
CNN vs RNN: Perbedaan Antara CNN dan RNN
Diterbitkan: 2021-02-25Daftar isi
pengantar
Di bidang Kecerdasan Buatan, Jaringan Syaraf Tiruan yang terinspirasi dari otak manusia banyak digunakan dalam mengekstraksi dan memproses informasi yang kompleks dari berbagai data dan penggunaan Jaringan Syaraf Tiruan (CNN) dan Jaringan Syaraf Berulang (RNN) dalam aplikasi semacam itu. terbukti bermanfaat.
Pada artikel ini, kita akan memahami konsep di balik Jaringan Saraf Konvolusi dan Jaringan Saraf Berulang, melihat aplikasinya dan membedakan perbedaan antara kedua jenis Jaringan Saraf Tiruan yang populer.
Pelajari Pelatihan Pembelajaran Mesin dari Universitas top dunia. Dapatkan Master, PGP Eksekutif, atau Program Sertifikat Tingkat Lanjut untuk mempercepat karier Anda.
Jaringan Neural dan Pembelajaran Mendalam
Sebelum kita masuk ke konsep Jaringan Neural Convolutional dan Jaringan Syaraf Berulang, mari kita pahami konsep di balik Jaringan Syaraf Tiruan dan bagaimana hal itu terkait dengan Pembelajaran Mendalam.
Belakangan ini, Deep Learning pernah menjadi konsep yang banyak digunakan di berbagai bidang dan karenanya menjadi topik hangat akhir-akhir ini. Tapi apa alasan di baliknya begitu banyak dibicarakan? Untuk menjawab pertanyaan ini, kita akan belajar tentang konsep Neural Networks.
Singkatnya, Neural Networks adalah tulang punggung Deep Learning. Mereka adalah sejumlah lapisan yang terdiri dari elemen-elemen yang sangat saling berhubungan yang dikenal sebagai neuron yang melakukan serangkaian transformasi pada data yang menghasilkan pemahamannya sendiri tentang data itu yang kita sebut istilah, fitur.

Apa itu Neural Network?
Konsep pertama yang perlu kita selesaikan adalah Neural Networks. Kita tahu bahwa Otak Manusia adalah salah satu struktur kompleks yang pernah dipelajari. Karena kerumitannya, ada kesulitan besar dalam mengungkap cara kerja bagian dalamnya, tetapi saat ini, beberapa jenis penelitian sedang dilakukan untuk mengungkap rahasianya. Otak Manusia ini menjadi inspirasi di balik model Neural Network.
Menurut definisi, Neural Networks adalah unit fungsional Deep Learning yang memanfaatkan Neural Networks ini untuk meniru aktivitas otak dan memecahkan masalah yang kompleks. Ketika data input diumpankan ke Neural Network, diproses melalui lapisan perceptron dan akhirnya memberikan output.
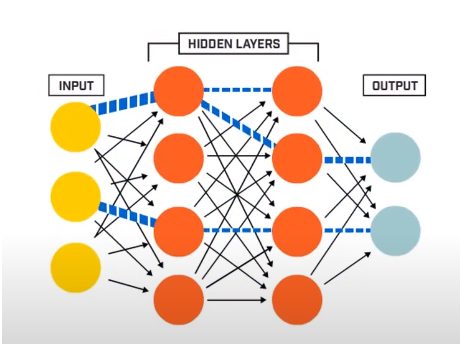
Neural Network pada dasarnya terdiri dari 3 lapisan –
- Lapisan Masukan
- Lapisan Tersembunyi
- Lapisan Keluaran
Lapisan Input membaca data input yang dimasukkan ke dalam sistem Jaringan Saraf Tiruan untuk pra-pemrosesan lebih lanjut oleh lapisan neuron buatan berikutnya. Semua lapisan yang ada di antara Lapisan Input dan Lapisan Output disebut sebagai Lapisan Tersembunyi.
Di Lapisan Tersembunyi inilah neuron yang ada di dalamnya menggunakan input dan bias berbobot dan menghasilkan output menggunakan fungsi aktivasi. Output Layer adalah lapisan terakhir dari neuron yang memberikan kita output untuk program yang diberikan.
Sumber
Bagaimana Neural Network Bekerja?
Sekarang kita memiliki gagasan tentang struktur dasar Neural Networks, kita akan maju dan memahami cara kerjanya. Untuk memahami cara kerjanya, pertama-tama kita harus mempelajari salah satu struktur dasar Neural Networks, yang dikenal sebagai Perceptron.
