
Comprendre l'en-tête Vary
Publié: 2022-03-10L'en-tête HTTP Vary est envoyé chaque jour dans des milliards de réponses HTTP. Mais son utilisation n'a jamais rempli sa vision initiale, et de nombreux développeurs comprennent mal ce qu'il fait ou ne réalisent même pas que leur serveur Web l'envoie. Avec l'arrivée des conseils client, des variantes et des spécifications clés, les réponses variées prennent un nouveau départ.
Qu'est-ce que Vary ?
L'histoire de Vary commence par une belle idée de la façon dont le Web devrait fonctionner. En principe, une URL ne représente pas une page Web, mais une ressource conceptuelle, comme votre relevé bancaire. Imaginez que vous vouliez voir votre relevé bancaire : vous allez sur bank.com et envoyez une requête GET pour /statement . Jusqu'ici tout va bien, mais vous n'avez pas précisé dans quel format vous voulez la déclaration. C'est pourquoi votre navigateur inclura également quelque chose comme Accept: text/html dans votre demande. En théorie, au moins, cela signifie que vous pourriez dire Accept: text/csv à la place et obtenir la même ressource dans un format différent.

Étant donné que la même URL produit désormais des réponses différentes en fonction de la valeur de l'en-tête Accept , tout cache qui stocke cette réponse doit savoir que cet en-tête est important. Le serveur nous dit que l'en-tête Accept est important comme ceci :
Vary: Accept Vous pouvez lire ceci comme suit : "Cette réponse varie en fonction de la valeur de l'en-tête Accept de votre demande."
Cela ne fonctionne fondamentalement pas sur le Web d'aujourd'hui. La soi-disant « négociation de contenu » était une excellente idée, mais elle a échoué. Cela ne signifie pas pour autant que Vary est inutile. Une partie décente des pages que vous visitez sur le Web portent un en-tête Vary dans la réponse - peut-être que vos sites Web en ont aussi, et vous ne le savez pas. Donc, si l'en-tête ne fonctionne pas pour la négociation de contenu, pourquoi est-il toujours aussi populaire et comment les navigateurs le gèrent-ils ? Nous allons jeter un coup d'oeil.
J'ai déjà écrit sur Vary en relation avec les réseaux de diffusion de contenu (CDN), ces caches intermédiaires (tels que Fastly, CloudFront et Akamai) que vous pouvez placer entre vos serveurs et l'utilisateur. Les navigateurs doivent également comprendre et répondre aux règles Vary, et la façon dont ils le font est différente de la façon dont Vary est traité par les CDN. Dans cet article, j'explorerai le monde trouble de la variation du cache dans le navigateur.
Cas d'utilisation d'aujourd'hui pour varier dans le navigateur
Comme nous l'avons vu précédemment, l'utilisation traditionnelle de Vary consiste à effectuer une négociation de contenu à l'aide des en-têtes Accept , Accept-Language et Accept-Encoding et, historiquement, les deux premiers d'entre eux ont lamentablement échoué. Varier sur Accept-Encoding pour fournir des réponses compressées Gzip ou Brotli, lorsqu'elles sont prises en charge, fonctionne généralement assez bien, mais tous les navigateurs prennent en charge Gzip ces jours-ci, ce n'est donc pas très excitant.
Que diriez-vous de certains de ces scénarios?
- Nous souhaitons diffuser des images qui correspondent exactement à la largeur de l'écran de l'utilisateur. Si l'utilisateur redimensionne son navigateur, nous téléchargeons de nouvelles images (variant selon les conseils du client).
- Si l'utilisateur se déconnecte, nous voulons éviter d'utiliser les pages mises en cache pendant qu'il était connecté (en utilisant un cookie comme
Key). - Les utilisateurs de navigateurs prenant en charge le format d'image WebP doivent obtenir des images WebP ; sinon, ils devraient obtenir des JPEG.
- Lors de l'utilisation d'un navigateur sur un écran haute densité, l'utilisateur doit obtenir des images 2x. S'ils déplacent la fenêtre du navigateur sur un écran de densité standard et l'actualisent, ils devraient obtenir des images 1x.
