
Arbres dans la structure des données : 8 types d'arbres que tout scientifique de données devrait connaître
Publié: 2021-05-26Table des matières
introduction
Dans le domaine informatique, les structures de données font référence au modèle d'arrangement des données sur un disque, ce qui permet un stockage et un affichage pratiques. Ils appartiennent au domaine de la science des données, qui devrait être un choix de carrière lucratif en 2021. Sur la base des prévisions pour les prochaines années, des modèles d'apprentissage en profondeur à grande échelle et des appareils intelligents de nouvelle génération ouvriront l'avenir de ce secteur.
Ainsi, l'obtention de la connaissance des structures de données serait essentielle pour trouver une carrière appropriée au milieu des progrès technologiques. Selon les prévisions de l'industrie de la science des données de 2021, les États-Unis et l'Inde emploieraient environ 50 000 scientifiques des données et 300 000 analystes de données au sein de leurs plus de 2 50 000 entreprises. [1]
Les structures de données sont appliquées pour concevoir les voies d'attribution, de gestion et de récupération des informations. Les structures de données sont particulièrement nécessaires pour rédiger et améliorer l'efficacité de l'ensemble des données traitées. Ils gèrent les données en les regroupant et en les organisant pour faciliter efficacement l'échange d'informations.
Arbres dans les structures de données
Les « arbres » sont un type d'ADT (types de données abstraits), qui suivent un modèle hiérarchique pour leur allocation de données. Essentiellement, un arbre est une collection de plusieurs nœuds connectés par des arêtes. Ces « arbres » forment une conception de structure de données qui ressemble à un arbre, où le nœud « racine » mène aux nœuds « parents », qui mènent éventuellement aux nœuds « enfants ». Les connexions sont faites avec des lignes appelées 'arêtes'.
Les nœuds "feuilles" sont des points de terminaison sans autres nœuds enfants provenant d'eux. Les arbres dans les structures de données jouent un rôle vital en raison de la nature non linéaire de leur disposition. Cela permet un temps de réponse plus rapide lors d'une recherche, ainsi qu'une commodité tout au long des étapes de conception.
