
Comment implémenter la classification dans l'apprentissage automatique ?
Publié: 2021-03-12L'application de l'apprentissage automatique dans divers domaines a augmenté à pas de géant au cours des dernières années, et continue de le faire. L'une des tâches les plus populaires du modèle d'apprentissage automatique consiste à reconnaître des objets et à les séparer dans leurs classes désignées.
C'est la méthode de classification qui est l'une des applications les plus populaires de l'apprentissage automatique. La classification est utilisée pour séparer une énorme quantité de données en un ensemble de valeurs discrètes qui peuvent être binaires telles que 0/1, Oui/Non, ou multi-classes telles que les animaux, les voitures, les oiseaux, etc.
Dans l'article suivant, nous comprendrons le concept de classification dans l'apprentissage automatique, les types de données impliquées et verrons certains des algorithmes de classification les plus populaires utilisés dans l'apprentissage automatique pour classer plusieurs données.
Table des matières
Qu'est-ce que l'apprentissage supervisé ?
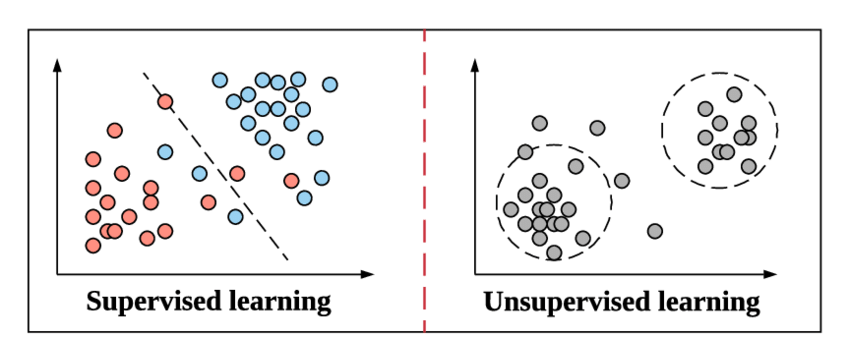
Alors que nous nous préparons à plonger dans le concept de classification et ses types, rafraîchissons-nous rapidement avec ce que l'on entend par apprentissage supervisé et en quoi il diffère de l'autre méthode d'apprentissage non supervisé dans l'apprentissage automatique.
Comprenons cela en prenant un exemple simple tiré de notre cours de physique au lycée. Supposons qu'il y ait un problème simple impliquant une nouvelle méthode. Si on nous présente une question que nous devons résoudre en utilisant la même méthode, ne devrions-nous pas tous nous référer à un exemple de problème avec la même méthode et essayer de le résoudre. Une fois que nous sommes confiants avec cette méthode, nous n'avons pas besoin de nous y référer à nouveau et de continuer à la résoudre.
La source

C'est de la même manière que l'apprentissage supervisé fonctionne dans l'apprentissage automatique. Il apprend par l'exemple. Pour le garder encore plus simple, dans l'apprentissage supervisé, toutes les données sont alimentées avec leurs étiquettes correspondantes et donc pendant le processus de formation, le modèle d'apprentissage automatique compare sa sortie pour une donnée particulière avec la vraie sortie de ces mêmes données et essaie de minimiser l'erreur entre la valeur d'étiquette prédite et réelle.
Les algorithmes de classification que nous allons aborder dans cet article suivent cette méthode d'apprentissage supervisé, par exemple, la détection de spam et la reconnaissance d'objets.
L'apprentissage non supervisé est une étape au-dessus dans laquelle les données ne sont pas alimentées avec leurs étiquettes. Il appartient à la responsabilité et à l'efficacité du modèle d'apprentissage automatique de dériver des modèles à partir des données et de donner le résultat. Les algorithmes de clustering suivent cette méthode d'apprentissage non supervisée.
Qu'est-ce que le Classement ?
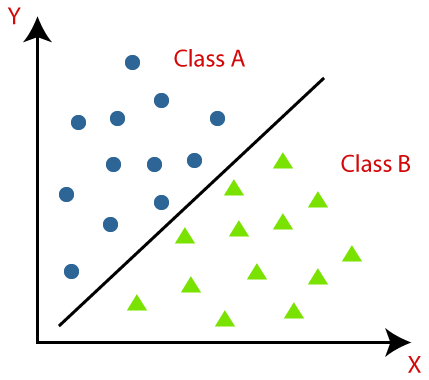
La classification est définie comme la reconnaissance, la compréhension et le regroupement des objets ou des données dans des classes prédéfinies. En catégorisant les données avant le processus de formation du modèle Machine Learning, nous pouvons utiliser divers algorithmes de classification pour classer les données en plusieurs classes. Contrairement à la régression, un problème de classification se produit lorsque la variable de sortie est une catégorie, telle que « Oui » ou « Non » ou « Maladie » ou « Pas de maladie ».
