
Cara Membuat Scraper Produk Amazon Dengan Node.js
Diterbitkan: 2022-03-10Pernahkah Anda berada dalam posisi di mana Anda perlu mengetahui secara mendalam pasar untuk produk tertentu? Mungkin Anda meluncurkan beberapa perangkat lunak dan perlu tahu bagaimana menentukan harganya. Atau mungkin Anda sudah memiliki produk sendiri di pasar dan ingin melihat fitur mana yang harus ditambahkan untuk keunggulan kompetitif. Atau mungkin Anda hanya ingin membeli sesuatu untuk diri sendiri dan ingin memastikan Anda mendapatkan yang terbaik untuk uang Anda.
Semua situasi ini memiliki satu kesamaan: Anda memerlukan data yang akurat untuk membuat keputusan yang benar . Sebenarnya, ada hal lain yang mereka bagikan. Semua skenario bisa mendapatkan keuntungan dari penggunaan scraper web.
Pengikisan web adalah praktik mengekstraksi data web dalam jumlah besar melalui penggunaan perangkat lunak. Jadi, pada dasarnya, ini adalah cara untuk mengotomatiskan proses yang membosankan dengan menekan 'salin' dan kemudian 'menempel' 200 kali. Tentu saja, bot dapat melakukannya dalam waktu yang Anda perlukan untuk membaca kalimat ini, jadi tidak hanya kurang membosankan tetapi juga jauh lebih cepat.
Tetapi pertanyaan yang membara adalah: mengapa seseorang ingin mengikis halaman Amazon?
Anda akan segera mengetahuinya! Tapi pertama-tama, saya ingin menjelaskan sesuatu sekarang — sementara tindakan menggores data yang tersedia untuk umum adalah legal, Amazon memiliki beberapa tindakan untuk mencegahnya di halaman mereka. Karena itu, saya mendorong Anda untuk selalu memperhatikan situs web saat menggores, berhati-hatilah agar tidak merusaknya, dan mengikuti pedoman etika.
Bacaan yang Direkomendasikan : “Panduan Pengikisan Etis Situs Web Dinamis Dengan Node.js Dan Puppeteer” oleh Andreas Altheimer
Mengapa Anda Harus Mengekstrak Data Produk Amazon
Menjadi pengecer online terbesar di planet ini, aman untuk mengatakan bahwa jika Anda ingin membeli sesuatu, Anda mungkin bisa mendapatkannya di Amazon. Jadi, tak perlu dikatakan seberapa besar harta karun data situs web itu.
Saat mengikis web, pertanyaan utama Anda adalah apa yang harus dilakukan dengan semua data itu. Meskipun ada banyak alasan individual, ini bermuara pada dua kasus penggunaan yang menonjol: mengoptimalkan produk Anda dan menemukan penawaran terbaik.
“
Mari kita mulai dengan skenario pertama. Kecuali Anda telah merancang produk baru yang benar-benar inovatif, kemungkinan besar Anda sudah dapat menemukan sesuatu yang setidaknya serupa di Amazon. Menggores halaman produk tersebut dapat memberi Anda data yang sangat berharga seperti:
- Strategi penetapan harga pesaing
Jadi, Anda dapat menyesuaikan harga agar kompetitif dan memahami cara orang lain menangani penawaran promosi; - Pendapat pelanggan
Untuk melihat apa yang paling dipedulikan oleh basis klien masa depan Anda dan bagaimana meningkatkan pengalaman mereka; - Fitur paling umum
Untuk melihat apa yang ditawarkan pesaing Anda untuk mengetahui fungsi mana yang penting dan mana yang dapat dibiarkan nanti.
Intinya, Amazon memiliki semua yang Anda butuhkan untuk analisis pasar dan produk yang mendalam. Anda akan lebih siap untuk merancang, meluncurkan, dan memperluas jajaran produk Anda dengan data tersebut.
Skenario kedua dapat berlaku untuk bisnis dan orang biasa. Idenya sangat mirip dengan apa yang saya sebutkan sebelumnya. Anda dapat mengikis harga, fitur, dan ulasan dari semua produk yang dapat Anda pilih, sehingga Anda dapat memilih salah satu yang menawarkan manfaat paling banyak dengan harga terendah. Lagi pula, siapa yang tidak suka penawaran bagus?
Tidak semua produk layak mendapatkan tingkat perhatian terhadap detail ini, tetapi dapat membuat perbedaan besar dengan pembelian yang mahal. Sayangnya, meskipun manfaatnya jelas, banyak kesulitan yang menyertai mengikis Amazon.
Tantangan Menggores Data Produk Amazon
Tidak semua situs web sama. Sebagai aturan praktis, semakin kompleks dan luas sebuah situs web, semakin sulit untuk mengikisnya. Ingat ketika saya mengatakan bahwa Amazon adalah situs e-commerce yang paling menonjol? Nah, itu membuatnya sangat populer dan cukup kompleks.
