
Réflexions sur Markdown
Publié: 2022-03-10Markdown est une seconde nature pour beaucoup d'entre nous. Avec le recul, je me souviens avoir commencé à taper dans Markdown peu de temps après que John Gruber ait publié son premier analyseur basé sur Perl en 2004 après avoir collaboré sur le langage avec Aaron Swartz.
La syntaxe de Markdown est destinée à un seul but : être utilisée comme format d'écriture pour le Web.
—John Gruber
C'était il y a presque 20 ans - beurk ! Ce qui a commencé comme une syntaxe HTML plus conviviale pour l'écrivain et le lecteur est devenu un chouchou pour la façon d'écrire et de stocker de la prose technique pour les programmeurs et les personnes averties en technologie.
Markdown est un signifiant pour la culture des développeurs et des bricoleurs de texte. Mais depuis son introduction, le monde du contenu numérique a également changé. Bien que Markdown soit toujours bon pour certaines choses, je ne pense pas que cela devrait plus être la référence pour le contenu.
Il y a deux raisons principales pour cela:
- Markdown n'a pas été conçu pour répondre aux besoins de contenu d'aujourd'hui.
- Markdown retient l'expérience éditoriale.
Bien sûr, cette position est influencée par le fait de travailler pour une plateforme de contenu structuré. Chez Sanity.io, nous passons la plupart de nos journées à réfléchir à la façon dont le contenu en tant que données libère beaucoup de valeur, et nous passons beaucoup de temps à réfléchir profondément sur les expériences des éditeurs, et comment faire gagner du temps aux gens et rendre le travail avec le contenu numérique agréable. . Donc, il y a de la peau dans le jeu, mais j'espère pouvoir dépeindre cela même si je vais m'opposer à Markdown comme format de choix pour le contenu, j'ai toujours une profonde appréciation de son importance, de son application et de son héritage.
Avant mon poste actuel, je travaillais comme consultant en technologie dans une agence où nous devions littéralement lutter contre les CMS qui bloquaient le contenu de nos clients en l'intégrant dans des modèles de présentation et de données complexes (oui, même ceux open source). J'ai observé des gens aux prises avec la syntaxe Markdown et être démotivés dans leur travail d'éditeurs et de créateurs de contenu. Nous avons passé des heures (et l'argent du client) à créer des rendus de balises personnalisés qui n'ont jamais été utilisés parce que les gens n'ont ni le temps ni la motivation pour utiliser la syntaxe. Même moi, lorsque j'étais très motivé, j'ai renoncé à contribuer à la documentation open source parce que l'implémentation de Markdown basée sur les composants introduisait trop de frictions.
Mais je vois aussi le revers de la médaille. Markdown est livré avec un écosystème impressionnant et du point de vue d'un développeur, il existe une simplicité élégante pour les fichiers en texte brut et une syntaxe facile à analyser pour les personnes habituées à lire du code. Une fois, j'ai passé des jours à construire un impressionnant MultiMarkdown -> LaTeX -> real-time-PDF-preview-pipeline dans Sublime Text pour mes écrits universitaires. Et il est logique qu'un fichier README.md puisse être ouvert et modifié dans un éditeur de code et bien rendu sur GitHub. Il ne fait aucun doute que Markdown apporte de la commodité aux développeurs dans certains cas d'utilisation.
C'est aussi pourquoi je veux construire mon avis contre Markdown en revenant sur la raison pour laquelle il a été introduit en premier lieu, et en passant en revue certains des développements majeurs du contenu sur le Web. Pour beaucoup d'entre nous, je soupçonne que Markdown est quelque chose que nous tenons pour acquis comme une "chose qui existe". Mais toute technologie a une histoire et est le produit de l'interaction humaine. Il est important de s'en souvenir lorsque vous, le lecteur, développez une technologie que d'autres pourront utiliser.
Saveurs et spécifications
Markdown a été conçu pour permettre aux rédacteurs Web de travailler plus facilement avec des articles à une époque où la publication Web nécessitait l'écriture de code HTML. Ainsi, l'intention était de simplifier l'interface avec le formatage de texte en HTML. Ce n'était pas la première syntaxe simplifiée sur la planète, mais c'est celle qui a gagné le plus de terrain au fil des ans. Aujourd'hui, l'utilisation de Markdown s'est développée bien au-delà de son intention de conception d'être un moyen plus simple de lire et d'écrire du HTML, pour devenir une approche de balisage de texte brut dans de nombreux contextes différents. Bien sûr, les technologies et les idées peuvent évoluer au-delà de leur intention, mais la tension dans l'utilisation actuelle de Markdown peut être attribuée à cette origine et aux contraintes mises dans sa conception.
