
Classification des images dans CNN : tout ce que vous devez savoir
Publié: 2021-02-25Table des matières
introduction
En parcourant le flux Facebook, vous êtes-vous déjà demandé comment les personnes d'une photo de groupe sont automatiquement étiquetées par le logiciel de Facebook ? Derrière chaque interface utilisateur interactive de Facebook que vous voyez, il y a un algorithme complexe et puissant qui est utilisé pour reconnaître et étiqueter chaque image que nous téléchargeons sur la plate-forme de médias sociaux. Avec chacune de nos images, nous ne faisons qu'aider à améliorer l'efficacité de l'algorithme. Oui, la classification d'images est l'un des algorithmes les plus utilisés où l'on voit l'application de l'intelligence artificielle.
Ces derniers temps, les réseaux de neurones convolutifs (CNN) sont devenus l'un des plus fervents partisans de l'apprentissage en profondeur. Une application populaire de ces réseaux convolutifs est la classification d'images. Dans ce didacticiel, nous allons passer en revue les bases des réseaux de neurones convolutifs, voir les différentes couches impliquées dans la construction d'un modèle CNN et enfin visualiser un exemple de la tâche de classification d'images.
Classification des images
Avant d'entrer dans les détails de l'apprentissage en profondeur et des réseaux de neurones convolutifs, comprenons les bases de la classification des images. En général, la classification d'images est définie comme la tâche dans laquelle nous donnons une image comme entrée à un modèle construit à l'aide d'un algorithme spécifique qui produit la classe ou la probabilité de la classe à laquelle l'image appartient. Ce processus dans lequel nous étiquetons une image dans une classe particulière s'appelle l'apprentissage supervisé.
Il y a une énorme différence entre la façon dont nous voyons une image et la façon dont la machine (ordinateur) voit la même image. Pour nous, nous sommes capables de visualiser l'image et de la caractériser en fonction de la couleur et de la taille. D'un autre côté, pour la machine, tout ce qu'elle voit, ce sont des chiffres. Les nombres qui sont vus sont appelés pixels.
Chaque pixel a une valeur comprise entre 0 et 255. Par conséquent, avec ces données numériques, la machine nécessite certaines étapes de prétraitement afin de dériver des motifs ou des caractéristiques spécifiques qui distinguent une image de l'autre. Les réseaux de neurones convolutifs nous aident à créer des algorithmes capables de dériver le modèle spécifique à partir d'images.
Ce que nous voyons contre ce que l'ordinateur voit
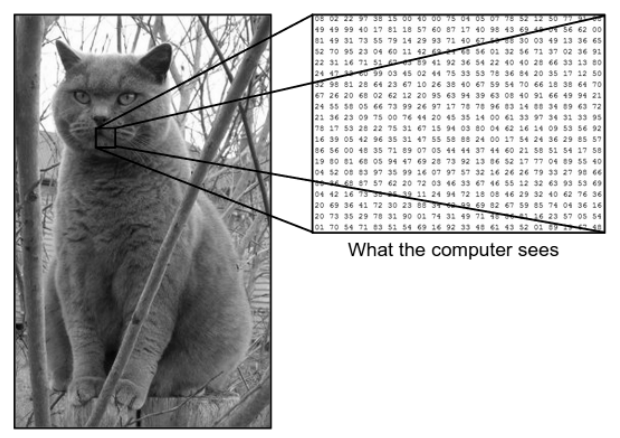 Source - Différence entre l'ordinateur et l'œil humain
Source - Différence entre l'ordinateur et l'œil humain

Apprentissage en profondeur pour la classification d'images
Maintenant que nous avons compris ce qu'est la classification d'images, voyons maintenant comment nous pouvons l'implémenter à l'aide de l'intelligence artificielle. Pour cela, nous utilisons les méthodes populaires de Deep Learning. L'apprentissage en profondeur est un sous-ensemble de l'intelligence artificielle qui utilise de grands ensembles de données d'images pour reconnaître et dériver des modèles à partir de diverses images afin de différencier les différentes classes présentes dans l'ensemble de données d'images.
