
Présentation de l'API basée sur les composants
Publié: 2022-03-10Cet article a été mis à jour le 31 janvier 2019 pour réagir aux commentaires des lecteurs. L'auteur a ajouté des fonctionnalités d'interrogation personnalisées à l'API basée sur les composants et décrit son fonctionnement .
Une API est le canal de communication permettant à une application de charger des données à partir du serveur. Dans le monde des API, REST a été la méthodologie la plus établie, mais a récemment été éclipsée par GraphQL, qui offre des avantages importants par rapport à REST. Alors que REST nécessite plusieurs requêtes HTTP pour récupérer un ensemble de données afin de rendre un composant, GraphQL peut interroger et récupérer ces données en une seule requête, et la réponse sera exactement ce qui est requis, sans sur-extraction ou sous-extraction de données comme cela se produit généralement dans DU REPOS.
Dans cet article, je décrirai une autre façon de récupérer des données que j'ai conçue et appelée "PoP" (et open source ici), qui développe l'idée de récupérer des données pour plusieurs entités dans une seule requête introduite par GraphQL et prend un pas plus loin, c'est-à-dire que pendant que REST récupère les données d'une ressource et que GraphQL récupère les données de toutes les ressources d'un composant, l'API basée sur les composants peut récupérer les données de toutes les ressources de tous les composants d'une seule page.
L'utilisation d'une API basée sur des composants a plus de sens lorsque le site Web est lui-même construit à l'aide de composants, c'est-à-dire lorsque la page Web est composée de manière itérative de composants enveloppant d'autres composants jusqu'à ce que, tout en haut, nous obtenions un seul composant qui représente la page. Par exemple, la page Web illustrée dans l'image ci-dessous est construite avec des composants, qui sont entourés de carrés :
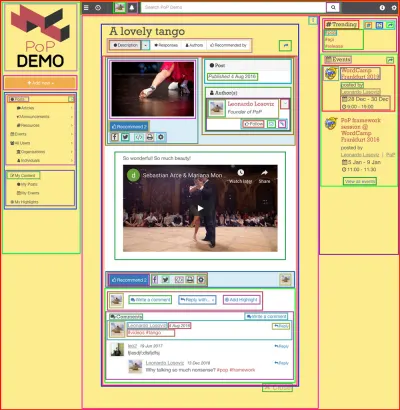
Une API basée sur des composants est capable de faire une seule demande au serveur en demandant les données pour toutes les ressources de chaque composant (ainsi que pour tous les composants de la page), ce qui est accompli en conservant les relations entre les composants dans la structure de l'API elle-même.
Entre autres, cette structure offre les avantages suivants :
- Une page avec de nombreux composants ne déclenchera qu'une seule requête au lieu de plusieurs ;
- Les données partagées entre les composants ne peuvent être extraites qu'une seule fois de la base de données et imprimées une seule fois dans la réponse ;
- Cela peut réduire considérablement, voire supprimer complètement, le besoin d'un magasin de données.
Nous les explorerons en détail tout au long de l'article, mais d'abord, explorons ce que sont réellement les composants et comment nous pouvons créer un site basé sur ces composants, et enfin, explorons le fonctionnement d'une API basée sur les composants.
Lecture recommandée : A GraphQL Primer : Pourquoi nous avons besoin d'un nouveau type d'API
Construire un site via des composants
Un composant est simplement un ensemble de morceaux de code HTML, JavaScript et CSS réunis pour créer une entité autonome. Cela peut ensuite envelopper d'autres composants pour créer des structures plus complexes, et être lui-même enveloppé par d'autres composants également. Un composant a un objectif, qui peut aller de quelque chose de très basique (comme un lien ou un bouton) à quelque chose de très élaboré (comme un carrousel ou un téléchargeur d'images par glisser-déposer). Les composants sont plus utiles lorsqu'ils sont génériques et permettent la personnalisation via des propriétés injectées (ou "accessoires"), afin qu'ils puissent servir un large éventail de cas d'utilisation. Dans le pire des cas, le site lui-même devient un composant.
Le terme « composant » est souvent utilisé pour désigner à la fois la fonctionnalité et la conception. Par exemple, en ce qui concerne les fonctionnalités, les frameworks JavaScript tels que React ou Vue permettent de créer des composants côté client, capables de s'auto-rendre (par exemple, après que l'API a récupéré les données requises), et d'utiliser des accessoires pour définir des valeurs de configuration sur leur composants enveloppés, permettant la réutilisation du code. En ce qui concerne la conception, Bootstrap a normalisé l'apparence et la convivialité des sites Web grâce à sa bibliothèque de composants frontaux, et il est devenu une tendance saine pour les équipes de créer des systèmes de conception pour maintenir leurs sites Web, ce qui permet aux différents membres de l'équipe (concepteurs et développeurs, mais aussi marketeurs et vendeurs) de parler un langage unifié et d'exprimer une identité cohérente.
La composition d'un site est alors un moyen très judicieux de rendre le site Web plus facile à maintenir. Les sites utilisant des frameworks JavaScript tels que React et Vue sont déjà basés sur des composants (au moins côté client). L'utilisation d'une bibliothèque de composants comme Bootstrap ne rend pas nécessairement le site basé sur des composants (il peut s'agir d'un gros blob de HTML), mais il intègre le concept d'éléments réutilisables pour l'interface utilisateur.
