
Utilisation de SSE au lieu de WebSockets pour un flux de données unidirectionnel sur HTTP/2
Publié: 2022-03-10Lors de la création d'une application Web, il faut tenir compte du type de mécanisme de livraison qu'ils vont utiliser. Disons que nous avons une application multiplateforme qui fonctionne avec des données en temps réel ; une application boursière permettant d'acheter ou de vendre des actions en temps réel. Cette application est composée de widgets qui apportent une valeur différente aux différents utilisateurs.
En ce qui concerne la livraison des données du serveur au client, nous sommes limités à deux approches générales : le client pull ou le server push . Comme exemple simple avec n'importe quelle application Web, le client est le navigateur Web. Lorsque le site Web de votre navigateur demande des données au serveur, cela s'appelle le client pull . À l'inverse, lorsque le serveur envoie de manière proactive des mises à jour à votre site Web, cela s'appelle un push de serveur .
De nos jours, il existe plusieurs façons de les mettre en œuvre :
- Interrogation longue/courte (appel client)
- WebSockets (poussée du serveur)
- Événements envoyés par le serveur (poussée du serveur).
Nous allons examiner en profondeur les trois alternatives après avoir défini les exigences de notre analyse de rentabilisation.
L'analyse de rentabilisation
Afin de pouvoir livrer rapidement et plug'n'play de nouveaux widgets pour notre application boursière sans redéploiement de l'ensemble de la plateforme, nous avons besoin qu'ils soient autonomes et gèrent leurs propres entrées/sorties de données. Les widgets ne sont en aucun cas couplés les uns aux autres. Dans le cas idéal, tous vont s'abonner à un point de terminaison d'API et commencer à en obtenir des données. Outre un délai de mise sur le marché plus rapide des nouvelles fonctionnalités, cette approche nous donne la possibilité d'exporter du contenu sur des sites Web tiers, tandis que nos widgets apportent tout ce dont ils ont besoin par eux-mêmes.
Le principal écueil ici est que le nombre de connexions va croître de manière linéaire avec le nombre de widgets que nous avons et nous allons atteindre la limite des navigateurs pour le nombre de requêtes HTTP traitées en même temps.
Les données que nos widgets vont recevoir sont principalement composées de chiffres et de mises à jour de leurs chiffres : la réponse initiale contient dix actions avec certaines valeurs de marché pour elles. Cela inclut les mises à jour d'ajout/suppression d'actions et les mises à jour des valeurs marchandes de celles actuellement présentées. Nous transférons aussi rapidement que possible de petites quantités de chaînes JSON pour chaque mise à jour.
HTTP/2 permet le multiplexage des requêtes provenant du même domaine, ce qui signifie que nous ne pouvons obtenir qu'une seule connexion pour plusieurs réponses. Cela semble pouvoir résoudre notre problème. Nous commençons par explorer les différentes options pour obtenir les données et voir ce que nous pouvons en tirer.
- Nous allons utiliser NGINX pour l'équilibrage de charge et le proxy pour cacher tous nos points de terminaison derrière le même domaine. Cela nous permettra d'utiliser le multiplexage HTTP/2 prêt à l'emploi.
- Nous voulons utiliser efficacement le réseau et la batterie des appareils mobiles.
Les Alternatives
Interrogation longue

L'attraction client est l'équivalent de la mise en œuvre logicielle de l'enfant ennuyeux assis sur le siège arrière de votre voiture qui demande constamment : « Y sommes-nous déjà ? » En bref, le client demande au serveur des données. Le serveur n'a pas de données et attend un certain temps avant d'envoyer la réponse :
- Si quelque chose apparaît pendant l'attente, le serveur l'envoie et ferme la requête ;
- S'il n'y a rien à envoyer et que le temps d'attente maximum est atteint, le serveur envoie une réponse indiquant qu'il n'y a pas de données ;
- Dans les deux cas, le client ouvre la prochaine demande de données ;
- Faire mousser, rincer, répéter.