Caches tout le long
Contrairement aux caches périphériques, qui agissent comme un gigantesque cache partagé par tous les utilisateurs, le navigateur n'est destiné qu'à un seul utilisateur, mais il possède de nombreux caches différents pour des utilisations distinctes et spécifiques :
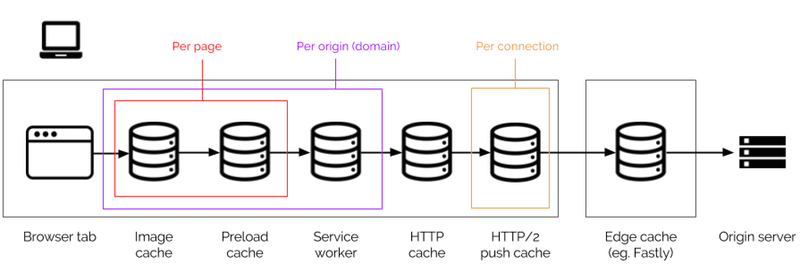
Certains d'entre eux sont assez nouveaux, et comprendre exactement à partir de quel cache le contenu est chargé est un calcul complexe qui n'est pas bien pris en charge par les outils de développement. Voici ce que font ces caches :
- cache d'images
Il s'agit d'un cache de page qui stocke les données d'image décodées, de sorte que, par exemple, si vous incluez plusieurs fois la même image sur une page, le navigateur n'a besoin de la télécharger et de la décoder qu'une seule fois. - cache de préchargement
Ceci est également limité à la page et stocke tout ce qui a été préchargé dans un en-tête deLinkou une<link rel="preload">, même si la ressource est normalement impossible à mettre en cache. Comme le cache d'images, le cache de préchargement est détruit lorsque l'utilisateur quitte la page. - API de cache de service worker
Cela fournit un arrière-plan de cache avec une interface programmable ; ainsi, rien n'est stocké ici à moins que vous ne l'y mettiez spécifiquement via du code JavaScript dans un service worker. Il ne sera également vérifié que si vous le faites explicitement dans un gestionnaire d'fetchde service worker. Le cache du service worker est limité à l'origine et, bien qu'il ne soit pas garanti qu'il soit persistant, il est plus persistant que le cache HTTP du navigateur. - Cache HTTP
C'est la cache principale que les gens connaissent le mieux. C'est le seul cache qui prête attention aux en-têtes de cache de niveau HTTP tels queCache-Control, et il les combine avec les propres règles heuristiques du navigateur pour déterminer s'il faut mettre quelque chose en cache et pour combien de temps. Il a la portée la plus large, étant partagé par tous les sites Web ; Ainsi, si deux sites Web non liés chargent le même actif (par exemple, Google Analytics), ils peuvent partager le même accès au cache. - Cache push HTTP/2 (ou "cache push H2")
Cela se trouve avec la connexion et stocke les objets qui ont été poussés depuis le serveur mais qui n'ont pas encore été demandés par une page utilisant la connexion. Il est limité aux pages utilisant une connexion particulière, ce qui revient essentiellement à être limité à une seule origine, mais il est également détruit lorsque la connexion se ferme.
Parmi ceux-ci, le cache HTTP et le cache de service worker sont les mieux définis. En ce qui concerne les caches d'image et de préchargement, certains navigateurs peuvent les implémenter comme un seul "cache mémoire" lié au rendu d'une navigation particulière, mais le modèle mental que je décris ici est toujours la bonne façon de penser au processus. Voir la note de spécification sur la preload si vous êtes intéressé. Dans le cas du push du serveur H2, la discussion sur le sort de ce cache reste active.
