
Qu'est-ce que l'apprentissage automatique avec Java ? Comment l'implémenter ?
Publié: 2021-03-10Table des matières
Qu'est-ce que l'apprentissage automatique ?
L'apprentissage automatique est une division de l'intelligence artificielle qui apprend à partir des données, des exemples et des expériences disponibles pour imiter le comportement et l'intelligence humains. Un programme créé à l'aide de l'apprentissage automatique peut construire sa propre logique sans qu'un humain ait à écrire manuellement le code.
Tout a commencé avec le test de Turing au début des années 1950, quand Alan Turning a conclu que pour qu'un ordinateur ait une véritable intelligence, il devrait manipuler ou convaincre un humain qu'il était aussi humain. L'apprentissage automatique est un concept relativement ancien, mais ce n'est qu'aujourd'hui que ce domaine émergent fait l'objet d'une concrétisation puisque les ordinateurs peuvent désormais traiter des algorithmes complexes. Les algorithmes d'apprentissage automatique ont évolué au cours de la dernière décennie pour inclure des compétences informatiques complexes qui, à leur tour, ont conduit à une amélioration de leurs capacités d'imitation.
Les applications d'apprentissage automatique ont également augmenté à un rythme alarmant. De la santé, de la finance, de l'analyse et de l'éducation à la fabrication, au marketing et aux opérations gouvernementales, chaque industrie a connu une amélioration significative de la qualité et de l'efficacité après la mise en œuvre des technologies d'apprentissage automatique. Il y a eu des améliorations qualitatives généralisées dans le monde entier, ce qui a stimulé la demande de professionnels de l'apprentissage automatique.
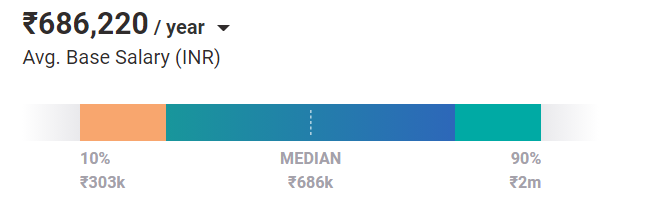
En moyenne, les ingénieurs en apprentissage automatique valent un salaire de ₹ 686 220 / an aujourd'hui. Et c'est le cas pour un poste d'entrée de gamme. Avec de l'expérience et des compétences, ils peuvent gagner jusqu'à 2 millions de ₹ par an en Inde.
Types d'algorithmes d'apprentissage automatique
Les algorithmes d'apprentissage automatique sont de trois types :
1. Apprentissage supervisé : Dans ce type d'apprentissage, les ensembles de données de formation guident un algorithme pour faire des prédictions précises ou des décisions analytiques. Il utilise l'apprentissage des ensembles de données de formation passés pour traiter de nouvelles données. Voici quelques exemples de modèles d'apprentissage automatique supervisés :

- Régression linéaire
- Régression logistique
- Arbre de décision
2. Apprentissage non supervisé : Dans ce type d'apprentissage, un modèle d'apprentissage automatique apprend à partir d'informations non étiquetées. Il utilise le regroupement de données en regroupant des objets ou en comprenant la relation entre eux, ou en exploitant leurs propriétés statistiques pour effectuer une analyse. Voici des exemples d'algorithmes d'apprentissage non supervisé :
- K-means clustering
- Classification hiérarchique
3. Apprentissage par renforcement : Ce processus est basé sur le succès et l'essai. C'est apprendre en interagissant avec l'espace ou un environnement. Un algorithme RL apprend de ses expériences passées en interagissant avec l'environnement et en déterminant le meilleur plan d'action.
Comment mettre en œuvre l'apprentissage automatique avec Java ?
Java fait partie des principaux langages de programmation utilisés pour implémenter des algorithmes d'apprentissage automatique. La plupart de ses bibliothèques sont open-source, offrant un support de documentation étendu, une maintenance facile, une commercialisation et une lisibilité facile.
