
15 questions et réponses d'entrevue sur l'apprentissage automatique pour 2022
Publié: 2021-01-08Êtes-vous quelqu'un qui souhaite faire une carrière réussie dans l'apprentissage automatique? Si oui, tant mieux pour vous !
Mais d'abord, vous devez vous préparer pour le brise-glace - l'entretien ML.
Étant donné que le processus de préparation d'un entretien peut être écrasant, nous avons décidé d'intervenir - voici une liste organisée des 15 questions les plus fréquemment posées dans les entretiens d'apprentissage automatique !
- Quelle est la différence entre Deep Learning et Machine Learning ?
Alors que l'apprentissage automatique implique l'application et l'utilisation d'algorithmes avancés pour analyser les données, découvrir les modèles cachés dans les données et en tirer des leçons, et enfin appliquer les connaissances acquises pour prendre des décisions commerciales éclairées. Quant au Deep Learning, il s'agit d'un sous-ensemble du Machine Learning qui implique l'utilisation de réseaux neuronaux artificiels qui s'inspirent de la structure du réseau neuronal du cerveau humain. Le Deep Learning est largement utilisé dans la détection de fonctionnalités.
- Définir - Précision et rappel.
La précision ou la valeur prédictive positive mesure ou prédit plus précisément le nombre de vrais positifs revendiqués par un modèle par rapport au nombre de positifs qu'il revendique réellement.
Le rappel ou taux de vrais positifs fait référence au nombre de positifs revendiqués par un modèle par rapport au nombre réel de positifs présents dans les données.

Rejoignez le cours d'apprentissage automatique en ligne des meilleures universités du monde - Masters, programmes de troisième cycle pour cadres et programme de certificat avancé en ML et IA pour accélérer votre carrière.
- Expliquez les termes « biais » et « variance ». '
Au cours du processus de formation, l'erreur attendue d'un algorithme d'apprentissage est généralement classée ou décomposée en deux parties : le biais et la variance. Alors que le «biais» est une situation d'erreur due à l'utilisation d'hypothèses simples dans l'algorithme d'apprentissage, la «variance» désigne une erreur due à la complexité de cet algorithme d'apprentissage dans l'analyse des données. Le biais mesure la proximité du classificateur moyen créé par l'algorithme d'apprentissage par rapport à la fonction cible, et la variance mesure de combien la prédiction de l'algorithme d'apprentissage varie pour différents ensembles de données d'apprentissage.
- Comment fonctionne une courbe ROC ?
La courbe ROC ou Receiver Operating Characteristic est une représentation graphique de la variation entre les taux de vrais positifs et les taux de faux positifs à différents seuils. C'est un outil fondamental pour l'évaluation des tests de diagnostic et est souvent utilisé comme représentation du compromis entre la sensibilité du modèle (vrais positifs) et la probabilité de déclencher de fausses alarmes (faux positifs).
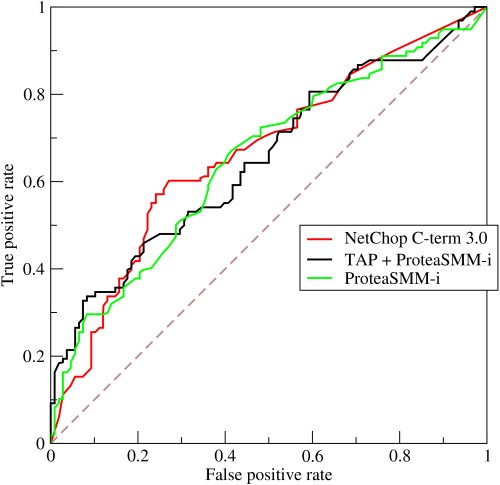
La source
- La courbe représente le compromis entre sensibilité et spécificité - si la sensibilité augmente, la spécificité diminuera.
- Si la courbe se rapproche davantage de l'axe de gauche et du haut de l'espace ROC, le test est généralement plus précis. Cependant, si la courbe se rapproche de la diagonale à 45 degrés de l'espace ROC, le test est moins précis ou fiable.
- La pente de la ligne tangente à un point de coupure indique le rapport de vraisemblance (LR) pour cette valeur particulière du test.
- L'aire sous la courbe mesure la précision du test.