Si le site est une grosse goutte de HTML, pour que nous le composions, nous devons diviser la mise en page en une série de modèles récurrents, pour lesquels nous devons identifier et cataloguer les sections de la page en fonction de leur similitude de fonctionnalités et de styles, et briser ces sections en couches, aussi granulaires que possible, en essayant de concentrer chaque couche sur un seul objectif ou action, et en essayant également de faire correspondre des couches communes à travers différentes sections.
Remarque : "Atomic Design" de Brad Frost est une excellente méthodologie pour identifier ces modèles communs et construire un système de conception réutilisable.
Par conséquent, construire un site à travers des composants s'apparente à jouer avec LEGO. Chaque composant est soit une fonctionnalité atomique, soit une composition d'autres composants, soit une combinaison des deux.
Comme illustré ci-dessous, un composant de base (un avatar) est itérativement composé par d'autres composants jusqu'à obtenir la page Web en haut :

La spécification de l'API basée sur les composants
Pour l'API basée sur les composants que j'ai conçue, un composant est appelé un "module", donc à partir de maintenant les termes "composant" et "module" sont utilisés de manière interchangeable.
La relation de tous les modules s'enveloppant les uns les autres, du module le plus haut jusqu'au dernier niveau, s'appelle la "hiérarchie des composants". Cette relation peut être exprimée via un tableau associatif (un tableau de key => property) côté serveur, dans lequel chaque module indique son nom comme attribut key et ses modules internes sous la propriété modules . L'API encode ensuite simplement ce tableau en tant qu'objet JSON pour la consommation :
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }La relation entre les modules est définie de manière strictement descendante : un module enveloppe d'autres modules et sait qui ils sont, mais il ne sait pas — et s'en moque — quels modules l'enveloppent.
Par exemple, dans le code JSON ci-dessus, le module module-level1 sait qu'il encapsule les modules module-level11 et module-level12 , et, de manière transitive, il sait également qu'il module-level121 ; mais le module module-level11 ne se soucie pas de qui l'enveloppe, par conséquent, il ignore module-level1 .
Ayant la structure basée sur les composants, nous pouvons maintenant ajouter les informations réelles requises par chaque module, qui sont classées en paramètres (tels que les valeurs de configuration et autres propriétés) et les données (telles que les ID des objets de base de données interrogés et autres propriétés) , et placé en conséquence sous les entrées modulesettings et moduledata :
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } Ensuite, l'API ajoutera les données d'objet de la base de données. Ces informations ne sont pas placées sous chaque module, mais sous une section partagée appelée bases de databases , pour éviter la duplication des informations lorsque deux ou plusieurs modules différents récupèrent les mêmes objets de la base de données.
De plus, l'API représente les données de l'objet de la base de données de manière relationnelle, pour éviter la duplication des informations lorsque deux ou plusieurs objets de la base de données différents sont liés à un objet commun (par exemple, deux messages ayant le même auteur). En d'autres termes, les données d'objet de base de données sont normalisées.
Lecture recommandée : Créer un formulaire de contact sans serveur pour votre site statique
La structure est un dictionnaire, organisé sous chaque type d'objet d'abord et ID d'objet ensuite, à partir duquel nous pouvons obtenir les propriétés de l'objet :
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }Cet objet JSON est déjà la réponse de l'API basée sur les composants. Son format est une spécification à part entière : tant que le serveur renvoie la réponse JSON dans son format requis, le client peut consommer l'API indépendamment de la façon dont elle est implémentée. Par conséquent, l'API peut être implémentée sur n'importe quel langage (ce qui est l'une des beautés de GraphQL : être une spécification et non une implémentation réelle lui a permis de devenir disponible dans une myriade de langages.)
Note : Dans un prochain article, je décrirai mon implémentation de l'API à base de composants en PHP (qui est celle disponible dans le repo).
Exemple de réponse API
Par exemple, la réponse de l'API ci-dessous contient une hiérarchie de composants avec deux modules, page => post-feed , où le module post-feed récupère les articles de blog. Veuillez noter ce qui suit :
- Chaque module sait quels sont ses objets interrogés à partir de la propriété
dbobjectids(ID4et9pour les articles de blog) - Chaque module connaît le type d'objet pour ses objets interrogés à partir de la propriété
dbkeys(les données de chaque publication se trouvent sousposts, et les données de l'auteur de la publication, correspondant à l'auteur avec l'ID donné sous la propriétéauthorde la publication, se trouvent soususers) - Étant donné que les données de l'objet de la base de données sont relationnelles, l'
authorde la propriété contient l'ID de l'objet auteur au lieu d'imprimer directement les données de l'auteur.
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }Différences de récupération de données à partir d'API basées sur les ressources, basées sur les schémas et basées sur les composants
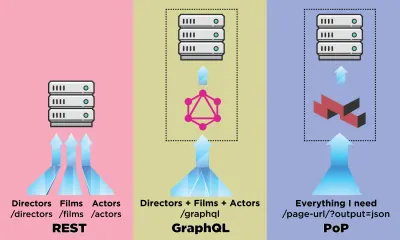
Voyons comment une API basée sur des composants telle que PoP se compare, lors de la récupération de données, à une API basée sur des ressources telle que REST et à une API basée sur un schéma telle que GraphQL.