Selon la popularité, voici les 10 meilleures bibliothèques d'apprentissage automatique utilisées pour implémenter l'apprentissage automatique en Java.
1. ADAMS
Le système avancé d'exploration de données et d'apprentissage automatique ou ADAMS vise à créer des systèmes de flux de travail nouveaux et flexibles et à gérer des processus complexes du monde réel. ADAMS utilise une architecture arborescente pour gérer le flux de données au lieu d'établir des connexions manuelles d'entrée-sortie.
Il élimine tout besoin de connexions explicites. Il est basé sur le principe «moins c'est plus» et effectue la récupération, la visualisation et les visualisations basées sur les données. ADAMS maîtrise le traitement des données, le streaming de données, la gestion des bases de données, les scripts et la documentation.
2. JavaML
JavaML offre une variété d'algorithmes de ML et d'exploration de données écrits pour Java pour aider les ingénieurs en logiciel, les programmeurs, les scientifiques des données et les chercheurs. Chaque algorithme a une interface commune facile à utiliser et un support de documentation étendu même s'il n'y a pas d'interface graphique.
Il est plutôt simple et direct à mettre en œuvre par rapport à d'autres algorithmes de clustering. Ses fonctionnalités principales incluent la manipulation de données, la documentation, la gestion de base de données, la classification des données, le clustering, la sélection de fonctionnalités, etc.
Rejoignez le cours d'apprentissage automatique en ligne des meilleures universités du monde - Masters, programmes de troisième cycle pour cadres et programme de certificat avancé en ML et IA pour accélérer votre carrière.
3. WEKA
Weka est également une bibliothèque d'apprentissage automatique open source écrite pour Java qui prend en charge l'apprentissage en profondeur. Il fournit un ensemble d'algorithmes d'apprentissage automatique et trouve une utilisation intensive dans l'exploration de données, la préparation de données, le regroupement de données, la visualisation de données et la régression, entre autres opérations de données.
Exemple : Nous allons le démontrer à l'aide d'un petit ensemble de données sur le diabète.
Étape 1 : Charger les données à l'aide de Weka
| importer weka.core.Instances ; importer weka.core.converters.ConverterUtils.DataSource ; classe publique principale { public static void main(String[] args) lance une exception { // Spécification de la source de données DataSource dataSource = new DataSource("data.arff"); // Chargement du jeu de données instances dataInstances = dataSource.getDataSet(); // Affichage du nombre d'instances log.info("Le nombre d'instances chargées est : " + dataInstances.numInstances()); log.info("data:" + dataInstances.toString()); } } |
Étape 2 : L'ensemble de données comporte 768 instances. Nous devons accéder au nombre d'attributs, c'est-à-dire 9.
| log.info("Le nombre d'attributs (caractéristiques) dans l'ensemble de données : " + dataInstances.numAttributes()); |
Étape 3 : Nous devons déterminer la colonne cible avant de construire un modèle et de trouver le nombre de classes.
| // Identification de l'index de l'étiquette dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // Obtenir le nombre de log.info(“Le nombre de classes : ” + dataInstances.numClasses()); |
Etape 4 : Nous allons maintenant construire le modèle à l'aide d'un classificateur arborescent simple, J48.
| // Création d'un classificateur d'arbre de décision J48 treeClassifier = new J48(); treeClassifier.setOptions(new String[] { "-U" }); treeClassifier.buildClassifier(dataInstances); |
Le code ci-dessus explique comment créer une arborescence non élaguée composée des instances de données requises pour la formation du modèle. Une fois l'arborescence imprimée après l'apprentissage du modèle, nous pouvons déterminer comment les règles ont été construites en interne.