- Expliquez la différence entre les erreurs de type 1 et de type 2 ?
L'erreur de type 1 est une erreur faussement positive qui « prétend » qu'un incident s'est produit alors qu'en fait rien ne s'est produit. Le meilleur exemple d'erreur faussement positive est une fausse alarme incendie – l'alarme se met à sonner lorsqu'il n'y a pas d'incendie. Contrairement à cela, une erreur de type 2 est une erreur faussement négative qui "affirme" que rien ne s'est produit alors que quelque chose s'est définitivement produit. Ce serait une erreur de type 2 de dire à une femme enceinte qu'elle ne porte pas de bébé.
- Pourquoi Bayes est-il appelé « Bayes naïf » ?
Naive Bayes est qualifié de "naïf" car bien qu'il ait de nombreuses applications pratiques, il est basé sur l'hypothèse impossible à trouver dans les données réelles - toutes les caractéristiques d'un ensemble de données sont cruciales, indépendantes et égales. Dans l'approche Naive Bayes, la probabilité conditionnelle est calculée comme le produit pur des probabilités des composants individuels, ce qui implique l'indépendance complète des caractéristiques. Malheureusement, cette hypothèse ne peut jamais être satisfaite dans un scénario réel.
- Qu'entend-on par le terme "Sur-ajustement" ? Pouvez-vous l'éviter? Si c'est le cas, comment?
Habituellement, pendant le processus de formation, un modèle reçoit de grandes quantités de données. Au cours du processus, les données commencent à apprendre même à partir des informations inexactes et du bruit présents dans l'ensemble de données d'échantillon. Cela crée une influence négative sur les performances du modèle sur les nouvelles données, c'est-à-dire que le modèle ne peut pas classer avec précision les nouvelles instances/données en dehors de celles de l'ensemble d'apprentissage. C'est ce qu'on appelle le surajustement.
Oui, il est possible d'éviter le surajustement. Voici comment:
- Rassemblez plus de données (provenant de sources disparates) pour entraîner le modèle avec différents échantillons.
- Appliquez des méthodes d'assemblage (par exemple, Random Forest) qui utilisent l'approche de bagging pour minimiser la variation des prédictions en juxtaposant les résultats de plusieurs arbres de décision sur différentes unités de l'ensemble de données.
- Assurez-vous d'utiliser des techniques de validation croisée.
- Nommez les deux méthodes utilisées pour l'étalonnage en apprentissage supervisé.
Les deux méthodes d'étalonnage dans l'apprentissage supervisé sont l'étalonnage de Platt et la régression isotonique. Ces deux méthodes sont spécifiquement conçues pour la classification binaire.
- Pourquoi taillez-vous un arbre de décision ?
Les arbres de décision doivent être élagués pour se débarrasser des branches aux faibles capacités prédictives. Cela permet de minimiser le quotient de complexité du modèle d'arbre de décision et d'optimiser sa précision prédictive. L'élagage peut se faire de haut en bas ou de bas en haut. L'élagage à erreurs réduites, l'élagage à complexité de coût, l'élagage à complexité d'erreurs et l'élagage à erreurs minimales sont quelques-unes des méthodes d'élagage d'arbre de décision les plus utilisées.

- Qu'entend-on par score F1?
En termes simples, le score F1 est une mesure des performances d'un modèle - une moyenne de la précision et du rappel d'un modèle, les résultats proches de 1 étant les meilleurs et ceux proches de 0 étant les pires. Le score F1 peut être utilisé dans les tests de classification qui n'accordent pas d'importance aux vrais négatifs.
- Différencier un algorithme Génératif et Discriminatif.
Alors qu'un algorithme génératif apprend les catégories de données, un algorithme discriminant apprend la distinction entre différentes catégories de données. En ce qui concerne les tâches de classification, les modèles discriminatifs dépassent généralement les modèles génératifs.
- Qu'est-ce que l'Ensemble Learning ?
Ensemble Learning utilise une combinaison d'algorithmes d'apprentissage pour optimiser les performances prédictives des modèles. Dans cette méthode, plusieurs modèles tels que des classificateurs ou des experts sont à la fois générés et combinés de manière stratégique pour éviter le surajustement dans les modèles. Il est principalement utilisé pour améliorer la prédiction, la classification, l'approximation de fonctions, les performances, etc., d'un modèle.
