
Test du pipeline 101 pour les tests frontaux
Publié: 2022-03-10Imaginez cette situation : vous approchez rapidement d'une échéance et vous utilisez chaque minute disponible pour atteindre votre objectif de terminer cette refactorisation complexe, avec de nombreuses modifications dans vos fichiers CSS. Vous travaillez même sur les dernières étapes pendant votre trajet en bus. Cependant, vos tests locaux semblent échouer à chaque fois et vous ne pouvez pas les faire fonctionner. Votre niveau de stress augmente .
Il y a en effet une scène similaire dans une série bien connue : Elle est tirée de la troisième saison de la série télévisée de Netflix, « How to Sell Drugs Online (Fast) » :
Cypress + Vue est présenté *SUR UNE ÉMISSION TÉLÉVISÉE NETFLIX*
– jess (@_jessicasachs) 7 août 2021
C'est une comédie intitulée "Comment vendre de la drogue (rapidement)" et elle contient certaines des représentations les plus réalistes du webdev.
Saison 3, épisode 1 @ 20h20 et une ou deux fois avant. pic.twitter.com/ICSAwMxyFB
Eh bien, il utilise au moins des tests, vous pourriez penser. Pourquoi est-il toujours en détresse, vous vous demandez peut-être ? Il y a encore beaucoup de place à l'amélioration et pour éviter une telle situation, même si vous écrivez des tests. Comment pensez-vous surveiller votre base de code et tous vos changements depuis le début ? En conséquence, vous n'aurez pas de telles mauvaises surprises, n'est-ce pas ? Il n'est pas trop difficile d'inclure de telles routines de test automatisées : créons ensemble ce pipeline de test du début à la fin.
Allons-y!
Tout d'abord : Termes de base
Une routine de construction peut vous aider à rester confiant dans une refactorisation plus complexe, même dans vos petits projets parallèles. Cependant, cela ne signifie pas que vous devez être un ingénieur DevOps. Il est essentiel d'apprendre quelques termes et stratégies, et c'est pour cela que vous êtes ici, n'est-ce pas ? Heureusement, vous êtes au bon endroit ! Commençons par les termes fondamentaux que vous rencontrerez bientôt lors de la gestion d'un pipeline de test pour votre projet frontal.
Si vous cherchez sur Google votre chemin à travers le monde des tests en général, il se peut que vous soyez déjà tombé sur les termes "CI/CD" comme l'un des premiers termes. C'est l'abréviation de « Intégration continue, livraison continue » et « Déploiement continu » et décrit exactement cela : comme vous l'avez probablement déjà entendu, il s'agit d'une méthode de distribution de logiciels utilisée par les équipes de développement pour déployer des modifications de code plus fréquemment et de manière plus fiable. CI/CD implique deux approches complémentaires, qui s'appuient fortement sur l'automatisation.
- Intégration continue
C'est un terme désignant des mesures d'automatisation pour implémenter de petites modifications régulières du code et les fusionner dans un référentiel partagé. L'intégration continue comprend les étapes de construction et de test de votre code.
CD est l'acronyme de « livraison continue » et de « déploiement continu », deux concepts similaires mais parfois utilisés dans des contextes différents. La différence entre les deux réside dans la portée de l'automatisation :
- Livraison continue
Il fait référence au processus de votre code qui était déjà testé auparavant, à partir duquel l'équipe des opérations peut maintenant les déployer dans un environnement de production en direct. Cette dernière étape peut cependant être manuelle. - Déploiement continu
Il se concentre sur l'aspect « déploiement », comme son nom l'indique. C'est un terme désignant le processus de publication entièrement automatisé des modifications apportées par le développeur depuis le référentiel jusqu'à la production, où le client peut les utiliser directement.
Ces processus visent à permettre aux développeurs et aux équipes d'avoir un produit, que vous pouvez publier à tout moment s'ils le souhaitent : Avoir la confiance d'une application surveillée, testée et déployée en permanence.
Pour parvenir à une stratégie CI/CD bien conçue, la plupart des personnes et des organisations utilisent des processus appelés « pipelines ». "Pipeline" est un mot que nous avons déjà utilisé dans ce guide sans l'expliquer. Si vous pensez à de tels pipelines, il n'est pas trop exagéré de penser à des tubes servant de lignes longue distance pour transporter des choses telles que le gaz. Un pipeline dans la zone DevOps fonctionne de manière assez similaire : il "transporte" des logiciels à déployer.
Attendez, cela ressemble à beaucoup de choses à apprendre et à retenir, n'est-ce pas ? N'avons-nous pas parlé de tests ? Vous avez raison : couvrir le concept complet d'un pipeline CI/CD fournira suffisamment de contenu pour plusieurs articles, et nous voulons nous occuper d'un pipeline de test pour les petits projets frontaux. Ou il ne vous manque que l'aspect test de vos pipelines, vous vous concentrez donc uniquement sur les processus d'intégration continue. Ainsi, en particulier, nous nous concentrerons sur la partie "Tests" des pipelines. Par conséquent, nous allons créer un "petit" pipeline de test dans ce guide.
