
Teorema Bayes dalam Pembelajaran Mesin: Pendahuluan, Cara Menerapkan & Contoh
Diterbitkan: 2021-02-04Daftar isi
Pendahuluan: Apa itu Teorema Bayes?
Teorema Bayes dinamai untuk matematikawan Inggris Thomas Bayes, yang bekerja secara ekstensif dalam teori keputusan, bidang matematika yang melibatkan probabilitas. Teorema Bayes juga digunakan secara luas dalam pembelajaran mesin, yang merupakan cara sederhana dan efektif untuk memprediksi kelas dengan presisi dan akurasi. Metode Bayesian untuk menghitung probabilitas bersyarat digunakan dalam aplikasi pembelajaran mesin yang melibatkan tugas klasifikasi.
Versi sederhana dari Teorema Bayes, yang dikenal sebagai Klasifikasi Naive Bayes, digunakan untuk mengurangi waktu dan biaya komputasi. Pada artikel ini, kami membawa Anda melalui konsep-konsep ini dan mendiskusikan penerapan Teorema Bayes dalam pembelajaran mesin.
Bergabunglah dengan kursus pembelajaran mesin online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
Mengapa menggunakan Teorema Bayes dalam Pembelajaran Mesin?
Teorema Bayes adalah metode untuk menentukan probabilitas bersyarat - yaitu, probabilitas satu peristiwa yang terjadi mengingat peristiwa lain telah terjadi. Karena probabilitas bersyarat mencakup kondisi tambahan – dengan kata lain, lebih banyak data – ini dapat berkontribusi pada hasil yang lebih akurat.
Dengan demikian, probabilitas bersyarat adalah suatu keharusan dalam menentukan prediksi dan probabilitas yang akurat dalam Machine Learning. Mengingat bahwa bidang ini semakin tersebar luas di berbagai domain, penting untuk memahami peran algoritme dan metode seperti Teorema Bayes dalam Pembelajaran Mesin.
Sebelum kita masuk ke teorema itu sendiri, mari kita pahami beberapa istilah melalui sebuah contoh. Katakanlah seorang manajer toko buku memiliki informasi tentang usia dan pendapatan pelanggannya. Dia ingin tahu bagaimana penjualan buku didistribusikan di tiga kelas usia pelanggan: remaja (18-35), paruh baya (35-60), dan manula (60+).

Mari kita istilahkan data kita X. Dalam terminologi Bayesian, X disebut bukti. Kami memiliki beberapa hipotesis H, di mana kami memiliki beberapa X yang termasuk dalam kelas C tertentu.
Tujuan kami adalah untuk menentukan probabilitas bersyarat dari hipotesis kami H diberikan X, yaitu, P(H | X).
Secara sederhana, dengan menentukan P(H | X), kita mendapatkan probabilitas X termasuk dalam kelas C, mengingat X. X memiliki atribut usia dan pendapatan – katakanlah, misalnya, berusia 26 tahun dengan pendapatan $2000. H adalah hipotesis kami bahwa pelanggan akan membeli buku.
Perhatikan empat istilah berikut ini:
- Bukti – Seperti yang telah dibahas sebelumnya, P(X) dikenal sebagai bukti. Ini hanyalah probabilitas bahwa pelanggan akan, dalam hal ini, berusia 26 tahun, menghasilkan $2000.
- Probabilitas Sebelumnya – P(H), yang dikenal sebagai probabilitas sebelumnya, adalah probabilitas sederhana dari hipotesis kami – yaitu, bahwa pelanggan akan membeli buku. Probabilitas ini tidak akan diberikan input tambahan berdasarkan usia dan pendapatan. Karena perhitungan dilakukan dengan informasi yang lebih sedikit, hasilnya kurang akurat.
- Probabilitas Posterior – P(H | X) dikenal sebagai probabilitas posterior. Di sini, P(H | X) adalah probabilitas pelanggan membeli buku (H) jika diberi X (bahwa dia berusia 26 tahun dan berpenghasilan $2000).
- Kemungkinan – P(X | H) adalah probabilitas kemungkinan. Dalam kasus ini, jika kita tahu pelanggan akan membeli buku, probabilitas kemungkinan adalah probabilitas bahwa pelanggan berusia 26 tahun dan memiliki pendapatan $2000.
Mengingat ini, Teorema Bayes menyatakan:
P(H | X) = [ P(X | H) * P(H) ] / P(X)
Perhatikan kemunculan empat istilah di atas dalam teorema – probabilitas posterior, probabilitas kemungkinan, probabilitas sebelumnya, dan bukti.
Baca: Penjelasan Naive Bayes
Cara Menerapkan Teorema Bayes dalam Pembelajaran Mesin
Naive Bayes Classifier, versi sederhana dari Teorema Bayes, digunakan sebagai algoritma klasifikasi untuk mengklasifikasikan data ke dalam berbagai kelas dengan akurasi dan kecepatan.
Mari kita lihat bagaimana Naive Bayes Classifier dapat diterapkan sebagai algoritma klasifikasi.
- Perhatikan contoh umum: X adalah vektor yang terdiri dari atribut 'n', yaitu, X = {x1, x2, x3, …, xn}.
