Panduan Pemula untuk Convolutional Neural Network (CNN)
Diterbitkan: 2021-07-05Dekade terakhir telah melihat pertumbuhan luar biasa dalam Kecerdasan Buatan dan mesin yang lebih cerdas. Bidang ini telah memunculkan banyak sub-disiplin yang mengkhususkan diri dalam aspek-aspek berbeda dari kecerdasan manusia. Misalnya, pemrosesan bahasa alami mencoba memahami dan memodelkan ucapan manusia, sedangkan visi komputer bertujuan untuk memberikan visi seperti manusia ke mesin.
Karena kita akan berbicara tentang Convolutional Neural Networks, fokus kita sebagian besar adalah pada visi komputer. Visi komputer bertujuan untuk memungkinkan mesin melihat dunia seperti yang kita lakukan dan memecahkan masalah yang terkait dengan pengenalan gambar, klasifikasi gambar, dan banyak lagi. Convolutional Neural Networks digunakan untuk mencapai berbagai tugas visi komputer. Juga dikenal sebagai CNN atau ConvNet, mereka mengikuti arsitektur yang menyerupai pola dan koneksi neuron di otak manusia dan terinspirasi oleh berbagai proses biologis yang terjadi di otak untuk membuat komunikasi terjadi.
Daftar isi
Signifikansi biologis dari Jaringan Saraf yang Berbelit-belit
CNN terinspirasi oleh korteks visual kita. Ini adalah area korteks serebral yang terlibat dalam pemrosesan visual di otak kita. Korteks visual memiliki berbagai daerah seluler kecil yang sensitif terhadap rangsangan visual.
Ide ini diperluas pada tahun 1962 oleh Hubel dan Wiesel dalam sebuah eksperimen di mana ditemukan bahwa sel-sel saraf yang berbeda merespons (dipecat) dengan adanya tepi yang berbeda dari orientasi tertentu. Misalnya, beberapa neuron akan menyala saat mendeteksi tepi horizontal, yang lain mendeteksi tepi diagonal, dan beberapa lainnya akan menyala saat mendeteksi tepi vertikal. Melalui percobaan ini. Hubel dan Wiesel menemukan bahwa neuron diatur secara modular, dan semua modul bersama-sama diperlukan untuk menghasilkan persepsi visual.
Pendekatan modular ini – gagasan bahwa komponen khusus di dalam sistem memiliki tugas khusus – adalah yang menjadi dasar CNN.
Setelah itu selesai, mari beralih ke cara CNN belajar memahami input visual.

Pembelajaran Jaringan Saraf Konvolusi
Gambar terdiri dari piksel individual, yang merupakan representasi antara angka 0 dan 255. Jadi, gambar apa pun yang Anda lihat dapat diubah menjadi representasi digital yang tepat dengan menggunakan angka-angka ini – dan begitulah cara komputer juga bekerja dengan gambar.
Berikut adalah beberapa operasi utama yang membuat CNN belajar untuk deteksi atau klasifikasi gambar. Ini akan memberi Anda gambaran tentang bagaimana pembelajaran berlangsung di CNN.
1. Konvolusi
Konvolusi secara matematis dapat dipahami sebagai integrasi gabungan dari dua fungsi yang berbeda untuk mengetahui bagaimana pengaruh dari fungsi yang berbeda atau memodifikasi satu sama lain. Berikut cara mendefinisikannya dalam istilah matematika:
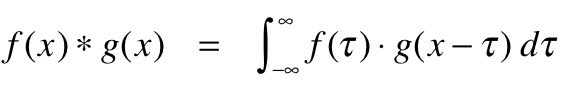
Tujuan dari konvolusi adalah untuk mendeteksi fitur visual yang berbeda dalam gambar, seperti garis, tepi, warna, bayangan, dan banyak lagi. Ini adalah properti yang sangat berguna karena setelah CNN Anda mempelajari karakteristik fitur tertentu dalam gambar, CNN nantinya dapat mengenali fitur tersebut di bagian lain gambar.
