
Conversion d'image en texte avec React et Tesseract.js (OCR)
Publié: 2022-03-10Les données sont l'épine dorsale de toute application logicielle, car le but principal d'une application est de résoudre des problèmes humains. Pour résoudre des problèmes humains, il est nécessaire d'avoir quelques informations à leur sujet.
Ces informations sont représentées sous forme de données, notamment par calcul. Sur le Web, les données sont principalement collectées sous forme de textes, d'images, de vidéos et bien d'autres. Parfois, les images contiennent des textes essentiels qui sont destinés à être traités pour atteindre un certain objectif. Ces images étaient principalement traitées manuellement car il n'y avait aucun moyen de les traiter par programmation.
L'impossibilité d'extraire du texte à partir d'images était une limitation du traitement des données que j'ai vécue de première main dans ma dernière entreprise. Nous devions traiter les cartes-cadeaux numérisées et nous devions le faire manuellement car nous ne pouvions pas extraire le texte des images.
Il y avait un département appelé "Opérations" au sein de l'entreprise qui était responsable de la confirmation manuelle des cartes-cadeaux et du crédit des comptes des utilisateurs. Bien que nous disposions d'un site Web via lequel les utilisateurs se connectaient avec nous, le traitement des cartes-cadeaux était effectué manuellement dans les coulisses.
À l'époque, notre site Web était construit principalement avec PHP (Laravel) pour le backend et JavaScript (jQuery et Vue) pour le frontend. Notre pile technique était assez bonne pour travailler avec Tesseract.js à condition que le problème soit considéré comme important par la direction.
J'étais prêt à résoudre le problème mais il n'était pas nécessaire de le résoudre du point de vue de l'entreprise ou de la direction. Après avoir quitté l'entreprise, j'ai décidé de faire des recherches et d'essayer de trouver des solutions possibles. Finalement, j'ai découvert l'OCR.
Qu'est-ce que l'OCR ?
OCR signifie « reconnaissance optique de caractères » ou « lecteur optique de caractères ». Il est utilisé pour extraire des textes à partir d'images.
L'évolution de l'OCR peut être attribuée à plusieurs inventions, mais Optophone, "Gismo", scanner à plat CCD, Newton MesssagePad et Tesseract sont les principales inventions qui élèvent la reconnaissance de caractères à un autre niveau d'utilité.
Alors, pourquoi utiliser l'OCR ? Eh bien, la reconnaissance optique de caractères résout beaucoup de problèmes, dont l'un m'a poussé à écrire cet article. Je me suis rendu compte que la possibilité d'extraire des textes d'une image assure de nombreuses possibilités telles que :
- Régulation
Chaque organisation doit réglementer les activités des utilisateurs pour certaines raisons. Le règlement pourrait être utilisé pour protéger les droits des utilisateurs et les protéger contre les menaces ou les escroqueries.
Extraire des textes d'une image permet à une organisation de traiter des informations textuelles sur une image à des fins de régulation, notamment lorsque les images sont fournies par certains utilisateurs.
Par exemple, une régulation similaire à celle de Facebook du nombre de textes sur les images utilisées pour les publicités peut être obtenue avec l'OCR. En outre, le masquage de contenu sensible sur Twitter est également rendu possible par l'OCR. - Recherche
La recherche est l'une des activités les plus courantes, en particulier sur Internet. Les algorithmes de recherche sont principalement basés sur la manipulation de textes. Avec la reconnaissance optique de caractères, il est possible de reconnaître les caractères sur les images et de les utiliser pour fournir des résultats d'image pertinents aux utilisateurs. En bref, les images et les vidéos sont désormais consultables à l'aide de l'OCR. - Accessibilité
Avoir des textes sur les images a toujours été un défi pour l'accessibilité et c'est la règle d'or d'avoir peu de textes sur une image. Avec l'OCR, les lecteurs d'écran peuvent avoir accès aux textes sur les images pour fournir une expérience nécessaire à ses utilisateurs. - Automatisation du traitement des données Le traitement des données est principalement automatisé à grande échelle. Avoir des textes sur les images est une limitation au traitement des données car les textes ne peuvent être traités que manuellement. La reconnaissance optique de caractères (OCR) permet d'extraire des textes sur des images par programmation, assurant ainsi l'automatisation du traitement des données, en particulier lorsqu'il s'agit de traiter des textes sur des images.