- Katakanlah kita memiliki kelas 'm' {C1, C2, …, Cm}. Pengklasifikasi kami harus memprediksi X milik kelas tertentu. Kelas yang memberikan probabilitas posterior tertinggi akan dipilih sebagai kelas terbaik. Jadi secara matematis, classifier akan memprediksi untuk kelas Ci jika P(Ci | X) > P(Cj | X). Menerapkan Teorema Bayes:
P(Ci | X) = [ P(X | Ci) * P(Ci) ] / P(X)
- P(X), karena kondisi-independen, adalah konstan untuk setiap kelas. Jadi untuk memaksimalkan P(Ci | X), kita harus memaksimalkan [P(X | Ci) * P(Ci)]. Mengingat setiap kelas memiliki peluang yang sama, kita memiliki P(C1) = P(C2) = P(C3) … = P(Cn). Jadi pada akhirnya, kita hanya perlu memaksimalkan P(X | Ci).
- Karena kumpulan data besar biasanya memiliki beberapa atribut, maka secara komputasi mahal untuk melakukan operasi P(X | Ci) untuk setiap atribut. Di sinilah independensi bersyarat kelas masuk untuk menyederhanakan masalah dan mengurangi biaya komputasi. Dengan independensi bersyarat kelas, yang kami maksud adalah bahwa kami menganggap nilai atribut independen satu sama lain secara kondisional. Ini adalah Klasifikasi Naive Bayes.
P(Xi | C) = P(x1 | C) * P(x2 | C) *… * P(xn | C)
Sekarang mudah untuk menghitung probabilitas yang lebih kecil. Satu hal penting yang perlu diperhatikan di sini: karena xk milik setiap atribut, kita juga perlu memeriksa apakah atribut yang kita hadapi adalah categorical atau continuous .
- Jika kita memiliki atribut kategoris , semuanya menjadi lebih sederhana. Kita dapat menghitung jumlah instance kelas Ci yang terdiri dari nilai xk untuk atribut k dan kemudian membaginya dengan jumlah instance kelas Ci.
- Jika kita memiliki atribut kontinu, mengingat kita memiliki fungsi distribusi normal, kita menerapkan rumus berikut, dengan mean ? dan simpangan baku?:
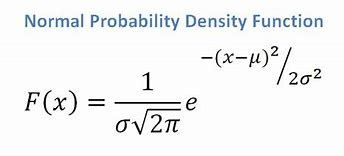

Sumber
Akhirnya, kita akan memiliki P(x | Ci) = F(xk, ?k, ?k).
- Sekarang, kita memiliki semua nilai yang kita butuhkan untuk menggunakan Teorema Bayes untuk setiap kelas Ci. Kelas prediksi kami akan menjadi kelas yang mencapai probabilitas tertinggi P(X | Ci) * P(Ci).
Contoh: Secara Prediktif Mengklasifikasikan Pelanggan Toko Buku
Kami memiliki dataset berikut dari toko buku:
| Usia | Penghasilan | Murid | Peringkat kredit | Beli_Buku |
| Anak muda | Tinggi | Tidak | Adil | Tidak |
| Anak muda | Tinggi | Tidak | Bagus sekali | Tidak |
| Paruh baya | Tinggi | Tidak | Adil | Ya |
| Senior | Sedang | Tidak | Adil | Ya |
| Senior | Rendah | Ya | Adil | Ya |
| Senior | Rendah | Ya | Bagus sekali | Tidak |
| Paruh baya | Rendah | Ya | Bagus sekali | Ya |
| Anak muda | Sedang | Tidak | Adil | Tidak |
| Anak muda | Rendah | Ya | Adil | Ya |
| Senior | Sedang | Ya | Adil | Ya |
| Anak muda | Sedang | Ya | Bagus sekali | Ya |
| Paruh baya | Sedang | Tidak | Bagus sekali | Ya |
| Paruh baya | Tinggi | Ya | Adil | Ya |
| Senior | Sedang | Tidak | Bagus sekali | Tidak |
Kami memiliki atribut seperti usia, pendapatan, siswa, dan peringkat kredit. Kelas kami, buys_book, memiliki dua hasil: Ya atau Tidak.
Tujuan kami adalah untuk mengklasifikasikan berdasarkan atribut berikut:
X = {umur = muda, pelajar = ya, pendapatan = sedang, kredit_rating = cukup}.
Seperti yang kita tunjukkan sebelumnya, untuk memaksimalkan P(Ci | X), kita perlu memaksimalkan [ P(X | Ci) * P(Ci) ] untuk i = 1 dan i = 2.