Disons qu'IMDB a une page avec deux composants qui doivent récupérer des données : "Featured director" (montrant une description de George Lucas et une liste de ses films) et "Films recommended for you" (montrant des films tels que Star Wars : Episode I — La Menace Fantôme et Le Terminator ). Cela pourrait ressembler à ceci :
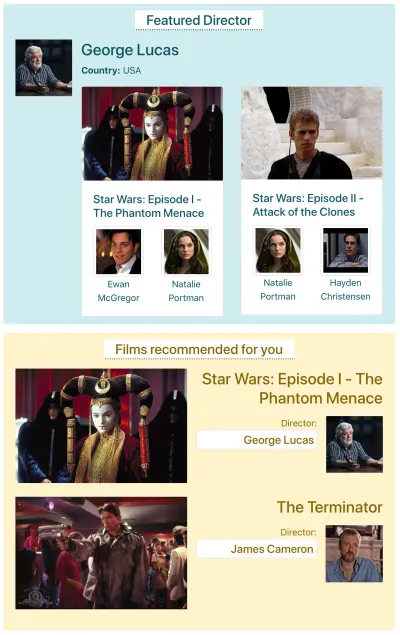
Voyons combien de requêtes sont nécessaires pour récupérer les données via chaque méthode API. Pour cet exemple, le composant "Featured director" apporte un résultat ("George Lucas"), dont il récupère deux films ( Star Wars : Episode I — La Menace fantôme et Star Wars : Episode II — L'Attaque des clones ), et pour chaque film deux acteurs (« Ewan McGregor » et « Natalie Portman » pour le premier film, et « Natalie Portman » et « Hayden Christensen » pour le deuxième film). Le volet "Films recommandés pour vous" apporte deux résultats ( Star Wars : Episode I - La Menace fantôme et Terminator ), puis va chercher leurs réalisateurs ("George Lucas" et "James Cameron" respectivement).
En utilisant REST pour rendre le composant featured-director , nous aurons peut-être besoin des 7 requêtes suivantes (ce nombre peut varier en fonction de la quantité de données fournies par chaque point de terminaison, c'est-à-dire de la quantité de surextraction mise en œuvre) :
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQL permet, grâce à des schémas fortement typés, de récupérer toutes les données requises en une seule requête par composant. La requête pour récupérer des données via GraphQL pour le composant featuredDirector ressemble à ceci (après avoir implémenté le schéma correspondant) :
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }Et il produit la réponse suivante :
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }Et la requête pour le composant "Films recommandés pour vous" produit la réponse suivante :
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoP n'émettra qu'une seule demande pour récupérer toutes les données de tous les composants de la page et normaliser les résultats. Le point de terminaison à appeler est simplement le même que l'URL pour laquelle nous devons obtenir les données, en ajoutant simplement un paramètre supplémentaire output=json pour indiquer d'apporter les données au format JSON au lieu de les imprimer au format HTML :
GET - /url-of-the-page/?output=json En supposant que la structure du module a un module supérieur nommé page contenant les modules featured-director et films-recommended-for-you , et ceux-ci ont également des sous-modules, comme ceci :
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"La réponse JSON unique renvoyée ressemblera à ceci :
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }Analysons comment ces trois méthodes se comparent, en termes de vitesse et de quantité de données récupérées.
Vitesse
Grâce à REST, devoir récupérer 7 requêtes juste pour rendre un composant peut être très lent, principalement sur des connexions de données mobiles et fragiles. Par conséquent, le saut de REST à GraphQL représente beaucoup pour la vitesse, car nous sommes capables de rendre un composant avec une seule requête.
PoP, car il peut récupérer toutes les données de nombreux composants en une seule requête, sera plus rapide pour rendre plusieurs composants à la fois ; cependant, cela n'est probablement pas nécessaire. Faire en sorte que les composants soient rendus dans l'ordre (tels qu'ils apparaissent dans la page) est déjà une bonne pratique, et pour les composants qui apparaissent sous le pli, il n'y a certainement pas d'urgence à les rendre. Par conséquent, les API basées sur le schéma et basées sur les composants sont déjà assez bonnes et clairement supérieures à une API basée sur les ressources.
Quantité de données
À chaque requête, les données de la réponse GraphQL peuvent être dupliquées : l'actrice "Natalie Portman" est récupérée deux fois dans la réponse du premier composant, et lorsque l'on considère la sortie conjointe des deux composants, on peut également trouver des données partagées, telles que le film Star Wars : Épisode I - La Menace fantôme .
PoP, d'autre part, normalise les données de la base de données et ne les imprime qu'une seule fois, cependant, il entraîne la surcharge de l'impression de la structure du module. Par conséquent, selon la demande particulière ayant des données dupliquées ou non, l'API basée sur le schéma ou l'API basée sur les composants aura une taille plus petite.
En conclusion, une API basée sur un schéma telle que GraphQL et une API basée sur des composants telle que PoP sont également bonnes en termes de performances et supérieures à une API basée sur des ressources telle que REST.
Lecture recommandée : Comprendre et utiliser les API REST
Propriétés particulières d'une API basée sur les composants
Si une API basée sur des composants n'est pas nécessairement meilleure en termes de performances qu'une API basée sur un schéma, vous vous demandez peut-être, alors qu'est-ce que j'essaie de réaliser avec cet article ?
Dans cette section, je vais tenter de vous convaincre qu'une telle API a un potentiel incroyable, offrant plusieurs fonctionnalités très désirables, ce qui en fait un concurrent sérieux dans le monde des API. Je décris et démontre chacune de ses grandes caractéristiques uniques ci-dessous.
