
Lembar Cheat Ilmu Data Utama Yang Harus Dimiliki Setiap Ilmuwan Data
Diterbitkan: 2021-01-29Untuk semua profesional pemula dan pemula yang berpikir untuk terjun ke dunia ilmu data yang sedang booming, kami telah menyusun lembar contekan cepat untuk membuat Anda mempelajari dasar-dasar dan metodologi yang menggarisbawahi bidang ini.
Daftar isi
Ilmu Data-Dasar-Dasarnya
Data yang dihasilkan di dunia kita dalam bentuk mentah, yaitu, angka, kode, kata, kalimat, dll. Data Science mengambil data yang sangat mentah ini untuk memprosesnya menggunakan metode ilmiah untuk mengubahnya menjadi bentuk yang bermakna untuk mendapatkan pengetahuan dan wawasan .
Data
Sebelum kita menyelami prinsip-prinsip ilmu data, mari kita bicara sedikit tentang data, jenisnya, dan pemrosesan data.
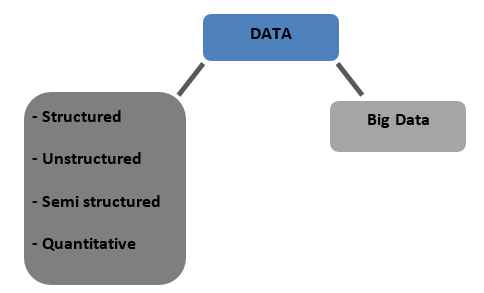
Jenis Data
Terstruktur – Data yang disimpan dalam format tabulasi dalam database. Itu bisa berupa angka atau teks
Tidak terstruktur – Data yang tidak dapat ditabulasi dengan struktur definitif untuk dibicarakan disebut data tidak terstruktur
Semi-terstruktur – Data campuran dengan ciri-ciri data terstruktur dan tidak terstruktur
Kuantitatif – Data dengan nilai numerik tertentu yang dapat dikuantifikasi
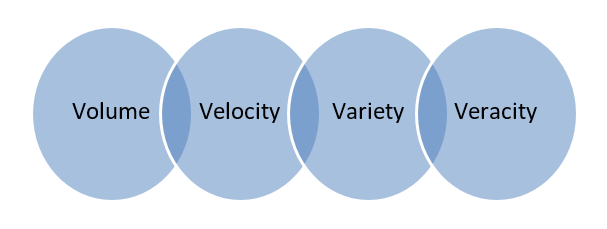
Big Data – Data yang disimpan dalam database besar yang mencakup banyak komputer atau server farm disebut Big Data. Data biometrik, data media sosial, dll. dianggap Big Data. Data besar dicirikan oleh 4 V's
Prapemrosesan Data
Klasifikasi Data – Ini adalah proses mengkategorikan atau melabeli data ke dalam kelas seperti numerik, tekstual atau gambar, teks, video, dll.
Pembersihan Data – Ini terdiri dari menghilangkan data yang hilang/tidak konsisten/tidak kompatibel atau mengganti data menggunakan salah satu metode berikut.
- Interpolasi
- Heuristis
- Tugas acak
- Tetangga Terdekat
Data Masking – Menyembunyikan atau menutupi data rahasia untuk menjaga privasi informasi sensitif sambil tetap dapat memprosesnya.
Terbuat dari Apa Ilmu Data?
