
Premiers pas avec Node : introduction aux API, HTTP et JavaScript ES6+
Publié: 2022-03-10Vous avez probablement entendu parler de Node.js comme étant un "environnement d'exécution JavaScript asynchrone construit sur le moteur JavaScript V8 de Chrome", et qu'il "utilise un modèle d'E/S non bloquant piloté par les événements qui le rend léger et efficace". Mais pour certains, ce n'est pas la meilleure des explications.
Qu'est-ce que Node en premier lieu ? Qu'est-ce que cela signifie exactement pour Node d'être "asynchrone", et en quoi cela diffère-t-il de "synchrone" ? Quelle est la signification de « événementiel » et « non bloquant » de toute façon, et comment Node s'intègre-t-il dans le tableau plus large des applications, des réseaux Internet et des serveurs ?
Nous tenterons de répondre à toutes ces questions et plus encore tout au long de cette série en examinant en profondeur le fonctionnement interne de Node, en découvrant le protocole de transfert hypertexte, les API et JSON, et en créant notre propre API Bookshelf en utilisant MongoDB, Express, Lodash, Moka et Guidons.
Qu'est-ce que Node.js
Node n'est qu'un environnement, ou runtime, dans lequel exécuter du JavaScript normal (avec des différences mineures) en dehors du navigateur. Nous pouvons l'utiliser pour créer des applications de bureau (avec des frameworks comme Electron), écrire des serveurs Web ou d'applications, etc.
Blocage/non blocage et synchrone/asynchrone
Supposons que nous fassions un appel à la base de données pour récupérer les propriétés d'un utilisateur. Cet appel va prendre du temps, et si la requête est "bloquante", cela signifie qu'elle bloquera l'exécution de notre programme jusqu'à ce que l'appel soit terminé. Dans ce cas, nous avons fait une requête "synchrone" puisqu'elle a fini par bloquer le thread.
Ainsi, une opération synchrone bloque un processus ou un thread jusqu'à ce que cette opération soit terminée, laissant le thread dans un "état d'attente". Une opération asynchrone , en revanche, est non bloquante . Il permet à l'exécution du thread de se poursuivre quel que soit le temps qu'il faut pour que l'opération se termine ou le résultat avec lequel elle se termine, et aucune partie du thread ne tombe dans un état d'attente à aucun moment.
Regardons un autre exemple d'appel synchrone qui bloque un thread. Supposons que nous construisons une application qui compare les résultats de deux API météo pour trouver leur pourcentage de différence de température. De manière bloquante, nous faisons un appel à Weather API One et attendons le résultat. Une fois que nous obtenons un résultat, nous appelons Weather API Two et attendons son résultat. Ne vous inquiétez pas à ce stade si vous n'êtes pas familier avec les API. Nous les couvrirons dans une prochaine section. Pour l'instant, considérez simplement une API comme le moyen par lequel deux ordinateurs peuvent communiquer entre eux.
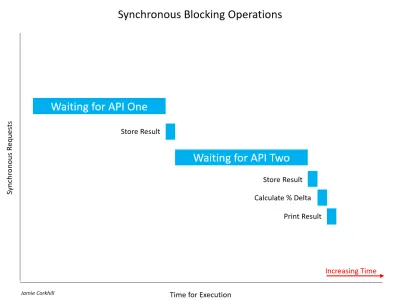
Permettez-moi de noter qu'il est important de reconnaître que tous les appels synchrones ne sont pas nécessairement bloquants. Si une opération synchrone parvient à se terminer sans bloquer le thread ou provoquer un état d'attente, elle est non bloquante. La plupart du temps, les appels synchrones seront bloqués et le temps qu'ils prendront dépendra de divers facteurs, tels que la vitesse des serveurs de l'API, la vitesse de téléchargement de la connexion Internet de l'utilisateur final, etc.
Dans le cas de l'image ci-dessus, nous avons dû attendre pas mal de temps pour récupérer les premiers résultats d'API One. Par la suite, nous avons dû attendre tout aussi longtemps pour obtenir une réponse de l'API Two. En attendant les deux réponses, l'utilisateur remarquerait que notre application se bloque - l'interface utilisateur se verrouillerait littéralement - et ce serait mauvais pour l'expérience utilisateur.
Dans le cas d'un appel non bloquant, nous aurions quelque chose comme ceci :

Vous pouvez clairement voir à quel point nous avons conclu l'exécution plus rapidement. Plutôt que d'attendre l'API 1, puis d'attendre l'API 2, nous pourrions attendre que les deux se terminent en même temps et obtenir nos résultats presque 50 % plus rapidement. Remarquez qu'une fois que nous avons appelé l'API One et que nous avons commencé à attendre sa réponse, nous avons également appelé l'API Two et avons commencé à attendre sa réponse en même temps que One.
À ce stade, avant de passer à des exemples plus concrets et tangibles, il est important de mentionner que, pour plus de facilité, le terme "Synchronous" est généralement abrégé en "Sync", et le terme "Asynchronous" est généralement abrégé en "Async". Vous verrez cette notation utilisée dans les noms de méthode/fonction.
Fonctions de rappel
Vous vous demandez peut-être : « si nous pouvons gérer un appel de manière asynchrone, comment savons-nous quand cet appel est terminé et que nous avons une réponse ? Généralement, nous transmettons comme argument à notre méthode asynchrone une fonction de rappel, et cette méthode "rappellera" cette fonction ultérieurement avec une réponse. J'utilise les fonctions ES5 ici, mais nous mettrons à jour les normes ES6 plus tard.
function asyncAddFunction(a, b, callback) { callback(a + b); //This callback is the one passed in to the function call below. } asyncAddFunction(2, 4, function(sum) { //Here we have the sum, 2 + 4 = 6. }); Une telle fonction est appelée "Fonction d'ordre supérieur" car elle prend une fonction (notre rappel) comme argument. Alternativement, une fonction de rappel peut prendre un objet d'erreur et un objet de réponse comme arguments, et les présenter lorsque la fonction asynchrone est terminée. Nous verrons cela plus tard avec Express. Lorsque nous avons appelé asyncAddFunction(...) , vous remarquerez que nous avons fourni une fonction de rappel pour le paramètre de rappel à partir de la définition de la méthode. Cette fonction est une fonction anonyme (elle n'a pas de nom) et est écrite en utilisant la syntaxe d'expression . La définition de la méthode, en revanche, est une instruction de fonction. Ce n'est pas anonyme car il a en fait un nom (c'est-à-dire "asyncAddFunction").
Certains peuvent noter une confusion puisque, dans la définition de la méthode, nous fournissons un nom, celui-ci étant "callback". Cependant, la fonction anonyme transmise en tant que troisième paramètre à asyncAddFunction(...) ne connaît pas le nom et reste donc anonyme. Nous ne pouvons pas non plus exécuter cette fonction ultérieurement par son nom, nous devrons repasser par la fonction d'appel asynchrone pour la déclencher.
Comme exemple d'appel synchrone, nous pouvons utiliser la méthode Node.js readFileSync(...) . Encore une fois, nous passerons à ES6 + plus tard.
var fs = require('fs'); var data = fs.readFileSync('/example.txt'); // The thread will be blocked here until complete.Si nous faisions cela de manière asynchrone, nous passerions une fonction de rappel qui se déclencherait lorsque l'opération asynchrone serait terminée.
var fs = require('fs'); var data = fs.readFile('/example.txt', function(err, data) { //Move on, this will fire when ready. if(err) return console.log('Error: ', err); console.log('Data: ', data); // Assume var data is defined above. }); // Keep executing below, don't wait on the data. Si vous n'avez jamais vu return utilisé de cette manière auparavant, nous disons simplement d'arrêter l'exécution de la fonction afin de ne pas imprimer l'objet de données si l'objet d'erreur est défini. Nous aurions également pu simplement envelopper l'instruction log dans une clause else .
