
Qu'est-ce qu'un arbre de décision dans l'exploration de données ? Types, exemples concrets et applications
Publié: 2021-06-15Table des matières
Introduction à l'exploration de données
Les données sont souvent présentes sous forme de données brutes qui doivent être traitées efficacement pour être converties en informations utiles. La prédiction des résultats repose souvent sur le processus de recherche de modèles, d'anomalies ou de corrélations dans les données. Le processus a été appelé la « découverte des connaissances dans les bases de données ».
Ce n'est que dans les années 1990 que le terme « data mining » a été inventé. L'exploration de données a été fondée sur trois disciplines : les statistiques, l'intelligence artificielle et l'apprentissage automatique. L'exploration de données automatisée a fait passer le processus d'analyse d'une approche fastidieuse à une approche plus rapide. L'exploration de données permet à l'utilisateur de
- Supprimez toutes les données bruyantes et chaotiques
- Comprendre les données pertinentes et les utiliser pour la prédiction d'informations utiles.
- Le processus de prédiction des décisions éclairées est accéléré .
L'exploration de données peut également être qualifiée de processus d'identification de modèles d'informations cachés qui nécessitent une catégorisation. Ce n'est qu'alors que les données peuvent être converties en données utiles. Les données utiles peuvent être introduites dans un entrepôt de données, des algorithmes d'exploration de données, une analyse de données pour la prise de décision.
Arbre de décision en Datamining
Un type de technique d'exploration de données, l'arbre de décision dans l'exploration de données construit un modèle pour la classification des données. Les modèles sont construits sous forme d'arborescence et appartiennent donc à la forme d'apprentissage supervisé. Outre les modèles de classification, les arbres de décision sont utilisés pour construire des modèles de régression pour prédire des étiquettes de classe ou des valeurs facilitant le processus de prise de décision. Les données numériques et catégorielles telles que le sexe, l'âge, etc. peuvent être utilisées par un arbre de décision.
Structure d'un arbre de décision
La structure d'un arbre de décision se compose d'un nœud racine, de branches et de nœuds feuilles. Les nœuds ramifiés sont les résultats d'un arbre et les nœuds internes représentent le test sur un attribut. Les nœuds feuilles représentent une étiquette de classe.
Fonctionnement d'un arbre de décision
1. Un arbre de décision fonctionne selon l'approche d'apprentissage supervisé pour les variables discrètes et continues. L'ensemble de données est divisé en sous-ensembles sur la base de l'attribut le plus significatif de l'ensemble de données. L'identification de l'attribut et le fractionnement sont effectués par les algorithmes.
2. La structure de l'arbre de décision se compose du nœud racine, qui est le nœud prédicteur significatif. Le processus de division se produit à partir des nœuds de décision qui sont les sous-nœuds de l'arbre. Les nœuds qui ne se divisent pas davantage sont appelés nœuds feuilles ou nœuds terminaux.
3. L'ensemble de données est divisé en régions homogènes et sans chevauchement selon une approche descendante. La couche supérieure fournit les observations à un seul endroit qui se divise ensuite en branches. Le processus est appelé "approche gourmande" en raison de sa concentration uniquement sur le nœud actuel plutôt que sur les futurs nœuds.
4. Tant qu'un critère d'arrêt n'est pas atteint, l'arbre de décision continue de fonctionner.
5. Avec la construction d'un arbre de décision, beaucoup de bruit et de valeurs aberrantes sont générés. Pour supprimer ces données aberrantes et bruitées, une méthode de «Tree pruning» est appliquée. Par conséquent, la précision du modèle augmente.
6. La précision d'un modèle est vérifiée sur un jeu de test composé de tuples de test et d'étiquettes de classe. Un modèle précis est défini sur la base des pourcentages d'uplets et de classes de l'ensemble de tests de classification par le modèle.
