
Garder Node.js rapide : outils, techniques et astuces pour créer des serveurs Node.js hautes performances
Publié: 2022-03-10Si vous construisez quelque chose avec Node.js depuis assez longtemps, vous avez sans aucun doute connu la douleur de problèmes de vitesse inattendus. JavaScript est un langage événementiel et asynchrone. Cela peut compliquer le raisonnement sur les performances, comme cela deviendra évident. La popularité croissante de Node.js a mis en évidence le besoin d'outils, de techniques et d'une réflexion adaptés aux contraintes de JavaScript côté serveur.
En matière de performances, ce qui fonctionne dans le navigateur ne convient pas nécessairement à Node.js. Alors, comment s'assurer qu'une implémentation Node.js est rapide et adaptée à son objectif ? Passons en revue un exemple pratique.
Outils
Node est une plate-forme très polyvalente, mais l'une des applications prédominantes est la création de processus en réseau. Nous allons nous concentrer sur le profilage des plus courants d'entre eux : les serveurs Web HTTP.
Nous aurons besoin d'un outil capable de faire exploser un serveur avec de nombreuses requêtes tout en mesurant les performances. Par exemple, nous pouvons utiliser AutoCannon :
npm install -g autocannonApache Bench (ab) et wrk2 sont d'autres bons outils d'analyse comparative HTTP, mais AutoCannon est écrit en Node, fournit une pression de charge similaire (ou parfois supérieure) et est très facile à installer sur Windows, Linux et Mac OS X.
Après avoir établi une mesure de performance de base, si nous décidons que notre processus pourrait être plus rapide, nous aurons besoin d'un moyen de diagnostiquer les problèmes avec le processus. Un excellent outil pour diagnostiquer divers problèmes de performances est Node Clinic, qui peut également être installé avec npm :
npm install -g clinicCela installe en fait une suite d'outils. Nous utiliserons Clinic Doctor et Clinic Flame (un wrapper autour de 0x) au fur et à mesure.
Remarque : Pour cet exemple pratique, nous aurons besoin de Node 8.11.2 ou supérieur.
Le code
Notre cas d'exemple est un serveur REST simple avec une seule ressource : une grande charge utile JSON exposée en tant que route GET à /seed/v1 . Le serveur est un dossier d' app composé d'un fichier package.json (selon restify 7.1.0 ), d'un fichier index.js et d'un fichier util.js.
Le fichier index.js de notre serveur ressemble à ceci :
'use strict' const restify = require('restify') const { etagger, timestamp, fetchContent } = require('./util')() const server = restify.createServer() server.use(etagger().bind(server)) server.get('/seed/v1', function (req, res, next) { fetchContent(req.url, (err, content) => { if (err) return next(err) res.send({data: content, url: req.url, ts: timestamp()}) next() }) }) server.listen(3000) Ce serveur est représentatif du cas courant de diffusion de contenu dynamique mis en cache par le client. Ceci est réalisé avec le middleware etagger , qui calcule un en-tête ETag pour le dernier état du contenu.
Le fichier util.js fournit des éléments d'implémentation qui seraient couramment utilisés dans un tel scénario, une fonction pour récupérer le contenu pertinent à partir d'un backend, le middleware etag et une fonction d'horodatage qui fournit des horodatages minute par minute :
'use strict' require('events').defaultMaxListeners = Infinity const crypto = require('crypto') module.exports = () => { const content = crypto.rng(5000).toString('hex') const ONE_MINUTE = 60000 var last = Date.now() function timestamp () { var now = Date.now() if (now — last >= ONE_MINUTE) last = now return last } function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } function fetchContent (url, cb) { setImmediate(() => { if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404})) else cb(null, content) }) } return { timestamp, etagger, fetchContent } }Ne prenez en aucun cas ce code comme un exemple de bonnes pratiques ! Il existe plusieurs odeurs de code dans ce fichier, mais nous les localiserons au fur et à mesure que nous mesurerons et profilerons l'application.
