
Panduan Regresi Linier Menggunakan Scikit [Dengan Contoh]
Diterbitkan: 2021-06-18Algoritme pembelajaran terawasi umumnya terdiri dari dua jenis: Regresi dan klasifikasi dengan prediksi keluaran kontinu dan diskrit.
Artikel berikut akan membahas regresi linier dan implementasinya menggunakan salah satu library machine learning python yang paling populer, library Scikit-learn. Alat untuk pembelajaran mesin dan model statistik tersedia di pustaka python untuk klasifikasi, regresi, pengelompokan, dan pengurangan dimensi. Ditulis dalam bahasa pemrograman python, perpustakaan dibangun di atas perpustakaan python NumPy, SciPy, dan Matplotlib.
Daftar isi
Regresi linier
Regresi linier melakukan tugas regresi di bawah metode pembelajaran terawasi. Berdasarkan variabel independen, nilai target diprediksi. Metode ini banyak digunakan untuk meramalkan dan mengidentifikasi hubungan antar variabel.
Dalam aljabar, istilah linearitas berarti hubungan linier antar variabel. Sebuah garis lurus ditarik antara variabel dalam ruang dua dimensi.
Jika sebuah garis adalah plot antara variabel bebas pada sumbu X dan variabel terikat pada sumbu Y, garis lurus dicapai melalui regresi linier yang paling sesuai dengan titik data.
Persamaan garis lurus berbentuk

Y = mx + b
Dimana, b = intersep
m = kemiringan garis
Oleh karena itu, melalui regresi linier,
- Nilai yang paling optimal untuk intersep dan kemiringan ditentukan dalam dua dimensi.
- Tidak ada perubahan dalam variabel x dan y karena mereka adalah fitur data dan karenanya tetap sama.
- Hanya nilai intersep dan kemiringan yang dapat dikontrol.
- Beberapa garis lurus berdasarkan nilai kemiringan dan intersep mungkin ada, namun melalui algoritma regresi linier beberapa garis dipasang pada titik data dan garis dengan kesalahan terkecil dikembalikan.
Regresi Linier dengan Python
Untuk mengimplementasikan regresi linier di python, paket yang tepat harus diterapkan bersama dengan fungsi dan kelasnya. Paket NumPy dalam Python adalah open source dan memungkinkan beberapa operasi pada array, baik array tunggal maupun multidimensi.
Pustaka lain yang banyak digunakan dalam python adalah Scikit-learn yang digunakan untuk masalah pembelajaran mesin.
Scikit-belajarN
Pustaka Scikit-learn menawarkan algoritme pengembang berdasarkan pembelajaran yang diawasi dan tidak diawasi. Pustaka python sumber terbuka dirancang untuk tugas pembelajaran mesin.
Ilmuwan data dapat mengimpor data, memprosesnya terlebih dahulu, memplotnya, dan memprediksi data melalui penggunaan scikit-learn.
David Cournapeau pertama kali mengembangkan scikit-learn pada tahun 2007, dan perpustakaan telah mengalami pertumbuhan sejak beberapa dekade.
Tools yang disediakan oleh scikit-learn adalah:
- Regresi: Termasuk Regresi Logistik dan Regresi Linier
- Klasifikasi: Termasuk metode K-Nearest Neighbors
- Pemilihan model
- Pengelompokan: Termasuk K-Means++ dan K-Means
- Pra-pemrosesan
Kelebihan perpustakaan adalah :
- Pembelajaran dan implementasi perpustakaan mudah dilakukan.
- Ini adalah perpustakaan sumber terbuka dan karenanya gratis.
- Aspek pembelajaran mesin dapat ditutupi termasuk pembelajaran yang mendalam.
- Ini adalah paket yang kuat dan serbaguna.
- Perpustakaan memiliki dokumentasi rinci.
- Salah satu toolkit yang paling banyak digunakan untuk pembelajaran mesin.
Mengimpor scikit-belajar
scikit-learn harus diinstal terlebih dahulu melalui pip atau melalui conda.
- Persyaratan: Python 3 versi 64-bit dengan pustaka terinstal NumPy dan Scipy. Juga untuk visualisasi plot data, matplotlib diperlukan.
