
Les mathématiques derrière l'apprentissage automatique : ce que vous devez savoir ?
Publié: 2021-03-10L'apprentissage automatique est une division de l'IA qui se concentre sur la création d'applications en traitant avec précision les données disponibles. L'objectif principal de l'apprentissage automatique est d'aider les ordinateurs à traiter les calculs sans intervention humaine. Ceci est rendu possible en permettant à une machine d'apprendre à imiter l'intelligence humaine via des méthodes d'apprentissage supervisées ou non supervisées.
L'apprentissage automatique est une combinaison de nombreux domaines qui incluent les statistiques, les probabilités, l'algèbre linéaire, le calcul, etc., sur la base desquels un modèle d'apprentissage automatique peut créer ou être alimenté par des algorithmes pour improviser selon l'intelligence humaine. Plus l'application est complexe, plus son algorithme sera complexe.
Des assistants numériques aux appareils intelligents en passant par les sites Web recommandant vos produits préférés en fonction de vos activités en ligne et les téléphones portables vous informant de votre horaire de vol, les produits et outils basés sur l'apprentissage automatique sont partout autour de nous. À mesure que notre dépendance aux appareils et appareils intelligents augmente, le besoin de mise en œuvre de l'apprentissage automatique augmentera également.
À cette fin, dans cet article, nous explorerons les concepts mathématiques nécessaires à l'écriture d'algorithmes d'apprentissage automatique et à leur mise en œuvre.
Table des matières
Quelle est l'importance des mathématiques dans l'apprentissage automatique ?
Les applications d'apprentissage automatique fournissent des analyses et des informations tirées des données disponibles qui contribuent à la prise de décision exploitable dans les entreprises. Étant donné que l'apprentissage automatique s'articule autour de l'étude et de la mise en œuvre d'algorithmes, il est important de renforcer vos compétences en mathématiques. Il aide à éliminer l'incertitude et à prédire avec précision les valeurs des données lorsque des paramètres et des caractéristiques de données complexes sont impliqués. Cela nous aide également à mieux comprendre le compromis biais-variance.
La maîtrise de l'apprentissage automatique nécessite la connaissance de concepts mathématiques tels que l'algèbre linéaire, le calcul vectoriel, la géométrie analytique, les décompositions matricielles, les probabilités et les statistiques. Une bonne compréhension de ceux-ci aide à créer des applications d'apprentissage automatique intuitives.

Algèbre linéaire
L'algèbre linéaire concerne les vecteurs et les matrices, et tourne principalement autour du calcul. Il joue un rôle essentiel dans les techniques d'apprentissage automatique et d'apprentissage en profondeur. Selon Skyler Speakman , ce sont les mathématiques du 21ème siècle.
L'algèbre linéaire est généralement utilisée par les ingénieurs ML et les scientifiques des données ou les chercheurs pour créer des algorithmes linéaires, des régressions logistiques, des arbres de décision et des machines à vecteurs de support.
Calcul
Calculus pilote des algorithmes d'apprentissage automatique. Sans connaissance de ses concepts, il ne serait pas possible de prédire les résultats à l'aide d'un ensemble de données donné. Le calcul aide à analyser la vitesse à laquelle les quantités changent et s'intéresse aux performances optimales des algorithmes d'apprentissage automatique. Les intégrations, les différentiels, les limites et les dérivés sont quelques concepts de calcul qui aident à former des réseaux de neurones profonds.
Probabilité
La probabilité dans l'apprentissage automatique prédit l'ensemble des résultats, tandis que les statistiques conduisent le résultat favorable à sa conclusion. L'événement pourrait être aussi simple que de lancer une pièce de monnaie. La probabilité peut être divisée en deux catégories : la probabilité conditionnelle et la probabilité conjointe. La probabilité conjointe se produit lorsque les événements sont indépendants les uns des autres, tandis que la probabilité conditionnelle se produit lorsqu'un événement remplace l'autre.
Statistiques
Les statistiques se concentrent sur les aspects quantitatifs et qualitatifs de l'algorithme. Il nous aide à identifier les objectifs et à transformer les données collectées en observations précises en les présentant de manière concise. Les statistiques en apprentissage automatique se concentrent sur les statistiques descriptives et les statistiques inférentielles.
Les statistiques descriptives consistent à décrire et à résumer le petit ensemble de données sur lequel un modèle travaille. Les méthodes utilisées ici sont la moyenne, la médiane, le mode, l'écart-type et la variation. Les résultats finaux sont présentés sous forme de représentations picturales.
Les statistiques inférentielles traitent de l'extraction d'informations à partir d'un échantillon donné tout en travaillant avec un grand ensemble de données. Les statistiques inférentielles permettent aux machines d'analyser des données au-delà de la portée des informations fournies. Les tests d'hypothèses, les distributions d'échantillonnage, l'analyse de la variance sont quelques aspects des statistiques inférentielles.