Jadi, P(beli_buku = ya) = 14/9 = 0,643
P(beli_buku = tidak ada) = 14/5 = 0,357
P(umur = remaja | beli_buku = ya) = 2/9 = 0,222
P(umur = muda | beli_buku = tidak) =3/5 = 0,600
P(penghasilan = sedang | buku_pembelian = ya) = 4/9 = 0,444
P(penghasilan = sedang | buku_pembelian = tidak) = 2/5 = 0,400
P(siswa = ya | beli_buku = ya) = 6/9 = 0,667
P(siswa = ya | beli_buku = tidak) = 1/5 = 0,200
P(peringkat_kredit = wajar | buku_pembelian = ya) = 6/9 = 0,667
P(peringkat_kredit = wajar | buku_pembelian = tidak) = 2/5 = 0,400
Dengan menggunakan probabilitas yang dihitung di atas, kita memiliki
P(X | beli_buku = ya) = 0,222 x 0,444 x 0,667 x 0,667 = 0,044
Demikian pula,
P(X | beli_buku = tidak) = 0,600 x 0,400 x 0,200 x 0,400 = 0,019
Kelas manakah yang memberikan nilai P(X|Ci)*P(Ci) maksimum? Kami menghitung:
P(X | beli_buku = ya)* P(beli_buku = ya) = 0,044 x 0,643 = 0,028
P(X | beli_buku = tidak)* P(beli_buku = tidak) = 0,019 x 0,357 = 0,007
Membandingkan dua di atas, karena 0,028 > 0,007, Pengklasifikasi Naive Bayes memprediksi bahwa pelanggan dengan atribut yang disebutkan di atas akan membeli buku.
Lihat: Ide & Topik Proyek Pembelajaran Mesin
Apakah Pengklasifikasi Bayesian Metode yang Baik?
Algoritma berdasarkan Teorema Bayes dalam pembelajaran mesin memberikan hasil yang sebanding dengan algoritma lain, dan pengklasifikasi Bayesian umumnya dianggap sebagai metode akurasi tinggi yang sederhana. Namun, perhatian harus diberikan untuk mengingat bahwa pengklasifikasi Bayesian sangat sesuai di mana asumsi independensi bersyarat kelas valid, dan tidak di semua kasus. Kekhawatiran praktis lainnya adalah bahwa memperoleh semua data probabilitas mungkin tidak selalu layak.
Kesimpulan
Teorema Bayes memiliki banyak aplikasi dalam pembelajaran mesin, terutama dalam masalah berbasis klasifikasi. Menerapkan keluarga algoritma ini dalam pembelajaran mesin melibatkan keakraban dengan istilah-istilah seperti probabilitas sebelumnya dan probabilitas posterior. Dalam artikel ini, kami membahas dasar-dasar Teorema Bayes, penggunaannya dalam masalah pembelajaran mesin, dan bekerja melalui contoh klasifikasi.
Karena Teorema Bayes merupakan bagian penting dari algoritme berbasis klasifikasi dalam Pembelajaran Mesin, Anda dapat mempelajari lebih lanjut tentang Program Sertifikat Tingkat Lanjut upGrad dalam Pembelajaran Mesin & NLP . Kursus ini telah dibuat dengan mengingat berbagai jenis siswa yang tertarik dengan Pembelajaran Mesin, menawarkan bimbingan 1-1 dan banyak lagi.
Mengapa kita menggunakan teorema Bayes dalam Machine Learning?
Teorema Bayes adalah metode untuk menghitung probabilitas bersyarat, atau kemungkinan satu peristiwa terjadi jika yang lain telah terjadi sebelumnya. Probabilitas bersyarat dapat menghasilkan hasil yang lebih akurat dengan menyertakan kondisi tambahan — dengan kata lain, lebih banyak data. Untuk mendapatkan estimasi dan probabilitas yang benar dalam Machine Learning, probabilitas bersyarat diperlukan. Mengingat meningkatnya prevalensi bidang ini di berbagai domain, sangat penting untuk memahami pentingnya algoritme dan pendekatan seperti Teorema Bayes dalam Pembelajaran Mesin.
Apakah Bayesian Classifier merupakan pilihan yang baik?
Dalam pembelajaran mesin, algoritme berdasarkan Teorema Bayes menghasilkan hasil yang sebanding dengan metode lain, dan pengklasifikasi Bayesian secara luas dianggap sebagai pendekatan akurasi tinggi yang sederhana. Namun, penting untuk diingat bahwa pengklasifikasi Bayesian paling baik digunakan ketika kondisi independensi bersyarat kelas benar, tidak dalam semua keadaan. Pertimbangan lain adalah bahwa memperoleh semua data kemungkinan tidak selalu memungkinkan.
Bagaimana teorema Bayes dapat diterapkan secara praktis?
Teorema Bayes menghitung kemungkinan terjadinya berdasarkan bukti baru yang terkait atau dapat dikaitkan dengannya. Metode ini juga dapat digunakan untuk melihat bagaimana informasi baru hipotetis mempengaruhi kemungkinan suatu peristiwa, dengan asumsi informasi baru itu benar. Ambil, misalnya, satu kartu yang dipilih dari setumpuk 52 kartu. Peluang kartu menjadi raja adalah 4 dibagi 52, atau 1/13, atau kira-kira 7,69 persen. Perlu diingat bahwa dek berisi empat raja. Katakanlah terungkap bahwa kartu yang dipilih adalah kartu wajah. Karena ada 12 kartu wajah dalam satu dek, kemungkinan kartu yang terambil adalah raja adalah 4 dibagi 12, atau kira-kira 33,3 persen.