
Classificateur KNN pour l'apprentissage automatique : tout ce que vous devez savoir
Publié: 2021-09-28Vous souvenez-vous de l'époque où l'intelligence artificielle (IA) n'était qu'un concept limité aux romans et aux films de science-fiction ? Eh bien, grâce aux progrès technologiques, l'IA est quelque chose avec laquelle nous vivons maintenant tous les jours. D'Alexa et Siri étant là à notre entière disposition aux plates-formes OTT "sélectionnant" les films que nous aimerions regarder, l'IA est presque devenue l'ordre du jour et est là pour dire dans un avenir prévisible.
Tout cela est possible grâce aux algorithmes ML avancés. Aujourd'hui, nous allons parler d'un tel algorithme ML utile, le classificateur K-NN.
Branche de l'IA et de l'informatique, l'apprentissage automatique utilise des données et des algorithmes pour imiter la compréhension humaine tout en améliorant progressivement la précision des algorithmes. L'apprentissage automatique implique la formation d'algorithmes pour effectuer des prédictions ou des classifications et découvrir des informations clés qui guident la prise de décision stratégique au sein des entreprises et des applications.
L'algorithme KNN (k-plus proche voisin) est un algorithme fondamental d'apprentissage automatique supervisé utilisé pour résoudre des problèmes de régression et de classification. Alors, plongeons-nous pour en savoir plus sur le classificateur K-NN.
Table des matières
Apprentissage automatique supervisé ou non supervisé
L'apprentissage supervisé et non supervisé sont deux approches fondamentales de la science des données, et il est pertinent de connaître la différence avant d'entrer dans les détails de KNN.
L'apprentissage supervisé est une approche d'apprentissage automatique qui utilise des ensembles de données étiquetés pour aider à prédire les résultats. Ces ensembles de données sont conçus pour « superviser » ou former des algorithmes afin de prédire les résultats ou de classer les données avec précision. Par conséquent, les entrées et les sorties étiquetées permettent au modèle d'apprendre au fil du temps tout en améliorant sa précision.

L'apprentissage supervisé implique deux types de problèmes : la classification et la régression. Dans les problèmes de classification , les algorithmes répartissent les données de test en catégories discrètes, telles que la séparation des chats des chiens.
Un exemple réel significatif serait de classer les spams dans un dossier séparé de votre boîte de réception. D'autre part, la méthode de régression de l' apprentissage supervisé forme des algorithmes pour comprendre la relation entre les variables indépendantes et dépendantes. Il utilise différents points de données pour prédire des valeurs numériques, telles que la projection du chiffre d'affaires d'une entreprise.
L'apprentissage non supervisé , au contraire, utilise des algorithmes d'apprentissage automatique pour l'analyse et le regroupement d'ensembles de données non étiquetés. Ainsi, il n'y a pas besoin d'intervention humaine ("non supervisée") pour que les algorithmes identifient des modèles cachés dans les données.
Les modèles d'apprentissage non supervisé ont trois applications principales : l'association, le regroupement et la réduction de la dimensionnalité. Cependant, nous n'entrerons pas dans les détails car cela dépasse le cadre de notre discussion.
K-Voisin le plus proche (KNN)
L'algorithme K-Nearest Neighbor ou KNN est un algorithme d'apprentissage automatique basé sur le modèle d'apprentissage supervisé. L'algorithme K-NN fonctionne en supposant que des choses similaires existent à proximité les unes des autres. Par conséquent, l'algorithme K-NN utilise la similarité des caractéristiques entre les nouveaux points de données et les points de l'ensemble d'apprentissage (cas disponibles) pour prédire les valeurs des nouveaux points de données. Essentiellement, l'algorithme K-NN attribue une valeur au dernier point de données en fonction de sa ressemblance avec les points de l'ensemble d'apprentissage. L'algorithme K-NN trouve une application dans les problèmes de classification et de régression, mais est principalement utilisé pour les problèmes de classification.
Voici un exemple pour comprendre le classificateur K-NN.

