
Membangun Layanan Logging Pusat In-House
Diterbitkan: 2022-03-10Kita semua tahu betapa pentingnya debugging untuk meningkatkan kinerja dan fitur aplikasi. BrowserStack menjalankan satu juta sesi sehari pada tumpukan aplikasi yang sangat terdistribusi! Masing-masing melibatkan beberapa bagian yang bergerak, karena satu sesi klien dapat menjangkau beberapa komponen di beberapa wilayah geografis.
Tanpa kerangka kerja dan alat yang tepat, proses debugging bisa menjadi mimpi buruk. Dalam kasus kami, kami membutuhkan cara untuk mengumpulkan peristiwa yang terjadi selama tahap yang berbeda dari setiap proses untuk mendapatkan pemahaman mendalam tentang segala sesuatu yang terjadi selama sesi. Dengan infrastruktur kami, pemecahan masalah ini menjadi rumit karena setiap komponen mungkin memiliki beberapa peristiwa dari siklus hidup pemrosesan permintaan.
Itu sebabnya kami mengembangkan alat Layanan Logging Pusat (CLS) internal kami sendiri untuk merekam semua peristiwa penting yang dicatat selama sesi. Peristiwa ini membantu pengembang kami mengidentifikasi kondisi di mana terjadi kesalahan dalam suatu sesi dan membantu melacak metrik produk utama tertentu.
Data debug berkisar dari hal-hal sederhana seperti latensi respons API hingga memantau kesehatan jaringan pengguna. Dalam artikel ini, kami membagikan kisah kami tentang membangun alat CLS kami yang mengumpulkan 70G data kronologis yang relevan per hari dari 100+ komponen secara andal, dalam skala besar dan dengan dua instans EC2 M3.large.
Keputusan Untuk Membangun In-House
Pertama, mari kita pertimbangkan mengapa kami membuat alat CLS kami sendiri daripada menggunakan solusi yang sudah ada. Setiap sesi kami mengirimkan rata-rata 15 acara, dari beberapa komponen ke layanan - diterjemahkan menjadi sekitar 15 juta total acara per hari.
Layanan kami membutuhkan kemampuan untuk menyimpan semua data ini. Kami mencari solusi lengkap untuk mendukung penyimpanan, pengiriman, dan kueri acara di seluruh acara. Saat kami mempertimbangkan solusi pihak ketiga seperti Amplitudo dan Keen, metrik evaluasi kami mencakup biaya, kinerja dalam menangani permintaan paralel yang tinggi, dan kemudahan penerapan. Sayangnya, kami tidak dapat menemukan kecocokan yang memenuhi semua persyaratan kami sesuai anggaran - meskipun manfaatnya mencakup penghematan waktu dan meminimalkan peringatan. Meskipun akan membutuhkan upaya tambahan, kami memutuskan untuk mengembangkan solusi internal sendiri.

Detail Teknis
Dalam hal arsitektur untuk komponen kami, kami menguraikan persyaratan dasar berikut:
- Kinerja Klien
Tidak memengaruhi kinerja klien/komponen yang mengirim acara. - Skala
Mampu menangani sejumlah besar permintaan secara paralel. - Kinerja layanan
Cepat untuk memproses semua acara yang dikirim ke sana. - Wawasan ke dalam data
Setiap peristiwa yang dicatat harus memiliki beberapa informasi meta agar dapat secara unik mengidentifikasi komponen atau pengguna, akun, atau pesan dan memberikan lebih banyak informasi untuk membantu pengembang melakukan debug lebih cepat. - Antarmuka yang dapat ditanyakan
Pengembang dapat menanyakan semua peristiwa untuk sesi tertentu, membantu men-debug sesi tertentu, membuat laporan kesehatan komponen, atau menghasilkan statistik kinerja yang berarti dari sistem kami. - Adopsi lebih cepat dan lebih mudah
Integrasi yang mudah dengan komponen yang ada atau baru tanpa membebani tim dan menghabiskan sumber daya mereka. - Perawatan yang rendah
Kami adalah tim teknik kecil, jadi kami mencari solusi untuk meminimalkan peringatan!