Le défi majeur auquel le Deep Learning est confronté est que pour une énorme base de données, cela prend très longtemps et a un coût de calcul élevé. Cependant, les réseaux de neurones convolutifs, qui sont un type d'algorithme d'apprentissage en profondeur, résolvent bien ce problème.
Réseaux de neurones convolutifs
Dans Deep Learning, les réseaux de neurones convolutifs sont une classe de réseaux de neurones profonds qui sont principalement utilisés dans l'imagerie visuelle. Il s'agit d'une architecture particulière des Réseaux de Neurones Artificiels (ANN) proposés en 1998 par Yann LeCunn. Les réseaux de neurones convolutifs se composent de deux parties.
La première partie comprend les couches convolutives et les couches de regroupement dans lesquelles se déroule le processus d'extraction des caractéristiques principales. Dans la deuxième partie, les couches entièrement connectées et denses effectuent plusieurs transformations non linéaires sur les entités extraites et agissent comme la partie classificateur. Apprenez CNN pour la classification des images.
Considérez l'exemple d'image ci-dessus de ce que l'homme et la machine voient. Comme nous le voyons, l'ordinateur voit un tableau de pixels. Par exemple, si la taille de l'image est de 500 × 500, la taille du tableau sera de 500x500x3. Ici, 500 représente chaque hauteur et largeur, 3 représente le canal RVB où chaque canal de couleur est représenté par un tableau séparé. L'intensité des pixels varie de 0 à 255.
Maintenant, pour la classification des images, l'ordinateur recherchera les fonctionnalités au niveau de base. Selon nous, en tant qu'humains, ces caractéristiques de base du chat sont ses oreilles, son nez et ses moustaches. Alors que pour l'ordinateur, ces caractéristiques de base sont les courbures et les limites. De cette manière, en utilisant plusieurs couches différentes telles que les couches convolutives et les couches de regroupement, l'ordinateur extrait les caractéristiques de niveau de base des images.
Dans le modèle Convolutional Neural Network, il existe plusieurs types de couches telles que -
- Couche d'entrée
- Couche convolutive
- Couche de regroupement
- Couche entièrement connectée
- Couche de sortie
- Fonctions d'activation
Passons brièvement en revue chacune des couches avant d'aborder son application dans la classification des images.
Couche d'entrée
D'après le nom, nous comprenons qu'il s'agit de la couche dans laquelle l'image d'entrée sera introduite dans le modèle CNN. Selon nos besoins, nous pouvons remodeler l'image en différentes tailles telles que (28,28,3)
Couche convolutive
Vient ensuite la couche la plus importante qui consiste en un filtre (également appelé noyau) avec une taille fixe. L'opération mathématique de convolution est effectuée entre l'image d'entrée et le filtre. C'est l'étape au cours de laquelle la plupart des caractéristiques de base telles que les arêtes vives et les courbes sont extraites de l'image et, par conséquent, cette couche est également connue sous le nom de couche d'extraction de caractéristiques.
Couche de regroupement
Après avoir effectué l'opération de convolution, nous effectuons l'opération de mise en commun. Ceci est également connu sous le nom de sous-échantillonnage où le volume spatial de l'image est réduit. Par exemple, si nous effectuons une opération de mise en commun avec une foulée de 2 sur une image de dimensions 28×28, puis la taille de l'image réduite à 14×14, elle est réduite à la moitié de sa taille d'origine.
Couche entièrement connectée
La couche entièrement connectée (FC) est placée juste avant la sortie de classification finale du modèle CNN. Ces couches sont utilisées pour aplatir les résultats avant la classification. Elle implique plusieurs biais, poids et neurones. L'attachement d'une couche FC avant la classification donne un vecteur à N dimensions où N est un nombre de classes parmi lesquelles le modèle doit choisir une classe.
