
6 Fitur Pengubah Game Apache Spark pada 2022 [Bagaimana Seharusnya Anda Menggunakannya]
Diterbitkan: 2021-01-07Sejak Big Data menguasai dunia teknologi dan bisnis, telah terjadi peningkatan yang sangat besar pada alat dan platform Big Data, terutama Apache Hadoop dan Apache Spark. Hari ini, kita hanya akan fokus pada Apache Spark dan membahas panjang lebar tentang manfaat bisnis dan aplikasinya.
Apache Spark menjadi pusat perhatian pada tahun 2009, dan sejak itu, secara bertahap mengukir ceruk untuk dirinya sendiri di industri. Menurut Apache org., Spark adalah "mesin analitik terpadu secepat kilat" yang dirancang untuk memproses sejumlah besar Data Besar. Berkat komunitas yang aktif, hari ini, Spark adalah salah satu platform Big Data open-source terbesar di dunia.
Daftar isi
Apa itu Apache Spark?
Awalnya dikembangkan di AMPLab University of California (Berkeley), Spark dirancang sebagai mesin pemrosesan yang tangguh untuk data Hadoop, dengan fokus khusus pada kecepatan dan kemudahan penggunaan. Ini adalah alternatif sumber terbuka untuk Hadoop's MapReduce. Pada dasarnya, Spark adalah kerangka kerja pemrosesan data paralel yang dapat berkolaborasi dengan Apache Hadoop untuk memfasilitasi pengembangan aplikasi Big Data canggih yang lancar dan cepat di Hadoop.
Spark hadir dengan berbagai pustaka untuk algoritma Machine Learning (ML) dan algoritma grafik. Tidak hanya itu, ia juga mendukung streaming real-time dan aplikasi SQL melalui Spark Streaming dan Shark. Bagian terbaik tentang menggunakan Spark adalah Anda dapat menulis aplikasi Spark di Java, Scala, atau bahkan Python, dan aplikasi ini akan berjalan hampir sepuluh kali lebih cepat (pada disk) dan 100 kali lebih cepat (dalam memori) daripada aplikasi MapReduce.
Apache Spark cukup serbaguna karena dapat digunakan dalam banyak cara, dan juga menawarkan binding asli untuk bahasa pemrograman Java, Scala, Python, dan R. Ini mendukung SQL, pemrosesan grafik, streaming data, dan Pembelajaran Mesin. Inilah sebabnya mengapa Spark banyak digunakan di berbagai sektor industri, termasuk bank, perusahaan telekomunikasi, perusahaan pengembangan game, lembaga pemerintah, dan tentu saja, di semua perusahaan top dunia teknologi – Apple, Facebook, IBM, dan Microsoft.
6 Fitur Terbaik Apache Spark
Fitur yang menjadikan Spark salah satu platform Big Data yang paling banyak digunakan adalah:

1. Kecepatan pemrosesan yang sangat cepat
Pemrosesan Big Data adalah tentang memproses sejumlah besar data kompleks. Oleh karena itu, ketika berbicara tentang pemrosesan Big Data, organisasi dan perusahaan menginginkan kerangka kerja seperti itu yang dapat memproses sejumlah besar data dengan kecepatan tinggi. Seperti yang kami sebutkan sebelumnya, aplikasi Spark dapat berjalan hingga 100x lebih cepat di memori dan 10x lebih cepat di disk di cluster Hadoop.
Itu bergantung pada Resilient Distributed Dataset (RDD) yang memungkinkan Spark menyimpan data secara transparan di memori dan membaca/menulisnya ke disk hanya jika diperlukan. Ini membantu mengurangi sebagian besar waktu baca dan tulis disk selama pemrosesan data.
2. Kemudahan penggunaan
Spark memungkinkan Anda untuk menulis aplikasi yang dapat diskalakan di Java, Scala, Python, dan R. Jadi, pengembang mendapatkan ruang lingkup untuk membuat dan menjalankan aplikasi Spark dalam bahasa pemrograman pilihan mereka. Selain itu, Spark dilengkapi dengan lebih dari 80 operator tingkat tinggi bawaan. Anda dapat menggunakan Spark secara interaktif untuk menanyakan data dari shell Scala, Python, R, dan SQL.