Types d'arbres dans la structure de données
Les différents types d' arbres dans les structures de données sont expliqués en détail ci-dessous :
1. Arbre général
Un arbre général est caractérisé par l'absence de toute spécification ou contrainte sur le nombre d'enfants qu'un nœud peut avoir. Tout arbre avec une structure hiérarchique peut être classé comme un arbre général. Un nœud peut avoir plusieurs enfants, et il peut y avoir n'importe quelle sorte de combinaison pour l'orientation de l'arbre. Les nœuds peuvent être de n'importe quel degré, de 0 à n.
Voici un exemple classique d'arborescence générale dans la structure de données, avec '2' en haut étant le nœud racine.
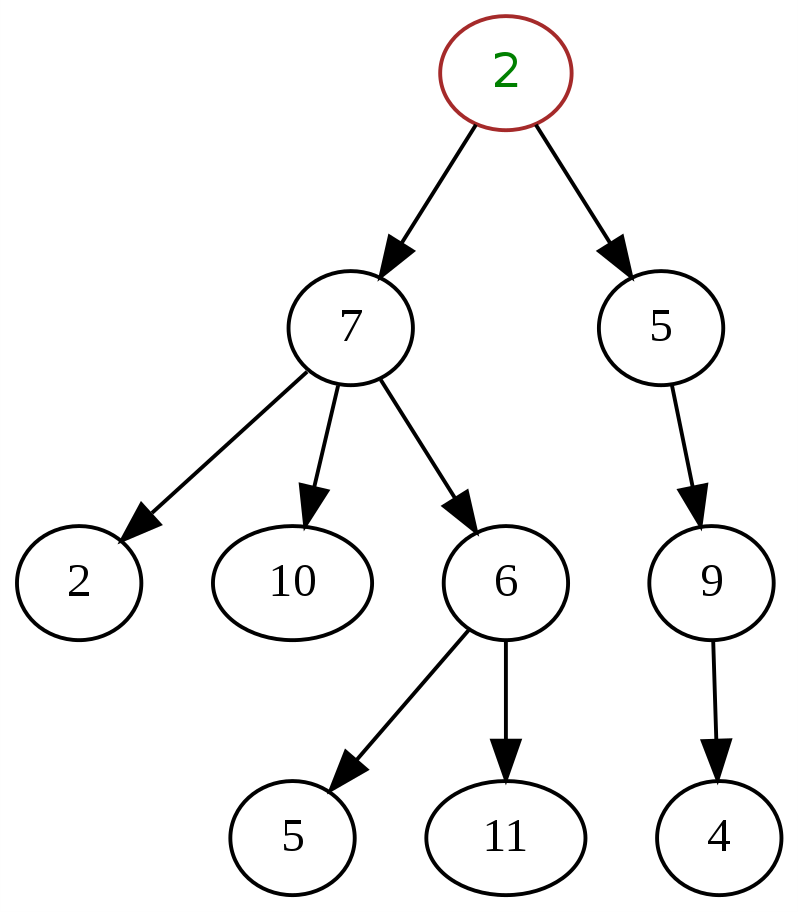
La source
2. Arbre binaire
Tel que défini par le mot "binaire", qui signifie deux nombres, un arbre binaire se compose de nœuds pouvant avoir 2 nœuds enfants. Tout nœud dans un arbre binaire peut avoir 0, 1 ou 2 nœuds au maximum. Les arbres binaires dans les structures de données sont des ADT hautement fonctionnels et peuvent être subdivisés en plusieurs types. Ils sont principalement utilisés dans les structures de données à deux fins :
- Pour accéder aux nœuds et les étiqueter, comme observé dans les arbres de recherche binaires.
- Pour la représentation des données à travers une structure bifurquante.
Voici un schéma de base d'un arbre binaire dans une structure de données :
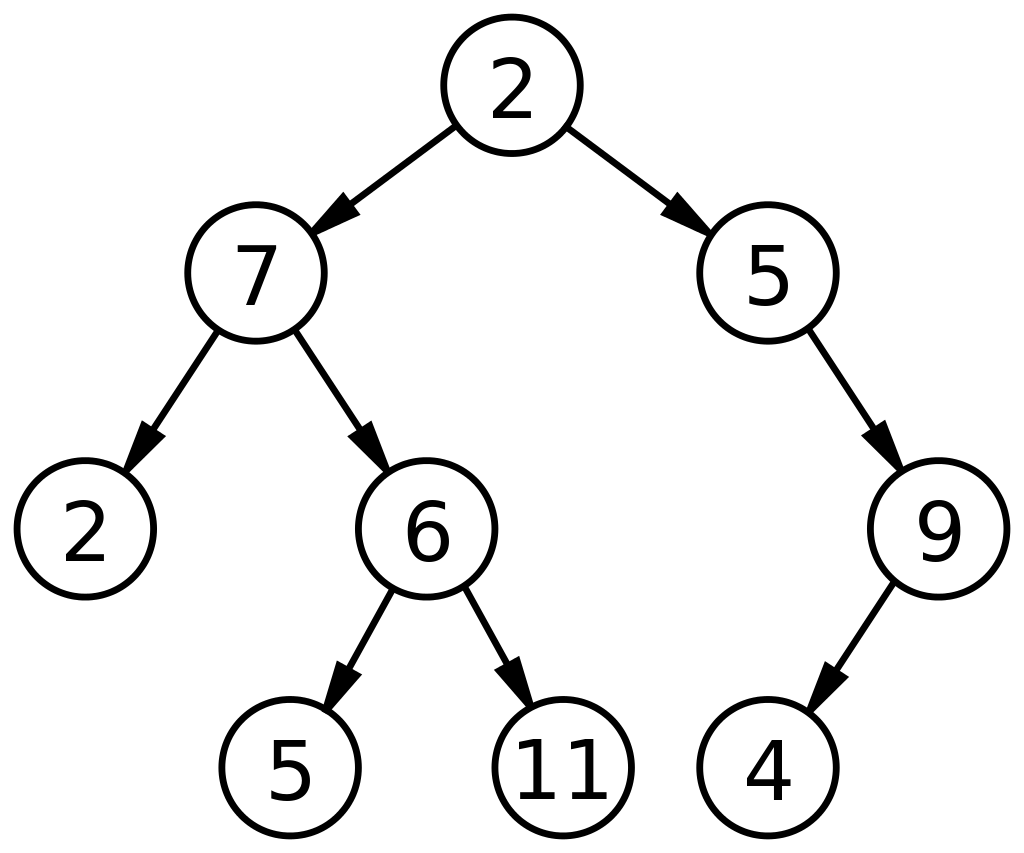
La source
3. Arbre de recherche binaire
Un arbre de recherche binaire (BST) est un sous-type unique d'arbres binaires qui sont disposés de manière à faciliter une recherche/recherche ou un ajout/suppression de données plus rapide. Un BST est défini par la représentation des nœuds basée sur trois champs : les données, son enfant gauche et son enfant droit. Les facteurs déterminants pour la BST sont :
- Chaque nœud du côté gauche (enfant gauche) doit contenir une valeur inférieure à son nœud parent.