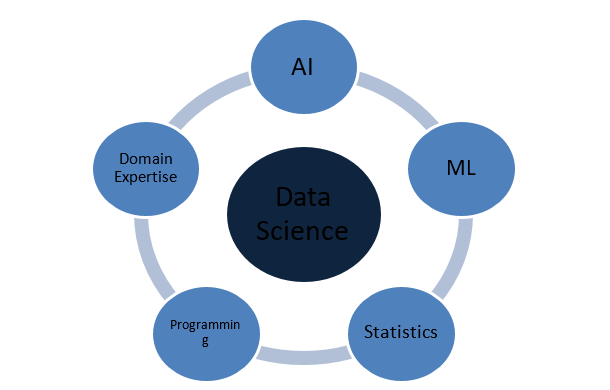
Konsep Statistik
Regresi
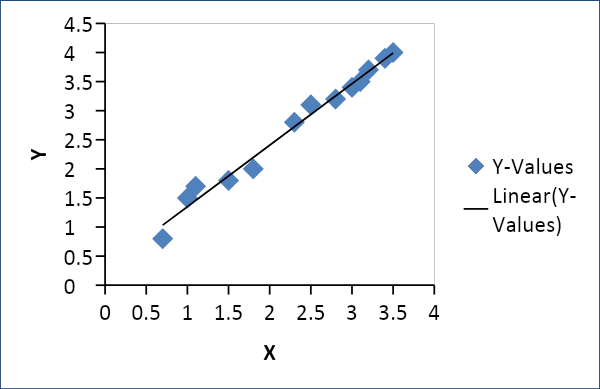
Regresi linier
Regresi Linier digunakan untuk membangun hubungan antara dua variabel seperti penawaran dan permintaan, harga dan konsumsi, dll. Regresi ini menghubungkan satu variabel x sebagai fungsi linier dari variabel lain y sebagai berikut
Y = f(x) atau Y =mx + c, di mana m = koefisien
Regresi logistik
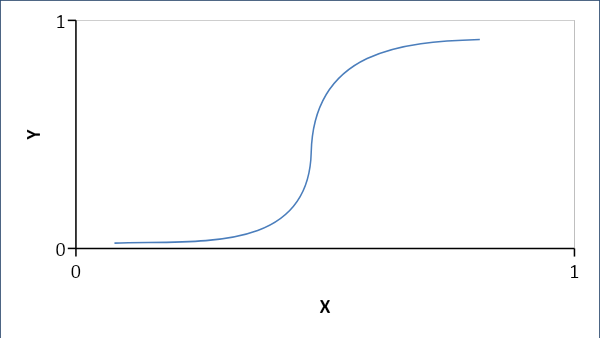
Regresi logistik menetapkan hubungan probabilistik daripada hubungan linier antar variabel. Jawaban yang dihasilkan adalah 0 atau 1 dan kami mencari probabilitas dan kurvanya berbentuk S.
Jika p < 0,5, maka 0 nya 1
Rumus:
Y = e^ (b0 + b1x) / (1 + e^ (b0 +b1x))
dimana b0 = bias dan b1 = koefisien
Kemungkinan
Probabilitas membantu untuk memprediksi kemungkinan terjadinya suatu peristiwa. Beberapa terminologi:
Contoh: Himpunan kemungkinan hasil
Kejadian: Merupakan himpunan bagian dari ruang sampel
Variabel Acak: Variabel acak membantu memetakan atau mengukur kemungkinan hasil ke angka atau garis dalam ruang sampel
Distribusi Probabilitas
Distribusi Diskrit: Memberikan probabilitas sebagai kumpulan nilai diskrit (bilangan bulat)
P[X=x] = p(x)
 Sumber Gambar
Sumber Gambar
Distribusi Kontinu: Memberikan probabilitas atas sejumlah titik atau interval kontinu alih-alih nilai diskrit. Rumus:
P[a x b] = a∫bf(x) dx, di mana a, b adalah titik-titik
Sumber gambar
Korelasi dan Kovarians
Standar Deviasi: Variasi atau deviasi dari kumpulan data yang diberikan dari nilai rata-ratanya
= {(Σi=1N ( xi – x ) ) / (N -1)}
kovarians
Ini mendefinisikan tingkat deviasi variabel acak X dan Y dengan rata-rata dari dataset.
Cov(X,Y) = 2XY= E[(X−μX)(Y−μY)] = E[XY]−μXμY
Korelasi
Korelasi mendefinisikan sejauh mana hubungan linier antara variabel bersama dengan arahnya, +ve atau -ve
XY= 2XY/ X * *σY
Kecerdasan buatan
Kemampuan mesin untuk memperoleh pengetahuan dan membuat keputusan berdasarkan input disebut Artificial Intelligence atau AI.
Jenis
- Mesin Reaktif: AI mesin reaktif bekerja dengan belajar bereaksi terhadap skenario yang telah ditentukan dengan mempersempit ke opsi tercepat dan terbaik. Mereka kekurangan memori dan paling baik untuk tugas dengan serangkaian parameter yang ditentukan. Sangat dapat diandalkan dan konsisten.
- Memori Terbatas: AI ini memiliki beberapa data pengamatan dan warisan dunia nyata yang dimasukkan ke dalamnya. Itu dapat belajar dan membuat keputusan berdasarkan data yang diberikan tetapi tidak dapat memperoleh pengalaman baru.
- Theory of Mind: Ini adalah AI interaktif yang dapat membuat keputusan berdasarkan perilaku entitas di sekitarnya.
