
Prapemrosesan Data dalam Pembelajaran Mesin: 7 Langkah Mudah Untuk Diikuti
Diterbitkan: 2021-07-15Prapemrosesan data dalam Pembelajaran Mesin adalah langkah penting yang membantu meningkatkan kualitas data untuk mendorong ekstraksi wawasan yang bermakna dari data. Prapemrosesan data dalam Machine Learning mengacu pada teknik menyiapkan (membersihkan dan mengatur) data mentah agar sesuai untuk membangun dan melatih model Machine Learning. Dengan kata sederhana, data preprocessing dalam Machine Learning adalah teknik data mining yang mengubah data mentah menjadi format yang dapat dimengerti dan dibaca.
Daftar isi
Mengapa Prapemrosesan Data dalam Pembelajaran Mesin?
Dalam hal membuat model Pembelajaran Mesin, prapemrosesan data adalah langkah pertama yang menandai inisiasi proses. Biasanya, data dunia nyata tidak lengkap, tidak konsisten, tidak akurat (berisi kesalahan atau outlier), dan seringkali tidak memiliki nilai/tren atribut tertentu. Di sinilah prapemrosesan data memasuki skenario – ini membantu membersihkan, memformat, dan mengatur data mentah, sehingga membuatnya siap digunakan untuk model Machine Learning. Mari jelajahi berbagai langkah prapemrosesan data dalam pembelajaran mesin.
Bergabunglah dengan Kursus Kecerdasan Buatan online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
Langkah-langkah dalam Prapemrosesan Data dalam Pembelajaran Mesin
Ada tujuh langkah penting dalam prapemrosesan data di Machine Learning:
1. Dapatkan kumpulan data
Memperoleh set data adalah langkah pertama dalam prapemrosesan data dalam pembelajaran mesin. Untuk membangun dan mengembangkan model Machine Learning, Anda harus terlebih dahulu memperoleh dataset yang relevan. Kumpulan data ini akan terdiri dari data yang dikumpulkan dari berbagai sumber dan berbeda yang kemudian digabungkan dalam format yang tepat untuk membentuk kumpulan data. Format kumpulan data berbeda menurut kasus penggunaan. Misalnya, kumpulan data bisnis akan sangat berbeda dari kumpulan data medis. Sementara kumpulan data bisnis akan berisi data industri dan bisnis yang relevan, kumpulan data medis akan mencakup data terkait perawatan kesehatan.
Ada beberapa sumber online tempat Anda dapat mengunduh kumpulan data seperti https://www.kaggle.com/uciml/datasets dan https://archive.ics.uci.edu/ml/index.php . Anda juga dapat membuat kumpulan data dengan mengumpulkan data melalui API Python yang berbeda. Setelah kumpulan data siap, Anda harus memasukkannya ke dalam format file CSV, atau HTML, atau XLSX.

2. Impor semua perpustakaan penting
Karena Python adalah pustaka yang paling banyak digunakan dan juga paling disukai oleh Ilmuwan Data di seluruh dunia, kami akan menunjukkan cara mengimpor pustaka Python untuk pra-pemrosesan data dalam Pembelajaran Mesin. Baca lebih lanjut tentang perpustakaan Python untuk Ilmu Data di sini. Pustaka Python yang telah ditentukan sebelumnya dapat melakukan pekerjaan prapemrosesan data tertentu. Mengimpor semua library penting adalah langkah kedua dalam prapemrosesan data dalam pembelajaran mesin. Tiga pustaka Python inti yang digunakan untuk prapemrosesan data ini dalam Pembelajaran Mesin adalah:
- NumPy – NumPy adalah paket dasar untuk perhitungan ilmiah dengan Python. Oleh karena itu, ini digunakan untuk memasukkan semua jenis operasi matematika ke dalam kode. Menggunakan NumPy, Anda juga dapat menambahkan array dan matriks multidimensi yang besar dalam kode Anda.
- Pandas – Pandas adalah pustaka Python open-source yang sangat baik untuk manipulasi dan analisis data. Ini banyak digunakan untuk mengimpor dan mengelola kumpulan data. Ini dikemas dalam struktur data berkinerja tinggi dan mudah digunakan serta alat analisis data untuk Python.