| plas <= 127 | masse <= 26,4 | | preg <= 7 : testé_négatif (117,0/1,0) | | enceinte > 7 | | | masse <= 0 : testé_positif (2.0) | | | masse > 0 : testé_négatif (13.0) | masse > 26,4 | | âge <= 28 : test_négatif (180,0/22,0) | | âge > 28 ans | | | plas <= 99 : testé_négatif (55,0/10,0) | | | plas > 99 | | | | pedi <= 0,56 : testé_négatif (84,0/34,0) | | | | pedi > 0,56 | | | | | enceinte <= 6 | | | | | | âge <= 30 : testé_positif (4.0) | | | | | | âge > 30 ans | | | | | | | âge <= 34 : test_négatif (7,0/1,0) | | | | | | | âge > 34 ans | | | | | | | | masse <= 33,1 : testé_positif (6,0) | | | | | | | | masse > 33,1 : testé_négatif (4,0/1,0) | | | | | preg > 6 : testé_positif (13.0) plas > 127 | masse <= 29,9 | | plas <= 145 : testé_négatif (41,0/6,0) | | plas > 145 | | | âge <= 25 : testé_négatif (4.0) | | | âge > 25 ans | | | | âge <= 61 | | | | | masse <= 27,1 : testé_positif (12,0/1,0) | | | | | masse > 27,1 | | | | | | près <= 82 | | | | | | | pedi <= 0,396 : testé_positif (8,0/1,0) | | | | | | | pedi > 0,396 : testé_négatif (3,0)  | | | | | | prés > 82 : testé_négatif (4.0) | | | | âge > 61 : test_négatif (4.0) | masse > 29,9 | | plas <= 157 | | | pres <= 61 : testé_positif (15,0/1,0) | | | presse > 61 | | | | âge <= 30 : testé_négatif (40,0/13,0) | | | | âge > 30 : testé_positif (60,0/17,0) | | plas > 157 : testé_positif (92.0/12.0) Nombre de feuilles : 22 Taille de l'arbre : 43 |
4. Apache Mahaut
Mahaut est une collection d'algorithmes pour aider à mettre en œuvre l'apprentissage automatique à l'aide de Java. Il s'agit d'un cadre d'algèbre linéaire évolutif à l'aide duquel les développeurs peuvent effectuer des analyses mathématiques et statisticiennes. Il est généralement utilisé par les scientifiques des données, les ingénieurs de recherche et les professionnels de l'analyse pour créer des applications prêtes pour l'entreprise. Son évolutivité et sa flexibilité permettent aux utilisateurs de mettre en œuvre des clusters de données, des systèmes de recommandation et de créer rapidement et facilement des applications d'apprentissage automatique performantes.
5. Apprentissage en profondeur4j
Deeplearning4j est une bibliothèque de programmation écrite en Java et offre un support étendu pour l'apprentissage en profondeur. Il s'agit d'un cadre open source qui combine des réseaux de neurones profonds et un apprentissage par renforcement profond pour servir les opérations commerciales. Il est compatible avec Scala, Kotlin, Apache Spark, Hadoop et d'autres langages JVM et frameworks de calcul Big Data.
Il est généralement utilisé pour détecter des schémas et des émotions dans la voix, la parole et le texte écrit. Il sert d'outil de bricolage qui peut découvrir les écarts dans les transactions et gérer plusieurs tâches. Il s'agit d'une bibliothèque distribuée de qualité commerciale qui dispose d'une documentation API détaillée en raison de sa nature open source.
Voici un exemple de la façon dont vous pouvez mettre en œuvre l'apprentissage automatique à l'aide de Deeplearning4j.
Exemple : À l'aide de Deeplearning4j, nous allons construire un modèle de réseau de neurones à convolution (CNN) pour classer les chiffres manuscrits à l'aide de la bibliothèque MNIST.