Figure 1 : Exemple d'un arbre non élagué et d'un arbre élagué
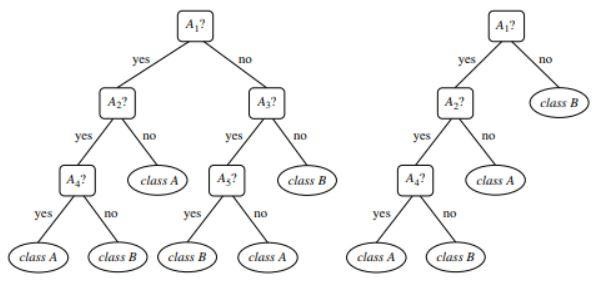
La source
Types d'arbre de décision
Les arbres de décision conduisent au développement de modèles de classification et de régression basés sur une structure arborescente. Les données sont décomposées en sous-ensembles plus petits. Le résultat d'un arbre de décision est un arbre avec des nœuds de décision et des nœuds feuilles. Deux types d'arbres de décision sont expliqués ci-dessous :
1. Classement
La classification comprend la construction de modèles décrivant les étiquettes de classe importantes. Ils sont appliqués dans les domaines de l'apprentissage automatique et de la reconnaissance de formes. Les arbres de décision dans l'apprentissage automatique via des modèles de classification conduisent à la détection de fraude, au diagnostic médical, etc. Le processus en deux étapes d'un modèle de classification comprend :
- Apprentissage : Un modèle de classification basé sur les données d'apprentissage est construit.
- Classification : la précision du modèle est vérifiée puis utilisée pour la classification des nouvelles données. Les étiquettes de classe se présentent sous la forme de valeurs discrètes comme "oui", ou "non", etc.
Figure 2 : Exemple de modèle de classification .
La source
2. Régression
Les modèles de régression sont utilisés pour l'analyse de régression des données, c'est-à-dire la prédiction des attributs numériques. Celles-ci sont également appelées valeurs continues. Par conséquent, au lieu de prédire les étiquettes de classe, le modèle de régression prédit les valeurs continues.
Liste des algorithmes utilisés
Un algorithme d'arbre de décision connu sous le nom de "ID3" a été développé en 1980 par un chercheur en machine nommé J. Ross Quinlan. Cet algorithme a été remplacé par d'autres algorithmes comme C4.5 développés par lui. Les deux algorithmes ont appliqué l'approche gourmande. L'algorithme C4.5 n'utilise pas de backtracking et les arbres sont construits selon une méthode descendante récursive de division et de conquête. L'algorithme a utilisé un ensemble de données d'apprentissage avec des étiquettes de classe qui sont divisées en sous-ensembles plus petits au fur et à mesure que l'arbre est construit.
- Trois paramètres sont initialement sélectionnés : la liste des attributs, la méthode de sélection des attributs et la partition des données. Les attributs de l'ensemble d'apprentissage sont décrits dans la liste des attributs.
- Le procédé de sélection d'attribution comprend le procédé de sélection du meilleur attribut pour la discrimination parmi les tuples.
- Une arborescence dépend de la méthode de sélection des attributs.
- La construction d'un arbre commence par un seul nœud.
- Le fractionnement des tuples se produit lorsque différentes étiquettes de classe sont représentées dans un tuple. Cela conduira à la formation de branches de l'arbre.
- La méthode de fractionnement détermine quel attribut doit être sélectionné pour la partition de données. Sur la base de cette méthode, les branches sont développées à partir d'un nœud en fonction du résultat du test.
- La méthode de fractionnement et de partitionnement est effectuée de manière récursive, aboutissant finalement à un arbre de décision pour les tuples d'ensemble de données d'apprentissage.
- Le processus de formation de l'arbre continue jusqu'à ce que et à moins que les tuples restants ne puissent plus être partitionnés.
- La complexité de l'algorithme est notée
n * |D| * journal |D|
Où, n est le nombre d'attributs dans l'ensemble de données d'apprentissage D et |D| est le nombre de tuples.
La source
Figure 3 : Un découpage en valeurs discrètes
Les listes d'algorithmes utilisés dans un arbre de décision sont :
ID3
L'ensemble des données S est considéré comme le nœud racine lors de la formation de l'arbre de décision. Une itération est ensuite effectuée sur chaque attribut et un découpage des données en fragments. L'algorithme vérifie et prend les attributs qui n'ont pas été pris avant ceux itérés. Le fractionnement des données dans l'algorithme ID3 prend du temps et n'est pas un algorithme idéal car il suradapte les données.
C4.5
Il s'agit d'une forme avancée d'algorithme car les données sont classées en tant qu'échantillons. Les valeurs continues et discrètes peuvent être gérées efficacement contrairement à ID3. Une méthode d'élagage est présente qui supprime les branches indésirables.
