
Concevoir et construire une application Web progressive sans framework (Partie 2)
Publié: 2022-03-10La raison d'être de cette aventure était de pousser un peu votre humble auteur dans les disciplines du design visuel et du codage JavaScript. La fonctionnalité de l'application que j'avais décidé de construire n'était pas différente d'une application « à faire ». Il est important de souligner qu'il ne s'agissait pas d'un exercice de réflexion originale. La destination était beaucoup moins importante que le voyage.
Vous voulez savoir comment l'application s'est terminée? Pointez le navigateur de votre téléphone sur https://io.benfrain.com.
Voici un résumé de ce que nous allons couvrir dans cet article :
- La configuration du projet et pourquoi j'ai opté pour Gulp comme outil de construction ;
- Modèles de conception d'applications et ce qu'ils signifient dans la pratique ;
- Comment stocker et visualiser l'état de l'application ;
- comment CSS a été étendu aux composants ;
- quelles subtilités UI / UX ont été utilisées pour rendre les choses plus "app-like" ;
- Comment le mandat a changé par itération.
Commençons par les outils de construction.
Outils de construction
Pour que mes outils de base de TypeScipt et PostCSS soient opérationnels et créer une expérience de développement décente, j'aurais besoin d'un système de construction.
Dans mon travail quotidien, depuis environ cinq ans, je construis des prototypes d'interfaces en HTML/CSS et, dans une moindre mesure, en JavaScript. Jusqu'à récemment, j'ai utilisé Gulp avec n'importe quel nombre de plugins presque exclusivement pour répondre à mes besoins de construction assez modestes.
En règle générale, je dois traiter CSS, convertir JavaScript ou TypeScript en JavaScript plus largement pris en charge et, occasionnellement, effectuer des tâches connexes telles que la réduction de la sortie de code et l'optimisation des ressources. L'utilisation de Gulp m'a toujours permis de résoudre ces problèmes avec aplomb.
Pour ceux qui ne sont pas familiers, Gulp vous permet d'écrire du JavaScript pour faire "quelque chose" aux fichiers de votre système de fichiers local. Pour utiliser Gulp, vous avez généralement un seul fichier (appelé gulpfile.js ) à la racine de votre projet. Ce fichier JavaScript vous permet de définir des tâches en tant que fonctions. Vous pouvez ajouter des "plugins" tiers, qui sont essentiellement d'autres fonctions JavaScript, qui traitent de tâches spécifiques.
Un exemple de tâche Gulp
Un exemple de tâche Gulp pourrait être d'utiliser un plugin pour exploiter PostCSS à traiter en CSS lorsque vous modifiez une feuille de style de création (gulp-postcss). Ou compiler des fichiers TypeScript en JavaScript vanille (gulp-typescript) au fur et à mesure que vous les enregistrez. Voici un exemple simple de la façon dont vous écrivez une tâche dans Gulp. Cette tâche utilise le plugin 'del' gulp pour supprimer tous les fichiers dans un dossier appelé 'build' :
var del = require("del"); gulp.task("clean", function() { return del(["build/**/*"]); }); Le require affecte le plugin del à une variable. Ensuite, la méthode gulp.task est appelée. Nous nommons la tâche avec une chaîne comme premier argument ("clean"), puis exécutons une fonction qui, dans ce cas, utilise la méthode "del" pour supprimer le dossier qui lui est transmis en tant qu'argument. Les astérisques sont des modèles "glob" qui disent essentiellement "n'importe quel fichier dans n'importe quel dossier" du dossier de construction.
Les tâches de Gulp peuvent devenir beaucoup plus compliquées, mais en substance, c'est la mécanique de la façon dont les choses sont gérées. La vérité est qu'avec Gulp, vous n'avez pas besoin d'être un assistant JavaScript pour vous débrouiller ; des compétences de copier-coller de niveau 3 sont tout ce dont vous avez besoin.
J'étais resté avec Gulp comme outil de construction/exécuteur de tâches par défaut pendant toutes ces années avec une politique de 'si ce n'est pas cassé; n'essayez pas de le réparer'.
Cependant, j'avais peur de rester coincé dans mes habitudes. C'est un piège dans lequel il est facile de tomber. Tout d'abord, vous commencez à passer des vacances au même endroit chaque année, puis vous refusez d'adopter les nouvelles tendances de la mode avant de finalement et fermement refuser d'essayer de nouveaux outils de construction.
J'avais entendu beaucoup de bavardages sur Internet à propos de 'Webpack' et j'ai pensé qu'il était de mon devoir d'essayer un projet en utilisant le nouveau toast des cool-kids du développeur front-end.
