
La montée des machines d'État
Publié: 2022-03-10Nous sommes déjà en 2018 et d'innombrables développeurs front-end mènent toujours une bataille contre la complexité et l'immobilité. Mois après mois, ils ont recherché le Saint Graal : une architecture d'application sans bogue qui les aidera à livrer rapidement et avec une qualité élevée. Je suis l'un de ces développeurs, et j'ai trouvé quelque chose d'intéressant qui pourrait aider.
Nous avons fait un bon pas en avant avec des outils tels que React et Redux. Cependant, ils ne suffisent pas à eux seuls dans les applications à grande échelle. Cet article vous présentera le concept de machines à états dans le cadre du développement front-end. Vous en avez probablement déjà construit plusieurs sans vous en rendre compte.
Une introduction aux machines d'état
Une machine à états est un modèle mathématique de calcul. C'est un concept abstrait selon lequel la machine peut avoir différents états, mais n'en remplit à un instant donné qu'un seul. Il existe différents types de machines à états. La plus célèbre, je crois, est la machine de Turing. C'est une machine à états infinie, ce qui signifie qu'elle peut avoir un nombre incalculable d'états. La machine de Turing ne s'intègre pas bien dans le développement actuel de l'interface utilisateur car, dans la plupart des cas, nous avons un nombre fini d'états. C'est pourquoi les machines à états finis, telles que Mealy et Moore, ont plus de sens.
La différence entre eux est que la machine Moore change d'état uniquement en fonction de son état précédent. Malheureusement, nous avons beaucoup de facteurs externes, tels que les interactions des utilisateurs et les processus réseau, ce qui signifie que la machine Moore n'est pas assez bonne pour nous non plus. Ce que nous recherchons, c'est la machine Mealy. Il a un état initial, puis passe à de nouveaux états en fonction de l'entrée et de son état actuel.
L'un des moyens les plus simples d'illustrer le fonctionnement d'une machine à états est de regarder un tourniquet. Il a un nombre fini d'états : verrouillé et déverrouillé. Voici un graphique simple qui nous montre ces états, avec leurs entrées et transitions possibles.
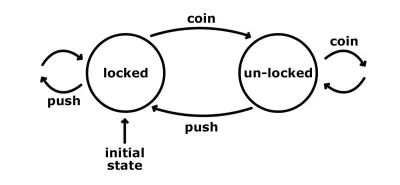
L'état initial du tourniquet est verrouillé. Peu importe combien de fois nous pouvons le pousser, il reste dans cet état verrouillé. Cependant, si nous lui passons une pièce, il passe à l'état déverrouillé. Une autre pièce à ce stade ne ferait rien; il serait toujours dans l'état déverrouillé. Une poussée de l'autre côté fonctionnerait, et nous serions en mesure de passer. Cette action fait également passer la machine à l'état verrouillé initial.
Si nous voulions implémenter une seule fonction qui contrôle le tourniquet, nous nous retrouverions probablement avec deux arguments : l'état actuel et une action. Et si vous utilisez Redux, cela vous semble probablement familier. C'est similaire à la fonction de réduction bien connue, où nous recevons l'état actuel, et en fonction de la charge utile de l'action, nous décidons quel sera l'état suivant. Le réducteur est la transition dans le contexte des machines à états. En fait, toute application qui a un état que nous pouvons changer d'une manière ou d'une autre peut être appelée une machine à états. C'est juste que nous implémentons tout manuellement encore et encore.
En quoi une machine à états est-elle meilleure ?
Au travail, nous utilisons Redux, et j'en suis plutôt content. Cependant, j'ai commencé à voir des modèles que je n'aime pas. Par « n'aime pas », je ne veux pas dire qu'ils ne fonctionnent pas. C'est plus qu'ils ajoutent de la complexité et m'obligent à écrire plus de code. Je devais entreprendre un projet parallèle dans lequel j'avais de la place pour expérimenter, et j'ai décidé de repenser nos pratiques de développement React et Redux. J'ai commencé à prendre des notes sur les choses qui me préoccupaient, et j'ai réalisé qu'une abstraction de la machine à états résoudrait vraiment certains de ces problèmes. Allons-y et voyons comment implémenter une machine d'état en JavaScript.