Perintah instalasi: pip install -U scikit-learn
Kemudian verifikasi apakah instalasi selesai
Instalasi Numpy, Scipy, dan matplotlib
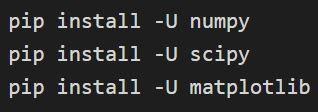
Pemasangan dapat dikonfirmasi melalui:
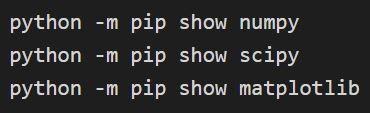
Sumber
Regresi linier melalui Scikit-belajar
Implementasi regresi linier melalui paket scikit-learn meliputi langkah-langkah sebagai berikut.
- Paket dan kelas yang dibutuhkan harus diimpor.
- Data diperlukan untuk bekerja dengan dan juga untuk melakukan transformasi yang sesuai.
- Sebuah model regresi harus dibuat dan dilengkapi dengan data yang ada.
- Data pemasangan model harus diperiksa untuk menganalisis apakah model yang dibuat memuaskan.
- Prediksi harus dibuat melalui penerapan model.
Paket NumPy dan kelas LinearRegression harus diimpor dari sklearn.linear_model.

Sumber
Fungsionalitas yang diperlukan untuk regresi linier sklearn semuanya hadir untuk akhirnya menerapkan regresi linier. Kelas sklearn.linear_model.LinearRegression digunakan untuk melakukan analisis regresi ( linier dan polinomial ) dan melakukan prediksi.
Untuk setiap algoritma pembelajaran mesin dan scikit belajar regresi linier , kumpulan data harus diimpor terlebih dahulu. Tiga opsi tersedia di Scikit-learn untuk mendapatkan data:
- Kumpulan data seperti klasifikasi iris atau himpunan regresi untuk harga perumahan Boston.
- Kumpulan data dunia nyata dapat diunduh dari internet secara langsung melalui fungsi yang telah ditentukan Scikit-learn.
- Kumpulan data dapat dihasilkan secara acak untuk dicocokkan dengan pola tertentu melalui generator data Scikit-learn.
Opsi apa pun yang dipilih, kumpulan data modul harus diimpor.

impor sklearn.datasets sebagai dataset
1. Kumpulan klasifikasi iris
iris = datasets.load_iris()
Dataset iris disimpan sebagai bidang data larik 2D dari n_samples * n_features. Impornya dilakukan sebagai objek kamus. Ini berisi semua data yang diperlukan bersama dengan metadata.
Fungsi DESCR, shape dan _names dapat digunakan untuk mendapatkan deskripsi dan format data. Pencetakan hasil fungsi akan menampilkan informasi dataset yang mungkin diperlukan saat mengerjakan dataset iris.
Kode berikut akan memuat informasi dari dataset iris.
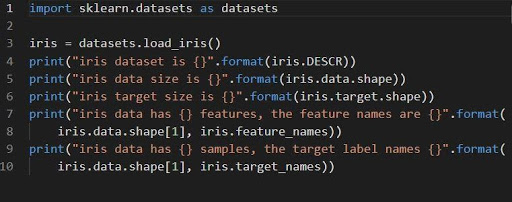
Sumber
2. Pembuatan data regresi
Jika tidak ada kebutuhan untuk built-in data, maka data dapat dihasilkan melalui distribusi yang dapat dipilih.
Menghasilkan data regresi dengan seperangkat 1 fitur informatif dan 1 fitur.
X , Y = kumpulan data.make_regression(n_features=1, n_informative=1)
Data yang dihasilkan disimpan dalam dataset 2D dengan objek x, dan y. Karakteristik data yang dihasilkan dapat diubah melalui perubahan parameter fungsi make_regression.
Dalam contoh ini, parameter fitur dan fitur informatif diubah dari nilai default 10 menjadi 1.
Parameter lain yang dipertimbangkan adalah sampel dan target di mana jumlah variabel target dan sampel yang dilacak dikendalikan.
- Fitur yang memberikan informasi yang berguna untuk algoritma ML disebut sebagai fitur informatif sedangkan yang tidak membantu disebut sebagai fitur on-informatif.