Pour obtenir la source complète de notre point de départ, le serveur lent peut être trouvé ici.
Profilage
Pour profiler, nous avons besoin de deux terminaux, l'un pour démarrer l'application et l'autre pour le tester en charge.
Dans un terminal, dans le dossier app , nous pouvons exécuter :
node index.jsDans un autre terminal, nous pouvons le profiler comme suit :
autocannon -c100 localhost:3000/seed/v1Cela ouvrira 100 connexions simultanées et bombardera le serveur de requêtes pendant dix secondes.
Les résultats devraient être quelque chose de similaire à ce qui suit (Exécution du test 10s @ https://localhost:3000/seed/v1 — 100 connexions) :
| Statistique | Moy | Stdev | Max |
|---|---|---|---|
| Latence (ms) | 3086.81 | 1725.2 | 5554 |
| Demande/Sec | 23.1 | 19.18 | 65 |
| Octets/s | 237,98 ko | 197,7 Ko | 688,13 ko |
Les résultats varient en fonction de la machine. Cependant, étant donné qu'un serveur Node.js "Hello World" est facilement capable de traiter trente mille requêtes par seconde sur cette machine qui a produit ces résultats, 23 requêtes par seconde avec une latence moyenne supérieure à 3 secondes est lamentable.
Diagnostiquer
Découvrir la zone problématique
Nous pouvons diagnostiquer l'application avec une seule commande, grâce à la commande –on-port de Clinic Doctor. Dans le dossier de l' app , nous exécutons :
clinic doctor --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsCela créera un fichier HTML qui s'ouvrira automatiquement dans notre navigateur une fois le profilage terminé.
Les résultats devraient ressembler à ce qui suit :
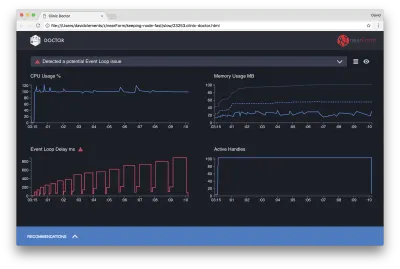
Le docteur nous dit que nous avons probablement eu un problème de boucle d'événement.
En plus du message en haut de l'interface utilisateur, nous pouvons également voir que le graphique de la boucle d'événements est rouge et affiche un retard en constante augmentation. Avant d'approfondir ce que cela signifie, commençons par comprendre l'effet que le problème diagnostiqué a sur les autres mesures.
Nous pouvons voir que le processeur est constamment égal ou supérieur à 100 %, car le processus travaille dur pour traiter les requêtes en file d'attente. Le moteur JavaScript de Node (V8) utilise en fait deux cœurs de processeur dans ce cas car la machine est multicœur et V8 utilise deux threads. L'un pour la boucle d'événement et l'autre pour la récupération de place. Lorsque nous voyons le processeur grimper jusqu'à 120 % dans certains cas, le processus collecte des objets liés aux requêtes traitées.
Nous voyons cela corrélé dans le graphique de la mémoire. La ligne pleine dans le graphique Mémoire correspond à la métrique Heap Used. Chaque fois qu'il y a un pic de CPU, nous constatons une chute de la ligne Heap Used, indiquant que la mémoire est désallouée.
Les poignées actives ne sont pas affectées par le délai de boucle d'événement. Un handle actif est un objet qui représente soit des E/S (comme un socket ou un handle de fichier) soit une minuterie (comme un setInterval ). Nous avons demandé à AutoCannon d'ouvrir 100 connexions ( -c100 ). Les descripteurs actifs conservent un nombre constant de 103. Les trois autres sont les descripteurs de STDOUT, STDERR et le descripteur du serveur lui-même.
