
Création de compétences vocales pour Google Assistant et Amazon Alexa
Publié: 2022-03-10Au cours de la dernière décennie, il y a eu un changement sismique vers les interfaces conversationnelles. Au fur et à mesure que les gens atteignent le "pic d'écran" et commencent même à réduire l'utilisation de leur appareil, les fonctionnalités de bien-être numérique sont intégrées à la plupart des systèmes d'exploitation.
Pour lutter contre la fatigue des écrans, les assistants vocaux sont entrés sur le marché pour devenir une option privilégiée pour récupérer rapidement des informations. Une statistique bien répétée indique que 50% des recherches seront effectuées par la voix en 2020. De plus, à mesure que l'adoption augmente, il appartient aux développeurs d'ajouter des «interfaces conversationnelles» et des «assistants vocaux» à leur ceinture d'outils.
Concevoir l'invisible
Pour beaucoup, se lancer dans un projet d'interface vocale (VUI) peut être un peu comme entrer dans l'inconnu. En savoir plus sur les leçons apprises par William Merrill lors de la conception pour la voix. Lire un article connexe →
Qu'est-ce qu'une interface conversationnelle ?
Une interface conversationnelle (parfois abrégée en CUI, est toute interface dans un langage humain. Elle est censée être une interface plus naturelle pour le grand public que l'interface graphique utilisateur graphique, que les développeurs frontaux sont habitués à construire. Une interface graphique nécessite des humains pour apprendre ses syntaxes spécifiques de l'interface (pensez aux boutons, curseurs et listes déroulantes).
Cette différence clé dans l'utilisation du langage humain rend le CUI plus naturel pour les gens ; il nécessite peu de connaissances et place le fardeau de la compréhension sur l'appareil.
Généralement, les CUI se présentent sous deux formes : les chatbots et les assistants vocaux. Les deux ont connu une augmentation massive de leur adoption au cours de la dernière décennie grâce aux progrès du traitement du langage naturel (TAL).
Comprendre le jargon vocal

| Mot-clé | Signification |
|---|---|
| Compétence/Action | Une application vocale, qui peut répondre à une série d'intentions |
| Intention | Action prévue pour la compétence à accomplir, ce que l'utilisateur veut que la compétence fasse en réponse à ce qu'il dit. |
| Énonciation | La phrase qu'un utilisateur dit ou prononce. |
| Mot de réveil | Le mot ou la phrase utilisée pour démarrer l'écoute d'un assistant vocal, par exemple "Hey google", "Alexa" ou "Hey Siri" |
| Le contexte | Les éléments d'information contextuelle dans un énoncé, qui aident la compétence à réaliser une intention, par exemple « aujourd'hui », « maintenant », « quand je rentrerai ». |
Qu'est-ce qu'un assistant vocal ?
Un assistant vocal est un logiciel capable de NLP (Natural Language Processing). Il reçoit une commande vocale et renvoie une réponse au format audio. Ces dernières années, la portée de la façon dont vous pouvez interagir avec un assistant s'est élargie et a évolué, mais le cœur de la technologie est le langage naturel, beaucoup de calculs, le langage naturel.
Pour ceux qui veulent un peu plus de détails :
- Le logiciel reçoit une demande audio d'un utilisateur, transforme le son en phonèmes, les éléments constitutifs du langage.
- Par la magie de l'IA (Spécifiquement Speech-To-Text), ces phonèmes sont convertis en une chaîne de la requête approchée, celle-ci est conservée dans un fichier JSON qui contient également des informations supplémentaires sur l'utilisateur, la requête et la session.
- Le JSON est ensuite traité (généralement dans le cloud) pour déterminer le contexte et l'intention de la demande.
- Sur la base de l'intention, une réponse est renvoyée, encore une fois dans une réponse JSON plus grande, soit sous forme de chaîne, soit sous forme de SSML (plus à ce sujet plus tard)
- La réponse est traitée à l'aide de l'IA (naturellement l'inverse - Text-To-Speech) qui est ensuite renvoyée à l'utilisateur.