Les appels AJAX fonctionnent sur le protocole HTTP, ce qui signifie que les requêtes vers le même domaine doivent être multiplexées par défaut. Cependant, nous avons rencontré plusieurs problèmes en essayant de faire fonctionner cela comme requis. Certains des pièges que nous avons identifiés avec notre approche des widgets :
En-têtes
Chaque requête et réponse d'interrogation est un message HTTP complet et contient un ensemble complet d'en-têtes HTTP dans le cadrage du message. Dans notre cas où nous avons de petits messages fréquents, les en-têtes représentent en fait le plus grand pourcentage des données transmises. La charge utile utile réelle est bien inférieure au total des octets transmis (par exemple, 15 Ko d'en-têtes pour 5 Ko de données).Latence maximale
Une fois que le serveur a répondu, il ne peut plus envoyer de données au client jusqu'à ce que le client envoie la requête suivante. Alors que la latence moyenne pour une interrogation longue est proche d'un transit réseau, la latence maximale est supérieure à trois transits réseau : réponse, demande, réponse. Cependant, en raison de la perte et de la retransmission de paquets, la latence maximale pour tout protocole TCP/IP sera supérieure à trois transits réseau (évitable avec le pipeline HTTP). Alors que dans une connexion LAN directe, ce n'est pas un gros problème, cela devient un problème lorsque l'on est en déplacement et que l'on change de cellules de réseau. Dans une certaine mesure, cela est observé avec SSE et WebSockets, mais l'effet est plus important avec les sondages.Etablissement de la connexion
Bien que cela puisse être évité en utilisant une connexion HTTP persistante réutilisable pour de nombreuses demandes d'interrogation, il est difficile de chronométrer en conséquence tous vos composants pour interroger dans des durées courtes pour maintenir la connexion active. Finalement, en fonction des réponses du serveur, vos sondages seront désynchronisés.Dégradation des performances
Un client (ou un serveur) à interrogation longue qui est sous charge a une tendance naturelle à se dégrader en termes de performances au détriment de la latence des messages. Lorsque cela se produit, les événements poussés vers le client sont mis en file d'attente. Cela dépend vraiment de la mise en œuvre; dans notre cas, nous devons agréger toutes les données car nous envoyons des événements d'ajout/suppression/mise à jour à nos widgets.Délais d'attente
Les demandes d'interrogation longues doivent rester en attente jusqu'à ce que le serveur ait quelque chose à envoyer au client. Cela peut entraîner la fermeture de la connexion par le serveur proxy s'il reste inactif trop longtemps.Multiplexage
Cela peut se produire si les réponses se produisent en même temps via une connexion HTTP/2 persistante. Cela peut être délicat à faire car les réponses aux sondages ne peuvent pas vraiment être synchronisées.
Pour en savoir plus sur les problèmes du monde réel que l'on pourrait rencontrer avec de longs sondages, cliquez ici .
WebSockets

Comme premier exemple de la méthode push du serveur , nous allons examiner WebSockets.
Via MDN :
WebSockets est une technologie avancée qui permet d'ouvrir une session de communication interactive entre le navigateur de l'utilisateur et un serveur. Avec cette API, vous pouvez envoyer des messages à un serveur et recevoir des réponses basées sur des événements sans avoir à interroger le serveur pour obtenir une réponse.
Il s'agit d'un protocole de communication fournissant des canaux de communication en duplex intégral sur une seule connexion TCP.
HTTP et WebSockets sont tous deux situés au niveau de la couche application du modèle OSI et dépendent donc de TCP au niveau de la couche 4.
- Application
- Présentation
- Session
- Transport
- Réseau
- Liaison de données
- Physique
La RFC 6455 stipule que WebSocket "est conçu pour fonctionner sur les ports HTTP 80 et 443 ainsi que pour prendre en charge les proxys et intermédiaires HTTP", le rendant ainsi compatible avec le protocole HTTP. Pour assurer la compatibilité, la poignée de main WebSocket utilise l'en-tête HTTP Upgrade pour passer du protocole HTTP au protocole WebSocket.
Il y a aussi un très bon article qui explique tout ce qu'il faut savoir sur les WebSockets sur Wikipedia. Je vous encourage à le lire.
