
Top 15 des questions et réponses des entretiens Hadoop en 2022
Publié: 2021-01-09Avec l'essor de l'analyse des données, il y a eu une augmentation de la demande de personnes capables de gérer le Big Data. Des analystes de données aux scientifiques des données, le Big Data crée aujourd'hui un éventail de profils d'emploi. La première et la plus importante chose avec laquelle vous êtes censé être pratique est Hadoop.
Quel que soit votre rôle/profil, vous travaillerez probablement sur Hadoop d'une manière ou d'une autre. Ainsi, vous pouvez toujours vous attendre à ce que les enquêteurs posent quelques questions Hadoop à votre façon.
Pour cela et plus encore, examinons les 15 principales questions d'entretien Hadoop auxquelles vous pouvez vous attendre dans tout entretien auquel vous vous présentez.
Qu'est-ce qu'Hadoop ? Quels sont les principaux composants Hadoop ?
Hadoop est une infrastructure équipée d'outils et de services pertinents nécessaires au traitement et au stockage du Big Data. Pour être précis, Hadoop est la "solution" à tous les défis du Big Data. De plus, le framework Hadoop aide également les organisations à analyser le Big Data et à prendre de meilleures décisions commerciales.
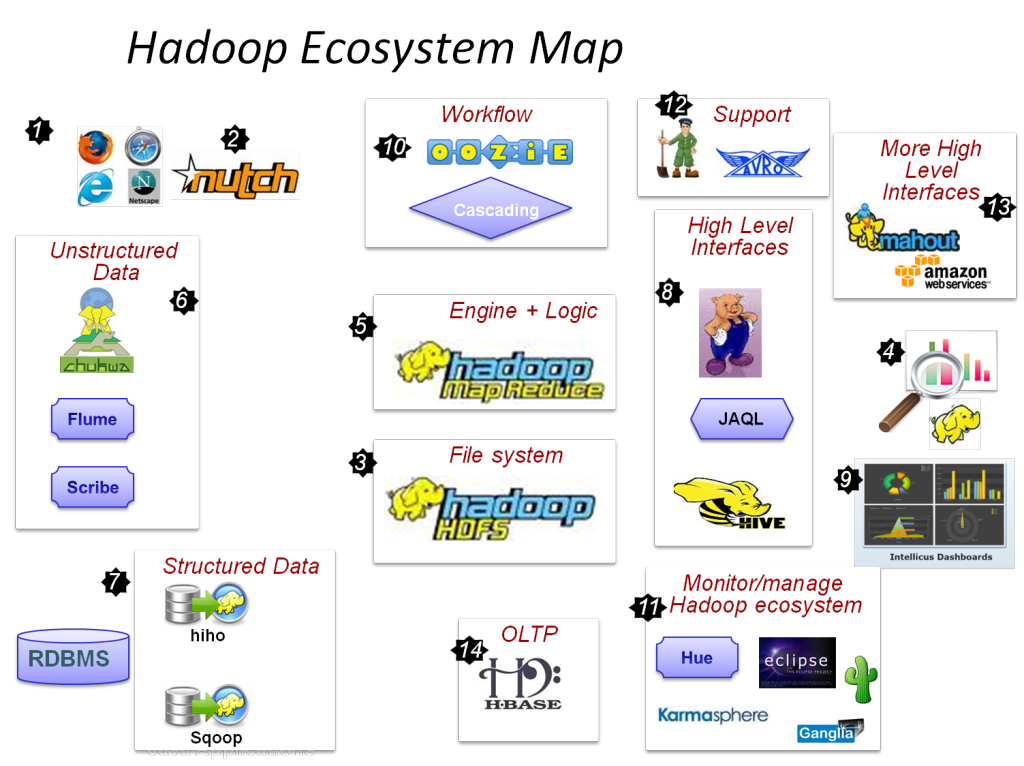
Les principaux composants de Hadoop sont :
- HDFS
- Hadoop MapReduce
- Commun Hadoop
- FIL
- PIG et HIVE - Les composants d'accès aux données.