L'ordre dans lequel une requête vérifie ces caches avant de s'aventurer sur le réseau est important, car demander quelque chose peut le faire passer d'une couche externe de mise en cache à une couche interne. Par exemple, si votre serveur HTTP/2 pousse une feuille de style avec une page qui en a besoin, et que cette page précharge également la feuille de style avec une <link rel="preload"> , alors la feuille de style finira par toucher trois caches dans le navigateur. Tout d'abord, il restera dans le cache push H2, attendant d'être demandé. Lorsque le navigateur affiche la page et accède à la balise de preload , il extrait la feuille de style du cache push, via le cache HTTP (qui peut la stocker, en fonction de l'en-tête Cache-Control de la feuille de style), et enregistre dans le cache de préchargement.
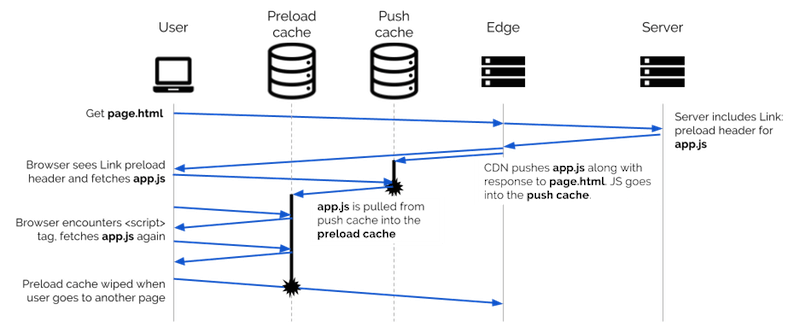
Présentation de Vary en tant que validateur
OK, alors que se passe-t-il lorsque nous prenons cette situation et ajoutons Vary au mélange ?
Contrairement aux caches intermédiaires (tels que les CDN), les navigateurs n'implémentent généralement pas la capacité de stocker plusieurs variantes par URL . La raison en est que les éléments pour lesquels nous utilisons généralement Vary (principalement Accept-Encoding et Accept-Language ) ne changent pas fréquemment dans le contexte d'un seul utilisateur. Accept-Encoding peut (mais ne change probablement pas) lors d'une mise à niveau du navigateur, et Accept-Language ne changera probablement que si vous modifiez les paramètres régionaux de langue de votre système d'exploitation. Il se trouve également qu'il est beaucoup plus facile d'implémenter Vary de cette manière, bien que certains auteurs de spécifications pensent que c'était une erreur.
Ce n'est pas une grande perte la plupart du temps pour un navigateur de ne stocker qu'une seule variante, mais il est important que nous n'utilisions pas accidentellement une variante qui n'est plus valide si les données "variées" changent.
Le compromis consiste à traiter Vary comme un validateur et non comme une clé. Les navigateurs calculent les clés de cache de la manière normale (essentiellement, en utilisant l'URL), puis s'ils obtiennent un résultat, ils vérifient que la demande satisfait toutes les règles Vary qui sont intégrées dans la réponse mise en cache. Si ce n'est pas le cas, le navigateur traite la demande comme un échec dans le cache et passe à la couche de cache suivante ou au réseau. Lorsqu'une nouvelle réponse est reçue, elle écrasera alors la version mise en cache, même s'il s'agit techniquement d'une variante différente.

Démontrer un comportement variable
Pour démontrer la façon dont Vary est géré, j'ai créé une petite suite de tests. Le test charge une gamme d'URL différentes, variant sur différents en-têtes, et détecte si la requête a atteint le cache ou non. J'utilisais à l'origine ResourceTiming pour cela, mais pour une plus grande compatibilité, j'ai fini par me contenter de mesurer le temps nécessaire à l'exécution de la requête (et j'ai intentionnellement ajouté un délai d'une seconde aux réponses côté serveur pour que la différence soit vraiment claire).
Examinons chacun des types de cache et comment Vary devrait fonctionner et si cela fonctionne réellement comme ça. Pour chaque test, je montre ici si nous devons nous attendre à voir un résultat du cache ("HIT" contre "MISS") et ce qui s'est réellement passé.