- Matplotlib – Matplotlib adalah pustaka plot 2D Python yang digunakan untuk memplot semua jenis bagan dengan Python. Hal ini dapat memberikan angka kualitas publikasi dalam berbagai format hard copy dan lingkungan interaktif di seluruh platform (kerang IPython, notebook Jupyter, server aplikasi web, dll).
Baca : Ide Proyek Machine Learning untuk Pemula
3. Impor kumpulan data
Pada langkah ini, Anda perlu mengimpor kumpulan data yang telah Anda kumpulkan untuk proyek ML yang ada. Mengimpor kumpulan data adalah salah satu langkah penting dalam prapemrosesan data dalam pembelajaran mesin. Namun, sebelum Anda dapat mengimpor dataset/s, Anda harus mengatur direktori saat ini sebagai direktori kerja. Anda dapat mengatur direktori kerja di Spyder IDE dalam tiga langkah sederhana:
- Simpan file Python Anda di direktori yang berisi dataset.
- Buka opsi File Explorer di Spyder IDE dan pilih direktori yang diperlukan.
- Sekarang, klik tombol F5 atau opsi Run untuk mengeksekusi file.
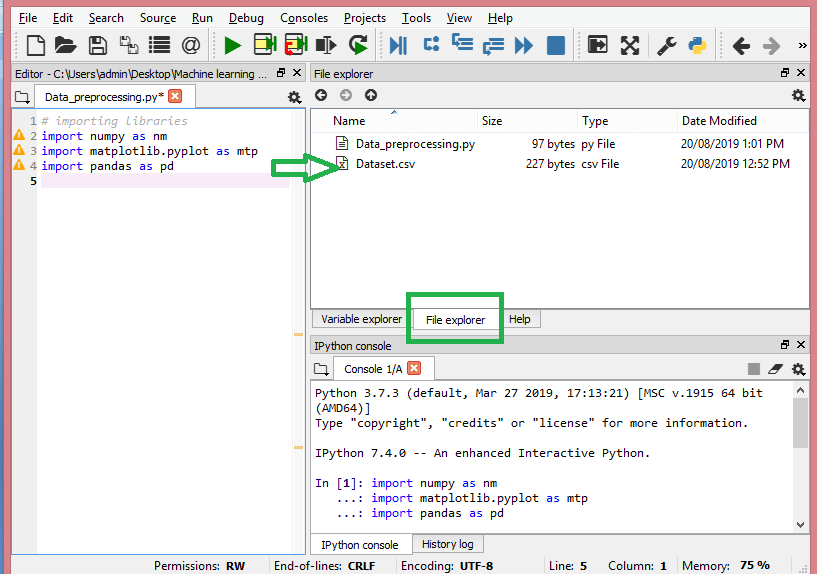
Sumber
Ini adalah bagaimana direktori kerja akan terlihat.
Setelah Anda mengatur direktori kerja yang berisi kumpulan data yang relevan, Anda dapat mengimpor kumpulan data menggunakan fungsi “read_csv()” dari pustaka Pandas. Fungsi ini dapat membaca file CSV (baik secara lokal atau melalui URL) dan juga melakukan berbagai operasi di dalamnya. read_csv() ditulis sebagai:
data_set= pd.read_csv('Dataset.csv')
Di baris kode ini, "data_set" menunjukkan nama variabel tempat Anda menyimpan dataset. Fungsi tersebut juga berisi nama dataset. Setelah Anda mengeksekusi kode ini, dataset akan berhasil diimpor.
Selama proses pengimporan dataset, ada hal penting lain yang harus Anda lakukan – mengekstrak variabel dependen dan independen. Untuk setiap model Machine Learning, perlu untuk memisahkan variabel independen (matriks fitur) dan variabel dependen dalam sebuah dataset.