Comme notre asyncAddFunction(...) , le code derrière la fs.readFile(...) serait quelque chose comme :
function readFile(path, callback) { // Behind the scenes code to read a file stream. // The data variable is defined up here. callback(undefined, data); //Or, callback(err, undefined); }Permettez-nous d'examiner une dernière implémentation d'un appel de fonction asynchrone. Cela aidera à solidifier l'idée que les fonctions de rappel sont déclenchées ultérieurement, et cela nous aidera à comprendre l'exécution d'un programme Node.js typique.
setTimeout(function() { // ... }, 1000); La méthode setTimeout(...) prend une fonction de rappel pour le premier paramètre qui sera déclenchée après que le nombre de millisecondes spécifié comme deuxième argument s'est produit.
Prenons un exemple plus complexe :
console.log('Initiated program.'); setTimeout(function() { console.log('3000 ms (3 sec) have passed.'); }, 3000); setTimeout(function() { console.log('0 ms (0 sec) have passed.'); }, 0); setTimeout(function() { console.log('1000 ms (1 sec) has passed.'); }, 1000); console.log('Terminated program');La sortie que nous recevons est :
Initiated program. Terminated program. 0 ms (0 sec) have passed. 1000 ms (1 sec) has passed. 3000 ms (3 sec) have passed. Vous pouvez voir que la première instruction de journal s'exécute comme prévu. Instantanément, la dernière instruction de journal s'imprime à l'écran, car cela se produit avant que 0 seconde ne soit dépassée après le deuxième setTimeout(...) . Immédiatement après, les deuxième, troisième et première méthodes setTimeout(...) s'exécutent.
Si Node.js n'était pas non bloquant, nous verrions la première instruction de journal, attendrions 3 secondes pour voir la suivante, verrions instantanément la troisième (le 0 seconde setTimeout(...) , puis nous devions attendre une autre seconde pour voir les deux dernières instructions de journal. La nature non bloquante de Node fait que tous les minuteurs commencent à décompter à partir du moment où le programme est exécuté, plutôt que l'ordre dans lequel ils sont saisis. Vous voudrez peut-être examiner les API Node, les Callstack et Event Loop pour plus d'informations sur le fonctionnement de Node sous le capot.
Il est important de noter que ce n'est pas parce que vous voyez une fonction de rappel qu'il y a nécessairement un appel asynchrone dans le code. Nous avons appelé la asyncAddFunction(…) ci-dessus "async" car nous supposons que l'opération prend du temps, comme faire un appel à un serveur. En réalité, le processus d'ajout de deux nombres n'est pas asynchrone, et ce serait donc en fait un exemple d'utilisation d'une fonction de rappel d'une manière qui ne bloque pas réellement le thread.
Promesses sur les rappels
Les rappels peuvent rapidement devenir désordonnés en JavaScript, en particulier les rappels imbriqués multiples. Nous sommes habitués à passer un rappel comme argument à une fonction, mais Promises nous permet de virer ou d'attacher un rappel à un objet renvoyé par une fonction. Cela nous permettrait de gérer plusieurs appels asynchrones de manière plus élégante.
Par exemple, supposons que nous fassions un appel d'API et que notre fonction, qui n'est pas si unique nommée ' makeAPICall(...) ', prend une URL et un rappel.
Notre fonction, makeAPICall(...) , serait définie comme
function makeAPICall(path, callback) { // Attempt to make API call to path argument. // ... callback(undefined, res); // Or, callback(err, undefined); depending upon the API's response. }et nous l'appellerions avec:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); // ... }); Si nous voulions faire un autre appel d'API en utilisant la réponse du premier, nous devions imbriquer les deux rappels. Supposons que je doive injecter la propriété userName de l'objet res1 dans le chemin du deuxième appel d'API. Nous aurions:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); makeAPICall('/newExample/' + res1.userName, function(err2, res2) { if(err2) return console.log('Error: ', err2); console.log(res2); }); }); Remarque : La méthode ES6+ pour injecter la propriété res1.userName plutôt que la concaténation de chaîne serait d'utiliser "Template Strings". De cette façon, plutôt que d'encapsuler notre chaîne entre guillemets ( ' , ou " ), nous utiliserions des backticks ( ` ). situés sous la touche Échap de votre clavier. Ensuite, nous utiliserions la notation ${} pour intégrer toute expression JS à l'intérieur Au final, notre chemin précédent serait : /newExample/${res.UserName} , entouré de backticks.
Il est clair que cette méthode d'imbrication des callbacks peut rapidement devenir assez inélégante, ce qu'on appelle la "JavaScript Pyramid of Doom". En sautant, si nous utilisions des promesses plutôt que des rappels, nous pourrions refactoriser notre code à partir du premier exemple en tant que tel :
makeAPICall('/example').then(function(res) { // Success callback. // ... }, function(err) { // Failure callback. console.log('Error:', err); }); Le premier argument de la fonction then() est notre rappel de succès, et le deuxième argument est notre rappel d'échec. Alternativement, nous pourrions perdre le deuxième argument de .then() et appeler .catch() à la place. Les arguments de .then() sont facultatifs et appeler .catch() serait équivalent à .then(successCallback, null) .
En utilisant .catch() , nous avons :
makeAPICall('/example').then(function(res) { // Success callback. // ... }).catch(function(err) { // Failure Callback console.log('Error: ', err); });Nous pouvons également restructurer cela pour plus de lisibilité :
makeAPICall('/example') .then(function(res) { // ... }) .catch(function(err) { console.log('Error: ', err); }); Il est important de noter que nous ne pouvons pas simplement ajouter un appel .then() à n'importe quelle fonction et nous attendre à ce qu'il fonctionne. La fonction que nous appelons doit en fait renvoyer une promesse, une promesse qui déclenchera le .then() lorsque cette opération asynchrone sera terminée. Dans ce cas, makeAPICall(...) fera son travail, en déclenchant soit le bloc then() soit le bloc catch() une fois terminé.
Pour que makeAPICall(...) renvoie une Promise, nous attribuons une fonction à une variable, où cette fonction est le constructeur Promise. Les promesses peuvent être soit remplies , soit rejetées , où remplie signifie que l'action relative à la promesse s'est déroulée avec succès, et rejetée signifie le contraire. Une fois que la promesse est remplie ou rejetée, nous disons qu'elle a été réglée , et en attendant qu'elle soit réglée, peut-être lors d'un appel asynchrone, nous disons que la promesse est en attente .
Le constructeur Promise prend une fonction de rappel comme argument, qui reçoit deux paramètres - resolve et reject , que nous appellerons ultérieurement pour déclencher soit le rappel de succès dans .then() , soit l'échec de .then() callback, ou .catch() , si fourni.