Pour ceux qui ne connaissent pas la syntaxe, prenez le contenu HTML suivant :
<p>The <a href=”https://daringfireball.net/projects/markdown/syntax#philosophy”>Markdown syntax</a> is designed to be <em>easy-to-read</em> and <em>easy-to.write</em>.</p>Avec Markdown, vous pouvez exprimer le même formatage que :
The [Markdown syntax](https://daringfireball.net/projects/markdown/syntax#philosophy) is designed to be _easy-to-read_ and _easy-to-write_.C'est comme une loi de la nature que l'adoption de la technologie s'accompagne de la pression d'évoluer et d'y ajouter des fonctionnalités. La popularité croissante de Markdown signifiait que les gens voulaient l'adapter à leurs cas d'utilisation. Ils voulaient plus de fonctionnalités comme la prise en charge des notes de bas de page et des tableaux. L'implémentation d'origine était accompagnée d'une position opiniâtre, qui à l'époque était raisonnable compte tenu de l'intention de conception :
Pour tout balisage qui n'est pas couvert par la syntaxe de Markdown, vous utilisez simplement HTML lui-même. Il n'est pas nécessaire de le préfacer ou de le délimiter pour indiquer que vous passez de Markdown à HTML ; vous utilisez simplement les balises.
—John Gruber
En d'autres termes, si vous voulez une table, utilisez <table></table> . Vous constaterez que c'est toujours le cas pour l'implémentation d'origine. L'un des successeurs spirituels de Markdown, MDX, a repris le même principe mais l'a étendu à JSX, un langage de template basé sur JS.
De Markdown à Markdown ?
Il peut sembler que l'attrait de Markdown pour beaucoup n'était pas tant son lien avec HTML, mais l'ergonomie du texte en clair et la syntaxe simple pour le formatage. Certains créateurs de contenu souhaitaient utiliser Markdown pour d'autres cas d'utilisation que de simples articles sur le web. Des implémentations telles que MultiMarkdown ont introduit des affordances pour les rédacteurs universitaires qui souhaitaient utiliser des fichiers en texte brut mais avaient besoin de plus de fonctionnalités. Bientôt, vous auriez une gamme d'applications d'écriture acceptant la syntaxe Markdown, sans nécessairement la transformer en HTML ou même utiliser la syntaxe Markdown comme format de stockage.
Dans de nombreuses applications, vous trouverez des éditeurs qui vous offrent un ensemble limité d'options de formatage, et certains d'entre eux sont plus "inspirés" de la syntaxe d'origine. En fait, l'un des commentaires que j'ai reçus sur un brouillon de cet article était qu'à présent, "Markdown" devrait être en minuscules, car il est devenu si courant, et pour le distinguer de l'implémentation d'origine. Parce que ce que nous reconnaissons comme démarque est également devenu très diversifié.
CommonMark : une tentative d'apprivoiser le Markdown
Comme la crème glacée, Markdown se décline en de nombreuses saveurs, certaines plus populaires que d'autres. Lorsque les gens ont commencé à bifurquer l'implémentation d'origine et à y ajouter des fonctionnalités, deux choses se sont produites :
- Il est devenu plus imprévisible ce que vous, en tant qu'écrivain, pouviez et ne pouviez pas faire avec Markdown.
- Les développeurs de logiciels devaient prendre des décisions sur l'implémentation à adopter pour leur logiciel. L'implémentation d'origine contenait également des incohérences qui ajoutaient des frictions pour les personnes qui souhaitaient l'utiliser par programmation.
Cela a lancé des conversations sur la formalisation de Markdown dans une spécification proprement dite. Chose à laquelle Gruber a résisté, et le fait toujours, ce qui est intéressant, car il a reconnu que les gens voulaient utiliser Markdown à des fins différentes et "aucune syntaxe ne rendrait tout le monde heureux". C'est une position intéressante étant donné que Markdown se traduit en HTML, qui est une spécification qui évolue pour répondre à différents besoins.
Même si l'implémentation originale de Markdown est couverte par une licence "de type BSD", elle indique également "Ni le nom Markdown ni les noms de ses contributeurs ne peuvent être utilisés pour approuver ou promouvoir des produits dérivés de ce logiciel sans autorisation écrite préalable spécifique. ” Nous pouvons supposer en toute sécurité que la plupart des produits qui utilisent "Markdown" dans le cadre de leurs supports marketing n'ont pas acquis cette autorisation écrite.
La tentative la plus réussie d'intégrer Markdown dans une spécification partagée est ce que l'on appelle aujourd'hui CommonMark. Il était dirigé par Jeff Atwood (connu pour avoir co-fondé Stack Overflow and Discourse) et John McFarlane (un professeur de philosophie à Berkely qui est derrière Babelmark et pandoc). Ils l'ont initialement lancé sous le nom de "Standard Markdown", mais l'ont changé en "CommonMark" après avoir reçu des critiques de Gruber. Dont la position était cohérente, l' intention de Markdown est d'être une syntaxe de création simple qui se traduit en HTML :
@davewiner Et c'est ce qui ne va pas avec CommonMark. Ils veulent faciliter les choses pour les programmeurs comme objectif principal. Ils manquent le point.
– John Gruber (@gruber) 8 septembre 2014
Je pense que cela a également marqué le point où Markdown était entré dans le domaine public. Même si CommonMark n'est pas marqué comme "Markdown" (conformément à la licence), cette spécification est reconnue et appelée "markdown". Aujourd'hui, vous trouverez CommonMark comme implémentation sous-jacente pour des logiciels tels que Discourse, GitHub, GitLab, Reddit, Qt, Stack Overflow et Swift. Des projets comme unified.js les syntaxes en les traduisant en arbres de syntaxe abstraite, s'appuient également sur CommonMark pour leur prise en charge du démarquage.
