
Arsitektur Apache Kafka: Panduan Komprehensif Untuk Pemula [2022]
Diterbitkan: 2021-12-23Sebelum kita mempelajari detail arsitektur Apache Kafka, penting untuk menjelaskan mengapa Kafka menjadi berita utama. Untuk memulainya, Apache Kafka terutama digunakan dalam arsitektur data streaming real-time untuk menyediakan analitik real-time. Tahan lama, cepat, terukur, dan toleran terhadap kesalahan, sistem pesan publish-subscribe Kafka telah menggunakan kasus untuk hal-hal seperti melacak data sensor IoT atau melacak panggilan layanan.
Perusahaan seperti LinkedIn, Netflix, Microsoft, Uber, Spotify, Goldman Sachs, Cisco, PayPal, dan banyak lainnya menggunakan Apache Kafka untuk memproses data streaming waktu nyata. Misalnya, LinkedIn, tempat Kafka berasal, menggunakannya untuk melacak metrik operasional dan data aktivitas. Demikian juga, untuk Netflix, Apache Kafka adalah standar de-facto untuk kebutuhan perpesanan, acara, dan pemrosesan streaming.
Pelajari Pelatihan pengembangan perangkat lunak online dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.
Utilitas Apache Kafka lebih dihargai dengan pemahaman tentang arsitektur Apache Kafka dan komponen dasarnya. Jadi, mari kita telusuri detail arsitektur Kafka.
Daftar isi
Konsep Dasar Arsitektur Kafka
Konsep-konsep berikut adalah dasar untuk memahami arsitektur Apache Kafka:
1. Topik
Topik Kafka menentukan saluran melalui mana data dialirkan. Dengan demikian, produsen mempublikasikan pesan ke topik, dan konsumen membaca pesan dari topik yang mereka langgani. Tidak ada batasan jumlah topik yang dibuat dalam klaster Kafka, dan nama unik mengidentifikasi setiap topik.

2. Pialang
Pialang adalah server dalam klaster Kafka yang berfungsi sebagai wadah dan menampung banyak topik dengan partisi yang berbeda. ID bilangan bulat unik mengidentifikasi pialang dalam klaster Kafka, dan koneksi dengan salah satu pialang ini berarti terhubung dengan seluruh klaster.
3. Partisi
Topik Kafka dibagi menjadi banyak bagian yang dikenal sebagai partisi. Partisi dipisahkan secara berurutan dan memungkinkan banyak konsumen membaca data dari topik tertentu secara paralel. Partisi suatu topik didistribusikan ke beberapa server di kluster Kafka, dan setiap server mengelola data dan permintaan untuk banyak partisinya. Pesan mencapai broker dan sebuah kunci, dan kunci tersebut menentukan partisi yang akan dituju oleh pesan tertentu. Oleh karena itu, pesan dengan kunci yang sama masuk ke partisi yang sama. Jika kunci tidak ditentukan, partisi diputuskan mengikuti pendekatan round-robin.
4. Replika
Di Kafka, replika seperti backup partisi untuk memastikan tidak ada kehilangan data jika terjadi shutdown atau kegagalan yang direncanakan. Dengan kata lain, replika adalah salinan dari partisi.
5. Offset Partisi
Karena pesan atau catatan di Kafka ditetapkan ke partisi, setiap catatan dilengkapi dengan offset untuk menentukan posisinya di dalam partisi. Dengan demikian, nilai offset yang terkait dengan catatan membantu dalam identifikasi yang mudah di dalam partisi. Offset partisi hanya memiliki arti di dalam partisi tertentu, dan karena record ditambahkan ke bagian akhir partisi, record yang lebih lama akan memiliki nilai offset yang lebih rendah.
6. Produser
Produsen Kafka memublikasikan pesan ke satu atau beberapa topik dan mengirim data ke klaster Kafka. Segera setelah produser memublikasikan pesan ke topik Kafka, broker menerima pesan dan menambahkannya ke partisi tertentu. Kemudian, produser dapat memilih partisi tempat mereka ingin mempublikasikan pesan mereka.
7. Konsumen dan Kelompok Konsumen
Konsumen membaca pesan dari klaster Kafka. Ketika konsumen siap menerima pesan, data ditarik dari broker. Konsumen termasuk dalam kelompok konsumen, dan setiap konsumen dalam kelompok tertentu bertanggung jawab untuk membaca subset dari partisi setiap topik yang dilanggankannya.