Pertimbangkan kumpulan data ini:
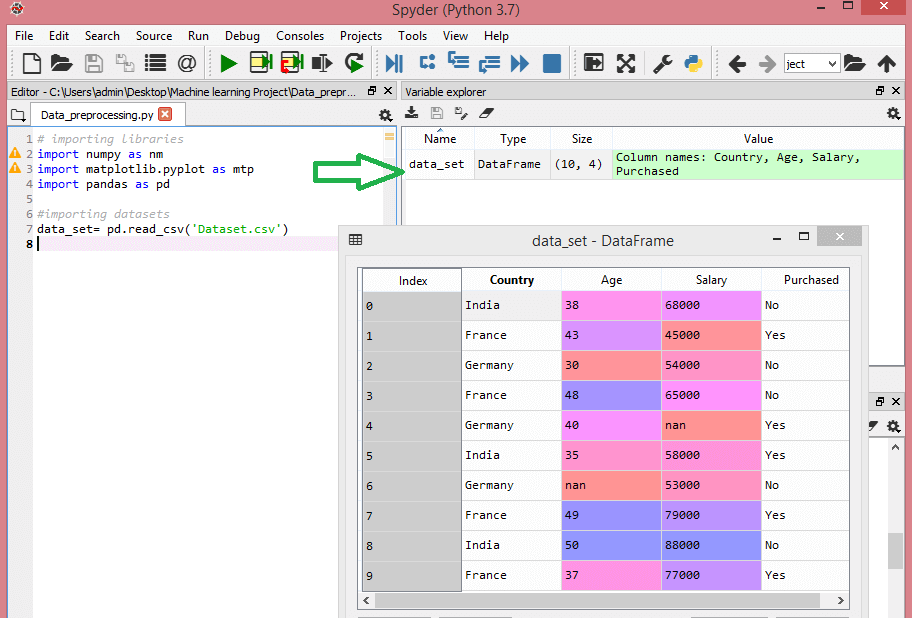
Sumber
Dataset ini berisi tiga variabel independen – negara, usia, dan gaji, dan satu variabel dependen – dibeli.
Bagaimana cara mengekstrak variabel independen?
Untuk mengekstrak variabel independen, Anda dapat menggunakan fungsi “iloc[ ]” dari perpustakaan Pandas. Fungsi ini dapat mengekstrak baris dan kolom yang dipilih dari kumpulan data.
x= data_set.iloc[:,:-1].values
Pada baris kode di atas, titik dua (:) pertama mempertimbangkan semua baris dan titik dua (:) kedua mempertimbangkan semua kolom. Kode berisi “:-1” karena Anda harus meninggalkan kolom terakhir yang berisi variabel dependen. Dengan mengeksekusi kode ini, Anda akan mendapatkan matriks fitur, seperti ini –
[['India' 38.0 680000.0]
['Prancis' 43.0 450000.0]
['Jerman' 30,0 54000,0]
['Prancis' 48,0 65000,0]
['Jerman' 40,0 nan]
['India' 35.0 580000.0]
['Jerman' dan 53000,0]
['Prancis' 49.0 79000.0]
['India' 50,0 88000,0]
['Prancis' 37,0 77000,0]]
Bagaimana cara mengekstrak variabel dependen?
Anda dapat menggunakan fungsi “iloc[ ]” untuk mengekstrak variabel dependen juga. Begini cara Anda menulisnya:
y= data_set.iloc[:,3].nilai
Baris kode ini mempertimbangkan semua baris dengan kolom terakhir saja. Dengan mengeksekusi kode di atas, Anda akan mendapatkan array variabel dependen, seperti –
array(['Tidak', 'Ya', 'Tidak', 'Tidak', 'Ya', 'Ya', 'Tidak', 'Ya', 'Tidak', 'Ya'],
dtype=objek)
4. Mengidentifikasi dan menangani nilai-nilai yang hilang
Dalam pra-pemrosesan data, sangat penting untuk mengidentifikasi dan menangani nilai yang hilang dengan benar, jika tidak melakukannya, Anda mungkin menarik kesimpulan dan inferensi yang tidak akurat dan salah dari data. Tak perlu dikatakan, ini akan menghambat proyek ML Anda.
Pada dasarnya, ada dua cara untuk menangani data yang hilang:
- Menghapus baris tertentu – Dalam metode ini, Anda menghapus baris tertentu yang memiliki nilai nol untuk fitur atau kolom tertentu di mana lebih dari 75% nilai tidak ada. Namun, metode ini tidak 100% efisien, dan Anda disarankan untuk menggunakannya hanya jika kumpulan data memiliki sampel yang memadai. Anda harus memastikan bahwa setelah menghapus data, tidak ada penambahan bias.