Membangun Solusi CLS Kami
Keputusan 1: Memilih Antarmuka Untuk Diekspos
Dalam mengembangkan CLS, kami jelas tidak ingin kehilangan data apa pun, tetapi kami juga tidak ingin kinerja komponen terpengaruh. Belum lagi faktor tambahan yang mencegah komponen yang ada menjadi lebih rumit, karena akan menunda adopsi dan rilis secara keseluruhan. Dalam menentukan antarmuka kami, kami mempertimbangkan pilihan berikut:
- Menyimpan peristiwa di Redis lokal di setiap komponen, saat prosesor latar belakang mendorongnya ke CLS. Namun, ini memerlukan perubahan di semua komponen, bersama dengan pengenalan Redis untuk komponen yang belum memuatnya.
- Penerbit - model Pelanggan, di mana Redis lebih dekat ke CLS. Saat semua orang memublikasikan acara, sekali lagi kami memiliki faktor komponen yang berjalan di seluruh dunia. Selama waktu lalu lintas tinggi, ini akan menunda komponen. Selanjutnya, tulisan ini sebentar-sebentar bisa melompat hingga lima detik (karena internet saja).
- Mengirim acara melalui UDP, yang menawarkan dampak yang lebih kecil pada kinerja aplikasi. Dalam hal ini data akan dikirim dan dilupakan, namun kerugiannya di sini adalah kehilangan data.
Menariknya, kehilangan data kami melalui UDP kurang dari 0,1 persen, yang merupakan jumlah yang dapat diterima bagi kami untuk mempertimbangkan membangun layanan semacam itu. Kami mampu meyakinkan semua tim bahwa jumlah kerugian ini sepadan dengan kinerjanya, dan melanjutkan untuk memanfaatkan antarmuka UDP yang mendengarkan semua acara yang dikirim.
Sementara satu hasil adalah dampak yang lebih kecil pada kinerja aplikasi, kami menghadapi masalah karena lalu lintas UDP tidak diizinkan dari semua jaringan, sebagian besar dari pengguna kami - menyebabkan kami dalam beberapa kasus tidak menerima data sama sekali. Sebagai solusinya, kami mendukung aktivitas logging menggunakan permintaan HTTP. Semua peristiwa yang datang dari sisi pengguna akan dikirim melalui HTTP, sedangkan semua peristiwa yang direkam dari komponen kami akan melalui UDP.
Keputusan 2: Tumpukan Teknologi (Bahasa, Kerangka Kerja & Penyimpanan)
Kami adalah toko Ruby. Namun, kami tidak yakin apakah Ruby akan menjadi pilihan yang lebih baik untuk masalah khusus kami. Layanan kami harus menangani banyak permintaan yang masuk, serta memproses banyak penulisan. Dengan kunci Global Interpreter, mencapai multithreading atau konkurensi akan sulit di Ruby (jangan tersinggung - kami menyukai Ruby!). Jadi kami membutuhkan solusi yang akan membantu kami mencapai konkurensi semacam ini.
Kami juga ingin mengevaluasi bahasa baru di tumpukan teknologi kami, dan proyek ini tampaknya sempurna untuk bereksperimen dengan hal-hal baru. Saat itulah kami memutuskan untuk mencoba Golang karena menawarkan dukungan bawaan untuk konkurensi dan thread serta go-routine yang ringan. Setiap titik data yang dicatat menyerupai pasangan nilai kunci di mana 'kunci' adalah peristiwa dan 'nilai' berfungsi sebagai nilai yang terkait.
Tetapi memiliki kunci dan nilai sederhana tidak cukup untuk mengambil data terkait sesi - ada lebih banyak metadata untuk itu. Untuk mengatasi ini, kami memutuskan acara apa pun yang perlu dicatat akan memiliki ID sesi bersama dengan kunci dan nilainya. Kami juga menambahkan bidang tambahan seperti stempel waktu, ID pengguna, dan komponen yang mencatat data, sehingga menjadi lebih mudah untuk mengambil dan menganalisis data.

Sekarang setelah kami memutuskan struktur muatan kami, kami harus memilih penyimpanan data kami. Kami mempertimbangkan Pencarian Elastis, tetapi kami juga ingin mendukung permintaan pembaruan untuk kunci. Ini akan memicu seluruh dokumen untuk diindeks ulang, yang mungkin memengaruhi kinerja penulisan kita. MongoDB lebih masuk akal sebagai penyimpanan data karena akan lebih mudah untuk menanyakan semua peristiwa berdasarkan salah satu bidang data yang akan ditambahkan. Ini mudah!
Keputusan 3: Ukuran DB Sangat Besar Dan Kueri Dan Pengarsipan Menyebalkan!