Il se passe beaucoup de choses là-bas, dont la plupart ne nécessitent pas une seconde réflexion. Mais chaque plate-forme le fait différemment, et ce sont les nuances de la plate-forme qui nécessitent un peu plus de compréhension.

Appareils à commande vocale
Les exigences pour qu'un appareil puisse avoir un assistant vocal intégré sont assez faibles. Ils nécessitent un microphone, une connexion Internet et un haut-parleur. Les haut-parleurs intelligents comme le Nest Mini et l'Echo Dot offrent ce type de contrôle vocal low-fi.
Le prochain dans les rangs est la voix + écran, c'est ce qu'on appelle un appareil « multimodal » (plus sur ceux-ci plus tard), et ce sont des appareils comme le Nest Hub et l'Echo Show. Comme les smartphones ont cette fonctionnalité, ils peuvent également être considérés comme un type d'appareil vocal multimodal.
Compétences vocales
Tout d'abord, chaque plate-forme a un nom différent pour ses "compétences vocales", Amazon va avec des compétences, que je conserverai comme un terme universellement compris. Google opte pour « Actions » et Samsung opte pour des « capsules ».
Chaque plate-forme a ses propres compétences intégrées, comme demander l'heure, la météo et les jeux de sport. Les compétences créées par les développeurs (tierces) peuvent être invoquées avec une phrase spécifique ou, si la plate-forme l'aime, peuvent être invoquées implicitement, sans phrase clé.
Invocation explicite : "Hey Google, parle à <nom de l'application>."
Il est explicitement indiqué quelle compétence est demandée :
Invocation implicite : "Hey Google, quel temps fait-il aujourd'hui ?"
Le contexte de la demande implique le service souhaité par l'utilisateur.
Quels sont les assistants vocaux ?
Sur le marché occidental, les assistants vocaux sont vraiment une course à trois chevaux. Apple, Google et Amazon ont des approches très différentes de leurs assistants et, à ce titre, s'adressent à différents types de développeurs et de clients.
Siri d'Apple
Nom de l'appareil : "Siri"
Phrase de réveil : "Hey Siri"
Siri compte plus de 375 millions d'utilisateurs actifs, mais par souci de brièveté, je n'entrerai pas trop dans les détails pour Siri. Bien qu'il puisse être globalement bien adopté et intégré à la plupart des appareils Apple, il nécessite que les développeurs aient déjà une application sur l'une des plates-formes d'Apple et soit écrit en rapide (alors que les autres peuvent être écrits dans le favori de tous : Javascript). À moins que vous ne soyez un développeur d'applications qui souhaite étendre l'offre de son application, vous pouvez actuellement ignorer Apple jusqu'à ce qu'il ouvre sa plate-forme.
Assistant Google
Noms d'appareil : "Google Home, Nest"
Phrase de réveil : "Hey Google"
Google a le plus d'appareils des trois grands, avec plus d'un milliard dans le monde, cela est principalement dû à la masse d'appareils Android sur lesquels Google Assistant est intégré, en ce qui concerne leurs haut-parleurs intelligents dédiés, les chiffres sont un peu plus petits. La mission globale de Google avec son assistant est de ravir les utilisateurs, et ils ont toujours été très bons pour fournir des interfaces légères et intuitives.
Leur objectif principal sur la plate-forme est d'utiliser le temps - avec l'idée de devenir une partie intégrante de la routine quotidienne des clients. En tant que tels, ils se concentrent principalement sur l'utilité, le plaisir en famille et les expériences agréables.
Les compétences conçues pour Google sont meilleures lorsqu'il s'agit de pièces d'engagement et de jeux, axés principalement sur le plaisir familial. Leur ajout récent de toile pour les jeux témoigne de cette approche. La plate-forme Google est beaucoup plus stricte pour les soumissions de compétences, et à ce titre, leur répertoire est beaucoup plus petit.
