
Apache Kafka: Arsitektur, Konsep, Fitur & Aplikasi
Diterbitkan: 2021-03-09Kafka diluncurkan pada tahun 2011, semua berkat LinkedIn. Sejak itu, telah menyaksikan pertumbuhan yang luar biasa sampai-sampai sebagian besar perusahaan yang terdaftar di Fortune 500 sekarang menggunakannya. Ini adalah produk yang sangat skalabel, tahan lama, dan throughput tinggi yang dapat menangani data streaming dalam jumlah besar. Tetapi apakah itu satu-satunya alasan di balik popularitasnya yang luar biasa? Yah, tidak. Kami bahkan belum memulai fitur-fiturnya, kualitas yang dihasilkannya, dan kemudahan yang diberikannya kepada pengguna.
Kami akan menyelami itu nanti. Mari kita pahami dulu apa itu Kafka dan di mana ia digunakan.
Daftar isi
Apa itu Apache Kafka?
Apache Kafka adalah perangkat lunak pemrosesan aliran sumber terbuka yang bertujuan untuk memberikan throughput tinggi dan latensi rendah sambil mengelola data waktu nyata. Ditulis dalam Java dan Scala, Kafka memberikan daya tahan melalui layanan mikro dalam memori dan memiliki peran integral untuk dimainkan dalam mempertahankan peristiwa pasokan ke Layanan Streaming Peristiwa Kompleks, atau dikenal sebagai CEP atau Sistem Otomasi.
Ini adalah sistem terdistribusi yang sangat serbaguna dan tahan kesalahan, yang memungkinkan perusahaan seperti Uber untuk mengelola pencocokan penumpang dan pengemudi. Ini juga menyediakan data real-time dan pemeliharaan proaktif untuk produk rumah pintar British Gas selain membantu LinkedIn dalam melacak beberapa layanan real-time.
Sering digunakan dalam arsitektur data streaming real-time untuk memberikan analitik real-time, Kafka adalah sistem pesan cepat, kokoh, terukur, dan publish-subscribe. Apache Kafka dapat digunakan sebagai pengganti MOM tradisional karena kompatibilitasnya yang sangat baik dan arsitektur fleksibel yang memungkinkannya melacak panggilan layanan atau data sensor IoT.
Kafka bekerja sangat baik dengan Apache Flume/Flafka, Apache Spark Streaming, Apache Storm, HBase, Apache Flink, dan Apache Spark untuk penyerapan, penelitian, analisis, dan pemrosesan data streaming secara real-time. Perantara Kafka juga memfasilitasi laporan tindak lanjut latensi rendah di Hadoop atau Spark. Kafka juga memiliki proyek anak perusahaan bernama Kafka Stream yang berfungsi sebagai alat yang efektif untuk analisis waktu nyata.

Arsitektur dan Komponen Kafka
Kafka digunakan untuk streaming data real-time ke beberapa sistem penerima. Kafka berfungsi sebagai lapisan pusat untuk memisahkan jalur pipa data waktu nyata. Itu tidak banyak digunakan dalam perhitungan langsung. Ini paling kompatibel dengan sistem pengumpanan jalur cepat, berbasis data real-time atau operasional, untuk mengalirkan sejumlah besar data untuk analisis data batch.
Kerangka kerja Storm, Flink, Spark, dan CEP adalah beberapa sistem data yang digunakan Kafka untuk menyelesaikan analitik waktu nyata, membuat cadangan, audit, dan banyak lagi. Itu juga dapat diintegrasikan dengan platform data besar atau sistem basis data seperti RDBMS, dan Cassandra, Spark, dll, untuk pemecahan ilmu data, pelaporan, dll.
Diagram di bawah ini menggambarkan Ekosistem Kafka:
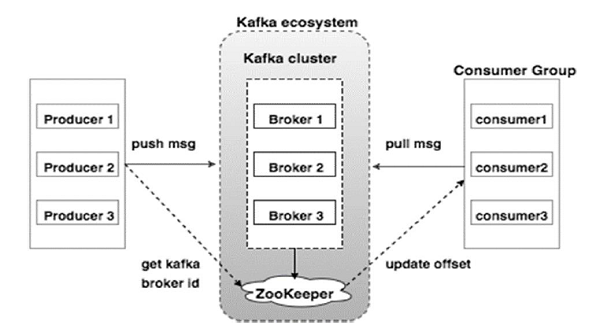
Sumber
Berikut adalah berbagai komponen ekosistem Kafka seperti yang digambarkan dalam diagram arsitektur Kafka:
1. Pialang Kafka
Kafka mengemulasi sebuah cluster yang terdiri dari beberapa server, masing-masing dikenal sebagai "broker." Setiap komunikasi antara klien dan server mematuhi protokol TCP kinerja tinggi. Ini terdiri dari lebih dari satu broker tanpa kewarganegaraan untuk menangani beban berat. Broker Kafka tunggal mampu mengelola beberapa lac membaca dan menulis setiap detik tanpa mengorbankan kinerja. Mereka menggunakan ZooKeeper untuk memelihara cluster dan memilih pemimpin broker.
2. Kafka Zookeeper
Seperti disebutkan di atas, ZooKeeper bertugas mengelola broker Kafka. Setiap penambahan baru atau kegagalan broker di ekosistem Kafka diberitahukan kepada produsen atau konsumen melalui ZooKeeper.
3. Produser Kafka
Mereka bertanggung jawab untuk mengirimkan data ke broker. Produsen tidak bergantung pada broker untuk mengakui penerimaan pesan. Sebaliknya, mereka menentukan seberapa banyak broker dapat menangani dan mengirim pesan yang sesuai.