Untuk memotong pemeliharaan, layanan kami harus menangani sebanyak mungkin acara. Mengingat tingkat rilis fitur dan produk BrowserStack, kami yakin jumlah acara kami akan meningkat pada tingkat yang lebih tinggi dari waktu ke waktu, yang berarti layanan kami harus terus berkinerja baik. Seiring bertambahnya ruang, membaca dan menulis membutuhkan lebih banyak waktu – yang bisa menjadi pukulan besar pada kinerja layanan.
Solusi pertama yang kami jelajahi adalah memindahkan log dari periode tertentu dari database (dalam kasus kami, kami memutuskan pada 15 hari). Untuk melakukan ini, kami membuat database yang berbeda untuk setiap hari, memungkinkan kami menemukan log yang lebih lama dari periode tertentu tanpa harus memindai semua dokumen tertulis. Sekarang kami terus menghapus basis data yang lebih lama dari 15 hari dari Mongo, sambil tentu saja menyimpan cadangan untuk berjaga-jaga.
Satu-satunya bagian yang tersisa adalah antarmuka pengembang untuk menanyakan data terkait sesi. Sejujurnya, ini adalah masalah termudah untuk dipecahkan. Kami menyediakan antarmuka HTTP, di mana orang dapat menanyakan acara terkait sesi di database terkait di MongoDB, untuk data apa pun yang memiliki ID sesi tertentu.
Arsitektur
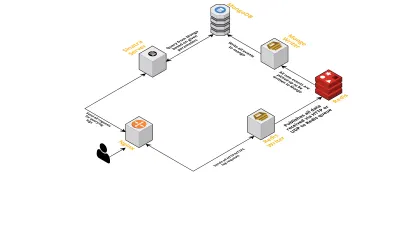
Mari kita bicara tentang komponen internal layanan, dengan mempertimbangkan poin-poin berikut:
- Seperti yang telah dibahas sebelumnya, kami membutuhkan dua antarmuka - satu mendengarkan melalui UDP dan satu lagi mendengarkan melalui HTTP. Jadi kami membangun dua server, sekali lagi satu untuk setiap antarmuka, untuk mendengarkan acara. Segera setelah acara tiba, kami menguraikannya untuk memeriksa apakah itu memiliki bidang yang diperlukan - ini adalah ID sesi, kunci, dan nilai. Jika tidak, data akan dihapus. Jika tidak, data dilewatkan melalui saluran Go ke goroutine lain, yang bertanggung jawab penuh untuk menulis ke MongoDB.
- Kemungkinan kekhawatiran di sini adalah menulis ke MongoDB. Jika penulisan ke MongoDB lebih lambat dari kecepatan data yang diterima, ini akan menciptakan kemacetan. Ini, pada gilirannya, membuat kelaparan acara masuk lainnya dan berarti data yang hilang. Oleh karena itu, server harus cepat dalam memproses log yang masuk dan siap untuk memproses log yang akan datang. Untuk mengatasi masalah ini, kami membagi server menjadi dua bagian: yang pertama menerima semua peristiwa dan mengantrekannya untuk yang kedua, yang memproses dan menulisnya ke dalam MongoDB.
- Untuk antrian kami memilih Redis. Dengan membagi seluruh komponen menjadi dua bagian ini, kami mengurangi beban kerja server, memberikan ruang untuk menangani lebih banyak log.
- Kami menulis layanan kecil menggunakan server Sinatra untuk menangani semua pekerjaan kueri MongoDB dengan parameter yang diberikan. Ini mengembalikan respons HTML/JSON kepada pengembang ketika mereka membutuhkan informasi tentang sesi tertentu.
Semua proses ini berjalan dengan senang hati pada satu instance m3.large tunggal.
Permintaan fitur
Karena alat CLS kami semakin banyak digunakan dari waktu ke waktu, alat ini membutuhkan lebih banyak fitur. Di bawah ini, kami membahas ini dan bagaimana mereka ditambahkan.
Metadata Hilang
Secara bertahap seiring bertambahnya jumlah komponen di BrowserStack, kami menuntut lebih banyak dari CLS. Misalnya, kami membutuhkan kemampuan untuk mencatat peristiwa dari komponen yang tidak memiliki ID sesi. Jika tidak, mendapatkannya akan membebani infrastruktur kami, dalam bentuk memengaruhi kinerja aplikasi dan menimbulkan lalu lintas di server utama kami.