Couche de sortie
Enfin, la couche de sortie se compose de l'étiquette qui est principalement codée à l'aide de la méthode de codage à chaud.
Fonction d'activation
Ces fonctions d'activation sont au cœur de tout modèle de réseau neuronal convolutif. Ces fonctions sont utilisées pour déterminer la sortie d'un réseau de neurones. En bref, il détermine si un neurone particulier doit être activé ("activé") ou non. Ce sont généralement des fonctions non linéaires qui sont exécutées sur les signaux d'entrée. Cette sortie transformée est ensuite envoyée en entrée à la couche suivante de neurones. Il existe plusieurs fonctions d'activation telles que le Sigmoid, ReLU, Leaky ReLU, TanH et Softmax.
Architecture CNN de base
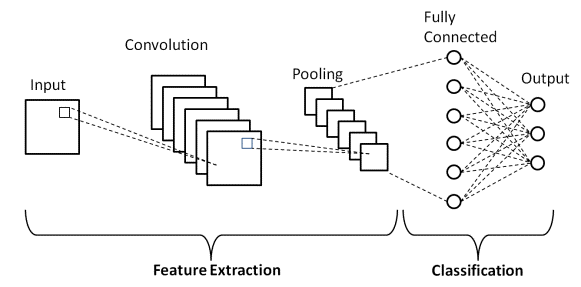
Source : Architecture de base de CNN
Comme défini précédemment, le diagramme ci-dessus est l'architecture de base d'un modèle de réseau neuronal convolutif. Maintenant que nous sommes prêts avec les bases de la classification d'images et de CNN, plongeons maintenant dans son application avec un problème en temps réel. En savoir plus sur l'architecture CNN de base.
Implémentation de réseaux de neurones convolutifs
Maintenant que nous avons compris les bases de la classification d'images et des réseaux de neurones convolutifs, visualisons son implémentation dans TensorFlow/Keras avec le codage Python. En cela, nous allons construire un modèle de réseau neuronal convolutif simple avec une architecture LeNet de base, former le modèle sur un ensemble d'apprentissage et un ensemble de test et enfin obtenir la précision du modèle sur les données de l'ensemble de test.
Ensemble de problèmes
Dans cet article pour la construction et la formation du modèle de réseau neuronal convolutif, nous utiliserons le célèbre jeu de données Fashion MNIST. MNIST signifie Institut national modifié des normes et de la technologie. Fashion-MNIST est un ensemble de données d'images d'articles de Zalando, composé d'un ensemble d'apprentissage de 60 000 exemples et d'un ensemble de test de 10 000 exemples. Chaque exemple est une image en niveaux de gris 28×28, associée à une étiquette de 10 classes.

Chaque exemple de formation et de test est affecté à l'une des étiquettes suivantes :
0 – T-shirt/haut
1 – Pantalon
2 – Pull
3 – Habillez-vous
4 – Manteau
5 – Sandale
6 – Chemise
7 – Basket
8 – Sac
9 – Bottines
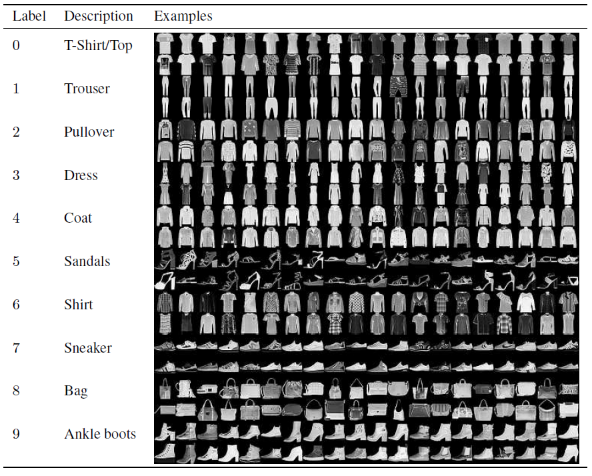
Source : Images de l'ensemble de données Fashion MNIST
Code de programme
Étape 1 - Importation des bibliothèques
La première étape pour créer un modèle d'apprentissage en profondeur consiste à importer les bibliothèques nécessaires au programme. Dans notre exemple, comme nous utilisons le framework TensorFlow, nous allons importer la bibliothèque Keras ainsi que d'autres bibliothèques importantes telles que le nombre pour le calcul et la matplotlib pour tracer les tracés.