- Définissez 'Kernel Trick'.
La méthode Kernel Trick implique l'utilisation de fonctions du noyau qui peuvent fonctionner dans un espace de caractéristiques de dimension supérieure et implicite sans avoir à calculer explicitement les coordonnées des points dans cette dimension. Les fonctions du noyau calculent les produits internes entre les images de toutes les paires de données présentes dans un espace de caractéristiques. Cette procédure est moins coûteuse en termes de calcul que le calcul explicite des coordonnées et est connue sous le nom de Kernel Trick.
- Comment devez-vous gérer les données manquantes ou corrompues dans un jeu de données ?
Pour trouver les données manquantes/corrompues dans un jeu de données, vous devez soit supprimer les lignes et les colonnes, soit les remplacer par d'autres valeurs. La bibliothèque Pandas a deux excellentes méthodes pour trouver les données manquantes/corrompues - isnull() et dropna(). Ces deux fonctions sont spécifiquement conçues pour vous aider à trouver les lignes/colonnes de données avec des données manquantes/corrompues et à supprimer ces valeurs.
- Qu'est-ce qu'une table de hachage ?
Une table de hachage est une structure de données qui crée un tableau associatif, dans lequel une clé est mappée à des valeurs spécifiques à l'aide d'une fonction de hachage. Les tables de hachage sont principalement utilisées dans l'indexation de bases de données.
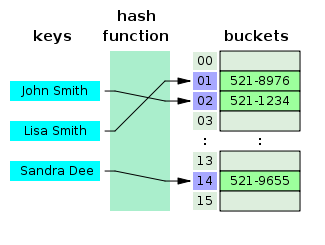
La source
Cette liste de questions est uniquement destinée à vous présenter les bases du Machine Learning, et franchement, ces vingt questions ne sont qu'une goutte dans l'océan. L'apprentissage automatique progresse en ce moment même, et donc, avec le temps, de nouveaux concepts émergeront. La clé pour réussir vos entretiens ML réside donc dans le besoin constant d'apprendre et d'améliorer vos compétences. Alors, lancez-vous et fouettez Internet, lisez des revues, rejoignez des communautés en ligne, assistez à des conférences et des séminaires sur le ML - il y a tellement de façons d'apprendre.
Pour entrer dans une grande organisation, un certificat d'une institution réputée est indispensable. Découvrez le programme Executive PG de l'IIIT-B en apprentissage automatique et IA et obtenez une assistance professionnelle des meilleures entreprises de ML et d'IA.
Quelles sont les limites d'Ensemble Learning ?
Les approches d'ensemble peuvent aider à réduire la variance et à développer des modèles plus robustes. Cependant, l'utilisation de techniques d'ensemble présente certains inconvénients, tels qu'un manque d'explicabilité et de performance. De plus, gardez à l'esprit que l'efficacité des ensembles provient de leur capacité à agréger plusieurs modèles qui se concentrent sur différents aspects de la question. Cependant, ils ont une période de prévision plus longue car vous pouvez avoir besoin des prévisions de centaines de modèles. Même s'ils ont de meilleures projections, le gain en précision n'en vaut peut-être pas la peine.
Combien de temps faut-il pour apprendre le Machine Learning ?
En ce qui concerne l'apprentissage automatique, les technologies complexes utilisées à cette fin pourraient facilement effrayer les gens. Cependant, le comprendre petit à petit n'est pas difficile. Une expérience préalable en statistiques, en mathématiques avancées, etc. vous aidera sans aucun doute à saisir rapidement tous les concepts. Cependant, étant donné que la formation et les compétences varient d'une personne à l'autre, une personne peut apprendre le ML en trois semaines tandis qu'une autre peut avoir besoin d'un an.
Comment le Machine Learning est-il utilisé dans notre vie de tous les jours ?
Gmail classe les e-mails comme essentiels en les triant comme principal, promotions, social et mise à jour à l'aide de l'apprentissage automatique. Les entreprises utilisent des réseaux de neurones pour détecter les transactions frauduleuses sur la base de données telles que la dernière fréquence des transactions, le montant de la transaction et le type de commerçant. Les détecteurs de plagiat utilisent également l'apprentissage automatique. En ce qui concerne l'ingénierie ML, il faut environ six mois pour terminer.