
UI Suara Alternatif Untuk Asisten Suara
Diterbitkan: 2022-03-10Bagi kebanyakan orang, hal pertama yang terlintas dalam pikiran ketika memikirkan antarmuka pengguna suara adalah asisten suara, seperti Siri, Amazon Alexa atau Google Assistant. Faktanya, asisten adalah satu-satunya konteks di mana kebanyakan orang pernah menggunakan suara untuk berinteraksi dengan sistem komputer.
Sementara asisten suara telah membawa antarmuka pengguna suara ke arus utama, paradigma asisten bukan satu-satunya, atau bahkan cara terbaik untuk menggunakan, merancang, dan membuat antarmuka pengguna suara.
Pada artikel ini, saya akan membahas masalah yang dialami oleh asisten suara dan menyajikan pendekatan baru untuk antarmuka pengguna suara yang saya sebut interaksi suara langsung.
Asisten Suara Adalah Chatbot Berbasis Suara
Asisten suara adalah perangkat lunak yang menggunakan bahasa alami alih-alih ikon dan menu sebagai antarmuka penggunanya. Asisten biasanya menjawab pertanyaan dan sering kali secara proaktif mencoba membantu pengguna.
Alih-alih transaksi dan perintah langsung, asisten meniru percakapan manusia dan menggunakan bahasa alami secara dua arah sebagai modalitas interaksi, yang berarti ia menerima masukan dari pengguna dan menjawab pengguna dengan menggunakan bahasa alami.
Asisten pertama adalah sistem tanya jawab berbasis dialog. Salah satu contoh awal adalah Microsoft's Clippy yang berusaha membantu pengguna Microsoft Office dengan memberi mereka instruksi berdasarkan apa yang menurut mereka coba dicapai oleh pengguna. Saat ini, kasus penggunaan khas untuk paradigma asisten adalah chatbots, sering digunakan untuk dukungan pelanggan dalam diskusi obrolan.
Asisten suara, di sisi lain, adalah chatbot yang menggunakan suara alih-alih mengetik dan teks . Masukan pengguna bukanlah pilihan atau teks tetapi ucapan dan respons dari sistem juga diucapkan dengan lantang. Asisten ini dapat berupa asisten umum seperti Google Assistant atau Alexa yang dapat menjawab banyak pertanyaan dengan cara yang wajar atau asisten khusus yang dibuat untuk tujuan khusus seperti pemesanan makanan cepat saji.
Meskipun seringkali masukan pengguna hanya satu atau dua kata dan dapat disajikan sebagai pilihan alih-alih teks yang sebenarnya, seiring perkembangan teknologi, percakapan akan menjadi lebih terbuka dan kompleks . Fitur pertama yang menentukan dari chatbot dan asisten adalah penggunaan bahasa alami dan gaya percakapan alih-alih ikon, menu, dan gaya transaksional yang mendefinisikan pengalaman pengguna aplikasi seluler atau situs web pada umumnya.
Bacaan yang disarankan : Membangun Chatbot AI Sederhana Dengan Web Speech API Dan Node.js
Karakteristik kedua yang menentukan yang berasal dari respons bahasa alami adalah ilusi persona. Nada, kualitas, dan bahasa yang digunakan sistem menentukan pengalaman asisten, ilusi empati dan kerentanan terhadap layanan, serta personanya. Ide pengalaman asisten yang baik seperti bertunangan dengan orang yang nyata .
Karena suara adalah cara paling alami bagi kita untuk berkomunikasi, ini mungkin terdengar luar biasa, tetapi ada dua masalah utama dalam menggunakan respons bahasa alami. Salah satu masalah ini, terkait dengan seberapa baik komputer dapat meniru manusia, mungkin diperbaiki di masa depan dengan perkembangan teknologi AI percakapan , tetapi masalah bagaimana otak manusia menangani informasi adalah masalah manusia, tidak dapat diperbaiki di masa mendatang. Mari kita lihat masalah-masalah ini selanjutnya.
Dua Masalah Dengan Respons Bahasa Alami
Antarmuka pengguna suara tentu saja adalah antarmuka pengguna yang menggunakan suara sebagai modalitas. Tetapi modalitas suara dapat digunakan untuk dua arah: untuk memasukkan informasi dari pengguna dan mengeluarkan informasi dari sistem kembali ke pengguna. Misalnya, beberapa elevator menggunakan sintesis ucapan untuk mengonfirmasi pilihan pengguna setelah pengguna menekan tombol. Kami kemudian akan membahas antarmuka pengguna suara yang hanya menggunakan suara untuk memasukkan informasi dan menggunakan antarmuka pengguna grafis tradisional untuk menampilkan informasi kembali kepada pengguna.