- Kesadaran Diri: AI ini menyadari keberadaan dan fungsinya terpisah dari lingkungan. Ia dapat mengembangkan kemampuan kognitif dan memahami serta mengevaluasi dampak dari tindakannya sendiri terhadap lingkungan sekitarnya.
istilah AI
Jaringan Saraf
Neural Network adalah sekelompok atau jaringan node yang saling berhubungan yang menyampaikan data dan informasi dalam suatu sistem. NN dimodelkan untuk meniru neuron di otak kita dan dapat mengambil keputusan dengan belajar dan memprediksi.
Heuristik
Heuristik adalah kemampuan untuk memprediksi berdasarkan perkiraan dan perkiraan dengan cepat menggunakan pengalaman sebelumnya dalam situasi di mana informasi yang tersedia tidak merata. Ini cepat tetapi tidak akurat atau tepat.
Penalaran Berbasis Kasus
Kemampuan untuk belajar dari kasus pemecahan masalah sebelumnya dan menerapkannya dalam situasi saat ini untuk sampai pada solusi yang dapat diterima
Pemrosesan Bahasa Alami
Ini hanyalah kemampuan mesin untuk memahami dan berinteraksi secara langsung dalam ucapan atau teks manusia. Misalnya, perintah suara di dalam mobil
Pembelajaran mesin
Machine Learning hanyalah sebuah aplikasi AI menggunakan berbagai model dan algoritma untuk memprediksi dan memecahkan masalah.

Jenis
Diawasi
Metode ini mengandalkan data masukan yang bersifat asosiatif dengan data keluaran. Mesin dilengkapi dengan satu set variabel target Y dan harus sampai pada variabel target melalui satu set variabel input X di bawah pengawasan algoritma optimasi. Contoh pembelajaran yang diawasi adalah Neural Networks, Random Forest, Deep Learning, Support Vector Machines, dll.
Tidak diawasi
Dalam metode ini, variabel input tidak memiliki pelabelan atau asosiasi, dan algoritma bekerja untuk menemukan pola dan cluster yang menghasilkan pengetahuan dan wawasan baru.
Diperkuat
Pembelajaran yang diperkuat berfokus pada teknik improvisasi untuk mempertajam atau memoles perilaku belajar. Ini adalah metode berbasis hadiah di mana mesin secara bertahap meningkatkan tekniknya untuk memenangkan hadiah target.
Metode Pemodelan
Regresi
Model regresi selalu memberikan angka sebagai keluaran melalui interpolasi atau ekstrapolasi data kontinu.
Klasifikasi
Model klasifikasi muncul dengan output sebagai kelas atau label dan lebih baik dalam memprediksi hasil diskrit seperti 'jenis apa'
Baik regresi dan klasifikasi adalah model yang diawasi.
Kekelompokan
Clustering adalah model tanpa pengawasan yang mengidentifikasi cluster berdasarkan ciri, atribut, fitur, dll.
Algoritma ML
Pohon Keputusan
Pohon keputusan menggunakan pendekatan biner untuk sampai pada solusi berdasarkan pertanyaan berurutan pada setiap tahap sehingga hasilnya adalah salah satu dari dua kemungkinan seperti 'Ya' atau 'Tidak'. Pohon keputusan mudah untuk diimplementasikan dan diinterpretasikan.
Hutan Acak atau Bagging
Random Forest adalah algoritma lanjutan dari pohon keputusan. Ini menggunakan sejumlah besar pohon keputusan yang membuat strukturnya padat dan kompleks seperti hutan. Ini menghasilkan banyak hasil dan dengan demikian mengarah pada hasil dan kinerja yang lebih akurat.
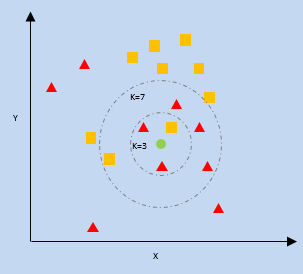
K- Tetangga Terdekat (KNN)
kNN memanfaatkan kedekatan titik data terdekat pada plot relatif terhadap titik data baru untuk memprediksi kategori mana yang termasuk dalam. Titik data baru ditugaskan ke kategori dengan jumlah tetangga yang lebih tinggi.
k = jumlah tetangga terdekat
Naif Bayes
Naive Bayes bekerja pada dua pilar, pertama bahwa setiap fitur titik data independen, tidak terkait satu sama lain, yaitu unik, dan kedua pada teorema Bayes yang memprediksi hasil berdasarkan suatu kondisi atau hipotesis.