D'accord, donc la "partie test" est notre objectif principal. Dans ce contexte, quels tests connaissez-vous déjà et qui vous viennent à l'esprit au premier coup d'œil ? Si je pense à tester de cette façon, voici les types de tests auxquels je pense spontanément :
- Le test unitaire est une sorte de test dans lequel des parties ou unités testables mineures d'une application, appelées unités, sont testées individuellement et indépendamment pour un fonctionnement correct.
- Les tests d'intégration se concentrent sur l'interaction entre les composants ou les systèmes. Ce type de test signifie que nous vérifions l'interaction des unités et comment elles fonctionnent ensemble.
- Les tests de bout en bout , ou tests E2E, signifient que les interactions réelles de l'utilisateur sont simulées par l'ordinateur ; ce faisant, les tests E2E doivent inclure autant de domaines fonctionnels et de parties de la pile technologique utilisées dans l'application que possible.
- Le test visuel est le processus de vérification de la sortie visible d'une application et de sa comparaison avec les résultats attendus. En d'autres termes, cela aide à trouver des "bugs visuels" dans l'apparence d'une page ou d'un écran différents des bugs purement fonctionnels.
- L'analyse statique n'est pas précisément un test, mais je pense qu'il est essentiel de le mentionner ici. Vous pouvez l'imaginer fonctionner comme une correction orthographique : il débogue votre code sans exécuter le programme et détecte les problèmes de style de code. Cette mesure simple peut éviter de nombreux bugs.
Pour être confiant dans la fusion d'une refactorisation massive dans notre projet unique, nous devrions envisager d'utiliser tous ces types de tests dans notre pipeline de tests. Mais prendre de l'avance mène rapidement à la frustration : vous pourriez vous sentir perdu en évaluant ces types de tests. Par où dois-je commencer ? Combien de tests de quels types sont raisonnables ?
Élaboration de stratégies : pyramides et trophées
Nous devons travailler sur une stratégie de test avant de plonger dans la construction de notre pipeline. En cherchant des réponses à toutes ces questions auparavant, vous pourriez trouver une solution possible dans certaines métaphores : sur le Web et dans les communautés de test en particulier, les gens ont tendance à utiliser des analogies pour vous donner une idée du nombre de tests que vous devez utiliser et de quel type.
La première métaphore que vous rencontrerez probablement est la pyramide d'automatisation des tests. Mike Cohn a proposé ce concept dans son livre "Succeeding with Agile", développé plus avant sous le nom de "Practical Test Pyramid" par Martin Fowler. Il ressemble à ceci :
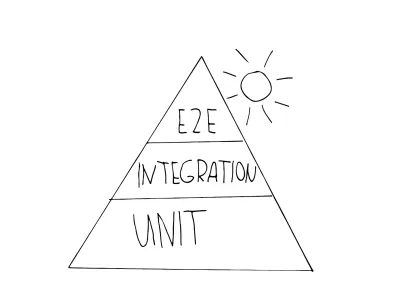
Comme vous le voyez, il se compose de trois niveaux, qui correspondent aux trois niveaux de test présentés. La pyramide est destinée à clarifier la bonne combinaison de différents tests, pour vous guider lors de l'élaboration d'une stratégie de test :
- Unité
Vous trouverez ces tests sur la couche de base de la pyramide car ils sont d'exécution rapide et simples à entretenir. Cela est dû à leur isolement et au fait qu'ils ciblent les plus petites unités. Voir celui-ci pour un exemple de test unitaire typique testant un très petit produit. - L'intégration
Ceux-ci se situent au milieu de la pyramide, car ils sont toujours acceptables en termes de vitesse d'exécution, mais vous apportent toujours la confiance d'être plus proches de l'utilisateur que les tests unitaires ne peuvent l'être. Un exemple de test de type intégration est un test API, les tests de composants peuvent également être considérés comme ce type. - Tests E2E (également appelés tests UI )
Comme nous l'avons vu, ces tests simulent un véritable utilisateur et son interaction. Ces tests nécessitent plus de temps pour être exécutés et sont donc plus coûteux, étant placés au sommet de la pyramide. Si vous souhaitez inspecter un exemple typique de test E2E, rendez-vous sur celui-ci.
Cependant, ces dernières années, cette métaphore s'est sentie hors du temps. L'un de ses défauts, en particulier, est pour moi crucial : les analyses statiques sont contournées dans cette stratégie. L'utilisation de fixateurs de style code ou d'autres solutions de peluchage n'est pas prise en compte dans cette métaphore, étant un énorme défaut, à mon avis. Les peluches et autres outils d'analyse statique font partie intégrante du pipeline utilisé et ne doivent pas être ignorés.