3. Menawarkan dukungan untuk analitik canggih
Spark tidak hanya mendukung operasi "peta" dan "mengurangi" sederhana, tetapi juga mendukung kueri SQL, data streaming, dan analitik lanjutan, termasuk ML dan algoritme grafik. Muncul dengan tumpukan perpustakaan yang kuat seperti SQL & DataFrames dan MLlib (untuk ML), GraphX, dan Spark Streaming. Yang menarik adalah bahwa Spark memungkinkan Anda menggabungkan kemampuan semua perpustakaan ini dalam satu alur kerja/aplikasi.
4. Pemrosesan aliran waktu nyata
Spark dirancang untuk menangani streaming data waktu nyata. Sementara MapReduce dibangun untuk menangani dan memproses data yang sudah disimpan di cluster Hadoop, Spark dapat melakukan keduanya dan juga memanipulasi data secara real-time melalui Spark Streaming.
Tidak seperti solusi streaming lainnya, Spark Streaming dapat memulihkan pekerjaan yang hilang dan memberikan semantik yang tepat di luar kotak tanpa memerlukan kode atau konfigurasi tambahan. Plus, ini juga memungkinkan Anda menggunakan kembali kode yang sama untuk pemrosesan batch dan streaming dan bahkan untuk menggabungkan data streaming ke data historis.
5. Ini fleksibel
Spark dapat berjalan secara independen dalam mode cluster, dan juga dapat berjalan di Hadoop YARN, Apache Mesos, Kubernetes, dan bahkan di cloud. Selain itu, dapat mengakses sumber data yang beragam. Misalnya, Spark dapat berjalan di manajer klaster YARN dan membaca data Hadoop yang ada. Itu dapat membaca dari sumber data Hadoop seperti HBase, HDFS, Hive, dan Cassandra. Aspek Spark ini menjadikannya alat yang ideal untuk memigrasikan aplikasi Hadoop murni, asalkan kasus penggunaan aplikasi ramah terhadap Spark.
6. Komunitas yang aktif dan berkembang
Pengembang dari lebih 300 perusahaan telah berkontribusi untuk merancang dan membangun Apache Spark. Sejak 2009, lebih dari 1200 pengembang telah berkontribusi secara aktif untuk menjadikan Spark seperti sekarang ini! Secara alami, Spark didukung oleh komunitas pengembang aktif yang bekerja untuk meningkatkan fitur dan kinerjanya secara terus-menerus. Untuk menjangkau komunitas Spark, Anda dapat menggunakan milis untuk pertanyaan apa pun, dan Anda juga dapat menghadiri grup pertemuan dan konferensi Spark.
Anatomi Aplikasi Spark
Setiap aplikasi Spark terdiri dari dua proses inti – proses penggerak utama dan kumpulan proses pelaksana .
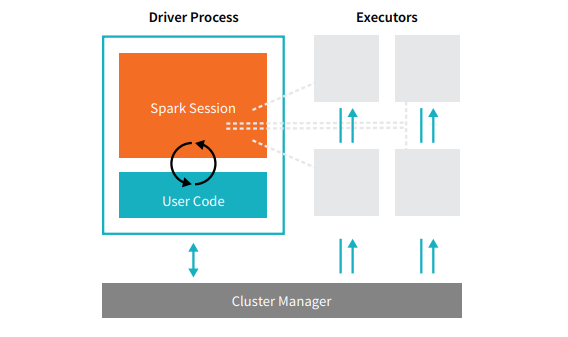
Sumber
Proses driver yang berada di node dalam cluster bertanggung jawab untuk menjalankan fungsi main(). Ini juga menangani tiga tugas lain – memelihara informasi tentang Aplikasi Spark, menanggapi kode atau input pengguna, dan menganalisis, mendistribusikan, dan menjadwalkan pekerjaan di seluruh pelaksana. Proses driver merupakan inti dari Aplikasi Spark – berisi dan memelihara semua informasi penting yang mencakup masa pakai aplikasi Spark.