Webpack
Je me souviens très bien d'avoir sauté sur le site webpack.js.org avec un vif intérêt. La première explication de ce qu'est Webpack et de ce qu'il fait a commencé comme ceci :
import bar from './bar';Tu peux répéter s'il te plait? Dans les mots du Dr Evil, "Jetez-moi un putain d'os ici, Scott".
Je sais que c'est mon propre blocage à gérer, mais j'ai développé une répulsion pour toute explication de codage qui mentionne 'foo', 'bar' ou 'baz'. Cela, ajouté à l'absence totale de description succincte de ce à quoi Webpack était réellement destiné , m'a fait soupçonner que ce n'était peut-être pas pour moi.
En creusant un peu plus loin dans la documentation de Webpack, une explication un peu moins opaque a été proposée : "À la base, Webpack est un bundler de modules statiques pour les applications JavaScript modernes".
Hmmm. Bundler de modules statiques. Était-ce ce que je voulais ? Je n'étais pas convaincu. J'ai continué à lire mais plus je lisais, moins j'étais clair. À l'époque, des concepts tels que les graphiques de dépendance, le rechargement de modules à chaud et les points d'entrée m'étaient essentiellement perdus.
Quelques soirées de recherche sur Webpack plus tard, j'ai abandonné toute idée de l'utiliser.
Je suis sûr que dans la bonne situation et entre des mains plus expérimentées, Webpack est extrêmement puissant et approprié, mais cela semblait être une exagération complète pour mes humbles besoins. Le regroupement de modules, le tremblement d'arborescence et le rechargement de modules à chaud sonnaient bien ; Je n'étais tout simplement pas convaincu que j'en avais besoin pour ma petite "application".
Donc, revenons à Gulp alors.
Sur le thème de ne pas changer les choses pour le plaisir de changer, une autre technologie que je voulais évaluer était Yarn over NPM pour la gestion des dépendances de projet. Jusque-là, j'avais toujours utilisé NPM et Yarn était présenté comme une alternative meilleure et plus rapide. Je n'ai pas grand-chose à dire sur Yarn si ce n'est que si vous utilisez actuellement NPM et que tout va bien, vous n'avez pas besoin de vous embêter à essayer Yarn.
Un outil qui est arrivé trop tard pour que j'évalue cette application est Parceljs. Avec une configuration nulle et un BrowserSync comme le rechargement du navigateur, j'y ai depuis trouvé une grande utilité ! De plus, à la décharge de Webpack, on me dit que la version 4 de Webpack ne nécessite pas de fichier de configuration. Pour l'anecdote, dans un sondage plus récent que j'ai réalisé sur Twitter, sur les 87 répondants, plus de la moitié ont choisi Webpack plutôt que Gulp, Parcel ou Grunt.
J'ai commencé mon fichier Gulp avec des fonctionnalités de base pour être opérationnel.
Une tâche "par défaut" surveillerait les dossiers "source" des feuilles de style et des fichiers TypeScript et les compilerait dans un dossier de build avec le code HTML de base et les cartes source associées.
J'ai aussi fait fonctionner BrowserSync avec Gulp. Je ne savais peut-être pas quoi faire avec un fichier de configuration Webpack, mais cela ne signifiait pas que j'étais une sorte d'animal. Avoir à actualiser manuellement le navigateur lors de l'itération avec HTML/CSS est tellement 2010 et BrowserSync vous donne cette courte boucle de rétroaction et d'itération qui est si utile pour le codage frontal.
Voici le fichier gulp de base au 11.6.2017
Vous pouvez voir comment j'ai modifié le Gulpfile plus près de la fin de l'expédition, en ajoutant une minification avec ugilify :
Structure du projet
Par suite de mes choix technologiques, certains éléments d'organisation du code pour l'application se définissaient d'eux-mêmes. Un gulpfile.js à la racine du projet, un dossier node_modules (où Gulp stocke le code du plugin), un dossier preCSS pour les feuilles de style de création, un dossier ts pour les fichiers TypeScript et un dossier build pour que le code compilé vive.
L'idée était d'avoir un index.html contenant le "shell" de l'application, y compris toute structure HTML non dynamique, puis des liens vers les styles et le fichier JavaScript qui feraient fonctionner l'application. Sur le disque, cela ressemblerait à ceci :
build/ node_modules/ preCSS/ img/ partials/ styles.css ts/ .gitignore gulpfile.js index.html package.json tsconfig.json Configurer BrowserSync pour regarder ce dossier de build signifiait que je pouvais pointer mon navigateur sur localhost:3000 et tout allait bien.
Avec un système de construction de base en place, une organisation des fichiers établie et quelques conceptions de base pour commencer, je n'avais plus de fourrage de procrastination que je pouvais légitimement utiliser pour m'empêcher de construire réellement la chose !