Alors, coupons court : nous devrions utiliser une stratégie plus actualisée. Mais les outils de peluche manquants ne sont pas le seul défaut - il y a même un point plus important à considérer. Au lieu de cela, nous pourrions déplacer légèrement notre attention : la citation suivante le résume assez bien :
« Rédiger des tests. Pas trop. Surtout l'intégration.
—Guillermo Rauch
Décomposons cette citation pour en savoir plus :
- Rédiger des tests
Assez explicite - vous devriez toujours écrire des tests. Les tests sont cruciaux pour instaurer la confiance dans votre application, tant pour les utilisateurs que pour les développeurs. Même pour vous-même ! - Pas trop
Écrire des tests au hasard ne vous mènera nulle part ; la pyramide des tests est toujours valable dans sa déclaration pour garder les tests prioritaires. - Principalement l'intégration
Un atout des tests les plus "chers" que la pyramide ignore est que la confiance dans les tests augmente à mesure que vous montez dans la pyramide. Cette augmentation signifie que l'utilisateur et vous-même en tant que développeur sont les plus susceptibles de faire confiance à ces tests.
Cela signifie que nous devrions opter pour des tests plus proches de l'utilisateur, par conception. En conséquence, vous pourriez payer plus, mais vous récupérez beaucoup de valeur. Vous vous demandez peut-être pourquoi ne pas choisir le test E2E ? Comme ils imitent les utilisateurs, ne sont-ils pas les plus proches de l'utilisateur, pour commencer ? C'est vrai, mais ils sont toujours beaucoup plus lents à exécuter et nécessitent la pile d'applications complète. Ce retour sur investissement est donc plus tardif qu'avec les tests d'intégration : Par conséquent, les tests d'intégration offrent un juste équilibre entre la confiance d'une part et la rapidité et l'effort d'autre part.
Si vous suivez Kent C.Dodds, ces arguments peuvent vous sembler familiers, surtout si vous lisez cet article de lui en particulier. Ces arguments ne sont pas une coïncidence : il a proposé une nouvelle stratégie dans son travail. Je suis tout à fait d'accord avec ses points et relie le plus important ici et d'autres dans la section des ressources. Son approche suggérée découle de la pyramide des tests mais l'élève à un autre niveau en modifiant sa forme pour refléter la priorité plus élevée accordée aux tests d'intégration. C'est ce qu'on appelle le « Trophée des essais ».
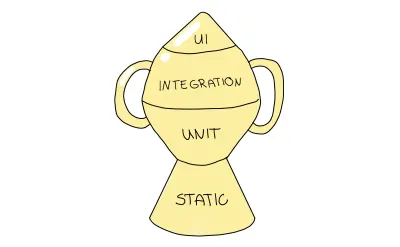
Le trophée de test est une métaphore décrivant la granularité des tests d'une manière légèrement différente; vous devez répartir vos tests dans les types de tests suivants :
- L'analyse statique joue un rôle essentiel dans cette métaphore. De cette façon, vous détecterez les fautes de frappe, les erreurs de frappe et d'autres bogues en exécutant simplement les étapes de débogage mentionnées.
- Les tests unitaires doivent garantir que votre plus petite unité est correctement testée, mais le trophée de test ne les mettra pas autant en valeur que la pyramide de test.
- L'intégration est l'objectif principal car elle équilibre le coût et la confiance accrue de la meilleure façon.
- Les tests d'interface utilisateur , y compris les tests E2E et visuels, sont au sommet du trophée de test, similaire à leur rôle dans la pyramide des tests.
J'ai opté pour cette stratégie de trophée de test dans la plupart de mes projets, et je continuerai à le faire dans ce guide. Cependant, je dois donner un petit avertissement ici : Bien sûr, mon choix est basé sur les projets sur lesquels je travaille dans ma vie quotidienne. Ainsi, les avantages et la sélection d'une stratégie de test correspondante dépendent toujours du projet sur lequel vous travaillez. Alors, ne vous sentez pas mal si cela ne correspond pas à vos besoins, j'ajouterai des ressources à d'autres stratégies dans le paragraphe correspondant.
Alerte spoiler mineur : D'une certaine manière, je devrai également m'écarter un peu de ce concept, comme vous le verrez bientôt. Cependant, je pense que c'est bien, mais nous y reviendrons dans un instant. Mon propos est de réfléchir à la hiérarchisation et à la distribution des types de tests avant de planifier et de mettre en œuvre vos pipelines.
Comment construire ces pipelines en ligne (rapidement)
Le protagoniste de la troisième saison de la série télévisée de Netflix "Comment vendre des médicaments en ligne (rapidement)" utilise Cypress pour les tests E2E alors qu'il était proche d'une date limite, cependant, il ne s'agissait en réalité que de tests locaux. Aucun CI/CD n'était visible, ce qui lui causait un stress inutile. Nous devrions éviter la pression du protagoniste donné dans les épisodes correspondants avec la théorie que nous avons apprise. Cependant, comment pouvons-nous appliquer ces apprentissages à la réalité ?