Amazon Alexa
Noms des appareils : "Amazon Fire, Amazon Echo"
Phrase de réveil : "Alexa"
Amazon a dépassé les 100 millions d'appareils en 2019, cela provient principalement des ventes de leurs haut-parleurs intelligents et de leurs écrans intelligents, ainsi que de leur gamme "fire" ou de tablettes et d'appareils de streaming.
Les compétences créées pour Amazon ont tendance à viser l'achat de compétences. Si vous recherchez une plateforme pour développer votre e-commerce/service, ou proposer un abonnement, alors Amazon est fait pour vous. Cela étant dit, le FAI n'est pas une exigence pour Alexa Skills, ils prennent en charge toutes sortes d'utilisations et sont beaucoup plus ouverts aux soumissions.
Les autres
Il existe encore plus d'assistants vocaux, tels que Bixby de Samsung, Cortana de Microsoft et le célèbre assistant vocal open source Mycroft. Tous les trois ont un public raisonnable, mais restent minoritaires par rapport aux trois Goliaths d'Amazon, Google et Apple.
Construire sur Amazon Alexa
L'écosystème d'Amazon pour la voix a évolué pour permettre aux développeurs de développer toutes leurs compétences au sein de la console Alexa, donc à titre d'exemple simple, je vais utiliser ses fonctionnalités intégrées.
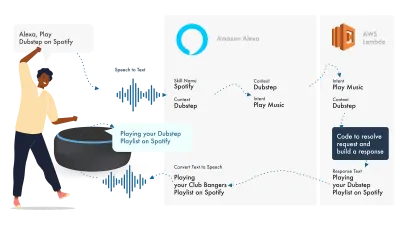
Alexa s'occupe du traitement du langage naturel, puis trouve une intention appropriée, qui est transmise à notre fonction Lambda pour gérer la logique. Cela renvoie certains bits de conversation (SSML, texte, cartes, etc.) à Alexa, qui convertit ces bits en audio et visuels à afficher sur l'appareil.
Travailler sur Amazon est relativement simple, car ils vous permettent de créer toutes les parties de vos compétences dans la console de développement Alexa. La flexibilité est là pour utiliser AWS ou un point de terminaison HTTPS, mais pour des compétences simples, tout exécuter dans la console Dev devrait être suffisant.
Construisons une compétence Alexa simple
Rendez-vous sur la console Amazon Alexa, créez un compte si vous n'en avez pas et connectez-vous,
Cliquez sur Create Skill puis donnez-lui un nom,
Choisissez custom comme modèle,
et choisissez Alexa-Hosted (Node.js) pour votre ressource backend.
Une fois l'approvisionnement terminé, vous disposerez d'une compétence Alexa de base, votre intention sera construite pour vous et un code back-end pour vous aider à démarrer.
Si vous cliquez sur HelloWorldIntent dans vos Intents, vous verrez quelques exemples d'énoncés déjà configurés pour vous, ajoutons-en un nouveau en haut. Notre compétence s'appelle hello world, alors ajoutez Hello World comme exemple d'énoncé. L'idée est de capturer tout ce que l'utilisateur pourrait dire pour déclencher cette intention. Cela pourrait être "Hi World", "Howdy World", et ainsi de suite.
Que se passe-t-il dans le Fulfillment JS ?
Alors que fait le code ? Voici le code par défaut :
const HelloWorldIntentHandler = { canHandle(handlerInput) { return Alexa.getRequestType(handlerInput.requestEnvelope) === 'IntentRequest' && Alexa.getIntentName(handlerInput.requestEnvelope) === 'HelloWorldIntent'; }, handle(handlerInput) { const speakOutput = 'Hello World!'; return handlerInput.responseBuilder .speak(speakOutput) .getResponse(); } }; Cela utilise le ask-sdk-core et construit essentiellement JSON pour nous. canHandle fait savoir à ask qu'il peut gérer les intentions, en particulier "HelloWorldIntent". handle prend l'entrée et construit la réponse. Ce que cela génère ressemble à ceci :

{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }
Nous pouvons voir que speak sort ssml dans notre json, c'est ce que l'utilisateur entendra tel qu'énoncé par Alexa.