En dehors de cela, les prouesses en matière de codage sont une condition préalable cruciale pour l'apprentissage automatique. L'expertise dans des langages tels que Python et Java aide à une meilleure compréhension de la modélisation des données. Le formatage de chaînes, la définition de fonctions, les boucles avec plusieurs itérateurs de variables, si ou bien les expressions conditionnelles sont quelques-unes de ses fonctions de base.
Quant à la modélisation des données, c'est le processus par lequel nous estimons la structure des ensembles de données et détectons les variations et les modèles possibles. Pour pouvoir faire des prédictions précises, il faut être conscient des diverses propriétés des données collectives.
Comment pouvez-vous apprendre l'apprentissage automatique ?
Bien que l'apprentissage automatique soit un domaine lucratif, il nécessite beaucoup de pratique et de patience. Compte tenu de ses applications dans presque tous les secteurs aujourd'hui, les ingénieurs en apprentissage automatique sont très demandés.
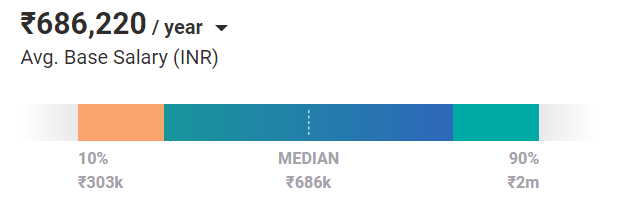
Le salaire moyen d'un ingénieur débutant avec une formation en machine learning est de Rs 686k /an. Et avec l'expérience et le perfectionnement, le potentiel de gagner un salaire plus élevé augmente de façon exponentielle.
Il existe plusieurs cours disponibles pour quelqu'un qui souhaite améliorer sa base de connaissances en apprentissage automatique. Il vous faudrait un minimum de 6 mois à 2 ans pour maîtriser le sujet.
Avec un minimum d'un baccalauréat et un an d'expérience de travail, mieux encore un diplôme en mathématiques ou en statistiques, vous pouvez suivre l'un des cours suivants sur upGrad pour augmenter vos chances de réussite dans le domaine.
- Programme de certificat avancé en apprentissage automatique et en apprentissage profond de l'IIT Bangalore (6 mois)
- Programme de certificat avancé en apprentissage automatique et NLP de l'IIT Bangalore (6 mois)
- Programme exécutif PG en apprentissage automatique et IA de l'IIT Bangalore (12 mois)
- Certification avancée en Machine Learning et Cloud de l'IIT Madras (12 mois)
- Master of Science en Machine Learning et AI de LJMU et IIT Bangalore (18 mois)
Tous ces cours offrent un minimum de 240 heures d'apprentissage et au moins 5 études de cas qui vous aideraient à acquérir une compréhension approfondie de l'apprentissage automatique et de ses divers domaines auxiliaires. Vous pouvez couvrir des sujets essentiels tels que Python, MySQL, Tensor, NLTK, statsmodels, excel, etc. qui forment l'épine dorsale du codage. Voici un aperçu détaillé des différents cours upGrad en apprentissage automatique afin que vous puissiez choisir celui qui vous convient le mieux.

Rejoignez le cours d'intelligence artificielle en ligne des meilleures universités du monde - Masters, Executive Post Graduate Programs et Advanced Certificate Program in ML & AI pour accélérer votre carrière.
Applications de l'apprentissage automatique
L'apprentissage automatique joue un rôle crucial dans notre vie quotidienne, tant dans la sphère professionnelle que personnelle. Ses capacités analytiques et intuitives ont le potentiel d'avoir un impact considérable sur la façon dont nous effectuons nos tâches quotidiennes. Il s'est avéré ingénieux pour économiser de l'argent et du temps pour une organisation.
Bien que l'apprentissage automatique soit un vaste domaine avec des applications dans presque tous les secteurs, voici quelques exemples les plus marquants :
- La reconnaissance d'image est l'une des applications les plus couramment utilisées car elle aide à la détection des visages, créant ainsi une base de données distincte pour chaque individu. Il peut également être utilisé pour identifier les styles d'écriture manuscrite.
- L'apprentissage automatique dans le secteur de la santé a amélioré les capacités des prestataires de soins de santé. Il peut être utilisé dans un diagnostic médical plus rapide. Dans de nombreux cas, l'IA a aidé au diagnostic précoce des maladies, permettant ainsi aux médecins de proposer des traitements et des mesures préventives susceptibles de sauver des vies.
- L'apprentissage automatique a des applications majeures dans le secteur financier en matière d'investissements, de fusions et d'acquisitions. Il aide les banques et autres institutions économiques à faire des choix judicieux.
- Son efficacité est peut-être plus évidente dans le secteur de l'assistance et des services à la clientèle, car l'apprentissage automatique rationalise les opérations et fournit des solutions rapidement et plus efficacement.