3. Merencanakan data
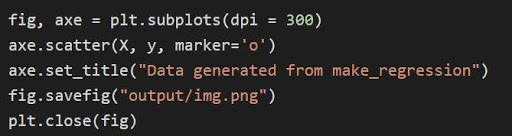
Data diplot menggunakan pustaka matplotlib. Pertama, matplotlib harus diimpor.
Impor matplotlib.pyplot sebagai plt
Grafik di atas diplot melalui matplotlib melalui kode
Sumber
Dalam kode di atas:
- Variabel tupel dibongkar dan disimpan sebagai variabel terpisah di baris 1 kode. Oleh karena itu, atribut yang terpisah dapat dimanipulasi dan disimpan.
- Dataset x,y digunakan untuk menghasilkan scatter plot melalui baris 2. Dengan tersedianya parameter marker di matplotlib, visual ditingkatkan dengan menandai titik data dengan titik (o).
- Judul plot yang dihasilkan diatur melalui baris 3.
- Gambar dapat disimpan sebagai file gambar .png dan kemudian gambar saat ini ditutup.
Plot regresi yang dihasilkan melalui kode di atas adalah
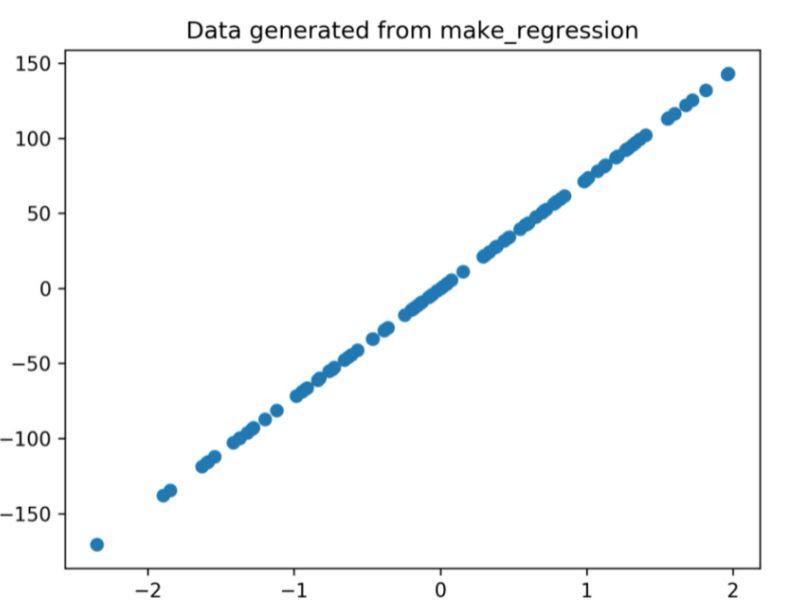
Gambar 1: Plot regresi yang dihasilkan dari kode di atas.
4. Menerapkan algoritma regresi linier
Menggunakan data sampel harga perumahan Boston, algoritma regresi linier Scikit-learn diimplementasikan dalam contoh berikut. Seperti algoritme ML lainnya, kumpulan data diimpor dan kemudian dilatih menggunakan data sebelumnya.
Metode regresi linier digunakan oleh bisnis, karena merupakan model prediktif yang memprediksi hubungan antara kuantitas numerik dan variabelnya dengan nilai keluaran dengan arti memiliki nilai dalam kenyataan.
Ketika log data sebelumnya hadir, model dapat diterapkan dengan baik karena dapat memprediksi hasil masa depan dari apa yang akan terjadi di masa depan jika ada kelanjutan dari pola tersebut.
Secara matematis, data dapat dipasang untuk meminimalkan jumlah semua residual yang ada antara titik data dan nilai yang diprediksi.
Cuplikan berikut menunjukkan implementasi regresi linier sklearn.