Les données à extraire de la base de données peuvent être déduites de la hiérarchie des composants
Lorsqu'un module affiche une propriété d'un objet DB, le module peut ne pas savoir ou ne pas se soucier de quel objet il s'agit ; tout ce dont il se soucie est de définir quelles propriétés de l'objet chargé sont requises.
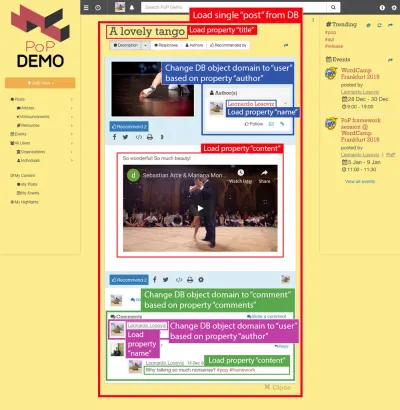
Par exemple, considérez l'image ci-dessous. Un module charge un objet de la base de données (dans ce cas, un seul article), puis ses modules descendants afficheront certaines propriétés de l'objet, telles que le title et content :
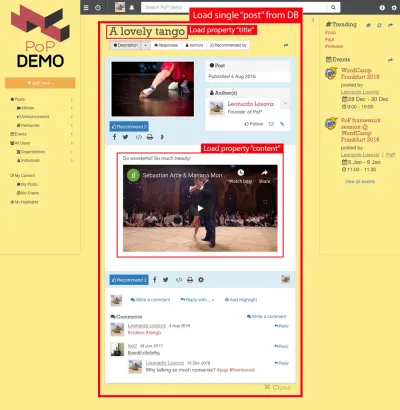
Ainsi, le long de la hiérarchie des composants, les modules "dataloading" seront chargés de charger les objets interrogés (le module chargeant le message unique, dans ce cas), et ses modules descendants définiront quelles propriétés de l'objet DB sont requises ( title et content , dans ce cas).
La récupération de toutes les propriétés requises pour l'objet DB peut être effectuée automatiquement en parcourant la hiérarchie des composants : en partant du module de chargement de données, nous parcourons tous ses modules descendants jusqu'à atteindre un nouveau module de chargement de données, ou jusqu'à la fin de l'arborescence ; à chaque niveau, nous obtenons toutes les propriétés requises, puis fusionnons toutes les propriétés ensemble et les interrogeons à partir de la base de données, toutes une seule fois.
Dans la structure ci-dessous, le module single-post récupère les résultats de la base de données (le message avec l'ID 37), et les sous-modules post-title et post-content définissent les propriétés à charger pour l'objet DB interrogé ( title et content respectivement); les sous-modules post-layout et fetch-next-post-button ne nécessitent aucun champ de données.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"La requête à exécuter est calculée automatiquement à partir de la hiérarchie des composants et de leurs champs de données obligatoires, contenant toutes les propriétés nécessaires à tous les modules et leurs sous-modules :
SELECT title, content FROM posts WHERE id = 37 En récupérant les propriétés à récupérer directement depuis les modules, la requête sera automatiquement mise à jour chaque fois que la hiérarchie des composants change. Si, par exemple, nous ajoutons ensuite le sous-module post-thumbnail , qui nécessite le champ de données thumbnail :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"Ensuite, la requête est automatiquement mise à jour pour récupérer la propriété supplémentaire :
SELECT title, content, thumbnail FROM posts WHERE id = 37Parce que nous avons établi les données d'objet de base de données à récupérer de manière relationnelle, nous pouvons également appliquer cette stratégie parmi les relations entre les objets de base de données eux-mêmes.
Considérez l'image ci-dessous : en partant du type d'objet post et en descendant dans la hiérarchie des composants, nous devrons déplacer le type d'objet DB vers user et comment , correspondant respectivement à l'auteur du message et à chacun des commentaires du message, puis, pour chaque commentaire, il doit à nouveau changer le type d'objet en user correspondant à l'auteur du commentaire.
Passer d'un objet de base de données à un objet relationnel (éventuellement en changeant le type d'objet, comme dans post => author allant de post à user , ou non, comme dans author => followers allant de user à user ) est ce que j'appelle "changer de domaine ”.
Après le passage à un nouveau domaine, à partir de ce niveau dans la hiérarchie des composants vers le bas, toutes les propriétés requises seront soumises au nouveau domaine :
- le
nameest extrait de l'objetuser(représentant l'auteur du message), -
contentest extrait de l'objetcomment(représentant chacun des commentaires de l'article), -
nameest extrait de l'objetuser(représentant l'auteur de chaque commentaire).
En parcourant la hiérarchie des composants, l'API sait quand elle bascule vers un nouveau domaine et, de manière appropriée, met à jour la requête pour récupérer l'objet relationnel.
Par exemple, si nous devons afficher les données de l'auteur de la publication, le sous-module d'empilement post-author changera le domaine à ce niveau de post à l' user correspondant, et à partir de ce niveau vers le bas, l'objet DB chargé dans le contexte passé au module est l'utilisateur. Ensuite, les sous-modules user-name et user-avatar sous post-author chargeront les propriétés name et avatar sous l'objet user :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"Résultat de la requête suivante :
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.idEn résumé, en configurant chaque module de manière appropriée, il n'est pas nécessaire d'écrire la requête pour récupérer des données pour une API basée sur des composants. La requête est automatiquement produite à partir de la structure de la hiérarchie des composants elle-même, obtenant quels objets doivent être chargés par les modules de chargement de données, les champs à récupérer pour chaque objet chargé défini à chaque module descendant et la commutation de domaine définie à chaque module descendant.