Rédaction d'une candidature
Le principe de fonctionnement de l'application était le suivant. Il y aurait un magasin de données. Lorsque le JavaScript était chargé, il chargeait ces données, parcourait chaque lecteur dans les données, créant le code HTML nécessaire pour représenter chaque lecteur sous forme de ligne dans la mise en page et les plaçant dans la section d'entrée/sortie appropriée. Ensuite, les interactions de l'utilisateur déplaceraient un joueur d'un état à un autre. Simple.
Lorsqu'il s'agissait d'écrire l'application, les deux grands défis conceptuels qu'il fallait comprendre étaient :
- Comment représenter les données d'une application d'une manière qui pourrait être facilement étendue et manipulée ;
- Comment faire réagir l'interface utilisateur lorsque les données ont été modifiées à partir de l'entrée de l'utilisateur.
L'un des moyens les plus simples de représenter une structure de données en JavaScript consiste à utiliser la notation d'objet. Cette phrase lit un peu d'informatique. Plus simplement, un « objet » dans le jargon JavaScript est un moyen pratique de stocker des données.
Considérez cet objet JavaScript assigné à une variable appelée ioState (pour In/Out State) :
var ioState = { Count: 0, // Running total of how many players RosterCount: 0; // Total number of possible players ToolsExposed: false, // Whether the UI for the tools is showing Players: [], // A holder for the players }Si vous ne connaissez pas très bien JavaScript, vous pouvez probablement au moins comprendre ce qui se passe : chaque ligne à l'intérieur des accolades est une propriété (ou une "clé" dans le langage JavaScript) et une paire de valeurs. Vous pouvez définir toutes sortes de choses sur une clé JavaScript. Par exemple, des fonctions, des tableaux d'autres données ou des objets imbriqués. Voici un exemple :
var testObject = { testFunction: function() { return "sausages"; }, testArray: [3,7,9], nestedtObject { key1: "value1", key2: 2, } }Le résultat net est qu'en utilisant ce type de structure de données, vous pouvez obtenir et définir n'importe laquelle des clés de l'objet. Par exemple, si nous voulons définir le nombre de l'objet ioState sur 7 :
ioState.Count = 7;Si nous voulons définir un morceau de texte sur cette valeur, la notation fonctionne comme ceci :
aTextNode.textContent = ioState.Count;Vous pouvez voir que l'obtention de valeurs et la définition de valeurs pour cet objet d'état sont simples du côté JavaScript. Cependant, refléter ces changements dans l'interface utilisateur l'est moins. C'est le domaine principal où les frameworks et les bibliothèques cherchent à faire abstraction de la douleur.
En termes généraux, lorsqu'il s'agit de gérer la mise à jour de l'interface utilisateur en fonction de l'état, il est préférable d'éviter d'interroger le DOM, car cela est généralement considéré comme une approche sous-optimale.
Considérez l'interface Entrée/Sortie. Il affiche généralement une liste de joueurs potentiels pour une partie. Ils sont listés verticalement, l'un sous l'autre, en bas de la page.
Peut-être que chaque joueur est représenté dans le DOM avec une label enveloppant une input de case à cocher. De cette façon, cliquer sur un lecteur basculerait le lecteur sur "In" en vertu de l'étiquette rendant l'entrée "cochée".
Pour mettre à jour notre interface, nous pourrions avoir un "écouteur" sur chaque élément d'entrée dans le JavaScript. Sur un clic ou un changement, la fonction interroge le DOM et compte combien de nos entrées de joueur sont vérifiées. Sur la base de ce décompte, nous mettrons ensuite à jour quelque chose d'autre dans le DOM pour montrer à l'utilisateur combien de joueurs sont vérifiés.
Considérons le coût de cette opération de base. Nous écoutons sur plusieurs nœuds DOM le clic/vérification d'une entrée, puis nous interrogeons le DOM pour voir combien d'un type de DOM particulier sont vérifiés, puis nous écrivons quelque chose dans le DOM pour montrer à l'utilisateur, au niveau de l'interface utilisateur, le nombre de joueurs nous venons de compter.
L'alternative serait de conserver l'état de l'application en tant qu'objet JavaScript en mémoire. Un clic sur un bouton/une entrée dans le DOM pourrait simplement mettre à jour l'objet JavaScript, puis, en fonction de ce changement dans l'objet JavaScript, effectuer une mise à jour en un seul passage de toutes les modifications d'interface nécessaires. Nous pourrions ignorer l'interrogation du DOM pour compter les joueurs car l'objet JavaScript contiendrait déjà cette information.