Pelaksana atau proses pelaksana adalah item sekunder yang harus menjalankan tugas yang diberikan kepada mereka oleh driver. Pada dasarnya, setiap pelaksana melakukan dua fungsi penting – menjalankan kode yang diberikan oleh driver dan melaporkan status komputasi (pada pelaksana itu) ke node driver. Pengguna dapat memutuskan dan mengkonfigurasi berapa banyak pelaksana yang harus dimiliki setiap node.
Dalam aplikasi Spark, manajer cluster mengontrol semua mesin dan mengalokasikan sumber daya ke aplikasi. Di sini, manajer cluster dapat menjadi salah satu dari manajer cluster inti Spark, termasuk YARN (manajer cluster mandiri Spark) atau Mesos. Ini mensyaratkan bahwa sebuah cluster dapat menjalankan beberapa Aplikasi Spark secara bersamaan.
Aplikasi Apache Spark dunia nyata
Spark adalah platform Big Dara berperingkat teratas dan banyak digunakan di industri modern. Beberapa contoh aplikasi Apache Spark di dunia nyata yang paling terkenal adalah:
Percikan untuk Pembelajaran Mesin
Apache Spark membanggakan perpustakaan Machine Learning yang dapat diskalakan – MLlib. Pustaka ini secara eksplisit dirancang untuk kesederhanaan, skalabilitas, dan memfasilitasi integrasi tanpa batas dengan alat lain. MLlib tidak hanya memiliki skalabilitas, kompatibilitas bahasa, dan kecepatan Spark, tetapi juga dapat melakukan sejumlah tugas analitik tingkat lanjut seperti klasifikasi, pengelompokan, pengurangan dimensi. Berkat MLlib, Spark dapat digunakan untuk analisis prediktif, analisis sentimen, segmentasi pelanggan, dan kecerdasan prediktif.
Fitur lain yang mengesankan dari Apache Spark terletak pada domain keamanan jaringan. Spark Streaming memungkinkan pengguna untuk memantau paket data secara real time sebelum memasukkannya ke penyimpanan. Selama proses ini, ia dapat berhasil mengidentifikasi aktivitas mencurigakan atau berbahaya yang muncul dari sumber ancaman yang diketahui. Bahkan setelah paket data dikirim ke penyimpanan, Spark menggunakan MLlib untuk menganalisis data lebih lanjut dan mengidentifikasi potensi risiko pada jaringan. Fitur ini juga dapat digunakan untuk mendeteksi penipuan dan kejadian.
Percikan untuk Komputasi Kabut
Apache Spark adalah alat yang sangat baik untuk komputasi kabut, terutama jika menyangkut Internet of Things (IoT). IoT sangat bergantung pada konsep pemrosesan paralel skala besar. Karena jaringan IoT terdiri dari ribuan dan jutaan perangkat yang terhubung, data yang dihasilkan oleh jaringan ini setiap detik berada di luar pemahaman.
Secara alami, untuk memproses data dalam jumlah besar yang dihasilkan oleh perangkat IoT, Anda memerlukan platform skalabel yang mendukung pemrosesan paralel. Dan apa yang lebih baik daripada arsitektur kuat Spark dan kemampuan komputasi kabut untuk menangani data dalam jumlah besar seperti itu!
Komputasi kabut mendesentralisasikan data dan penyimpanan, dan alih-alih menggunakan pemrosesan cloud, ia melakukan fungsi pemrosesan data di tepi jaringan (terutama tertanam di perangkat IoT).
Untuk melakukan ini, komputasi kabut membutuhkan tiga kemampuan, yaitu latensi rendah, pemrosesan paralel ML, dan algoritma analisis grafik yang kompleks – yang masing-masing ada di Spark. Selain itu, kehadiran Spark Streaming, Shark (alat kueri interaktif yang dapat berfungsi secara real-time), MLlib, dan GraphX (mesin analisis grafik) semakin meningkatkan kemampuan komputasi kabut Spark.