L'ajout, la suppression, le remplacement ou la modification de tout module mettra automatiquement à jour la requête. Après l'exécution de la requête, les données récupérées seront exactement ce qui est requis - ni plus ni moins.
Observer des données et calculer des propriétés supplémentaires
En partant du module de chargement de données vers le bas de la hiérarchie des composants, n'importe quel module peut observer les résultats renvoyés et calculer des éléments de données supplémentaires en fonction de ceux-ci, ou des valeurs de feedback , qui sont placées sous l'entrée moduledata .
Par exemple, le module fetch-next-post-button peut ajouter une propriété indiquant s'il y a plus de résultats à récupérer ou non (en fonction de cette valeur de retour, s'il n'y a pas plus de résultats, le bouton sera désactivé ou masqué) :
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }La connaissance implicite des données requises réduit la complexité et rend le concept de « point final » obsolète
Comme indiqué ci-dessus, l'API basée sur les composants peut récupérer exactement les données requises, car elle dispose du modèle de tous les composants sur le serveur et des champs de données requis par chaque composant. Ensuite, il peut rendre implicite la connaissance des champs de données requis.

L'avantage est que la définition des données requises par le composant peut être mise à jour uniquement côté serveur, sans avoir à redéployer les fichiers JavaScript, et le client peut être rendu muet, en demandant simplement au serveur de fournir les données dont il a besoin. , diminuant ainsi la complexité de l'application côté client.
De plus, l'appel de l'API pour récupérer les données de tous les composants d'une URL spécifique peut être effectué simplement en interrogeant cette URL et en ajoutant le paramètre supplémentaire output=json pour indiquer le retour des données de l'API au lieu d'imprimer la page. Ainsi, l'URL devient son propre point de terminaison ou, considéré d'une manière différente, le concept de « point de terminaison » devient obsolète.
Récupération de sous-ensembles de données : les données peuvent être récupérées pour des modules spécifiques, trouvés à n'importe quel niveau de la hiérarchie des composants
Que se passe-t-il si nous n'avons pas besoin de récupérer les données de tous les modules d'une page, mais simplement les données d'un module spécifique à partir de n'importe quel niveau de la hiérarchie des composants ? Par exemple, si un module implémente un défilement infini, lors du défilement vers le bas, nous ne devons récupérer que les nouvelles données pour ce module, et non pour les autres modules de la page.
Cela peut être accompli en filtrant les branches de la hiérarchie des composants qui seront incluses dans la réponse, pour inclure les propriétés uniquement à partir du module spécifié et ignorer tout ce qui se trouve au-dessus de ce niveau. Dans mon implémentation (que je décrirai dans un prochain article), le filtrage est activé en ajoutant le paramètre modulefilter=modulepaths à l'URL, et le module (ou les modules) sélectionné est indiqué via un paramètre modulepaths[] , où un "module path ” est la liste des modules commençant par le module le plus haut jusqu'au module spécifique (par exemple module1 => module2 => module3 a un chemin de module [ module1 , module2 , module3 ] et est passé comme paramètre d'URL sous module1.module2.module3 ) .
Par exemple, dans la hiérarchie des composants ci-dessous, chaque module a une entrée dbobjectids :
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Ensuite, demander l'URL de la page Web en ajoutant les paramètres modulefilter=modulepaths et modulepaths[]=module1.module2.module5 produira la réponse suivante :
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Essentiellement, l'API commence à charger les données à partir de module1 => module2 => module5 . C'est pourquoi module6 , qui relève de module5 , apporte également ses données alors que module3 et module4 ne le font pas.
De plus, nous pouvons créer des filtres de modules personnalisés pour inclure un ensemble de modules pré-arrangés. Par exemple, appeler une page avec modulefilter=userstate ne peut imprimer que les modules qui nécessitent un état utilisateur pour les afficher dans le client, tels que les modules module3 et module6 :
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] Les informations sur les modules de départ se trouvent dans la section requestmeta , sous l'entrée filteredmodules , sous la forme d'un tableau de chemins de modules :
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }Cette fonctionnalité permet de mettre en place une Single-Page Application simple, dans laquelle le frame du site est chargé à la requête initiale :
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] Mais, à partir d'eux, nous pouvons ajouter le paramètre modulefilter=page à toutes les URL demandées, en filtrant le cadre et en n'apportant que le contenu de la page :
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] Semblable aux filtres de module userstate et page décrits ci-dessus, nous pouvons implémenter n'importe quel filtre de module personnalisé et créer des expériences utilisateur riches.
Le module est sa propre API
Comme indiqué ci-dessus, nous pouvons filtrer la réponse de l'API pour récupérer des données à partir de n'importe quel module. Par conséquent, chaque module peut interagir avec lui-même du client au serveur en ajoutant simplement son chemin de module à l'URL de la page Web dans laquelle il a été inclus.