Étape 1 : Chargez le jeu de données pour afficher sa taille.
| DataSetIterator MNISTTrain = new MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = new MnistDataSetIterator(batchSize,false,seed); |
Étape 2 : Assurez-vous que le jeu de données nous donne dix étiquettes uniques.
| log.info("Le nombre total d'étiquettes trouvées dans l'ensemble de données d'apprentissage" + MNISTTrain.totalOutcomes()); log.info("Le nombre total d'étiquettes trouvées dans l'ensemble de données de test" + MNISTTest.totalOutcomes()); |
Étape 3 : Maintenant, nous allons configurer l'architecture du modèle en utilisant deux couches de convolution avec une couche aplatie pour afficher la sortie.
Il existe des options dans Deeplearning4j qui vous permettent d'initialiser le schéma de pondération.
| // Construction du modèle CNN MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(seed) // graine aléatoire .l2(0.0005) // régularisation .weightInit(WeightInit.XAVIER) // initialisation du schéma de poids .updater(new Adam(1e-3)) // Définition de l'algorithme d'optimisation .liste() .layer(nouveau ConvolutionLayer.Builder(5, 5) //Définition de la foulée, de la taille du noyau et de la fonction d'activation. .nIn(nCanaux) .foulée(1,1) .nOut(20) .activation(Activation.IDENTITY) .construire()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // sous-échantillonnage de la convolution .kernelSize(2,2) .foulée(2,2) .construire()) .layer(nouveau ConvolutionLayer.Builder(5, 5) // Définition de la foulée, de la taille du noyau et de la fonction d'activation. .foulée(1,1) .nOut(50) .activation(Activation.IDENTITY) .construire()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // sous-échantillonnage de la convolution .kernelSize(2,2) .foulée(2,2) .construire()) .layer(new DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(numSortie) .activation(Activation.SOFTMAX) .construire()) // la couche de sortie finale est 28×28 avec une profondeur de 1. .setInputType(InputType.convolutionalFlat(28,28,1)) .construire(); |
Étape 4 : Après avoir configuré l'architecture, nous allons initialiser le mode et le jeu de données d'entraînement, et commencer l'entraînement du modèle.
| Modèle MultiLayerNetwork = new MultiLayerNetwork(conf); // initialise les poids du modèle. modèle.init(); log.info("Etape 2 : démarrer l'entraînement du modèle"); //Définition d'un écouteur toutes les 10 itérations et évaluation sur l'ensemble de tests à chaque époque model.setListeners(new ScoreIterationListener(10), new EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // Entraînement du modèle model.fit(MNISTTrain, nEpochs); |
Au début de la formation du modèle, vous aurez la matrice de confusion de la précision de la classification.
Voici la précision du modèle après dix périodes d'entraînement :
| =========================Matrice de confusion======================= == 0 1 2 3 4 5 6 7 8 9 ————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ELKI
L'environnement de développement d'applications KDD pris en charge par Index-structure ou ELKI est une collection d'algorithmes et de programmes intégrés utilisés pour l'exploration de données. Écrit en Java, il s'agit d'une bibliothèque open source qui comprend des paramètres hautement configurables dans des algorithmes. Il est généralement utilisé par les chercheurs scientifiques et les étudiants pour mieux comprendre les ensembles de données. Comme son nom l'indique, il fournit un environnement pour développer des programmes sophistiqués d'exploration de données et des bases de données à l'aide d'une structure d'index.
7. JSAT
L'outil d'analyse statistique Java ou JSAT est une bibliothèque GPL3 qui utilise un cadre orienté objet pour aider les utilisateurs à mettre en œuvre l'apprentissage automatique avec Java. Il est généralement utilisé à des fins d'auto-apprentissage par les étudiants et les développeurs. Par rapport aux autres bibliothèques d'implémentation d'IA, JSAT possède le plus grand nombre d'algorithmes ML et est le plus rapide parmi tous les frameworks. Sans aucune dépendance externe, il est très flexible et efficace et offre des performances élevées.