CommonMark a apporté beaucoup d'unification autour de la façon dont le démarquage est mis en œuvre et, à bien des égards, a simplifié l'intégration du support du démarquage dans les logiciels pour les programmeurs. Mais cela n'a pas apporté la même unification à la façon dont le démarquage est écrit et utilisé. Prenez GitHub Flavored Markdown (GFM). Il est basé sur CommonMark mais l'étend avec plus de fonctionnalités (telles que des tableaux, des listes de tâches et le barré). Reddit décrit son "Reddit Flavored Markdown" comme "une variante de GFM" et introduit des fonctionnalités telles que la syntaxe pour marquer les spoilers. Je pense que nous pouvons conclure en toute sécurité que le groupe derrière CommonMark et Gruber avaient raison : cela aide certainement avec des spécifications partagées, mais oui, les gens veulent utiliser Markdown pour différentes choses spécifiques.
Markdown comme raccourci de formatage
Gruber a résisté à formaliser Markdown dans une spécification partagée parce qu'il supposait que cela en ferait moins un outil pour les écrivains et plus un outil pour les programmeurs. Nous avons déjà vu que même avec l'adoption généralisée d'une spécification, nous n'obtenons pas automatiquement une syntaxe qui, de manière prévisible, fonctionne de la même manière dans différents contextes. Et les spécifications comme CommonMark, aussi populaire soit-elle, ont également un succès limité. Un exemple évident est l'implémentation de démarquage de Slack (appelée mrkdown ) qui traduit *this* en fort/gras, et non en accentuation/italique, et ne prend pas en charge la syntaxe [link](https://slack.com) , mais utilise <link|https://slack.com> à la place.
Vous constaterez également que vous pouvez utiliser une syntaxe de type Markdown pour initialiser la mise en forme dans des éditeurs de texte enrichi dans des logiciels tels que Notion, Dropbox Paper, Craft et, dans une certaine mesure, Google Docs (par exemple, un asterisk + space sur une nouvelle ligne se transformera en un liste à puces). Ce qui est pris en charge et ce qui est traduit en ce qui varie. Ainsi, vous ne pouvez pas nécessairement emporter votre mémoire musculaire avec vous dans ces applications. Pour certaines personnes, c'est bien, et ils peuvent s'adapter. Pour d'autres, il s'agit d'un papier découpé et cela les empêche d'utiliser ces fonctionnalités. Qui pose la question, pour qui Markdown a-t-il été conçu, et qui sont ses utilisateurs aujourd'hui ?
Qui sont les utilisateurs de Markdown censés être ?
Nous avons vu que la démarque existe dans une tension entre différents cas d'utilisation, publics et notions de qui sont ses utilisateurs. Ce qui a commencé comme un langage de balisage pour les rédacteurs Web maîtrisant spécifiquement HTML, est devenu un chouchou pour les types de développeurs.
En 2014, les rédacteurs Web ont commencé à s'éloigner du déplacement de fichiers via des analyseurs en Perl et FTP. Les systèmes de gestion de contenu (CMS) comme WordPress, Drupal et Moveable Type (que Gruber utilise encore, je crois) se sont progressivement développés pour devenir les outils de référence pour la publication Web. Ils offraient des affordances telles que des éditeurs de texte enrichi que les rédacteurs Web pouvaient utiliser dans leurs navigateurs.
Ces éditeurs de texte enrichi assumaient toujours HTML et Markdown comme syntaxe de texte enrichi sous-jacente, mais ils supprimaient une partie de la surcharge cognitive en ajoutant des boutons pour insérer cette syntaxe dans l'éditeur. Et de plus en plus, les écrivains n'étaient pas et n'avaient pas besoin d'être versés dans le HTML. Je parie que si vous faisiez du développement Web avec des CMS dans les années 2010, vous deviez probablement faire face à du « HTML indésirable » qui passait par ces éditeurs lorsque les gens collaient directement à partir de Word.
Aujourd'hui, je soutiendrai que les principaux utilisateurs de Markdown sont les développeurs et les personnes intéressées par le code. Ce n'est pas une coïncidence si Slack a fait du WYSIWYG le mode de saisie par défaut une fois que son logiciel a été utilisé par plus de personnes en dehors des services techniques. Et le fait qu'il s'agisse d'une décision controversée, à tel point qu'ils ont dû la ramener en option, montre à quel point l'amour pour le démarquage est profond dans la communauté des développeurs. Il n'y avait pas beaucoup de célébrations de Slack essayant de le rendre plus facile et plus accessible pour tout le monde. Et c'est le nœud du problème.
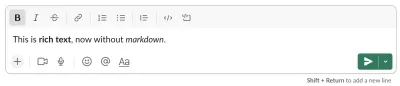
L'idéologie du Markdown
Le fait que le démarquage soit devenu le style d'écriture de la lingua franca, et ce à quoi la plupart des frameworks de sites Web s'adressent, est également la principale raison pour laquelle j'ai été un peu nerveux à l'idée de publier ceci. On en parle souvent comme d'un bien inhérent et indéniable. Markdown est devenu une caractéristique d'être convivial pour les développeurs. Des personnes intelligentes et compétentes ont consacré de nombreuses heures collectives à permettre la démarque dans toutes sortes de contextes. Alors, contester son hégémonie en agacera sûrement certains. Mais j'espère que cela peut engendrer une discussion fructueuse sur une chose qui est souvent tenue pour acquise.