CNN menggunakan kernel atau filter untuk mendeteksi berbagai fitur yang ada dalam gambar apa pun. Kernel hanyalah matriks nilai yang berbeda (dikenal sebagai bobot di dunia Jaringan Syaraf Tiruan) yang dilatih untuk mendeteksi fitur tertentu. Filter bergerak di seluruh gambar untuk memeriksa apakah ada fitur yang terdeteksi atau tidak. Filter melakukan operasi konvolusi untuk memberikan nilai akhir yang menunjukkan seberapa yakin fitur tertentu ada.
Jika ada fitur pada citra, hasil operasi konvolusi adalah bilangan positif dengan nilai tinggi. Jika fitur tidak ada, operasi konvolusi menghasilkan 0 atau angka bernilai sangat rendah.
Mari kita memahami ini lebih baik menggunakan sebuah contoh. Pada gambar di bawah, filter telah dilatih untuk mendeteksi tanda plus. Kemudian, filter dilewatkan di atas gambar asli. Karena bagian dari gambar asli berisi fitur yang sama dengan filter yang dilatih, nilai di setiap sel tempat fitur tersebut ada adalah angka positif. Demikian juga hasil operasi konvolusi juga akan menghasilkan bilangan yang besar.
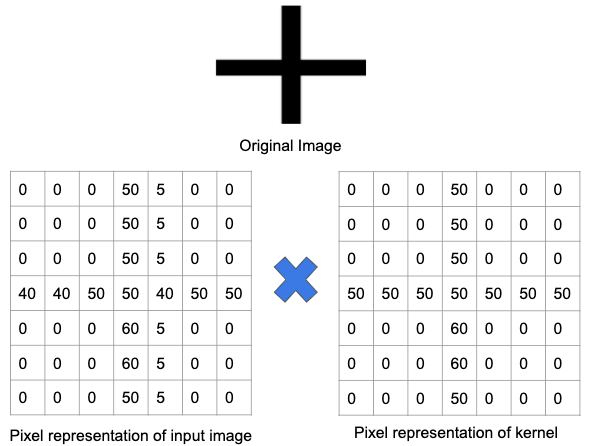
Namun, ketika filter yang sama dilewatkan pada gambar dengan serangkaian fitur dan tepi yang berbeda, output dari operasi konvolusi akan lebih rendah – menyiratkan tidak adanya tanda tambah yang kuat pada gambar.
Jadi, dalam kasus gambar kompleks yang memiliki berbagai fitur seperti kurva, tepi, warna, dan sebagainya, kita memerlukan sejumlah N pendeteksi fitur tersebut.
Ketika filter ini dilewatkan melalui gambar, peta fitur dihasilkan yang pada dasarnya adalah matriks keluaran yang menyimpan konvolusi filter ini di berbagai bagian gambar. Dalam kasus banyak filter, kita akan berakhir dengan output 3D. Filter ini harus memiliki jumlah saluran yang sama dengan gambar input agar operasi konvolusi berlangsung.
Selanjutnya, filter dapat digeser di atas gambar input pada interval yang berbeda, menggunakan nilai langkah. Nilai langkah menginformasikan seberapa banyak filter harus bergerak di setiap langkah.
Oleh karena itu, jumlah lapisan keluaran dari blok konvolusi yang diberikan dapat ditentukan dengan menggunakan rumus berikut:

2. Bantalan
Satu masalah saat bekerja dengan lapisan convolutional adalah bahwa beberapa piksel cenderung hilang di sekeliling gambar asli. Karena umumnya, filter yang digunakan berukuran kecil, piksel yang hilang per filter mungkin sedikit, tetapi ini bertambah saat kami menerapkan lapisan konvolusi yang berbeda, yang mengakibatkan banyak piksel hilang.
Konsep padding adalah tentang menambahkan piksel ekstra ke gambar saat filter CNN memprosesnya. Ini adalah salah satu solusi untuk membantu filter dalam pemrosesan gambar – dengan mengisi gambar dengan nol untuk memberikan lebih banyak ruang bagi kernel untuk menutupi seluruh gambar. Dengan menambahkan nol padding ke filter, pemrosesan gambar oleh CNN jauh lebih akurat dan tepat.

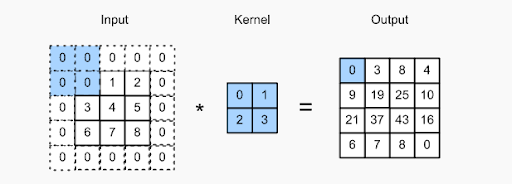
Periksa gambar di atas – padding telah dilakukan dengan menambahkan nol tambahan pada batas gambar input. Ini memungkinkan pengambilan semua fitur berbeda tanpa kehilangan piksel apa pun.