Alors. L'utilisation d'une structure d'objet JavaScript pour l'état semblait simple mais suffisamment flexible pour encapsuler l'état de l'application à un moment donné. La théorie de la façon dont cela pourrait être géré semblait également assez solide – cela devait être à quoi ressemblaient des expressions comme « flux de données à sens unique » ? Cependant, la première véritable astuce serait de créer du code qui mettrait automatiquement à jour l'interface utilisateur en fonction de toute modification de ces données.
La bonne nouvelle est que des personnes plus intelligentes que moi ont déjà compris ce genre de choses ( Dieu merci ! ). Les gens ont perfectionné les approches de ce genre de défi depuis l'aube des applications. Cette catégorie de problèmes est le pain quotidien des « modèles de conception ». Le surnom de "modèle de conception" m'a semblé ésotérique au début, mais après avoir creusé un peu, tout a commencé à ressembler moins à de l'informatique et plus de bon sens.
Modèles de conception
Un modèle de conception, dans le lexique informatique, est une manière prédéfinie et éprouvée de résoudre un défi technique commun. Considérez les modèles de conception comme l'équivalent de codage d'une recette de cuisine.
La littérature la plus célèbre sur les modèles de conception est peut-être "Design Patterns : Elements of Reusable Object-Oriented Software" de 1994. Bien que cela traite de C++ et de smalltalk, les concepts sont transférables. Pour JavaScript, "Learning JavaScript Design Patterns" d'Addy Osmani couvre un terrain similaire. Vous pouvez également le lire en ligne gratuitement ici.
Modèle d'observateur
Généralement, les modèles de conception sont divisés en trois groupes : créationnels, structurels et comportementaux. Je cherchais quelque chose de comportemental qui aidait à gérer les changements de communication autour des différentes parties de l'application.
Plus récemment, j'ai vu et lu une très bonne plongée en profondeur sur la mise en œuvre de la réactivité dans une application par Gregg Pollack. Il y a à la fois un article de blog et une vidéo pour votre plaisir ici.
En lisant la description d'ouverture du modèle 'Observer' dans Learning JavaScript Design Patterns , j'étais à peu près sûr que c'était le modèle pour moi. Il est décrit ainsi :
L'observateur est un modèle de conception où un objet (appelé sujet) maintient une liste d'objets qui en dépendent (observateurs), les notifiant automatiquement de tout changement d'état.
Lorsqu'un sujet doit informer les observateurs d'un événement intéressant, il diffuse une notification aux observateurs (qui peut inclure des données spécifiques liées au sujet de la notification).
La clé de mon enthousiasme était que cela semblait offrir une certaine façon de mettre à jour les choses en cas de besoin.
Supposons que l'utilisateur ait cliqué sur une joueuse nommée "Betty" pour sélectionner qu'elle était "In" pour le jeu. Quelques éléments peuvent devoir se produire dans l'interface utilisateur :
- Ajouter 1 au nombre de joueurs
- Supprimer Betty du pool de joueurs "Out"
- Ajouter Betty au pool de joueurs "In"
L'application devrait également mettre à jour les données qui représentaient l'interface utilisateur. Ce que je tenais à éviter, c'est ceci :
playerName.addEventListener("click", playerToggle); function playerToggle() { if (inPlayers.includes(e.target.textContent)) { setPlayerOut(e.target.textContent); decrementPlayerCount(); } else { setPlayerIn(e.target.textContent); incrementPlayerCount(); } }L'objectif était d'avoir un flux de données élégant qui mettait à jour ce qui était nécessaire dans le DOM quand et si les données centrales étaient modifiées.
Avec un modèle Observer, il était possible d'envoyer des mises à jour de l'état et donc de l'interface utilisateur de manière assez succincte. Voici un exemple, la fonction réelle utilisée pour ajouter un nouveau joueur à la liste :
function itemAdd(itemString: string) { let currentDataSet = getCurrentDataSet(); var newPerson = new makePerson(itemString); io.items[currentDataSet].EventData.splice(0, 0, newPerson); io.notify({ items: io.items }); } La partie pertinente pour le modèle Observer étant la méthode io.notify . Comme cela nous montre la modification de la partie items de l'état de l'application, permettez-moi de vous montrer l'observateur qui a écouté les modifications apportées aux « éléments » :
io.addObserver({ props: ["items"], callback: function renderItems() { // Code that updates anything to do with items... } });Nous avons une méthode de notification qui apporte des modifications aux données, puis des observateurs à ces données qui répondent lorsque les propriétés qui les intéressent sont mises à jour.

Avec cette approche, l'application pourrait avoir des observables surveillant les changements dans n'importe quelle propriété des données et exécuter une fonction chaque fois qu'un changement se produisait.
Si vous êtes intéressé par le modèle Observer pour lequel j'ai opté, je le décris plus en détail ici.