Mon impression est que la convivialité pour les développeurs que les gens associent à Markdown est principalement liée à 3 facteurs :
- L'abstraction confortable d'un fichier texte brut.
- Il existe un écosystème d'outillage.
- Vous pouvez garder votre contenu proche de votre workflow de développement.
Je ne dis pas que ces positions sont fausses, mais je suggérerai qu'elles s'accompagnent de compromis et d'hypothèses déraisonnables.
Le modèle mental simple d'un fichier texte brut
Les bases de données sont des choses incroyables. Mais ils ont également la réputation méritée d'être difficiles et inaccessibles pour les développeurs frontaux. J'ai connu beaucoup de grands développeurs qui évitent le code backend et les bases de données, car ils représentent une complexité sur laquelle ils ne veulent pas passer du temps. Même avec WordPress, qui fait beaucoup de choses pour vous éviter d'avoir à gérer sa base de données après la configuration, c'était une surcharge de mise en place et de fonctionnement.
Les fichiers en texte brut, cependant, sont plus tangibles et sont assez simples à raisonner (tant que vous êtes habitué à la gestion des fichiers). Surtout par rapport à un système qui divisera votre contenu en plusieurs tables dans une base de données relationnelle avec une structure propriétaire. Pour les cas d'utilisation limités, comme les articles de blog contenant du texte enrichi simple avec des images et des liens, le démarquage fera le travail. Vous pouvez copier le fichier et le coller dans un dossier ou l'archiver dans git. Le contenu se sent le vôtre en raison de la tangibilité des fichiers. Même s'ils sont hébergés sur GitHub, qui est un logiciel en tant que service à but lucratif appartenant à Microsoft, et donc couvert par leurs conditions d'utilisation.
À l'époque où vous deviez créer une base de données locale pour lancer votre développement local et gérer sa synchronisation avec la télécommande, l'attrait des fichiers en texte brut est compréhensible. Mais cette époque est pratiquement révolue avec l'émergence des backends en tant que service. Des services et des outils tels que Fauna, Firestore, Hasura, Prisma, PlanetScale et Sanity's Content Lake investissent massivement dans l'expérience des développeurs. Même l'exploitation de bases de données traditionnelles sur le développement local est devenue moins compliquée qu'il y a à peine 10 ans.
Si vous y réfléchissez, êtes-vous moins propriétaire de votre contenu s'il est hébergé dans une base de données ? Et l'expérience des développeurs face aux bases de données n'est-elle pas devenue beaucoup plus simple avec l'avènement des outils SaaS ? Et est-il juste de dire que la technologie de base de données propriétaire empiète sur la portabilité de votre contenu ? Aujourd'hui, vous pouvez lancer ce qui est essentiellement une base de données Postgres sans compétences d'administrateur système, créer vos tables et vos colonnes, y placer votre contenu et à tout moment l'exporter sous forme de vidage .sql .
La portabilité du contenu a beaucoup plus à voir avec la façon dont vous structurez ce contenu en premier lieu. Prenez WordPress, c'est entièrement open-source, vous pouvez héberger votre propre base de données. Il a même un format d'exportation standardisé en XML. Mais quiconque a essayé de sortir d'une installation WordPress mature sait à quel point cela aide peu si vous essayez de vous éloigner de WordPress.
Un vaste écosystème… pour les développeurs
Nous avons déjà abordé le vaste écosystème de la démarque. Si vous regardez les frameworks de sites Web contemporains, la plupart d'entre eux supposent que le démarquage est le format de contenu principal, certains d'entre eux, le seul format. Par exemple, Hugo, le générateur de site statique utilisé par Smashing Magazine, nécessite toujours des fichiers de démarquage pour la publication paginée. Cela signifie que si Smashing Magazine souhaite utiliser un CMS pour stocker des articles, il doit interagir avec des fichiers de démarque ou convertir tout le contenu en fichiers de démarque. Si vous regardez dans la documentation de Next.js, Nuxt.js, VuePress, Gatsby.js, etc., le démarquage figurera en bonne place. C'est également la syntaxe par défaut pour les README sur GitHub, qui l'utilise également pour le formatage dans les notes et commentaires de la demande d'extraction.
Il y a quelques mentions honorables d'initiatives visant à apporter l'ergonomie de la démarque aux masses. Netlify CMS et TinaCMS (le descendant spirituel de Forestry) vous donneront des interfaces utilisateur où la syntaxe de démarquage est principalement abstraite pour les éditeurs. Vous constaterez généralement que les éditeurs basés sur le démarquage dans les CMS vous offrent une fonctionnalité de prévisualisation pour le formatage. Certains éditeurs, comme celui de Notion, vous permettront de coller la syntaxe Markdown, et ils la traduiront dans leur formatage natif. Mais je pense qu'il est prudent de dire que l'énergie qui a été investie pour innover pour le démarquage n'a pas favorisé les personnes qui n'aiment pas écrire sa syntaxe. Il n'a pas remonté la pile, pour ainsi dire.
Workflows de contenu ou workflows de développeur ?
