
Prévision boursière à l'aide de l'apprentissage automatique [Mise en œuvre étape par étape]
Publié: 2021-02-26Table des matières
introduction
La prévision et l'analyse du marché boursier font partie des tâches les plus compliquées à accomplir. Il y a plusieurs raisons à cela, telles que la volatilité du marché et tant d'autres facteurs dépendants et indépendants pour décider de la valeur d'une action particulière sur le marché. Ces facteurs rendent très difficile pour tout analyste boursier de prédire la hausse et la baisse avec des degrés de précision élevés.
Cependant, avec l'avènement de l'apprentissage automatique et de ses algorithmes robustes, les derniers développements en matière d'analyse de marché et de prédiction boursière ont commencé à intégrer ces techniques dans la compréhension des données boursières.
En bref, les algorithmes d'apprentissage automatique sont largement utilisés par de nombreuses organisations pour analyser et prédire les valeurs des actions. Cet article passera par une mise en œuvre simple de l'analyse et de la prédiction des valeurs des stocks d'un magasin de détail en ligne mondial populaire à l'aide de plusieurs algorithmes d'apprentissage automatique en Python.
Énoncé du problème
Avant d'aborder la mise en place du programme pour prédire les valeurs boursières, visualisons les données sur lesquelles nous allons travailler. Ici, nous analyserons la valeur des actions de Microsoft Corporation (MSFT) de la National Association of Securities Dealers Automated Quotations (NASDAQ). Les données sur la valeur des actions seront présentées sous la forme d'un fichier séparé par des virgules (.csv), qui peut être ouvert et visualisé à l'aide d'Excel ou d'un tableur.
MSFT a ses actions enregistrées au NASDAQ et ses valeurs sont mises à jour chaque jour ouvrable du marché boursier. Notez que le marché n'autorise pas les échanges les samedis et dimanches ; il y a donc un décalage entre les deux dates. Pour chaque date, la valeur d'ouverture du stock, les valeurs les plus élevées et les plus basses de ce stock les mêmes jours sont notées, ainsi que la valeur de clôture à la fin de la journée.
La valeur de clôture ajustée indique la valeur de l'action après la publication des dividendes (trop technique !). De plus, le volume total des actions sur le marché est également indiqué. Avec ces données, il appartient au travail d'un apprentissage automatique/scientifique des données d'étudier les données et de mettre en œuvre plusieurs algorithmes capables d'extraire des modèles de l'historique des actions de Microsoft Corporation. Les données.

Longue mémoire à court terme
Pour développer un modèle d'apprentissage automatique pour prédire le cours des actions de Microsoft Corporation, nous utiliserons la technique de la mémoire à court terme longue (LSTM). Ils sont utilisés pour apporter de petites modifications à l'information par des multiplications et des additions. Par définition, la mémoire à long terme (LSTM) est une architecture de réseau de neurones récurrents artificiels (RNN) utilisée dans l'apprentissage en profondeur.
Contrairement aux réseaux de neurones à rétroaction standard, LSTM a des connexions de rétroaction. Il peut traiter des points de données uniques (tels que des images) et des séquences de données entières (telles que la parole ou la vidéo). Pour comprendre le concept derrière LSTM, prenons un exemple simple d'un avis client en ligne sur un téléphone mobile.
Supposons que nous voulions acheter le téléphone portable, nous nous référons généralement aux avis nets d'utilisateurs certifiés. En fonction de leur réflexion et de leurs contributions, nous décidons si le mobile est bon ou mauvais, puis nous l'achetons. Au fur et à mesure que nous lisons les critiques, nous recherchons des mots-clés tels que "incroyable", "bon appareil photo", "meilleure batterie de secours" et de nombreux autres termes liés à un téléphone mobile.
On a tendance à ignorer les mots usuels en anglais comme « it », « gave », « this », etc. Ainsi, lorsque l'on décide d'acheter ou non le téléphone mobile, on ne retient que ces mots-clés définis ci-dessus. Très probablement, nous oublions les autres mots.
C'est de la même manière que fonctionne l'algorithme de mémoire à court terme. Il ne se souvient que des informations pertinentes et les utilise pour faire des prédictions en ignorant les données non pertinentes. De cette façon, nous devons construire un modèle LSTM qui ne reconnaît essentiellement que les données essentielles sur ce stock et omet ses valeurs aberrantes.