Tout d'abord, nous avons besoin d'une base de code comme base de test pour commencer. Idéalement, ce devrait être un projet que beaucoup d'entre nous, développeurs frontaux, rencontrerons. Son cas d'utilisation devrait être fréquent, être bien adapté à une approche pratique et nous permettre de mettre en œuvre un pipeline de test à partir de zéro. Que pourrait être un tel projet ?
Ma suggestion d'un pipeline principal
La première chose qui m'est venue à l'esprit était évidente : mon site Web, c'est-à-dire ma page de portfolio, est bien adapté pour être considéré comme un exemple de base de code à tester par notre aspirant pipeline. Il est publié en open source sur Github, vous pouvez donc le consulter et l'utiliser librement. Quelques mots sur la tech stack du site : A la base, j'ai construit ce site sur Vue.js (malheureusement encore sur la version 2 quand j'ai écrit cet article) comme framework JavaScript avec Nuxt.js comme framework web supplémentaire. Vous pouvez trouver l'exemple d'implémentation complet dans son référentiel GitHub.
Avec notre exemple de base de code sélectionné, nous devrions commencer à appliquer nos apprentissages. Étant donné que nous voulons utiliser le trophée de test comme point de départ de notre stratégie de test, j'ai proposé le concept suivant :
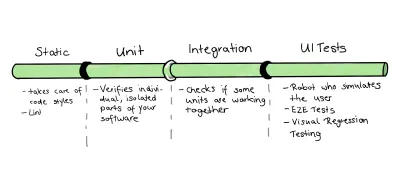
Comme nous avons affaire à une base de code relativement petite, je vais fusionner les parties des tests unitaires et d'intégration. Cependant, ce n'est qu'une petite raison de le faire. D'autres raisons plus importantes sont celles-ci :
- La définition d'une unité est souvent « à discuter » : si vous demandez à un groupe de développeurs de définir une unité, vous obtiendrez la plupart du temps des réponses diverses et divergentes. Comme certains font référence à une fonction, une classe ou un service (unités mineures), un autre développeur comptera dans le composant complet.
- En plus de ces difficultés de définition, tracer une ligne entre l'unité et l'intégration peut être délicat, car c'est très flou. Cette lutte est réelle, surtout pour Frontend, car nous avons souvent besoin du DOM pour valider la base de test avec succès.
- Il est généralement possible d'utiliser les mêmes outils et bibliothèques pour écrire les deux tests d'intégration. Ainsi, nous pourrions être en mesure d'économiser des ressources en les fusionnant.
Outil de choix : actions GitHub
Comme nous savons ce que nous voulons imaginer à l'intérieur d'un pipeline, la prochaine étape est le choix de la plate-forme d'intégration et de livraison continues (CI/CD). En choisissant une telle plateforme pour notre projet, je pense à celles avec lesquelles j'ai déjà acquis de l'expérience :
- GitLab, par la routine quotidienne sur mon lieu de travail,
- Actions GitHub dans la plupart de mes projets parallèles.
Cependant, il existe de nombreuses autres plates-formes parmi lesquelles choisir. Je suggérerais de toujours baser votre choix sur vos projets et leurs exigences spécifiques, en tenant compte des technologies et des frameworks utilisés - afin que les problèmes de compatibilité ne se produisent pas. N'oubliez pas que nous utilisons un projet Vue 2 qui a déjà été publié sur GitHub, correspondant par coïncidence à mon expérience antérieure. De plus, les actions GitHub mentionnées n'ont besoin que du référentiel GitHub de votre projet comme point de départ ; pour créer et exécuter un flux de travail GitHub Actions spécifiquement pour lui. En conséquence, je vais utiliser GitHub Actions pour ce guide.
Ainsi, ces actions GitHub vous fournissent une plate-forme pour exécuter des flux de travail spécifiquement définis si certains événements donnés se produisent. Ces événements sont des activités particulières dans notre référentiel qui déclenchent le flux de travail, par exemple, envoyer des modifications à une branche. Dans ce guide, ces événements sont liés au CI/CD, mais ces flux de travail peuvent également automatiser d'autres flux de travail, comme l'ajout d'étiquettes aux demandes d'extraction. GitHub peut les exécuter sur des machines virtuelles Windows, Linux et macOS.

Pour visualiser un tel flux de travail, cela ressemblerait à ceci :
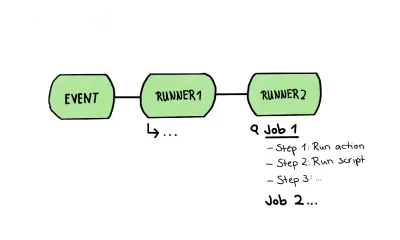
Dans cet article, j'utiliserai un flux de travail pour imaginer un pipeline ; cela signifie qu'un flux de travail contiendra toutes nos étapes de test, de l'analyse statique aux tests d'interface utilisateur de toutes sortes. Ce pipeline, ou appelé "workflow" dans les paragraphes suivants, sera composé d'un ou même plusieurs jobs, qui sont un ensemble d'étapes s'exécutant sur le même runner.