Pertama, Amazon tahu cara kerja bot pengikis, sehingga situs web memiliki tindakan pencegahan. Yaitu, jika scraper mengikuti pola yang dapat diprediksi, mengirimkan permintaan pada interval tetap, lebih cepat dari yang bisa dilakukan manusia atau dengan parameter yang hampir sama, Amazon akan memperhatikan dan memblokir IP. Proxy dapat mengatasi masalah ini, tetapi saya tidak membutuhkannya karena kami tidak akan menggores terlalu banyak halaman dalam contoh.
Selanjutnya, Amazon sengaja menggunakan struktur halaman yang bervariasi untuk produk mereka. Artinya, jika Anda memeriksa halaman untuk produk yang berbeda, ada kemungkinan besar Anda akan menemukan perbedaan yang signifikan dalam struktur dan atributnya. Alasan di balik ini cukup sederhana. Anda perlu menyesuaikan kode scraper Anda untuk sistem tertentu , dan jika Anda menggunakan skrip yang sama pada jenis halaman baru, Anda harus menulis ulang bagian-bagiannya. Jadi, mereka pada dasarnya membuat Anda bekerja lebih banyak untuk data.
Terakhir, Amazon adalah situs web yang luas. Jika Anda ingin mengumpulkan data dalam jumlah besar, menjalankan perangkat lunak pengikisan di komputer Anda mungkin akan memakan terlalu banyak waktu untuk kebutuhan Anda. Masalah ini semakin diperkuat oleh fakta bahwa berjalan terlalu cepat akan membuat scraper Anda terhalang. Jadi, jika Anda ingin memuat banyak data dengan cepat, Anda memerlukan scraper yang benar-benar kuat.
Nah, itu cukup berbicara tentang masalah, mari fokus pada solusi!
Cara Membuat Scraper Web Untuk Amazon
Untuk mempermudah, kami akan mengambil pendekatan langkah demi langkah untuk menulis kode. Jangan ragu untuk bekerja secara paralel dengan panduan ini.
Cari data yang kita butuhkan
Jadi, inilah skenarionya: Saya akan pindah dalam beberapa bulan ke tempat baru, dan saya memerlukan beberapa rak baru untuk menyimpan buku dan majalah. Saya ingin mengetahui semua pilihan saya dan mendapatkan kesepakatan sebaik mungkin. Jadi, mari kita pergi ke pasar Amazon, mencari "rak", dan melihat apa yang kita dapatkan.
URL untuk penelusuran ini dan laman yang akan kami gores ada di sini.
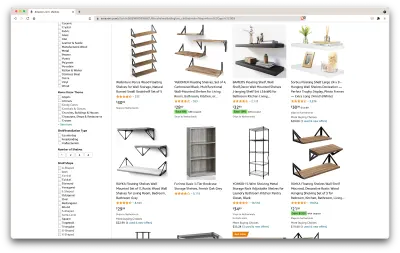
Oke, mari kita lihat apa yang kita miliki di sini. Hanya dengan melirik halaman, kita bisa mendapatkan gambaran yang baik tentang:
- bagaimana tampilan rak;
- apa yang termasuk dalam paket;
- bagaimana pelanggan menilai mereka;
- harga mereka;
- tautan ke produk;
- saran untuk alternatif yang lebih murah untuk beberapa item.
Itu lebih dari yang bisa kami minta!
Dapatkan alat yang dibutuhkan
Mari kita pastikan semua alat berikut telah diinstal dan dikonfigurasi sebelum melanjutkan ke langkah berikutnya.
- Chrome
Kita bisa mendownloadnya dari sini. - Kode VSC
Ikuti petunjuk di halaman ini untuk menginstalnya di perangkat khusus Anda. - Node.js
Sebelum mulai menggunakan Axios atau Cheerio, kita perlu menginstal Node.js dan Node Package Manager. Cara termudah untuk menginstal Node.js dan NPM adalah dengan mendapatkan salah satu installer dari sumber resmi Node.Js dan menjalankannya.
Sekarang, mari buat proyek NPM baru. Buat folder baru untuk proyek dan jalankan perintah berikut:
npm init -yUntuk membuat scraper web, kita perlu menginstal beberapa dependensi dalam proyek kita:
- ceria
Pustaka sumber terbuka yang membantu kami mengekstrak informasi yang berguna dengan mengurai markup dan menyediakan API untuk memanipulasi data yang dihasilkan. Cheerio memungkinkan kita untuk memilih tag dari dokumen HTML dengan menggunakan penyeleksi:$("div"). Pemilih khusus ini membantu kami memilih semua elemen<div>pada halaman. Untuk menginstal Cheerio, jalankan perintah berikut di folder proyek:
npm install cheerio- aksio
Pustaka JavaScript yang digunakan untuk membuat permintaan HTTP dari Node.js.
npm install axiosPeriksa sumber halaman
Dalam langkah-langkah berikut, kita akan mempelajari lebih lanjut tentang bagaimana informasi diatur di halaman. Idenya adalah untuk mendapatkan pemahaman yang lebih baik tentang apa yang dapat kita gali dari sumber kita.