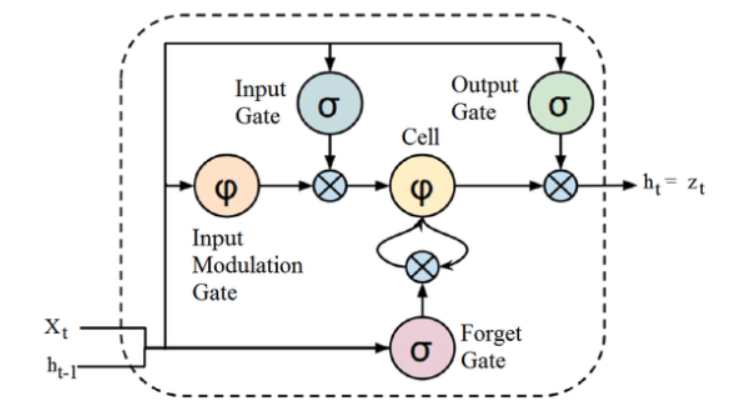
La source
Bien que la structure ci-dessus d'une architecture LSTM puisse sembler intrigante au premier abord, il suffit de se rappeler que LSTM est une version avancée des réseaux de neurones récurrents qui conservent la mémoire pour traiter des séquences de données. Il peut supprimer ou ajouter des informations à l'état de la cellule, soigneusement régulées par des structures appelées portes.
L'unité LSTM comprend une cellule, une porte d'entrée, une porte de sortie et une porte d'oubli. La cellule se souvient des valeurs sur des intervalles de temps arbitraires, et les trois portes régulent le flux d'informations entrant et sortant de la cellule.
Mise en œuvre du programme
Nous allons passer à la partie où nous utilisons le LSTM pour prédire la valeur du stock à l'aide de Machine Learning en Python.
Étape 1 - Importation des bibliothèques
Comme nous le savons tous, la première étape consiste à importer les bibliothèques nécessaires pour prétraiter les données boursières de Microsoft Corporation et les autres bibliothèques requises pour créer et visualiser les sorties du modèle LSTM. Pour cela, nous utiliserons la librairie Keras sous le framework TensorFlow. Les modules requis sont importés de la bibliothèque Keras individuellement.
#Importer les bibliothèques
importer des pandas en tant que PD
importer NumPy en tant que np
%matplotlib en ligne
importer matplotlib. pyplot comme plt
importer matplotlib
de sklearn. Prétraitement de l'importation MinMaxScaler
de Kéras. calques importés LSTM, Dense, Dropout
depuis sklearn.model_selection importer TimeSeriesSplit
de sklearn.metrics importer mean_squared_error, r2_score
importer matplotlib. dates comme mandats
de sklearn. Prétraitement de l'importation MinMaxScaler
de sklearn importer linear_model
de Kéras. Importation de modèles Séquentielle
de Kéras. Importation de calques dense
importer Keras. Backend comme K
de Kéras. Les rappels importent EarlyStopping
de Kéras. Les optimiseurs importent Adam
de Kéras. Importation de modèles load_model
de Kéras. Importation de calques LSTM
de Kéras. utils.vis_utils importer plot_model
Étape 2 - Obtenir la visualisation des données
À l'aide de la bibliothèque de lecteurs de données Pandas, nous allons télécharger les données de stock du système local sous forme de fichier Comma Separated Value (.csv) et les stocker dans un pandas DataFrame. Enfin, nous verrons également les données.
#Obtenir le jeu de données
df = pd.read_csv(“MicrosoftStockData.csv”,na_values=['null'],index_col='Date',parse_dates=True,infer_datetime_format=True)
df.head()
Obtenez une certification AI en ligne auprès des meilleures universités du monde - Masters, Executive Post Graduate Programs et Advanced Certificate Program in ML & AI pour accélérer votre carrière.
Étape 3 - Imprimez la forme DataFrame et vérifiez les valeurs nulles.
Dans cette autre étape cruciale, nous imprimons d'abord la forme de l'ensemble de données. Pour nous assurer qu'il n'y a pas de valeurs nulles dans le bloc de données, nous les vérifions. La présence de valeurs nulles dans l'ensemble de données a tendance à causer des problèmes lors de la formation car elles agissent comme des valeurs aberrantes entraînant une grande variance dans le processus de formation.