Pour un développeur qui crée son blog, l'utilisation de fichiers de démarquage réduit une partie des frais généraux liés à sa mise en place et à son fonctionnement, car les frameworks sont souvent livrés avec une analyse intégrée ou l'offrent généralement dans le cadre du code de démarrage. Et il n'y a rien de plus à s'inscrire. Vous pouvez utiliser git pour valider ces fichiers avec votre code. Si vous êtes à l'aise avec les diffs git, vous aurez même un contrôle de révision comme vous en avez l'habitude avec la programmation. En d'autres termes, puisque les fichiers de démarquage sont en texte brut, ils peuvent être intégrés à votre flux de travail de développeur.

Mais au-delà de cela, l'expérience du développeur devient rapidement plus complexe. Et vous finissez par compromettre l'expérience utilisateur de votre équipe en tant que créateurs de contenu, et notre propre expérience de développeur étant bloquée par le démarquage pour résoudre des problèmes qui vont bien au-delà de son intention de conception.
Oui, cela pourrait être cool si vous demandez à votre équipe de contenu d'utiliser git et de vérifier leurs modifications, mais en même temps, est-ce la meilleure utilisation de leur temps ? Voulez-vous vraiment que vos éditeurs se heurtent aux conflits de fusion ou comment rebaser les branches ? Git est assez difficile pour les développeurs qui l'utilisent tous les jours. Et cette configuration représente-t-elle vraiment le meilleur flux de travail pour les personnes qui travaillent principalement avec du contenu ? N'est-ce pas un cas où l'expérience du développeur a pris le pas sur l'expérience de l'éditeur, et n'est-ce pas le coût, le temps et les efforts qui pourraient être nécessaires pour améliorer quelque chose pour les utilisateurs ?
Parce que les attentes et les besoins des environnements de contenu et d'édition ont évolué, je ne pense pas que le démarquage le fera pour nous. Je ne vois pas comment une partie de l'ergonomie des développeurs finit par favoriser les non-développeurs, et je pense que même pour les développeurs, le démarquage retient notre propre création de contenu et a besoin de retour. Parce que le contenu sur le Web a considérablement changé depuis le début des années 2000.
Des paragraphes aux blocs
Markdown a toujours eu la possibilité de désactiver HTML si vous vouliez des choses plus complexes. Cela fonctionnait bien lorsque l'auteur était également le webmaster, ou du moins connaissait le HTML. Cela fonctionnait également bien car les sites Web étaient généralement principalement HTML et CSS. La façon dont vous avez conçu les sites Web consistait principalement à créer des mises en page entières. Vous pouvez transformer Markdown en balisage HTML et le placer à côté de votre fichier style.css . Bien sûr, nous avions aussi des CMS et des générateurs de sites statiques dans les années 2000, mais ils fonctionnaient pour la plupart de la même manière, en insérant le contenu HTML à l'intérieur des modèles sans aucun passage de "props" entre les composants.
Mais la plupart d'entre nous ne créons plus vraiment de code HTML comme autrefois. Le contenu sur le Web a évolué, passant principalement d'articles avec un simple formatage de texte enrichi à des composants multimédias composés et spécialisés, souvent avec une interactivité de l'utilisateur (ce qui est une façon élégante de dire "appel à l'inscription à la newsletter").
Des articles aux applications
Au début des années 2010, le Web 2.0 était à son apogée et les entreprises de logiciels en tant que service ont commencé à utiliser le Web pour des applications gourmandes en données. HTML, CSS et JavaScript étaient de plus en plus utilisés pour piloter des interfaces utilisateur interactives. Bootstrap open source de Twitter, leur framework pour créer des interfaces utilisateur plus cohérentes et résilientes. Cela a conduit à ce que nous pouvons appeler la "composantisation" de la conception Web. Cela a changé la façon dont nous construisons pour le Web de manière fondamentale.
Les différents frameworks CSS qui ont émergé à cette époque (par exemple Bootstrap et Foundation) avaient tendance à utiliser des noms de classe standardisés et supposaient des structures HTML spécifiques pour rendre moins difficile la création d'interfaces utilisateur résilientes et réactives. Avec la philosophie de conception Web d'Atomic Design et les conventions de nom de classe telles que Block-Element-Modifier (BEM), la valeur par défaut est passée de penser d'abord à la mise en page, pour voir les pages comme une collection d'éléments de conception reproductibles et compatibles.
Quel que soit le contenu que vous avez à l'intérieur de Markdown n'est pas compatible avec cela. À moins que vous ne tombiez dans le trou du lapin en injectant les analyseurs de démarques et que vous l'ayez modifié pour afficher la syntaxe souhaitée (nous en reparlerons plus tard). Pas étonnant, Markdown a été conçu pour être de simples articles en texte enrichi d'éléments HTML natifs que vous cibleriez avec une feuille de style.
C'est toujours un problème pour les personnes qui utilisent Markdown pour générer du contenu pour leurs sites.