Dans la plupart des problèmes d'apprentissage automatique, une fois que l'ensemble de données est chargé dans le programme, avant l'entraînement, divisez l'ensemble de données en un ensemble d'apprentissage et un ensemble de test avec un rapport fixe (généralement 70 % d'ensemble d'entraînement et 30 % d'ensemble de test). Ce processus de division permet au modèle d'effectuer une rétropropagation dans laquelle il tente de corriger son erreur de la valeur prédite par rapport à la valeur réelle par plusieurs approximations mathématiques.
De même, avant de commencer la classification, l'ensemble de données d'entraînement est créé. L'algorithme de classification subit une formation sur celui-ci lors des tests sur l'ensemble de données de test à chaque itération, appelée époque.
La source
L'une des applications d'algorithmes de classification les plus courantes consiste à filtrer les e-mails pour déterminer s'ils sont « spam » ou « non-spam ». En bref, nous pouvons définir la classification dans l'apprentissage automatique comme une forme de "reconnaissance de modèles" dans laquelle ces algorithmes appliqués aux données d'apprentissage sont utilisés pour extraire plusieurs modèles des données (tels que des mots ou des séquences de chiffres similaires, des sentiments, etc. .).
La classification est un processus de catégorisation d'un ensemble donné de données en classes ; elle peut être effectuée sur des données structurées ou non structurées. Il commence par prédire la classe des points de données donnés. Ces classes sont également appelées variables de sortie, étiquettes cibles, etc. Plusieurs algorithmes ont des fonctions mathématiques intégrées pour approximer la fonction de mappage des variables de point de données d'entrée à la classe cible de sortie. L'objectif principal de la classification est d'identifier dans quelle classe/catégorie les nouvelles données tomberont.
Types d'algorithmes de classification dans l'apprentissage automatique
Selon le type de données sur lesquelles les algorithmes de classification sont appliqués, il existe deux grandes catégories d'algorithmes, les modèles linéaires et non linéaires.
Modèles linéaires
- Régression logistique
- Machines à vecteurs de support (SVM)
Modèles non linéaires
- Classification K-plus proches voisins (KNN)
- SVM du noyau
- Classification naïve de Bayes
- Classification de l'arbre de décision
- Classification aléatoire des forêts
Dans cet article, nous allons brièvement passer en revue le concept derrière chacun des algorithmes mentionnés ci-dessus.
Évaluation d'un modèle de classification en apprentissage automatique
Avant de nous lancer dans les concepts de ces algorithmes mentionnés ci-dessus, nous devons comprendre comment nous pouvons évaluer notre modèle d'apprentissage automatique construit au-dessus de ces algorithmes. Il est essentiel d'évaluer la précision de notre modèle à la fois sur l'ensemble d'apprentissage et sur l'ensemble de test.
Perte d'entropie croisée ou perte de journal
Il s'agit du premier type de fonction de perte que nous utiliserons pour évaluer les performances d'un classificateur dont la sortie est comprise entre 0 et 1. Ceci est principalement utilisé pour les modèles de classification binaire. La formule Log Loss est donnée par,
Log Loss = -((1 – y) * log(1 – yhat) + y * log(yhat))
Où c'est la valeur prédite, et y est la valeur réelle.
Matrice de confusion
Une matrice de confusion est une matrice NXN, où N est le nombre de classes prédites. La matrice de confusion nous fournit une matrice/table en sortie et décrit les performances du modèle. Il se compose du résultat des prédictions sous la forme d'une matrice à partir de laquelle nous pouvons dériver plusieurs mesures de performance pour évaluer le modèle de classification. Il est de la forme,
| Positif réel | Réel négatif | |
| Prédit positif | Vrai positif | Faux positif |
| Prédit négatif | Faux négatif | Vrai négatif |
Quelques-unes des mesures de performance qui peuvent être dérivées du tableau ci-dessus sont données ci-dessous.