- Chaque nœud du côté droit (enfant droit) doit contenir une valeur supérieure à son nœud parent.
Un tel agencement réduit les temps de recherche à la moitié d'une recherche linéaire, comme on le trouve dans un réseau. Ainsi, les arbres de recherche binaires dans les structures de données sont largement applicables pour la recherche et le tri par rapport aux autres ADT.
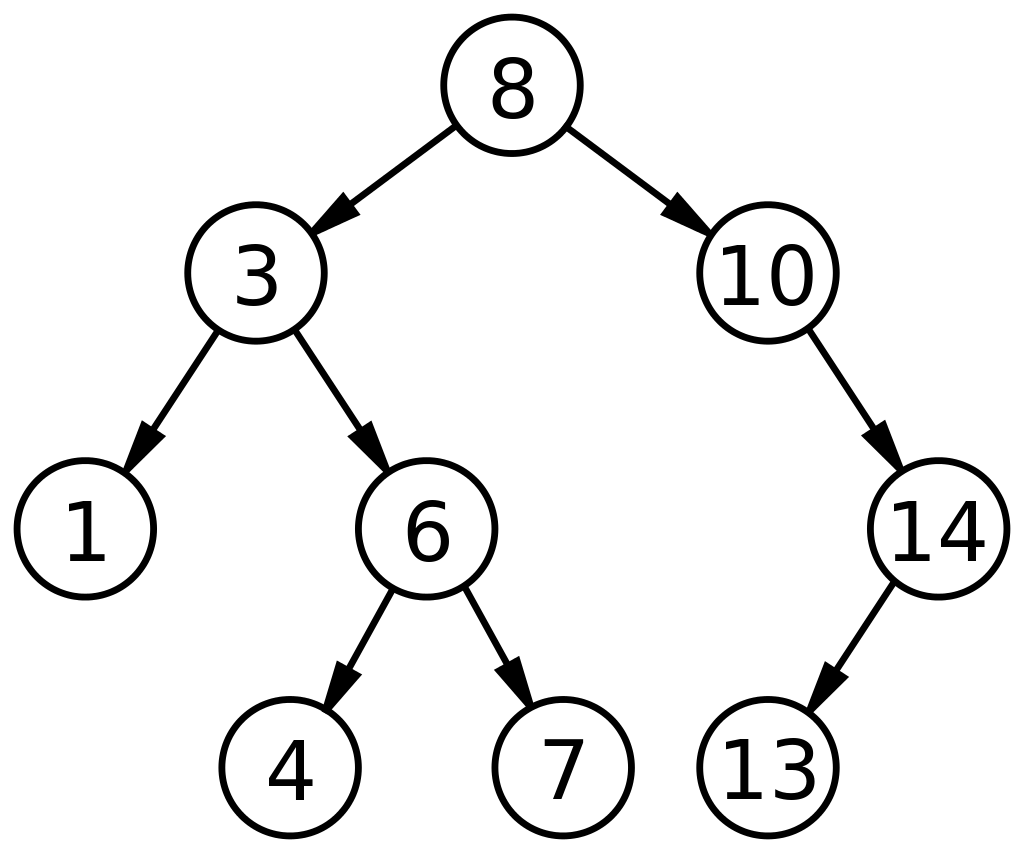
La source
Même si les BT et les BST sont essentiellement des arbres dans les structures de données , ne vous trompez pas par la similitude de leurs noms. Découvrez en détail la différence entre un arbre binaire et un arbre de recherche binaire sur upGrad.