- Numérisation des documents imprimés
Tout se numérise et il reste encore beaucoup de documents à numériser. Les chèques, certificats et autres documents physiques peuvent désormais être numérisés grâce à la reconnaissance optique de caractères.
Découvrir toutes les utilisations ci-dessus a approfondi mes intérêts, j'ai donc décidé d'aller plus loin en posant une question :
« Comment puis-je utiliser l'OCR sur le Web, en particulier dans une application React ? »
Cette question m'a conduit à Tesseract.js.
Qu'est-ce que Tesseract.js ?
Tesseract.js est une bibliothèque JavaScript qui compile le Tesseract original de C vers JavaScript WebAssembly, rendant ainsi l'OCR accessible dans le navigateur. Le moteur Tesseract.js a été écrit à l'origine dans ASM.js et il a ensuite été porté sur WebAssembly, mais ASM.js sert toujours de sauvegarde dans certains cas lorsque WebAssembly n'est pas pris en charge.
Comme indiqué sur le site Web de Tesseract.js, il prend en charge plus de 100 langues , l'orientation automatique du texte et la détection de script, une interface simple pour lire les paragraphes, les mots et les cadres de délimitation des caractères.
Tesseract est un moteur de reconnaissance optique de caractères pour divers systèmes d'exploitation. C'est un logiciel libre, publié sous la licence Apache. Hewlett-Packard a développé Tesseract en tant que logiciel propriétaire dans les années 1980. Il est sorti en open source en 2005 et son développement est sponsorisé par Google depuis 2006.
La dernière version, la version 4, de Tesseract a été publiée en octobre 2018 et contient un nouveau moteur OCR qui utilise un système de réseau neuronal basé sur la mémoire à long court terme (LSTM) et qui est destiné à produire des résultats plus précis.
Comprendre les API Tesseract
Pour vraiment comprendre le fonctionnement de Tesseract, nous devons décomposer certaines de ses API et leurs composants. Selon la documentation de Tesseract.js, il existe deux façons de l'utiliser. Vous trouverez ci-dessous la première approche et sa décomposition :
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } La méthode de recognize prend image comme premier argument, language (qui peut être multiple) comme deuxième argument et { logger: m => console.log(me) } comme dernier argument. Les formats d'image pris en charge par Tesseract sont jpg, png, bmp et pbm qui ne peuvent être fournis que sous forme d'éléments (img, vidéo ou toile), objet fichier ( <input> ), objet blob, chemin ou URL vers une image et image encodée en base64 . (Lisez ici pour plus d'informations sur tous les formats d'image que Tesseract peut gérer.)
La langue est fournie sous la forme d'une chaîne telle que eng . Le signe + peut être utilisé pour concaténer plusieurs langues comme dans eng+chi_tra . L'argument de langage est utilisé pour déterminer les données de langage appris à utiliser dans le traitement des images.
Note : Vous trouverez toutes les langues disponibles et leurs codes ici.
{ logger: m => console.log(m) } est très utile pour obtenir des informations sur la progression d'une image en cours de traitement. La propriété logger prend une fonction qui sera appelée plusieurs fois lorsque Tesseract traitera une image. Le paramètre de la fonction logger doit être un objet avec workerId , jobId , status et progress comme propriétés :
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress est un nombre compris entre 0 et 1, et il est en pourcentage pour montrer la progression d'un processus de reconnaissance d'image.
Tesseract génère automatiquement l'objet en tant que paramètre de la fonction d'enregistrement, mais il peut également être fourni manuellement. Lorsqu'un processus de reconnaissance est en cours, les propriétés de l'objet de logger sont mises à jour chaque fois que la fonction est appelée . Ainsi, il peut être utilisé pour afficher une barre de progression de conversion, modifier une partie d'une application ou être utilisé pour obtenir le résultat souhaité.
Le result dans le code ci-dessus est le résultat du processus de reconnaissance d'image. Chacune des propriétés de result a la propriété bbox comme coordonnées x/y de sa boîte englobante.