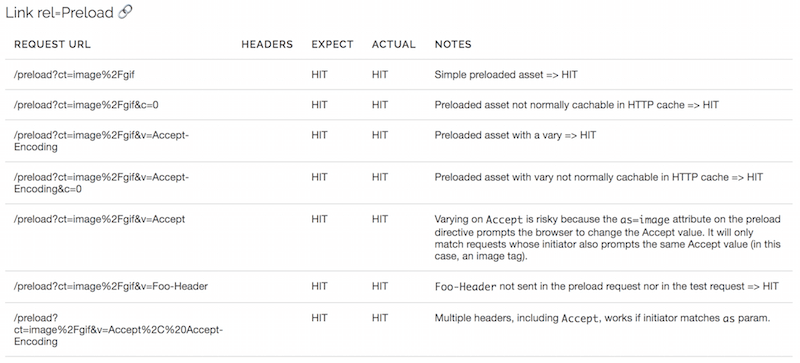
Précharge
Le préchargement n'est actuellement pris en charge que dans Chrome, où les réponses préchargées sont stockées dans un cache mémoire jusqu'à ce qu'elles soient nécessaires à la page. Les réponses remplissent également le cache HTTP sur leur chemin vers le cache de préchargement, si elles peuvent être mises en cache HTTP. Étant donné qu'il est impossible de spécifier des en-têtes de requête avec un préchargement et que le cache de préchargement ne dure que le temps de la page, il est difficile de tester cela, mais nous pouvons au moins voir que les objets avec un en-tête Vary sont préchargés avec succès :
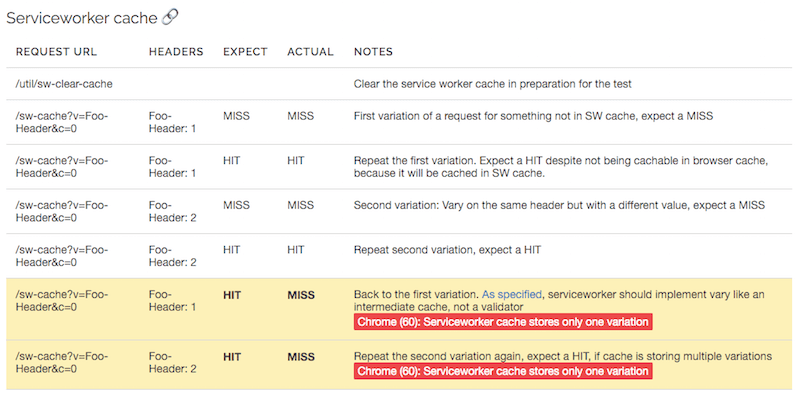
API de cache de service worker
Chrome et Firefox prennent en charge les techniciens de service, et lors du développement de la spécification du technicien de service, les auteurs voulaient corriger ce qu'ils considéraient comme des implémentations défectueuses dans les navigateurs, pour que Vary dans le navigateur fonctionne davantage comme des CDN. Cela signifie que si le navigateur ne doit stocker qu'une seule variante dans le cache HTTP, il est censé conserver plusieurs variantes dans l'API Cache. Firefox (54) le fait correctement, alors que Chrome utilise la même logique de variation en tant que validateur qu'il utilise pour le cache HTTP (le bogue est suivi).
Cache HTTP
Le cache HTTP principal doit observer Vary et le fait de manière cohérente (en tant que validateur) dans tous les navigateurs. Pour beaucoup, beaucoup plus à ce sujet, consultez le post de Mark Nottingham "State of Browser Caching, Revisited".
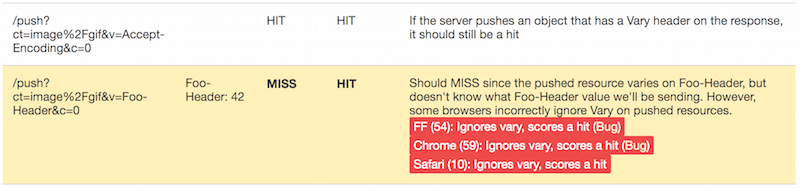
Cache de transmission HTTP/2
Vary doit être observé, mais en pratique, aucun navigateur ne le respecte réellement, et les navigateurs se feront un plaisir de faire correspondre et de consommer des réponses poussées avec des requêtes qui portent des valeurs aléatoires dans les en-têtes sur lesquels les réponses varient.