CHARIOT
Les tâches de classification et de régression peuvent être effectuées par l'algorithme. Contrairement à ID3 et C4.5, les points de décision sont créés en considérant l'indice de Gini. Un algorithme glouton est appliqué pour la méthode de découpage visant à réduire la fonction de coût. Dans les tâches de classification, l'indice de Gini est utilisé comme fonction de coût pour indiquer la pureté des nœuds feuilles. Dans les tâches de régression, l'erreur quadratique somme est utilisée comme fonction de coût pour trouver la meilleure prédiction.
CHAID
Comme son nom l'indique, il s'agit de Chi-square Automatic Interaction Detector, un processus traitant de tout type de variables. Il peut s'agir de variables nominales, ordinales ou continues. Les arbres de régression utilisent le test F, tandis que le test du chi carré est utilisé dans le modèle de classification.

MARS
Il représente les splines de régression adaptative multivariée. L'algorithme est spécialement implémenté dans les tâches de régression, où les données sont principalement non linéaires.
Fractionnement binaire récursif gourmand
Une méthode de fractionnement binaire se produit, ce qui donne deux branches. Le fractionnement des tuples est effectué avec le calcul de la fonction de coût fractionné. La division de coût la plus faible est sélectionnée et le processus est exécuté de manière récursive pour calculer la fonction de coût des autres tuples.
Arbre de décision avec exemple du monde réel
Prédire le processus d'éligibilité au prêt à partir de données données.
Etape 1 : Chargement des données
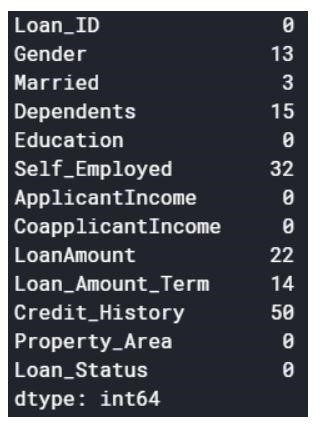
Les valeurs nulles peuvent être supprimées ou remplies avec certaines valeurs. La forme de l'ensemble de données d'origine était (614,13) et le nouvel ensemble de données après suppression des valeurs nulles est (480,13).
Étape 2 : un aperçu de l'ensemble de données.

Étape 3 : Fractionnement des données en ensembles d'apprentissage et de test.
Étape 4 : Construisez le modèle et installez le train

Avant la visualisation quelques calculs sont à faire.
Calcul 1 : calcule l'entropie de l'ensemble de données total.

Calcul 2 : Trouvez l'entropie et le gain pour chaque colonne.
- Colonne Genre
- Condition 1 : ensemble de données contenant tous les hommes, puis,
p=278, n=116 , p+n=489
Entropie (G = Homme) = 0,87
- Condition 2 : ensemble de données contenant toutes les femmes, puis,
p = 54 , n = 32 , p+n = 86
Entropie (G = Femme) = 0,95
- Information moyenne dans la colonne sexe

- Colonne mariée
- Condition 1 : Marié = Oui(1)
Dans cette division, l'ensemble de données complet avec le statut Marié oui
p = 227 , n = 84 , p+n = 311
E(Marié = Oui) = 0,84
- Condition 2 : Marié = Non(0)
Dans cette division, l'ensemble de données complet avec le statut Marié non
p = 105 , n = 64 , p+n = 169
E(Marié = Non) = 0,957
- L'information moyenne dans la colonne Marié est
- Chronique éducative
- Condition 1 : Éducation = Diplômé(1)
p = 271 , n = 112 , p+n = 383
E(Éducation = Diplômé) = 0,87
- Condition 2 : Éducation = Non Diplômé(0)
p = 61 , n = 36 , p+n = 97
E(Éducation = Non Diplômé) = 0,95
- Colonne Information moyenne sur l'éducation = 0,886
Gain = 0,01
4) Colonne des travailleurs indépendants
- Condition 1 : Indépendant = Oui(1)
p = 43 , n = 23 , p+n = 66
E(Travailleur indépendant=Oui) = 0,93
- Condition 2 : Indépendant = Non(0)
p = 289 , n = 125 , p+n = 414
E(Travailleur indépendant=Non) = 0,88
- Information moyenne dans la colonne des travailleurs indépendants en formation = 0,886
Gain = 0,01
- Colonne Pointage de crédit : la colonne contient les valeurs 0 et 1.