Nous allons nous attaquer à un problème simple. Nous voulons récupérer des données à partir d'une API back-end et les afficher à l'utilisateur. La toute première étape consiste à apprendre à penser par états plutôt que par transitions. Avant d'aborder les machines d'état, mon flux de travail pour la création d'une telle fonctionnalité ressemblait à ceci :
- Nous affichons un bouton de récupération de données.
- L'utilisateur clique sur le bouton d'extraction de données.
- Envoyez la requête au serveur principal.
- Récupérez les données et analysez-les.
- Montrez-le à l'utilisateur.
- Ou, s'il y a une erreur, affichez le message d'erreur et affichez le bouton de récupération des données afin que nous puissions déclencher à nouveau le processus.
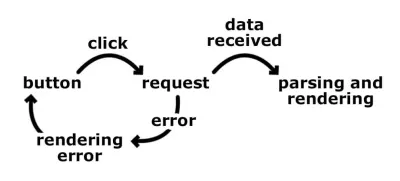
Nous pensons linéairement et essayons essentiellement de couvrir toutes les directions possibles jusqu'au résultat final. Une étape en entraînant une autre, et rapidement nous commencerions à ramifier notre code. Qu'en est-il des problèmes tels que l'utilisateur double-cliquant sur le bouton, ou l'utilisateur cliquant sur le bouton pendant que nous attendons la réponse du back-end, ou la requête réussissant mais les données étant corrompues. Dans ces cas, nous aurions probablement divers drapeaux qui nous montreraient ce qui s'est passé. Avoir des drapeaux signifie plus de clauses if et, dans des applications plus complexes, plus de conflits.
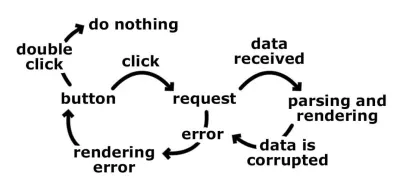
C'est parce que nous pensons aux transitions. Nous nous concentrons sur la façon dont ces transitions se produisent et dans quel ordre. Se concentrer plutôt sur les différents états de l'application serait beaucoup plus simple. Combien d'États avons-nous et quelles sont leurs contributions possibles ? En utilisant le même exemple :
- inactif
Dans cet état, nous affichons le bouton de récupération de données, asseyons-nous et attendons. L'action possible est :- Cliquez sur
Lorsque l'utilisateur clique sur le bouton, nous lançons la requête vers le back-end, puis passons la machine à un état de "récupération".
- Cliquez sur
- aller chercher
La demande est en vol, et nous nous asseyons et attendons. Les gestes sont :- Succès
Les données arrivent avec succès et ne sont pas corrompues. Nous utilisons les données d'une manière ou d'une autre et revenons à l'état "inactif". - échec
S'il y a une erreur lors de la demande ou de l'analyse des données, nous passons à un état "erreur".
- Succès
- Erreur
Nous affichons un message d'erreur et affichons le bouton de récupération des données. Cet état accepte une action :- réessayez
Lorsque l'utilisateur clique sur le bouton de nouvelle tentative, nous lançons à nouveau la demande et passons la machine à l'état "récupération".
- réessayez
Nous avons décrit à peu près les mêmes processus, mais avec des états et des entrées.