Asisten suara, di sisi lain, menggunakan suara untuk input dan output . Pendekatan ini memiliki dua masalah utama:
Masalah #1: Kegagalan Meniru Manusia
Sebagai manusia, kita memiliki kecenderungan bawaan untuk mengaitkan fitur mirip manusia dengan objek non-manusia. Kami melihat ciri-ciri seorang pria di awan melayang atau melihat sandwich dan sepertinya itu menyeringai pada kami. Ini disebut antropomorfisme .

Fenomena ini juga berlaku untuk asisten, dan ini dipicu oleh respons bahasa alami mereka. Meskipun antarmuka pengguna grafis dapat dibuat agak netral, tidak mungkin manusia tidak dapat mulai memikirkan apakah suara seseorang adalah milik orang muda atau orang tua atau apakah mereka laki-laki atau perempuan. Karena itu, pengguna hampir mulai berpikir bahwa asisten itu memang manusia.
Namun, kita manusia sangat pandai mendeteksi palsu . Anehnya, semakin dekat sesuatu yang menyerupai manusia, semakin banyak penyimpangan kecil yang mulai mengganggu kita. Ada perasaan ngeri terhadap sesuatu yang mencoba menjadi seperti manusia tetapi tidak cukup sesuai dengan itu. Dalam robotika dan animasi komputer ini disebut sebagai "lembah luar biasa".

Semakin baik dan lebih mirip manusia yang kami coba untuk membuat asisten, pengalaman pengguna akan semakin menyeramkan dan mengecewakan ketika terjadi kesalahan. Setiap orang yang pernah mencoba asisten mungkin pernah menemukan masalah dalam merespons dengan sesuatu yang terasa konyol atau bahkan kasar.
Lembah luar biasa asisten suara menimbulkan masalah kualitas dalam pengalaman pengguna asisten yang sulit diatasi. Faktanya, tes Turing (dinamai sesuai dengan matematikawan terkenal Alan Turing) lulus ketika seorang evaluator manusia yang menunjukkan percakapan antara dua agen tidak dapat membedakan mana di antara mereka yang merupakan mesin dan mana yang manusia. Selama ini belum pernah dilewati.
Ini berarti bahwa paradigma asisten memberikan janji pengalaman layanan seperti manusia yang tidak akan pernah bisa dipenuhi dan pengguna pasti akan kecewa. Pengalaman sukses hanya membangun kekecewaan akhirnya, karena pengguna mulai mempercayai asisten mereka yang seperti manusia.
Soal 2: Interaksi Berurutan dan Lambat
Masalah kedua dari asisten suara adalah bahwa sifat respon bahasa alami yang berbasis giliran menyebabkan penundaan interaksi. Ini karena cara otak kita memproses informasi.
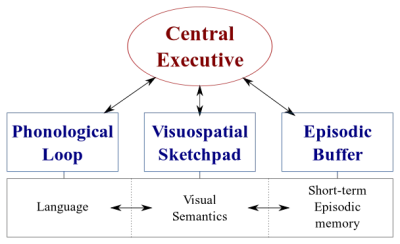
Ada dua jenis sistem pemrosesan data di otak kita:
- Sistem linguistik yang memproses ucapan;
- Sistem visuospasial yang mengkhususkan diri dalam memproses informasi visual dan spasial.
Kedua sistem ini dapat beroperasi secara paralel, tetapi kedua sistem hanya memproses satu hal pada satu waktu . Inilah sebabnya mengapa Anda dapat berbicara dan mengendarai mobil pada saat yang sama, tetapi Anda tidak dapat mengirim SMS dan mengemudi karena kedua aktivitas tersebut akan terjadi dalam sistem visuospasial.

Demikian pula, ketika Anda berbicara dengan asisten suara, asisten harus tetap diam dan sebaliknya. Ini menciptakan percakapan berbasis giliran , di mana bagian lain selalu sepenuhnya pasif.
Namun, pertimbangkan topik sulit yang ingin Anda diskusikan dengan teman Anda. Anda mungkin akan mendiskusikan tatap muka daripada melalui telepon, bukan? Itu karena dalam percakapan tatap muka kami menggunakan komunikasi non-verbal untuk memberikan umpan balik visual waktu nyata kepada mitra percakapan kami. Ini menciptakan lingkaran pertukaran informasi dua arah dan memungkinkan kedua belah pihak untuk secara aktif terlibat dalam percakapan secara bersamaan.