- L'apprentissage automatique automatise des tâches qui, autrement, devraient être effectuées par un humain sur le terrain. Par exemple, si nous devions envisager des assistants virtuels, il pourrait s'agir d'une tâche aussi simple que de changer le mot de passe ou de vérifier le soir votre solde bancaire. Avec l'apprentissage automatique, il est désormais possible d'allouer des ressources humaines à des tâches plus urgentes qui nécessitent une prise de décision compliquée ou une intervention humaine à accomplir.
Portée future de l'apprentissage automatique
Même si l'apprentissage automatique existe depuis des décennies, son application est la plus évidente aujourd'hui. L'industrie doit encore prospérer et improviser, ce qui implique que l'avenir de l'apprentissage automatique est prometteur. La plupart des grandes entreprises récoltent déjà les bénéfices de l'apprentissage automatique et adaptent leurs services et produits pour stimuler la croissance.
Naturellement, les ingénieurs ML sont très demandés et l'apprentissage automatique se présente comme une carrière lucrative. Il offre aux entreprises l'avantage dont elles ont besoin. L'IA a généré environ 2,3 millions d'opportunités d'emploi jusqu'à présent. Il a été prévu que d'ici la fin de 2022, l' industrie mondiale du ML augmentera à un TCAC de 42,2 % pour atteindre 9 milliards USD .
Voici quelques tendances majeures en matière d'apprentissage automatique :
- De plus en plus d'algorithmes s'orientent vers des implémentations non supervisées. Les entreprises investissent dans l'informatique quantique basée sur ces algorithmes non supervisés qui ont le potentiel de transformer l'apprentissage automatique. Ceux-ci contribuent à analyser et à tirer des informations significatives, aidant ainsi les entreprises à obtenir de meilleurs résultats qui n'auraient pas été possibles en utilisant des techniques d'apprentissage automatique classiques.
- Des robots alimentés par l'IA sont déployés pour effectuer des opérations commerciales. Cependant, ces technologies en sont à leurs balbutiements et, à mesure que les entreprises investissent dans l'implantation de l'IA et du ML, les robots contribueront bientôt à augmenter la productivité de manière exponentielle. À titre d'exemple, nous avons des drones qui se présentent comme de puissants outils commerciaux sur le marché de la consommation où ils sont utilisés pour accomplir des opérations commerciales et des tâches simples comme la livraison de marchandises.
- Les algorithmes d'apprentissage automatique prennent en charge une personnalisation améliorée. Ces algorithmes étudient le comportement en ligne des clients potentiels et renvoient des informations aux entreprises. Les entreprises leur envoient à leur tour des recommandations de produits et de services. Ces techniques d'apprentissage automatique aident à identifier les goûts et les aversions des clients. Grâce à l'apprentissage automatique, les entreprises donnent à leurs clients ce qu'ils désirent, et quand ils le désirent, ce qui augmente la fidélisation de la clientèle et attire plus d'affaires dans l'organisation. L'amélioration de la personnalisation est l'avenir de l'apprentissage automatique.
- Grâce aux algorithmes d'apprentissage automatique améliorés, les applications mobiles et Web sont désormais plus intelligentes que jamais. Des services cognitifs améliorés permettent aux développeurs de créer des bases de données distinctes pour chaque client, basées sur la reconnaissance visuelle, leur parole, leur son, leur voix, etc.
Cela nous amène à la fin de l'article. Nous espérons que vous avez trouvé ces informations utiles !
Pourquoi l'homoscédasticité est-elle requise dans la régression linéaire ?
L'homoscédasticité décrit à quel point les données sont similaires ou éloignées de la moyenne. Il s'agit d'une hypothèse importante à faire car les tests statistiques paramétriques sont sensibles aux différences. L'hétéroscédasticité n'induit pas de biais dans les estimations des coefficients, mais elle réduit leur précision. Avec une précision moindre, les estimations des coefficients sont plus susceptibles de s'écarter de la valeur de population correcte. Pour éviter cela, l'homoscédasticité est une hypothèse cruciale à affirmer.
Quels sont les deux types de multicolinéarité dans la régression linéaire ?
Les données et la multicolinéarité structurelle sont les deux types de base de multicolinéarité. Lorsque nous fabriquons un terme modèle à partir d'autres termes, nous obtenons une multicolinéarité structurelle. En d'autres termes, plutôt que d'être présent dans les données elles-mêmes, c'est le résultat du modèle que nous fournissons. Bien que la multicolinéarité des données ne soit pas un artefact de notre modèle, elle est présente dans les données elles-mêmes. La multicolinéarité des données est plus courante dans les enquêtes observationnelles.
Quels sont les inconvénients de l'utilisation du test t pour des tests indépendants ?
Il y a des problèmes avec la répétition des mesures au lieu des différences entre les conceptions de groupe lors de l'utilisation de tests t d'échantillons appariés, ce qui entraîne des effets de report. En raison d'erreurs de type I, le test t ne peut pas être utilisé pour des comparaisons multiples. Il sera difficile de rejeter l'hypothèse nulle lors d'un test t apparié sur un ensemble d'échantillons. L'obtention des sujets pour les données de l'échantillon est un aspect long et coûteux du processus de recherche.