Le Web intégrable
Mais quelque chose est également arrivé à notre contenu. Non seulement avons-nous pu commencer à le trouver en dehors des balises HTML sémantiques <article> , mais il a commencé à contenir plus… de choses. Une grande partie de notre contenu est passée de nos LiveJournals et de nos blogs aux médias sociaux : Facebook, Twitter, tumblr, YouTube. Pour réintégrer les extraits de contenu dans nos articles, nous devions pouvoir les intégrer. La convention HTML a commencé à utiliser la <iframe> pour canaliser le lecteur vidéo de YouTube ou même insérer une boîte de tweet entre vos paragraphes de texte. Certains systèmes ont commencé à résumer cela en "codes courts", le plus souvent des parenthèses contenant un mot-clé pour identifier le bloc de contenu qu'il doit représenter, et certains attributs de valeur-clé. Par exemple, dev.to a permis d'insérer la syntaxe du langage de template liquid dans son éditeur Markdown :
{% youtube dQw4w9WgXcQ %}Bien sûr, cela nécessite que vous utilisiez un analyseur Markdown personnalisé et que vous ayez une logique spéciale pour vous assurer que le bon HTML a été inséré lorsque la syntaxe a été transformée en HTML. Et vos créateurs de contenu devront se souvenir de ces codes (à moins qu'il n'y ait une sorte de barre d'outils pour les insérer automatiquement). Et si un crochet est supprimé ou gâché, cela pourrait casser le site.
Mais qu'en est-il du MDX ?
Une tentative pour résoudre le besoin de contenu de bloc est MDX, présenté avec le slogan "Markdown pour l'ère des composants". MDX vous permet d'utiliser le langage de modèles JSX, ainsi que JavaScript, entrelacé dans la syntaxe de démarquage. Il y a beaucoup d'ingénierie impressionnante dans la communauté autour de MDX, y compris Unified.js , qui se spécialise dans l'analyse de diverses syntaxes en arbres de syntaxe abstraite (AST), afin qu'elles soient plus accessibles pour être utilisées par programme. Notez que la standardisation du démarquage simplifierait le travail des personnes derrière Unified.js et de ses utilisateurs, car il y a moins de cas extrêmes à gérer.
MDX apporte certainement une meilleure expérience de développeur dans l'intégration de composants dans Markdown. Mais cela n'apporte pas une meilleure expérience d'éditeur, car cela ajoute beaucoup de surcharge cognitive à la production et à l'édition de contenu :
import {Chart} from './snowfall.js' export const year = 2018 # Last year's snowfall In {year}, the snowfall was above average. It was followed by a warm spring which caused flood conditions in many of the nearby rivers. <Chart year={year} color="#fcb32c" />La quantité de connaissances supposées juste pour cet exemple simple est substantielle. Vous devez connaître les modules ES6, les variables JavaScript, la syntaxe des modèles JSX et savoir comment utiliser les accessoires, les codes hexadécimaux et les types de données, et vous devez connaître les composants que vous pouvez utiliser et comment les utiliser. Et vous devez le taper correctement et dans un environnement qui vous donne une sorte de rétroaction. Je ne doute pas qu'il y aura des outils de création plus accessibles en plus de MDX, c'est comme résoudre quelque chose qui n'a pas besoin d'être un problème en premier lieu.
À moins que vous ne soyez extrêmement diligent dans la façon dont vous composez et nommez vos composants MDX, cela lie également votre contenu à une présentation spécifique. Prenez simplement l'exemple ci-dessus tiré de la page d'accueil du MDX. Vous trouverez un hexagone de couleur codé en dur pour le graphique. Lorsque vous reconcevez votre site, cette couleur peut ne pas être compatible avec votre nouveau système de conception. Bien sûr, rien ne vous empêche d'abstraire cela et d'utiliser le prop color=”primary” , mais il n'y a aussi rien dans l'outil qui vous pousse à prendre des décisions judicieuses comme celle-ci.
L'intégration de problèmes de présentation spécifiques dans votre contenu est de plus en plus devenue un handicap et quelque chose qui entravera l'adaptation, l'itération et l'évolution rapide de votre contenu. Il le verrouille de manière beaucoup plus subtile que d'avoir du contenu dans une base de données. Vous risquez de vous retrouver au même endroit que de sortir d'une installation WordPress mature avec des plugins. Il est fastidieux de dissocier structure et présentation.
La demande de contenu structuré
Avec des sites et des parcours utilisateurs plus complexes, nous constatons également la nécessité de présenter les mêmes éléments de contenu sur l'ensemble d'un site Web. Si vous exploitez un site de commerce électronique, vous souhaitez intégrer des informations sur les produits à de nombreux endroits en dehors d'une seule page de produit. Si vous gérez un site marketing moderne, vous souhaitez pouvoir partager la même copie sur plusieurs vues personnalisées.
Pour le faire de manière efficace et fiable, vous devrez adapter le contenu structuré. Cela signifie que votre contenu doit être intégré à des métadonnées et regroupé de manière à permettre l'analyse de l'intention. Si un développeur ne voit que "page" avec "contenu", il est très difficile d'inclure les bonnes choses aux bons endroits. S'ils peuvent accéder à toutes les "descriptions de produits" avec une API ou une requête, cela facilite tout.
Avec le démarquage, vous êtes limité à exprimer des taxonomies et du contenu structuré soit dans une sorte d'organisation de dossiers (ce qui rend difficile de mettre le même contenu dans plusieurs taxonomies), soit vous devez augmenter la syntaxe avec autre chose.