Après avoir établi que les sockets pouvaient réellement fonctionner pour nous, nous avons commencé à explorer leurs capacités dans notre analyse de rentabilisation, et nous nous sommes attaqués mur après mur après mur.
Serveurs proxy : En général, il existe quelques problèmes différents avec les WebSockets et les proxy :
- Le premier est lié aux fournisseurs de services Internet et à la manière dont ils gèrent leurs réseaux. Des problèmes avec les proxys Radius ont bloqué les ports, etc.
- Le deuxième type de problèmes est lié à la façon dont le proxy est configuré pour gérer le trafic HTTP non sécurisé et les connexions de longue durée (l'impact est atténué avec HTTPS).
- Le troisième problème "avec WebSockets, vous êtes obligé d'exécuter des proxys TCP par opposition aux proxys HTTP. Les proxys TCP ne peuvent pas injecter d'en-têtes, réécrire des URL ou effectuer de nombreux rôles que nous laissons traditionnellement prendre en charge par nos proxys HTTP.
Un nombre de connexions : La fameuse limite de connexion pour les requêtes HTTP qui tourne autour du chiffre 6, ne s'applique pas aux WebSockets. 50 prises = 50 connexions. Dix onglets de navigateur par 50 sockets = 500 connexions et ainsi de suite. Étant donné que WebSocket est un protocole différent pour la livraison de données, il n'est pas automatiquement multiplexé sur les connexions HTTP/2 (il ne fonctionne pas du tout sur HTTP). La mise en œuvre d'un multiplexage personnalisé à la fois sur le serveur et sur le client est trop compliquée pour rendre les sockets utiles dans l'analyse de rentabilisation spécifiée. De plus, cela couple nos widgets à notre plate-forme car ils auront besoin d'une sorte d'API sur le client pour s'abonner et nous ne sommes pas en mesure de les distribuer sans cela.
Équilibrage de charge (sans multiplexage) : Si chaque utilisateur ouvre
nnombre de sockets, un bon équilibrage de charge est très compliqué. Lorsque vos serveurs sont surchargés et que vous devez créer de nouvelles instances et résilier les anciennes en fonction de la mise en œuvre de votre logiciel, les actions entreprises lors de la "reconnexion" peuvent déclencher une chaîne massive d'actualisations et de nouvelles demandes de données qui surchargeront votre système. . Les WebSockets doivent être maintenus à la fois sur le serveur et sur le client. Il n'est pas possible de déplacer les connexions de socket vers un autre serveur si le serveur actuel subit une charge élevée. Ils doivent être fermés et rouverts.DoS : Ceci est généralement géré par des proxies HTTP frontaux qui ne peuvent pas être gérés par des proxies TCP qui sont nécessaires pour les WebSockets. On peut se connecter au socket et commencer à inonder vos serveurs de données. Les WebSockets vous rendent vulnérable à ce type d'attaques.
Réinventer la roue : Avec WebSockets, on doit gérer tout seul de nombreux problèmes qui sont pris en charge en HTTP.
Pour en savoir plus sur les problèmes réels avec WebSockets, cliquez ici.
Certains bons cas d'utilisation de WebSockets sont les chats et les jeux multijoueurs dans lesquels les avantages l'emportent sur les problèmes de mise en œuvre. Avec leur principal avantage étant la communication duplex, et nous n'en avons pas vraiment besoin, nous devons passer à autre chose.
Impacter
Nous obtenons des frais généraux opérationnels accrus en termes de développement, de test et de mise à l'échelle ; le logiciel et son infrastructure informatique avec à la fois : polling et WebSockets.
Nous rencontrons le même problème sur les appareils mobiles et les réseaux avec les deux. La conception matérielle de ces appareils maintient une connexion ouverte en maintenant l'antenne et la connexion au réseau cellulaire actives. Cela entraîne une réduction de la durée de vie de la batterie, de la chaleur et, dans certains cas, des frais supplémentaires pour les données.
Mais pourquoi avons-nous encore des problèmes avec les appareils mobiles ?