Voici les propriétés de l'objet result , leurs significations ou utilisations :
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: tout le texte reconnu sous forme de chaîne. -
lines: Un tableau de chaque ligne de texte reconnue par ligne. -
words: Un tableau de chaque mot reconnu. -
symbols: Un tableau de chacun des caractères reconnus. -
paragraphs: Un tableau de chaque paragraphe reconnu. Nous allons discuter de la "confiance" plus tard dans cet article.
Tesseract peut aussi être utilisé de manière plus impérative comme dans :
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();Cette approche est liée à la première approche mais avec des implémentations différentes.
createWorker(options) crée un processus de travail Web ou un processus enfant de nœud qui crée un travail Tesseract. Le travailleur aide à configurer le moteur Tesseract OCR. La méthode load() charge les scripts de base de Tesseract, loadLanguage() charge n'importe quelle langue qui lui est fournie sous forme de chaîne, initialize() s'assure que Tesseract est entièrement prêt à l'emploi, puis la méthode de reconnaissance est utilisée pour traiter l'image fournie. La méthode terminate() arrête le worker et nettoie tout.
Remarque : Veuillez consulter la documentation des API Tesseract pour plus d'informations.
Maintenant, nous devons construire quelque chose pour vraiment voir à quel point Tesseract.js est efficace.
Qu'allons-nous construire ?
Nous allons créer un extracteur de code PIN de carte-cadeau, car l'extraction du code PIN d'une carte-cadeau a été le problème qui a conduit à cette aventure d'écriture en premier lieu.
Nous allons créer une application simple qui extrait le code PIN d'une carte-cadeau scannée . Alors que j'entreprenais de construire un simple extracteur de broches pour cartes-cadeaux, je vous expliquerai certains des défis auxquels j'ai été confronté tout au long de la ligne, les solutions que j'ai fournies et ma conclusion basée sur mon expérience.
- Aller au code source →
Vous trouverez ci-dessous l'image que nous allons utiliser pour les tests car elle possède des propriétés réalistes qui sont possibles dans le monde réel.

Nous allons extraire AQUX-QWMB6L-R6JAU de la carte. Alors, commençons.
Installation de React et Tesseract
Il y a une question à laquelle il faut répondre avant d'installer React et Tesseract.js et la question est, pourquoi utiliser React avec Tesseract ? Pratiquement, nous pouvons utiliser Tesseract avec Vanilla JavaScript, toutes les bibliothèques ou frameworks JavaScript tels que React, Vue et Angular.
L'utilisation de React dans ce cas est une préférence personnelle. Au départ, je voulais utiliser Vue mais j'ai décidé d'opter pour React car je connais mieux React que Vue.
Maintenant, continuons avec les installations.
Pour installer React avec create-react-app, vous devez exécuter le code ci-dessous :
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jsou
npm install tesseract.jsJ'ai décidé d'utiliser le fil pour installer Tesseract.js car je ne pouvais pas installer Tesseract avec npm mais le fil a fait le travail sans stress. Vous pouvez utiliser npm mais je recommande d'installer Tesseract avec du fil à en juger par mon expérience.
Maintenant, démarrons notre serveur de développement en exécutant le code ci-dessous :
yarn startou
npm startAprès avoir exécuté yarn start ou npm start, votre navigateur par défaut devrait ouvrir une page Web qui ressemble à ceci :

Vous pouvez également accéder à localhost:3000 dans le navigateur à condition que la page ne soit pas lancée automatiquement.
Après avoir installé React et Tesseract.js, et ensuite ?
Configurer un formulaire de téléchargement
Dans ce cas, nous allons ajuster la page d'accueil (App.js) que nous venons de visualiser dans le navigateur pour contenir le formulaire dont nous avons besoin :
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App La partie du code ci-dessus qui requiert notre attention à ce stade est la fonction handleChange .
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } Dans la fonction, URL.createObjectURL prend un fichier sélectionné via event.target.files[0] et crée une URL de référence qui peut être utilisée avec des balises HTML telles que img, audio et vidéo. Nous avons utilisé setImagePath pour ajouter l'URL à l'état. Maintenant, l'URL est désormais accessible avec imagePath .
<img src={imagePath} className="App-logo" alt="image"/> Nous définissons l'attribut src de l'image sur {imagePath} pour la prévisualiser dans le navigateur avant de la traiter.