#Imprimer la forme de la trame de données et vérifier les valeurs nulles
print("Forme de la trame de données : ", df. forme)
print("Valeur nulle présente : ", df.IsNull().values.any())
>> Forme de la trame de données : (7334, 6)
>>Valeur nulle présente : Faux
| Date | Ouvrir | Haut | Meugler | Fermer | Fermer ajusté | Le volume |
| 1990-01-02 | 0,605903 | 0,616319 | 0,598090 | 0,616319 | 0,447268 | 53033600 |
| 1990-01-03 | 0,621528 | 0,626736 | 0,614583 | 0,619792 | 0,449788 | 113772800 |
| 1990-01-04 | 0,619792 | 0,638889 | 0,616319 | 0,638021 | 0,463017 | 125740800 |
| 1990-01-05 | 0,635417 | 0,638889 | 0,621528 | 0,622396 | 0,451678 | 69564800 |
| 1990-01-08 | 0,621528 | 0,631944 | 0,614583 | 0,631944 | 0,458607 | 58982400 |
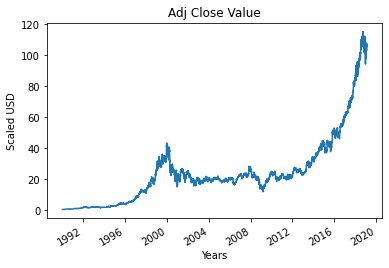
Étape 4 - Tracé de la valeur de clôture ajustée réelle
La valeur de sortie finale qui doit être prédite à l'aide du modèle d'apprentissage automatique est la valeur de clôture ajustée. Cette valeur représente la valeur de clôture de l'action ce jour particulier de négociation en bourse.
#Tracer la valeur de fermeture True Adj
df['Ajustement Fermé'].plot()
Étape 5 - Définition de la variable cible et sélection des fonctionnalités
Dans l'étape suivante, nous attribuons la colonne de sortie à la variable cible. Dans ce cas, il s'agit de la valeur relative ajustée du Microsoft Stock. De plus, nous sélectionnons également les caractéristiques qui agissent comme la variable indépendante de la variable cible (variable dépendante). Pour tenir compte de l'objectif de la formation, nous choisissons quatre caractéristiques, qui sont :

- Ouvrir
- Haut
- Meugler
- Le volume
#Définir la variable cible
output_var = PD.DataFrame(df['Adj Close'])
#Sélection des fonctionnalités
fonctionnalités = ['Ouvert', 'Haut', 'Bas', 'Volume']
Étape 6 - Mise à l'échelle
Pour réduire le coût de calcul des données dans le tableau, nous allons réduire les valeurs de stock à des valeurs comprises entre 0 et 1. De cette façon, toutes les données en grand nombre sont réduites, réduisant ainsi l'utilisation de la mémoire. De plus, nous pouvons obtenir plus de précision en réduisant l'échelle car les données ne sont pas réparties en valeurs énormes. Ceci est effectué par la classe MinMaxScaler de la bibliothèque sci-kit-learn.
#Mise à l'échelle
scaler = MinMaxScaler()
feature_transform = scaler.fit_transform(df[features])
feature_transform= pd.DataFrame(columns=features, data=feature_transform, index=df.index)
feature_transform.head()
| Date | Ouvrir | Haut | Meugler | Le volume |
| 1990-01-02 | 0,000129 | 0,000105 | 0,000129 | 0,064837 |
| 1990-01-03 | 0,000265 | 0,000195 | 0,000273 | 0,144673 |
| 1990-01-04 | 0,000249 | 0,000300 | 0,000288 | 0,160404 |
| 1990-01-05 | 0,000386 | 0,000300 | 0,000334 | 0,086566 |
| 1990-01-08 | 0,000265 | 0,000240 | 0,000273 | 0,072656 |
Comme mentionné ci-dessus, nous voyons que les valeurs des variables de caractéristique sont réduites à des valeurs plus petites par rapport aux valeurs réelles données ci-dessus.
Étape 7 - Fractionnement en un ensemble d'apprentissage et un ensemble de test.
Avant d'introduire les données dans le modèle d'apprentissage, nous devons diviser l'ensemble de données en ensemble d'apprentissage et de test. Le modèle Machine Learning LSTM sera formé sur les données présentes dans l'ensemble d'apprentissage et testé sur l'ensemble de test pour la précision et la rétropropagation.