Considérons comment l'appareil mobile par défaut se connecte à Internet :
Une explication simple du fonctionnement du réseau mobile : les appareils mobiles ont généralement une antenne de faible puissance qui peut recevoir des données d'une cellule. De cette façon, une fois que l'appareil reçoit les données d'un appel entrant, il démarre l'antenne en duplex intégral afin d'établir l'appel. La même antenne est utilisée chaque fois que vous souhaitez passer un appel ou accéder à Internet (si aucun WiFi n'est disponible). L'antenne en duplex intégral doit établir une connexion au réseau cellulaire et procéder à une authentification. Une fois la connexion établie, il y a une communication entre votre appareil et la cellule afin de faire notre demande de réseau. Nous sommes redirigés vers le proxy interne du fournisseur de services mobiles qui gère les requêtes Internet. Dès lors, la procédure est déjà connue : il demande à un DNS où se trouve réellement www.domainname.ext , reçoit l'URI vers la ressource, et finit par être redirigé vers celle-ci.
Ce processus, comme vous pouvez l'imaginer, consomme beaucoup d'énergie de la batterie. C'est la raison pour laquelle les vendeurs de téléphones portables donnent un temps de veille de quelques jours et un temps de conversation de quelques heures seulement.
Sans WiFi, les WebSockets et les sondages nécessitent que l'antenne en duplex intégral fonctionne presque constamment. Ainsi, nous sommes confrontés à une consommation de données accrue et à une consommation d'énergie accrue - et selon l'appareil - à la chaleur également.

Au moment où les choses semblent sombres, il semble que nous devrons reconsidérer les exigences commerciales de notre application. Manquons-nous quelque chose?
ESS
Via MDN :
« L'interface EventSource est utilisée pour recevoir les événements envoyés par le serveur. Il se connecte à un serveur via HTTP et reçoit des événements au format texte/flux d'événements sans fermer la connexion.
La principale différence avec l'interrogation est que nous n'obtenons qu'une seule connexion et que nous la traversons par un flux d'événements. L'interrogation longue crée une nouvelle connexion pour chaque pull - par exemple les en-têtes généraux et d'autres problèmes auxquels nous avons été confrontés là-bas.
Via html5doctor.com :
Les événements envoyés par le serveur sont des événements en temps réel émis par le serveur et reçus par le navigateur. Ils sont similaires aux WebSockets en ce sens qu'ils se produisent en temps réel, mais il s'agit en fait d'une méthode de communication unidirectionnelle à partir du serveur.
Cela semble un peu étrange, mais après réflexion, notre principal flux de données va du serveur au client et, dans beaucoup moins d'occasions, du client au serveur.
Il semble que nous puissions l'utiliser pour notre analyse de rentabilisation principale consistant à fournir des données. Nous pouvons résoudre les achats des clients en envoyant une nouvelle requête car le protocole est unidirectionnel et le client ne peut pas envoyer de messages au serveur via celui-ci. Cela finira par avoir le délai de l'antenne en duplex intégral pour démarrer sur les appareils mobiles. Cependant, nous pouvons vivre avec cela de temps en temps - ce retard est mesuré en millisecondes après tout.
Caractéristiques uniques
- Le flux de connexion provient du serveur et est en lecture seule.
- Ils utilisent des requêtes HTTP régulières pour la connexion persistante, pas un protocole spécial. Obtenir le multiplexage sur HTTP/2 prêt à l'emploi.
- Si la connexion est interrompue, EventSource déclenche un événement d'erreur et tente automatiquement de se reconnecter. Le serveur peut également contrôler le délai avant que le client ne tente de se reconnecter (expliqué plus en détail ultérieurement).
- Les clients peuvent envoyer un identifiant unique avec des messages. Lorsqu'un client essaie de se reconnecter après une connexion interrompue, il enverra le dernier ID connu. Ensuite, le serveur peut voir que le client a manqué
nnombre de messages et envoyer l'arriéré de messages manqués lors de la reconnexion.
Exemple d'implémentation client
Ces événements sont similaires aux événements JavaScript ordinaires qui se produisent dans le navigateur - comme les événements de clic - sauf que nous pouvons contrôler le nom de l'événement et les données qui lui sont associées.