Jekyll, un des premiers générateurs de sites statiques (SSG) conçu pour les fichiers de démarquage, a introduit "Front Matter" comme moyen d'ajouter des métadonnées aux publications à l'aide de YAML (un format clé-valeur simple qui utilise des espaces pour créer une portée) entre trois tirets en haut du dossier. Donc, maintenant, vous aurez deux syntaxes à gérer. YAML a également la réputation d'être espiègle (surtout si vous venez de Norvège). Néanmoins, d'autres SSG ont adopté cette convention, ainsi que des CMS basés sur git qui utilisent le démarquage comme format de contenu.
Lorsque vous devez ajouter une syntaxe supplémentaire à vos fichiers simples pour obtenir certains des avantages du contenu structuré, vous pouvez commencer à vous demander si cela en vaut vraiment la peine. Et à qui s'adresse le format et à qui il exclut.
Si vous y réfléchissez, une grande partie de ce que nous faisons sur le Web ne consiste pas seulement à consommer du contenu, nous le créons ! J'écris actuellement ce long article dans un traitement de texte avancé de mon navigateur.
On s'attend de plus en plus à ce que vous puissiez également créer du contenu de bloc dans les applications de contenu modernes. Les gens ont commencé à s'habituer à des expériences utilisateur agréables qui fonctionnent et qui ont l'air agréables, et où l'on ne s'attend pas à ce que vous ayez à apprendre une syntaxe spécialisée. Medium a popularisé l'idée que vous pouviez avoir une création de contenu agréable et intuitive sur le Web. Et en parlant de "notion", l'application de notes populaire a tout misé sur le contenu des blocs et permet aux utilisateurs de mélanger au maximum un large éventail de types différents. La plupart de ces blocs vont au-delà du démarquage et des éléments natifs de HTML.
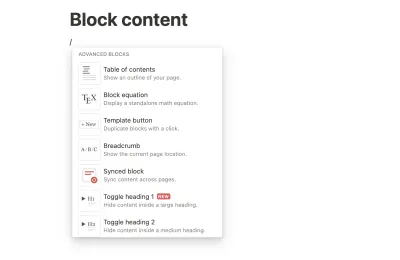
Il est à noter que Notion, décrivant son processus pour rendre son contenu accessible via son API très attendue, met l'accent sur le choix de son format de contenu :
Les documents d'un éditeur Markdown seront souvent analysés et rendus différemment dans une autre application. L'incohérence a tendance à être gérable pour les documents simples, mais c'est un gros problème pour la riche bibliothèque de blocs et d'options de formatage en ligne de Notion, dont beaucoup ne sont tout simplement pas prises en charge dans les implémentations Markdown largement utilisées.
Notion est allé avec un format basé sur JSON qui leur a permis de s'exprimer sous forme de données structurées. Leur argument est qu'il est plus facile et plus prévisible d'interagir avec les développeurs qui souhaitent créer leur propre présentation du contenu de bloc qui sort des API de Notion.
Si ce n'est pas Markdown, alors quoi ?
Je soupçonne que l'importance de Markdown a freiné l'innovation et les progrès du contenu numérique. Donc, quand je soutiens que nous devrions arrêter de le choisir comme moyen principal de stocker du contenu, il est difficile de donner une réponse directe à ce qui devrait le remplacer. Ce que nous savons, cependant, c'est ce que nous devrions attendre des formats de contenu et des outils de création modernes.
Investissons dans des expériences de création accessibles
L'utilisation de Markdown vous oblige à apprendre la syntaxe, et souvent plusieurs syntaxes et balises sur mesure pour être pratique avec les attentes modernes. Aujourd'hui, cela ressemble à une attente complètement inutile pour la plupart des gens. J'aimerais que nous puissions consacrer plus d'énergie à créer des expériences éditoriales accessibles et agréables qui produisent des formats de contenu portables modernes.
Même s'il est notoirement difficile de créer d'excellents éditeurs de contenu de bloc, il existe quelques options viables qui peuvent être étendues et personnalisées pour votre cas d'utilisation (par exemple Slate.js, Quill.js ou Prosemirror). Là encore, investir dans les communautés autour de ces outils pourrait également contribuer à leur développement.
De plus en plus, les gens s'attendront à ce que les outils de création soient accessibles, en temps réel et collaboratifs. Pourquoi devrait-on appuyer sur un bouton de sauvegarde sur le Web en 2021 ? Pourquoi ne devrait-il pas être possible d'apporter une modification à un document sans risquer une situation de concurrence critique, car votre collègue a ouvert le document dans un onglet ? Doit-on s'attendre à ce que les auteurs aient à gérer des conflits de fusion ? Et ne devrions-nous pas permettre aux créateurs de contenu de travailler facilement avec du contenu structuré avec des possibilités visuelles qui ont du sens ?
Pour être un peu polémique : les innovations de la dernière décennie dans les frameworks JavaScript réactifs et les composants d'interface utilisateur sont parfaites pour créer des outils de création impressionnants. Au lieu de les utiliser pour transpiler Markdown en HTML et dans un arbre de syntaxe abstraite pour ensuite l'intégrer dans un langage de modèle JavaScript qui génère du HTML.