Conversion d'images sélectionnées en textes
Comme nous avons saisi le chemin de l'image sélectionnée, nous pouvons passer le chemin de l'image à Tesseract.js pour en extraire les textes.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default AppNous ajoutons la fonction "handleClick" à "App.js et elle contient l'API Tesseract.js qui prend le chemin vers l'image sélectionnée. Tesseract.js prend "imagePath", "langue", "un objet de réglage".
Le bouton ci-dessous est ajouté au formulaire pour appeler "handClick" qui déclenche la conversion image-texte chaque fois que le bouton est cliqué.
<button onClick={handleClick} style={{height:50}}> convert to text</button>Lorsque le traitement est réussi, nous accédons à la fois à la "confiance" et au "texte" du résultat. Ensuite, nous ajoutons "text" à l'état avec "setText(text)".
En ajoutant à <p> {text} </p> , on affiche le texte extrait.
Il est évident que du « texte » est extrait de l'image mais qu'est-ce que la confiance ?
La confiance indique la précision de la conversion. Le niveau de confiance est compris entre 1 et 100. 1 représente le pire tandis que 100 représente le meilleur en termes de précision. Il peut également être utilisé pour déterminer si un texte extrait doit être accepté comme exact ou non.
Ensuite, la question est de savoir quels facteurs peuvent affecter le score de confiance ou la précision de l'ensemble de la conversion ? Il est principalement affecté par trois facteurs majeurs : la qualité et la nature du document utilisé, la qualité de la numérisation créée à partir du document et les capacités de traitement du moteur Tesseract.
Maintenant, ajoutons le code ci-dessous à "App.css" pour styliser un peu l'application.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }Voici le résultat de mon premier test :
Résultat dans Firefox
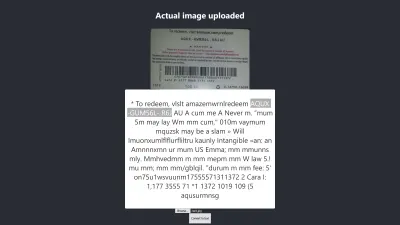
Le niveau de confiance du résultat ci-dessus est de 64. Il convient de noter que l'image de la carte-cadeau est de couleur sombre et cela affecte définitivement le résultat que nous obtenons.

Si vous regardez de plus près l'image ci-dessus, vous verrez que la broche de la carte est presque exacte dans le texte extrait. Ce n'est pas exact car la carte cadeau n'est pas vraiment claire.
Oh, attendez! À quoi ressemblera-t-il dans Chrome ?
Résultat dans Chrome
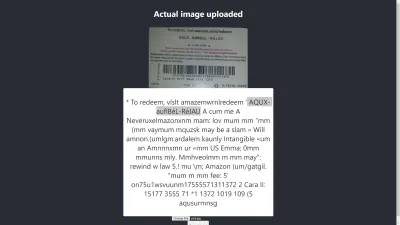
Ah ! Le résultat est encore pire dans Chrome. Mais pourquoi le résultat dans Chrome est-il différent de Mozilla Firefox ? Différents navigateurs traitent les images et leurs profils de couleurs différemment. Cela signifie qu'une image peut être rendue différemment selon le navigateur . En fournissant des image.data pré-rendues à Tesseract, il est probable que cela produise un résultat différent dans différents navigateurs car différentes image.data sont fournies à Tesseract en fonction du navigateur utilisé. Le prétraitement d'une image, comme nous le verrons plus loin dans cet article, aidera à obtenir un résultat cohérent.
Nous devons être plus précis afin d'être sûrs d'obtenir ou de donner les bonnes informations. Il faut donc aller un peu plus loin.
Essayons plus pour voir si nous pouvons atteindre l'objectif à la fin.
Test de précision
De nombreux facteurs affectent une conversion image-texte avec Tesseract.js. La plupart de ces facteurs tournent autour de la nature de l'image que nous voulons traiter et le reste dépend de la façon dont le moteur Tesseract gère la conversion.
En interne, Tesseract prétraite les images avant la conversion OCR proprement dite, mais cela ne donne pas toujours des résultats précis.
Comme solution, nous pouvons prétraiter les images pour obtenir des conversions précises. Nous pouvons binariser, inverser, dilater, redresser ou redimensionner une image pour la prétraiter pour Tesseract.js.