Si nous cliquons sur le panneau Recommandations en bas de l'écran, nous devrions voir quelque chose comme ceci :
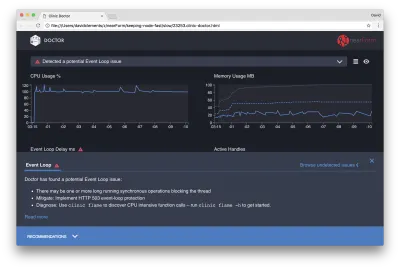
Atténuation à court terme
L'analyse des causes profondes des problèmes de performances graves peut prendre du temps. Dans le cas d'un projet déployé en direct, il vaut la peine d'ajouter une protection contre les surcharges aux serveurs ou aux services. L'idée de la protection contre les surcharges est de surveiller le délai de la boucle d'événement (entre autres) et de répondre par "503 Service indisponible" si un seuil est dépassé. Cela permet à un équilibreur de charge de basculer vers d'autres instances ou, dans le pire des cas, signifie que les utilisateurs devront actualiser. Le module de protection contre les surcharges peut fournir cela avec une surcharge minimale pour Express, Koa et Restify. Le framework Hapi a un paramètre de configuration de charge qui offre la même protection.
Comprendre la zone problématique
Comme l'explique la courte explication dans Clinic Doctor, si la boucle d'événements est retardée au niveau que nous observons, il est très probable qu'une ou plusieurs fonctions « bloquent » la boucle d'événements.
Il est particulièrement important avec Node.js de reconnaître cette caractéristique principale de JavaScript : les événements asynchrones ne peuvent pas se produire tant que le code en cours d'exécution n'est pas terminé.
C'est pourquoi un setTimeout ne peut pas être précis.
Par exemple, essayez d'exécuter ce qui suit dans les DevTools d'un navigateur ou le Node REPL :
console.time('timeout') setTimeout(console.timeEnd, 100, 'timeout') let n = 1e7 while (n--) Math.random() La mesure de temps résultante ne sera jamais de 100 ms. Il sera probablement compris entre 150 ms et 250 ms. Le setTimeout a planifié une opération asynchrone ( console.timeEnd ), mais le code en cours d'exécution n'est pas encore terminé ; il y a deux autres lignes. Le code en cours d'exécution est connu sous le nom de "tick" actuel. Pour que le tick se termine, Math.random doit être appelé dix millions de fois. Si cela prend 100 ms, le temps total avant la résolution du délai d'attente sera de 200 ms (plus le temps nécessaire à la fonction setTimeout pour mettre en file d'attente le délai d'attente au préalable, généralement quelques millisecondes).
Dans un contexte côté serveur, si une opération dans le tick actuel prend beaucoup de temps pour se terminer, les requêtes ne peuvent pas être traitées et la récupération des données ne peut pas se produire car le code asynchrone ne sera pas exécuté tant que le tick actuel ne sera pas terminé. Cela signifie qu'un code coûteux en calculs ralentira toutes les interactions avec le serveur. Il est donc recommandé de diviser le travail intense en ressources en processus séparés et de les appeler depuis le serveur principal, cela évitera les cas où une route rarement utilisée mais coûteuse ralentit les performances d'autres routes fréquemment utilisées mais peu coûteuses.
L'exemple de serveur a du code qui bloque la boucle d'événements, donc l'étape suivante consiste à localiser ce code.
en cours d'analyse
Une façon d'identifier rapidement le code peu performant consiste à créer et à analyser un graphique de flamme. Un graphique à flammes représente les appels de fonction sous forme de blocs superposés, non pas dans le temps, mais globalement. La raison pour laquelle on l'appelle un " graphe de flamme " est qu'il utilise généralement un schéma de couleurs orange à rouge, où plus un bloc est rouge, plus une fonction est " chaude ", c'est-à-dire plus elle est susceptible de bloquer la boucle d'événements. La capture de données pour un graphique de flamme est effectuée par échantillonnage du processeur, ce qui signifie qu'un instantané de la fonction en cours d'exécution et de sa pile est pris. La chaleur est déterminée par le pourcentage de temps pendant le profilage qu'une fonction donnée est au sommet de la pile (par exemple la fonction en cours d'exécution) pour chaque échantillon. Si ce n'est pas la dernière fonction à être appelée dans cette pile, il est probable qu'elle bloque la boucle d'événements.