Voici un exemple de ce à quoi cela ressemble :
var examplePromise = new Promise(function(resolve, reject) { // Do whatever we are going to do and then make the appropiate call below: resolve('Happy!'); // — Everything worked. reject('Sad!'); // — We noticed that something went wrong. }):Ensuite, nous pouvons utiliser :
examplePromise.then(/* Both callback functions in here */); // Or, the success callback in .then() and the failure callback in .catch(). Notez, cependant, que examplePromise ne peut prendre aucun argument. Cela va à l'encontre de l'objectif, nous pouvons donc rendre une promesse à la place.
function makeAPICall(path) { return new Promise(function(resolve, reject) { // Make our async API call here. if (/* All is good */) return resolve(res); //res is the response, would be defined above. else return reject(err); //err is error, would be defined above. }); } Les promesses brillent vraiment pour améliorer la structure, et par la suite, l'élégance, de notre code avec le concept de "Promise Chaining". Cela nous permettrait de renvoyer une nouvelle promesse dans une clause .then() , afin que nous puissions attacher un deuxième .then() par la suite, ce qui déclencherait le rappel approprié à partir de la deuxième promesse.
En refactorisant notre appel d'URL multi API ci-dessus avec Promises, nous obtenons :
makeAPICall('/example').then(function(res) { // First response callback. Fires on success to '/example' call. return makeAPICall(`/newExample/${res.UserName}`); // Returning new call allows for Promise Chaining. }, function(err) { // First failure callback. Fires if there is a failure calling with '/example'. console.log('Error:', err); }).then(function(res) { // Second response callback. Fires on success to returned '/newExample/...' call. console.log(res); }, function(err) { // Second failure callback. Fire if there is a failure calling with '/newExample/...' console.log('Error:', err); }); Notez que nous appelons d'abord makeAPICall('/example') . Cela renvoie une promesse, et nous attachons donc un .then() . À l'intérieur de then() , nous renvoyons un nouvel appel à makeAPICall(...) , qui, en soi, comme vu précédemment, renvoie une promesse, nous permettant de chaîner sur un nouveau .then() après le premier.
Comme ci-dessus, nous pouvons restructurer cela pour plus de lisibilité et supprimer les rappels d'échec pour une clause générique catch() all. Ensuite, nous pouvons suivre le principe DRY (Ne vous répétez pas) et n'avoir à implémenter la gestion des erreurs qu'une seule fois.
makeAPICall('/example') .then(function(res) { // Like earlier, fires with success and response from '/example'. return makeAPICall(`/newExample/${res.UserName}`); // Returning here lets us chain on a new .then(). }) .then(function(res) { // Like earlier, fires with success and response from '/newExample'. console.log(res); }) .catch(function(err) { // Generic catch all method. Fires if there is an err with either earlier call. console.log('Error: ', err); }); Notez que les rappels de succès et d'échec dans .then() ne se déclenchent que pour le statut de la promesse individuelle à laquelle .then() correspond. Le bloc catch , cependant, interceptera toutes les erreurs qui se déclenchent dans l'un des .then() s.
ES6 Const contre Let
Dans tous nos exemples, nous avons utilisé les fonctions ES5 et l'ancien mot-clé var . Alors que des millions de lignes de code s'exécutent encore aujourd'hui en utilisant ces méthodes ES5, il est utile de mettre à jour les normes ES6 + actuelles, et nous refactoriserons une partie de notre code ci-dessus. Commençons par const et let .
Vous avez peut-être l'habitude de déclarer une variable avec le mot-clé var :
var pi = 3.14;Avec les normes ES6 +, nous pourrions faire cela soit
let pi = 3.14;ou
const pi = 3.14; où const signifie "constante" - une valeur qui ne peut pas être réaffectée ultérieurement. (Sauf pour les propriétés d'objet - nous en parlerons bientôt. De plus, les variables déclarées const ne sont pas immuables, seule la référence à la variable l'est.)
Dans l'ancien JavaScript, bloquez les étendues, telles que celles de if , while , {} . for , etc. n'a aucunement affecté var , ce qui est assez différent des langages typés plus statiquement comme Java ou C++. Autrement dit, la portée de var est l'ensemble de la fonction englobante - et cela peut être global (si placé en dehors d'une fonction) ou local (si placé dans une fonction). Pour illustrer cela, consultez l'exemple suivant :
function myFunction() { var num = 5; console.log(num); // 5 console.log('--'); for(var i = 0; i < 10; i++) { var num = i; console.log(num); //num becomes 0 — 9 } console.log('--'); console.log(num); // 9 console.log(i); // 10 } myFunction();Sortir:
5 --- 0 1 2 3 ... 7 8 9 --- 9 10 La chose importante à noter ici est que la définition d'un nouveau var num à l'intérieur de la portée for affecte directement le var num à l'extérieur et au-dessus du for . En effet, la portée de var est toujours celle de la fonction englobante, et non celle d'un bloc.
Encore une fois, par défaut, var i à l'intérieur for() utilise par défaut la portée de myFunction , et nous pouvons donc accéder à i en dehors de la boucle et obtenir 10.
En termes d'attribution de valeurs aux variables, let est équivalent à var , c'est juste que let a une portée de bloc, et donc les anomalies qui se sont produites avec var ci-dessus ne se produiront pas.
function myFunction() { let num = 5; console.log(num); // 5 for(let i = 0; i < 10; i++) { let num = i; console.log('--'); console.log(num); // num becomes 0 — 9 } console.log('--'); console.log(num); // 5 console.log(i); // undefined, ReferenceError } En regardant le mot-clé const , vous pouvez voir que nous obtenons une erreur si nous essayons de lui réaffecter :
const c = 299792458; // Fact: The constant "c" is the speed of light in a vacuum in meters per second. c = 10; // TypeError: Assignment to constant variable. Les choses deviennent intéressantes quand on assigne une variable const à un objet :
const myObject = { name: 'Jane Doe' }; // This is illegal: TypeError: Assignment to constant variable. myObject = { name: 'John Doe' }; // This is legal. console.log(myObject.name) -> John Doe myObject.name = 'John Doe'; Comme vous pouvez le voir, seule la référence en mémoire à l'objet assigné à un objet const est immuable, pas la valeur elle-même.
Fonctions fléchées ES6
Vous avez peut-être l'habitude de créer une fonction comme celle-ci :
function printHelloWorld() { console.log('Hello, World!'); }Avec les fonctions fléchées, cela deviendrait :
const printHelloWorld = () => { console.log('Hello, World!'); };Supposons que nous ayons une fonction simple qui renvoie le carré d'un nombre :
const squareNumber = (x) => { return x * x; } squareNumber(5); // We can call an arrow function like an ES5 functions. Returns 25.Vous pouvez voir que, tout comme avec les fonctions ES5, nous pouvons prendre des arguments avec des parenthèses, nous pouvons utiliser des instructions de retour normales et nous pouvons appeler la fonction comme n'importe quelle autre.
Il est important de noter que, bien que les parenthèses soient nécessaires si notre fonction ne prend aucun argument (comme avec printHelloWorld() ci-dessus), nous pouvons supprimer les parenthèses si elle n'en prend qu'une, de sorte que notre précédente définition de méthode squareNumber() peut être réécrite comme suit :
const squareNumber = x => { // Notice we have dropped the parentheses for we only take in one argument. return x * x; }Que vous choisissiez d'encapsuler un seul argument entre parenthèses ou non est une question de goût personnel, et vous verrez probablement les développeurs utiliser les deux méthodes.