Asisten tidak memberikan umpan balik visual waktu nyata. Mereka mengandalkan teknologi yang disebut end-pointing untuk memutuskan kapan pengguna berhenti berbicara dan hanya membalas setelah itu. Dan ketika mereka membalas, mereka tidak menerima masukan apa pun dari pengguna pada saat yang bersamaan. Pengalaman ini sepenuhnya searah dan berbasis giliran.
Dalam percakapan tatap muka dua arah dan waktu nyata, kedua belah pihak dapat segera bereaksi terhadap sinyal visual dan linguistik. Ini memanfaatkan sistem pemrosesan informasi yang berbeda dari otak manusia dan percakapan menjadi lebih lancar dan efisien.
Asisten suara terjebak dalam mode searah karena mereka menggunakan bahasa alami baik sebagai saluran input dan output. Meskipun suara hingga empat kali lebih cepat daripada mengetik untuk input, ini jauh lebih lambat untuk dicerna daripada membaca. Karena informasi perlu diproses secara berurutan , pendekatan ini hanya berfungsi dengan baik untuk perintah sederhana seperti "matikan lampu" yang tidak memerlukan banyak output dari asisten.

Sebelumnya, saya berjanji untuk membahas antarmuka pengguna suara yang menggunakan suara hanya untuk memasukkan data dari pengguna. Antarmuka pengguna suara semacam ini mendapat manfaat dari bagian terbaik dari antarmuka pengguna suara — kealamian, kecepatan, dan kemudahan penggunaan — tetapi tidak menderita bagian yang buruk — lembah luar biasa dan interaksi berurutan
Mari kita pertimbangkan alternatif ini.
Alternatif yang Lebih Baik Untuk Asisten Suara
Solusi untuk mengatasi masalah ini di asisten suara adalah melepaskan respons bahasa alami, dan menggantinya dengan umpan balik visual waktu nyata. Mengalihkan umpan balik ke visual akan memungkinkan pengguna memberi dan menerima umpan balik secara bersamaan. Ini akan memungkinkan aplikasi untuk bereaksi tanpa mengganggu pengguna dan memungkinkan aliran informasi dua arah. Karena arus informasi bersifat dua arah, throughputnya lebih besar.
Saat ini, kasus penggunaan teratas untuk asisten suara adalah mengatur alarm, memutar musik, memeriksa cuaca, dan mengajukan pertanyaan sederhana. Semua ini adalah tugas berisiko rendah yang tidak membuat pengguna terlalu frustrasi saat gagal.
Seperti yang pernah ditulis David Pierce dari Wall Street Journal :
“Saya tidak bisa membayangkan memesan penerbangan atau mengatur anggaran saya melalui asisten suara, atau melacak diet saya dengan meneriakkan bahan-bahan di speaker saya.”
— David Pierce dari Wall Street Journal
Ini adalah tugas berat informasi yang harus dilakukan dengan benar.
Namun, pada akhirnya, antarmuka pengguna suara akan gagal. Kuncinya adalah untuk menutupi ini secepat mungkin. Banyak kesalahan terjadi saat mengetik di keyboard atau bahkan dalam percakapan tatap muka. Namun, ini sama sekali tidak membuat frustrasi karena pengguna dapat memulihkan hanya dengan mengklik backspace dan mencoba lagi atau meminta klarifikasi.
Pemulihan cepat dari kesalahan ini memungkinkan pengguna menjadi lebih efisien dan tidak memaksa mereka melakukan percakapan aneh dengan asisten.
Interaksi Suara Langsung
Di sebagian besar aplikasi, tindakan dilakukan dengan memanipulasi elemen grafis di layar, dengan menusuk atau menggesek (pada layar sentuh), mengklik mouse, dan/atau menekan tombol pada keyboard. Input suara dapat ditambahkan sebagai opsi atau modalitas tambahan untuk memanipulasi elemen grafis ini. Jenis interaksi ini bisa disebut interaksi suara langsung .
Perbedaan antara interaksi suara langsung dan asisten adalah bahwa alih-alih meminta avatar, asisten, untuk melakukan tugas, pengguna secara langsung memanipulasi antarmuka pengguna grafis dengan suara.
"Bukankah ini semantik?", Anda mungkin bertanya. Jika Anda akan berbicara dengan komputer, apakah penting jika Anda berbicara langsung ke komputer atau melalui persona virtual? Dalam kedua kasus, Anda hanya berbicara dengan komputer!
Ya, perbedaannya halus, tetapi kritis. Saat mengklik tombol atau item menu di GUI ( G raphical U ser I nterface ) sangat jelas bahwa kita sedang mengoperasikan mesin. Tidak ada ilusi seseorang. Dengan mengganti klik itu dengan perintah suara, kami meningkatkan interaksi manusia-komputer. Dengan paradigma asisten, di sisi lain, kami menciptakan versi interaksi manusia-ke-manusia yang memburuk dan karenanya, melakukan perjalanan ke lembah yang luar biasa.