Utilisons la clinic flame pour générer un graphique de flamme de l'exemple d'application :
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsLe résultat devrait s'ouvrir dans notre navigateur avec quelque chose comme ceci :
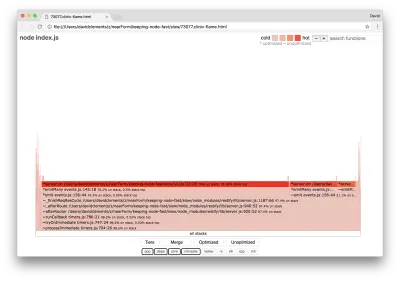
La largeur d'un bloc représente le temps total passé sur le processeur. Trois piles principales peuvent être observées prenant le plus de temps, toutes mettant en évidence server.on comme la fonction la plus chaude. En vérité, les trois piles sont identiques. Ils divergent car lors du profilage, les fonctions optimisées et non optimisées sont traitées comme des cadres d'appel distincts. Les fonctions précédées d'un * sont optimisées par le moteur JavaScript, et celles précédées d'un ~ ne sont pas optimisées. Si l'état optimisé n'est pas important pour nous, nous pouvons simplifier davantage le graphique en appuyant sur le bouton Fusionner. Cela devrait conduire à une vue similaire à la suivante :
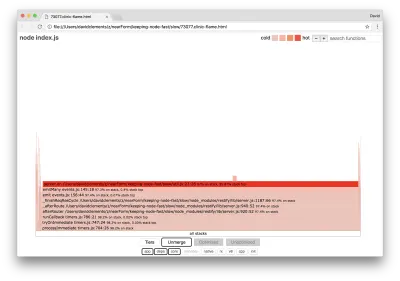
D'emblée, on peut en déduire que le code incriminé se trouve dans le fichier util.js du code de l'application.
La fonction lente est également un gestionnaire d'événements : les fonctions menant à la fonction font partie du module d' events de base, et server.on est un nom de secours pour une fonction anonyme fournie en tant que fonction de gestion d'événements. Nous pouvons également voir que ce code n'est pas dans le même tick que le code qui gère réellement la requête. Si c'était le cas, les fonctions des modules principaux http , net et stream seraient dans la pile.
Ces fonctions de base peuvent être trouvées en développant d'autres parties, beaucoup plus petites, du graphique de la flamme. Par exemple, essayez d'utiliser l'entrée de recherche en haut à droite de l'interface utilisateur pour rechercher send (le nom des méthodes internes restify et http ). Il devrait être à droite du graphique (les fonctions sont triées par ordre alphabétique) :
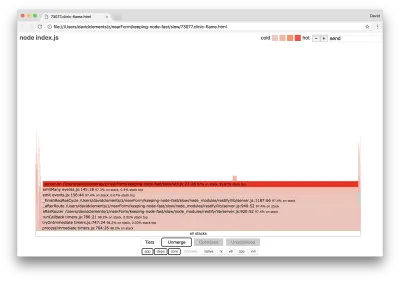
Remarquez à quel point tous les blocs de traitement HTTP réels sont relativement petits.

Nous pouvons cliquer sur l'un des blocs mis en surbrillance en cyan qui se développera pour afficher des fonctions telles que writeHead et write dans le fichier http_outgoing.js (partie de la bibliothèque http principale de Node) :
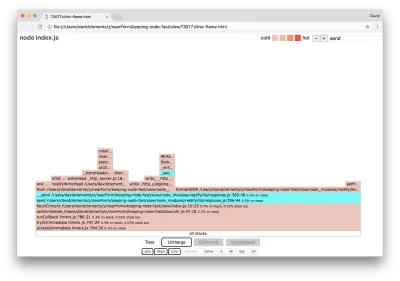
Nous pouvons cliquer sur toutes les piles pour revenir à la vue principale.