Construire pour Google Assistant
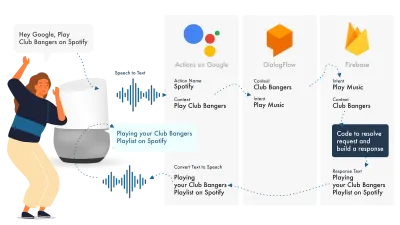
Le moyen le plus simple de créer des actions sur Google consiste à utiliser leur console AoG en combinaison avec Dialogflow, vous pouvez étendre vos compétences avec firebase, mais comme avec le didacticiel Amazon Alexa, gardons les choses simples.
Google Assistant utilise trois parties principales, AoG, qui traite du NLP, Dialogflow, qui élabore vos intentions, et Firebase, qui répond à la demande et produit la réponse qui sera renvoyée à AoG.
Tout comme avec Alexa, Dialogflow vous permet de construire vos fonctions directement au sein de la plateforme.
Créons une action sur Google
Il y a trois plates-formes pour jongler à la fois avec la solution de Google, qui sont accessibles par trois consoles différentes, alors tabulez !
Configurer Dialogflow
Commençons par nous connecter à la console Dialogflow. Une fois connecté, créez un nouvel agent à partir du menu déroulant juste en dessous du logo Dialogflow.
Donnez un nom à votre agent et ajoutez-le dans la "liste déroulante des projets Google", tout en ayant sélectionné "Créer un nouveau projet Google".
Cliquez sur le bouton Créer et laissez-le faire sa magie, la configuration de l'agent prendra un peu de temps, alors soyez patient.
Configuration des fonctions Firebase
Bon, maintenant nous pouvons commencer à brancher la logique Fulfillment.
Rendez-vous sur l'onglet Exécution. Cochez pour activer l'éditeur en ligne et utilisez les extraits JS ci-dessous :
index.js
'use strict'; // So that you have access to the dialogflow and conversation object const { dialogflow } = require('actions-on-google'); // So you have access to the request response stuff >> functions.https.onRequest(app) const functions = require('firebase-functions'); // Create an instance of dialogflow for your app const app = dialogflow({debug: true}); // Build an intent to be fulfilled by firebase, // the name is the name of the intent that dialogflow passes over app.intent('Default Welcome Intent', (conv) => { // Any extra logic goes here for the intent, before returning a response for firebase to deal with return conv.ask(`Welcome to a firebase fulfillment`); }); // Finally we export as dialogflowFirebaseFulfillment so the inline editor knows to use it exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);package.json
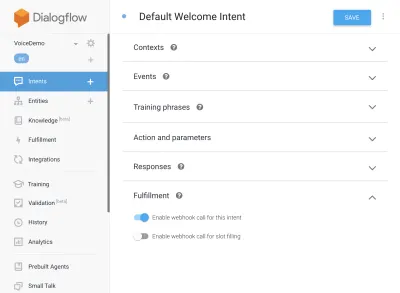
{ "name": "functions", "description": "Cloud Functions for Firebase", "scripts": { "lint": "eslint .", "serve": "firebase serve --only functions", "shell": "firebase functions:shell", "start": "npm run shell", "deploy": "firebase deploy --only functions", "logs": "firebase functions:log" }, "engines": { "node": "10" }, "dependencies": { "actions-on-google": "^2.12.0", "firebase-admin": "~7.0.0", "firebase-functions": "^3.3.0" }, "devDependencies": { "eslint": "^5.12.0", "eslint-plugin-promise": "^4.0.1", "firebase-functions-test": "^0.1.6" }, "private": true }Revenez maintenant à vos intentions, accédez à l'intention de bienvenue par défaut et faites défiler jusqu'à la réalisation, assurez-vous que "Activer l'appel webhook pour cette intention" est coché pour toutes les intentions que vous souhaitez réaliser avec javascript. Appuyez sur Enregistrer.