3. Peta Aktivasi
Peta fitur perlu melewati fungsi pemetaan yang bersifat non-linier. Peta fitur disertakan dengan istilah bias dan kemudian melewati fungsi aktivasi (ReLu), yang non-linier. Fungsi ini bertujuan untuk membawa sejumlah nonlinier ke dalam CNN karena gambar yang dideteksi dan diperiksa juga bersifat nonlinier, terdiri dari objek yang berbeda.
4. Tahap Penyatuan
Setelah fase aktivasi selesai, kami melanjutkan ke langkah penyatuan, di mana CNN menurunkan sampel fitur yang berbelit-belit, yang membantu menghemat waktu pemrosesan. Ini juga membantu dalam mengurangi ukuran keseluruhan gambar, overfitting, dan masalah lain yang akan terjadi jika Jaringan Saraf Saraf yang Berbelit-belit diberi banyak informasi – terutama jika informasi itu tidak terlalu relevan dalam mengklasifikasikan atau mendeteksi gambar.
Pooling pada dasarnya terdiri dari dua jenis – max pooling dan min pooling. Pada yang pertama, sebuah jendela dilewatkan di atas gambar sesuai dengan nilai langkah yang ditetapkan, dan pada setiap langkah, nilai maksimum yang termasuk dalam jendela dikumpulkan dalam matriks keluaran. Dalam pooling min, nilai minimum dikumpulkan dalam matriks output.
Matriks baru yang terbentuk sebagai hasil dari output disebut pooled feature map.
Dari min dan max pooling, salah satu keuntungan dari max-pooling adalah memungkinkan CNN untuk fokus pada beberapa neuron yang memiliki nilai tinggi daripada fokus pada semua neuron. Pendekatan seperti itu membuatnya sangat kecil kemungkinannya untuk menyesuaikan data pelatihan dan membuat prediksi dan generalisasi keseluruhan berjalan dengan baik.
5. Meratakan
Setelah pooling selesai, representasi 3D dari gambar kini telah diubah menjadi vektor fitur. Ini kemudian diteruskan ke perceptron multi-layer untuk menghasilkan output. Lihat gambar di bawah ini untuk lebih memahami operasi perataan:
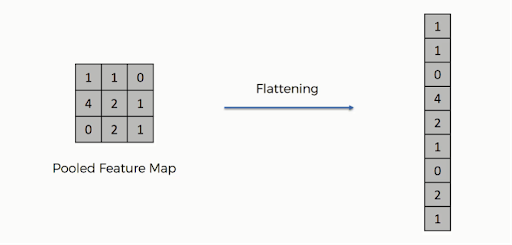
Seperti yang Anda lihat, baris matriks digabungkan menjadi satu vektor fitur. Jika beberapa lapisan input hadir, semua baris terhubung untuk membentuk vektor fitur yang lebih rata.
6. Lapisan Terhubung Sepenuhnya (FCL)
Pada langkah ini, peta yang diratakan diumpankan ke jaringan saraf. Koneksi lengkap jaringan saraf mencakup lapisan input, FCL, dan lapisan output akhir. Lapisan yang terhubung penuh dapat dipahami sebagai lapisan tersembunyi di Jaringan Syaraf Tiruan, kecuali, tidak seperti lapisan tersembunyi, lapisan ini sepenuhnya terhubung. Informasi melewati seluruh jaringan, dan kesalahan prediksi dihitung. Kesalahan ini kemudian dikirim sebagai umpan balik (backpropagation) melalui sistem untuk menyesuaikan bobot dan meningkatkan hasil akhir, agar lebih akurat.
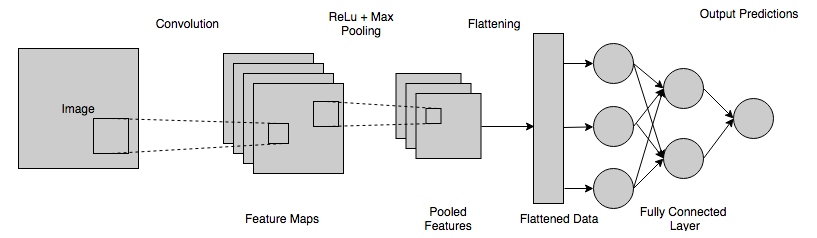
Keluaran akhir yang diperoleh dari lapisan jaringan saraf di atas umumnya tidak berjumlah satu. Output ini perlu diturunkan ke angka dalam kisaran [0,1] – yang kemudian akan mewakili probabilitas setiap kelas. Untuk ini, fungsi Softmax digunakan.