#TensorFlow - Importation des bibliothèques
importer numpy en tant que np
importer matplotlib.pyplot en tant que plt
%matplotlib en ligne
importer tensorflow en tant que tf
de tensorflow importer Keras
Étape 2 - Obtenir et diviser l'ensemble de données
Une fois que nous avons importé les bibliothèques, l'étape suivante consiste à télécharger l'ensemble de données et à diviser l'ensemble de données Fashion MNIST en 60 000 données d'entraînement et 10 000 données de test respectives. Heureusement, keras nous fournit une fonction prédéfinie pour importer l'ensemble de données Fashion MNIST et nous pouvons les diviser dans la ligne suivante en utilisant une simple ligne de code qui est auto-comprise.
#TensorFlow - Obtenir et diviser l'ensemble de données
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
Étape 3 - Visualiser les données
Au fur et à mesure que l'ensemble de données est téléchargé avec les images et leurs étiquettes correspondantes, pour le rendre plus clair pour l'utilisateur, il est toujours conseillé de visualiser les données afin que nous puissions comprendre le type de données que nous traitons pour construire le Convolutional Neural Modèle de réseau en conséquence. Ici, avec ce simple bloc de code donné ci-dessous, nous allons visualiser les 3 premières images de l'ensemble de données d'apprentissage mélangées de manière aléatoire.
#TensorFlow – Visualiser les données
def imshowTensorFlow(img):
plt.imshow(img, cmap='gray')
print("Libellé :", img[0])
imshowTensorFlow(train_images_tf[0])
Étiquette : 9 Étiquette : 0 Étiquette : 3


L'image ci-dessus et leurs étiquettes peuvent être vérifiées avec les étiquettes qui sont données dans les détails de l'ensemble de données Fashion MNIST ci-dessus. Nous en déduisons que notre image de données est une image en niveaux de gris d'une hauteur de 28 pixels et d'une largeur de 28 pixels.
Par conséquent, le modèle peut être construit avec une taille d'entrée de (28,28,1), où 1 représente l'image en niveaux de gris.
Étape 4 - Construire le modèle
Comme mentionné ci-dessus, dans cet article, nous allons construire un simple réseau de neurones convolutionnels avec l'architecture LeNet. LeNet est une structure de réseau neuronal convolutif proposée par Yann LeCun et al. en 1989. En général, LeNet fait référence à LeNet-5 et est un simple réseau neuronal convolutif.