Memadukan fungsionalitas suara ke dalam antarmuka pengguna grafis juga menawarkan potensi untuk memanfaatkan kekuatan modalitas yang berbeda. Sementara pengguna dapat menggunakan suara untuk mengoperasikan aplikasi, mereka juga memiliki kemampuan untuk menggunakan antarmuka grafis tradisional. Ini memungkinkan pengguna untuk beralih antara sentuhan dan suara dengan mulus dan memilih opsi terbaik berdasarkan konteks dan tugas mereka.
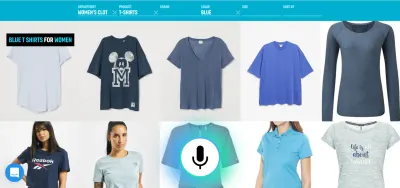
Misalnya, suara adalah metode yang sangat efisien untuk memasukkan informasi yang kaya. Memilih di antara beberapa alternatif yang valid, sentuh atau klik mungkin lebih baik. Pengguna kemudian dapat mengganti pengetikan dan penelusuran dengan mengatakan sesuatu seperti, "Tampilkan penerbangan dari London ke New York yang berangkat besok," dan pilih opsi terbaik dari daftar dengan menggunakan sentuhan.
Sekarang Anda mungkin bertanya, “Oke, ini terlihat bagus, jadi mengapa kita belum pernah melihat contoh antarmuka pengguna suara seperti itu sebelumnya? Mengapa perusahaan teknologi besar tidak membuat alat untuk hal seperti ini?” Yah, mungkin ada banyak alasan untuk itu. Salah satu alasannya adalah bahwa paradigma asisten suara saat ini mungkin merupakan cara terbaik bagi mereka untuk memanfaatkan data yang mereka dapatkan dari pengguna akhir. Alasan lain berkaitan dengan cara teknologi suara mereka dibangun.
Antarmuka pengguna suara yang berfungsi dengan baik membutuhkan dua bagian berbeda:
- Pengenalan ucapan yang mengubah ucapan menjadi teks;
- Komponen pemahaman bahasa alami yang mengekstrak makna dari teks itu.
Bagian kedua adalah sulap yang mengubah ucapan “Matikan lampu ruang tamu” dan “Tolong matikan lampu di ruang tamu” menjadi tindakan yang sama.
Bacaan yang disarankan : Cara Membuat Tindakan Anda Sendiri Untuk Google Home Menggunakan API.AI
Jika Anda pernah menggunakan asisten dengan tampilan (seperti Siri atau Google Assistant), Anda mungkin memperhatikan bahwa Anda mendapatkan transkrip hampir secara realtime, tetapi setelah Anda berhenti berbicara, dibutuhkan beberapa detik sebelum sistem benar-benar melakukan tindakan yang Anda minta. Ini karena pengenalan ucapan dan pemahaman bahasa alami terjadi secara berurutan.
Mari kita lihat bagaimana ini bisa diubah.
Pemahaman Bahasa Lisan Waktu Nyata: Saus Rahasia Untuk Perintah Suara yang Lebih Efisien
Seberapa cepat aplikasi bereaksi terhadap input pengguna merupakan faktor utama dalam keseluruhan pengalaman pengguna aplikasi. Inovasi terpenting dari iPhone asli adalah layar sentuh yang sangat responsif dan reaktif. Kemampuan antarmuka pengguna suara untuk bereaksi terhadap input suara secara instan sama pentingnya.
Untuk membuat lingkaran pertukaran informasi dua arah yang cepat antara pengguna dan UI, GUI yang diaktifkan dengan suara harus dapat langsung bereaksi — bahkan di tengah kalimat — setiap kali pengguna mengatakan sesuatu yang dapat ditindaklanjuti. Ini membutuhkan teknik yang disebut streaming pemahaman bahasa lisan .
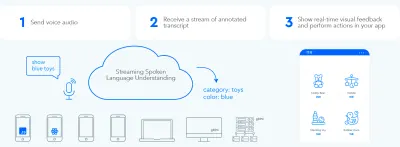
Berlawanan dengan sistem asisten suara berbasis giliran tradisional yang menunggu pengguna berhenti berbicara sebelum memproses permintaan pengguna, sistem yang menggunakan pemahaman bahasa lisan streaming secara aktif mencoba memahami maksud pengguna sejak pengguna mulai berbicara. Segera setelah pengguna mengatakan sesuatu yang dapat ditindaklanjuti, UI langsung bereaksi.