Enfin, si nous ne voulons renvoyer implicitement qu'une seule expression, comme avec squareNumber(...) ci-dessus, nous pouvons mettre l'instruction return en ligne avec la signature de la méthode :
const squareNumber = x => x * x;C'est-à-dire,
const test = (a, b, c) => expressionest le même que
const test = (a, b, c) => { return expression }Notez que lorsque vous utilisez le raccourci ci-dessus pour renvoyer implicitement un objet, les choses deviennent obscures. Qu'est-ce qui empêche JavaScript de croire que les crochets dans lesquels nous devons encapsuler notre objet ne sont pas notre corps de fonction ? Pour contourner ce problème, nous enveloppons les crochets de l'objet entre parenthèses. Cela permet explicitement à JavaScript de savoir que nous renvoyons effectivement un objet, et que nous ne définissons pas simplement un corps.
const test = () => ({ pi: 3.14 }); // Spaces between brackets are a formality to make the code look cleaner.Pour aider à solidifier le concept des fonctions ES6, nous allons refactoriser une partie de notre code précédent nous permettant de comparer les différences entre les deux notations.
asyncAddFunction(...) , d'en haut, pourrait être refactorisé à partir de :
function asyncAddFunction(a, b, callback){ callback(a + b); }pour:
const aysncAddFunction = (a, b, callback) => { callback(a + b); };ou même à :
const aysncAddFunction = (a, b, callback) => callback(a + b); // This will return callback(a + b).Lors de l'appel de la fonction, nous pourrions passer une fonction fléchée pour le rappel :
asyncAddFunction(10, 12, sum => { // No parentheses because we only take one argument. console.log(sum); }Il est clair de voir comment cette méthode améliore la lisibilité du code. Pour vous montrer un seul cas, nous pouvons prendre notre ancien exemple basé sur la promesse ES5 ci-dessus et le refactoriser pour utiliser les fonctions fléchées.
makeAPICall('/example') .then(res => makeAPICall(`/newExample/${res.UserName}`)) .then(res => console.log(res)) .catch(err => console.log('Error: ', err)); Maintenant, il y a quelques mises en garde avec les fonctions fléchées. D'une part, ils ne lient pas this mot-clé. Supposons que j'ai l'objet suivant :
const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Vous pouvez vous attendre à ce qu'un appel à Person.greeting() renvoie "Salut. Je m'appelle John Doe. Au lieu de cela, nous obtenons : « Salut. Mon nom n'est pas défini. En effet, les fonctions fléchées n'ont pas de this , et donc tenter d'utiliser this à l'intérieur d'une fonction fléchée prend par défaut le this de la portée englobante, et la portée englobante de l'objet Person est window , dans le navigateur ou module.exports dans Nœud.
Pour prouver cela, si nous utilisons à nouveau le même objet, mais que nous définissons la propriété name du global this sur quelque chose comme 'Jane Doe', alors this.name dans la fonction de flèche renvoie 'Jane Doe', car le global this est dans le portée englobante ou est le parent de l'objet Person .
this.name = 'Jane Doe'; const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting(); // Hi. My name is Jane DoeC'est ce qu'on appelle la « portée lexicale », et nous pouvons la contourner en utilisant la soi-disant « syntaxe courte », dans laquelle nous perdons les deux-points et la flèche pour refactoriser notre objet en tant que tel :
const Person = { name: 'John Doe', greeting() { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting() //Hi. My name is John Doe.Cours ES6
Bien que JavaScript n'ait jamais pris en charge les classes, vous pouvez toujours les émuler avec des objets comme ci-dessus. EcmaScript 6 prend en charge les classes utilisant les mots-clés class et new :
class Person { constructor(name) { this.name = name; } greeting() { console.log(`Hi. My name is ${this.name}.`); } } const person = new Person('John'); person.greeting(); // Hi. My name is John. La fonction constructeur est appelée automatiquement lors de l'utilisation du new mot-clé, dans lequel nous pouvons passer des arguments pour configurer initialement l'objet. Cela devrait être familier à tout lecteur qui a de l'expérience avec des langages de programmation orientés objet plus typés statiquement comme Java, C++ et C#.
Sans entrer dans trop de détails sur les concepts de la POO, un autre paradigme de ce type est «l'héritage», qui consiste à permettre à une classe d'hériter d'une autre. Une classe appelée Car , par exemple, sera très générale - contenant des méthodes telles que "stop", "start", etc., comme toutes les voitures en ont besoin. Un sous-ensemble de la classe appelé SportsCar pourrait alors hériter des opérations fondamentales de Car et remplacer tout ce dont il a besoin. On pourrait désigner une telle classe comme suit :
class Car { constructor(licensePlateNumber) { this.licensePlateNumber = licensePlateNumber; } start() {} stop() {} getLicensePlate() { return this.licensePlateNumber; } // … } class SportsCar extends Car { constructor(engineRevCount, licensePlateNumber) { super(licensePlateNumber); // Pass licensePlateNumber up to the parent class. this.engineRevCount = engineRevCount; } start() { super.start(); } stop() { super.stop(); } getLicensePlate() { return super.getLicensePlate(); } getEngineRevCount() { return this.engineRevCount; } } Vous pouvez clairement voir que le mot-clé super nous permet d'accéder aux propriétés et aux méthodes de la classe parente ou super.
Événements JavaScript
Un événement est une action qui se produit à laquelle vous avez la possibilité de réagir. Supposons que vous construisiez un formulaire de connexion pour votre application. Lorsque l'utilisateur appuie sur le bouton "soumettre", vous pouvez réagir à cet événement via un "gestionnaire d'événements" dans votre code - généralement une fonction. Lorsque cette fonction est définie comme gestionnaire d'événements, nous disons que nous "enregistrons un gestionnaire d'événements". Le gestionnaire d'événements pour le clic sur le bouton d'envoi vérifiera probablement la mise en forme de l'entrée fournie par l'utilisateur, la purifiera pour empêcher des attaques telles que les injections SQL ou les scripts intersites (veuillez noter qu'aucun code côté client ne peut jamais être considéré Nettoyez toujours les données sur le serveur - ne faites jamais confiance à quoi que ce soit du navigateur), puis vérifiez si cette combinaison de nom d'utilisateur et de mot de passe existe dans une base de données pour authentifier un utilisateur et lui fournir un jeton.
Puisqu'il s'agit d'un article sur Node, nous nous concentrerons sur le modèle d'événement Node.
Nous pouvons utiliser le module d' events de Node pour émettre et réagir à des événements spécifiques. Tout objet qui émet un événement est une instance de la classe EventEmitter .
Nous pouvons émettre un événement en appelant la méthode emit() et nous écoutons cet événement via la méthode on() , qui sont toutes deux exposées via la classe EventEmitter .
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); Avec myEmitter maintenant une instance de la classe EventEmitter , nous pouvons accéder à emission emit() et on() :
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', () => { console.log('The "someEvent" event was fired (emitted)'); }); myEmitter.emit('someEvent'); // This will call the callback function above. Le deuxième paramètre de myEmitter.on() est la fonction de rappel qui se déclenchera lorsque l'événement est émis - c'est le gestionnaire d'événements. Le premier paramètre est le nom de l'événement, qui peut être n'importe quoi, bien que la convention de dénomination camelCase soit recommandée.