Le prétraitement d'images représente beaucoup de travail ou un vaste domaine en soi. Heureusement, P5.js a fourni toutes les techniques de prétraitement d'image que nous souhaitons utiliser. Au lieu de réinventer la roue ou d'utiliser toute la bibliothèque juste parce que nous voulons en utiliser une infime partie, j'ai copié celles dont nous avons besoin. Toutes les techniques de prétraitement d'image sont incluses dans preprocess.js.
Qu'est-ce que la binarisation ?
La binarisation est la conversion des pixels d'une image en noir ou en blanc. Nous voulons binariser la carte-cadeau précédente pour vérifier si la précision sera meilleure ou non.
Auparavant, nous extrayions certains textes d'une carte-cadeau, mais le code PIN cible n'était pas aussi précis que nous le souhaitions. Il est donc nécessaire de trouver un autre moyen d'obtenir un résultat précis.
Maintenant, nous voulons binariser la carte-cadeau , c'est-à-dire que nous voulons convertir ses pixels en noir et blanc afin que nous puissions voir si un meilleur niveau de précision peut être atteint ou non.
Les fonctions ci-dessous seront utilisées pour la binarisation et sont incluses dans un fichier séparé appelé preprocess.js.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImageA quoi sert le code ci-dessus ?
Nous introduisons canvas pour contenir des données d'image pour appliquer des filtres, pour pré-traiter l'image, avant de la transmettre à Tesseract pour la conversion.
La première fonction preprocessImage se trouve dans preprocess.js et prépare le canevas en récupérant ses pixels. La fonction thresholdFilter binarise l'image en convertissant ses pixels en noir ou en blanc .
Appelons preprocessImage pour voir si le texte extrait de la carte-cadeau précédente peut être plus précis.
Au moment où nous mettons à jour App.js, il devrait maintenant ressembler au code suivant :
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default AppTout d'abord, nous devons importer "preprocessImage" depuis "preprocess.js" avec le code ci-dessous :
import preprocessImage from './preprocess'; Ensuite, nous ajoutons une balise canvas au formulaire. Nous définissons l'attribut ref des balises canvas et img sur { canvasRef } et { imageRef } respectivement. Les références sont utilisées pour accéder au canevas et à l'image à partir du composant App. Nous récupérons à la fois le canevas et l'image avec "useRef" comme dans :
const canvasRef = useRef(null); const imageRef = useRef(null);Dans cette partie du code, nous fusionnons l'image avec le canevas car nous ne pouvons prétraiter un canevas qu'en JavaScript. Nous le convertissons ensuite en une URL de données avec "jpeg" comme format d'image.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");"dataUrl" est transmis à Tesseract en tant qu'image à traiter.
Maintenant, vérifions si le texte extrait sera plus précis.
Essai #2

L'image ci-dessus montre le résultat dans Firefox. Il est évident que la partie sombre de l'image a été changée en blanc mais le prétraitement de l'image ne conduit pas à un résultat plus précis. C'est encore pire.
La première conversion n'a que deux caractères incorrects mais celle-ci a quatre caractères incorrects. J'ai même essayé de changer le niveau de seuil mais en vain. Nous n'obtenons pas un meilleur résultat, non pas parce que la binarisation est mauvaise, mais parce que la binarisation de l'image ne fixe pas la nature de l'image d'une manière adaptée au moteur Tesseract.
Voyons à quoi cela ressemble également dans Chrome :

Nous obtenons le même résultat.
Après avoir obtenu un moins bon résultat en binarisant l'image, il est nécessaire de vérifier d'autres techniques de prétraitement d'image pour voir si nous pouvons résoudre le problème ou non. Nous allons donc essayer la dilatation, l'inversion et le floutage ensuite.
Obtenons simplement le code pour chacune des techniques de P5.js tel qu'utilisé par cet article. Nous allons ajouter les techniques de traitement d'image à preprocess.js et les utiliser une par une. Il est nécessaire de comprendre chacune des techniques de prétraitement d'image que nous voulons utiliser avant de les utiliser, nous allons donc en discuter d'abord.
Qu'est-ce que la dilatation ?