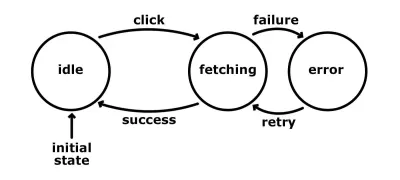
Cela simplifie la logique et la rend plus prévisible. Il résout également certains des problèmes mentionnés ci-dessus. Notez que, pendant que nous sommes dans l'état "récupération", nous n'acceptons aucun clic. Ainsi, même si l'utilisateur clique sur le bouton, rien ne se passera car la machine n'est pas configurée pour répondre à cette action dans cet état. Cette approche élimine automatiquement les branchements imprévisibles de notre logique de code. Cela signifie que nous aurons moins de code à couvrir lors des tests . En outre, certains types de tests, tels que les tests d'intégration, peuvent être automatisés. Pensez à la façon dont nous aurions une idée vraiment claire de ce que fait notre application, et nous pourrions créer un script qui passe en revue les états et les transitions définis et qui génère des assertions. Ces affirmations pourraient prouver que nous avons atteint tous les états possibles ou couvert un voyage particulier.
En fait, il est plus facile d'écrire tous les états possibles que d'écrire toutes les transitions possibles car nous savons de quels états nous avons besoin ou avons. Soit dit en passant, dans la plupart des cas, les états décriraient la logique métier de notre application, alors que les transitions sont très souvent inconnues au départ. Les bogues de nos logiciels sont le résultat d'actions envoyées dans un mauvais état et/ou au mauvais moment. Ils laissent notre application dans un état que nous ignorons, et cela casse notre programme ou le fait se comporter de manière incorrecte. Bien sûr, nous ne voulons pas être dans une telle situation. Les machines d'état sont de bons pare -feux. Ils nous empêchent d'atteindre des états inconnus parce que nous fixons des limites à ce qui peut arriver et quand, sans dire explicitement comment. Le concept d'une machine à états se marie très bien avec un flux de données unidirectionnel. Ensemble, ils réduisent la complexité du code et éclaircissent le mystère de l'origine d'un état.
Création d'une machine d'état en JavaScript
Assez parlé - voyons un peu de code. Nous utiliserons le même exemple. Sur la base de la liste ci-dessus, nous commencerons par ce qui suit :
const machine = { 'idle': { click: function () { ... } }, 'fetching': { success: function () { ... }, failure: function () { ... } }, 'error': { 'retry': function () { ... } } }Nous avons les états comme objets et leurs entrées possibles comme fonctions. L'état initial manque cependant. Changeons le code ci-dessus en ceci :
const machine = { state: 'idle', transitions: { 'idle': { click: function() { ... } }, 'fetching': { success: function() { ... }, failure: function() { ... } }, 'error': { 'retry': function() { ... } } } }Une fois que nous avons défini tous les états qui ont du sens pour nous, nous sommes prêts à envoyer l'entrée et à changer d'état. Nous le ferons en utilisant les deux méthodes d'assistance ci-dessous :
const machine = { dispatch(actionName, ...payload) { const actions = this.transitions[this.state]; const action = this.transitions[this.state][actionName]; if (action) { action.apply(machine, ...payload); } }, changeStateTo(newState) { this.state = newState; }, ... } La fonction de dispatch vérifie s'il existe une action portant le nom donné dans les transitions de l'état actuel. Si tel est le cas, il le déclenche avec la charge utile donnée. Nous appelons également le gestionnaire d' action avec la machine comme contexte, afin que nous puissions envoyer d'autres actions avec this.dispatch(<action>) ou changer l'état avec this.changeStateTo(<new state>) .
Suivant le parcours utilisateur de notre exemple, la première action que nous devons dispatcher est click . Voici à quoi ressemble le gestionnaire de cette action :
transitions: { 'idle': { click: function () { this.changeStateTo('fetching'); service.getData().then( data => { try { this.dispatch('success', JSON.parse(data)); } catch (error) { this.dispatch('failure', error) } }, error => this.dispatch('failure', error) ); } }, ... } machine.dispatch('click'); Nous changeons d'abord l'état de la machine en fetching . Ensuite, nous déclenchons la requête au back-end. Supposons que nous ayons un service avec une méthode getData qui renvoie une promesse. Une fois qu'il est résolu et que l'analyse des données est OK, nous envoyons le success , sinon failure .