8. Le cadre d'apprentissage automatique Encog
Encog est écrit en Java et C# et comprend des bibliothèques qui aident à implémenter des algorithmes d'apprentissage automatique. Il est utilisé pour créer des algorithmes génétiques, des réseaux bayésiens, des modèles statistiques comme le modèle de Markov caché, etc.
9. Maillet
Machine Learning for Language Toolkit ou Mallet est utilisé dans le traitement du langage naturel (TAL). Comme la plupart des autres frameworks d'implémentation ML, Mallet prend également en charge la modélisation des données, le regroupement des données, le traitement des documents, la classification des documents, etc.
10. Étincelle MLlib
Spark MLlib est utilisé par les entreprises pour améliorer l'efficacité et l'évolutivité de la gestion des workflows. Il traite de grandes quantités de données et prend en charge des algorithmes ML très chargés.
Paiement : Idées de projets d'apprentissage automatique
Conclusion
Cela nous amène à la fin de l'article. Pour plus d'informations sur les concepts d'apprentissage automatique, contactez les meilleurs professeurs de l'IIIT Bangalore et de l'Université John Moores de Liverpool via le programme de maîtrise ès sciences en apprentissage automatique et IA d'upGrad.
Pourquoi devrions-nous utiliser Java avec Machine Learning ?
Les professionnels de l'apprentissage automatique trouveront plus facile de s'interfacer avec les référentiels de code actuels s'ils choisissent Java comme langage de programmation pour leurs projets. Il s'agit d'un langage d'apprentissage automatique de préférence en raison de fonctionnalités telles que la facilité d'utilisation, les services de package, une meilleure interaction avec l'utilisateur, un débogage rapide et une illustration graphique des données. Java permet aux développeurs de Machine Learning de faire facilement évoluer leurs systèmes, ce qui en fait un excellent choix pour créer de grandes applications de Machine Learning sophistiquées à partir de zéro. Java Virtual Machine (JVM) prend en charge un certain nombre d'environnements de développement intégrés (IDE) qui permettent aux apprenants machine de concevoir rapidement de nouveaux outils.
Est-ce facile d'apprendre Java ?
Comme Java est un langage de haut niveau, il est simple à appréhender. En tant qu'apprenant, vous n'aurez pas à entrer dans les détails car il s'agit d'un langage bien structuré, orienté objet, suffisamment simple à comprendre pour les novices. Parce qu'il existe de nombreuses procédures qui fonctionnent automatiquement, vous pouvez les maîtriser rapidement. Vous n'avez pas besoin d'entrer dans les détails sur la façon dont les choses fonctionnent là-bas. Java est un langage de programmation indépendant de la plate-forme. Il permet à un programmeur de créer une application mobile qui peut être utilisée sur n'importe quel appareil. C'est le langage préféré de l'Internet des objets, ainsi que le meilleur outil pour développer des applications au niveau de l'entreprise.
Qu'est-ce qu'ADAMS et en quoi est-il utile dans l'apprentissage automatique ?
Le système avancé d'exploration de données et d'apprentissage automatique (ADAMS) est un moteur de flux de travail sous licence GPLv3 permettant de créer et de gérer rapidement des flux de travail réactifs basés sur les données qui peuvent être facilement intégrés aux processus métier. Le moteur de workflow, qui suit le principe du moins c'est plus, est au cœur d'ADAMS. ADAMS utilise une structure arborescente au lieu de permettre à l'utilisateur d'organiser les opérateurs (ou les acteurs dans le jargon ADAMS) sur un canevas, puis de lier manuellement les entrées et les sorties. Aucune connexion explicite n'est requise car cette structure et les acteurs de contrôle déterminent la manière dont les données circulent dans le processus. La représentation interne de l'objet et l'imbrication des sous-opérateurs dans les gestionnaires d'opérateurs donnent une structure arborescente. ADAMS fournit un ensemble diversifié d'agents pour la récupération, le traitement, l'exploration et l'affichage des données.