La dilatation consiste à ajouter des pixels aux limites des objets d'une image pour la rendre plus large, plus grande ou plus ouverte. La technique de « dilatation » est utilisée pour prétraiter nos images afin d'augmenter la luminosité des objets sur les images. Nous avons besoin d'une fonction pour dilater les images en utilisant JavaScript, donc l'extrait de code pour dilater une image est ajouté à preprocess.js.
Qu'est-ce que le flou ?
Le flou consiste à lisser les couleurs d'une image en réduisant sa netteté. Parfois, les images ont de petits points/taches. Pour supprimer ces correctifs, nous pouvons brouiller les images. L'extrait de code pour flouter une image est inclus dans preprocess.js.
Qu'est-ce que l'inversion ?
L'inversion consiste à changer les zones claires d'une image en une couleur sombre et les zones sombres en une couleur claire. Par exemple, si une image a un arrière-plan noir et un avant-plan blanc, nous pouvons l'inverser pour que son arrière-plan soit blanc et son avant-plan noir. Nous avons également ajouté l'extrait de code pour inverser une image en preprocess.js.
Après avoir ajouté dilate , invertColors et blurARGB à "preprocess.js", nous pouvons maintenant les utiliser pour prétraiter les images. Pour les utiliser, nous devons mettre à jour la fonction initiale "preprocessImage" dans preprocess.js :
preprocessImage(...) ressemble maintenant à ceci :
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } Dans preprocessImage ci-dessus, nous appliquons quatre techniques de prétraitement à une image : blurARGB() pour supprimer les points sur l'image, dilate() pour augmenter la luminosité de l'image, invertColors() pour changer la couleur de premier plan et d'arrière-plan de l'image et thresholdFilter() pour convertir l'image en noir et blanc, ce qui convient mieux à la conversion Tesseract.
Le thresholdFilter() prend image.data et level comme paramètres. Le level est utilisé pour définir le degré de blanc ou de noir de l'image. Nous avons déterminé le niveau thresholdFilter et le rayon blurRGB par essais et erreurs car nous ne savons pas à quel point l'image doit être blanche, sombre ou lisse pour que Tesseract produise un excellent résultat.
Essai #3
Voici le nouveau résultat après application de quatre techniques :

L'image ci-dessus représente le résultat que nous obtenons à la fois dans Chrome et Firefox.
Oups! Le résultat est terrible.
Au lieu d'utiliser les quatre techniques, pourquoi ne pas en utiliser deux à la fois ?
Ouais! Nous pouvons simplement utiliser les techniques invertColors et thresholdFilter pour convertir l'image en noir et blanc et basculer le premier plan et l'arrière-plan de l'image. Mais comment savoir quoi et quelles techniques combiner ? Nous savons ce qu'il faut combiner en fonction de la nature de l'image que nous voulons prétraiter.
Par exemple, une image numérique doit être convertie en noir et blanc, et une image avec des patchs doit être floutée pour supprimer les points/patchs. Ce qui compte vraiment, c'est de comprendre à quoi sert chacune des techniques.
Pour utiliser invertColors et thresholdFilter , nous devons commenter à la fois blurARGB et dilate dans preprocessImage :
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }Essai #4
Maintenant, voici le nouveau résultat :

Le résultat est encore pire que celui sans aucun prétraitement. Après avoir ajusté chacune des techniques pour cette image particulière et quelques autres images, je suis arrivé à la conclusion que les images de nature différente nécessitent des techniques de prétraitement différentes.
En bref, l'utilisation de Tesseract.js sans prétraitement d'image a produit le meilleur résultat pour la carte-cadeau ci-dessus. Toutes les autres expériences de prétraitement d'image ont donné des résultats moins précis.
Publier
Au départ, je voulais extraire le code PIN de n'importe quelle carte-cadeau Amazon, mais je n'ai pas pu y parvenir car il est inutile de faire correspondre un code PIN incohérent pour obtenir un résultat cohérent. Bien qu'il soit possible de traiter une image pour obtenir un code PIN précis, un tel prétraitement sera néanmoins incohérent au moment où une autre image de nature différente sera utilisée.
Le meilleur résultat produit
L'image ci-dessous présente le meilleur résultat produit par les expériences.