Jusqu'ici tout va bien. Ensuite, nous devons implémenter les actions et les entrées de success et d' failure sous l'état de fetching :
transitions: { 'idle': { ... }, 'fetching': { success: function (data) { // render the data this.changeStateTo('idle'); }, failure: function (error) { this.changeStateTo('error'); } }, ... } Remarquez comment nous avons libéré notre cerveau d'avoir à penser au processus précédent. Nous ne nous soucions pas des clics des utilisateurs ou de ce qui se passe avec la requête HTTP. Nous savons que l'application est dans un état de fetching et nous n'attendons que ces deux actions. C'est un peu comme écrire une nouvelle logique de manière isolée.
Le dernier bit est l'état error . Ce serait bien si nous fournissions cette logique de nouvelle tentative afin que l'application puisse se remettre d'un échec.
transitions: { 'error': { retry: function () { this.changeStateTo('idle'); this.dispatch('click'); } } } Ici, nous devons dupliquer la logique que nous avons écrite dans le gestionnaire de click . Pour éviter cela, nous devons soit définir le gestionnaire comme une fonction accessible aux deux actions, soit passer d'abord à l'état idle , puis envoyer l'action de click manuellement.
Un exemple complet de la machine d'état de travail peut être trouvé dans mon Codepen.
Gestion des machines d'état avec une bibliothèque
Le modèle de machine à états finis fonctionne, que nous utilisions React, Vue ou Angular. Comme nous l'avons vu dans la section précédente, nous pouvons facilement implémenter une machine d'état sans trop de problèmes. Cependant, une bibliothèque offre parfois plus de flexibilité. Certains des bons sont Machina.js et XState. Dans cet article, cependant, nous parlerons de Stent, ma bibliothèque de type Redux qui intègre le concept de machines à états finis.
Stent est une implémentation d'un conteneur de machines d'état. Il suit certaines des idées des projets Redux et Redux-Saga, mais fournit, à mon avis, des processus plus simples et sans passe-partout. Il est développé à l'aide d'un développement piloté par readme, et j'ai littéralement passé des semaines uniquement sur la conception de l'API. Parce que j'écrivais la bibliothèque, j'ai eu la chance de résoudre les problèmes que j'ai rencontrés lors de l'utilisation des architectures Redux et Flux.

Créer des machines
Dans la plupart des cas, nos applications couvrent plusieurs domaines. Nous ne pouvons pas nous contenter d'une seule machine. Ainsi, Stent permet la création de nombreuses machines :
import { Machine } from 'stent'; const machineA = Machine.create('A', { state: ..., transitions: ... }); const machineB = Machine.create('B', { state: ..., transitions: ... }); Plus tard, nous pourrons accéder à ces machines en utilisant la méthode Machine.get :
const machineA = Machine.get('A'); const machineB = Machine.get('B');Connecter les machines à la logique de rendu
Le rendu dans mon cas se fait via React, mais nous pouvons utiliser n'importe quelle autre bibliothèque. Cela revient à déclencher un rappel dans lequel nous déclenchons le rendu. L'une des premières fonctionnalités sur lesquelles j'ai travaillé a été la fonction de connect :
import { connect } from 'stent/lib/helpers'; Machine.create('MachineA', ...); Machine.create('MachineB', ...); connect() .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { ... rendering here }); Nous disons quelles machines sont importantes pour nous et donnons leurs noms. Le rappel que nous passons à la map est déclenché une fois initialement, puis plus tard chaque fois que l'état de certaines machines change. C'est là que nous déclenchons le rendu. À ce stade, nous avons un accès direct aux machines connectées, nous pouvons donc récupérer l'état actuel et les méthodes. Il existe également mapOnce , pour que le rappel ne soit déclenché qu'une seule fois, et mapSilent , pour ignorer cette exécution initiale.
Pour plus de commodité, un assistant est exporté spécifiquement pour l'intégration de React. C'est vraiment similaire au connect(mapStateToProps) de Redux.
import React from 'react'; import { connect } from 'stent/lib/react'; class TodoList extends React.Component { render() { const { isIdle, todos } = this.props; ... } } // MachineA and MachineB are machines defined // using Machine.create function export default connect(TodoList) .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { isIdle: MachineA.isIdle, todos: MachineB.state.todos }); Stent exécute notre rappel de mappage et s'attend à recevoir un objet - un objet qui est envoyé en tant props à notre composant React.