Le contenu du bloc doit suivre une spécification
Je n'ai pas mentionné les éditeurs WYSIWYG pour HTML. Parce qu'ils sont la mauvaise chose. Les éditeurs de contenu de bloc modernes devraient de préférence interagir avec un format spécifié. Les éditeurs susmentionnés ont au moins un modèle de document interne sensé qui peut être transformé en quelque chose de plus portable. If you look at the content management system landscape, you start to see various JSON-based block content formats emerge. Some of them are still tied to HTML assumptions or overly concerned with character positions. And none of them aren't really offered as a generic specification.
At Sanity.io, we decided early that the block content format should never assume HTML as neither input nor output, and that we could use algorithms to synchronize text strings. More importantly, was it that block content and rich text should be deeply typed and queryable. The result was the open specification Portable Text. Its structure not only makes it flexible enough to accommodate custom data structures as blocks and inline spans; it's also fully queryable with open-source query languages like GROQ.
Portable Text isn't design to be written or be easily readable in its raw form; it's designed to be produced by an user interface, manipulated by code, and to be serialized and rendered where ever it needs to go. For example, you can use it to express content for voice assistants.
{ "style": "normal", "_type": "block", "children": [ { "_type": "span", "marks": ["a-key", "emphasis"], "text": "some text" } ], "markDefs": [ { "_key": "a-key", "_type": "markType", "extraData": "some data" } ] }An interesting side-effect of turning block content into structured data is exactly that: It becomes data! And data can be queried and processed. That can be highly useful and practical, and it lets you ask your content repository questions that would be otherwise harder and more errorprone in formats like Markdown.
For example, if I for some reason wanted to know what programming languages we've covered in examples on Sanity's blog, that's within reach with a short query. You can imagine how trivial it is to build specialized tools and views on top of this that can be helpful for content editors:
distinct( *["code" in body[]._type] .body[_type == "code"] .language ) // output [ "text", "javascript", "json", "html", "markdown", "sh", "groq", "jsx", "bash", "css", "typescript", "tsx", "scss" ]Example: Get a distinct list of all programming languages that you have code blocks of.
Portable Text is also serializable, meaning that you can recursively loop through it, and make an API that exposes its nodes in callback functions mapped to block types, marked-up spans, and so on. We have spent the last years learning a lot about how it works and how it can be improved, and plan to take it to 1.0 in the near future. The next step is to offer an editor experience outside of Sanity Studio. As we have learned from Markdown, the design intent is important.
Of course, whatever the alternative to markdown is, it doesn't need to be Portable Text, but it needs to be portable text. And it needs to share a lot of its characteristics. There have been a couple of other JSON-based block content format popping up the last few years, but a lot of them seem to bring with them a lot of “HTMLism.” The convenience is understandable, since a lot of content still ends up on the web serialized into HTML, but the convenience limits the portability and the potential for reuse.
You can disregard my short pitch for something we made at Sanity, as long as you embrace the idea of structured content and formats that let you move between systems in a fundamental manner. For example, a goal for Portable Text will be improved compatibility with Unified.js, so it's easier to travel between formats.
Embracing The Legacy Of Markdown
Markdown dans toutes ses saveurs, interprétations et fourchettes ne disparaîtra pas. I suspect that plain text files will always have a place in developers' note apps, blogs, docs, and digital gardens. As a writer who has used markdown for almost two decades, I've become accustomed to “markdown shortcuts” that are available in many rich text editors and am frequently stumped from Google Docs' lack of markdownisms. But I'm not sure if the next generation of content creators and even developers will be as bought in on markdown, and nor should they have to be.
I also think that markdown captured a culture of savvy tinkerers who love text, markup, and automation. I'd love to see that creative energy expand and move into collectively figuring out how we can make better and more accessible block content editors, and building out an ecosystem around specifications that can express block content that's agnostic to HTML. Structured data formats for block content might not have the same plain text ergonomics, but they are highly “tinkerable” and open for a lot of creativity of expression and authoring.
If you are a developer, product owner, or a decision-maker, I really want you to be circumspect of how you want to store and format your content going forward. If you're going for markdown, at least consider the following trade-offs:
Markdown is not great for the developer experience in modern stacks :
- It can be a hassle to parse and validate, even with great tooling.
- Even if you adopt CommonMark, you aren't guaranteed compatibility with tooling or people's expectations.
- It's not great for structured content, YAML frontmatter only takes you so far.
Markdown is not great for editorial experience :
- Most content creators don't want to learn syntax, their time is better spent on other things.
- Most markdown systems are brittle, especially when people get syntax wrong (which they will).
- It's hard to accommodate great collaborative user experiences for block content on top of markdown.
Markdown is not great in block content age , and shouldn't be forced into it. Block content needs to:
- Be untangled from HTMLisms and presentation agnostic.
- Accommodate structured content, so it can be easily used wherever it needs to be used.
- Have stable specification(s), so it's possible to build on.
- Support real-time collaborative systems.
What's common for people like me who challenge the prevalence of markdown, and those who are really into the simple way of expressing text formating is an appreciation of how we transcribe intent into code. That's where I think we can all meet. But I do think it's time to look at the landscape and the emerging content formats that try to encompass modern needs, and ask how we can make sure that we build something that truly caters to editorial experience, and that can speak to developer experience as well.
I want to express my gratitude to Titus Wormer (@wooorm) for his insightful feedback on my first draft of this post, and for the great work he and the Unified.js team have done for the web community.