4. Konsumen Kafka
Merupakan tanggung jawab konsumen Kafka untuk mencatat jumlah pesan yang dikonsumsi oleh offset partisi. Mengakui pesan menunjukkan bahwa pesan yang dikirim sebelum mereka telah dikonsumsi. Untuk memastikan bahwa broker memiliki buffer byte yang siap dikirim ke konsumen, konsumen memulai permintaan tarik asinkron. ZooKeeper memiliki peran untuk dimainkan dalam mempertahankan nilai offset dari melewatkan atau memutar ulang pesan.
Mekanisme Kafka melibatkan pengiriman pesan antar aplikasi dalam sistem terdistribusi. Kafka menggunakan log komit, yang ketika berlangganan menerbitkan data yang ada ke berbagai aplikasi streaming. Pengirim mengirim pesan ke Kafka, sedangkan penerima menerima pesan dari aliran yang didistribusikan oleh Kafka.
Pesan dirangkai menjadi topik — pembahasan yang efektif oleh Kafka. Topik tertentu mewakili kumpulan data yang terorganisir berdasarkan jenis atau klasifikasi tertentu. Produser menulis pesan untuk dibaca konsumen yang didasarkan pada suatu topik.
Setiap topik diberi nama yang unik. Pesan apa pun dari topik tertentu yang dikirim oleh pengirim diterima oleh semua pengguna yang mendengarkan topik itu. Setelah dipublikasikan, data dalam suatu topik tidak dapat diperbarui atau dimodifikasi.
Fitur Kafka
- Kafka terdiri dari log komit abadi yang memungkinkan Anda untuk berlangganan, dan kemudian mempublikasikan data ke beberapa sistem atau aplikasi waktu nyata.
- Ini memberi aplikasi kemampuan untuk mengontrol data yang datang. Streams API di Apache Kafka adalah library yang kuat dan ringan yang memfasilitasi pemrosesan data batch saat itu juga.
- Ini adalah aplikasi Java yang memungkinkan Anda untuk mengatur alur kerja Anda dan secara signifikan mengurangi kebutuhan pemeliharaan.
- Kafka berfungsi sebagai “penyimpanan kebenaran” yang mendistribusikan data ke beberapa node dengan mengaktifkan penyebaran data melalui beberapa sistem data.
- Log komit Kafka menjadikannya sistem penyimpanan yang andal. Kafka membuat replika/cadangan partisi yang membantu mencegah kehilangan data (konfigurasi yang tepat dapat menghasilkan nol kehilangan data). Ini juga mencegah kegagalan server dan meningkatkan daya tahan Kafka.
- Topik di Kafka memiliki ribuan partisi, membuatnya mampu menangani jumlah data yang berubah-ubah dan pemuatan yang berat.
- Kafka bergantung pada kernel OS untuk memindahkan data dengan cepat. Kumpulan informasi ini dienkripsi ujung-ke-ujung, dari produsen ke sistem file hingga konsumen akhir.
- Batching di Kafka membuat efisiensi kompresi data dan menurunkan latensi I/O.
Aplikasi Kafka
Banyak perusahaan yang menangani data dalam jumlah besar setiap hari menggunakan Kafka.

- LinkedIn menggunakan Kafka untuk melacak aktivitas pengguna dan metrik kinerja. Twitter menggabungkannya dengan Storm untuk mengaktifkan kerangka pemrosesan aliran.
- Square menggunakan Kafka untuk memfasilitasi perpindahan semua peristiwa sistem ke pusat data Square lainnya. Ini termasuk log, peristiwa khusus, dan metrik.
- Perusahaan populer lainnya yang memanfaatkan manfaat Kafka termasuk Netflix, Spotify, Uber, Tumblr, CloudFlare, dan PayPal.
Mengapa Anda Harus Mempelajari Apache Kafka?
Kafka adalah platform streaming acara luar biasa yang dapat secara efisien menangani, melacak, dan memantau data waktu nyata. Arsitekturnya yang toleran terhadap kesalahan dan skalabel memungkinkan integrasi data latensi rendah yang menghasilkan throughput tinggi dari peristiwa streaming. Kafka secara signifikan mengurangi "waktu-ke-nilai" untuk data.
Ia bekerja sebagai sistem dasar yang menghasilkan informasi untuk organisasi dengan menghilangkan "log" di sekitar data. Hal ini memungkinkan ilmuwan data dan spesialis untuk mengakses informasi dengan mudah kapan saja.
Untuk alasan ini, ini adalah platform streaming teratas pilihan bagi banyak perusahaan top dan oleh karena itu, kandidat dengan kualifikasi di Apache Kafka sangat dicari.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang Kafka, Big Data, Anda harus memeriksa PG Diploma dalam Spesialisasi Pengembangan Perangkat Lunak di Big Data yang menawarkan 7+ studi kasus & proyek dan bimbingan dari fakultas kelas dunia & pakar industri. Program 13 bulan mencakup 14 bahasa pemrograman dan mengajarkan Pemrosesan Data, Pengurangan Peta, Pergudangan Data, Pemrosesan Waktu Nyata, Pemrosesan Data Besar di Cloud, di antara keterampilan lainnya.
Lihat Kursus Rekayasa Perangkat Lunak kami yang lain di upGrad.