8. Pemimpin dan Pengikut
Setiap partisi Kafka memiliki satu server yang berperan sebagai pemimpin. Leader melakukan semua tugas read-and-write untuk partisi tertentu. Di sisi lain, tugas pengikut adalah mereplikasi data pemimpin. Ketika seorang pemimpin di partisi tertentu gagal, salah satu node pengikut mengambil peran sebagai pemimpin. Sebuah partisi tidak boleh memiliki satu pun atau banyak pengikut.
Diagram berikut adalah presentasi sederhana dari keterkaitan antara komponen arsitektur Apache Kafka yang dibahas di atas.
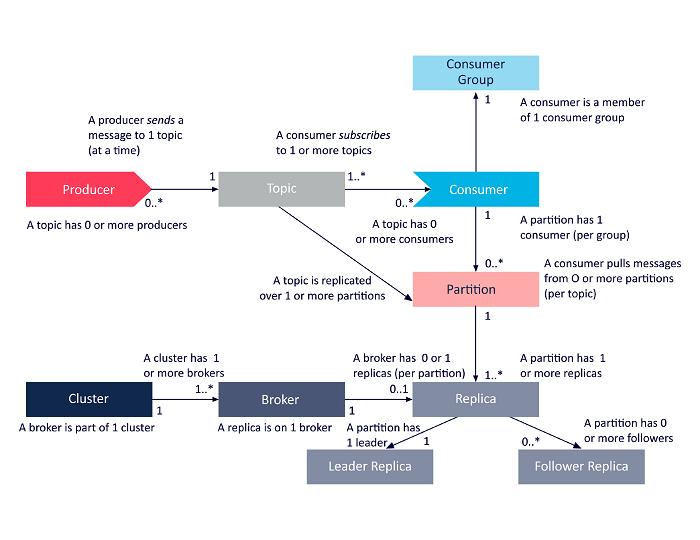
Sumber
Arsitektur Cluster Apache Kafka
Berikut adalah tampilan detail dari komponen arsitektur utama Kafka:

1. Pialang Kafka
Cluster Kafka biasanya berisi beberapa node yang dikenal sebagai broker. Pialang menjaga keseimbangan beban. Setiap broker Kafka dapat menangani ratusan dan ribuan pembacaan dan penulisan setiap detik. Broker berfungsi sebagai pemimpin untuk satu partisi tertentu. Pemimpin memiliki satu atau beberapa pengikut, dengan data tentang pemimpin direplikasi di seluruh pengikut dari partisi tertentu.
Pengikut harus tetap diperbarui dengan data pemimpin. Pemimpin, pada gilirannya, melacak pengikut yang selaras dengannya. Jika seorang pengikut tidak mengejar pemimpin atau tidak lagi hidup, itu akan dihapus dari daftar replika sinkron yang terkait dengan pemimpin tertentu. Seorang pemimpin baru dipilih dari antara pengikut setelah kematian pemimpin, dan ZooKeeper mengawasi pemilihan. Karena broker tidak memiliki kewarganegaraan, ZooKeeper mempertahankan status clusternya. Node dalam sebuah cluster mengirim pesan detak jantung ke ZooKeeper untuk memberi tahu yang terakhir bahwa mereka masih hidup.
2. Produser Kafka
Produsen Kafka langsung mengirimkan data ke broker yang berperan sebagai leader untuk partisi tertentu. Broker atau node dari cluster Kafka membantu produsen mengirim pesan langsung. Mereka melakukannya dengan menjawab permintaan metadata di server mana yang aktif dan status langsung dari pemimpin partisi suatu topik, memungkinkan produser untuk mengarahkan permintaannya sesuai dengan itu. Produser memutuskan partisi mana yang ingin mempublikasikan pesan. Pesan di Kafka dikirim dalam batch, yang disebut batch record. Produsen mengumpulkan pesan dalam memori dan mengirimkannya dalam batch baik setelah periode tertentu telah berlalu atau setelah sejumlah pesan terakumulasi.
3. Konsumen Kafka
Konsumen Kafka mengeluarkan permintaan ke broker yang menunjukkan partisi yang ingin dikonsumsi. Konsumen menentukan offset partisi dalam permintaannya dan menerima sepotong log (mulai dari posisi offset) dari broker. Log berisi catatan untuk periode yang dapat dikonfigurasi yang dikenal sebagai periode retensi.
Konsumen juga dapat menggunakan kembali data selama log berisi data tersebut. Konsumen Kafka bekerja pada pendekatan berbasis tarikan yang berarti bahwa broker tidak langsung mendorong data ke konsumen. Sebagai gantinya, pertama, konsumen mengirim permintaan ke broker yang menandakan bahwa mereka siap menggunakan data. Oleh karena itu, sistem berbasis tarik memastikan bahwa konsumen tidak kewalahan dengan pesan dan dapat mengejar ketinggalan jika mereka tertinggal.