Le point clé ici est que même si la fonction server.on n'est pas dans la même coche que le code de traitement des demandes réel, elle affecte toujours les performances globales du serveur en retardant l'exécution d'un code autrement performant.
Débogage
Nous savons d'après le graphique de flamme que la fonction problématique est le gestionnaire d'événements transmis à server.on dans le fichier util.js.
Nous allons jeter un coup d'oeil:
server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) Il est bien connu que la cryptographie a tendance à être coûteuse, tout comme la sérialisation ( JSON.stringify ) mais pourquoi n'apparaissent-ils pas dans le graphe de flamme ? Ces opérations se trouvent dans les échantillons capturés, mais elles sont cachées derrière le filtre cpp . Si nous appuyons sur le bouton cpp , nous devrions voir quelque chose comme ceci :
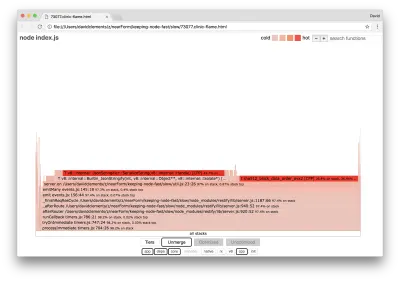
Les instructions internes V8 relatives à la fois à la sérialisation et à la cryptographie sont désormais présentées comme les piles les plus chaudes et comme prenant la plupart du temps. La méthode JSON.stringify appelle directement le code C++ ; c'est pourquoi nous ne voyons pas de fonction JavaScript. Dans le cas de la cryptographie, des fonctions telles que createHash et update se trouvent dans les données, mais elles sont soit en ligne (ce qui signifie qu'elles disparaissent dans la vue fusionnée), soit trop petites pour être rendues.
Une fois que nous commençons à raisonner sur le code dans la fonction etagger , il peut rapidement devenir évident qu'il est mal conçu. Pourquoi prenons-nous l'instance de server du contexte de la fonction ? Il y a beaucoup de hachage en cours, est-ce que tout cela est nécessaire ? Il n'y a pas non plus de prise en charge de l'en-tête If-None-Match dans l'implémentation, ce qui atténuerait une partie de la charge dans certains scénarios réels, car les clients ne feraient qu'une demande principale pour déterminer la fraîcheur.
Ignorons tous ces points pour le moment et validons la conclusion que le travail réel effectué dans server.on est en effet le goulot d'étranglement. Ceci peut être réalisé en définissant le code server.on sur une fonction vide et en générant un nouveau flamegraph.
Modifiez la fonction etagger comme suit :
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } La fonction d'écouteur d'événement transmise à server.on est désormais une fonction no-op.
Lançons à nouveau la clinic flame :
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsCela devrait produire un graphique de flamme semblable au suivant :
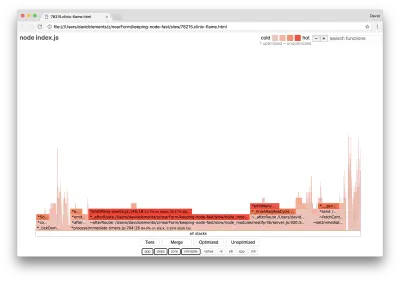
Cela semble mieux, et nous aurions dû remarquer une augmentation de la demande par seconde. Mais pourquoi l'événement émettant du code est-il si chaud ? Nous nous attendrions à ce stade que le code de traitement HTTP occupe la majorité du temps CPU, il n'y a rien du tout en cours d'exécution dans l'événement server.on .
Ce type de goulot d'étranglement est dû au fait qu'une fonction est exécutée plus qu'elle ne devrait l'être.