Qu'est-ce que l'état dans le contexte du stent ?
Jusqu'à présent, notre état était constitué de simples chaînes. Malheureusement, dans le monde réel, nous devons garder plus qu'une chaîne en état. C'est pourquoi l'état de Stent est en fait un objet avec des propriétés à l'intérieur. La seule propriété réservée est name . Tout le reste est des données spécifiques à l'application. Par exemple:
{ name: 'idle' } { name: 'fetching', todos: [] } { name: 'forward', speed: 120, gear: 4 }Mon expérience avec Stent jusqu'à présent me montre que si l'objet d'état devient plus grand, nous aurions probablement besoin d'une autre machine qui gère ces propriétés supplémentaires. L'identification des différents états prend un certain temps, mais je pense que c'est un grand pas en avant dans l'écriture d'applications plus gérables. C'est un peu comme prédire l'avenir et dessiner les cadres des actions possibles.
Travailler avec la machine d'état
Semblable à l'exemple du début, nous devons définir les états (finis) possibles de notre machine et décrire les entrées possibles :
import { Machine } from 'stent'; const machine = Machine.create('sprinter', { state: { name: 'idle' }, // initial state transitions: { 'idle': { 'run please': function () { return { name: 'running' }; } }, 'running': { 'stop now': function () { return { name: 'idle' }; } } } }); Nous avons notre état initial, idle , qui accepte une action de run . Une fois que la machine est en état de running , nous sommes en mesure de déclencher l'action d' stop , ce qui nous ramène à l'état d' idle .
Vous vous souviendrez probablement des aides dispatch et changeStateTo de notre implémentation précédente. Cette bibliothèque fournit la même logique, mais elle est cachée en interne, et nous n'avons pas à y penser. Pour plus de commodité, basé sur la propriété des transitions , Stent génère ce qui suit :
- méthodes d'assistance pour vérifier si la machine est dans un état particulier — l'état
idleproduit la méthodeisIdle(), alors que pourrunning, nous avonsisRunning(); - méthodes d'assistance pour la répartition des actions :
runPlease()etstopNow().
Ainsi, dans l'exemple ci-dessus, nous pouvons utiliser ceci :
machine.isIdle(); // boolean machine.isRunning(); // boolean machine.runPlease(); // fires action machine.stopNow(); // fires action En combinant les méthodes générées automatiquement avec la fonction utilitaire de connect , nous sommes en mesure de boucler la boucle. Une interaction de l'utilisateur déclenche l'entrée et l'action de la machine, qui met à jour l'état. En raison de cette mise à jour, la fonction de mappage transmise à connect est déclenchée et nous sommes informés du changement d'état. Ensuite, nous restituons.
Gestionnaires d'entrée et d'action
Le bit le plus important est probablement les gestionnaires d'action. C'est l'endroit où nous écrivons la majeure partie de la logique de l'application car nous répondons aux entrées et aux états modifiés. Quelque chose que j'aime beaucoup dans Redux est également intégré ici : l'immuabilité et la simplicité de la fonction de réduction. L'essence du gestionnaire d'action de Stent est la même. Il reçoit l'état actuel et la charge utile d'action, et il doit renvoyer le nouvel état. Si le gestionnaire ne renvoie rien ( undefined ), l'état de la machine reste le même.
transitions: { 'fetching': { 'success': function (state, payload) { const todos = [ ...state.todos, payload ]; return { name: 'idle', todos }; } } } Supposons que nous ayons besoin de récupérer des données à partir d'un serveur distant. Nous lançons la requête et passons la machine à un état de fetching . Une fois que les données proviennent du back-end, nous lançons une action success , comme ceci :
machine.success({ label: '...' }); Ensuite, nous revenons à un état idle et conservons certaines données sous la forme du tableau todos . Il existe quelques autres valeurs possibles à définir comme gestionnaires d'action. Le premier et le plus simple cas est lorsque nous passons juste une chaîne qui devient le nouvel état.