Essai #5

Les textes sur l'image et ceux extraits sont totalement les mêmes. La conversion a une précision de 100 %. J'ai essayé de reproduire le résultat mais je n'ai pu le reproduire qu'en utilisant des images de même nature.
Observation et leçons
- Certaines images qui ne sont pas prétraitées peuvent donner des résultats différents dans différents navigateurs . Cette affirmation est évidente dans le premier test. Le résultat dans Firefox est différent de celui de Chrome. Cependant, le prétraitement des images permet d'obtenir un résultat cohérent dans d'autres tests.
- La couleur noire sur un fond blanc a tendance à donner des résultats gérables. L'image ci-dessous est un exemple de résultat précis sans aucun prétraitement . J'ai également pu obtenir le même niveau de précision en prétraitant l'image, mais cela m'a demandé beaucoup d'ajustements, ce qui n'était pas nécessaire.
La conversion est précise à 100 %.
- Un texte avec une grande taille de police a tendance à être plus précis.
- Les polices avec des bords incurvés ont tendance à confondre Tesseract. Le meilleur résultat que j'ai obtenu a été obtenu lorsque j'ai utilisé Arial (police).
- L'OCR n'est actuellement pas assez bon pour automatiser la conversion image-texte, en particulier lorsqu'un niveau de précision supérieur à 80 % est requis. Cependant, il peut être utilisé pour rendre le traitement manuel des textes sur les images moins stressant en extrayant les textes pour une correction manuelle.
- L'OCR n'est actuellement pas assez bon pour transmettre des informations utiles aux lecteurs d'écran pour l' accessibilité . Fournir des informations inexactes à un lecteur d'écran peut facilement induire en erreur ou distraire les utilisateurs.
- L'OCR est très prometteur car les réseaux de neurones permettent d'apprendre et de s'améliorer. L'apprentissage en profondeur fera de l'OCR un changeur de jeu dans un avenir proche .
- Prendre des décisions en toute confiance. Un score de confiance peut être utilisé pour prendre des décisions qui peuvent avoir un impact important sur nos applications. Le score de confiance peut être utilisé pour déterminer s'il faut accepter ou rejeter un résultat. D'après mon expérience et mes expériences, j'ai réalisé que tout score de confiance inférieur à 90 n'est pas vraiment utile. Si j'ai seulement besoin d'extraire quelques épingles d'un texte, je m'attendrai à un score de confiance entre 75 et 100, et tout ce qui est en dessous de 75 sera rejeté .
Dans le cas où je traite des textes sans avoir besoin d'en extraire une partie, j'accepterai certainement un score de confiance entre 90 et 100 mais je rejetterai tout score inférieur à celui-ci. Par exemple, une précision de 90 et plus sera attendue si je veux numériser des documents tels que des chèques, une ébauche historique ou chaque fois qu'une copie exacte est nécessaire. Mais un score compris entre 75 et 90 est acceptable lorsqu'une copie exacte n'est pas importante, comme obtenir le code PIN d'une carte-cadeau. En bref, un score de confiance aide à prendre des décisions qui impactent nos applications.
Conclusion
Compte tenu de la limitation du traitement des données causée par les textes sur les images et des inconvénients qui y sont associés, la reconnaissance optique de caractères (OCR) est une technologie utile à adopter. Bien que l'OCR ait ses limites, il est très prometteur en raison de son utilisation des réseaux de neurones.
Au fil du temps, l'OCR surmontera la plupart de ses limites à l'aide de l'apprentissage en profondeur, mais avant cela, les approches mises en évidence dans cet article peuvent être utilisées pour gérer l'extraction de texte à partir d'images, au moins, pour réduire les difficultés et les pertes associées à l'apprentissage manuel. traitement — en particulier d'un point de vue commercial.
C'est maintenant à vous d'essayer l'OCR pour extraire les textes des images. Bonne chance!
Lectures complémentaires
- P5.js
- Prétraitement dans OCR
- Amélioration de la qualité de la sortie
- Utilisation de JavaScript pour prétraiter les images pour l'OCR
- OCR dans le navigateur avec Tesseract.js
- Une brève histoire de la reconnaissance optique de caractères
- L'avenir de l'OCR est le Deep Learning
- Chronologie de la reconnaissance optique de caractères