- Condition 1 : Pointage de crédit = 1
p = 325 , n = 85 , p+n = 410
E(pointage de crédit = 1) = 0,73
- Condition 2 : Pointage de crédit = 0
p = 63 , n = 7 , p+n = 70
E(pointage de crédit = 0) = 0,46
- Information moyenne dans la colonne Pointage de crédit = 0,69
Gain = 0,2
Comparez toutes les valeurs de gain

Le pointage de crédit a le gain le plus élevé. Par conséquent, il sera utilisé comme nœud racine.
Étape 5 : Visualisez l'arbre de décision

Figure 5 : Arbre de décision avec critère de Gini
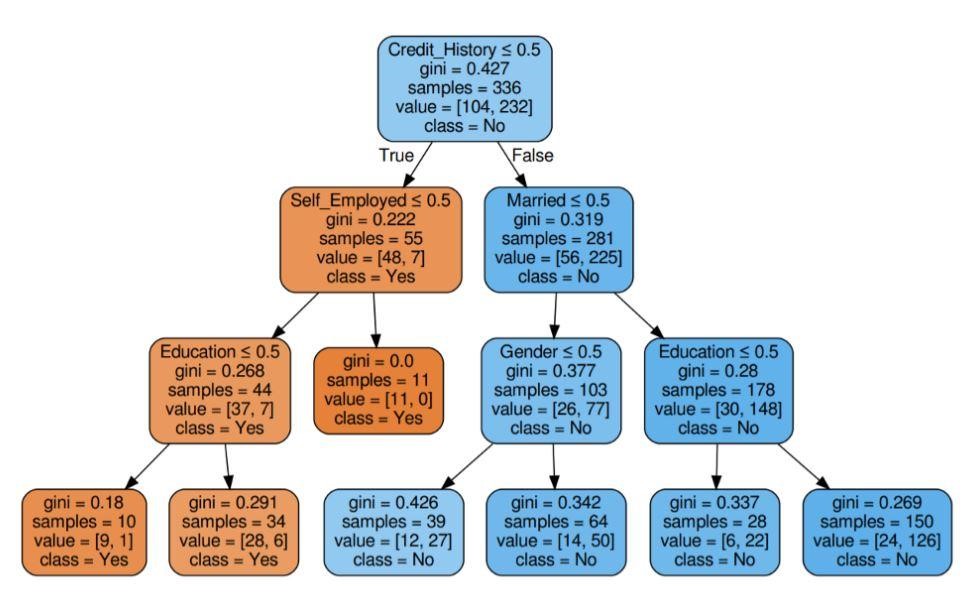 La source
La source
Figure 6 : Arbre de décision avec critère d'entropie
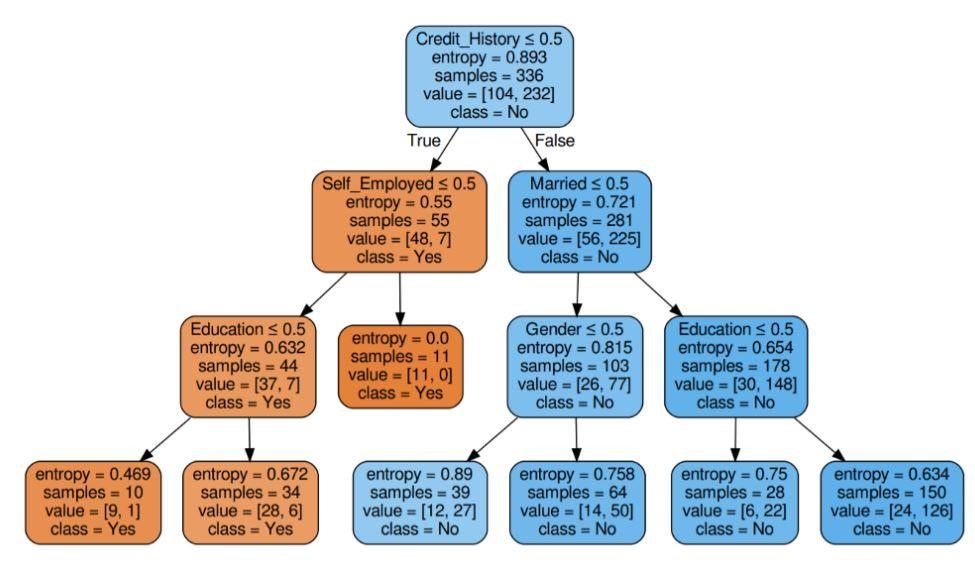
La source
Étape 6 : Vérifier le score du modèle
Près de 80 % de précision ont été obtenus.