transitions: { 'idle': { 'run': 'running' } } Il s'agit d'une transition de { name: 'idle' } à { name: 'running' } à l'aide de l'action run() . Cette approche est utile lorsque nous avons des transitions d'état synchrones et que nous n'avons pas de métadonnées. Donc, si nous gardons quelque chose d'autre en état, ce type de transition le débusquera. De même, nous pouvons passer directement un objet d'état :
transitions: { 'editing': { 'delete all todos': { name: 'idle', todos: [] } } } Nous passons de l' editing à l' idle à l'aide de l'action deleteAllTodos .
Nous avons déjà vu le gestionnaire de fonction, et la dernière variante du gestionnaire d'action est une fonction génératrice. Il est inspiré du projet Redux-Saga, et il ressemble à ceci :
import { call } from 'stent/lib/helpers'; Machine.create('app', { 'idle': { 'fetch data': function * (state, payload) { yield { name: 'fetching' } try { const data = yield call(requestToBackend, '/api/todos/', 'POST'); return { name: 'idle', data }; } catch (error) { return { name: 'error', error }; } } } });Si vous n'avez pas d'expérience avec les générateurs, cela peut sembler un peu énigmatique. Mais les générateurs en JavaScript sont un outil puissant. Nous sommes autorisés à mettre en pause notre gestionnaire d'action, à changer d'état plusieurs fois et à gérer la logique asynchrone.
Amusez-vous avec les générateurs
Lorsque j'ai découvert Redux-Saga pour la première fois, je pensais que c'était un moyen trop compliqué de gérer les opérations asynchrones. En fait, c'est une implémentation assez intelligente du modèle de conception de commande. Le principal avantage de ce modèle est qu'il sépare l'invocation de la logique et sa mise en œuvre réelle.
En d'autres termes, nous disons ce que nous voulons mais pas comment cela doit se passer. La série de blogs de Matt Hink m'a aidé à comprendre comment les sagas sont mises en œuvre, et je recommande fortement de la lire. J'ai apporté les mêmes idées dans Stent, et pour les besoins de cet article, nous dirons qu'en cédant des choses, nous donnons des instructions sur ce que nous voulons sans le faire réellement. Une fois l'action effectuée, nous recevons le contrôle en retour.
Pour le moment, quelques éléments peuvent être envoyés (cédés):
- un objet d'état (ou une chaîne) pour changer l'état de la machine ;
- un appel de l'assistant d'
call(il accepte une fonction synchrone, qui est une fonction qui renvoie une promesse ou une autre fonction génératrice) - nous disons essentiellement : "Exécutez ceci pour moi, et s'il est asynchrone, attendez. Une fois que vous avez terminé, donnez-moi le résultat. » ; - un appel de l'assistant
wait(il accepte une chaîne représentant une autre action) ; si nous utilisons cette fonction utilitaire, nous suspendons le gestionnaire et attendons qu'une autre action soit envoyée.
Voici une fonction qui illustre les variantes :
const fireHTTPRequest = function () { return new Promise((resolve, reject) => { // ... }); } ... transitions: { 'idle': { 'fetch data': function * () { yield 'fetching'; // sets the state to { name: 'fetching' } yield { name: 'fetching' }; // same as above // wait for getTheData and checkForErrors actions // to be dispatched const [ data, isError ] = yield wait('get the data', 'check for errors'); // wait for the promise returned by fireHTTPRequest // to be resolved const result = yield call(fireHTTPRequest, '/api/data/users'); return { name: 'finish', users: result }; } } }Comme nous pouvons le voir, le code semble synchrone, mais en fait il ne l'est pas. C'est juste Stent qui fait la partie ennuyeuse d'attendre la promesse résolue ou d'itérer sur un autre générateur.