Voyons l'aperçu du code simple pour le côté client :
// subscribe for messages var source = new EventSource('URL'); // handle messages source.onmessage = function(event) { // Do something with the data: event.data; };Ce que nous voyons dans l'exemple, c'est que le côté client est assez simple. Il se connecte à notre source et attend de recevoir des messages.
Pour permettre aux serveurs d'envoyer des données vers des pages Web via HTTP ou à l'aide de protocoles d'envoi de serveur dédiés, la spécification introduit l'interface "EventSource" sur le client. L'utilisation de cette API consiste à créer un objet `EventSource` et à enregistrer un écouteur d'événement.
L'implémentation du client pour WebSockets ressemble beaucoup à ceci. La complexité des sockets réside dans l'infrastructure informatique et la mise en œuvre du serveur.
Source de l'événement
Chaque objet EventSource possède les membres suivants :
- URL : définie lors de la construction.
- Requête : initialement est nulle.
- Temps de reconnexion : valeur en ms (valeur définie par l'utilisateur-agent).
- ID du dernier événement : initialement une chaîne vide.
- Etat prêt : état de la connexion.
- CONNEXION (0)
- OUVERT (1)
- FERMÉ (2)
Hormis l'URL, tous sont traités comme privés et ne sont pas accessibles de l'extérieur.
Événements intégrés :
- Ouvrir
- Un message
- Erreur
Gestion des interruptions de connexion
La connexion est automatiquement rétablie par le navigateur en cas de coupure. Le serveur peut envoyer un délai d'expiration pour réessayer ou fermer définitivement la connexion. Dans un tel cas, le navigateur se conformera soit en essayant de se reconnecter après le délai d'attente, soit en n'essayant pas du tout si la connexion a reçu un message de fin. Cela semble assez simple - et c'est en fait le cas.
Exemple d'implémentation de serveur
Eh bien, si le client est si simple, peut-être que l'implémentation du serveur est complexe ?
Eh bien, le gestionnaire de serveur pour SSE peut ressembler à ceci :
function handler(response) { // setup headers for the response in order to get the persistent HTTP connection response.writeHead(200, { 'Content-Type': 'text/event-stream', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive' }); // compose the message response.write('id: UniqueID\n'); response.write("data: " + data + '\n\n'); // whenever you send two new line characters the message is sent automatically }Nous définissons une fonction qui va gérer la réponse :
- En-têtes de configuration
- Créer un message
- Envoyer
Notez que vous ne voyez pas d'appel de méthode send() ou push() . En effet, la norme définit que le message sera envoyé dès qu'il recevra deux caractères \n\n comme dans l'exemple : response.write("data: " + data + '\n\n'); . Cela enverra immédiatement le message au client. Veuillez noter que les data doivent être une chaîne échappée et n'ont pas de caractères de nouvelle ligne à la fin.
Construction des messages
Comme mentionné précédemment, le message peut contenir quelques propriétés :
- identifiant
Si la valeur du champ ne contient pas U+0000 NULL, définissez le dernier tampon d'ID d'événement sur la valeur du champ. Sinon, ignorez le champ. - Données
Ajoutez la valeur du champ au tampon de données, puis ajoutez un seul caractère U+000A LINE FEED (LF) au tampon de données. - Événement
Définissez le tampon de type d'événement sur la valeur du champ. Cela conduit àevent.typeobtenir votre nom d'événement personnalisé. - Réessayez
Si la valeur du champ se compose uniquement de chiffres ASCII, interprétez la valeur du champ comme un entier en base dix et définissez l'heure de reconnexion du flux d'événements sur cet entier. Sinon, ignorez le champ.
Tout le reste sera ignoré. Nous ne pouvons pas introduire nos propres champs.
Exemple avec event ajouté :
response.write('id: UniqueID\n'); response.write('event: add\n'); response.write('retry: 10000\n'); response.write("data: " + data + '\n\n'); Ensuite, sur le client, cela est géré avec addEventListener en tant que tel :
source.addEventListener("add", function(event) { // do stuff with data event.data; });Vous pouvez envoyer plusieurs messages séparés par une nouvelle ligne tant que vous fournissez des identifiants différents.