- Menghitung mean – Metode ini berguna untuk fitur yang memiliki data numerik seperti usia, gaji, tahun, dll. Di sini, Anda dapat menghitung mean, median, atau mode fitur atau kolom atau baris tertentu yang berisi nilai yang hilang dan mengganti hasil untuk nilai yang hilang. Metode ini dapat menambah varians ke kumpulan data, dan kehilangan data apa pun dapat ditiadakan secara efisien. Oleh karena itu, ini menghasilkan hasil yang lebih baik dibandingkan dengan metode pertama (penghilangan baris/kolom). Cara aproksimasi lainnya adalah melalui deviasi nilai-nilai tetangga. Namun, ini berfungsi paling baik untuk data linier.
Baca: Aplikasi Aplikasi Machine Learning Menggunakan Cloud
5. Mengkodekan data kategorikal
Data kategoris mengacu pada informasi yang memiliki kategori tertentu dalam dataset. Dalam kumpulan data yang dikutip di atas, ada dua variabel kategori – negara dan pembelian.
Model Machine Learning terutama didasarkan pada persamaan matematika. Dengan demikian, Anda dapat memahami secara intuitif bahwa menyimpan data kategorikal dalam persamaan akan menyebabkan masalah tertentu karena Anda hanya memerlukan angka dalam persamaan.
Bagaimana cara menyandikan variabel negara?
Seperti yang terlihat dalam contoh kumpulan data kami, kolom negara akan menyebabkan masalah, jadi Anda harus mengubahnya menjadi nilai numerik. Untuk melakukannya, Anda dapat menggunakan kelas LabelEncoder() dari perpustakaan pembelajaran sci-kit. Kode akan menjadi sebagai berikut -
#data kategoris
#untuk Variabel Negara
dari sklearn.preprocessing impor LabelEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
Dan outputnya adalah -
Keluar[15]:
array([[2, 38.0, 680000.0],
[0, 43.0, 450000.0],
[1, 30,0, 54000,0],
[0, 48.0, 650000.0],
[1, 40.0, 65222.22222222222],
[2, 35.0, 580000.0],
[1, 41.111111111111114, 53000,0],
[0, 49.0, 79000.0],
[2, 50,0, 88000.0],
[0, 37,0, 77000,0]], dtype=objek)
Di sini kita dapat melihat bahwa kelas LabelEncoder telah berhasil mengkodekan variabel ke dalam angka. Namun, ada variabel negara yang dikodekan sebagai 0, 1, dan 2 pada output yang ditunjukkan di atas. Jadi, model ML dapat mengasumsikan bahwa ada korelasi antara ketiga variabel, sehingga menghasilkan output yang salah. Untuk menghilangkan masalah ini, sekarang kita akan menggunakan Dummy Encoding.
Variabel dummy adalah variabel yang mengambil nilai 0 atau 1 untuk menunjukkan tidak adanya atau adanya efek kategoris tertentu yang dapat menggeser hasil. Dalam hal ini, nilai 1 menunjukkan adanya variabel tersebut dalam kolom tertentu sedangkan variabel lainnya menjadi bernilai 0. Dalam pengkodean dummy, jumlah kolom sama dengan jumlah kategori.
Karena dataset kami memiliki tiga kategori, itu akan menghasilkan tiga kolom yang memiliki nilai 0 dan 1. Untuk Dummy Encoding, kami akan menggunakan kelas OneHotEncoder dari perpustakaan scikit-learn. Kode input akan menjadi sebagai berikut -
#untuk Variabel Negara
dari sklearn.preprocessing impor LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])

#Encoding untuk variabel dummy
onehot_encoder= OneHotEncoder(fitur_kategorikal= [0])
x= onehot_encoder.fit_transform(x).toarray()
Pada eksekusi kode ini, Anda akan mendapatkan output berikut -
array([[0,000000000e+00, 0,000000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0,000000000e+00, 0,000000000e+00, 4.30000000e+01,
4.50000000e+04],
[0,000000000e+00, 1,000000000e+00, 0,000000000e+00, 3,0000000e+01,
5.40000000e+04],
[1.00000000e+00, 0,000000000e+00, 0,000000000e+00, 4.80000000e+01,
6.50000000e+04],
[0,000000000e+00, 1,000000000e+00, 0,000000000e+00, 40000000e+01,
6.522222222e+04],
[0,000000000e+00, 0,000000000e+00, 1.000000000e+00, 3.50000000e+01,
5.80000000e+04],
[0,000000000e+00, 1,000000000e+00, 0,000000000e+00, 4.111111111e+01,
5.30000000e+04],
[1.00000000e+00, 0,000000000e+00, 0,000000000e+00, 4.9000000e+01,
7.90000000e+04],
[0,000000000e+00, 0,000000000e+00, 1.000000000e+00, 5.000000e+01,
8.80000000e+04],
[1.00000000e+00, 0,000000000e+00, 0,000000000e+00, 3.70000000e+01,
7.70000000e+04]])
Pada output yang ditunjukkan di atas, semua variabel dibagi menjadi tiga kolom dan dikodekan ke dalam nilai 0 dan 1.