Comment Stent résout mes problèmes de Redux
Trop de code standard
L'architecture Redux (et Flux) repose sur des actions qui circulent dans notre système. Lorsque l'application grandit, nous finissons généralement par avoir beaucoup de constantes et de créateurs d'action. Ces deux choses sont très souvent dans des dossiers différents, et le suivi de l'exécution du code prend parfois du temps. De plus, lors de l'ajout d'une nouvelle fonctionnalité, nous devons toujours gérer un ensemble d'actions, ce qui signifie définir davantage de noms d'action et de créateurs d'action.
Dans Stent, nous n'avons pas de noms d'action, et la bibliothèque crée automatiquement les créateurs d'action pour nous :
const machine = Machine.create('todo-app', { state: { name: 'idle', todos: [] }, transitions: { 'idle': { 'add todo': function (state, todo) { ... } } } }); machine.addTodo({ title: 'Fix that bug' }); Nous avons le créateur d'action machine.addTodo défini directement comme une méthode de la machine. Cette approche a également résolu un autre problème auquel j'étais confronté : trouver le réducteur qui répond à une action particulière. Habituellement, dans les composants React, nous voyons des noms de créateurs d'action tels que addTodo ; cependant, dans les réducteurs, nous travaillons avec un type d'action constant. Parfois, je dois sauter au code du créateur d'action juste pour que je puisse voir le type exact. Ici, nous n'avons aucun type.
Changements d'état imprévisibles
En général, Redux fait un bon travail de gestion de l'état de manière immuable. Le problème n'est pas dans Redux lui-même, mais en ce que le développeur est autorisé à envoyer n'importe quelle action à tout moment. Si nous disons que nous avons une action qui allume les lumières, est-il acceptable de déclencher cette action deux fois de suite ? Sinon, comment sommes-nous censés résoudre ce problème avec Redux ? Eh bien, nous mettrions probablement du code dans le réducteur qui protège la logique et qui vérifie si les lumières sont déjà allumées - peut-être une clause if qui vérifie l'état actuel. Maintenant, la question est, n'est-ce pas au-delà de la portée du réducteur ? Le réducteur doit-il être au courant de ces cas extrêmes ?
Ce qui me manque dans Redux, c'est un moyen d'arrêter l'envoi d'une action en fonction de l'état actuel de l'application sans polluer le réducteur avec une logique conditionnelle. Et je ne veux pas non plus prendre cette décision sur la couche de vue, où le créateur de l'action est renvoyé. Avec Stent, cela se produit automatiquement car la machine ne répond pas aux actions qui ne sont pas déclarées dans l'état actuel. Par exemple:
const machine = Machine.create('app', { state: { name: 'idle' }, transitions: { 'idle': { 'run': 'running', 'jump': 'jumping' }, 'running': { 'stop': 'idle' } } }); // this is fine machine.run(); // This will do nothing because at this point // the machine is in a 'running' state and there is // only 'stop' action there. machine.jump();Le fait que la machine n'accepte que des entrées spécifiques à un instant donné nous protège des bugs bizarres et rend nos applications plus prévisibles.
Des états, pas des transitions
Redux, comme Flux, nous fait penser en termes de transitions. Le modèle mental de développement avec Redux est essentiellement guidé par les actions et la manière dont ces actions transforment l'état de nos réducteurs. Ce n'est pas mal, mais j'ai trouvé qu'il était plus logique de penser en termes d'états à la place - dans quels états l'application pourrait se trouver et comment ces états représentent les exigences de l'entreprise.
Conclusion
Le concept de machines à états dans la programmation, en particulier dans le développement de l'interface utilisateur, m'a ouvert les yeux. J'ai commencé à voir des machines d'état partout, et j'ai un certain désir de toujours passer à ce paradigme. Je vois définitivement les avantages d'avoir des états et des transitions plus strictement définis entre eux. Je suis toujours à la recherche de moyens de rendre mes applications simples et lisibles. Je crois que les machines d'état sont un pas dans cette direction. Le concept est simple et en même temps puissant. Il a le potentiel d'éliminer beaucoup de bugs.