... id: 54 event: add data: "[{SOME JSON DATA}]" id: 55 event: remove data: JSON.stringify(some_data) id: 56 event: remove data: { data: "msg" : "JSON data"\n data: "field": "value"\n data: "field2": "value2"\n data: }\n\n ...Cela simplifie énormément ce que nous pouvons faire avec nos données.
Exigences spécifiques du serveur
Au cours de notre POC pour le back-end, nous avons identifié certaines spécificités qui doivent être traitées pour avoir une implémentation fonctionnelle de SSE. Dans le meilleur des cas, vous utiliserez un serveur basé sur une boucle d'événements comme NodeJS, Kestrel ou Twisted. L'idée étant qu'avec la solution basée sur les threads vous aurez un thread par connexion → 1000 connexions = 1000 threads. Avec la solution de boucle d'événement, vous aurez un thread pour 1000 connexions.
- Vous ne pouvez accepter les requêtes EventSource que si la requête HTTP indique qu'elle peut accepter le type MIME de flux d'événements ;
- Vous devez maintenir une liste de tous les utilisateurs connectés afin d'émettre de nouveaux événements ;
- Vous devez écouter les connexions interrompues et les supprimer de la liste des utilisateurs connectés ;
- Vous devez éventuellement conserver un historique des messages afin que les clients qui se reconnectent puissent rattraper les messages manqués.
Cela fonctionne comme prévu et ressemble à de la magie au premier abord. Nous obtenons tout ce que nous voulons pour que notre application fonctionne de manière efficace. Comme pour toutes les choses qui semblent trop belles pour être vraies, nous sommes parfois confrontés à des problèmes qui doivent être résolus. Cependant, ils ne sont pas compliqués à mettre en œuvre ou à faire le tour :
Les serveurs proxy hérités sont connus pour, dans certains cas, abandonner les connexions HTTP après un court délai. Pour se protéger contre de tels serveurs proxy, les auteurs peuvent inclure une ligne de commentaire (une ligne commençant par un caractère ':') toutes les 15 secondes environ.
Les auteurs souhaitant associer des connexions de sources d'événements les unes aux autres ou à des documents spécifiques précédemment servis peuvent constater que s'appuyer sur des adresses IP ne fonctionne pas, car des clients individuels peuvent avoir plusieurs adresses IP (en raison de la présence de plusieurs serveurs proxy) et des adresses IP individuelles peuvent avoir plusieurs clients (en raison du partage d'un serveur proxy). Il est préférable d'inclure un identifiant unique dans le document lorsqu'il est servi, puis de transmettre cet identifiant dans le cadre de l'URL lorsque la connexion est établie.
Les auteurs sont également avertis que la segmentation HTTP peut avoir des effets négatifs inattendus sur la fiabilité de ce protocole, en particulier si la segmentation est effectuée par une couche différente ignorant les exigences de synchronisation. S'il s'agit d'un problème, la segmentation peut être désactivée pour servir les flux d'événements.
Les clients qui prennent en charge la limitation de connexion HTTP par serveur peuvent rencontrer des problèmes lors de l'ouverture de plusieurs pages à partir d'un site si chaque page a un EventSource vers le même domaine. Les auteurs peuvent éviter cela en utilisant le mécanisme relativement complexe consistant à utiliser des noms de domaine uniques par connexion, ou en permettant à l'utilisateur d'activer ou de désactiver la fonctionnalité EventSource sur une base par page, ou en partageant un seul objet EventSource à l'aide d'un travailleur partagé.
Prise en charge du navigateur et Polyfills : Edge est en retard sur cette implémentation, mais un polyfill est disponible qui peut vous sauver. Cependant, le cas le plus important pour SSE est fait pour les appareils mobiles où IE/Edge n'ont pas de part de marché viable.
Certains des polyfills disponibles :
- Yaffle
- amvtek
- Rémy
Push sans connexion et autres fonctionnalités
Les agents utilisateurs s'exécutant dans des environnements contrôlés, par exemple des navigateurs sur des combinés mobiles liés à des opérateurs spécifiques, peuvent décharger la gestion de la connexion sur un proxy sur le réseau. Dans une telle situation, l'agent utilisateur aux fins de conformité est considéré comme incluant à la fois le logiciel du combiné et le proxy réseau.