Perceptron merupakan salah satu jenis Neural Network yang bentuknya paling dasar. Ini adalah jaringan saraf tiruan feed-forward sederhana dengan hanya satu lapisan tersembunyi. Dalam jaringan Perceptron, setiap neuron terhubung ke setiap neuron lainnya dalam arah maju.
Hubungan antara neuron-neuron ini diberi bobot karena informasi yang ditransfer antara dua neuron diperkuat atau dilemahkan oleh bobot ini. Dalam proses pelatihan Neural Networks, bobot inilah yang disesuaikan untuk mendapatkan nilai yang benar.
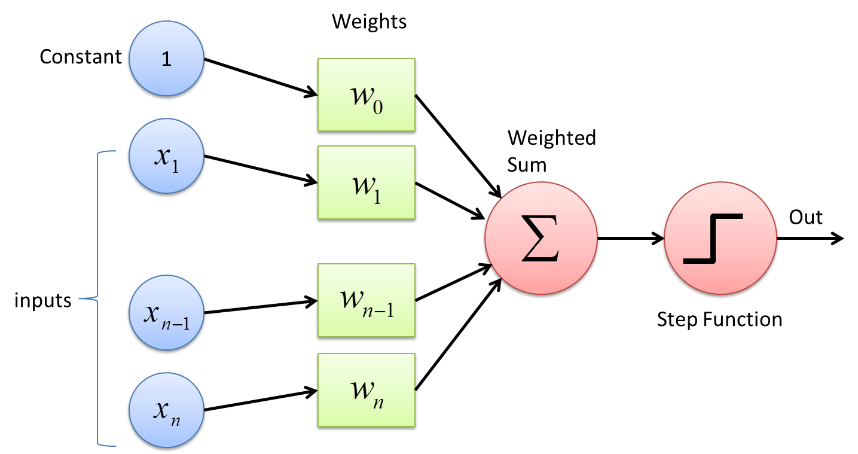
Perceptron menggunakan fungsi pengklasifikasi biner yang memetakan vektor variabel yang bersifat biner ke satu keluaran biner. Ini juga dapat digunakan dalam Pembelajaran Terawasi. Langkah-langkah dalam Algoritma Pembelajaran Perceptron adalah –
- Kalikan semua input dengan bobotnya w, di mana w adalah bilangan real yang awalnya dapat diperbaiki atau diacak.
- Tambahkan produk bersama-sama untuk mendapatkan jumlah tertimbang, wj xj
- Setelah jumlah bobot input diperoleh, Fungsi Aktivasi diterapkan untuk menentukan apakah jumlah bobot lebih besar dari nilai ambang tertentu atau tidak tergantung pada fungsi aktivasi yang diterapkan. Output ditetapkan sebagai 1 atau 0 tergantung pada kondisi ambang batas. Di sini nilai “-threshold” juga mengacu pada istilah bias, b.
Dengan cara ini, algoritma Perceptron Learning dapat digunakan untuk mengaktifkan (nilai = 1) neuron yang ada di Neural Networks yang dirancang dan dikembangkan saat ini. Representasi lain dari Algoritma Pembelajaran Perceptron adalah –
f(x) = 1, jika wj xj + b 0
0, jika wj xj + b < 0
Meskipun Perceptrons tidak banyak digunakan saat ini, Perceptron masih tetap sebagai salah satu konsep inti di Neural Networks. Pada penelitian lebih lanjut, diketahui bahwa perubahan kecil pada bobot atau bias bahkan pada satu perceptron dapat sangat mengubah output dari 1 menjadi 0 atau sebaliknya. Ini adalah salah satu kelemahan utama Perceptron. Oleh karena itu, fungsi aktivasi yang lebih kompleks seperti ReLU, fungsi Sigmoid dikembangkan yang hanya memperkenalkan perubahan moderat dalam bobot dan bias neuron buatan.
Sumber
Jaringan Saraf Konvolusional
Convolutional Neural Network adalah Algoritma Deep Learning yang mengambil gambar sebagai input, memberikan berbagai bobot dan bias ke berbagai bagian gambar sehingga mereka dapat dibedakan satu sama lain. Setelah mereka menjadi terdiferensiasi, menggunakan berbagai fungsi aktivasi Model Jaringan Saraf Konvolusi dapat melakukan beberapa tugas dalam domain Pemrosesan Gambar termasuk Pengenalan Gambar, Klasifikasi Gambar, Deteksi Objek dan Wajah, dll.