4. Arbre AVL
L'arbre AVL tire son nom de ses inventeurs : Adelson-Velsky et Landis. L'arbre AVL se caractérise par une nature auto-équilibrée. Les hauteurs de deux sous-arbres de ses nœuds racine sont limitées à moins de deux. Lorsque la différence de hauteur dépasse 1, les nœuds enfants sont rééquilibrés.
Les arbres AVL sont équilibrés en hauteur, et ce rééquilibrage se produit par des rotations simples ou doubles. Le facteur d'équilibrage est la différence entre les hauteurs du sous-arbre gauche et du sous-arbre droit, et les valeurs sont -1, 0 et 1.
5. Arbre noir rouge
Ce type ressemble aux arbres AVL puisque les arbres noirs rouges sont également équilibrés en hauteur. Ce qui les sépare, c'est qu'il ne faut pas plus de deux rotations pour les équilibrer. Ils contiennent un bit supplémentaire qui définit la couleur rouge ou noire d'un nœud, ce qui garantit que les arbres sont équilibrés lors des suppressions et des insertions. Le codage couleur rouge noir est également repeint lors des changements mais sans surcoût de mémoire ou presque.

6. Arbre étalé
Un autre sous-type de l'arbre de recherche binaire, l'arbre étalé, a une propriété unique d'effectuer des opérations de rotation pour ajuster le nœud récent. Le nœud auquel on a accédé récemment est organisé en nœud racine en effectuant une rotation. C'est un arbre équilibré, mais pas équilibré en hauteur.
L'action de « splaying » est effectuée après la recherche initiale de l'arbre binaire, car les rotations d'arbres sont effectuées d'une manière spécifique. Après chaque opération, l'arbre est tourné pour s'équilibrer et l'élément recherché est disposé en haut en tant que nœud racine.
7. Treap
Les « treaps » dans les structures de données sont une combinaison d'arbres et de tas. Dans les BST, la valeur de l'enfant gauche doit être inférieure à celle du nœud racine et la valeur de l'enfant droit doit être supérieure. Dans une structure de données en tas, le nœud racine a la valeur la plus faible et ses nœuds enfants (à gauche et à droite) ont des valeurs plus élevées.
Ainsi, un treap contient une valeur sous la forme d'une clé (ressemblant à des BST) et une priorité (comme des tas). Les nœuds de priorité la plus élevée sont insérés en premier dans un arbre de recherche binaire de manière à ce que les numéros de priorité soient des nombres aléatoires indépendants. Ils maintiennent un ensemble dynamique de clés ordonnées et permettent des recherches binaires dans leurs clés.
8. Arbre B
En tant que type d'arbre auto-équilibré dans les structures de données, B-Tree trie les données pour permettre la recherche, l'accès séquentiel, les suppressions et les insertions en temps logarithmique. Contrairement à un arbre binaire, un arbre B permet à ses nœuds d'avoir plus de deux enfants. Ils sont compatibles avec les bases de données et les systèmes de fichiers qui lisent et écrivent des blocs de données plus volumineux.
Un arbre B dans les structures de données est utilisé pour les systèmes de stockage plus importants, tels que les disques. Toutes les feuilles ne contiennent aucune information et elles apparaissent au même niveau. Les nœuds internes d'un B-tree peuvent avoir une taille variable de nœuds enfants liés par une plage.
Ce sont les arbres dans les structures de données , qui sont mis en œuvre par les programmeurs qui conçoivent le flux de données. Connaître leurs caractéristiques et leurs applications uniques est essentiel pour devenir un scientifique des données. Une autre méthode pour vous perfectionner serait de pratiquer à travers divers projets qui nécessitent la connaissance des arbres dans les structures de données et d'autres formes d'ADT.