Par exemple, un navigateur sur un appareil mobile, après avoir établi une connexion, peut détecter qu'il se trouve sur un réseau de support et demander qu'un serveur proxy sur le réseau prenne en charge la gestion de la connexion. La chronologie d'une telle situation pourrait être la suivante :
- Le navigateur se connecte à un serveur HTTP distant et demande la ressource spécifiée par l'auteur dans le constructeur EventSource.
- Le serveur envoie des messages occasionnels.
- Entre deux messages, le navigateur détecte qu'il est inactif à l'exception de l'activité réseau impliquée dans le maintien de la connexion TCP, et décide de passer en mode veille pour économiser de l'énergie.
- Le navigateur se déconnecte du serveur.
- Le navigateur contacte un service sur le réseau et demande que le service, un « proxy push », maintienne la connexion à la place.
- Le service « push proxy » contacte le serveur HTTP distant et demande la ressource spécifiée par l'auteur dans le constructeur EventSource (incluant éventuellement un en-tête HTTP
Last-Event-ID, etc.). - Le navigateur permet à l'appareil mobile de se mettre en veille.
- Le serveur envoie un autre message.
- Le service "push proxy" utilise une technologie telle que OMA push pour transmettre l'événement à l'appareil mobile, qui se réveille juste assez pour traiter l'événement, puis se rendort.
Cela peut réduire l'utilisation totale des données et, par conséquent, entraîner des économies d'énergie considérables.
Outre la mise en œuvre de l'API existante et du format de fil de flux texte/événement tel que défini par la spécification et de manière plus distribuée (comme décrit ci-dessus), les formats de cadrage d'événement définis par d'autres spécifications applicables peuvent être pris en charge.
Sommaire
Après de longs et exhaustifs POC incluant des implémentations serveur et client, il semble que SSE soit la réponse à nos problèmes de livraison de données. Il y a aussi quelques pièges, mais ils se sont avérés faciles à résoudre.
Voici à quoi ressemble notre configuration de production à la fin :
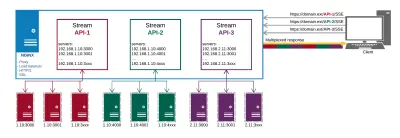
Nous obtenons ce qui suit de NGINX :
- Proxy aux points de terminaison API à différents endroits ;
- HTTP/2 et tous ses avantages comme le multiplexage des connexions ;
- L'équilibrage de charge;
- SSL.
De cette façon, nous gérons la livraison de nos données et nos certificats en un seul endroit au lieu de le faire séparément sur chaque terminal.
Les principaux avantages que nous tirons de cette approche sont :
- Efficacité des données ;
- Mise en œuvre plus simple ;
- Il est automatiquement multiplexé sur HTTP/2 ;
- Limite le nombre de connexions pour les données sur le client à une ;
- Fournit un mécanisme pour économiser la batterie en déchargeant la connexion vers un proxy.
SSE n'est pas seulement une alternative viable aux autres méthodes pour fournir des mises à jour rapides ; il semble qu'il soit dans une catégorie à part en ce qui concerne les optimisations pour les appareils mobiles. Il n'y a pas de surcoût dans sa mise en œuvre par rapport aux alternatives. En termes d'implémentation côté serveur, ce n'est pas très différent de l'interrogation. Sur le client, c'est beaucoup plus simple que l'interrogation car elle nécessite un abonnement initial et l'attribution de gestionnaires d'événements - très similaire à la façon dont les WebSockets sont gérés.
Consultez la démonstration de code si vous souhaitez obtenir une implémentation client-serveur simple.
Ressources
- "Problèmes connus et meilleures pratiques pour l'utilisation de l'interrogation longue et de la diffusion en continu dans le HTTP bidirectionnel", IETF (PDF)
- Recommandation du W3C, W3C
- « WebSocket survivra-t-il à HTTP/2 ? », Allan Denis, InfoQ
- "Diffusion des mises à jour avec les événements envoyés par le serveur", Eric Bidelman, HTML5 Rocks
- "Applications de transmission de données avec HTML5 SSE", Darren Cook, O'Reilly Media