La source
Dans l'image ci-dessus, la valeur d'entrée est une créature présentant des similitudes avec un chat et un chien. Cependant, nous voulons le classer en chat ou en chien. Nous pouvons donc utiliser l'algorithme K-NN pour cette classification. Le modèle K-NN trouvera des similitudes entre le nouvel ensemble de données (entrée) et les images de chat et de chien disponibles (ensemble de données d'entraînement). Par la suite, le modèle placera le nouveau point de données dans la catégorie chat ou chien en fonction des caractéristiques les plus similaires.
De même, la catégorie A (points verts) et la catégorie B (points orange) ont l'exemple graphique ci-dessus. Nous avons également un nouveau point de données (point bleu) qui tombera dans l'une ou l'autre des catégories. Nous pouvons résoudre ce problème de classification en utilisant un algorithme K-NN et identifier la nouvelle catégorie de points de données.
Définition des propriétés de l'algorithme K-NN
Les deux propriétés suivantes définissent le mieux l'algorithme K-NN :
- Il s'agit d'un algorithme d'apprentissage paresseux car au lieu d'apprendre immédiatement à partir de l'ensemble d'apprentissage, l'algorithme K-NN stocke l'ensemble de données et s'entraîne à partir de l'ensemble de données au moment de la classification.
- K-NN est également un algorithme non paramétrique , ce qui signifie qu'il ne fait aucune hypothèse sur les données sous-jacentes.
Fonctionnement de l'algorithme K-NN
Examinons maintenant les étapes suivantes pour comprendre le fonctionnement de l'algorithme K-NN.
Étape 1 : chargez les données d'entraînement et de test.
Étape 2 : Choisissez les points de données les plus proches, c'est-à-dire la valeur de K.
Étape 3 : Calculez la distance du nombre K de voisins (la distance entre chaque ligne de données d'apprentissage et de données de test). La méthode euclidienne est la plus couramment utilisée pour calculer la distance.
Étape 4 : Prenez les K voisins les plus proches en fonction de la distance euclidienne calculée.
Étape 5 : Parmi les K voisins les plus proches, comptez le nombre de points de données dans chaque catégorie.
Étape 6 : attribuez les nouveaux points de données à la catégorie pour laquelle le nombre de voisins est maximal.
Étape 7 : Fin. Le modèle est maintenant prêt.
Rejoignez les cours d'intelligence artificielle en ligne des meilleures universités du monde - Masters, Executive Post Graduate Programs et Advanced Certificate Program in ML & AI pour accélérer votre carrière.
Choisir la valeur de K
K est un paramètre critique dans l'algorithme K-NN. Par conséquent, nous devons garder à l'esprit certains points avant de décider d'une valeur de K.
L'utilisation de courbes d'erreur est une méthode courante pour déterminer la valeur de K. L'image ci-dessous montre des courbes d'erreur pour différentes valeurs de K pour les données de test et d'apprentissage.


La source
Dans l'exemple graphique ci-dessus, l'erreur de train est nulle à K = 1 dans les données d'apprentissage car le voisin le plus proche du point est ce point lui-même. Cependant, l'erreur de test est élevée même à de faibles valeurs de K. C'est ce qu'on appelle une variance élevée ou un surajustement des données. L'erreur de test diminue à mesure que l'on augmente la valeur de K., mais passé une certaine valeur de K, on constate que l'erreur de test augmente à nouveau, on parle de biais ou de sous-ajustement. Ainsi, l'erreur de données de test est initialement élevée en raison de la variance, elle diminue et se stabilise ensuite, et avec une augmentation supplémentaire de la valeur de K, l'erreur de test augmente à nouveau en raison du biais.
Par conséquent, la valeur de K à laquelle l'erreur de test se stabilise et est faible est prise comme valeur optimale de K. En considérant la courbe d'erreur ci-dessus, K=8 est la valeur optimale.
Un exemple pour comprendre le fonctionnement de l'algorithme K-NN
Considérez un ensemble de données qui a été tracé comme suit :

La source
Supposons qu'il existe un nouveau point de données (point noir) en (60,60) que nous devons classer dans la classe violette ou rouge. Nous utiliserons K=3, ce qui signifie que le nouveau point de données trouvera trois points de données les plus proches, deux dans la classe rouge et un dans la classe violette.
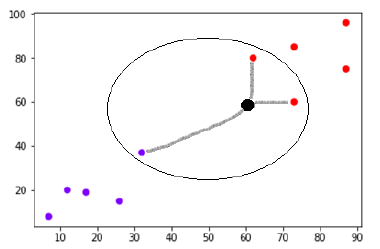
La source
Les voisins les plus proches sont déterminés en calculant la distance euclidienne entre deux points. Voici une illustration pour montrer comment le calcul est effectué.

La source
Maintenant, puisque deux (sur les trois) des voisins les plus proches du nouveau point de données (point noir) se trouvent dans la classe rouge, le nouveau point de données sera également affecté à la classe rouge.
Rejoignez le cours d'apprentissage automatique en ligne des meilleures universités du monde - Masters, programmes de troisième cycle pour cadres et programme de certificat avancé en ML et IA pour accélérer votre carrière.
K-NN comme classificateur (implémentation en Python)
Maintenant que nous avons eu une explication simplifiée de l'algorithme K-NN, passons à l'implémentation de l'algorithme K-NN en Python. Nous nous concentrerons uniquement sur le classificateur K-NN.
Étape 1 : importez les packages Python nécessaires.

