
Panduan Pengikisan Etis Situs Web Dinamis Dengan Node.js Dan Dalang
Diterbitkan: 2022-03-10Mari kita mulai dengan sedikit bagian tentang apa sebenarnya arti dari web scraping. Kita semua menggunakan scraping web dalam kehidupan sehari-hari. Ini hanya menggambarkan proses penggalian informasi dari sebuah situs web. Oleh karena itu, jika Anda menyalin dan menempelkan resep hidangan mie favorit Anda dari internet ke buku catatan pribadi Anda, Anda sedang melakukan pengikisan web .
Saat menggunakan istilah ini dalam industri perangkat lunak, kami biasanya mengacu pada otomatisasi tugas manual ini dengan menggunakan perangkat lunak. Berpegang pada contoh "hidangan mie" kami sebelumnya, proses ini biasanya melibatkan dua langkah:
- Mengambil halaman
Pertama kita harus mendownload halaman secara keseluruhan. Langkah ini seperti membuka halaman di browser web Anda saat menggores secara manual. - Mengurai data
Sekarang, kita harus mengekstrak resep dalam HTML situs web dan mengubahnya menjadi format yang dapat dibaca mesin seperti JSON atau XML.
Di masa lalu, saya telah bekerja di banyak perusahaan sebagai konsultan data. Saya kagum melihat betapa banyak tugas ekstraksi data, agregasi, dan pengayaan yang masih dilakukan secara manual meskipun mereka dapat dengan mudah diotomatisasi hanya dengan beberapa baris kode. Itulah gunanya pengikisan web bagi saya: mengekstrak dan menormalkan potongan informasi berharga dari situs web untuk mendorong proses bisnis penggerak nilai lainnya.
Selama waktu ini, saya melihat perusahaan menggunakan scraping web untuk semua jenis kasus penggunaan. Perusahaan investasi terutama berfokus pada pengumpulan data alternatif, seperti ulasan produk , informasi harga, atau postingan media sosial untuk mendukung investasi keuangan mereka.
Berikut salah satu contohnya. Seorang klien mendekati saya untuk mengikis data ulasan produk untuk daftar lengkap produk dari beberapa situs web e-niaga, termasuk peringkat, lokasi pengulas, dan teks ulasan untuk setiap ulasan yang dikirimkan. Data hasil memungkinkan klien untuk mengidentifikasi tren tentang popularitas produk di pasar yang berbeda. Ini adalah contoh yang sangat baik tentang bagaimana satu informasi yang tampaknya "tidak berguna" dapat menjadi berharga jika dibandingkan dengan jumlah yang lebih besar.
Perusahaan lain mempercepat proses penjualan mereka dengan menggunakan web scraping untuk menghasilkan lead . Proses ini biasanya melibatkan penggalian informasi kontak seperti nomor telepon, alamat email, dan nama kontak untuk daftar situs web tertentu. Mengotomatiskan tugas ini memberi tim penjualan lebih banyak waktu untuk mendekati prospek. Oleh karena itu, efisiensi proses penjualan meningkat.
Tetap Pada Aturan
Secara umum, web scraping data yang tersedia untuk umum adalah legal, sebagaimana dikonfirmasi oleh yurisdiksi kasus Linkedin vs. HiQ. Namun, saya telah menetapkan sendiri seperangkat aturan etis yang ingin saya patuhi saat memulai proyek pengikisan web baru. Ini termasuk:
- Memeriksa file robots.txt.
Biasanya berisi informasi yang jelas tentang bagian mana dari situs pemilik halaman yang boleh diakses oleh robot & scraper dan menyoroti bagian yang tidak boleh diakses. - Membaca syarat dan ketentuan.
Dibandingkan dengan robots.txt, informasi ini tidak terlalu sering tersedia, tetapi biasanya menyatakan bagaimana mereka memperlakukan pengikis data. - Menggores dengan kecepatan sedang.
Scraping menciptakan beban server pada infrastruktur situs target. Bergantung pada apa yang Anda kikis dan pada tingkat konkurensi mana pengikis Anda beroperasi, lalu lintas dapat menyebabkan masalah untuk infrastruktur server situs target. Tentu saja, kapasitas server memainkan peran besar dalam persamaan ini. Oleh karena itu, kecepatan scraper saya selalu seimbang antara jumlah data yang ingin saya kikis dan popularitas situs target. Menemukan keseimbangan ini dapat dicapai dengan menjawab satu pertanyaan: "Apakah kecepatan yang direncanakan akan secara signifikan mengubah lalu lintas organik situs?". Dalam kasus di mana saya tidak yakin tentang jumlah lalu lintas alami situs, saya menggunakan alat seperti ahrefs untuk mendapatkan gambaran kasar.