Configuration de l'AoG
Nous approchons maintenant de la ligne d'arrivée. Rendez-vous sur l'onglet Intégrations et cliquez sur Paramètres d'intégration dans l'option Assistant Google en haut. Cela ouvrira un modal, alors cliquons sur tester, ce qui intégrera votre Dialogflow à Google, et ouvrira une fenêtre de test sur Actions on Google.
Dans la fenêtre de test, nous pouvons cliquer sur Parler à mon application de test (nous allons changer cela dans une seconde), et le tour est joué, nous avons le message de notre javascript affiché sur un test de l'assistant Google.
Nous pouvons changer le nom de l'assistant dans l'onglet Développer, en haut.
Alors, que se passe-t-il dans le Fulfillment JS ?
Tout d'abord, nous utilisons deux packages npm, actions-on-google qui fournit tous les éléments dont AoG et Dialogflow ont besoin, et deuxièmement firebase-functions, que vous avez deviné, contient des aides pour firebase.
Nous créons ensuite "l'application", qui est un objet contenant toutes nos intentions.
Chaque intention créée a transmis "conv", qui est l'objet de conversation envoyé par Actions On Google. Nous pouvons utiliser le contenu de conv pour détecter des informations sur les interactions précédentes avec l'utilisateur (telles que son identifiant et des informations sur sa session avec nous).
Nous renvoyons un 'objet conv.ask', qui contient notre message de retour à l'utilisateur, prêt à ce qu'il réponde avec une autre intention. Nous pourrions utiliser 'conv.close' pour mettre fin à la conversation si nous voulions terminer la conversation ici.
Enfin, nous enveloppons le tout dans une fonction Firebase HTTPS, qui s'occupe de la logique de demande-réponse côté serveur pour nous.
Encore une fois, si nous regardons la réponse qui est générée :
{ "payload": { "google": { "expectUserResponse": true, "richResponse": { "items": [ { "simpleResponse": { "textToSpeech": "Welcome to a firebase fulfillment" } } ] } } } } Nous pouvons voir que conv.ask a vu son texte injecté dans la zone textToSpeech . Si nous avions choisi conv.close , expectUserResponse serait défini sur false et la conversation se fermerait après la livraison du message.
Constructeurs de voix tiers
Tout comme l'industrie des applications, à mesure que la voix gagne du terrain, des outils tiers ont commencé à apparaître dans le but d'alléger la charge des développeurs, leur permettant de construire une fois et de déployer deux fois.
Jovo et Voiceflow sont actuellement les deux plus populaires, surtout depuis l'acquisition de PullString par Apple. Chaque plate-forme offre un niveau d'abstraction différent, donc cela dépend vraiment de la simplicité de votre interface.
Extension de votre compétence
Maintenant que vous avez compris comment construire une compétence de base "Hello World", il y a beaucoup de cloches et de sifflets qui peuvent être ajoutés à votre compétence. Ce sont la cerise sur le gâteau des assistants vocaux et donneront à vos utilisateurs beaucoup de valeur supplémentaire, conduisant à une personnalisation répétée et à une opportunité commerciale potentielle.
SSML
SSML signifie langage de balisage de synthèse vocale et fonctionne avec une syntaxe similaire à HTML, la principale différence étant que vous créez une réponse parlée, et non du contenu sur une page Web.
« SSML » en tant que terme est un peu trompeur, il peut faire bien plus que de la synthèse vocale ! Vous pouvez avoir des voix en parallèle, vous pouvez inclure des bruits d'ambiance, des discours (qui valent la peine d'être écoutés, pensez aux émoticônes pour des phrases célèbres) et de la musique.