Dasar dari Convolutional Neural Network Model adalah menerima gambar masukan. Gambar input dapat diberi label (seperti kucing, anjing, singa, dll.) atau tidak berlabel. Tergantung pada ini, algoritma Deep Learning diklasifikasikan menjadi dua jenis yaitu Algoritma Supervised di mana gambar diberi label dan Algoritma Unsupervised di mana gambar tidak diberi label tertentu.
Untuk mesin komputer, gambar input dilihat sebagai array piksel, lebih sering dalam bentuk matriks. Gambar sebagian besar dalam bentuk hxwxd (Di mana h = Tinggi, w = Lebar, d = Dimensi). Misalnya, gambar dengan ukuran array matriks 16 x 16 x 3 menunjukkan Gambar RGB (3 singkatan dari nilai RGB). Di sisi lain, gambar array matriks 14 x 14 x 1 mewakili gambar skala abu-abu.
Sumber
Lapisan Jaringan Saraf Konvolusi
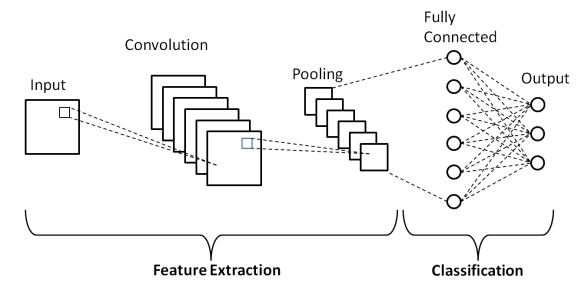
Seperti yang ditunjukkan dalam Arsitektur dasar Jaringan Saraf Konvolusi di atas, Model CNN terdiri dari beberapa lapisan di mana gambar input menjalani pra-pemrosesan untuk mendapatkan output. Pada dasarnya, lapisan ini dibedakan menjadi dua bagian –
- Tiga lapisan pertama termasuk Input Layer, Convolution Layer dan Pooling layer yang bertindak sebagai alat ekstraksi fitur untuk mendapatkan fitur tingkat dasar dari gambar yang dimasukkan ke dalam model.
- Lapisan Terhubung Sepenuhnya terakhir dan Lapisan Output memanfaatkan output dari lapisan ekstraksi fitur dan memprediksi kelas untuk gambar tergantung pada fitur yang diekstraksi.
Layer pertama adalah Input Layer dimana citra diumpankan ke dalam Convolutional Neural Network Model berupa array matriks yaitu 32 x 32 x 3, dimana 3 menyatakan bahwa citra tersebut merupakan citra RGB dengan tinggi dan lebar yang sama. dari 32 piksel. Kemudian, gambar masukan ini melewati Convolutional Layer dimana operasi matematika dari Convolution dilakukan.

Gambar input dililitkan dengan matriks persegi lain yang dikenal sebagai kernel atau filter. Dengan menggeser kernel satu per satu di atas piksel gambar input, kami memperoleh gambar output yang dikenal sebagai peta fitur yang memberikan informasi tentang fitur tingkat dasar gambar seperti tepi dan garis.
Convolutional Layer diikuti oleh Pooling layer yang bertujuan untuk mengurangi ukuran peta fitur untuk mengurangi biaya komputasi. Hal ini dilakukan dengan beberapa jenis pooling seperti Max Pooling, Average Pooling dan Sum Pooling.
Lapisan Terhubung Penuh (FC) adalah lapisan kedua dari belakang dari Model Jaringan Saraf Konvolusi di mana lapisan diratakan dan diumpankan ke lapisan FC. Di sini, dengan menggunakan fungsi aktivasi seperti fungsi Sigmoid, ReLU dan tanH, prediksi label terjadi dan diberikan di Output Layer akhir .
Dimana CNNs Jatuh Pendek
Dengan begitu banyak aplikasi Convolutional Neural Network yang berguna dalam data gambar visual, CNN memiliki kelemahan kecil karena mereka tidak bekerja dengan baik dengan urutan gambar (video) dan gagal dalam menafsirkan informasi temporal & blok teks.
Untuk menangani data temporal atau sekuensial seperti kalimat, kami memerlukan algoritma yang belajar dari data masa lalu dan juga data masa depan dalam urutan. Untungnya, Jaringan Saraf Berulang melakukan hal itu.