- HBase – Pour le stockage de données
- Ambari, Oozie et ZooKeeper – Composant de gestion et de surveillance des données
- Thrift et Avro – Composants de sérialisation des données
- Apache Flume, Sqoop, Chukwa - Les composants d'intégration de données
- Apache Mahout et Drill - Composants d'intelligence de données
Quels sont les concepts de base du framework Hadoop ?
Hadoop est fondamentalement basé sur deux concepts de base. Elles sont:
- HDFS : HDFS ou Hadoop Distributed File System est un système de fichiers fiable basé sur Java utilisé pour stocker de vastes ensembles de données au format bloc. L'architecture maître-esclave l'alimente.
- MapReduce : MapReduce est une structure de programmation qui permet de traiter de grands ensembles de données. Cette fonction est en outre décomposée en deux parties - tandis que "map" sépare les ensembles de données en tuples, "reduce" utilise les tuples de carte et crée une combinaison de plus petits morceaux de tuples.
Nommez les formats d'entrée les plus courants dans Hadoop ?
Il existe trois formats d'entrée courants dans Hadoop :
- Format d'entrée de texte : il s'agit du format d'entrée par défaut dans Hadoop.
- Format d'entrée de fichier de séquence : Ce format d'entrée est utilisé pour lire les fichiers en séquence.
- Format d'entrée de valeur clé : celui-ci est utilisé pour lire des fichiers en texte brut.
Qu'est-ce que le FIL ?
YARN est l'abréviation de Yet Another Resource Negotiator. C'est le cadre de traitement des données de Hadoop qui gère les ressources de données et crée un environnement pour un traitement réussi. 
Qu'est-ce que la "Rack Awareness" ?
"Rack Awareness" est un algorithme que NameNode utilise pour déterminer le modèle dans lequel les blocs de données et leurs répliques sont stockés dans le cluster Hadoop. Ceci est réalisé à l'aide de définitions de rack qui réduisent la congestion entre les nœuds de données contenus dans le même rack.

Que sont les NameNodes actifs et passifs ?
Un système Hadoop à haute disponibilité contient généralement deux NameNodes : Active NameNode et Passive NameNode.
Le NameNode qui exécute le cluster Hadoop est appelé Active NameNode et le NameNode de secours qui stocke les données de l'Active NameNode est le Passive NameNode.
Le but d'avoir deux NameNodes est que si le NameNode actif tombe en panne, le NameNode passif peut prendre la tête. Ainsi, le NameNode est toujours en cours d'exécution dans le cluster et le système ne tombe jamais en panne.
Quels sont les différents ordonnanceurs du framework Hadoop ?
Il existe trois planificateurs différents dans le framework Hadoop :
- COSHH - COSHH aide à planifier les décisions en examinant le cluster et la charge de travail combinés à l'hétérogénéité.
- Planificateur FIFO - FIFO aligne les travaux dans une file d'attente en fonction de leur heure d'arrivée, sans utiliser l'hétérogénéité.
- Partage équitable - Le partage équitable crée un pool pour les utilisateurs individuels contenant plusieurs cartes et réduit les emplacements sur une ressource qu'ils peuvent utiliser pour exécuter des tâches spécifiques.
Qu'est-ce que l'exécution spéculative ?
Souvent, dans le framework Hadoop, certains nœuds peuvent fonctionner plus lentement que les autres. Cela a tendance à limiter l'ensemble du programme. Pour surmonter cela, Hadoop détecte ou « spécule » d'abord lorsqu'une tâche s'exécute plus lentement que d'habitude, puis il lance une sauvegarde équivalente pour cette tâche. Ainsi, dans le processus, le nœud maître exécute les deux tâches simultanément et celle qui est terminée en premier est acceptée tandis que l'autre est tuée. Cette fonctionnalité de sauvegarde de Hadoop est connue sous le nom d'exécution spéculative.

Nommez les principaux composants d'Apache HBase ?
Apache HBase est composé de trois composants :
- Serveur de région : une fois qu'une table est divisée en plusieurs régions, les clusters de ces régions sont transmis aux clients via le serveur de région.
- HMaster : Il s'agit d'un outil qui permet de gérer et de coordonner le serveur Région.