La ride « 304 (non modifiée) »
Le statut de réponse HTTP "304 (non modifié)" est fascinant. Notre "cher chef", Artur Bergman, m'a fait remarquer ce joyau dans la spécification de mise en cache HTTP (c'est moi qui souligne):
Le serveur générant une réponse 304 doit générer l'un des champs d'en-tête suivants qui auraient été envoyés dans une réponse 200 (OK) à la même requête :
Cache-Control,Content-Location,Date,ETag,ExpiresetVary.
Pourquoi une réponse 304 renverrait-elle un en-tête Vary ? L'intrigue s'épaissit lorsque vous lisez ce que vous êtes censé faire après avoir reçu une réponse 304 contenant ces en-têtes :
Si une réponse stockée est sélectionnée pour la mise à jour, le cache doit \[…] utiliser d'autres champs d'en-tête fournis dans la réponse 304 (non modifiée) pour remplacer toutes les instances des champs d'en-tête correspondants dans la réponse stockée.
Attends quoi? Donc, si l'en-tête Vary du 304 est différent de celui de l'objet en cache existant, nous sommes censés mettre à jour l'objet en cache ? Mais cela pourrait signifier qu'il ne correspond plus à la demande que nous avons faite !
Dans ce scénario, à première vue, le 304 semble vous dire simultanément que vous pouvez et ne pouvez pas utiliser la version en cache. Bien sûr, si le serveur ne voulait vraiment pas que vous utilisiez la version en cache, il aurait envoyé un 200 , pas un 304 ; ainsi, la version en cache doit certainement être utilisée - mais après y avoir appliqué les mises à jour, elle pourrait ne plus être utilisée pour une future requête identique à celle qui a effectivement rempli le cache en premier lieu.
(Remarque : Chez Fastly, nous ne respectons pas cette bizarrerie de la spécification. Ainsi, si nous recevons un 304 de votre serveur d'origine, nous continuerons à utiliser l'objet mis en cache sans modification, à part réinitialiser le TTL.)
Les navigateurs semblent respecter cela, mais avec une bizarrerie. Ils mettent à jour non seulement les en-têtes de réponse, mais aussi les en-têtes de requête qui leur sont associés, afin de garantir que, après la mise à jour, la réponse mise en cache correspond à la requête en cours. Cela semble logique. La spécification ne le mentionne pas, les éditeurs de navigateurs sont donc libres de faire ce qu'ils veulent ; heureusement, tous les navigateurs présentent ce même comportement.
Conseils aux clients
La fonctionnalité Client Hints de Google est l'une des nouveautés les plus importantes qui soient arrivées à Vary dans le navigateur depuis longtemps. Contrairement à Accept-Encoding et Accept-Language , Client Hints décrit des valeurs susceptibles de changer régulièrement lorsqu'un utilisateur se déplace sur votre site Web, en particulier les suivantes :
-
DPR
Ratio de pixels de l'appareil, la densité de pixels de l'écran (peut varier si l'utilisateur a plusieurs écrans) -
Save-Data
Si l'utilisateur a activé le mode d'économie de données -
Viewport-Width
Largeur en pixels de la fenêtre courante -
Width
Largeur de ressource souhaitée en pixels physiques
Non seulement ces valeurs peuvent changer pour un seul utilisateur, mais la plage de valeurs pour celles liées à la largeur est large. Ainsi, nous pouvons totalement utiliser Vary avec ces en-têtes, mais nous risquons de réduire l'efficacité de notre cache ou même de rendre la mise en cache inefficace.
La proposition d'en-tête clé
Les conseils client et d'autres en-têtes très granulaires se prêtent à une proposition sur laquelle Mark a travaillé, nommée Key. Regardons quelques exemples :
Key: Viewport-Width;div=50 Cela signifie que la réponse varie en fonction de la valeur de l'en-tête de requête Viewport-Width , mais arrondie au multiple de 50 pixels le plus proche !