Pour cela, nous utiliserons la classe TimeSeriesSplit de la bibliothèque sci-kit-learn. Nous avons défini le nombre de fractionnements sur 10, ce qui signifie que 10 % des données seront utilisées comme ensemble de test et que 90 % des données seront utilisées pour la formation du modèle LSTM. L'avantage d'utiliser cette division de séries chronologiques est que les échantillons de données de séries chronologiques fractionnés sont observés à des intervalles de temps fixes.
#Splitting en ensemble d'entraînement et en ensemble de test
timesplit= TimeSeriesSplit(n_splits=10)
pour train_index, test_index dans timesplit.split(feature_transform):
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
Étape 8 - Traitement des données pour LSTM
Une fois que les ensembles de formation et de test sont prêts, nous pouvons alimenter les données dans le modèle LSTM une fois qu'il est construit. Avant cela, nous devons convertir les données de l'ensemble d'entraînement et de test en un type de données que le modèle LSTM acceptera. Nous convertissons d'abord les données de formation et les données de test en tableaux NumPy, puis les remodelons au format (nombre d'échantillons, 1, nombre de fonctionnalités) car le LSTM exige que les données soient alimentées sous forme 3D. Comme nous le savons, le nombre d'échantillons dans l'ensemble d'apprentissage est de 90 % de 7334, soit 6667, et le nombre de caractéristiques est de 4, l'ensemble d'apprentissage est remodelé en (6667, 1, 4). De même, l'ensemble de test est également remodelé.
#Traiter les données pour LSTM
trainX =np.array(X_train)
testX =np.array(X_test)
X_train = trainX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
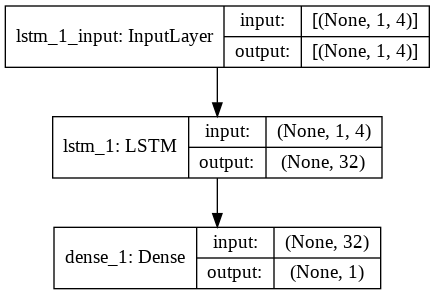
Étape 9 - Construire le modèle LSTM
Enfin, nous arrivons à l'étape où nous construisons le modèle LSTM. Ici, nous créons un modèle Keras séquentiel avec une couche LSTM. La couche LSTM a 32 unités et est suivie d'une couche dense de 1 neurone.
Nous utilisons Adam Optimizer et l'erreur quadratique moyenne comme fonction de perte pour compiler le modèle. Ces deux sont la combinaison la plus préférée pour un modèle LSTM. De plus, le modèle est également tracé et affiché ci-dessous.
#Construire le modèle LSTM
lstm = Séquentiel()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), activation='relu', return_sequences=False))
lstm.add(Dense(1))
lstm.compile(loss='mean_squared_error', optimiseur='adam')
plot_model(lstm, show_shapes=True, show_layer_names=True)
Étape 10 - Formation du modèle
Enfin, nous formons le modèle LSTM conçu ci-dessus sur les données de formation pour 100 époques avec une taille de lot de 8 en utilisant la fonction d'ajustement.
#Formation Modèle
history = lstm.fit(X_train, y_train, epochs=100, batch_size=8, verbose=1, shuffle=False)
Epoque 1/100
834/834 [==============================] – 3s 2ms/pas – perte : 67.1211
Époque 2/100
834/834 [==============================] – 1s 2ms/pas – perte : 70.4911
Epoque 3/100
834/834 [==============================] – 1s 2ms/pas – perte : 48.8155
Epoque 4/100
834/834 [==============================] – 1s 2ms/pas – perte : 21.5447
Epoque 5/100
834/834 [==============================] – 1s 2ms/pas – perte : 6.1709
Époque 6/100
834/834 [==============================] – 1s 2ms/pas – perte : 1.8726
Epoque 7/100
834/834 [=============================] – 1s 2ms/pas – perte : 0.9380
Epoque 8/100
834/834 [==============================] – 2s 2ms/pas – perte : 0.6566
Epoque 9/100
834/834 [==============================] – 1s 2ms/pas – perte : 0.5369
Epoque 10/100
834/834 [==============================] – 2s 2ms/pas – perte : 0.4761
.
.
.
.