Output yang diperoleh dari lapisan padat diumpankan ke fungsi aktivasi Softmax. Melalui ini, semua output akhir dipetakan ke vektor di mana jumlah semua elemen menjadi satu.
Lapisan yang terhubung penuh bekerja dengan melihat output lapisan sebelumnya dan kemudian menentukan fitur mana yang paling berkorelasi dengan kelas tertentu. Jadi, jika program memprediksi apakah suatu gambar mengandung kucing atau tidak, itu akan memiliki nilai tinggi di peta aktivasi yang mewakili fitur seperti empat kaki, cakar, ekor, dan sebagainya. Demikian juga, jika program memprediksi sesuatu yang lain, itu akan memiliki berbagai jenis peta aktivasi. Lapisan yang sepenuhnya terhubung menangani berbagai fitur yang sangat berkorelasi dengan kelas dan bobot tertentu sehingga perhitungan antara bobot dan lapisan sebelumnya akurat, dan Anda mendapatkan probabilitas yang benar untuk kelas keluaran yang berbeda.
Ringkasan singkat tentang cara kerja CNN
Berikut adalah ringkasan singkat dari keseluruhan proses bagaimana CNN bekerja dan membantu dalam visi komputer:
- Piksel yang berbeda dari gambar diumpankan ke lapisan konvolusi, di mana operasi konvolusi dilakukan.
- Langkah sebelumnya menghasilkan peta yang berbelit-belit.
- Peta ini dilewatkan melalui fungsi penyearah untuk memunculkan peta yang diperbaiki.
- Gambar diproses dengan konvolusi dan fungsi aktivasi yang berbeda untuk menemukan dan mendeteksi fitur yang berbeda.
- Pooling layer digunakan untuk mengidentifikasi bagian gambar yang spesifik dan berbeda.
- Lapisan yang dikumpulkan diratakan dan digunakan sebagai input ke lapisan yang terhubung sepenuhnya.
- Lapisan yang terhubung penuh menghitung probabilitas dan memberikan output dalam kisaran [0,1].
Kesimpulannya
Fungsi internal CNN sangat menarik dan membuka banyak kemungkinan untuk inovasi dan kreasi. Demikian juga, teknologi lain di bawah payung Kecerdasan Buatan sangat menarik dan mencoba bekerja antara kemampuan manusia dan kecerdasan mesin. Akibatnya, orang-orang dari seluruh dunia, yang termasuk dalam domain yang berbeda, menyadari minat mereka di bidang ini dan mengambil langkah pertama.
Untungnya, industri AI sangat ramah dan tidak membedakan berdasarkan latar belakang akademis Anda. Yang Anda butuhkan hanyalah pengetahuan tentang teknologi bersama dengan kualifikasi dasar, dan Anda sudah siap!
Jika Anda ingin menguasai seluk beluk ML dan AI, tindakan yang ideal adalah mendaftar di program AI/ML profesional. Misalnya, Program Eksekutif kami dalam Pembelajaran Mesin dan AI adalah kursus yang sempurna untuk calon ilmu data. Program ini mencakup mata pelajaran seperti statistik dan analisis data eksplorasi, pembelajaran mesin, dan pemrosesan bahasa alami. Juga, ini mencakup lebih dari 13 proyek industri, 25+ sesi langsung, dan 6 proyek batu penjuru. Bagian terbaik dari kursus ini adalah Anda dapat berinteraksi dengan rekan-rekan dari seluruh dunia. Ini memfasilitasi pertukaran ide dan membantu pelajar membangun hubungan yang langgeng dengan orang-orang dari berbagai latar belakang. Bantuan karir 360 derajat kami adalah apa yang Anda butuhkan untuk unggul dalam perjalanan ML dan AI Anda!
Pimpin Revolusi Teknologi Berbasis AI