Bagaimana cara menyandikan variabel yang dibeli?
Untuk variabel kategori kedua, yaitu, dibeli, Anda dapat menggunakan objek "labelencoder" dari kelas LableEncoder. Kami tidak menggunakan kelas OneHotEncoder karena variabel yang dibeli hanya memiliki dua kategori ya atau tidak, keduanya dikodekan menjadi 0 dan 1.
Kode input untuk variabel ini adalah –
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
Outputnya akan -
Keluar[17]: array([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
6. Memisahkan kumpulan data
Memisahkan kumpulan data adalah langkah selanjutnya dalam prapemrosesan data dalam pembelajaran mesin. Setiap set data untuk model Machine Learning harus dibagi menjadi dua set terpisah – set pelatihan dan set pengujian.
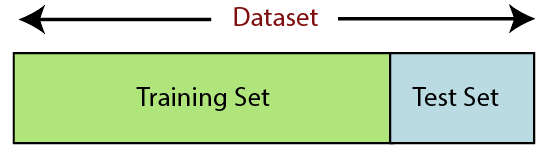
Sumber
Set pelatihan menunjukkan subset dari set data yang digunakan untuk melatih model pembelajaran mesin. Di sini, Anda sudah mengetahui outputnya. Set pengujian, di sisi lain, adalah subset dari dataset yang digunakan untuk menguji model pembelajaran mesin. Model ML menggunakan set pengujian untuk memprediksi hasil.
Biasanya, dataset dibagi menjadi rasio 70:30 atau rasio 80:20. Ini berarti Anda mengambil 70% atau 80% dari data untuk melatih model sementara meninggalkan 30% atau 20% sisanya. Proses pemisahan bervariasi sesuai dengan bentuk dan ukuran dataset yang bersangkutan.
Untuk membagi dataset, Anda harus menulis baris kode berikut –
dari sklearn.model_selection impor train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
Di sini, baris pertama membagi array dataset menjadi rangkaian acak dan subset pengujian. Baris kedua kode mencakup empat variabel:
- x_train – fitur untuk data pelatihan
- x_test – fitur untuk data pengujian
- y_train – variabel dependen untuk data pelatihan
- y_test – variabel independen untuk menguji data
Jadi, fungsi train_test_split() mencakup empat parameter, dua parameter pertama adalah untuk array data. Fungsi test_size menentukan ukuran set tes. Test_size mungkin .5, .3, atau .2 – ini menentukan rasio pembagian antara set pelatihan dan tes. Parameter terakhir, “random_state” menetapkan seed untuk generator acak sehingga outputnya selalu sama.
7. Penskalaan fitur
Penskalaan fitur menandai akhir dari prapemrosesan data di Machine Learning. Ini adalah metode untuk menstandardisasi variabel independen dari kumpulan data dalam rentang tertentu. Dengan kata lain, penskalaan fitur membatasi rentang variabel sehingga Anda dapat membandingkannya dengan alasan yang sama.
Pertimbangkan dataset ini misalnya -
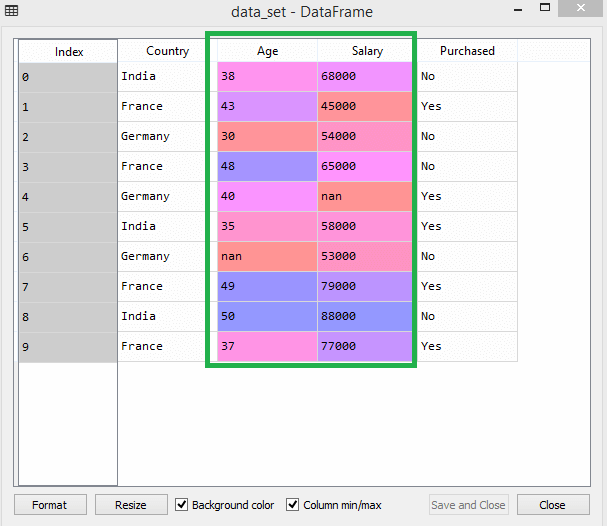
Sumber
Dalam dataset, Anda dapat melihat bahwa kolom usia dan gaji tidak memiliki skala yang sama. Dalam skenario seperti itu, jika Anda menghitung dua nilai dari kolom usia dan gaji, nilai gaji akan mendominasi nilai usia dan memberikan hasil yang salah. Dengan demikian, Anda harus menghapus masalah ini dengan melakukan penskalaan fitur untuk Machine Learning.