Quand dois-je utiliser SSML ?
SSML est génial ; cela rend l'expérience beaucoup plus attrayante pour l'utilisateur, mais cela réduit également la flexibilité de la sortie audio. Je recommande de l'utiliser pour les zones de discours plus statiques. Vous pouvez y utiliser des variables pour les noms, etc., mais à moins que vous n'ayez l'intention de créer un générateur SSML, la plupart des SSML seront assez statiques.
Commencez par un discours simple dans votre compétence, et une fois qu'il est terminé, améliorez les zones qui sont plus statiques avec SSML, mais obtenez votre noyau avant de passer aux cloches et aux sifflets. Cela étant dit, un rapport récent indique que 71 % des utilisateurs préfèrent une voix humaine (réelle) à une voix synthétisée, donc si vous avez la possibilité de le faire, allez-y et faites-le !

Dans les achats de compétences
Les achats intégrés (ou FAI) sont similaires au concept d'achats intégrés. Les compétences ont tendance à être gratuites, mais certaines permettent l'achat de contenu/d'abonnements "premium" dans l'application, ceux-ci peuvent améliorer l'expérience d'un utilisateur, débloquer de nouveaux niveaux sur les jeux ou permettre l'accès à du contenu payant.
Multimodal
Les réponses multimodales couvrent bien plus que la voix, c'est là que les assistants vocaux peuvent vraiment briller avec des visuels complémentaires sur les appareils qui les prennent en charge. La définition des expériences multimodales est beaucoup plus large et signifie essentiellement plusieurs entrées (clavier, souris, écran tactile, voix, etc.).
Les compétences multimodales sont destinées à compléter l'expérience vocale de base, en fournissant des informations complémentaires supplémentaires pour booster l'UX. Lorsque vous créez une expérience multimodale, n'oubliez pas que la voix est le principal vecteur d'information. De nombreux appareils n'ont pas d'écran, donc votre compétence doit toujours fonctionner sans écran, alors assurez-vous de tester avec plusieurs types d'appareils ; en vrai ou dans le simulateur.

Multilingue
Les compétences multilingues sont des compétences qui fonctionnent dans plusieurs langues et ouvrent vos compétences à plusieurs marchés.
La complexité de rendre votre compétence multilingue dépend de la dynamique de vos réponses. Les compétences avec des réponses relativement statiques, par exemple renvoyer la même phrase à chaque fois, ou n'utiliser qu'un petit groupe de phrases, sont beaucoup plus faciles à rendre multilingues que des compétences dynamiques tentaculaires.
L'astuce avec le multilingue est d'avoir un partenaire de traduction digne de confiance, que ce soit par l'intermédiaire d'une agence ou d'un traducteur sur Fiverr. Vous devez pouvoir faire confiance aux traductions fournies, surtout si vous ne comprenez pas la langue dans laquelle vous traduisez. Google translate ne coupera pas la moutarde ici !
Conclusion
S'il y avait un moment pour entrer dans l'industrie de la voix, ce serait maintenant. À ses débuts et à ses débuts, ainsi que les neuf grands, investissent des milliards pour le développer et apporter des assistants vocaux dans les maisons et les routines quotidiennes de tout le monde.
Choisir la plate-forme à utiliser peut être délicat, mais en fonction de ce que vous avez l'intention de construire, la plate-forme à utiliser doit briller ou, à défaut, utiliser un outil tiers pour couvrir vos paris et construire sur plusieurs plates-formes, surtout si votre compétence est moins compliqué avec moins de pièces mobiles.
Pour ma part, je suis enthousiasmé par l'avenir de la voix car elle devient omniprésente ; la dépendance à l'écran diminuera et les clients pourront interagir naturellement avec leur assistant. Mais d'abord, c'est à nous de construire les compétences que les gens voudront de leur assistant.