Memilih Teknologi yang Tepat
Faktanya, scraping dengan browser headless adalah salah satu teknologi berkinerja paling rendah yang dapat Anda gunakan, karena sangat memengaruhi infrastruktur Anda. Satu inti dari prosesor mesin Anda kira-kira dapat menangani satu instance Chrome.
Mari kita lakukan perhitungan contoh cepat untuk melihat apa artinya ini bagi proyek pengikisan web dunia nyata.
Skenario
- Anda ingin mengikis 20.000 URL.
- Waktu respons rata-rata dari situs target adalah 6 detik.
- Server Anda memiliki 2 inti CPU.
Proyek ini akan memakan waktu 16 jam untuk diselesaikan.
Oleh karena itu, saya selalu berusaha menghindari penggunaan browser saat melakukan uji kelayakan scraping untuk situs web dinamis.
Berikut adalah daftar periksa kecil yang selalu saya lalui:
- Bisakah saya memaksakan status halaman yang diperlukan melalui parameter GET di URL? Jika ya, kita cukup menjalankan permintaan HTTP dengan parameter yang ditambahkan.
- Apakah informasi dinamis merupakan bagian dari sumber halaman dan tersedia melalui objek JavaScript di suatu tempat di DOM? Jika ya, kita dapat kembali menggunakan permintaan HTTP normal dan mengurai data dari objek string.
- Apakah data diambil melalui permintaan XHR? Jika demikian, dapatkah saya mengakses titik akhir secara langsung dengan klien HTTP? Jika ya, kami dapat mengirim permintaan HTTP ke titik akhir secara langsung. Sering kali, responsnya bahkan diformat dalam JSON, yang membuat hidup kita lebih mudah.
Jika semua pertanyaan dijawab dengan “Tidak” yang pasti, kami secara resmi kehabisan opsi yang layak untuk menggunakan klien HTTP. Tentu saja, mungkin ada lebih banyak penyesuaian khusus situs yang dapat kami coba, tetapi biasanya, waktu yang diperlukan untuk memahaminya terlalu tinggi, dibandingkan dengan kinerja browser tanpa kepala yang lebih lambat. Keindahan menggores dengan browser adalah Anda dapat mengikis apa pun yang tunduk pada aturan dasar berikut:
Jika Anda dapat mengaksesnya dengan browser, Anda dapat mengikisnya.
Mari kita ambil situs berikut sebagai contoh scraper kita: https://quotes.toscrape.com/search.aspx. Ini fitur kutipan dari daftar penulis yang diberikan untuk daftar topik. Semua data diambil melalui XHR.
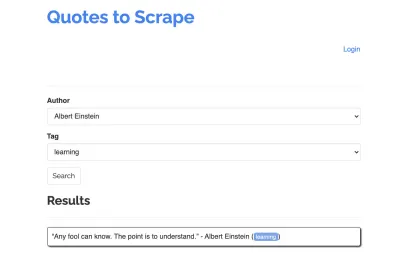
Siapa pun yang melihat dari dekat fungsi situs dan memeriksa daftar periksa di atas mungkin menyadari bahwa kutipan sebenarnya dapat dikikis menggunakan klien HTTP, karena dapat diambil dengan membuat permintaan POST pada titik akhir kutipan secara langsung. Tetapi karena tutorial ini seharusnya membahas cara mengikis situs web menggunakan Dalang, kami akan berpura-pura ini tidak mungkin.
Menginstal Prasyarat
Karena kita akan membangun semuanya menggunakan Node.js, pertama-tama mari kita buat dan buka folder baru, dan buat proyek Node baru di dalamnya, jalankan perintah berikut:
mkdir js-webscraper cd js-webscraper npm initPastikan Anda sudah menginstal npm. Pemasang akan menanyakan beberapa pertanyaan tentang meta-informasi tentang proyek ini, yang dapat kita lewati, tekan Enter .
Memasang Wayang
Kami telah berbicara tentang menggores dengan browser sebelumnya. Puppeteer adalah API Node.js yang memungkinkan kita untuk berbicara dengan instance Chrome tanpa kepala secara terprogram.