De plus, le gestionnaire d'événements peut prendre n'importe quel nombre d'arguments, qui sont transmis lorsque l'événement est émis :
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', (data) => { console.log(`The "someEvent" event was fired (emitted) with data: ${data}`); }); myEmitter.emit('someEvent', 'This is the data payload'); En utilisant l'héritage, nous pouvons exposer les méthodes emission emit() et on() de 'EventEmitter' à n'importe quelle classe. Cela se fait en créant une classe Node.js et en utilisant le mot-clé extends réservé pour hériter des propriétés disponibles sur EventEmitter :
const EventEmitter = require('events'); class MyEmitter extends EventEmitter { // This is my class. I can emit events from a MyEmitter object. } Supposons que nous construisons un programme de notification de collision de véhicule qui reçoit des données de gyroscopes, d'accéléromètres et de manomètres sur la coque de la voiture. Lorsqu'un véhicule entre en collision avec un objet, ces capteurs externes détectent l'accident, exécutent la fonction collide(...) et lui transmettent les données agrégées du capteur sous la forme d'un bel objet JavaScript. Cette fonction émettra un événement de collision , informant le vendeur du crash.

const EventEmitter = require('events'); class Vehicle extends EventEmitter { collide(collisionStatistics) { this.emit('collision', collisionStatistics) } } const myVehicle = new Vehicle(); myVehicle.on('collision', collisionStatistics => { console.log('WARNING! Vehicle Impact Detected: ', collisionStatistics); notifyVendor(collisionStatistics); }); myVehicle.collide({ ... }); Il s'agit d'un exemple compliqué car nous pourrions simplement placer le code dans le gestionnaire d'événements à l'intérieur de la fonction collide de la classe, mais il montre néanmoins comment le modèle d'événement de nœud fonctionne. Notez que certains tutoriels montreront la méthode util.inherits() permettant à un objet d'émettre des événements. Cela a été déprécié en faveur des classes ES6 et extends .
Le gestionnaire de paquets de nœuds
Lors de la programmation avec Node et JavaScript, il sera assez courant d'entendre parler de npm . Npm est un gestionnaire de packages qui fait exactement cela - permet le téléchargement de packages tiers qui résolvent les problèmes courants en JavaScript. D'autres solutions, telles que Yarn, Npx, Grunt et Bower existent également, mais dans cette section, nous nous concentrerons uniquement sur npm et comment vous pouvez installer des dépendances pour votre application via une simple interface de ligne de commande (CLI) en l'utilisant.
Commençons simplement, avec juste npm . Visitez la page d'accueil de NpmJS pour afficher tous les packages disponibles auprès de NPM. Lorsque vous démarrez un nouveau projet qui dépendra des packages NPM, vous devrez exécuter npm init via le terminal dans le répertoire racine de votre projet. On vous posera une série de questions qui seront utilisées pour créer un fichier package.json . Ce fichier stocke toutes vos dépendances - modules dont votre application dépend pour fonctionner, scripts - commandes de terminal prédéfinies pour exécuter des tests, construire le projet, démarrer le serveur de développement, etc., et plus encore.
Pour installer un package, exécutez simplement npm install [package-name] --save . L'indicateur de save garantira que le package et sa version sont enregistrés dans le fichier package.json . Depuis la version 5 de npm , les dépendances sont enregistrées par défaut, donc --save peut être omis. Vous remarquerez également un nouveau dossier node_modules , contenant le code de ce package que vous venez d'installer. Cela peut également être raccourci à npm i [package-name] . À titre de remarque utile, le dossier node_modules ne doit jamais être inclus dans un référentiel GitHub en raison de sa taille. Chaque fois que vous clonez un référentiel à partir de GitHub (ou de tout autre système de gestion de version), assurez-vous d'exécuter la commande npm install pour sortir et récupérer tous les packages définis dans le fichier package.json , en créant automatiquement le répertoire node_modules . Vous pouvez également installer un package à une version spécifique : npm i [package-name]@1.10.1 --save , par exemple.
La suppression d'un package est similaire à son installation : npm remove [package-name] .
Vous pouvez également installer un package globalement. Ce package sera disponible pour tous les projets, pas seulement celui sur lequel vous travaillez. Pour ce faire, utilisez le drapeau -g après npm i [package-name] . Ceci est couramment utilisé pour les CLI, telles que Google Firebase et Heroku. Malgré la facilité de cette méthode, il est généralement considéré comme une mauvaise pratique d'installer les packages globalement, car ils ne sont pas enregistrés dans le fichier package.json , et si un autre développeur tente d'utiliser votre projet, il n'atteindra pas toutes les dépendances requises à partir de npm install .
API et JSON
Les API sont un paradigme très courant dans la programmation, et même si vous débutez dans votre carrière de développeur, les API et leur utilisation, en particulier dans le développement Web et mobile, reviendront probablement plus souvent qu'autrement.
Une API est une interface de programmation d'application , et c'est essentiellement une méthode par laquelle deux systèmes découplés peuvent communiquer entre eux. En termes plus techniques, une API permet à un système ou à un programme informatique (généralement un serveur) de recevoir des requêtes et d'envoyer des réponses appropriées (à un client, également appelé hôte).
Supposons que vous construisez une application météo. Vous avez besoin d'un moyen de géocoder l'adresse d'un utilisateur en latitude et longitude, puis d'un moyen d'obtenir la météo actuelle ou prévue à cet endroit particulier.
As a developer, you want to focus on building your app and monetizing it, not putting the infrastructure in place to geocode addresses or placing weather stations in every city.
Luckily for you, companies like Google and OpenWeatherMap have already put that infrastructure in place, you just need a way to talk to it — that is where the API comes in. While, as of now, we have developed a very abstract and ambiguous definition of the API, bear with me. We'll be getting to tangible examples soon.
Now, it costs money for companies to develop, maintain, and secure that aforementioned infrastructure, and so it is common for corporations to sell you access to their API. This is done with that is known as an API key, a unique alphanumeric identifier associating you, the developer, with the API. Every time you ask the API to send you data, you pass along your API key. The server can then authenticate you and keep track of how many API calls you are making, and you will be charged appropriately. The API key also permits Rate-Limiting or API Call Throttling (a method of throttling the number of API calls in a certain timeframe as to not overwhelm the server, preventing DOS attacks — Denial of Service). Most companies, however, will provide a free quota, giving you, as an example, 25,000 free API calls a day before charging you.
Up to this point, we have established that an API is a method by which two computer programs can communicate with each other. If a server is storing data, such as a website, and your browser makes a request to download the code for that site, that was the API in action.
Let us look at a more tangible example, and then we'll look at a more real-world, technical one. Suppose you are eating out at a restaurant for dinner. You are equivalent to the client, sitting at the table, and the chef in the back is equivalent to the server.
Since you will never directly talk to the chef, there is no way for him/her to receive your request (for what order you would like to make) or for him/her to provide you with your meal once you order it. We need someone in the middle. In this case, it's the waiter, analogous to the API. The API provides a medium with which you (the client) may talk to the server (the chef), as well as a set of rules for how that communication should be made (the menu — one meal is allowed two sides, etc.)
Now, how do you actually talk to the API (the waiter)? You might speak English, but the chef might speak Spanish. Is the waiter expected to know both languages to translate? What if a third person comes in who only speaks Mandarin? What then? Well, all clients and servers have to agree to speak a common language, and in computer programming, that language is JSON, pronounced JAY-sun, and it stands for JavaScript Object Notation.
At this point, we don't quite know what JSON looks like. It's not a computer programming language, it's just, well, a language, like English or Spanish, that everyone (everyone being computers) understands on a guaranteed basis. It's guaranteed because it's a standard, notably RFC 8259 , the JavaScript Object Notation (JSON) Data Interchange Format by the Internet Engineering Task Force (IETF).
Even without formal knowledge of what JSON actually is and what it looks like (we'll see in an upcoming article in this series), we can go ahead introduce a technical example operating on the Internet today that employs APIs and JSON. APIs and JSON are not just something you can choose to use, it's not equivalent to one out of a thousand JavaScript frameworks you can pick to do the same thing. It is THE standard for data exchange on the web.