Teorema Bayes:
P(X|Y) = {P(Y|X) * P(X)} / P(Y)
Dimana P(X|Y) = Probabilitas bersyarat dari X jika diberikan kemunculan Y
P(Y|X) = Probabilitas bersyarat dari Y jika diberikan kemunculan X
P(X), P(Y) = Probabilitas X dan Y secara individu
Mendukung Mesin Vektor
Algoritma ini mencoba untuk memisahkan data dalam ruang berdasarkan batas-batas yang dapat berupa garis atau bidang. Batas ini disebut 'hyperplane' dan didefinisikan oleh titik data terdekat dari setiap kelas yang disebut 'vektor pendukung'. Jarak maksimum antara vektor pendukung dari kedua sisi disebut margin.
Jaringan Saraf
Perceptron
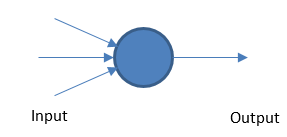
Jaringan saraf dasar bekerja dengan mengambil input dan output berbobot berdasarkan nilai ambang batas.
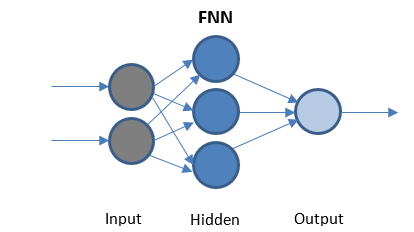
Jaringan Neural Umpan Maju
FFN adalah jaringan paling sederhana yang mentransmisikan data hanya dalam satu arah. Mungkin atau mungkin tidak memiliki lapisan tersembunyi.
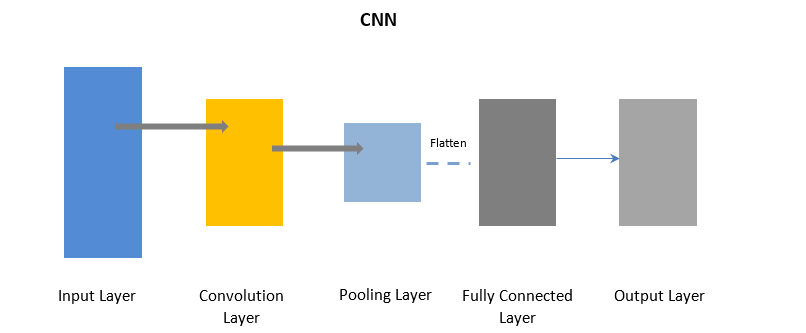
Jaringan Saraf Konvolusional
CNN menggunakan lapisan konvolusi untuk memproses bagian tertentu dari data input dalam batch diikuti oleh lapisan penyatuan untuk menyelesaikan output.
Jaringan Saraf Berulang
RNN terdiri dari beberapa lapisan berulang antara lapisan I/O yang dapat menyimpan data 'historis'. Aliran data bersifat dua arah dan diumpankan ke lapisan berulang untuk meningkatkan prediksi.
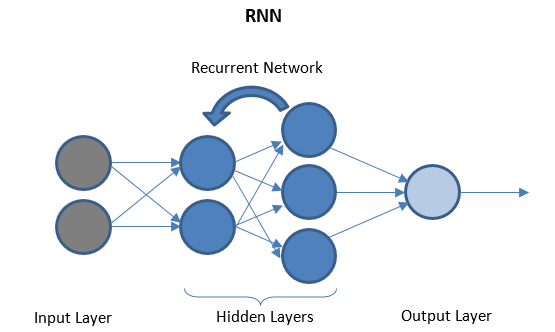
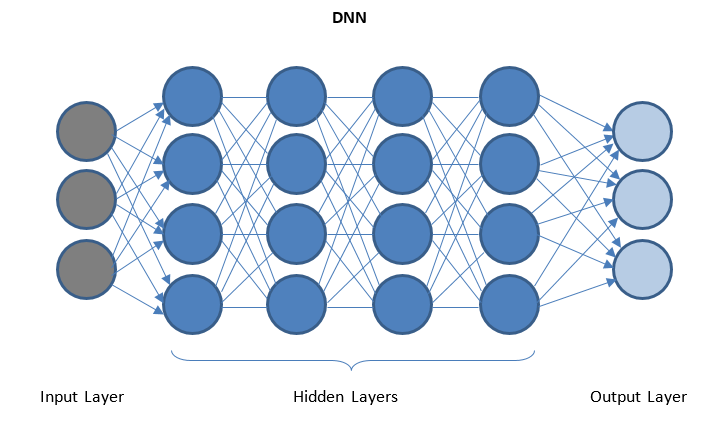
Jaringan Saraf Dalam dan Pembelajaran Mendalam
DNN adalah jaringan dengan beberapa lapisan tersembunyi di antara lapisan I/O. Lapisan tersembunyi menerapkan transformasi berturut-turut ke data sebelum mengirimkannya ke lapisan keluaran.