Sebagian besar model ML didasarkan pada Jarak Euclidean, yang direpresentasikan sebagai:
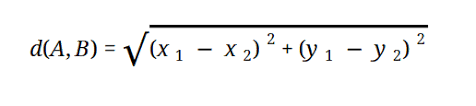
Sumber
Anda dapat melakukan penskalaan fitur di Machine Learning dengan dua cara:
Standardisasi
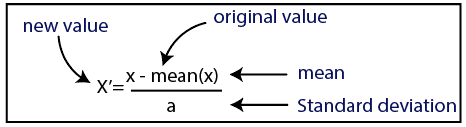
Sumber
Normalisasi
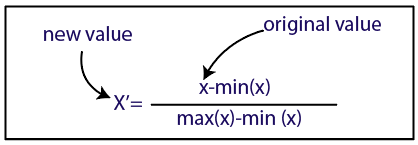
Sumber
Untuk dataset kami, kami akan menggunakan metode standardisasi. Untuk melakukannya, kami akan mengimpor kelas StandardScaler dari perpustakaan sci-kit-learn menggunakan baris kode berikut:
dari sklearn.preprocessing impor StandardScaler
Langkah selanjutnya adalah membuat objek kelas StandardScaler untuk variabel independen. Setelah ini, Anda dapat menyesuaikan dan mengubah set data pelatihan menggunakan kode berikut:
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
Untuk dataset pengujian, Anda dapat langsung menerapkan fungsi transform() (Anda tidak perlu menggunakan fungsi fit_transform() karena sudah dilakukan di set pelatihan). Kode akan menjadi sebagai berikut -
x_test= st_x.transform(x_test)
Keluaran untuk kumpulan data pengujian akan menampilkan nilai yang diskalakan untuk x_train dan x_test sebagai:
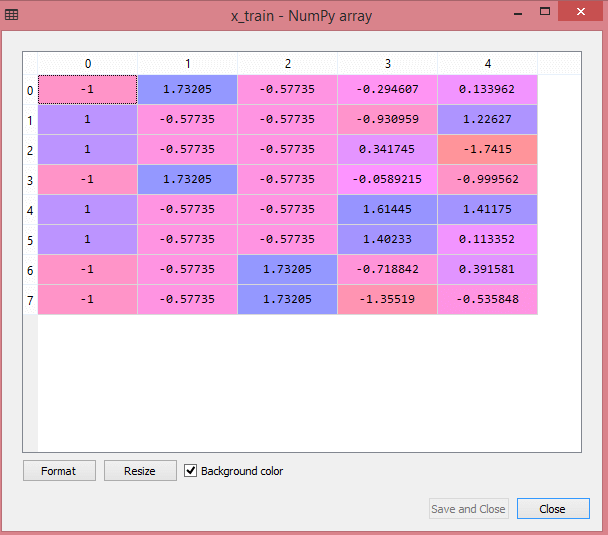
Sumber
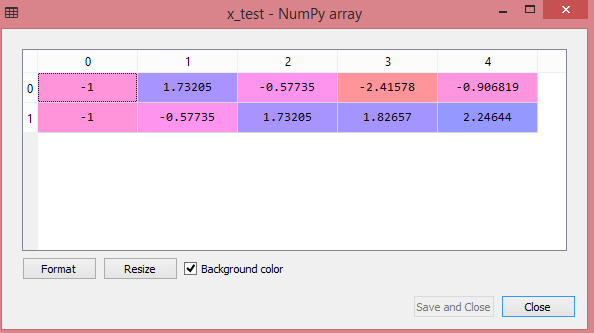
Sumber
Semua variabel dalam output diskalakan antara nilai -1 dan 1.