La source
Étape 2 : Téléchargez l'ensemble de données iris à partir du référentiel d'apprentissage automatique de l'UCI. Son lien Web est "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
Étape 3 : Attribuez des noms de colonne à l'ensemble de données.

La source
Étape 4 : Lire l'ensemble de données dans Pandas DataFrame.

La source
Étape 5 : Le prétraitement des données est effectué à l'aide des lignes de script suivantes.

La source
Étape 6 : Divisez l'ensemble de données en test et en fractionnement d'entraînement. Le code ci-dessous divisera l'ensemble de données en 40 % de données de test et 60 % de données d'entraînement.

La source
Étape 7 : La mise à l'échelle des données s'effectue comme suit :

La source
Étape 8 : Entraînez le modèle à l'aide de la classe KNeighborsClassifier de sklearn.

La source
Étape 9 : Faites une prédiction à l'aide du script suivant :

La source
Étape 10 : Imprimez les résultats.

La source
Sortir:

La source
Et ensuite ? Inscrivez-vous au programme de certificat avancé en apprentissage automatique de l'IIT Madras et upGrad
Supposons que vous aspiriez à devenir un Data Scientist qualifié ou un professionnel de l'apprentissage automatique. Dans ce cas, le cours de certification avancée en apprentissage automatique et cloud de l'IIT Madras et upGrad est fait pour vous !
Le programme en ligne de 12 mois est spécialement conçu pour les professionnels qui souhaitent maîtriser les concepts d'apprentissage automatique, de traitement de données volumineuses, de gestion de données, d'entreposage de données, de cloud et de déploiement de modèles d'apprentissage automatique.
Voici quelques faits saillants du cours pour vous donner une meilleure idée de ce que le programme offre :
- Certification prestigieuse mondialement acceptée de l'IIT Madras
- Plus de 500 heures d'apprentissage, plus de 20 études de cas et projets, plus de 25 sessions de mentorat de l'industrie, plus de 8 missions de codage
- Couverture complète de 7 langages et outils de programmation
- 4 semaines de projet de synthèse de l'industrie
- Ateliers pratiques pratiques
- Mise en réseau peer-to-peer hors ligne
Inscrivez-vous aujourd'hui pour en savoir plus sur le programme!
Conclusion
Avec le temps, le Big Data continue de croître et l'intelligence artificielle devient de plus en plus étroitement liée à nos vies. En conséquence, il existe une forte augmentation de la demande de professionnels de la science des données capables de tirer parti de la puissance des modèles d'apprentissage automatique pour recueillir des informations sur les données et améliorer les processus métier critiques et, en général, notre monde. Nul doute que le domaine de l'intelligence artificielle et de l'apprentissage automatique semble en effet prometteur. Avec upGrad , vous pouvez être assuré que votre carrière dans l'apprentissage automatique et le cloud est enrichissante !
Pourquoi K-NN est-il un bon classificateur ?
Le principal avantage de K-NN par rapport aux autres algorithmes d'apprentissage automatique est que nous pouvons facilement utiliser K-NN pour la classification multiclasse. Ainsi, K-NN est le meilleur algorithme si nous devons classer les données en plus de deux catégories ou si les données comprennent plus de deux étiquettes. En outre, il est idéal pour les données non linéaires et a une précision relativement élevée.
Quelle est la limite de l'algorithme K-NN ?
L'algorithme K-NN fonctionne en calculant la distance entre les points de données. Par conséquent, il est assez évident qu'il s'agit d'un algorithme relativement plus long et qu'il faudra plus de temps pour le classer dans certains cas. Par conséquent, il est préférable de ne pas utiliser trop de points de données lors de l'utilisation de K-NN pour la classification multiclasse. D'autres limitations incluent le stockage de mémoire élevé et la sensibilité aux fonctionnalités non pertinentes.
Quelles sont les applications réelles de K-NN ?
K-NN a plusieurs cas d'utilisation réels dans l'apprentissage automatique, tels que la détection de l'écriture manuscrite, la reconnaissance vocale, la reconnaissance vidéo et la reconnaissance d'images. Dans le secteur bancaire, K-NN est utilisé pour prédire si un individu est éligible à un prêt en fonction de ses caractéristiques similaires aux défaillants. En politique, K-NN peut être utilisé pour classer les électeurs potentiels en différentes classes comme « votera pour le parti X » ou « votera pour le parti Y », etc.