Le code suspect suivant en haut de util.js peut être un indice :
require('events').defaultMaxListeners = Infinity Supprimons cette ligne et commençons notre processus avec l' --trace-warnings :
node --trace-warnings index.jsSi nous profilons avec AutoCannon dans un autre terminal, comme ceci :
autocannon -c100 localhost:3000/seed/v1Notre processus produira quelque chose de similaire à :
(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
Node nous dit que de nombreux événements sont attachés à l'objet serveur . C'est étrange car il y a un booléen qui vérifie si l'événement a été attaché, puis revient tôt, ce qui fait de attachAfterEvent un no-op après que le premier événement est attaché.
Jetons un coup d'œil à la fonction attachAfterEvent :
var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } Le contrôle conditionnel est faux ! Il vérifie si attachAfterEvent est vrai au lieu de afterEventAttached . Cela signifie qu'un nouvel événement est attaché à l'instance de server à chaque demande, puis tous les événements attachés précédents sont déclenchés après chaque demande. Oups !
Optimisation
Maintenant que nous avons découvert les problèmes, voyons si nous pouvons rendre le serveur plus rapide.
Fruits mûrs
Remettons le code de l'écouteur server.on (au lieu d'une fonction vide) et utilisons le nom booléen correct dans la vérification conditionnelle. Notre fonction etagger se présente comme suit :
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (afterEventAttached === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } }Maintenant, nous vérifions notre correctif en profilant à nouveau. Démarrez le serveur dans un terminal :
node index.jsPuis profilez avec AutoCannon :
autocannon -c100 localhost:3000/seed/v1 Nous devrions voir des résultats quelque part dans la plage d'une amélioration de 200 fois (test d'exécution de 10 s @ https://localhost:3000/seed/v1 - 100 connexions) :
| Statistique | Moy | Stdev | Max |
|---|---|---|---|
| Latence (ms) | 19h47 | 4.29 | 103 |
| Demande/Sec | 5011.11 | 506.2 | 5487 |
| Octets/s | 51,8 Mo | 5,45 Mo | 58,72 Mo |
Il est important d'équilibrer les réductions potentielles des coûts des serveurs avec les coûts de développement. Nous devons définir, dans nos propres contextes situationnels, jusqu'où nous devons aller dans l'optimisation d'un projet. Sinon, il peut être trop facile de mettre 80% de l'effort dans 20% des améliorations de vitesse. Les contraintes du projet le justifient-elles ?
Dans certains scénarios, il pourrait être approprié d'obtenir une amélioration de 200 fois avec un fruit à portée de main et de l'appeler un jour. Dans d'autres, nous voudrons peut-être rendre notre implémentation aussi rapide que possible. Cela dépend vraiment des priorités du projet.
Une façon de contrôler les dépenses en ressources consiste à se fixer un objectif. Par exemple, 10 fois l'amélioration, ou 4000 requêtes par seconde. Il est plus logique de baser cela sur les besoins de l'entreprise. Par exemple, si les coûts du serveur dépassent de 100 % le budget, nous pouvons définir un objectif d'amélioration 2x.
Aller plus loin
Si nous produisons un nouveau graphique de flamme de notre serveur, nous devrions voir quelque chose de similaire à ce qui suit :
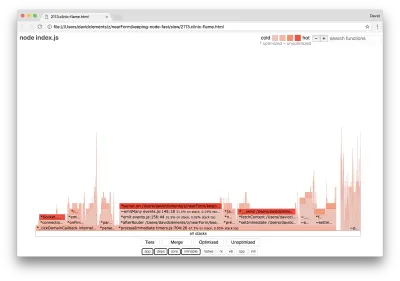
L'écouteur d'événements est toujours le goulot d'étranglement, il occupe toujours un tiers du temps CPU pendant le profilage (la largeur est d'environ un tiers du graphique entier).
Quels gains supplémentaires peuvent être réalisés, et les changements (ainsi que leurs perturbations associées) valent-ils la peine d'être apportés ?
