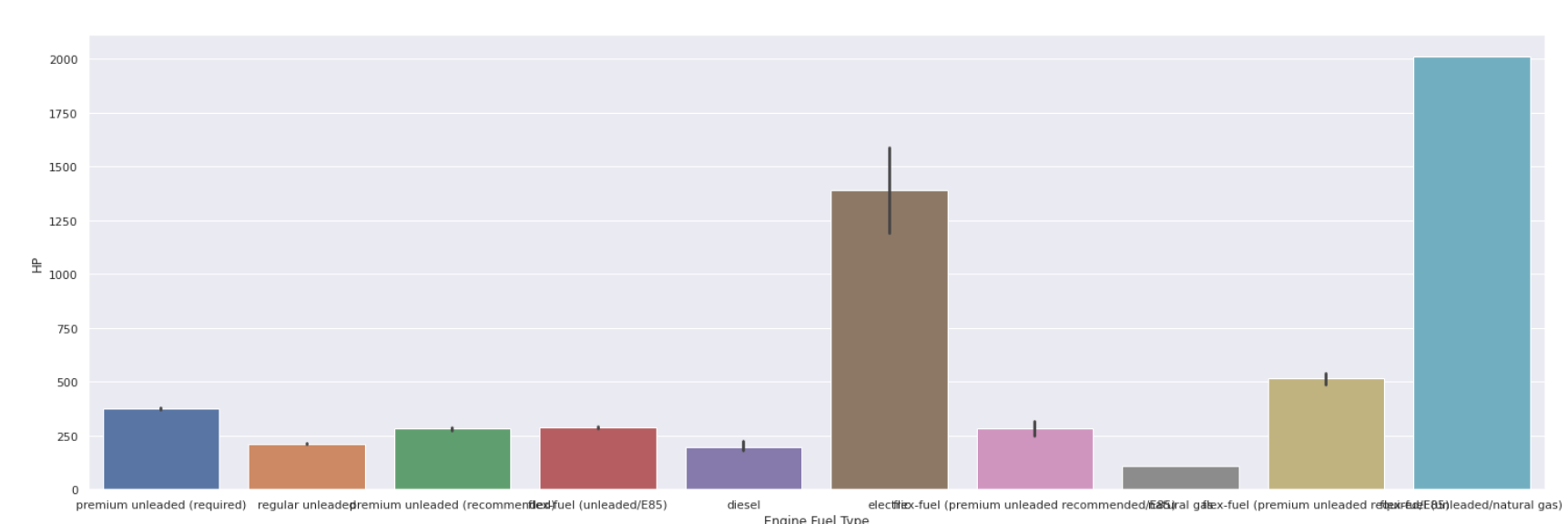
Plot Bar
| sns.barplot(data[ 'Jenis Bahan Bakar Mesin' ], data[ 'HP' ]) |
Dapatkan sertifikasi ilmu data dari Universitas top dunia. Pelajari Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karir Anda.
Kesimpulan
Seperti yang kita lihat, ada banyak langkah yang harus dibahas saat menjelajahi kumpulan data. Kami hanya membahas beberapa aspek dalam tutorial ini tetapi ini akan memberi Anda lebih dari sekadar pengetahuan dasar tentang EDA yang baik.
Jika Anda penasaran untuk belajar tentang Python, segala sesuatu tentang ilmu data, lihat IIIT-B & upGrad's PG Diploma in Data Science yang dibuat untuk para profesional yang bekerja dan menawarkan 10+ studi kasus & proyek, lokakarya praktis, bimbingan dengan industri pakar, tatap muka dengan mentor industri, 400+ jam pembelajaran dan bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa saja langkah-langkah dalam analisis data eksplorasi?
Langkah-langkah utama yang perlu Anda lakukan untuk melakukan analisis data eksplorasi adalah -
Variabel dan tipe data harus diidentifikasi.
Menganalisis metrik dasar
Analisis Non-Grafis Univariat
Analisis Grafis Univariat
Analisis Data Bivariat
Transformasi yang berubah-ubah
Perawatan untuk nilai yang hilang
Perawatan outlier
Analisis Korelasi
Pengurangan Dimensi
Apa tujuan dari analisis data eksplorasi?
Tujuan utama EDA adalah untuk membantu dalam analisis data sebelum membuat asumsi apapun. Ini dapat membantu dalam mendeteksi kesalahan yang jelas, serta pemahaman yang lebih baik tentang pola data, deteksi outlier atau kejadian yang tidak biasa, dan penemuan hubungan yang menarik antara variabel.
Analisis eksplorasi dapat digunakan oleh ilmuwan data untuk menjamin bahwa hasil yang mereka buat akurat dan sesuai dengan hasil dan tujuan bisnis yang ditargetkan. EDA juga membantu pemangku kepentingan dengan memastikan bahwa mereka menjawab pertanyaan yang sesuai. Standar deviasi, data kategorikal, dan interval kepercayaan semua dapat dijawab dengan EDA. Setelah selesainya EDA dan ekstraksi wawasan, fitur-fiturnya dapat diterapkan ke analisis atau pemodelan data yang lebih canggih, termasuk pembelajaran mesin.
Apa saja jenis-jenis analisis data eksplorasi?
Ada dua macam teknik EDA: grafis dan kuantitatif (non-grafis). Pendekatan kuantitatif, di sisi lain, membutuhkan kompilasi statistik ringkasan, sedangkan metode grafis memerlukan pengumpulan data secara diagram atau visual. Pendekatan univariat dan multivariat adalah bagian dari kedua jenis metodologi ini.
Untuk menyelidiki hubungan, pendekatan univariat melihat satu variabel (kolom data) pada satu waktu, sedangkan metode multivariat melihat dua atau lebih variabel sekaligus. Grafis dan non-grafis univariat dan multivariat adalah empat bentuk EDA. Prosedur kuantitatif lebih objektif, sedangkan metode bergambar lebih subjektif.