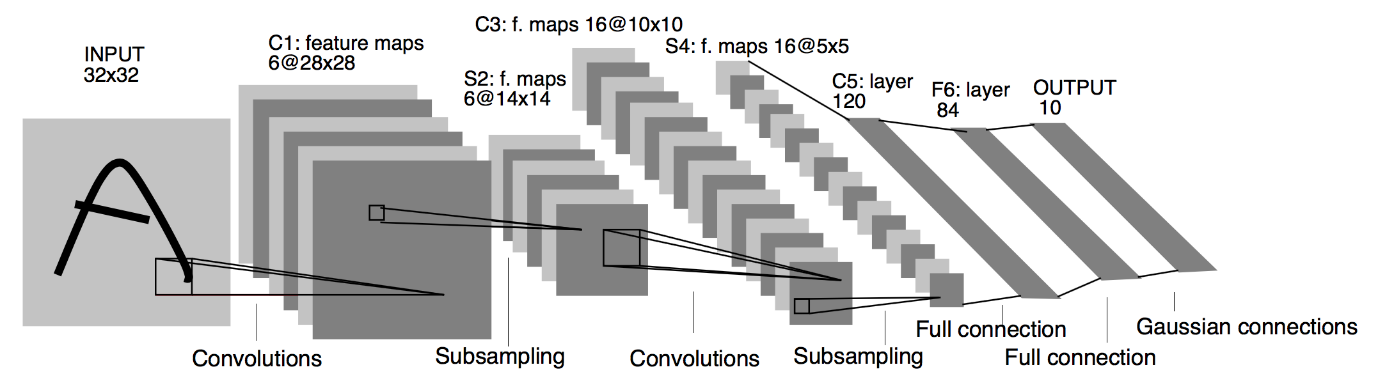
Source : L'architecture LeNet
D'après le diagramme d'architecture ci-dessus du modèle LeNet CNN, nous voyons qu'il y a 5 + 2 couches. Les première et deuxième couches sont une couche convolutive suivie d'une couche de mise en commun. Encore une fois, les troisième et quatrième couches consistent en une couche convolutive et une couche de mise en commun. À la suite de ces opérations, la taille de l'image d'entrée de 28×28 se réduit à 7×7.
La cinquième couche du modèle LeNet est la couche entièrement connectée qui aplatit la sortie de la couche précédente. Suivie de deux couches denses, la couche de sortie finale du modèle CNN consiste en une fonction d'activation Softmax avec 10 unités. La fonction Softmax prédit une probabilité de classe pour chacune des 10 classes de l'ensemble de données Fashion MNIST.
#TensorFlow - Construire le modèle
modèle = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1), filter=6, kernel_size=5, strides=1, padding=”same”, activation=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, foulées=2),
keras.layers.Conv2D(16, kernel_size=5, strides=1, padding=”same”, activation=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, foulées=2),
keras.layers.Flatten(),
keras.layers.Dense(120, activation=tf.nn.relu),
keras.layers.Dense(84, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
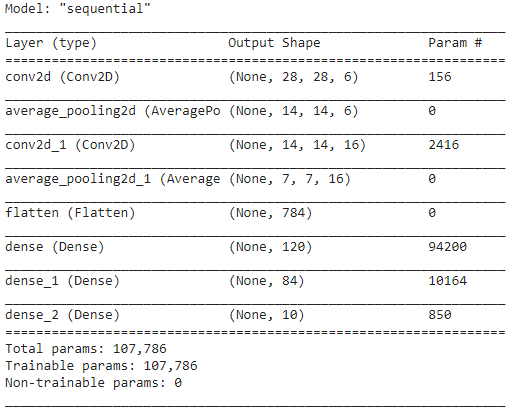
Étape 5 - Résumé du modèle
Une fois les couches du modèle LeNet finalisées, nous pouvons procéder à la compilation du modèle et visualiser une version résumée du modèle CNN conçu.
#TensorFlow - Résumé du modèle
model.compile(loss=keras.losses.categorical_crossentropy,
optimiseur='adam',
metrics=['acc'])
modèle. résumé ()
En cela, comme la sortie finale a plus de 2 classes (10 classes), nous utilisons l'entropie croisée catégorielle comme fonction de perte et l'Adam Optimizer pour notre modèle construit. Le résumé du modèle est donné ci-dessous.