J'espère que vous excuserez ma surexcitation, mais je ne saurais trop insister sur la beauté de cette fonctionnalité. Lors de la création d'un composant, nous n'avons pas besoin de créer une API pour l'accompagner pour récupérer des données (REST, GraphQL ou quoi que ce soit), car le composant est déjà capable de se parler dans le serveur et de charger son propre données - il est complètement autonome et égoïste .
Chaque module de chargement de données exporte l'URL pour interagir avec lui sous l'entrée dataloadsource de la section datasetmodulemeta :
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }La récupération des données est découplée entre les modules et DRY
Pour faire valoir mon point de vue sur le fait que la récupération de données dans une API basée sur des composants est hautement découplée et DRY (ne vous répétez pas), je devrai d'abord montrer comment dans une API basée sur un schéma telle que GraphQL , elle est moins découplée et pas sec.
Dans GraphQL, la requête pour récupérer les données doit indiquer les champs de données du composant, qui peuvent inclure des sous-composants, et ceux-ci peuvent également inclure des sous-composants, et ainsi de suite. Ensuite, le composant le plus élevé doit également savoir quelles données sont requises par chacun de ses sous-composants, afin de récupérer ces données.
Par exemple, le rendu du composant <FeaturedDirector> peut nécessiter les sous-composants suivants :
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> Dans ce scénario, la requête GraphQL est implémentée au niveau <FeaturedDirector> . Ensuite, si le sous-composant <Film> est mis à jour, en demandant le titre via la propriété filmTitle au lieu de title , la requête du composant <FeaturedDirector> devra également être mise à jour pour refléter ces nouvelles informations (GraphQL dispose d'un mécanisme de version qui peut traiter avec ce problème, mais tôt ou tard, nous devrions encore mettre à jour les informations). Cela entraîne une complexité de maintenance, qui peut être difficile à gérer lorsque les composants internes changent souvent ou sont produits par des développeurs tiers. Par conséquent, les composants ne sont pas complètement découplés les uns des autres.
De même, nous pouvons vouloir rendre directement le composant <Film> pour un film spécifique, pour lequel nous devons également implémenter une requête GraphQL à ce niveau, pour récupérer les données du film et de ses acteurs, ce qui ajoute du code redondant : des portions de la même requête vivra à différents niveaux de la structure du composant. Donc GraphQL n'est pas DRY .
Étant donné qu'une API basée sur des composants sait déjà comment ses composants s'intègrent dans sa propre structure, ces problèmes sont complètement évités. D'une part, le client peut simplement demander les données requises dont il a besoin, quelles que soient ces données ; if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
Dans l'API basée sur les composants, cependant, nous pouvons facilement utiliser les relations entre les modules déjà décrites dans l'API pour coupler les modules ensemble. Alors qu'à l'origine, nous aurons cette réponse :
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }Après avoir ajouté Instagram, nous aurons la réponse mise à jour :
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } Et juste en itérant toutes les valeurs sous modulesettings["share-on-social-media"].modules , le composant <ShareOnSocialMedia> peut être mis à niveau pour afficher le composant <InstagramShare> sans avoir besoin de redéployer un fichier JavaScript. Par conséquent, l'API prend en charge l'ajout et la suppression de modules sans compromettre le code d'autres modules, atteignant un degré de modularité plus élevé.
Cache/magasin de données côté client natif
Les données de la base de données récupérées sont normalisées dans une structure de dictionnaire et standardisées de sorte que, à partir de la valeur sur dbobjectids , toute donnée sous les bases de databases puisse être atteinte simplement en suivant le chemin d'accès comme indiqué par les entrées dbkeys , quelle que soit la façon dont il a été structuré . Par conséquent, la logique d'organisation des données est déjà native de l'API elle-même.
Nous pouvons profiter de cette situation de plusieurs manières. Par exemple, les données renvoyées pour chaque demande peuvent être ajoutées dans un cache côté client contenant toutes les données demandées par l'utilisateur tout au long de la session. Par conséquent, il est possible d'éviter d'ajouter un magasin de données externe tel que Redux à l'application (je veux dire concernant la gestion des données, pas concernant d'autres fonctionnalités telles que l'Undo/Redo, l'environnement collaboratif ou le débogage du voyage dans le temps).
De plus, la structure basée sur les composants favorise la mise en cache : la hiérarchie des composants ne dépend pas de l'URL, mais des composants nécessaires dans cette URL. De cette façon, deux événements sous /events/1/ et /events/2/ partageront la même hiérarchie de composants, et les informations sur les modules requis pourront être réutilisées entre eux. Par conséquent, toutes les propriétés (autres que les données de la base de données) peuvent être mises en cache sur le client après la récupération du premier événement et réutilisées à partir de là, de sorte que seules les données de la base de données pour chaque événement ultérieur doivent être récupérées et rien d'autre.
Extensibilité et réaffectation
La section databases de données de l'API peut être étendue, permettant de classer ses informations dans des sous-sections personnalisées. Par défaut, toutes les données d'objet de base de données sont placées sous l'entrée primary , cependant, nous pouvons également créer des entrées personnalisées où placer des propriétés d'objet DB spécifiques.
Par exemple, si le composant "Films recommandés pour vous" décrit précédemment affiche une liste des amis de l'utilisateur connecté qui ont regardé ce film sous la propriété friendsWhoWatchedFilm sur l'objet DB du film , car cette valeur changera en fonction de la connexion user alors nous enregistrons cette propriété sous une entrée userstate à la place, donc lorsque l'utilisateur se déconnecte, nous ne supprimons que cette branche de la base de données en cache sur le client, mais toutes les données primary restent :
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }De plus, jusqu'à un certain point, la structure de la réponse de l'API peut être réorientée. En particulier, les résultats de la base de données peuvent être imprimés dans une structure de données différente, telle qu'un tableau au lieu du dictionnaire par défaut.