Suppose you are building a travel website that compares prices for aircraft, rental car, and hotel ticket prices. Let us walk through, step-by-step, on a high level, how we would build such an application. Of course, we need our User Interface, the front-end, but that is out of scope for this article.
We want to provide our users with the lowest price booking method. Well, that means we need to somehow attain all possible booking prices, and then compare all of the elements in that set (perhaps we store them in an array) to find the smallest element (known as the infimum in mathematics.)
How will we get this data? Well, suppose all of the booking sites have a database full of prices. Those sites will provide an API, which exposes the data in those databases for use by you. You will call each API for each site to attain all possible booking prices, store them in your own array, find the lowest or minimum element of that array, and then provide the price and booking link to your user. We'll ask the API to query its database for the price in JSON, and it will respond with said price in JSON to us. We can then use, or parse, that accordingly. We have to parse it because APIs will return JSON as a string, not the actual JavaScript data type of JSON. This might not make sense now, and that's okay. We'll be covering it more in a future article.
Also, note that just because something is called an API does not necessarily mean it operates on the web and sends and receives JSON. The Java API, for example, is just the list of classes, packages, and interfaces that are part of the Java Development Kit (JDK), providing programming functionality to the programmer.
D'accord. We know we can talk to a program running on a server by way of an Application Programming Interface, and we know that the common language with which we do this is known as JSON. But in the web development and networking world, everything has a protocol. What do we actually do to make an API call, and what does that look like code-wise? That's where HTTP Requests enter the picture, the HyperText Transfer Protocol, defining how messages are formatted and transmitted across the Internet. Once we have an understanding of HTTP (and HTTP verbs, you'll see that in the next section), we can look into actual JavaScript frameworks and methods (like fetch() ) offered by the JavaScript API (similar to the Java API), that actually allow us to make API calls.
HTTP And HTTP Requests
HTTP is the HyperText Transfer Protocol. It is the underlying protocol that determines how messages are formatted as they are transmitted and received across the web. Let's think about what happens when, for example, you attempt to load the home page of Smashing Magazine in your web browser.
You type the website URL (Uniform Resource Locator) in the URL bar, where the DNS server (Domain Name Server, out of scope for this article) resolves the URL into the appropriate IP Address. The browser makes a request, called a GET Request, to the Web Server to, well, GET the underlying HTML behind the site. The Web Server will respond with a message such as “OK”, and then will go ahead and send the HTML down to the browser where it will be parsed and rendered accordingly.
There are a few things to note here. First, the GET Request, and then the “OK” response. Suppose you have a specific database, and you want to write an API to expose that database to your users. Suppose the database contains books the user wants to read (as it will in a future article in this series). Then there are four fundamental operations your user may want to perform on this database, that is, Create a record, Read a record, Update a record, or Delete a record, known collectively as CRUD operations.
Let's look at the Read operation for a moment. Without incorrectly assimilating or conflating the notion of a web server and a database, that Read operation is very similar to your web browser attempting to get the site from the server, just as to read a record is to get the record from the database.
C'est ce qu'on appelle une requête HTTP. Vous faites une demande à un serveur quelque part pour obtenir des données, et, en tant que telle, la demande est nommée de manière appropriée "GET", la capitalisation étant un moyen standard de désigner de telles demandes.
Qu'en est-il de la partie Créer de CRUD ? Eh bien, quand on parle de requêtes HTTP, c'est ce qu'on appelle une requête POST. Tout comme vous pouvez publier un message sur une plate-forme de médias sociaux, vous pouvez également publier un nouvel enregistrement dans une base de données.
La mise à jour de CRUD nous permet d'utiliser une requête PUT ou PATCH afin de mettre à jour une ressource. Le PUT de HTTP créera un nouvel enregistrement ou mettra à jour/remplacera l'ancien.
Regardons cela un peu plus en détail, puis nous arriverons à PATCH.
Une API fonctionne généralement en effectuant des requêtes HTTP vers des itinéraires spécifiques dans une URL. Supposons que nous créons une API pour parler à une base de données contenant la liste de livres d'un utilisateur. Ensuite, nous pourrons peut-être afficher ces livres à l'URL .../books . Une demande POST à .../books créera un nouveau livre avec les propriétés que vous définissez (pensez à l'identifiant, au titre, à l'ISBN, à l'auteur, aux données de publication, etc.) sur la route .../books . Peu importe la structure de données sous-jacente qui stocke tous les livres dans .../books en ce moment. Nous nous soucions juste que l'API expose ce point de terminaison (accessible via la route) pour manipuler les données. La phrase précédente était la clé : une requête POST crée un nouveau livre sur la route ...books/ . La différence entre PUT et POST est donc que PUT créera un nouveau livre (comme avec POST) si un tel livre n'existe pas, ou remplacera un livre existant si le livre existe déjà dans la structure de données susmentionnée.
Supposons que chaque livre ait les propriétés suivantes : id, title, ISBN, author, hasRead (booléen).
Ensuite, pour ajouter un nouveau livre, comme vu précédemment, nous ferions une requête POST à .../books . Si nous voulions complètement mettre à jour ou remplacer un livre, nous ferions une requête PUT à .../books/id où id est l'ID du livre que nous voulons remplacer.
Alors que PUT remplace complètement un livre existant, PATCH met à jour quelque chose ayant à voir avec un livre spécifique, peut-être en modifiant la propriété booléenne hasRead que nous avons définie ci-dessus — nous ferions donc une requête PATCH à …/books/id en envoyant les nouvelles données.
Il peut être difficile de voir la signification de cela pour le moment, car jusqu'à présent, nous avons tout établi en théorie, mais nous n'avons vu aucun code tangible qui fait réellement une requête HTTP. Nous y reviendrons cependant bientôt, en couvrant GET dans cet article, et le reste dans un prochain article.
Il y a une dernière opération CRUD fondamentale et elle s'appelle Supprimer. Comme vous vous en doutez, le nom d'une telle requête HTTP est "DELETE", et cela fonctionne à peu près de la même manière que PATCH, nécessitant que l'ID du livre soit fourni dans une route.
Nous avons donc appris jusqu'à présent que les routes sont des URL spécifiques auxquelles vous faites une requête HTTP, et que les points de terminaison sont des fonctions que l'API fournit, faisant quelque chose aux données qu'elle expose. Autrement dit, le point de terminaison est une fonction de langage de programmation située à l'autre extrémité de la route, et il exécute la requête HTTP que vous avez spécifiée. Nous avons également appris qu'il existe des termes tels que POST, GET, PUT, PATCH, DELETE, etc. (connus sous le nom de verbes HTTP) qui spécifient en fait les requêtes que vous adressez à l'API. Comme JSON, ces méthodes de requête HTTP sont des normes Internet telles que définies par l'Internet Engineering Task Force (IETF), notamment RFC 7231, section quatre : méthodes de requête, et RFC 5789, section deux : méthode de correctif, où RFC est un acronyme pour Demande pour des commentaires.
Ainsi, nous pourrions faire une requête GET à l'URL .../books/id où l'ID transmis est connu comme un paramètre. Nous pourrions faire une requête POST, PUT ou PATCH à .../books pour créer une ressource ou à .../books/id pour modifier/remplacer/mettre à jour une ressource. Et nous pouvons également faire une requête DELETE à .../books/id pour supprimer un livre spécifique.