Étape 6 - Formation du modèle
Enfin, nous arrivons à la partie où nous commençons le processus de formation du modèle LeNet CNN. Tout d'abord, nous remodelons l'ensemble de données d'apprentissage et le normalisons à des valeurs plus petites en divisant par 255,0 pour réduire le coût de calcul. Ensuite, les étiquettes d'apprentissage sont converties d'un vecteur de classe entier en une matrice de classe binaire. Par exemple, l'étiquette 3 est convertie en [0, 0, 0, 1, 0, 0, 0, 0, 0]
#TensorFlow - Entraînement du modèle
train_images_tensorflow = (train_images_tf / 255.0).reshape(train_images_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28 ,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
À la fin de l'entraînement après 30 époques, nous obtenons la précision et la perte d'entraînement finales comme,
Epoque 30/30
1875/1875 [==============================] – 4s 2ms/pas – perte : 0,0421 – acc : 0,9850
Précision de la formation : 98,294997215271 %
Perte d'entraînement : 0,04584110900759697
Étape 7 - Prédire les résultats
Enfin, une fois que nous aurons terminé notre processus de formation du modèle CNN, nous ajusterons le même modèle sur l'ensemble de données de test et prédirons la précision de 10 000 images de test.
#TensorFlow - Comparaison des résultats
prédictions = model.predict(test_images_tensorflow)
correct = 0
for i, pred in enumerate(predictions):
si np.argmax(pred) == test_labels_tf[i] :
correct += 1
print('Testez la précision du modèle sur les {} images de test : {}% avec TensorFlow'.format(test_images_tf.shape[0],100 * correct/test_images_tf.shape[0]))
La sortie que nous obtenons est,
Précision du test du modèle sur les 10000 images de test : 90,67 % avec TensorFlow
Avec cela, nous arrivons à la fin du programme sur la construction d'un modèle de classification d'images avec des réseaux de neurones convolutifs.
Lisez aussi : Idées de projets d'apprentissage automatique
Conclusion
Ainsi, dans ce tutoriel sur la mise en œuvre de la classification d'images dans CNN, nous avons compris les concepts de base derrière la classification d'images, les réseaux de neurones convolutifs ainsi que sa mise en œuvre dans le langage de programmation Python avec le framework TensorFlow.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le diplôme PG en apprentissage automatique et IA de IIIT-B & upGrad, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT- Statut B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Quel modèle CNN est considéré comme le plus optimal pour la classification des images ?
Le meilleur modèle CNN pour la classification des images est le VGG-16, qui signifie Very Deep Convolutional Networks for Large-Scale Image Recognition. VGG, qui a été conçu comme un CNN profond, surpasse les lignes de base sur un large éventail de tâches et d'ensembles de données en dehors d'ImageNet. La particularité du modèle est que lors de sa création, une plus grande attention a été accordée à l'incorporation d'excellentes couches de convolution plutôt qu'à l'ajout d'un grand nombre d'hyper paramètres. Il a un total de 16 couches, 5 blocs, et chaque bloc a une couche de mise en commun maximale, ce qui en fait un réseau assez vaste.
Quels sont les inconvénients de l'utilisation des modèles CNN pour la classification des images ?
En matière de classification d'images, les modèles CNN connaissent un grand succès. Cependant, l'utilisation de CNN présente plusieurs inconvénients. Si l'image à identifier est inclinée ou tournée, le modèle CNN a des problèmes pour identifier précisément l'image. Lorsque CNN visualise les images, il n'y a pas de représentations internes des composants et de leurs connexions partie-tout. De plus, si le modèle CNN à utiliser comprend de nombreuses couches convolutionnelles, le processus de classification prendra beaucoup de temps.
Pourquoi l'utilisation du modèle CNN est-elle préférée à l'ANN pour les données d'image en entrée ?
En combinant des filtres ou des transformations, CNN peut apprendre de nombreuses couches de représentations d'entités pour chaque image fournie en entrée. Le surajustement est diminué car le nombre de paramètres que le réseau doit apprendre dans CNN est considérablement plus petit que dans les réseaux de neurones multicouches. Lors de l'utilisation d'ANN, les réseaux de neurones peuvent apprendre une seule représentation caractéristique de l'image, mais, dans le cas d'images complexes, ANN ne parviendra pas à fournir des visualisations ou des classifications améliorées car il ne peut pas apprendre les dépendances de pixels existant dans les images d'entrée.