Mari kita instal menggunakan npm:
npm install puppeteerMembangun Scraper Kami
Sekarang, mari kita mulai membuat scraper dengan membuat file baru, bernama scraper.js .
Pertama, kami mengimpor perpustakaan yang diinstal sebelumnya, Dalang:
const puppeteer = require('puppeteer');Sebagai langkah selanjutnya, kami memberi tahu Puppeteer untuk membuka instance browser baru di dalam fungsi asinkron dan menjalankan sendiri:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();Catatan : Secara default, mode tanpa kepala dimatikan, karena ini meningkatkan kinerja. Namun, saat membuat scraper baru, saya suka mematikan mode tanpa kepala. Ini memungkinkan kami untuk mengikuti proses yang sedang dilalui browser dan melihat semua konten yang dirender. Ini akan membantu kami men-debug skrip kami nanti.
Di dalam instance browser kami yang dibuka, kami sekarang membuka halaman baru dan mengarahkan ke URL target kami:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); Sebagai bagian dari fungsi asinkron, kita akan menggunakan pernyataan await untuk menunggu perintah berikut dijalankan sebelum melanjutkan dengan baris kode berikutnya.
Sekarang kita telah berhasil membuka jendela browser dan menavigasi ke halaman, kita harus membuat status situs web , sehingga potongan informasi yang diinginkan menjadi terlihat untuk digores.
Topik yang tersedia dihasilkan secara dinamis untuk penulis yang dipilih. Oleh karena itu, pertama-tama kita akan memilih 'Albert Einstein' dan menunggu daftar topik yang dihasilkan. Setelah daftar dibuat sepenuhnya, kami memilih 'belajar' sebagai topik dan memilihnya sebagai parameter bentuk kedua. Kami kemudian klik kirim dan ekstrak kutipan yang diambil dari wadah yang menampung hasil.

Karena sekarang kita akan mengubahnya menjadi logika JavaScript, pertama-tama mari kita buat daftar semua pemilih elemen yang telah kita bicarakan di paragraf sebelumnya:
| Bidang pilih penulis | #author |
| Tag pilih bidang | #tag |
| tombol kirim | input[type="submit"] |
| wadah kutipan | .quote |
Sebelum kita mulai berinteraksi dengan halaman, kita akan memastikan bahwa semua elemen yang akan kita akses terlihat, dengan menambahkan baris berikut ke skrip kita:
await page.waitForSelector('#author'); await page.waitForSelector('#tag');Selanjutnya, kami akan memilih nilai untuk dua bidang pilihan kami:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');Kami sekarang siap untuk melakukan pencarian kami dengan menekan tombol "Cari" di halaman dan menunggu kutipan muncul:
await page.click('.btn'); await page.waitForSelector('.quote'); Karena kita sekarang akan mengakses struktur DOM HTML halaman, kita memanggil fungsi page.evaluate() yang disediakan, memilih wadah yang menyimpan tanda kutip (hanya satu dalam kasus ini). Kami kemudian membangun sebuah objek dan mendefinisikan null sebagai nilai mundur untuk setiap parameter object :
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });Kami dapat membuat semua hasil terlihat di konsol kami dengan mencatatnya:
console.log(quotes);Terakhir, mari tutup browser kita dan tambahkan pernyataan catch:
await browser.close();Scraper lengkap terlihat seperti berikut:
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();Mari kita coba menjalankan scraper kita dengan:
node scraper.jsDan di sana kita pergi! Scraper mengembalikan objek kutipan kami seperti yang diharapkan:
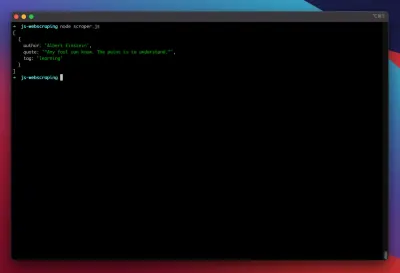
Pengoptimalan Tingkat Lanjut
Scraper dasar kami sekarang berfungsi. Mari tambahkan beberapa perbaikan untuk mempersiapkannya untuk beberapa tugas pengikisan yang lebih serius.