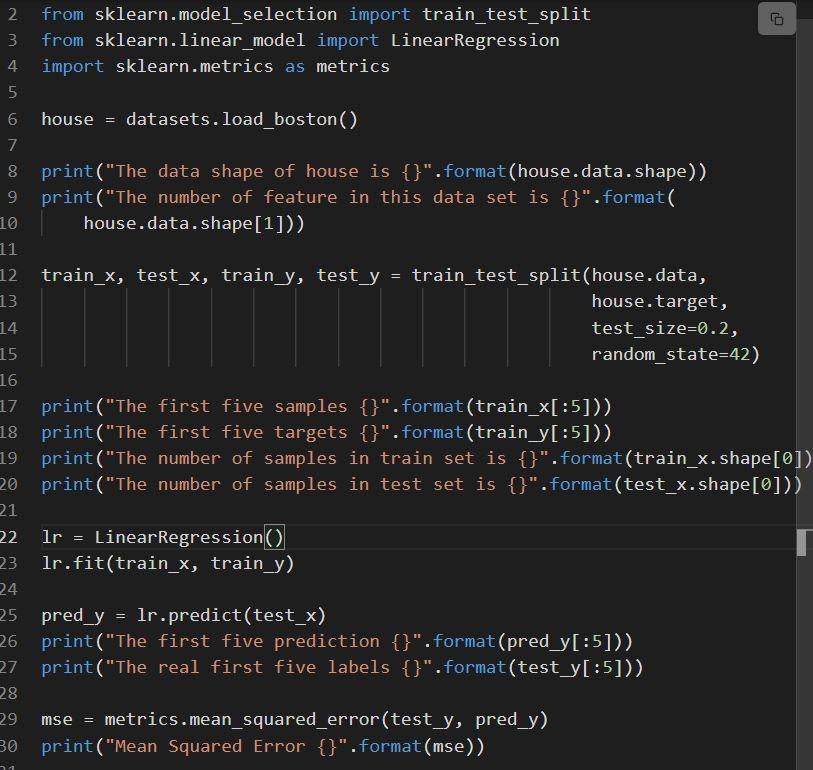
Sumber
Kode dijelaskan sebagai:
- Baris 6 memuat dataset yang disebut load_boston.
- Dataset dipecah pada baris 12, yaitu training set dengan 80% data dan test dengan 20% data.
- Pembuatan model regresi linier pada jalur 23 kemudian dilatih pada.
- Performa model dievaluasi pada linen 29 melalui pemanggilan mean_squared_error.
Plot regresi linier sklearn ditunjukkan di bawah ini:
Model regresi linier dari data sampel harga perumahan Boston
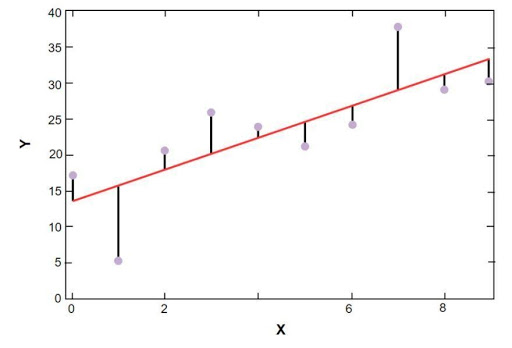
Sumber
Pada gambar di atas, garis merah mewakili model linier yang telah diselesaikan untuk data sampel harga perumahan Boston. Titik biru mewakili data asli dan jarak antara garis merah dan titik biru mewakili jumlah sisa. Tujuan dari model regresi linier scikit-learn adalah untuk mengurangi jumlah residu.
Kesimpulan
Artikel tersebut membahas regresi linier dan implementasinya melalui penggunaan paket python open-source yang disebut scikit-learn. Sekarang, Anda sudah bisa mendapatkan konsep bagaimana menerapkan regresi linier melalui paket ini. Sebaiknya pelajari cara menggunakan perpustakaan untuk analisis data Anda.
Jika Anda tertarik untuk mengeksplorasi topik lebih lanjut, seperti implementasi paket python dalam pembelajaran mesin dan masalah terkait AI, Anda dapat memeriksa kursus Master of Science dalam Pembelajaran Mesin & AI yang ditawarkan oleh upGrad . Menargetkan profesional entry-level berusia 21 hingga 45 tahun, kursus ini bertujuan untuk melatih siswa dalam pembelajaran mesin melalui pelatihan online 650+ jam, 25+ studi kasus, dan tugas. Bersertifikat dari LJMU , kursus ini menawarkan bimbingan yang sempurna dan bantuan penempatan kerja. Jika Anda memiliki pertanyaan atau pertanyaan, tinggalkan pesan kepada kami, kami akan dengan senang hati menghubungi Anda.