- ZooKeeper : ZooKeeper est un coordinateur au sein de l'environnement distribué HBase. Il aide à maintenir un état de serveur à l'intérieur du cluster grâce à la communication dans les sessions.
Qu'est-ce que le "point de contrôle" ? Quel est son avantage ?
Le point de contrôle fait référence à la procédure par laquelle une FsImage et un journal d'édition sont combinés pour former une nouvelle FsImage. Ainsi, au lieu de rejouer le journal d'édition, le NameNode peut directement charger l'état final en mémoire à partir du FsImage. Le NameNode secondaire est responsable de ce processus.
L'avantage qu'offre Checkpointing est qu'il minimise le temps de démarrage du NameNode, rendant ainsi l'ensemble du processus plus efficace.
Applications Big Data dans la culture pop
Comment déboguer un code Hadoop ?
Pour déboguer un code Hadoop, vous devez d'abord vérifier la liste des tâches MapReduce en cours d'exécution. Ensuite, vous devez vérifier si des tâches orphelines sont en cours d'exécution simultanément. Si tel est le cas, vous devez trouver l'emplacement des journaux de Resource Manager en suivant ces étapes simples :
Exécutez « ps –ef | grep –I ResourceManager » et dans le résultat affiché, essayez de trouver s'il y a une erreur liée à un identifiant de travail spécifique.
Maintenant, identifiez le noeud worker qui a été utilisé pour exécuter la tâche. Connectez-vous au nœud et exécutez « ps –ef | grep –iNodeManager.
Enfin, examinez le journal Node Manager. La plupart des erreurs sont générées à partir des journaux de niveau utilisateur pour chaque tâche de réduction de carte.
Quel est le but de RecordReader dans Hadoop ?
Hadoop décompose les données en formats de blocs. RecordReader permet d'intégrer ces blocs de données dans un seul enregistrement lisible. Par exemple, si les données d'entrée sont divisées en deux blocs -
Rangée 1 – Bienvenue à
Rangée 2 - UpGrad
RecordReader lira cela comme "Bienvenue dans UpG rad".
Quels sont les modes dans lesquels Hadoop peut fonctionner ?
Les modes dans lesquels Hadoop peut fonctionner sont :
- Mode autonome - Il s'agit d'un mode par défaut de Hadoop utilisé à des fins de débogage. Il ne prend pas en charge HDFS.
- Mode pseudo-distribué – Ce mode nécessitait la configuration des fichiers mapred-site.xml, core-site.xml et hdfs-site.xml. Les nœuds maître et esclave sont les mêmes ici.
- Mode entièrement distribué – Le mode entièrement distribué est l'étape de production de Hadoop dans laquelle les données sont distribuées sur différents nœuds d'un cluster Hadoop. Ici, les nœuds maître et esclave sont attribués séparément.
Nommez quelques applications pratiques de Hadoop.
Voici quelques exemples concrets où Hadoop fait la différence :
- Gestion du trafic routier
- Détection et prévention des fraudes
- Analysez les données clients en temps réel pour améliorer le service client
- Accéder aux données médicales non structurées des médecins, professionnels de la santé, etc., pour améliorer les services de santé.
Quels sont les outils Hadoop vitaux qui peuvent améliorer les performances du Big Data ?
Les outils Hadoop qui améliorent considérablement les performances du Big Data sont

• Ruche
• HDFS
• HBase
•SQL
• NoSQL
• Oozie
• Des nuages
• Avro
• Canal
• ZooKeeper
Ingénieurs Big Data : Mythes contre réalités
Conclusion
Ces questions d'entretien Hadoop devraient vous être d'une grande aide lors de votre prochain entretien. Bien que les enquêteurs aient parfois tendance à déformer certaines questions d'entretien Hadoop, cela ne devrait pas être un problème pour vous si vous avez trié vos bases.
Si vous souhaitez en savoir plus sur le Big Data, consultez notre programme PG Diploma in Software Development Specialization in Big Data qui est conçu pour les professionnels en activité et fournit plus de 7 études de cas et projets, couvre 14 langages et outils de programmation, pratique pratique ateliers, plus de 400 heures d'apprentissage rigoureux et d'aide au placement dans les meilleures entreprises.