Alat pengembang membantu kami menjelajahi Model Objek Dokumen (DOM) situs web secara interaktif. Kami akan menggunakan alat pengembang di Chrome, tetapi Anda dapat menggunakan browser web apa pun yang nyaman bagi Anda.
Mari kita buka dengan mengklik kanan di mana saja pada halaman dan memilih opsi "Periksa":
Ini akan membuka jendela baru yang berisi kode sumber halaman. Seperti yang telah kami katakan sebelumnya, kami mencari untuk mengikis informasi setiap rak.
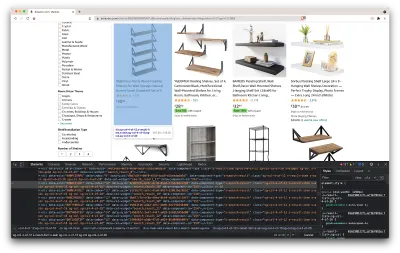
Seperti yang dapat kita lihat dari tangkapan layar di atas, wadah yang menampung semua data memiliki kelas berikut:

sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20Pada langkah selanjutnya, kita akan menggunakan Cheerio untuk memilih semua elemen yang berisi data yang kita butuhkan.
Ambil datanya
Setelah kita menginstal semua dependensi yang disajikan di atas, mari buat file index.js baru dan ketik baris kode berikut:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); Seperti yang bisa kita lihat, kita mengimpor dependensi yang kita butuhkan pada dua baris pertama, dan kemudian kita membuat fungsi fetchShelves() yang, menggunakan Cheerio, mendapatkan semua elemen yang berisi informasi produk kita dari halaman.
Itu mengulangi masing-masing dan mendorongnya ke array kosong untuk mendapatkan hasil yang diformat lebih baik.
Fungsi fetchShelves() hanya akan mengembalikan judul produk saat ini, jadi mari dapatkan informasi lainnya yang kita butuhkan. Harap tambahkan baris kode berikut setelah baris di mana kita mendefinisikan title variabel.
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } Dan ganti shelves.push(title) dengan shelves.push(element) .
Kami sekarang memilih semua informasi yang kami butuhkan dan menambahkannya ke objek baru yang disebut element . Setiap elemen kemudian didorong ke shelves untuk mendapatkan daftar objek yang hanya berisi data yang kita cari.
Beginilah tampilan objek shelf sebelum ditambahkan ke daftar kami:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }Format datanya
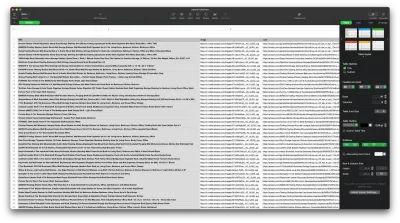
Sekarang kita telah berhasil mengambil data yang kita butuhkan, ada baiknya untuk menyimpannya sebagai file .CSV untuk meningkatkan keterbacaan. Setelah mendapatkan semua data, kita akan menggunakan modul fs yang disediakan oleh Node.js dan menyimpan file baru bernama saved-shelves.csv ke folder proyek. Impor modul fs di bagian atas file dan salin atau tulis di sepanjang baris kode berikut:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) Seperti yang bisa kita lihat, pada tiga baris pertama, kita memformat data yang telah kita kumpulkan sebelumnya dengan menggabungkan semua nilai objek rak menggunakan koma. Kemudian, dengan menggunakan modul fs , kita membuat file bernama saved-shelves.csv , menambahkan baris baru yang berisi header kolom, menambahkan data yang baru saja kita format dan membuat fungsi panggilan balik yang menangani kesalahan.
Hasilnya akan terlihat seperti ini:
Kiat Bonus!
Menggores Aplikasi Halaman Tunggal
Konten dinamis menjadi standar saat ini, karena situs web lebih kompleks dari sebelumnya. Untuk memberikan pengalaman pengguna sebaik mungkin, pengembang harus mengadopsi mekanisme pemuatan yang berbeda untuk konten dinamis , membuat pekerjaan kita sedikit lebih rumit. Jika Anda tidak tahu apa artinya, bayangkan browser tidak memiliki antarmuka pengguna grafis. Untungnya, ada Puppeteer — pustaka Node ajaib yang menyediakan API tingkat tinggi untuk mengontrol instance Chrome melalui Protokol DevTools. Namun, ia menawarkan fungsionalitas yang sama seperti browser, tetapi harus dikontrol secara terprogram dengan mengetikkan beberapa baris kode. Mari kita lihat cara kerjanya.