Menyetel Agen-Pengguna
Secara default, Dalang menggunakan agen pengguna yang berisi string HeadlessChrome . Beberapa situs web mencari tanda tangan semacam ini dan memblokir permintaan masuk dengan tanda tangan seperti itu. Untuk menghindari hal itu menjadi alasan potensial untuk scraper gagal, saya selalu menetapkan agen pengguna khusus dengan menambahkan baris berikut ke kode kami:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');Ini dapat ditingkatkan lebih jauh lagi dengan memilih agen pengguna acak dengan setiap permintaan dari serangkaian 5 agen pengguna teratas yang paling umum. Daftar agen pengguna yang paling umum dapat ditemukan di bagian Agen Pengguna Paling Umum.
Menerapkan Proxy
Dalang membuat koneksi ke proxy menjadi sangat mudah, karena alamat proxy dapat diteruskan ke Dalang saat diluncurkan, seperti ini:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxies menyediakan daftar besar proxy gratis yang dapat Anda gunakan. Atau, layanan proxy berputar dapat digunakan. Karena proxy biasanya dibagikan di antara banyak pelanggan (atau pengguna gratis dalam kasus ini), koneksi menjadi jauh lebih tidak dapat diandalkan daripada yang sudah ada dalam keadaan normal. Ini adalah saat yang tepat untuk berbicara tentang penanganan kesalahan dan manajemen coba lagi.
Kesalahan Dan Coba Lagi-Manajemen
Banyak faktor yang dapat menyebabkan scraper Anda gagal. Oleh karena itu, penting untuk menangani kesalahan dan memutuskan apa yang harus terjadi jika terjadi kegagalan. Karena kami telah menghubungkan scraper kami ke proxy dan mengharapkan koneksi menjadi tidak stabil (terutama karena kami menggunakan proxy gratis), kami ingin mencoba lagi empat kali sebelum menyerah.
Juga, tidak ada gunanya mencoba kembali permintaan dengan alamat IP yang sama jika sebelumnya gagal. Oleh karena itu, kita akan membangun sistem rotasi proxy kecil.
Pertama-tama, kami membuat dua variabel baru:
let retry = 0; let maxRetries = 5; Setiap kali kita menjalankan fungsi scrape() , kita akan meningkatkan variabel coba lagi sebesar 1. Kemudian kita membungkus logika scraping lengkap kita dengan pernyataan try and catch sehingga kita dapat menangani kesalahan. Manajemen coba lagi terjadi di dalam fungsi catch kami:
Instance browser sebelumnya akan ditutup, dan jika variabel retry kami lebih kecil dari variabel maxRetries kami, fungsi scrape dipanggil secara rekursif.
Scraper kami sekarang akan terlihat seperti ini:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };Sekarang, mari kita tambahkan rotator proxy yang disebutkan sebelumnya.
Pertama-tama mari kita buat array yang berisi daftar proxy:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];Sekarang, pilih nilai acak dari array:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];Kami sekarang dapat menjalankan proxy yang dihasilkan secara dinamis bersama dengan instance Dalang kami:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });Tentu saja, rotator proxy ini dapat lebih dioptimalkan untuk menandai proxy mati, dan seterusnya, tetapi ini pasti akan melampaui cakupan tutorial ini.
Ini adalah kode scraper kami (termasuk semua peningkatan):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();Voila! Menjalankan scraper kami di dalam terminal kami akan mengembalikan tanda kutip.
Penulis Drama Sebagai Alternatif Untuk Dalang
Dalang dikembangkan oleh Google. Pada awal tahun 2020, Microsoft merilis alternatif bernama Playwright. Microsoft merekrut banyak insinyur dari Tim Dalang. Oleh karena itu, Playwright dikembangkan oleh banyak insinyur yang sudah mulai mengerjakan Puppeteer. Selain sebagai anak baru di blog, poin pembeda terbesar Playwright adalah dukungan lintas-browser, karena mendukung Chromium, Firefox, dan WebKit (Safari).
Tes kinerja (seperti yang dilakukan oleh Checkly ini) menunjukkan bahwa Dalang umumnya memberikan kinerja sekitar 30% lebih baik, dibandingkan dengan Playwright, yang sesuai dengan pengalaman saya sendiri — setidaknya pada saat penulisan.
Perbedaan lain, seperti fakta bahwa Anda dapat menjalankan beberapa perangkat dengan satu browser, tidak terlalu berharga untuk konteks web scraping.
Sumber Daya Dan Tautan Tambahan
- Dokumentasi Dalang
- Belajar Dalang & Penulis Drama
- Pengikisan Web dengan Javascript oleh Zenscrape
- Agen Pengguna Paling Umum
- Dalang vs. Penulis Drama