Key: cookie;param=sessionAuth;param=flags L'ajout de cet en-tête dans une réponse signifie que nous varions sur deux cookies spécifiques : sessionAuth et flags . S'ils n'ont pas changé, nous pouvons réutiliser cette réponse pour une future requête.
Ainsi, les principales différences entre Key et Vary sont :
-
Keypermet de varier sur les sous- champs dans les en-têtes, ce qui rend soudainement possible de varier sur les cookies, car vous pouvez varier sur un seul cookie - ce serait énorme ; - les valeurs individuelles peuvent être regroupées en plages , pour augmenter les chances d'un accès au cache, particulièrement utile pour faire varier des éléments tels que la largeur de la fenêtre d'affichage.
- toutes les variantes avec la même URL doivent avoir la même clé. Ainsi, si un cache reçoit une nouvelle réponse pour une URL pour laquelle il a déjà des variantes existantes et que la valeur de l'en-tête
Keyde la nouvelle réponse ne correspond pas aux valeurs de ces variantes existantes, toutes les variantes doivent être supprimées du cache.
Au moment de la rédaction, aucun navigateur ou CDN ne prend en charge Key , bien que dans certains CDN, vous puissiez obtenir le même effet en divisant les en-têtes entrants en plusieurs en-têtes privés et en variant ceux-ci (voir notre article, "Tirer le meilleur parti de Vary With Rapidement »), les navigateurs sont donc le principal domaine où Key peut avoir un impact.
L'exigence que toutes les variantes aient la même recette clé est quelque peu limitative, et j'aimerais voir une sorte d'option de "sortie anticipée" dans la spécification. Cela vous permettrait de faire des choses comme "Varier l'état d'authentification et, si vous êtes connecté, varier également les préférences".
La proposition de variantes
Key est un bon mécanisme générique, mais certains en-têtes ont des règles plus complexes pour leurs valeurs, et comprendre la sémantique de ces valeurs peut nous aider à trouver des moyens automatisés de réduire la variation du cache. Par exemple, imaginez que deux requêtes arrivent avec des valeurs Accept-Language différentes, en-gb et en-us , mais bien que votre site Web prenne en charge les variations de langue, vous n'avez qu'un seul "anglais". Si nous répondons à la demande d'anglais américain et que cette réponse est mise en cache sur un CDN, elle ne peut pas être réutilisée pour la demande d'anglais britannique, car la valeur Accept-Language serait différente et le cache n'est pas assez intelligent pour savoir mieux .
Entrez, en grande pompe, la proposition de variantes. Cela permettrait aux serveurs de décrire les variantes qu'ils prennent en charge, permettant aux caches de prendre des décisions plus intelligentes sur les variantes réellement distinctes et celles qui sont effectivement identiques.
À l'heure actuelle, Variants est un projet très précoce, et parce qu'il est conçu pour aider avec Accept-Encoding et Accept-Language , son utilité est plutôt limitée aux caches partagés, tels que les CDN, plutôt qu'aux caches de navigateur. Mais il s'associe bien avec Key et complète l'image pour un meilleur contrôle de la variation du cache.
Conclusion
Il y a beaucoup à comprendre ici, et bien qu'il puisse être intéressant de comprendre comment le navigateur fonctionne sous le capot, il y a aussi quelques choses simples que vous pouvez en tirer :
- La plupart des navigateurs traitent
Varycomme un validateur. Si vous souhaitez que plusieurs variantes distinctes soient mises en cache, trouvez un moyen d'utiliser différentes URL à la place. - Les navigateurs ignorent
Varypour les ressources poussées à l'aide de la poussée du serveur HTTP/2, donc ne variez pas sur tout ce que vous poussez. - Les navigateurs ont une tonne de caches, et ils fonctionnent de différentes manières. Il vaut la peine d'essayer de comprendre l'impact de vos décisions de mise en cache sur les performances de chacun, en particulier dans le contexte de
Vary. -
Varyn'est pas aussi utile qu'il pourrait l'être, etKeyjumelé avec Client Hints commence à changer cela. Suivez le support du navigateur pour savoir quand vous pouvez commencer à les utiliser.
Allez de l'avant et soyez variable.