Une liste complète des méthodes de requête HTTP peut être trouvée ici.
Il est également important de noter qu'après avoir effectué une requête HTTP, nous recevrons une réponse. La réponse spécifique est déterminée par la manière dont nous construisons l'API, mais vous devriez toujours recevoir un code d'état. Plus tôt, nous avons dit que lorsque votre navigateur Web demande le code HTML au serveur Web, il répond par "OK". C'est ce qu'on appelle un code d'état HTTP, plus précisément HTTP 200 OK. Le code d'état spécifie simplement comment l'opération ou l'action spécifiée dans le point de terminaison (rappelez-vous, c'est notre fonction qui fait tout le travail) s'est terminée. Les codes d'état HTTP sont renvoyés par le serveur, et il y en a probablement beaucoup que vous connaissez, comme 404 Not Found (la ressource ou le fichier n'a pas pu être trouvé, ce serait comme faire une requête GET à .../books/id là où aucun ID de ce type n'existe.)
Une liste complète des codes d'état HTTP peut être trouvée ici.
MongoDB
MongoDB est une base de données NoSQL non relationnelle similaire à la base de données en temps réel Firebase. Vous parlerez à la base de données via un package Node tel que le pilote natif MongoDB ou Mongoose.
Dans MongoDB, les données sont stockées dans JSON, ce qui est assez différent des bases de données relationnelles telles que MySQL, PostgreSQL ou SQLite. Les deux sont appelées bases de données, avec des tables SQL appelées collections, des lignes de table SQL appelées documents et des colonnes de table SQL appelées champs.
Nous utiliserons la base de données MongoDB dans un prochain article de cette série lorsque nous créerons notre toute première API Bookshelf. Les opérations CRUD fondamentales répertoriées ci-dessus peuvent être effectuées sur une base de données MongoDB.
Il est recommandé de lire la documentation MongoDB pour savoir comment créer une base de données en direct sur un cluster Atlas et y effectuer des opérations CRUD avec le pilote natif MongoDB. Dans le prochain article de cette série, nous apprendrons comment mettre en place une base de données locale et une base de données de production cloud.
Création d'une application de nœud de ligne de commande
Lors de la création d'une application, vous verrez de nombreux auteurs vider l'intégralité de leur base de code au début de l'article, puis tenter d'expliquer chaque ligne par la suite. Dans ce texte, je vais adopter une approche différente. J'expliquerai mon code ligne par ligne, en construisant l'application au fur et à mesure. Je ne m'inquiéterai pas de la modularité ou des performances, je ne diviserai pas la base de code en fichiers séparés, et je ne suivrai pas le principe DRY ni ne tenterai de rendre le code réutilisable. Lors de l'apprentissage, il est utile de rendre les choses aussi simples que possible, et c'est donc l'approche que je vais adopter ici.
Soyons clairs sur ce que nous construisons. Nous ne nous préoccuperons pas des entrées de l'utilisateur, et nous n'utiliserons donc pas de packages comme Yargs. Nous ne construirons pas non plus notre propre API. Cela viendra dans un article ultérieur de cette série lorsque nous utiliserons Express Web Application Framework. J'adopte cette approche pour ne pas confondre Node.js avec la puissance d'Express et des API, comme le font la plupart des tutoriels. Au lieu de cela, je fournirai une méthode (parmi plusieurs) permettant d'appeler et de recevoir des données d'une API externe qui utilise une bibliothèque JavaScript tierce. L'API que nous appellerons est une API météo, à laquelle nous accéderons depuis Node et déverserons sa sortie sur le terminal, peut-être avec un certain formatage, connu sous le nom de "pretty-printing". Je couvrirai l'ensemble du processus, y compris la configuration de l'API et l'obtention de la clé API, dont les étapes fournissent les résultats corrects à partir de janvier 2019.
Nous utiliserons l'API OpenWeatherMap pour ce projet, donc pour commencer, accédez à la page d'inscription OpenWeatherMap et créez un compte avec le formulaire. Une fois connecté, recherchez l'élément de menu API Keys sur la page du tableau de bord (situé ici). Si vous venez de créer un compte, vous devrez choisir un nom pour votre clé API et cliquer sur "Générer". Cela peut prendre au moins 2 heures pour que votre nouvelle clé API soit fonctionnelle et associée à votre compte.
Avant de commencer à développer l'application, nous visiterons la documentation de l'API pour savoir comment formater notre clé API. Dans ce projet, nous spécifierons un code postal et un code de pays pour obtenir les informations météorologiques à cet endroit.
À partir de la documentation, nous pouvons voir que la méthode par laquelle nous procédons consiste à fournir l'URL suivante :
api.openweathermap.org/data/2.5/weather?zip={zip code},{country code}Dans lequel nous pourrions entrer des données :
api.openweathermap.org/data/2.5/weather?zip=94040,usMaintenant, avant de pouvoir réellement obtenir des données pertinentes à partir de cette API, nous devrons fournir notre nouvelle clé API en tant que paramètre de requête :
api.openweathermap.org/data/2.5/weather?zip=94040,us&appid={YOUR_API_KEY} Pour l'instant, copiez cette URL dans un nouvel onglet de votre navigateur Web, en remplaçant l'espace réservé {YOUR_API_KEY} par la clé API que vous avez obtenue précédemment lorsque vous vous êtes inscrit pour un compte.
Le texte que vous pouvez voir est en fait JSON - la langue convenue du Web, comme indiqué précédemment.
Pour inspecter cela plus en détail, appuyez sur Ctrl + Maj + I dans Google Chrome pour ouvrir les outils de développement Chrome, puis accédez à l'onglet Réseau. À l'heure actuelle, il ne devrait pas y avoir de données ici.
Pour surveiller réellement les données du réseau, rechargez la page et regardez l'onglet se remplir d'informations utiles. Cliquez sur le premier lien comme illustré dans l'image ci-dessous.
Une fois que vous avez cliqué sur ce lien, nous pouvons réellement afficher des informations spécifiques à HTTP, telles que les en-têtes. Les en-têtes sont envoyés dans la réponse de l'API (vous pouvez également, dans certains cas, envoyer vos propres en-têtes à l'API, ou vous pouvez même créer vos propres en-têtes personnalisés (souvent préfixés par x- ) à renvoyer lors de la construction de votre propre API ), et contiennent uniquement des informations supplémentaires dont le client ou le serveur peut avoir besoin.
Dans ce cas, vous pouvez voir que nous avons envoyé une requête HTTP GET à l'API et qu'elle a répondu avec un statut HTTP 200 OK. Vous pouvez également voir que les données renvoyées étaient au format JSON, comme indiqué dans la section "En-têtes de réponse".
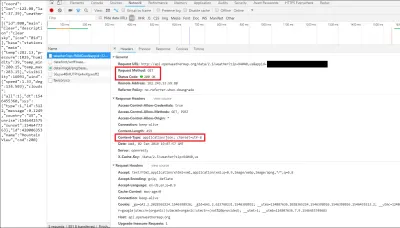
Si vous appuyez sur l'onglet d'aperçu, vous pouvez réellement afficher le JSON en tant qu'objet JavaScript. La version texte que vous pouvez voir dans votre navigateur est une chaîne, car JSON est toujours transmis et reçu sur le Web sous forme de chaîne. C'est pourquoi nous devons analyser le JSON dans notre code, pour le mettre dans un format plus lisible - dans ce cas (et dans presque tous les cas) - un objet JavaScript.