Avec une implémentation optimisée, mais néanmoins un peu plus contrainte, les performances suivantes peuvent être atteintes (Running 10s test @ https://localhost:3000/seed/v1 — 10 connexions) :
| Statistique | Moy | Stdev | Max |
|---|---|---|---|
| Latence (ms) | 0,64 | 0,86 | 17 |
| Demande/Sec | 8330.91 | 757.63 | 8991 |
| Octets/s | 84,17 Mo | 7,64 Mo | 92,27 Mo |
Bien qu'une amélioration de 1,6x soit significative, cela dépend sans doute de la situation si l'effort, les changements et la perturbation du code nécessaires pour créer cette amélioration sont justifiés. Surtout par rapport à l'amélioration de 200x par rapport à l'implémentation d'origine avec une seule correction de bogue.
Pour réaliser cette amélioration, la même technique itérative de profilage, génération de flamegraph, analyse, débogage et optimisation a été utilisée pour arriver au serveur final optimisé, dont le code peut être trouvé ici.
Les changements finaux pour atteindre 8000 req/s étaient :
- Ne créez pas d'objets puis sérialisez, créez directement une chaîne de JSON ;
- Utilisez quelque chose d'unique dans le contenu pour définir son Etag, plutôt que de créer un hachage ;
- Ne hachez pas l'URL, utilisez-la directement comme clé.
Ces changements sont légèrement plus complexes, un peu plus perturbateurs pour la base de code, et laissent le middleware etagger un peu moins flexible car il met la charge sur la route pour fournir la valeur Etag . Mais il réalise 3000 requêtes supplémentaires par seconde sur la machine de profilage.
Jetons un coup d'œil à un graphique de flamme pour ces dernières améliorations :
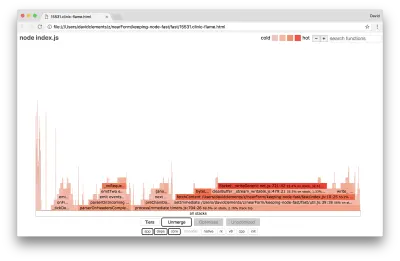
La partie la plus chaude du graphe de flamme fait partie du noyau Node, dans le module net . C'est idéal.
Prévention des problèmes de performances
Pour terminer, voici quelques suggestions sur les moyens de prévenir les problèmes de performances avant leur déploiement.
L'utilisation d'outils de performance comme points de contrôle informels pendant le développement peut filtrer les bogues de performance avant qu'ils ne soient mis en production. Il est recommandé d'intégrer AutoCannon et Clinic (ou leurs équivalents) dans les outils de développement quotidiens.
Lors de l'achat d'un framework, renseignez-vous sur sa politique de performance. Si le cadre ne donne pas la priorité aux performances, il est important de vérifier si cela correspond aux pratiques d'infrastructure et aux objectifs commerciaux. Par exemple, Restify a clairement (depuis la sortie de la version 7) investi dans l'amélioration des performances de la bibliothèque. Cependant, si le faible coût et la haute vitesse sont une priorité absolue, considérez Fastify qui a été mesuré comme 17% plus rapide par un contributeur Restify.
Méfiez-vous des autres choix de bibliothèque qui ont un impact considérable - pensez en particulier à la journalisation. Au fur et à mesure que les développeurs résolvent les problèmes, ils peuvent décider d'ajouter une sortie de journal supplémentaire pour aider à déboguer les problèmes liés à l'avenir. Si un enregistreur non performant est utilisé, cela peut étrangler les performances au fil du temps à la manière de la fable de la grenouille bouillante. L'enregistreur pino est l'enregistreur JSON délimité par une nouvelle ligne le plus rapide disponible pour Node.js.
Enfin, rappelez-vous toujours que la boucle d'événements est une ressource partagée. Un serveur Node.js est finalement contraint par la logique la plus lente dans le chemin le plus chaud.