Jaringan Saraf Berulang
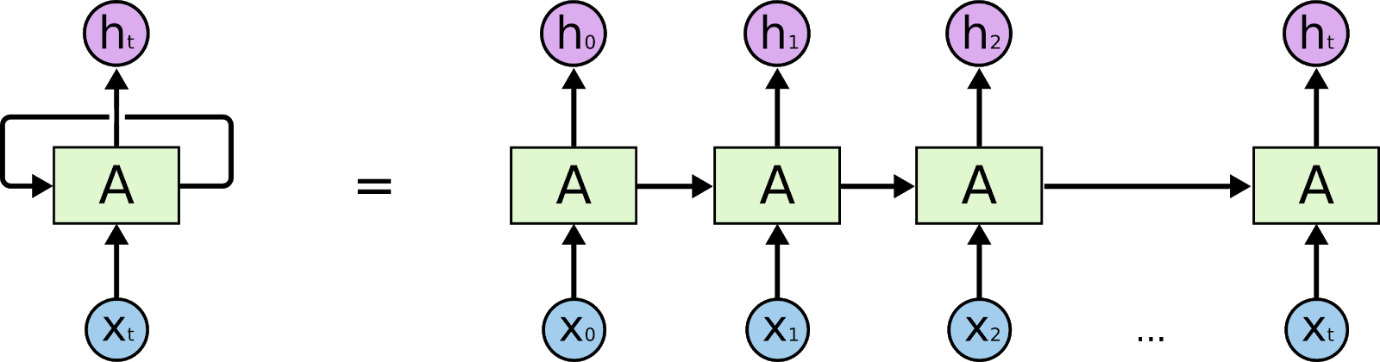
Recurrent Neural Networks adalah jaringan yang dirancang untuk menginterpretasikan informasi temporal atau sekuensial. RNN menggunakan titik data lain secara berurutan untuk membuat prediksi yang lebih baik. Mereka melakukan ini dengan mengambil input dan menggunakan kembali aktivasi node sebelumnya atau node yang lebih baru dalam urutan untuk mempengaruhi output.
Sumber
Sebagai hasil dari memori internal mereka, Jaringan Saraf Berulang dapat mengingat detail penting seperti input yang mereka terima, yang membuat mereka sangat tepat dalam memprediksi apa yang akan terjadi selanjutnya. Oleh karena itu, mereka adalah algoritma yang paling disukai untuk data sekuensial seperti deret waktu, ucapan, teks, audio, video, dan banyak lagi. Recurrent Neural Networks dapat membentuk pemahaman yang jauh lebih dalam tentang urutan dan konteksnya dibandingkan dengan algoritma lain.
Bagaimana Jaringan Saraf Berulang Bekerja?
Dasar untuk memahami cara kerja pada Recurrent Neural Network adalah sama dengan Convolutional Neural Network, Neural Network feed-forward sederhana, juga dikenal sebagai Perceptron. Selain itu, di jaringan Saraf Berulang, Output dari langkah sebelumnya diumpankan sebagai input ke langkah saat ini. Di sebagian besar Neural Network, output biasanya tidak tergantung pada input dan sebaliknya, ini adalah perbedaan mendasar antara RNN dan Neural Network lainnya.
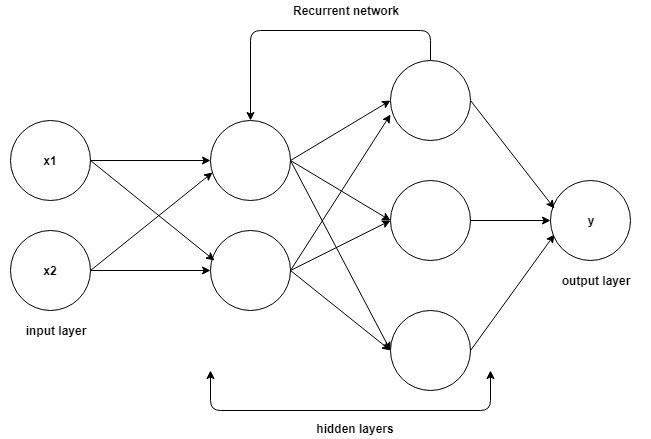
Sumber
Oleh karena itu, RNN memiliki dua input: masa kini dan masa lalu. Ini penting karena urutan data berisi informasi penting tentang apa yang akan terjadi selanjutnya, itulah sebabnya RNN dapat melakukan hal-hal yang tidak dapat dilakukan oleh algoritma lain. Fitur utama dan terpenting dari Recurrent Neural Networks adalah status Tersembunyi, yang mengingat beberapa informasi tentang suatu urutan.