Dalam proyek yang telah dibuat sebelumnya, instal pustaka Dalang dengan menjalankan npm install puppeteer , buat file puppeteer.js baru, dan salin atau tulis di sepanjang baris kode berikut:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() Pada contoh di atas, kami membuat instance Chrome dan membuka halaman browser baru yang diperlukan untuk membuka tautan ini. Pada baris berikut, kami memberi tahu browser tanpa kepala untuk menunggu hingga elemen dengan kelas rpBJOHq2PR60pnwJlUyP0 muncul di halaman. Kami juga telah menentukan berapa lama browser harus menunggu halaman dimuat (2000 milidetik).
Menggunakan metode evaluate pada variabel page , kami menginstruksikan Dalang untuk mengeksekusi cuplikan Javascript dalam konteks halaman tepat setelah elemen akhirnya dimuat. Ini akan memungkinkan kita untuk mengakses konten HTML halaman dan mengembalikan badan halaman sebagai output. Kami kemudian menutup instance Chrome dengan memanggil metode close pada variabel chrome . Pekerjaan yang dihasilkan harus terdiri dari semua kode HTML yang dihasilkan secara dinamis. Beginilah cara Dalang dapat membantu kami memuat konten HTML dinamis .
Jika Anda merasa tidak nyaman menggunakan Dalang, perhatikan bahwa ada beberapa alternatif di luar sana, seperti NightwatchJS, NightmareJS, atau CasperJS. Mereka sedikit berbeda, tetapi pada akhirnya, prosesnya sangat mirip.
Mengatur Header user-agent
user-agent adalah header permintaan yang memberi tahu situs web yang Anda kunjungi tentang diri Anda, yaitu browser dan OS Anda. Ini digunakan untuk mengoptimalkan konten untuk pengaturan Anda, tetapi situs web juga menggunakannya untuk mengidentifikasi bot yang mengirim banyak permintaan — bahkan jika itu mengubah IPS.
Berikut tampilan header user-agent :
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36Agar tidak terdeteksi dan diblokir, sebaiknya Anda mengganti header ini secara berkala. Berhati-hatilah untuk tidak mengirim tajuk kosong atau usang karena ini seharusnya tidak pernah terjadi pada pengguna biasa, dan Anda akan menonjol.
Pembatasan Tarif
Pencakar web dapat mengumpulkan konten dengan sangat cepat, tetapi Anda harus menghindari kecepatan tinggi. Ada dua alasan untuk ini:
- Terlalu banyak permintaan dalam waktu singkat dapat memperlambat server situs web atau bahkan menurunkannya, menyebabkan masalah bagi pemilik dan pengunjung lainnya. Ini pada dasarnya bisa menjadi serangan DoS.
- Tanpa memutar proxy, ini seperti mengumumkan dengan keras bahwa Anda menggunakan bot karena tidak ada manusia yang akan mengirim ratusan atau ribuan permintaan per detik.
Solusinya adalah dengan memperkenalkan penundaan antara permintaan Anda, praktik yang disebut "pembatasan tarif". ( Ini cukup sederhana untuk diterapkan juga! )
Dalam contoh Dalang yang diberikan di atas, sebelum membuat variabel body , kita dapat menggunakan metode waitForTimeout yang disediakan oleh Dalang untuk menunggu beberapa detik sebelum membuat permintaan lain:
await page.waitForTimeout(3000); Di mana ms adalah jumlah detik yang ingin Anda tunggu.
Juga, jika kita ingin melakukan hal yang sama untuk contoh aksio, kita dapat membuat janji yang memanggil metode setTimeout() , untuk membantu kita menunggu jumlah milidetik yang kita inginkan:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))Dengan cara ini, Anda dapat menghindari terlalu banyak tekanan pada server yang ditargetkan dan juga, membawa pendekatan yang lebih manusiawi ke web scraping.
Pikiran Penutup
Dan begitulah, panduan langkah demi langkah untuk membuat scraper web Anda sendiri untuk data produk Amazon! Tapi ingat, ini hanya satu situasi. Jika Anda ingin mengikis situs web yang berbeda, Anda harus melakukan beberapa penyesuaian untuk mendapatkan hasil yang berarti.
Bacaan Terkait
Jika Anda masih ingin melihat lebih banyak web scraping beraksi, berikut adalah beberapa bahan bacaan yang berguna untuk Anda:
- “Panduan Utama untuk Pengikisan Web dengan JavaScript dan Node.Js,” Robert Sfichi
- “Pengikisan Web Node.JS Tingkat Lanjut dengan Dalang,” Gabriel Cioci
- “Python Web Scraping: Panduan Utama untuk Membangun Scraper Anda,” Raluca Penciuc