Il y avait maintenant une approche pour mettre à jour l'interface utilisateur efficacement en fonction de l'état. Pêche. Cependant, cela me laissait toujours avec deux problèmes flagrants.
L'un était de savoir comment stocker l'état à travers les rechargements/sessions de page et le fait que malgré le fonctionnement de l'interface utilisateur, visuellement, ce n'était tout simplement pas très "app like". Par exemple, si un bouton était enfoncé, l'interface utilisateur changeait instantanément à l'écran. Ce n'était tout simplement pas particulièrement convaincant.
Traitons d'abord du côté du stockage.
État d'enregistrement
Mon principal intérêt, du côté du développement, était de comprendre comment les interfaces d'application pouvaient être construites et rendues interactives avec JavaScript. Comment stocker et récupérer des données à partir d'un serveur ou s'attaquer à l'authentification et aux connexions des utilisateurs était « hors de portée ».
Par conséquent, au lieu de me connecter à un service Web pour les besoins de stockage de données, j'ai choisi de conserver toutes les données sur le client. Il existe un certain nombre de méthodes de plate-forme Web pour stocker des données sur un client. J'ai opté pour localStorage .
L'API pour localStorage est incroyablement simple. Vous définissez et obtenez des données comme ceci :
// Set something localStorage.setItem("yourKey", "yourValue"); // Get something localStorage.getItem("yourKey"); LocalStorage a une méthode setItem à laquelle vous transmettez deux chaînes. Le premier est le nom de la clé avec laquelle vous souhaitez stocker les données et la seconde chaîne est la chaîne réelle que vous souhaitez stocker. La méthode getItem prend une chaîne comme argument qui vous renvoie tout ce qui est stocké sous cette clé dans localStorage. Agréable et simple.
Cependant, parmi les raisons de ne pas utiliser localStorage, il y a le fait que tout doit être enregistré sous forme de "chaîne". Cela signifie que vous ne pouvez pas stocker directement quelque chose comme un tableau ou un objet. Par exemple, essayez d'exécuter ces commandes dans la console de votre navigateur :
// Set something localStorage.setItem("myArray", [1, 2, 3, 4]); // Get something localStorage.getItem("myArray"); // Logs "1,2,3,4"Même si nous avons essayé de définir la valeur de 'myArray' en tant que tableau ; lorsque nous l'avons récupéré, il avait été stocké sous forme de chaîne (notez les guillemets autour de '1,2,3,4').
Vous pouvez certainement stocker des objets et des tableaux avec localStorage, mais vous devez garder à l'esprit qu'ils doivent être convertis dans les deux sens à partir de chaînes.
Ainsi, afin d'écrire des données d'état dans localStorage, elles ont été écrites dans une chaîne avec la méthode JSON.stringify() comme ceci :
const storage = window.localStorage; storage.setItem("players", JSON.stringify(io.items)); Lorsque les données devaient être récupérées à partir de localStorage, la chaîne a été transformée en données utilisables avec la méthode JSON.parse() comme ceci :
const players = JSON.parse(storage.getItem("players")); L'utilisation de localStorage signifiait que tout était sur le client et cela signifiait qu'il n'y avait aucun problème de services tiers ou de stockage de données.
Les données étaient désormais des actualisations et des sessions persistantes - Yay ! La mauvaise nouvelle était que localStorage ne survit pas à un utilisateur qui vide les données de son navigateur. Quand quelqu'un faisait cela, toutes ses données d'entrée/sortie étaient perdues. C'est une grave lacune.
Il n'est pas difficile de comprendre que `localStorage` n'est probablement pas la meilleure solution pour les applications `` appropriées ''. Outre le problème de chaîne mentionné ci-dessus, il est également lent pour un travail sérieux car il bloque le "thread principal". Des alternatives arrivent, comme KV Storage mais pour l'instant, faites une note mentale pour mettre en garde son utilisation en fonction de son adéquation.
Malgré la fragilité de l'enregistrement local des données sur l'appareil d'un utilisateur, la connexion à un service ou à une base de données a résisté. Au lieu de cela, le problème a été contourné en offrant une option « charger/sauvegarder ». Cela permettrait à tout utilisateur d'In/Out d'enregistrer ses données dans un fichier JSON qui pourrait être rechargé dans l'application si nécessaire.
Cela a bien fonctionné sur Android mais beaucoup moins élégamment sur iOS. Sur un iPhone, cela a entraîné une folie de texte à l'écran comme ceci :
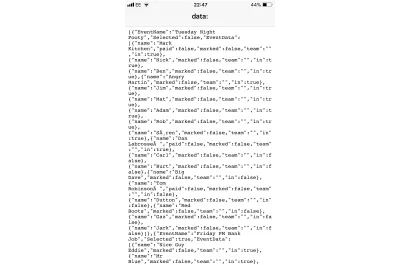
Comme vous pouvez l'imaginer, j'étais loin d'être le seul à réprimander Apple via WebKit à propos de cette lacune. Le bug pertinent était ici.