Ce flux de travail est exactement la structure que je voulais esquisser dans le dessin ci-dessus. Dans celui-ci, nous examinons de plus près un tel coureur contenant plusieurs tâches; Les étapes d'un travail elles-mêmes sont constituées de différentes étapes. Ces étapes peuvent être de deux types :
- Une étape peut exécuter un script simple.
- Une étape peut être capable d'exécuter une action. Une telle action est une extension réutilisable et est souvent une application complète et personnalisée.
En gardant cela à l'esprit, un flux de travail réel d'une action GitHub ressemble à ceci :
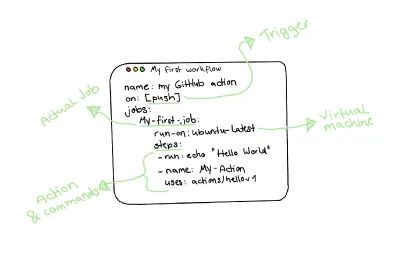
Écrire notre toute première action GitHub
Enfin, nous pouvons écrire notre première action Github et écrire du code ! Nous commencerons par notre flux de travail de base et notre premier aperçu des travaux que nous voulons représenter. En souvenir de notre trophée de test, chaque travail ressemblera à une couche du trophée de test. Les étapes seront les choses que nous devons faire pour automatiser ces couches.
Par conséquent, je crée le .github/workflows/ pour stocker nos flux de travail en premier. Nous allons créer un nouveau fichier appelé tests.yml pour contenir notre workflow de test dans ce répertoire. Parallèlement à la syntaxe de flux de travail standard vue dans le dessin ci-dessus, je procéderai comme suit :
- Je nommerai notre flux de travail
Tests CI. - Étant donné que je souhaite exécuter mon flux de travail à chaque poussée vers mes succursales distantes et fournir une option manuelle pour démarrer mon pipeline, je vais configurer mon flux de travail pour qu'il s'exécute sur
pushetworkflow_dispatch. - Enfin, comme indiqué dans le paragraphe "Ma suggestion d'un pipeline de base", mon workflow contiendra trois jobs :
-
static-eslintpour l'analyse statique ; -
unit-integration-jestpour les tests unitaires et d'intégration fusionnés en un seul travail ; -
ui-cypresscomme étape de l'interface utilisateur, y compris le test E2E de base et le test de régression visuelle.
-
- Une machine virtuelle basée sur Linux devrait exécuter tous les travaux, donc je vais utiliser
ubuntu-latest.
Mis dans la syntaxe correcte d'un fichier YAML , le premier aperçu de notre flux de travail pourrait ressembler à celui-ci :
name: Tests CI on: [push, workflow_dispatch] # On push and manual jobs: static-eslint: runs-on: ubuntu-latest steps: # 1 steps unit-integration-jest: runs-on: ubuntu-latest steps: # 1 step ui-cypress: runs-on: ubuntu-latest steps: # 2 steps: e2e and visualSi vous souhaitez vous plonger dans les détails des flux de travail dans l'action GitHub, n'hésitez pas à consulter sa documentation à tout moment. Quoi qu'il en soit, vous savez sans aucun doute que les étapes sont toujours manquantes. Ne vous inquiétez pas, je suis au courant aussi. Donc, pour donner vie à ce schéma de flux de travail, nous devons définir ces étapes et décider quels outils et cadres de test utiliser pour notre petit projet de portefeuille. Tous les paragraphes à venir décriront les tâches respectives et contiendront plusieurs étapes pour rendre possible l'automatisation desdits tests.
Analyse statique
Comme le suggère le trophée de test, nous commencerons par les linters et autres fixateurs de style code dans notre flux de travail. Dans ce contexte, vous pouvez choisir parmi de nombreux outils, et voici quelques exemples :
- Eslint en tant que fixateur de style de code Javascript.
- Stylelint pour la correction du code CSS.
- On peut envisager d'aller encore plus loin, par exemple, pour analyser la complexité du code, on pourrait se pencher sur des outils comme scrutateur.
Ces outils ont en commun qu'ils signalent les erreurs dans les modèles et les conventions. Cependant, sachez que certaines de ces règles sont une question de goût. C'est à vous de décider jusqu'à quel point vous voulez les appliquer. Pour ne citer qu'un exemple, si vous allez tolérer une indentation de deux ou quatre onglets. Il est beaucoup plus important de se concentrer sur l'exigence d'un style de code cohérent et sur la détection des causes d'erreurs les plus critiques, comme l'utilisation de « == » par rapport à « === ».