Kami mengatasi ini dengan mengaktifkan pencatatan peristiwa menggunakan kunci lain, seperti terminal dan ID pengguna. Sekarang setiap kali sesi dibuat atau diperbarui, CLS diinformasikan dengan ID sesi, serta ID pengguna dan terminal masing-masing. Ini menyimpan peta yang dapat diambil dengan proses penulisan ke MongoDB. Setiap kali suatu peristiwa yang berisi pengguna atau ID terminal diambil, ID sesi ditambahkan.
Menangani Spamming (Masalah Kode Di Komponen Lain)
CLS juga menghadapi kesulitan biasa dalam menangani peristiwa spam. Kami sering menemukan penerapan dalam komponen yang menghasilkan sejumlah besar permintaan yang dikirim ke CLS. Log lain akan terganggu dalam prosesnya, karena server menjadi terlalu sibuk untuk memproses ini dan log penting dibuang.
Sebagian besar, sebagian besar data yang dicatat adalah melalui permintaan HTTP. Untuk mengontrolnya, kami mengaktifkan pembatasan kecepatan pada nginx (menggunakan modul limit_req_zone), yang memblokir permintaan dari IP mana pun yang kami temukan mengenai permintaan lebih dari jumlah tertentu dalam waktu singkat. Tentu saja, kami memanfaatkan laporan kesehatan pada semua IP yang diblokir dan memberi tahu tim yang bertanggung jawab.
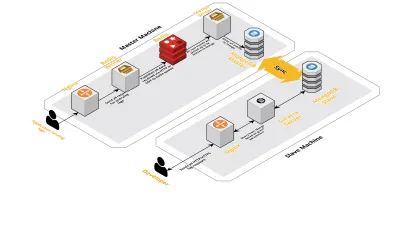
Skala v2
Karena sesi kami per hari meningkat, data yang dicatat ke CLS juga meningkat. Ini memengaruhi kueri yang dijalankan pengembang kami setiap hari, dan segera hambatan yang kami alami adalah dengan mesin itu sendiri. Pengaturan kami terdiri dari dua mesin inti yang menjalankan semua komponen di atas, bersama dengan sekumpulan skrip untuk menanyakan Mongo dan melacak metrik utama untuk setiap produk. Seiring waktu, data pada mesin telah meningkat pesat dan skrip mulai memakan banyak waktu CPU. Bahkan setelah mencoba mengoptimalkan kueri Mongo, kami selalu kembali ke masalah yang sama.
Untuk mengatasi ini, kami menambahkan mesin lain untuk menjalankan skrip laporan kesehatan dan antarmuka untuk menanyakan sesi ini. Prosesnya melibatkan mem-boot mesin baru dan menyiapkan budak Mongo yang berjalan di mesin utama. Ini telah membantu mengurangi lonjakan CPU yang kita lihat setiap hari yang disebabkan oleh skrip ini.
Kesimpulan
Membangun layanan untuk tugas sesederhana pencatatan data bisa menjadi rumit, karena jumlah data meningkat. Artikel ini membahas solusi yang kami jelajahi, beserta tantangan yang dihadapi saat menyelesaikan masalah ini. Kami bereksperimen dengan Golang untuk melihat seberapa cocoknya dengan ekosistem kami, dan sejauh ini kami puas. Pilihan kami untuk menciptakan layanan internal daripada membayar untuk layanan eksternal sangat hemat biaya. Kami juga tidak perlu menskalakan pengaturan kami ke komputer lain hingga beberapa saat kemudian - ketika volume sesi kami meningkat. Tentu saja, pilihan kami dalam mengembangkan CLS sepenuhnya didasarkan pada kebutuhan dan prioritas kami.
Saat ini CLS menangani hingga 15 juta acara setiap hari, yang merupakan data hingga 70 GB. Data ini digunakan untuk membantu kami memecahkan masalah apa pun yang dihadapi pelanggan kami selama sesi apa pun. Kami juga menggunakan data ini untuk tujuan lain. Mengingat wawasan yang diberikan oleh data setiap sesi tentang produk dan komponen internal yang berbeda, kami mulai memanfaatkan data ini untuk melacak setiap produk. Ini dicapai dengan mengekstrak metrik kunci untuk semua komponen penting.
Secara keseluruhan, kami telah melihat kesuksesan besar dalam membangun alat CLS kami sendiri. Jika itu masuk akal bagi Anda, saya sarankan Anda mempertimbangkan untuk melakukan hal yang sama!