Au moment d'écrire ces lignes, ce bogue a une solution et un correctif, mais n'a pas encore fait son chemin dans iOS Safari. Apparemment, iOS13 le corrige, mais c'est en version bêta au moment où j'écris.
Donc, pour mon produit minimum viable, cela concernait le stockage. Il était maintenant temps d'essayer de rendre les choses plus "app-like" !
App-I-Ness
Il s'avère qu'après de nombreuses discussions avec de nombreuses personnes, il est assez difficile de définir exactement ce que signifie « app like ».
En fin de compte, j'ai décidé que "semblable à une application" était synonyme d'une finesse visuelle généralement absente du Web. Quand je pense aux applications qui se sentent bien à utiliser, elles comportent toutes du mouvement. Pas gratuit, mais mouvement qui ajoute à l'histoire de vos actions. Il peut s'agir des transitions de page entre les écrans, de la manière dont les menus apparaissent. C'est difficile à décrire avec des mots, mais la plupart d'entre nous le savent quand nous le voyons.
Le premier élément visuel nécessaire consistait à déplacer les noms des joueurs vers le haut ou vers le bas de «In» à «Out» et vice-versa lorsqu'ils étaient sélectionnés. Faire en sorte qu'un joueur passe instantanément d'une section à l'autre était simple, mais certainement pas comme une application. Une animation au moment où un nom de joueur a été cliqué mettrait, espérons-le, en valeur le résultat de cette interaction - le joueur passant d'une catégorie à une autre.
Comme beaucoup de ces types d'interactions visuelles, leur simplicité apparente dément la complexité impliquée pour le faire fonctionner correctement.
Il a fallu quelques itérations pour obtenir le bon mouvement, mais la logique de base était la suivante :
- Une fois qu'un « joueur » est cliqué, capturez où ce joueur se trouve, géométriquement, sur la page ;
- Mesurez à quelle distance du haut de la zone le joueur doit se déplacer s'il monte (« In ») et à quelle distance se trouve le bas, s'il descend (« Out ») ;
- Si vous montez, un espace égal à la hauteur de la rangée de joueurs doit être laissé lorsque le joueur monte et les joueurs au-dessus doivent s'effondrer vers le bas au même rythme que le temps qu'il faut au joueur pour se déplacer pour atterrir dans l'espace. libéré par les joueurs "In" existants (s'il en existe) qui descendent ;
- Si un joueur sort et descend, tout le reste doit remonter dans l'espace restant et le joueur doit se retrouver en dessous de tous les joueurs "sortis" actuels.
Phew! C'était plus compliqué que je ne le pensais en anglais - sans parler de JavaScript !
Il y avait des complexités supplémentaires à considérer et à tester, telles que les vitesses de transition. Au départ, il n'était pas évident de savoir si une vitesse de déplacement constante (par exemple 20 pixels par 20 ms) ou une durée constante du mouvement (par exemple 0,2 s) serait meilleure. Le premier était légèrement plus compliqué car la vitesse devait être calculée "à la volée" en fonction de la distance que le joueur devait parcourir - une plus grande distance nécessitant une durée de transition plus longue.
Cependant, il s'est avéré qu'une durée de transition constante n'était pas seulement plus simple dans le code ; elle produisait en fait un effet plus favorable. La différence était subtile, mais c'est le genre de choix que vous ne pouvez déterminer qu'une fois que vous avez vu les deux options.
De temps en temps, en essayant de créer cet effet, un problème visuel attirait l'attention, mais il était impossible de le déconstruire en temps réel. J'ai trouvé que le meilleur processus de débogage consistait à créer un enregistrement QuickTime de l'animation, puis à le parcourir une image à la fois. Invariablement, cela a révélé le problème plus rapidement que n'importe quel débogage basé sur du code.
En regardant le code maintenant, je peux comprendre que sur quelque chose au-delà de mon humble application, cette fonctionnalité pourrait presque certainement être écrite plus efficacement. Étant donné que l'application connaîtrait le nombre de joueurs et connaîtrait la hauteur fixe des lattes, il devrait être tout à fait possible de faire tous les calculs de distance dans le JavaScript seul, sans aucune lecture DOM.
Ce n'est pas que ce qui a été livré ne fonctionne pas, c'est juste que ce n'est pas le genre de solution de code que vous présenteriez sur Internet. Oh, attendez.