Tanggapan instan segera memvalidasi bahwa sistem memahami pengguna dan mendorong pengguna untuk melanjutkan. Ini analog dengan anggukan atau singkat "a-ha" dalam komunikasi manusia-ke-manusia. Ini menghasilkan ucapan yang lebih panjang dan lebih kompleks yang didukung. Masing-masing, jika sistem tidak memahami pengguna atau pengguna salah bicara, umpan balik instan memungkinkan pemulihan cepat . Pengguna dapat segera mengoreksi dan melanjutkan, atau bahkan mengoreksi dirinya sendiri secara lisan: "Saya ingin ini, tidak, maksud saya, saya ingin itu." Anda dapat mencoba aplikasi semacam ini sendiri di demo pencarian suara kami.
Seperti yang Anda lihat di demo, umpan balik visual waktu nyata memungkinkan pengguna untuk mengoreksi diri mereka sendiri secara alami dan mendorong mereka untuk melanjutkan pengalaman suara. Karena mereka tidak bingung dengan persona virtual, mereka dapat menghubungkan kemungkinan kesalahan dengan cara yang mirip dengan kesalahan ketik — bukan sebagai penghinaan pribadi. Pengalaman lebih cepat dan lebih alami karena informasi yang diumpankan ke pengguna tidak dibatasi oleh kecepatan bicara khas sekitar 150 kata per menit.
Bacaan yang direkomendasikan : Merancang Pengalaman Suara oleh Lyndon Cerejo
Kesimpulan
Sementara asisten suara sejauh ini merupakan penggunaan yang paling umum untuk antarmuka pengguna suara, penggunaan respons bahasa alami membuatnya tidak efisien dan tidak alami. Suara adalah modalitas yang bagus untuk memasukkan informasi, tetapi mendengarkan mesin berbicara tidak terlalu menginspirasi. Ini adalah masalah besar asisten suara.
Oleh karena itu, masa depan suara seharusnya tidak dalam percakapan dengan komputer tetapi dalam menggantikan tugas-tugas pengguna yang membosankan dengan cara berkomunikasi yang paling alami: ucapan . Interaksi suara langsung dapat digunakan untuk meningkatkan pengalaman pengisian formulir di aplikasi web atau seluler, untuk menciptakan pengalaman pencarian yang lebih baik, dan untuk memungkinkan cara yang lebih efisien untuk mengontrol atau menavigasi dalam aplikasi.
Desainer dan pengembang aplikasi terus mencari cara untuk mengurangi gesekan di aplikasi atau situs web mereka. Meningkatkan antarmuka pengguna grafis saat ini dengan modalitas suara akan memungkinkan interaksi pengguna beberapa kali lebih cepat terutama dalam situasi tertentu seperti ketika pengguna akhir menggunakan ponsel dan dalam perjalanan dan mengetik sulit. Faktanya, pencarian suara bisa sampai lima kali lebih cepat daripada antarmuka pengguna penyaringan pencarian tradisional, bahkan saat menggunakan komputer desktop.
Lain kali, ketika Anda berpikir tentang bagaimana Anda dapat membuat tugas pengguna tertentu dalam aplikasi Anda lebih mudah digunakan, lebih menyenangkan untuk digunakan, atau Anda tertarik untuk meningkatkan konversi, pertimbangkan apakah tugas pengguna tersebut dapat dijelaskan secara akurat dalam bahasa alami. Jika ya, lengkapi antarmuka pengguna Anda dengan modalitas suara tetapi jangan paksa pengguna Anda untuk berbicara dengan komputer.
Sumber daya
- “Suara Pertama Versus Antarmuka Pengguna Multimodal Masa Depan,” Joan Palmiter Bajorek, UXmatters
- “Pedoman Untuk Membuat Aplikasi Berkemampuan Suara yang Produktif,” Hannes Heikinheimo, Speechly
- “6 Alasan Aplikasi Layar Sentuh Anda Harus Memiliki Kemampuan Suara,” Ottomatias Peura, UXmatters
- Mencampur Tangible Dan Intangible: Merancang Antarmuka Multimodal Menggunakan Adobe XD, Nick Babich, Smashing Magazine
( Adobe XD dapat untuk membuat prototipe sesuatu yang serupa ) - “Efisiensi Pada Kecepatan Suara: Janji Operasi Dengan Suara,” Eric Turkington, RAIN
- Demo yang menampilkan umpan balik visual waktu nyata dalam penyaringan pencarian suara eCommerce (versi video)
- Speechly menyediakan alat pengembang untuk antarmuka pengguna semacam ini
- Alternatif sumber terbuka: voice2json