1. Précision - la proportion du nombre total de prédictions correctes.
2. Valeur prédictive positive ou précision - la proportion de cas positifs correctement identifiés.
3. Valeur prédictive négative - la proportion de cas négatifs correctement identifiés.
4. Sensibilité ou rappel - la proportion de cas positifs réels qui sont correctement identifiés.
5. Spécificité – la proportion de cas négatifs réels qui sont correctement identifiés.
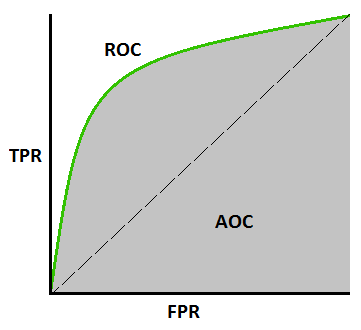
Courbe AUC-ROC –
Il s'agit d'une autre mesure de courbe importante qui évalue tout modèle d'apprentissage automatique. La courbe ROC correspond à la courbe des caractéristiques de fonctionnement du récepteur et AUC correspond à la zone sous la courbe. La courbe ROC est tracée avec TPR et FPR, où TPR (True Positive Rate) sur l'axe Y et FPR (False Positive Rate) sur l'axe X. Il montre les performances du modèle de classification à différents seuils.
La source
1. Régression logistique
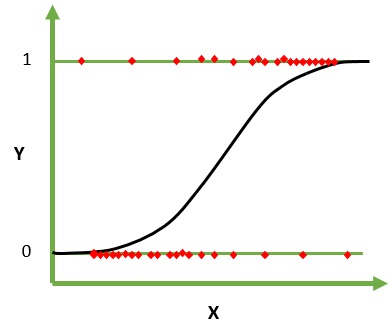
La régression logistique est un algorithme d'apprentissage automatique pour la classification. Dans cet algorithme, les probabilités décrivant les résultats possibles d'un seul essai sont modélisées à l'aide d'une fonction logistique. Il suppose que les variables d'entrée sont numériques et ont une distribution gaussienne (courbe en cloche).
La fonction logistique, également appelée fonction sigmoïde, a été initialement utilisée par les statisticiens pour décrire la croissance démographique en écologie. La fonction sigmoïde est une fonction mathématique utilisée pour mapper les valeurs prédites aux probabilités. La régression logistique a une courbe en forme de S et peut prendre des valeurs comprises entre 0 et 1 mais jamais exactement à ces limites.

La source
La régression logistique est principalement utilisée pour prédire un résultat binaire tel que Oui/Non et Réussite/Échec. Les variables indépendantes peuvent être catégorielles ou numériques, mais la variable dépendante est toujours catégorique. La formule de régression logistique est donnée par,
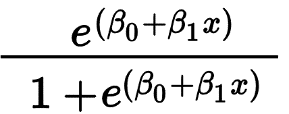
Où e représente la courbe en forme de S qui a des valeurs comprises entre 0 et 1.
2. Soutenir les machines vectorielles
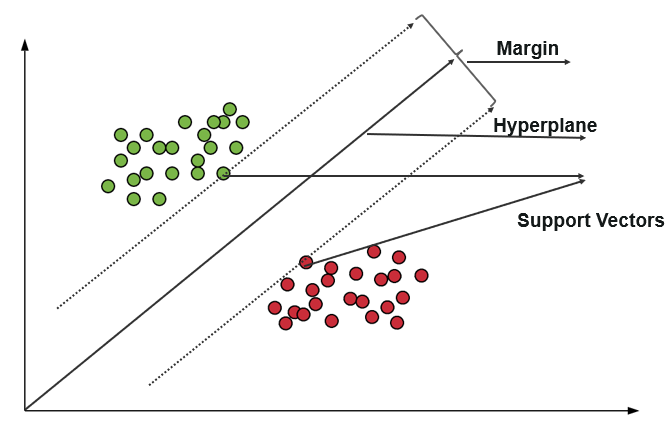
Une machine à vecteurs de support (SVM) utilise des algorithmes pour former et classer les données selon des degrés de polarité, les amenant à un degré au-delà de la prédiction X/Y. Dans SVM, la ligne utilisée pour séparer les classes est appelée Hyperplane. Les points de données de chaque côté de l'hyperplan les plus proches de l'hyperplan sont appelés vecteurs de support utilisés pour tracer la ligne de démarcation.
Cette machine à vecteur de support dans la classification représente les données d'entraînement sous forme de points de données dans un espace dans lequel de nombreuses catégories sont séparées dans les catégories Hyperplane. Lorsqu'un nouveau point entre, il est classé en prédisant dans quelle catégorie il tombe et appartient à un espace particulier.
La source
L'objectif principal de la machine à vecteurs de support est de maximiser la marge entre les deux vecteurs de support.