D'autres interactions "de type application" étaient beaucoup plus faciles à réaliser. Au lieu que les menus s'enclenchent et se détachent simplement avec quelque chose d'aussi simple que de basculer une propriété d'affichage, beaucoup de kilométrage a été gagné en les exposant simplement avec un peu plus de finesse. Il était toujours déclenché simplement mais CSS faisait tout le gros du travail :
.io-EventLoader { position: absolute; top: 100%; margin-top: 5px; z-index: 100; width: 100%; opacity: 0; transition: all 0.2s; pointer-events: none; transform: translateY(-10px); [data-evswitcher-showing="true"] & { opacity: 1; pointer-events: auto; transform: none; } } Là, lorsque l' data-evswitcher-showing="true" était basculé sur un élément parent, le menu s'estompait, se transformait à sa position par défaut et les événements de pointeur étaient réactivés afin que le menu puisse recevoir des clics.
Méthodologie des feuilles de style ECSS
Vous remarquerez dans ce code précédent que du point de vue de la création, les remplacements CSS sont imbriqués dans un sélecteur parent. C'est ainsi que je privilégie toujours l'écriture de feuilles de style d'interface utilisateur ; une seule source de vérité pour chaque sélecteur et tous les remplacements pour ce sélecteur encapsulés dans un seul ensemble d'accolades. C'est un modèle qui nécessite l'utilisation d'un processeur CSS (Sass, PostCSS, LESS, Stylus, et al) mais je pense que c'est le seul moyen positif d'utiliser la fonctionnalité d'imbrication.
J'avais cimenté cette approche dans mon livre, Enduring CSS et bien qu'il y ait une pléthore de méthodes plus impliquées disponibles pour écrire du CSS pour les éléments d'interface, ECSS m'a bien servi ainsi que les grandes équipes de développement avec lesquelles je travaille depuis que l'approche a été documentée pour la première fois retour en 2014 ! Il s'est avéré tout aussi efficace dans ce cas.
Partialiser le TypeScript
Même sans processeur CSS ou langage sur-ensemble comme Sass, CSS a eu la possibilité d'importer un ou plusieurs fichiers CSS dans un autre avec la directive import :
@import "other-file.css";Lorsque j'ai commencé avec JavaScript, j'ai été surpris qu'il n'y ait pas d'équivalent. Chaque fois que les fichiers de code deviennent plus longs qu'un écran ou si haut, on a toujours l'impression qu'il serait avantageux de le diviser en plus petits morceaux.
Un autre avantage de l'utilisation de TypeScript est qu'il dispose d'un moyen magnifiquement simple de diviser le code en fichiers et de les importer si nécessaire.
Cette fonctionnalité était antérieure aux modules JavaScript natifs et était une fonctionnalité très pratique. Lorsque TypeScript a été compilé, il a tout regroupé dans un seul fichier JavaScript. Cela signifiait qu'il était possible de diviser facilement le code de l'application en fichiers partiels gérables pour la création et de les importer ensuite facilement dans le fichier principal. Le haut des inout.ts principaux ressemblait à ceci :
/// <reference path="defaultData.ts" /> /// <reference path="splitTeams.ts" /> /// <reference path="deleteOrPaidClickMask.ts" /> /// <reference path="repositionSlat.ts" /> /// <reference path="createSlats.ts" /> /// <reference path="utils.ts" /> /// <reference path="countIn.ts" /> /// <reference path="loadFile.ts" /> /// <reference path="saveText.ts" /> /// <reference path="observerPattern.ts" /> /// <reference path="onBoard.ts" />Cette simple tâche d'entretien ménager et d'organisation a énormément aidé.
Événements multiples
Au départ, j'ai pensé que d'un point de vue fonctionnel, un seul événement, comme "Tuesday Night Football", suffirait. Dans ce scénario, si vous avez chargé In/Out, vous venez d'ajouter/supprimer ou de déplacer des joueurs et c'est tout. Il n'y avait aucune notion d'événements multiples.
J'ai rapidement décidé que (même en optant pour un produit minimum viable), cela donnerait une expérience assez limitée. Et si quelqu'un organisait deux matchs à des jours différents, avec une liste de joueurs différente ? In/Out pourrait/devrait sûrement répondre à ce besoin ? Il n'a pas fallu trop de temps pour remodeler les données pour rendre cela possible et modifier les méthodes nécessaires pour charger dans un ensemble différent.
Au départ, l'ensemble de données par défaut ressemblait à ceci :
var defaultData = [ { name: "Daz", paid: false, marked: false, team: "", in: false }, { name: "Carl", paid: false, marked: false, team: "", in: false }, { name: "Big Dave", paid: false, marked: false, team: "", in: false }, { name: "Nick", paid: false, marked: false, team: "", in: false } ];Un tableau contenant un objet pour chaque joueur.