Pour notre projet de portefeuille et ce guide, je souhaite commencer à installer Eslint, car nous utilisons beaucoup de Javascript. Je vais l'installer avec la commande suivante :
npm install eslint --save-dev Bien sûr, je peux également utiliser une commande alternative avec le gestionnaire de packages Yarn si je préfère ne pas utiliser NPM. Après l'installation, je dois créer un fichier de configuration appelé .eslintrc.json . Utilisons une configuration de base pour l'instant, car cet article ne vous apprendra pas comment configurer Eslint en premier lieu :
{ "extends": [ "eslint:recommended", ] } Si vous souhaitez en savoir plus sur la configuration d'Eslint en détail, rendez-vous sur ce guide. Ensuite, nous voulons faire nos premiers pas pour automatiser l'exécution d'Eslint. Pour commencer, je souhaite définir la commande pour exécuter Eslint en tant que script NPM. J'y parviens en utilisant cette commande dans notre fichier package.json dans la section script :
"scripts": { "lint": "eslint --ext .js .", }, Je peux ensuite exécuter ce script nouvellement créé dans notre flux de travail GitHub. Cependant, nous devons nous assurer que notre projet est disponible avant de le faire. Par conséquent, nous utilisons les actions/checkout@v2 qui font exactement cela : vérifier notre projet, afin que le flux de travail de votre action GitHub puisse y accéder. La prochaine étape consisterait à installer toutes les dépendances NPM dont nous avons besoin pour mon projet de portefeuille. Après cela, nous sommes enfin prêts à exécuter notre script eslint ! Notre travail final pour utiliser les peluches ressemble à ceci maintenant :
static-eslint: runs-on: ubuntu-latest steps: # Action to check out my codebase - uses: actions/checkout@v2 # install NPM dependencies - run: npm install # Run lint script - run: npm run lint Vous vous demandez peut-être maintenant : ce pipeline "échoue-t-il" automatiquement lorsque notre npm run lint dans un test qui échoue ? Oui, cela fonctionne hors de la boîte. Dès que nous aurons fini d'écrire notre workflow, nous regarderons les captures d'écran sur Github.
Unité et intégration
Ensuite, je veux créer notre travail contenant les étapes d'unité et d'intégration. Concernant le framework utilisé dans cet article, je voudrais vous présenter le framework Jest pour les tests frontaux. Bien sûr, vous n'avez pas besoin d'utiliser Jest si vous ne le souhaitez pas - il existe de nombreuses alternatives parmi lesquelles choisir :
- Cypress fournit également des tests de composants bien adaptés aux tests d'intégration.
- Jasmine est un autre cadre à examiner également.
- Et il y en a beaucoup plus; Je voulais juste en nommer quelques-uns.
Jest est fourni en open source par Facebook. Le framework met l'accent sur la simplicité tout en étant compatible avec de nombreux frameworks et projets JavaScript, notamment Vue.js, React ou Angular. Je peux également utiliser jest en tandem avec TypeScript. Cela rend le framework très intéressant, surtout pour mon petit projet de portfolio, car il est compatible et bien adapté.
Nous pouvons directement commencer l'installation de Jest à partir de ce dossier racine de mon projet de portfolio en saisissant la commande suivante :
npm install --save-dev jest Après l'installation, je suis déjà capable de commencer à écrire des tests. Cependant, cet article se concentre sur l'automatisation de ces tests en utilisant des actions Github. Alors, pour apprendre à écrire un test unitaire ou d'intégration, veuillez vous référer au guide suivant. Lors de la configuration du travail dans notre flux de travail, nous pouvons procéder de la même manière que le travail static-eslint . Donc, la première étape consiste à nouveau à créer un petit script NPM à utiliser dans notre travail plus tard :
"scripts": { "test": "jest", }, Ensuite, nous définirons le travail appelé unit-integration-jest de la même manière que nous l'avons déjà fait pour nos linters auparavant. Ainsi, le flux de travail vérifiera notre projet. En plus de cela, nous utiliserons deux légères différences par rapport à notre premier travail static-eslint :
- Nous utiliserons une action comme étape pour installer Node.
- Après cela, nous utiliserons notre script npm nouvellement créé pour exécuter notre test Jest.
De cette façon, notre travail unit-integration-jest ressemblera à ceci ::
unit-integration-jest: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 # Set up node - name: Run jest uses: actions/setup-node@v1 with: node-version: '12' - run: npm install # Run jest script - run: npm testTests d'interface utilisateur : tests E2E et visuels
Enfin, nous allons écrire notre Job ui-cypress , qui contiendra à la fois des tests E2E et des tests visuels. Il est astucieux de combiner ces deux en un seul travail car j'utiliserai le framework Cypress pour les deux. Bien sûr, vous pouvez envisager d'autres frameworks comme ceux ci-dessous, NightwatchJS et CodeceptJS.