Jaringan Saraf Berulang memiliki memori yang menyimpan semua informasi tentang apa yang telah dihitung. Dengan menggunakan parameter yang sama untuk setiap input dan melakukan tugas yang sama pada semua input atau lapisan tersembunyi, kompleksitas parameter berkurang.
Perbedaan Antara CNN dan RNN
| Jaringan Saraf Konvolusional | Jaringan Saraf Berulang |
| Dalam pembelajaran mendalam, jaringan saraf convolutional (CNN, atau ConvNet) adalah kelas jaringan saraf dalam, yang paling umum diterapkan untuk menganalisis citra visual. | Sebuah jaringan saraf berulang (RNN) adalah kelas jaringan saraf tiruan di mana koneksi antara node membentuk grafik diarahkan sepanjang urutan temporal. |
| Sangat cocok untuk data spasial seperti gambar. | RNN digunakan untuk data temporal, disebut juga data sekuensial. |
| CNN adalah jenis jaringan saraf tiruan feed-forward dengan variasi multilayer perceptron yang dirancang untuk menggunakan jumlah minimal preprocessing. | RNN, tidak seperti jaringan saraf feed-forward- dapat menggunakan memori internalnya untuk memproses urutan input yang berubah-ubah. |
| CNN dianggap lebih kuat dari RNN. | RNN menyertakan kompatibilitas fitur yang lebih sedikit jika dibandingkan dengan CNN. |
| CNN ini mengambil input dengan ukuran tetap dan menghasilkan output dengan ukuran tetap. | RNN dapat menangani panjang input/output yang berubah-ubah. |
| CNN ideal untuk pemrosesan gambar dan video. | RNN ideal untuk analisis teks dan ucapan. |
| Aplikasi termasuk Pengenalan Gambar, Klasifikasi Gambar, Analisis Gambar Medis, Deteksi Wajah, dan Penglihatan Komputer. | Aplikasi termasuk Terjemahan Teks, Pemrosesan Bahasa Alami, Terjemahan Bahasa, Analisis Sentimen, dan Analisis Pidato. |
Kesimpulan
Jadi, dalam artikel tentang perbedaan antara dua jenis Neural Network yang paling populer, Convolutional Neural Networks dan Recurrent Neural Networks, kita telah mempelajari struktur dasar Neural Network, bersama dengan dasar-dasar CNN dan RNN dan akhirnya merangkum sebuah perbandingan singkat antara keduanya dengan aplikasinya di dunia nyata.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat Program PG Eksekutif IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT -B Status Alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Mengapa CNN lebih cepat dari RNN?
CNN lebih cepat daripada RNN karena dirancang untuk menangani gambar, sedangkan RNN dirancang untuk menangani teks. Meskipun RNN dapat dilatih untuk menangani gambar, masih sulit bagi mereka untuk memisahkan fitur kontras yang lebih dekat satu sama lain. Seperti, misalnya, jika Anda memiliki gambar wajah dengan mata, hidung, dan mulut, RNN kesulitan menentukan fitur mana yang akan ditampilkan terlebih dahulu. CNN menggunakan grid poin, dan dengan menggunakan algoritma, mereka dapat dilatih untuk mengenali bentuk dan pola. CNN lebih baik daripada RNN dalam menyortir gambar; mereka lebih cepat daripada RNN karena mudah dihitung, dan lebih baik dalam menyortir gambar.
Untuk apa RNN digunakan?
Jaringan saraf berulang (RNNs) adalah kelas jaringan saraf tiruan di mana koneksi antar unit membentuk siklus terarah. Output dari satu unit menjadi input dari unit lain dan seterusnya, seperti output dari satu neuron menjadi input yang lain. RNN telah berhasil digunakan untuk melakukan tugas-tugas kompleks, seperti pengenalan suara dan terjemahan mesin, yang sulit dilakukan dengan metode standar.
Apa itu RNN dan apa bedanya dengan Feedforward Neural Networks?
Recurrent Neural Networks (RNNs) adalah sejenis Neural Network yang digunakan untuk memproses data sekuensial. Sebuah jaringan saraf berulang terdiri dari lapisan input, satu atau lebih lapisan tersembunyi dan lapisan output. Lapisan tersembunyi dirancang untuk mempelajari representasi internal dari data input, yang kemudian disajikan ke lapisan output sebagai representasi eksternal. RNN dilatih dengan bantuan backpropagation. RNN sering dibandingkan dengan feedforward neural networks (FNNs). Sementara RNN dan FNN dapat mempelajari representasi internal data, RNN mampu mempelajari dependensi jangka panjang, yang tidak dapat dilakukan oleh FNN.