Par exemple, si le type d'objet n'est qu'un (par exemple films ), il peut être formaté comme un tableau à alimenter directement dans un composant typeahead :
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]Prise en charge de la programmation orientée aspect
En plus de récupérer des données, l'API basée sur les composants peut également publier des données, par exemple pour créer une publication ou ajouter un commentaire, et exécuter tout type d'opération, comme la connexion ou la déconnexion de l'utilisateur, l'envoi d'e-mails, la journalisation, l'analyse, etc. Il n'y a aucune restriction : toute fonctionnalité fournie par le CMS sous-jacent peut être invoquée via un module, à n'importe quel niveau.
Le long de la hiérarchie des composants, nous pouvons ajouter n'importe quel nombre de modules, et chaque module peut exécuter sa propre opération. Par conséquent, toutes les opérations ne doivent pas nécessairement être liées à l'action attendue de la requête, comme lors de l'exécution d'une opération POST, PUT ou DELETE dans REST ou de l'envoi d'une mutation dans GraphQL, mais peuvent être ajoutées pour fournir des fonctionnalités supplémentaires, telles que l'envoi d'un e-mail. à l'administrateur lorsqu'un utilisateur crée un nouveau message.
Ainsi, en définissant la hiérarchie des composants via l'injection de dépendances ou des fichiers de configuration, on peut dire que l'API prend en charge la programmation orientée aspect, "un paradigme de programmation qui vise à augmenter la modularité en permettant la séparation des préoccupations transversales".
Lecture recommandée : Protéger votre site avec la politique des fonctionnalités
Sécurité renforcée
Les noms des modules ne sont pas nécessairement fixes lorsqu'ils sont imprimés dans la sortie, mais peuvent être raccourcis, mutilés, modifiés au hasard ou (en bref) rendus variables de n'importe quelle manière. Bien qu'initialement pensé pour raccourcir la sortie de l'API (afin que les noms de module carousel-featured-posts ou drag-and-drop-user-images puissent être raccourcis en une notation de base 64, telle que a1 , a2 et ainsi de suite, pour l'environnement de production ), cette fonctionnalité permet de modifier fréquemment les noms des modules dans la réponse de l'API pour des raisons de sécurité.
Par exemple, les noms d'entrée sont nommés par défaut comme leur module correspondant ; puis, les modules appelés username et password , qui doivent être rendus dans le client sous la forme <input type="text" name="{input_name}"> et <input type="password" name="{input_name}"> respectivement, peuvent être définies des valeurs aléatoires variables pour leurs noms d'entrée (comme zwH8DSeG et QBG7m6EF aujourd'hui, et c3oMLBjo et c46oVgN6 demain), ce qui rend plus difficile pour les spammeurs et les robots de cibler le site.
Polyvalence grâce à des modèles alternatifs
L'imbrication des modules permet de se ramifier vers un autre module pour ajouter une compatibilité pour un support ou une technologie spécifique, ou de modifier un style ou une fonctionnalité, puis de revenir à la branche d'origine.
Par exemple, supposons que la page Web ait la structure suivante :
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" Dans ce cas, nous aimerions que le site Web fonctionne également pour AMP, cependant, les modules module2 , module4 et module5 ne sont pas compatibles avec AMP. Nous pouvons ramifier ces modules en modules similaires et compatibles AMP module2AMP , module4AMP et module5AMP , après quoi nous continuons à charger la hiérarchie des composants d'origine, de sorte que seuls ces trois modules sont remplacés (et rien d'autre) :
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"Cela permet de générer assez facilement différentes sorties à partir d'une seule base de code, en ajoutant des fourches uniquement ici et là selon les besoins, et toujours limitées et limitées à des modules individuels.
Temps de démonstration
Le code implémentant l'API comme expliqué dans cet article est disponible dans ce référentiel open source.
J'ai déployé l'API PoP sous https://nextapi.getpop.org à des fins de démonstration. Le site Web fonctionne sur WordPress, donc les permaliens URL sont ceux typiques de WordPress. Comme indiqué précédemment, en leur ajoutant le paramètre output=json , ces URL deviennent leurs propres points de terminaison API.
Le site est soutenu par la même base de données du site Web PoP Demo, de sorte qu'une visualisation de la hiérarchie des composants et des données récupérées peut être effectuée en interrogeant la même URL dans cet autre site Web (par exemple, en visitant le https://demo.getpop.org/u/leo/ explique les données de https://nextapi.getpop.org/u/leo/?output=json ).
Les liens ci-dessous illustrent l'API pour les cas décrits précédemment :
- La page d'accueil, un article unique, un auteur, une liste d'articles et une liste d'utilisateurs.
- Un événement, filtrant à partir d'un module spécifique.
- Une balise, des modules de filtrage qui nécessitent un état utilisateur et un filtrage pour n'apporter qu'une page à partir d'une application monopage.
- Un tableau d'emplacements, à alimenter dans une dactylographie.
- Modèles alternatifs pour la page « Qui sommes-nous ? » : Normal, Imprimable, Embarquable.