Encore une fois, nous ne couvrirons que les bases pour le configurer dans notre flux de travail GitHub. Si vous voulez apprendre à écrire des tests Cypress en détail, je vous propose un autre de mes guides traitant précisément de cela. Cet article vous guidera à travers tout ce dont nous avons besoin pour définir nos étapes de test E2E. D'accord, nous allons d'abord installer Cypress, de la même manière que nous l'avons fait avec les autres frameworks, en utilisant la commande suivante dans notre dossier racine :
npm install --save-dev cypress Cette fois, nous n'avons pas besoin de définir un script NPM. Cypress nous fournit déjà sa propre action GitHub à utiliser, cypress-io/github-action@v2 . Là-dedans, nous n'avons qu'à configurer certaines choses pour le faire fonctionner :
- Nous devons nous assurer que notre application est entièrement configurée et fonctionne, car un test E2E nécessite la pile d'applications complète disponible.
- Nous devons nommer le navigateur dans lequel nous exécutons notre test E2E.
- Nous devons attendre que le serveur Web fonctionne pleinement, afin que l'ordinateur puisse se comporter comme un véritable utilisateur.
Heureusement, notre action Cypress nous aide à stocker toutes ces configurations avec la zone with . De cette façon, notre tâche GitHub actuelle ressemble à ceci :
steps: - name: Checkout uses: actions/checkout@v2 # Install NPM dependencies, cache them correctly # and run all Cypress tests - name: Cypress Run uses: cypress-io/github-action@v2 with: browser: chrome headless: true # Setup: Nuxt-specific things build: npm run generate start: npm run start wait-on: 'http://localhost:3000'Tests visuels : prêtez quelques yeux à votre test
Rappelez-vous notre première intention d'écrire ce guide : j'ai ma refactorisation importante avec de nombreux changements dans les fichiers SCSS - je veux ajouter des tests dans le cadre de la routine de construction pour m'assurer que cela n'a rien cassé d'autre. Avec des analyses statiques, des tests unitaires, d'intégration et E2E, nous devrions être assez confiants, non ? C'est vrai, mais il y a encore quelque chose que je peux faire pour rendre mon pipeline encore plus résistant et parfait. On pourrait dire qu'il devient le crémier. Surtout lorsqu'il s'agit de refactorisation CSS, un test E2E ne peut être que d'une aide limitée, car il ne fait que ce que vous lui avez dit de faire en l'écrivant dans votre test.
Heureusement, il existe un autre moyen de détecter les bogues en dehors des commandes écrites et, par conséquent, en dehors du concept. C'est ce qu'on appelle des tests visuels : vous pouvez imaginer que ce type de test ressemble à un puzzle de recherche de différences. Techniquement parlant, le test visuel est une comparaison de captures d'écran qui prendra des captures d'écran de votre application et la comparera au statu quo, par exemple, à partir de la branche principale de votre projet. De cette façon, aucun problème de style accidentel ne passera inaperçu, du moins dans les zones où vous utilisez les tests visuels. Cela peut transformer les tests visuels en une bouée de sauvetage pour les grandes refactorisations CSS, du moins d'après mon expérience.
Il existe de nombreux outils de test visuel parmi lesquels choisir et qui valent la peine d'être examinés :
- Percy.io, un outil de Browserstack que j'utilise pour ce guide ;
- Visual Regression Tracker si vous préférez ne pas utiliser une solution SaaS et passer en même temps entièrement open source ;
- Applitools avec prise en charge de l'IA. Il existe un guide passionnant à consulter sur le magazine Smashing à propos de cet outil ;
- Chromatique par Storybook.
Pour ce guide et essentiellement pour mon projet de portfolio, il était essentiel de réutiliser mes tests Cypress existants pour les tests visuels. Comme mentionné précédemment, j'utiliserai Percy pour cet exemple en raison de sa simplicité d'intégration. Bien qu'il s'agisse d'une solution SaaS, de nombreuses parties sont encore fournies en open source, et il existe un plan gratuit qui devrait suffire pour de nombreux projets open source ou autres. Cependant, si vous vous sentez plus à l'aise d'être entièrement auto-hébergé tout en utilisant également un outil open source, vous pouvez essayer Visual Regression Tracker.
Ce guide ne vous donnera qu'un bref aperçu de Percy, qui fournirait autrement le contenu d'un article entièrement nouveau. Cependant, je vais vous donner les informations pour vous aider à démarrer. Si vous voulez plonger dans les détails maintenant, je vous recommande de consulter la documentation de Percy. Alors, comment pouvons-nous donner des yeux à nos tests, pour ainsi dire? Supposons que nous ayons déjà écrit un ou deux tests Cypress maintenant. Imaginez-les ressembler à ceci :
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); });Bien sûr, si nous voulons installer Percy comme solution de test visuel, nous pouvons le faire avec un plugin cypress. Ainsi, comme nous l'avons fait plusieurs fois aujourd'hui, nous l'installons dans notre dossier racine en utilisant NPM :
npm install --save-dev @percy/cli @percy/cypress Ensuite, il vous suffit d'importer le percy/cypress dans votre fichier d'index cypress/support/index.js :
import '@percy/cypress';Cette importation vous permettra d'utiliser la commande snapshot de Percy, qui prendra un instantané de votre application. Dans ce contexte, un instantané signifie une collection de captures d'écran prises à partir de différentes fenêtres ou navigateurs que vous pouvez configurer.