Pour appliquer vos connaissances aux projets DS, les liens de blog suivants contiennent 13 idées de projets de structure de données intéressantes et des sujets pour les débutants [2021] .
Conclusion
Apprendre des concepts tels que les arbres dans une structure de données peut être délicat, et les aspirants à la programmation ont besoin de conseils d'experts pour s'éduquer. Pour en savoir plus sur les arbres dans une structure de données, consultez les cours en ligne de upGrad . Programme exécutif PG en développement de logiciels - Spécialisation en DevOps avec DevOps par IIIT-B & upGrad peut vous aider à construire votre carrière en tant que programmeur.
Comme la maîtrise des structures de données fait partie intégrante du processus de codage, elle peut aider l'étudiant à devenir un programmeur expert et un développeur de logiciels. Les programmeurs et les scientifiques des données seront forcément en demande pour les décennies à venir.
Nous avons 500 millions d'internautes en Inde, générant et consommant de grandes quantités de données, ce qui nécessite l'emploi de milliers de data scientists pour répondre à la demande. [2] Ces spécialistes des données ont besoin d'une formation adéquate, avec une expertise technologique pertinente, pour chercher un emploi dans ce secteur.
Un programme exécutif PG en développement de logiciels - Spécialisation en développement Full Stack , organisé par upGrad & IIIT-Bangalore, peut vous aider à améliorer votre profil et à obtenir de meilleures opportunités d'emploi en tant que programmeur.
- Un arbre de recherche est une structure de données utilisée pour localiser certaines clés dans un ensemble de données. La clé de chaque nœud doit être supérieure à toutes les clés des sous-arbres à gauche mais inférieure aux clés des sous-arbres juste à droite pour qu'un arbre agisse comme un arbre de recherche. Les données hiérarchiques, telles que la structure des dossiers, la structure organisationnelle et les données XML/HTML, doivent être stockées dans des arborescences. Un arbre binaire parfait est un arbre dans lequel chaque nœud intérieur a deux descendants et chaque feuille a la même profondeur ou le même niveau. Le tableau d'ascendance (non incestueux) d'une personne à une profondeur particulière est un exemple d'arbre binaire parfait, car chaque personne a précisément deux parents biologiques (une mère et un père).Quel type d'arbres peut être utilisé pour la recherche ?<br />
- Lorsque l'arbre est assez équilibré, c'est-à-dire que les feuilles aux deux extrémités sont de profondeurs équivalentes, les arbres de recherche ont un avantage en termes de temps de recherche. Il existe une variété de structures de données d'arborescence de recherche, dont certaines permettent en outre une insertion et une suppression efficaces d'éléments, lesquelles actions doivent ensuite préserver l'équilibre de l'arborescence.
- Un tableau associatif est fréquemment implémenté à l'aide d'arbres de recherche. L'algorithme d'arbre de recherche localise un emplacement à l'aide de la clé de la paire clé-valeur, puis l'application stocke la paire clé-valeur complète à cet emplacement.
- Les arbres de recherche binaires, les arbres B, les arbres (a,b) et les arbres de recherche ternaires sont des exemples d'arbres de recherche. Quelles sont les principales applications de la structure de données arborescente ?
1. Un arbre de recherche binaire est un arbre qui vous permet de rechercher, d'insérer et de supprimer rapidement des données qui ont été triées. Il vous aide également à localiser l'élément le plus proche de vous.
2. Heap est une structure de données arborescente qui utilise des tableaux et est utilisée pour construire des files d'attente prioritaires.
3. B-Tree et B+ Tree sont deux types d'arbres d'indexation utilisés dans les bases de données.
4. Les compilateurs utilisent l'arbre de syntaxe.
5. Un arbre de partitionnement d'espace utilisé pour organiser des points dans un espace de dimension K est connu sous le nom d'arbre KD.
6. Trie est une structure de données utilisée pour construire des dictionnaires ayant une recherche de préfixe.
7. Suffix Tree est utilisé pour rechercher rapidement des modèles dans un texte fixe.
8. Dans les réseaux informatiques, les routeurs et les ponts utilisent respectivement des arbres couvrants ainsi que des arbres de chemin le plus court. Qu'est-ce qu'un arbre parfait ?