Liste des candidatures
Les arbres de décision sont principalement utilisés par les experts en information pour mener une enquête analytique. Ils peuvent être largement utilisés à des fins commerciales pour analyser ou prévoir des difficultés. La flexibilité de l'arbre de décision permet de les utiliser dans un domaine différent :
1. Santé
Les arbres de décision permettent de prédire si un patient souffre d'une maladie particulière avec des conditions d'âge, de poids, de sexe, etc. D'autres prédictions incluent la décision de l'effet du médicament en tenant compte de facteurs tels que la composition, la période de fabrication, etc.
2. Secteurs bancaires
Les arbres de décision aident à prédire si une personne est éligible à un prêt compte tenu de sa situation financière, de son salaire, des membres de sa famille, etc. Il peut également identifier les fraudes à la carte de crédit, les défauts de paiement, etc.
3. Secteurs éducatifs
La présélection d'un étudiant en fonction de sa note de mérite, de son assiduité, etc. peut être décidée à l'aide d'arbres de décision.
Liste des avantages
- Les résultats interprétables d'un modèle décisionnel peuvent être présentés à la haute direction et aux parties prenantes.
- Lors de la construction d'un modèle d'arbre de décision, le prétraitement des données, c'est-à-dire la normalisation, la mise à l'échelle, etc. n'est pas nécessaire.
- Les deux types de données numériques et catégorielles peuvent être gérées par un arbre de décision qui affiche sa plus grande efficacité d'utilisation par rapport aux autres algorithmes.
- La valeur manquante dans les données n'affecte pas le processus d'un arbre de décision, ce qui en fait un algorithme flexible.
Et ensuite ?
Si vous souhaitez acquérir une expérience pratique de l'exploration de données et être formé par des experts, vous pouvez consulter le programme Executive PG en science des données d'upGrad. Le cours s'adresse à tout groupe d'âge entre 21 et 45 ans avec des critères d'éligibilité minimum de 50% ou des notes de passage équivalentes à l'obtention du diplôme. Tous les professionnels en activité peuvent rejoindre ce programme exécutif PG certifié par IIIT Bangalore.
Les arbres de décision dans l'exploration de données ont la capacité de gérer des données très complexes. Tous les arbres de décision ont trois nœuds ou portions vitaux. Discutons de chacun d'eux ci-dessous. Maintenant que nous avons compris le fonctionnement des arbres de décision, essayons d'examiner quelques avantages de l'utilisation des arbres de décision dans l'exploration de donnéesQu'est-ce qu'un arbre de décision dans le Data Mining ?
Un arbre de décision est un moyen de construire des modèles dans l'exploration de données. Il peut être compris comme un arbre binaire inversé. Il comprend un nœud racine, quelques branches et des nœuds feuilles à la fin.
Chacun des nœuds internes d'un arbre de décision signifie une étude sur un attribut. Chacune des divisions signifie la conséquence de cette étude ou de cet examen particulier. Et enfin, chaque nœud feuille représente une balise de classe.
L'objectif principal de la construction d'un arbre de décision est de créer un idéal qui peut être utilisé pour prévoir la classe particulière en utilisant des procédures de jugement sur des données précédentes.
Nous commençons par le nœud racine, établissons des relations avec la variable racine et effectuons des divisions qui correspondent à ces valeurs. Sur la base des choix de base, nous sautons aux nœuds suivants. Quels sont certains des nœuds importants utilisés dans les arbres de décision ?
Lorsque nous connectons tous ces nœuds, nous obtenons des divisions. Nous pouvons former des arbres avec une variété de difficultés en utilisant ces nœuds et divisions un nombre infini de fois. Quels sont les avantages d'utiliser les arbres de décision ?
1. Lorsque nous les comparons à d'autres méthodes, les arbres de décision ne nécessitent pas autant de calculs pour l'apprentissage des données lors du prétraitement.
2. La stabilisation des informations n'est pas impliquée dans les arbres de décision.
3. De plus, ils ne nécessitent même pas de mise à l'échelle des informations.
4. Même si certaines valeurs sont omises dans le jeu de données, cela n'interfère pas dans la construction des arbres.
5. Ces modèles instinctifs sont identiques. Ils sont également sans stress pour la description.