Sekarang, untuk menggabungkan semua langkah yang telah kami lakukan sejauh ini, Anda mendapatkan:
# mengimpor perpustakaan
impor numpy sebagai nm
impor matplotlib.pyplot sebagai mtp
impor panda sebagai pd
#mengimpor kumpulan data
data_set= pd.read_csv('Dataset.csv')
#Mengekstraksi Variabel Independen
x= data_set.iloc[:, :-1].values
#Mengekstrak variabel Dependen
y= data_set.iloc[:, 3].values
#menangani data yang hilang(Mengganti data yang hilang dengan nilai rata-rata)
dari sklearn.preprocessing import Imputer
imputer= Imputer(missing_values ='NaN', strategy='mean', axis = 0)
#Memasukkan objek imputer ke variabel independen x.
imputerimputer= imputer.fit(x[:, 1:3])
#Mengganti data yang hilang dengan nilai rata-rata yang dihitung
x[:, 1:3]= imputer.transform(x[:, 1:3])
#untuk Variabel Negara
dari sklearn.preprocessing impor LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Encoding untuk variabel dummy
onehot_encoder= OneHotEncoder(fitur_kategorikal= [0])
x= onehot_encoder.fit_transform(x).toarray()
#encoding untuk variabel yang dibeli
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
# Memisahkan dataset menjadi training dan test set.
dari sklearn.model_selection impor train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#Fitur Penskalaan kumpulan data
dari sklearn.preprocessing impor StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
Jadi, itulah pemrosesan data di Machine Learning secara singkat!
Anda dapat memeriksa Program PG Eksekutif IIT Delhi dalam Pembelajaran Mesin & AI yang terkait dengan upGrad . IIT Delhi adalah salah satu institusi paling bergengsi di India. Dengan lebih dari 500+ anggota fakultas In-house yang terbaik dalam mata pelajaran.
Apa pentingnya pra-pemrosesan data?
Karena kesalahan, redundansi, nilai yang hilang, dan inkonsistensi semuanya membahayakan integritas kumpulan data, Anda harus mengatasi semuanya untuk hasil yang lebih akurat. Asumsikan Anda menggunakan kumpulan data yang rusak untuk melatih sistem Pembelajaran Mesin untuk menangani pembelian klien Anda. Sistem cenderung menghasilkan bias dan penyimpangan, yang mengakibatkan pengalaman pengguna yang buruk. Oleh karena itu, sebelum Anda menggunakan data tersebut untuk tujuan yang diinginkan, data tersebut harus diatur dan 'bersih' sebaik mungkin. Tergantung pada jenis kesulitan yang Anda hadapi, ada banyak pilihan.
Apa itu pembersihan data?
Hampir pasti akan ada data yang hilang dan berisik dalam kumpulan data Anda. Karena prosedur pengumpulan data tidak ideal, Anda akan memiliki banyak informasi yang tidak berguna dan hilang. Pembersihan data adalah cara yang harus Anda terapkan untuk mengatasi masalah ini. Ini dapat dibagi menjadi dua kategori. Yang pertama membahas bagaimana menangani data yang hilang. Anda dapat memilih untuk mengabaikan nilai yang hilang di bagian pengumpulan data ini (disebut tupel). Metode pembersihan data yang kedua adalah untuk data yang berisik. Sangat penting untuk menyingkirkan data tidak berguna yang tidak dapat dibaca oleh sistem jika Anda ingin seluruh proses berjalan dengan lancar.
Apa yang dimaksud dengan transformasi dan reduksi data?
Pra-pemrosesan data beralih ke tahap transformasi setelah menangani masalah. Anda menggunakannya untuk mengubah data menjadi konformasi yang relevan untuk analisis. Normalisasi, pemilihan atribut, diskritisasi, dan Pembuatan Hirarki Konsep adalah beberapa pendekatan yang dapat digunakan untuk mencapai hal ini. Bahkan untuk metode otomatis, memilah-milah kumpulan data besar bisa memakan waktu lama. Itulah mengapa tahap reduksi data sangat penting: ini mengurangi ukuran kumpulan data dengan membatasinya pada informasi yang paling penting, meningkatkan efisiensi penyimpanan sambil menurunkan biaya keuangan dan waktu untuk bekerja dengannya.