Vous pouvez également utiliser l'extension Google Chrome "JSON View" pour le faire automatiquement.
Pour commencer à développer notre application, je vais ouvrir un terminal et créer un nouveau répertoire racine, puis y cd . Une fois à l'intérieur, je vais créer un nouveau fichier app.js , exécuter npm init pour générer un fichier package.json avec les paramètres par défaut, puis ouvrir Visual Studio Code.
mkdir command-line-weather-app && cd command-line-weather-app touch app.js npm init code . Ensuite, je vais télécharger Axios, vérifier qu'il a été ajouté à mon fichier package.json et noter que le dossier node_modules a été créé avec succès.
Dans le navigateur, vous pouvez voir que nous avons fait une demande GET à la main en tapant manuellement l'URL appropriée dans la barre d'URL. Axios est ce qui me permettra de faire cela à l'intérieur de Node.
À partir de maintenant, tout le code suivant sera situé à l'intérieur du fichier app.js , chaque extrait placé l'un après l'autre.
La première chose que je vais faire est d'exiger le package Axios que nous avons installé précédemment avec
const axios = require('axios'); Nous avons maintenant accès à Axios, et pouvons faire des requêtes HTTP pertinentes, via la constante axios .
Généralement, nos appels API seront dynamiques - dans ce cas, nous pourrions vouloir injecter différents codes postaux et codes de pays dans notre URL. Je vais donc créer des variables constantes pour chaque partie de l'URL, puis les assembler avec les chaînes de modèle ES6. Premièrement, nous avons la partie de notre URL qui ne changera jamais ainsi que notre clé API :
const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; Je vais également attribuer notre code postal et le code du pays. Étant donné que nous n'attendons pas d'entrée de l'utilisateur et que nous codons plutôt les données en dur, je vais également les rendre constantes, bien que, dans de nombreux cas, il sera plus utile d'utiliser let .
const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us';Nous devons maintenant rassembler ces variables dans une URL à laquelle nous pouvons utiliser Axios pour faire des requêtes GET à :
const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Voici le contenu de notre fichier app.js jusqu'à présent :
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Il ne reste plus qu'à utiliser axios pour envoyer une requête GET à cette URL. Pour cela, nous utiliserons la méthode get(url) fournie par axios .
axios.get(ENTIRE_API_URL) axios.get(...) renvoie en fait une promesse, et la fonction de rappel de succès prendra un argument de réponse qui nous permettra d'accéder à la réponse de l'API - la même chose que vous avez vue dans le navigateur. J'ajouterai également une clause .catch() pour intercepter les erreurs.
axios.get(ENTIRE_API_URL) .then(response => console.log(response)) .catch(error => console.log('Error', error)); Si nous exécutons maintenant ce code avec le node app.js dans le terminal, vous pourrez voir la réponse complète que nous recevons. Cependant, supposons que vous vouliez simplement voir la température pour ce code postal - alors la plupart de ces données dans la réponse ne vous sont pas utiles. Axios renvoie en fait la réponse de l'API dans l'objet de données, qui est une propriété de la réponse. Cela signifie que la réponse du serveur est en fait située dans response.data , donc imprimons-la à la place dans la fonction de rappel : console.log(response.data) .
Maintenant, nous avons dit que les serveurs Web traitent toujours JSON comme une chaîne, et c'est vrai. Vous remarquerez peut-être, cependant, que response.data est déjà un objet (évident en exécutant console.log(typeof response.data) ) — nous n'avons pas eu à l'analyser avec JSON.parse() . C'est parce qu'Axios s'en occupe déjà pour nous dans les coulisses.
La sortie dans le terminal de l'exécution de console.log(response.data) peut être formatée - "jolie-imprimée" - en exécutant console.log(JSON.stringify(response.data, undefined, 2)) . JSON.stringify() convertit un objet JSON en une chaîne et intègre l'objet, un filtre et le nombre de caractères à indenter lors de l'impression. Vous pouvez voir la réponse que cela fournit :
{ "coord": { "lon": -118.24, "lat": 33.97 }, "weather": [ { "id": 800, "main": "Clear", "description": "clear sky", "icon": "01d" } ], "base": "stations", "main": { "temp": 288.21, "pressure": 1022, "humidity": 15, "temp_min": 286.15, "temp_max": 289.75 }, "visibility": 16093, "wind": { "speed": 2.1, "deg": 110 }, "clouds": { "all": 1 }, "dt": 1546459080, "sys": { "type": 1, "id": 4361, "message": 0.0072, "country": "US", "sunrise": 1546441120, "sunset": 1546476978 }, "id": 420003677, "name": "Lynwood", "cod": 200 } Maintenant, il est clair que la température que nous recherchons est située sur la propriété main de l'objet response.data , nous pouvons donc y accéder en appelant response.data.main.temp . Regardons le code de notre application jusqu'à présent :
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => console.log(response.data.main.temp)) .catch(error => console.log('Error', error));La température que nous récupérons est en fait en Kelvin, qui est une échelle de température généralement utilisée en Physique, Chimie et Thermodynamique en raison du fait qu'elle fournit un point "zéro absolu", qui est la température à laquelle tout mouvement thermique de tous les les particules cessent. Nous avons juste besoin de convertir cela en Fahrenheit ou Celcius avec les formules ci-dessous :
F = K * 9/5 - 459,67
C = K - 273,15
Mettons à jour notre rappel de réussite pour imprimer les nouvelles données avec cette conversion. Nous ajouterons également une phrase appropriée aux fins de l'expérience utilisateur :
axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error)); Les parenthèses autour de la variable de message ne sont pas obligatoires, elles ont simplement l'air bien - comme lorsque vous travaillez avec JSX dans React. Les barres obliques inverses empêchent la chaîne de modèle de formater une nouvelle ligne et la méthode prototype replace() String supprime les espaces blancs à l'aide d'expressions régulières (RegEx). Les méthodes prototypes toFixed() Number arrondissent un float à un nombre spécifique de décimales — dans ce cas, deux.
Avec cela, notre app.js final ressemble à ceci :
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error));Conclusion
Nous avons beaucoup appris sur le fonctionnement de Node dans cet article, des différences entre les requêtes synchrones et asynchrones, aux fonctions de rappel, aux nouvelles fonctionnalités ES6, aux événements, aux gestionnaires de packages, aux API, au JSON et au protocole de transfert hypertexte, aux bases de données non relationnelles. , et nous avons même créé notre propre application en ligne de commande en utilisant la plupart de ces nouvelles connaissances.
Dans les prochains articles de cette série, nous examinerons en profondeur les API Call Stack, Event Loop et Node, nous parlerons du partage de ressources cross-origin (CORS) et nous construirons un Full API Stack Bookshelf utilisant des bases de données, des points de terminaison, l'authentification des utilisateurs, des jetons, un rendu de modèle côté serveur, etc.
À partir de là, commencez à créer vos propres applications Node, lisez la documentation Node, sortez et trouvez des API ou des modules Node intéressants et implémentez-les vous-même. Le monde vous appartient et vous avez à portée de main l'accès au plus grand réseau de connaissances de la planète : Internet. Utilisez-le à votre avantage.
Lectures complémentaires sur SmashingMag :
- Comprendre et utiliser les API REST
- Nouvelles fonctionnalités JavaScript qui changeront la façon dont vous écrivez Regex
- Garder Node.js rapide : outils, techniques et astuces pour créer des serveurs Node.js hautes performances
- Construire un chatbot AI simple avec l'API Web Speech et Node.js