Percikan untuk Analisis Interaktif
Tidak seperti MapReduce, atau Hive, atau Pig, yang memiliki kecepatan pemrosesan yang relatif rendah, Spark dapat membanggakan analitik interaktif berkecepatan tinggi. Ia mampu menangani kueri eksplorasi tanpa memerlukan pengambilan sampel data. Juga, Spark kompatibel dengan hampir semua bahasa pengembangan populer, termasuk R, Python, SQL, Java, dan Scala.
Versi terbaru Spark – Spark 2.0 – menampilkan fungsionalitas baru yang dikenal sebagai Streaming Terstruktur. Dengan fitur ini, pengguna dapat menjalankan kueri terstruktur dan interaktif terhadap data streaming secara real-time.
Pengguna Spark
Sekarang setelah Anda mengetahui dengan baik fitur dan kemampuan Spark, mari kita bicara tentang empat pengguna terkemuka Spark!
1. Yahoo
Yahoo menggunakan Spark untuk dua proyeknya, satu untuk mempersonalisasi halaman berita untuk pengunjung dan yang lainnya untuk menjalankan analitik untuk iklan. Untuk menyesuaikan halaman berita, Yahoo menggunakan algoritme ML canggih yang berjalan di Spark untuk memahami minat, preferensi, dan kebutuhan masing-masing pengguna dan mengkategorikan berita yang sesuai.
Untuk kasus penggunaan kedua, Yahoo memanfaatkan kemampuan interaktif Hive on Spark (untuk berintegrasi dengan alat apa pun yang dihubungkan ke Hive) untuk melihat dan menanyakan data analitik periklanan Yahoo yang dikumpulkan di Hadoop.
2. Uber
Uber menggunakan Spark Streaming dalam kombinasi dengan Kafka dan HDFS untuk ETL (mengekstrak, mengubah, dan memuat) sejumlah besar data real-time dari peristiwa diskrit menjadi data terstruktur dan dapat digunakan untuk analisis lebih lanjut. Data ini membantu Uber untuk merancang solusi yang lebih baik bagi pelanggan.

3. Konviva
Sebagai perusahaan streaming video, Conviva memperoleh rata-rata lebih dari 4 juta umpan video setiap bulan, yang menyebabkan churn pelanggan besar-besaran. Tantangan ini semakin diperparah oleh masalah pengelolaan lalu lintas video langsung. Untuk mengatasi tantangan ini secara efektif, Conviva menggunakan Spark Streaming untuk mempelajari kondisi jaringan secara real-time dan mengoptimalkan lalu lintas videonya. Hal ini memungkinkan Conviva memberikan pengalaman menonton yang konsisten dan berkualitas tinggi kepada pengguna.
4. Pinterest
Di Pinterest, pengguna dapat menyematkan topik favorit mereka kapan pun mereka mau saat menjelajahi Web dan media sosial. Untuk menawarkan pengalaman pelanggan yang dipersonalisasi dan ditingkatkan, Pinterest memanfaatkan kemampuan ETL Spark untuk mengidentifikasi kebutuhan dan minat unik setiap pengguna dan memberikan rekomendasi yang relevan kepada mereka di Pinterest.
Kesimpulan
Sebagai kesimpulan, Spark adalah platform Big Data yang sangat serbaguna dengan fitur yang dibuat untuk mengesankan. Karena ini adalah kerangka kerja sumber terbuka, ia terus meningkat dan berkembang, dengan fitur dan fungsi baru yang ditambahkan ke dalamnya. Seiring aplikasi Big Data menjadi lebih beragam dan ekspansif, demikian pula kasus penggunaan Apache Spark.
Jika Anda tertarik untuk mengetahui lebih banyak tentang Big Data, lihat Diploma PG kami dalam Spesialisasi Pengembangan Perangkat Lunak dalam program Big Data yang dirancang untuk para profesional yang bekerja dan menyediakan 7+ studi kasus & proyek, mencakup 14 bahasa & alat pemrograman, praktik langsung lokakarya, lebih dari 400 jam pembelajaran yang ketat & bantuan penempatan kerja dengan perusahaan-perusahaan top.
Lihat Kursus Rekayasa Perangkat Lunak kami yang lain di upGrad.