Après avoir pris en compte plusieurs événements, il a été modifié pour ressembler à ceci :
var defaultDataV2 = [ { EventName: "Tuesday Night Footy", Selected: true, EventData: [ { name: "Jack", marked: false, team: "", in: false }, { name: "Carl", marked: false, team: "", in: false }, { name: "Big Dave", marked: false, team: "", in: false }, { name: "Nick", marked: false, team: "", in: false }, { name: "Red Boots", marked: false, team: "", in: false }, { name: "Gaz", marked: false, team: "", in: false }, { name: "Angry Martin", marked: false, team: "", in: false } ] }, { EventName: "Friday PM Bank Job", Selected: false, EventData: [ { name: "Mr Pink", marked: false, team: "", in: false }, { name: "Mr Blonde", marked: false, team: "", in: false }, { name: "Mr White", marked: false, team: "", in: false }, { name: "Mr Brown", marked: false, team: "", in: false } ] }, { EventName: "WWII Ladies Baseball", Selected: false, EventData: [ { name: "C Dottie Hinson", marked: false, team: "", in: false }, { name: "P Kit Keller", marked: false, team: "", in: false }, { name: "Mae Mordabito", marked: false, team: "", in: false } ] } ]; Les nouvelles données étaient un tableau avec un objet pour chaque événement. Ensuite, dans chaque événement, il y avait une propriété EventData qui était un tableau avec des objets de joueur comme avant.
Il a fallu beaucoup plus de temps pour reconsidérer comment l'interface pouvait gérer au mieux cette nouvelle capacité.
Dès le départ, le design avait toujours été très stérile. Considérant que c'était aussi censé être un exercice de conception, je ne me sentais pas assez courageux. Donc, un peu plus de flair visuel a été ajouté, en commençant par l'en-tête. Voici ce que j'ai simulé dans Sketch:
Il n'allait pas gagner de prix, mais c'était certainement plus saisissant que là où il avait commencé.
Mis à part l'esthétique, ce n'est que lorsque quelqu'un d'autre l'a signalé que j'ai apprécié que la grande icône plus dans l'en-tête soit très déroutante. La plupart des gens pensaient que c'était une façon d'ajouter un autre événement. En réalité, il est passé en mode "Ajouter un joueur" avec une transition sophistiquée qui vous permet de taper le nom du joueur au même endroit que le nom de l'événement.
C'était un autre cas où un regard neuf était inestimable. C'était aussi une leçon importante pour lâcher prise. La vérité honnête était que j'avais conservé la transition du mode d'entrée dans l'en-tête parce que je trouvais que c'était cool et intelligent. Cependant, le fait était qu'il ne servait pas la conception et donc l'application dans son ensemble.
Cela a été modifié dans la version live. Au lieu de cela, l'en-tête ne traite que des événements - un scénario plus courant. Pendant ce temps, l'ajout de joueurs se fait à partir d'un sous-menu. Cela donne à l'application une hiérarchie beaucoup plus compréhensible.
L'autre leçon apprise ici est que, dans la mesure du possible, il est extrêmement avantageux d'obtenir des commentaires sincères de la part de ses pairs. S'ils sont bons et honnêtes, ils ne vous laisseront pas passer !
Résumé : Mon code pue
Droit. Jusqu'à présent, une rétrospective d'aventure technologique tellement normale ; ces choses coûtent dix centimes sur Medium ! La formule ressemble à ceci : le développeur détaille comment il a brisé tous les obstacles pour publier un logiciel finement réglé sur Internet, puis obtenir un entretien chez Google ou s'être fait embaucher quelque part. Cependant, la vérité est que j'étais un débutant dans ce malarkey de création d'applications, de sorte que le code a finalement été expédié en tant qu'application «terminée» puant au ciel!
Par exemple, l'implémentation du modèle Observer utilisée a très bien fonctionné. J'étais organisé et méthodique au début, mais cette approche s'est "estompée" au fur et à mesure que je cherchais désespérément à finir les choses. Comme un régime en série, de vieilles habitudes familières se sont glissées et la qualité du code a ensuite chuté.
Looking now at the code shipped, it is a less than ideal hodge-bodge of clean observer pattern and bog-standard event listeners calling functions. In the main inout.ts file there are over 20 querySelector method calls; hardly a poster child for modern application development!
I was pretty sore about this at the time, especially as at the outset I was aware this was a trap I didn't want to fall into. However, in the months that have since passed, I've become more philosophical about it.
The final post in this series reflects on finding the balance between silvery-towered code idealism and getting things shipped. It also covers the most important lessons learned during this process and my future aspirations for application development.