- Changer les noms des modules : original vs mangled.
- Filtrage des informations : uniquement les paramètres du module, les données du module plus les données de la base de données.
Conclusion
Une bonne API est un tremplin pour créer des applications fiables, facilement maintenables et puissantes. Dans cet article, j'ai décrit les concepts qui sous-tendent une API à base de composants qui, je pense, est une très bonne API, et j'espère vous avoir également convaincu.
Jusqu'à présent, la conception et la mise en œuvre de l'API ont impliqué plusieurs itérations et pris plus de cinq ans - et ce n'est pas encore tout à fait prêt. Cependant, il est dans un état assez décent, pas prêt pour la production mais en tant qu'alpha stable. Ces jours-ci, je travaille toujours dessus; travailler sur la définition de la spécification ouverte, implémenter les couches supplémentaires (comme le rendu) et rédiger la documentation.
Dans un prochain article, je décrirai le fonctionnement de mon implémentation de l'API. Jusque-là, si vous avez des idées à ce sujet, qu'elles soient positives ou négatives, j'aimerais lire vos commentaires ci-dessous.
Mise à jour (31 janvier) : capacités d'interrogation personnalisées
Alain Schlesser a commenté qu'une API qui ne peut pas être interrogée de manière personnalisée par le client est sans valeur, nous ramenant à SOAP, en tant que telle, elle ne peut rivaliser ni avec REST ni avec GraphQL. Après avoir donné son commentaire quelques jours de réflexion, j'ai dû admettre qu'il avait raison. Cependant, au lieu de rejeter l'API basée sur les composants comme une entreprise bien intentionnée mais pas encore tout à fait là, j'ai fait quelque chose de bien mieux : j'ai dû implémenter la capacité de requête personnalisée pour cela. Et cela fonctionne comme un charme !
Dans les liens suivants, les données d'une ressource ou d'un ensemble de ressources sont récupérées comme cela se fait généralement via REST. Cependant, grâce aux fields de paramètres, nous pouvons également spécifier les données spécifiques à récupérer pour chaque ressource, en évitant la sur-extraction ou la sous-extraction des données :
- Un article unique et une collection d'articles ajoutant des paramètres
fields=title,content,datetime - Un utilisateur et une collection d'utilisateurs ajoutant des paramètres
fields=name,username,description
Les liens ci-dessus illustrent la récupération de données uniquement pour les ressources interrogées. Qu'en est-il de leurs relations ? Par exemple, disons que nous voulons récupérer une liste de messages avec les champs "title" et "content" , les commentaires de chaque post avec les champs "content" et "date" , et l'auteur de chaque commentaire avec les champs "name" et "url" . Pour y parvenir dans GraphQL, nous implémenterions la requête suivante :
query { post { title content comments { content date author { name url } } } } Pour la mise en œuvre de l'API basée sur les composants, j'ai traduit la requête dans son expression de "syntaxe à points" correspondante, qui peut ensuite être fournie via des fields de paramètres . En interrogeant sur une ressource "post", cette valeur est :
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url Ou cela peut être simplifié, en utilisant | pour regrouper tous les champs appliqués à la même ressource :
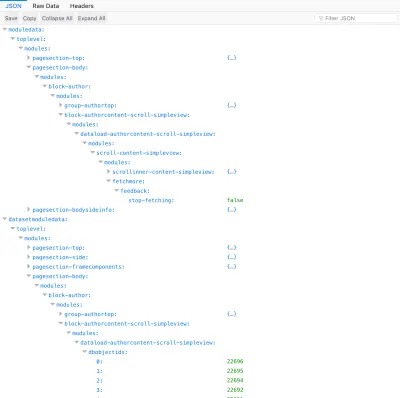
fields=title|content,comments.content|date,comments.author.name|urlLors de l'exécution de cette requête sur un seul article, nous obtenons exactement les données requises pour toutes les ressources impliquées :
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } Par conséquent, nous pouvons interroger les ressources de manière REST et spécifier des requêtes basées sur un schéma de manière GraphQL, et nous obtiendrons exactement ce qui est requis, sans surcharger ou sous-extraire les données, et en normalisant les données dans la base de données afin qu'aucune donnée ne soit dupliquée. De manière favorable, la requête peut inclure n'importe quel nombre de relations, imbriquées en profondeur, et celles-ci sont résolues avec un temps de complexité linéaire : pire cas de O(n+m), où n est le nombre de nœuds qui changent de domaine (dans ce cas 2 : comments et comments.author ) et m est le nombre de résultats récupérés (dans ce cas 5 : 1 message + 2 commentaires + 2 utilisateurs), et le cas moyen de O(n). (Ceci est plus efficace que GraphQL, qui a un temps de complexité polynomial O(n^c) et souffre d'un temps d'exécution croissant à mesure que la profondeur de niveau augmente).
Enfin, cette API peut également appliquer des modificateurs lors de l'interrogation des données, par exemple pour filtrer les ressources récupérées, comme cela peut être fait via GraphQL. Pour y parvenir, l'API se trouve simplement au-dessus de l'application et peut facilement utiliser ses fonctionnalités, il n'est donc pas nécessaire de réinventer la roue. Par exemple, l'ajout de paramètres filter=posts&searchfor=internet filtrera tous les messages contenant "internet" à partir d'une collection de messages.
La mise en place de cette nouvelle fonctionnalité sera décrite dans un prochain article.