Epoque 95/100
834/834 [==============================] – 1s 2ms/pas – perte : 0.4542
Epoque 96/100
834/834 [==============================] – 2s 2ms/pas – perte : 0.4553
Epoque 97/100
834/834 [==============================] – 1s 2ms/pas – perte : 0.4565
Epoque 98/100
834/834 [==============================] – 1s 2ms/pas – perte : 0.4576
Epoque 99/100
834/834 [==============================] – 1s 2ms/pas – perte : 0.4588
Epoque 100/100
834/834 [==============================] – 1s 2ms/pas – perte : 0.4599
Enfin, nous voyons que la valeur de perte a diminué de façon exponentielle au fil du temps au cours du processus de formation de 100 époques et a atteint une valeur de 0,4599
Étape 11 - Prédiction LSTM
Avec notre modèle prêt, il est temps d'utiliser le modèle formé à l'aide du réseau LSTM sur l'ensemble de test et de prédire la valeur de clôture adjacente de l'action Microsoft. Ceci est réalisé en utilisant la simple fonction de prédiction sur le modèle lstm construit.
Prédiction #LSTM
y_pred= lstm.predict(X_test)
Étape 12 - Valeur de clôture ajustée réelle vs prévue - LSTM
Enfin, comme nous avons prédit les valeurs de l'ensemble de test, nous pouvons tracer le graphique pour comparer les valeurs réelles d'Adj Close et la valeur prédite d'Adj Close par le modèle LSTM Machine Learning.
#True vs Predicted Adj Close Value - LSTM
plt.plot(y_test, label='True Value')
plt.plot(y_pred, label='Valeur LSTM')
plt.title ("Prédiction par LSTM")
plt.xlabel('Échelle de temps')
plt.ylabel('USD mis à l'échelle')
plt.légende()
plt.show()
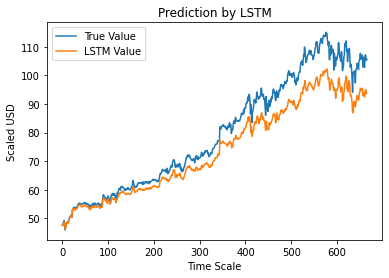
Le graphique ci-dessus montre qu'un modèle est détecté par le modèle de réseau LSTM unique très basique construit ci-dessus. En affinant plusieurs paramètres et en ajoutant plus de couches LSTM au modèle, nous pouvons obtenir une représentation plus précise de la valeur des actions d'une entreprise donnée.
Conclusion
Si vous souhaitez en savoir plus sur les exemples d'intelligence artificielle, l'apprentissage automatique, consultez le programme Executive PG d'IIIT-B & upGrad en apprentissage automatique et IA , conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas. & affectations, statut IIIT-B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Pouvez-vous prédire le marché boursier en utilisant l'apprentissage automatique ?
Aujourd'hui, nous disposons d'un certain nombre d'indicateurs pour aider à prévoir les tendances du marché. Cependant, nous n'avons pas besoin de chercher plus loin qu'un ordinateur puissant pour trouver les indicateurs les plus précis pour le marché boursier. Le marché boursier est un système ouvert et peut être considéré comme un réseau complexe. Le réseau est constitué des relations entre les actions, les entreprises, les investisseurs et les volumes d'échanges. En utilisant un algorithme d'exploration de données comme la machine à vecteurs de support, vous pouvez appliquer une formule mathématique pour extraire les relations entre ces variables. Le marché boursier est maintenant au-delà de la prédiction humaine.
Quel algorithme est le meilleur pour la prédiction du marché boursier ?
Pour de meilleurs résultats, vous devez utiliser la régression linéaire. La régression linéaire est une approche statistique utilisée pour déterminer la relation entre deux variables différentes. Dans cet exemple, les variables sont le prix et le temps. Dans la prévision boursière, le prix est la variable indépendante et le temps est la variable dépendante. Si une relation linéaire entre ces deux variables peut être déterminée, il est alors possible de prédire avec précision la valeur du stock à tout moment dans le futur.
La prévision boursière est-elle un problème de classification ou de régression ?
Avant de répondre, nous devons comprendre ce que signifient les prévisions boursières. Est-ce un problème de classification binaire ou un problème de régression ? Supposons que nous voulions prédire l'avenir d'un titre, où l'avenir signifie le jour, la semaine, le mois ou l'année suivant. Si la performance passée de l'action à un moment donné est l'entrée et l'avenir est la sortie, il s'agit alors d'un problème de régression. Si la performance passée d'une action et l'avenir d'une action sont indépendants, alors c'est un problème de classification.