'Deep Learning' difasilitasi melalui DNN dan dapat menangani sejumlah besar data kompleks dan mencapai akurasi tinggi karena banyak lapisan tersembunyi
Dapatkan sertifikasi ilmu data dari Universitas top dunia. Pelajari Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.
Kesimpulan
Ilmu data adalah bidang luas yang mengalir melalui aliran yang berbeda tetapi tampil sebagai revolusi dan wahyu bagi kami. Ilmu data sedang booming dan akan mengubah cara kerja dan perasaan sistem kami di masa depan.
Jika Anda penasaran untuk belajar tentang ilmu data, lihat Diploma PG IIIT-B & upGrad dalam Ilmu Data yang dibuat untuk para profesional yang bekerja dan menawarkan 10+ studi kasus & proyek, lokakarya praktis, bimbingan dengan pakar industri, 1- on-1 dengan mentor industri, 400+ jam pembelajaran dan bantuan pekerjaan dengan perusahaan-perusahaan top.
Bahasa pemrograman mana yang paling cocok untuk Ilmu Data dan mengapa?
Ada lusinan bahasa pemrograman untuk Ilmu data di luar sana, tetapi mayoritas komunitas ilmu data percaya bahwa jika Anda ingin unggul dalam ilmu data, maka Python adalah pilihan yang tepat. Di bawah ini adalah beberapa alasan yang mendukung keyakinan ini:
1. Python memiliki berbagai macam modul dan pustaka seperti TensorFlow dan PyTorch yang memudahkan untuk menangani konsep ilmu data.
2. Komunitas pengembang Python yang luas terus-menerus membantu pemula untuk melewati fase berikutnya dari perjalanan ilmu data mereka.
3. Bahasa ini sejauh ini merupakan salah satu bahasa yang paling nyaman dan mudah untuk ditulis dengan sintaks yang bersih yang meningkatkan keterbacaannya.
Apa konsep yang membuat ilmu data lengkap?
Ilmu Data adalah domain luas yang bertindak sebagai payung untuk berbagai domain penting lainnya. Berikut ini adalah konsep paling menonjol yang membentuk ilmu data:
Statistik
Statistik adalah konsep penting yang harus Anda kuasai, untuk maju dalam ilmu data. Lebih lanjut memiliki beberapa sub-topik:
1. Regresi Linier
2. Probabilitas
3. Distribusi Probabilitas
Kecerdasan buatan
Ilmu untuk menyediakan otak bagi mesin dan membiarkan mereka membuat keputusan sendiri berdasarkan input dikenal sebagai Kecerdasan Buatan. Mesin Reaktif, Memori Terbatas, Teori Pikiran, dan Kesadaran Diri adalah beberapa jenis Kecerdasan Buatan.
Pembelajaran mesin
Machine Learning adalah komponen penting lain dari Ilmu Data yang berhubungan dengan mesin pengajaran untuk memprediksi hasil di masa depan berdasarkan data yang disediakan. Pembelajaran mesin memiliki tiga metode pemodelan yang menonjol - Pengelompokan, regresi, dan Klasifikasi.
Jelaskan jenis-jenis Machine Learning?
Machine Learning atau ML sederhana memiliki tiga jenis utama berdasarkan metode kerjanya. Jenis-jenis tersebut adalah sebagai berikut:
1. Pembelajaran yang Diawasi
Ini adalah jenis ML paling primitif di mana data input diberi label. Mesin dilengkapi dengan kumpulan data yang lebih kecil yang memberi mesin wawasan tentang masalah dan dilatih untuk mengatasinya.
2. Pembelajaran Tanpa Pengawasan
Keuntungan terbesar dari jenis ini adalah bahwa data tidak berlabel di sini dan tenaga manusia hampir dapat diabaikan. Ini membuka gerbang untuk kumpulan data yang jauh lebih besar untuk diperkenalkan ke model.
3. Reinforced Learning Ini adalah jenis ML tercanggih yang terinspirasi dari kehidupan manusia. Output yang diinginkan diperkuat sementara output yang tidak berguna tidak disarankan.