Berikut adalah diagram arsitektur Apache Kafka yang disederhanakan:
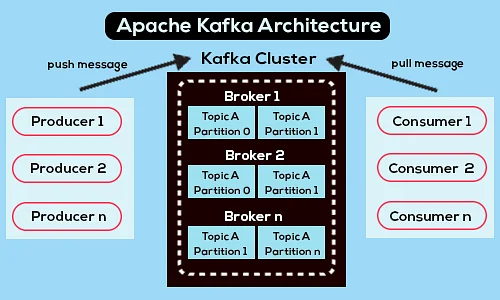
Sumber
Pelajari lebih lanjut tentang Apache Kafka.
Arsitektur Apache Kafka API
Apache Kafka memiliki empat API utama – Streams API, Connector API, Producer API, dan Consumer API. Mari kita lihat peran apa yang harus dimainkan masing-masing dalam meningkatkan kemampuan Apache Kafka:
1. Aliran API
Streams API dari Kafka memungkinkan aplikasi memproses data menggunakan algoritme pemrosesan stream. Dengan menggunakan Streams API, aplikasi dapat menggunakan aliran input dari satu atau beberapa topik, memprosesnya dengan operasi aliran, menghasilkan aliran output, dan akhirnya mengirimkannya ke satu atau beberapa topik. Dengan demikian, Streams API memfasilitasi transformasi aliran input ke aliran output.
2. API Konektor
API Konektor Kafka berguna untuk membangun, menjalankan, dan mengelola produsen dan konsumen yang dapat digunakan kembali yang menghubungkan topik Kafka ke sistem atau aplikasi data yang ada. Misalnya, konektor ke database relasional dapat menangkap semua pembaruan dan memastikan perubahan tersedia dalam topik Kafka.

3. API Produser
API Produser Kafka memungkinkan aplikasi untuk mempublikasikan aliran rekaman ke topik Kafka.
4. API Konsumen
API Konsumen Kafka Memungkinkan aplikasi untuk berlangganan topik Kafka. Ini juga memungkinkan aplikasi untuk memproses aliran rekaman yang dihasilkan untuk topik Kafka tersebut.
Jalan ke depan
Arsitektur Apache Kafka hanyalah sebagian kecil dari kumpulan alat dan bahasa yang luas yang ditangani oleh pengembang perangkat lunak. Misalkan Anda adalah pengembang perangkat lunak pemula dengan kecenderungan ke Big Data. Dalam hal ini, Anda dapat mengambil langkah pertama menuju tujuan Anda dengan Program PG Eksekutif upGrad dalam Pengembangan Perangkat Lunak – Spesialisasi dalam Big Data .
Berikut adalah ikhtisar program dengan beberapa sorotan utama:
- PGP Eksekutif dari IIIT Bangalore dengan sertifikasi Ilmu Data dan Infrastruktur Cloud
- Sesi online dan kuliah langsung dengan konten 400+ jam
- 7+ studi kasus dan proyek
- 14+ bahasa dan alat pemrograman
- Dukungan karir 360 derajat
- Jaringan rekan dan industri
Daftar untuk lebih jelasnya tentang kursus!
Kafka digunakan untuk apa?
Apache Kafka terutama digunakan untuk membangun saluran data streaming real-time dan aplikasi yang beradaptasi dengan aliran data tersebut. Ini memungkinkan penyimpanan dan analisis data real-time dan historis melalui kombinasi pengiriman pesan, penyimpanan, dan pemrosesan aliran.
Apakah Kafka sebuah kerangka kerja?
Apache Kafka adalah perangkat lunak sumber terbuka yang menyediakan kerangka kerja untuk menyimpan, membaca, dan menganalisis data streaming. Karena bersifat open-source, Kafka bebas digunakan dengan banyak pengembang dan pengguna yang berkontribusi terhadap fitur baru, pembaruan, dan dukungan untuk pengguna baru.
Mengapa kita membutuhkan aliran Kafka?
Kafka Streams adalah pustaka klien untuk membangun layanan mikro dan aplikasi streaming tempat data input dan data output disimpan di cluster Apache Kafka. Di satu sisi, ia menawarkan manfaat dari teknologi cluster sisi server Apache Kafka. Di sisi lain, ini menyederhanakan penulisan dan penerapan aplikasi Scala dan Java standar di sisi klien.