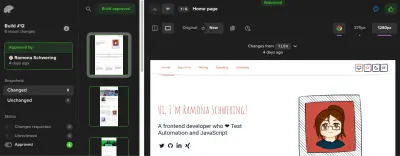
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); // Take a snapshot cy.percySnapshot('Home page'); }); Pour en revenir à notre fichier de flux de travail, je souhaite définir les tests de Percy comme la deuxième étape du travail. Dans celui-ci, nous exécuterons le script npx percy exec -- cypress run pour exécuter notre test avec Percy. Pour connecter nos tests et résultats à notre projet Percy, nous devrons passer notre jeton Percy, caché par un secret GitHub.
steps: # Before: Checkout, NPM, and E2E steps - name: Percy Test run: npx percy exec -- cypress run env: PERCY_TOKEN: ${{ secrets.PERCY_TOKEN }}Pourquoi ai-je besoin d'un jeton Percy ? C'est parce que Percy est une solution SaaS pour maintenir nos captures d'écran. Il conservera les captures d'écran et le statu quo à des fins de comparaison et nous fournira un flux de travail d'approbation des captures d'écran. Là, vous pouvez approuver ou rejeter tout changement à venir :
Affichage de nos travaux : intégration GitHub
Toutes nos félicitations! Nous étions en train de construire avec succès notre tout premier workflow d'action GitHub. Jetons un dernier coup d'œil à notre fichier de workflow complet dans le référentiel de ma page de portfolio. Ne vous demandez-vous pas à quoi cela ressemble dans la pratique? Vous pouvez trouver vos actions GitHub actives dans l'onglet "Actions" de votre référentiel :
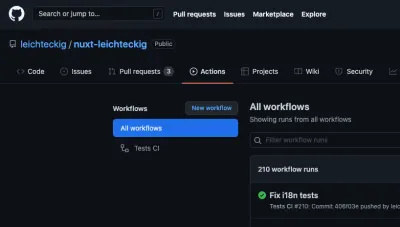
Vous y trouverez tous les flux de travail équivalents à vos fichiers de flux de travail. Si vous jetez un coup d'œil à un flux de travail, par exemple, mon flux de travail "Tests CI", vous pouvez en inspecter tous les travaux :
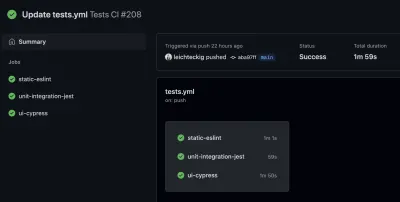
Si vous souhaitez jeter un œil à l'un de vos travaux, vous pouvez également le sélectionner dans la barre latérale. Là, vous pouvez inspecter le journal de vos tâches :
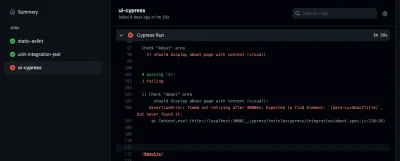
Vous voyez, vous êtes en mesure de détecter les erreurs si elles se produisent à l'intérieur de votre pipeline. Soit dit en passant, l'onglet "action" n'est pas le seul endroit où vous pouvez vérifier les résultats de vos actions GitHub. Vous pouvez également les inspecter dans vos pull requests :
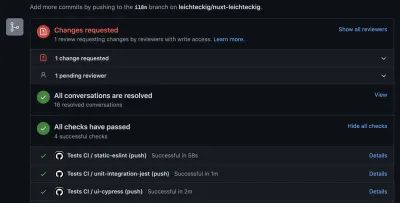
I like to configure those GitHub actions the way they need to be executed successfully: Otherwise, it's not possible to merge any pull requests into my repository.
Conclusion
CI/CD helps us perform even major refactorings — and dramatically minimizes the risk of running into nasty surprises. The testing part of CI/CD is taking care of our codebase being continuously tested and monitored. Consequently, we will notice errors very early, ideally before anyone merges them into your main branch. Plus, we will not get into the predicament of correcting our local tests on the way to work — or even worse — actual errors in our application. I think that's a great perspective, right?
To include this testing build routine, you don't need to be a full DevOps engineer: With the help of some testing frameworks and GitHub actions, you're able to implement these for your side projects as well. I hope I could give you a short kick-off and got you on the right track.
I'm looking forward to seeing more testing pipelines and GitHub action workflows out there! ️
Ressources
- An excellent guide on CI/CD by GitHub
- “The practical test pyramid”, Ham Vocke
- Articles on the testing trophy worth reading, by Kent C.Dodds:
- “Write tests. Not too many. Mostly integration”
- “The Testing Trophy and Testing Classifications”
- “Static vs Unit vs Integration vs E2E Testing for Frontend Apps”
- I referred to some examples of the Cypress real world app
- Documentation of used tools and frameworks:
- GitHub actions
- Eslint docs
- Documentation de plaisanterie
- Documentation Cyprès
- Percy documentation