Rejoignez le cours ML en ligne des meilleures universités du monde - Masters, Executive Post Graduate Programs et Advanced Certificate Program in ML & AI pour accélérer votre carrière.
3. Classification K-plus proches voisins (KNN)
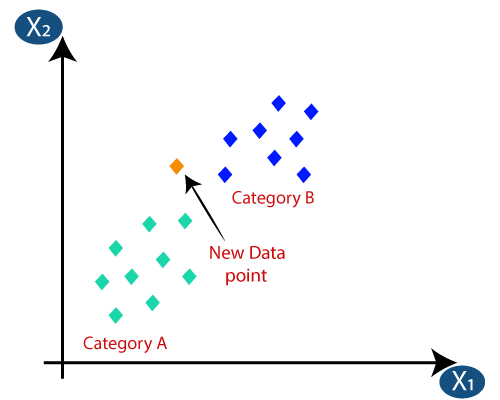
La classification KNN est l'un des algorithmes de classification les plus simples, mais elle est très utilisée en raison de sa grande efficacité et de sa facilité d'utilisation. Dans cette méthode, l'ensemble de données complet est initialement stocké dans la machine. Ensuite, une valeur – k est choisie, qui représente le nombre de voisins. De cette façon, lorsqu'un nouveau point de données est ajouté à l'ensemble de données, il prend le vote majoritaire des k étiquettes de classe des plus proches voisins de ce nouveau point de données. Avec ce vote, le nouveau point de données est ajouté à cette classe particulière avec le vote le plus élevé.
La source
4. SVM du noyau
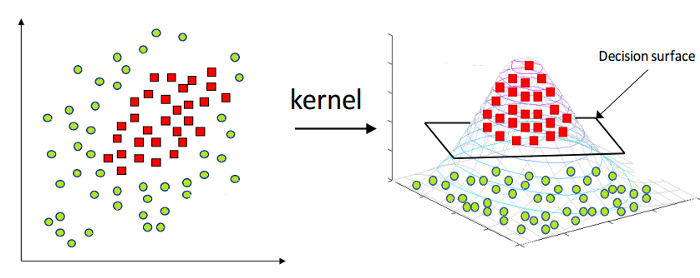
Comme mentionné ci-dessus, la machine à vecteurs de support linéaire ne peut être appliquée qu'aux seules données de nature linéaire. Cependant, toutes les données du monde ne sont pas linéairement séparables. Par conséquent, nous devons développer une machine à vecteurs de support pour tenir compte des données qui sont également séparables de manière non linéaire. Voici l'astuce du noyau, également connue sous le nom de Kernel Support Vector Machine ou Kernel SVM.
Dans Kernel SVM, nous sélectionnons un noyau tel que le RBF ou le noyau gaussien. Tous les points de données sont mappés à une dimension supérieure, où ils deviennent linéairement séparables. De cette manière, nous pouvons créer une frontière de décision entre les différentes classes du jeu de données.
La source
Par conséquent, de cette manière, en utilisant les concepts de base des machines à vecteurs de support, nous pouvons concevoir un noyau SVM pour non linéaire.
5. Classification naïve de Bayes
La classification naïve de Bayes a ses racines dans le théorème de Bayes, en supposant que toutes les variables indépendantes (caractéristiques) de l'ensemble de données sont indépendantes. Ils ont une importance égale dans la prédiction du résultat. Cette hypothèse du théorème de Bayes donne le nom de "naïf". Il est utilisé pour diverses tâches, telles que le filtrage du spam et d'autres domaines de la classification de texte. Naive Bayes calcule la possibilité qu'un point de données appartienne ou non à une certaine catégorie.
La formule de la classification naïve de Bayes est donnée par,
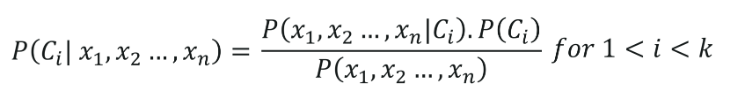
6. Classification de l'arbre de décision
Un arbre de décision est un algorithme d'apprentissage supervisé qui est parfait pour les problèmes de classification, car il peut ordonner les classes à un niveau précis. Il fonctionne sous la forme d'un organigramme où il sépare les points de données à chaque niveau. La structure finale ressemble à un arbre avec des nœuds et des feuilles.

La source
Un nœud de décision aura deux branches ou plus, et une feuille représente une classification ou une décision. Dans l'exemple ci-dessus d'un arbre de décision, en posant plusieurs questions, un organigramme est créé, ce qui nous aide à résoudre le problème simple de prédire s'il faut aller au marché ou non.
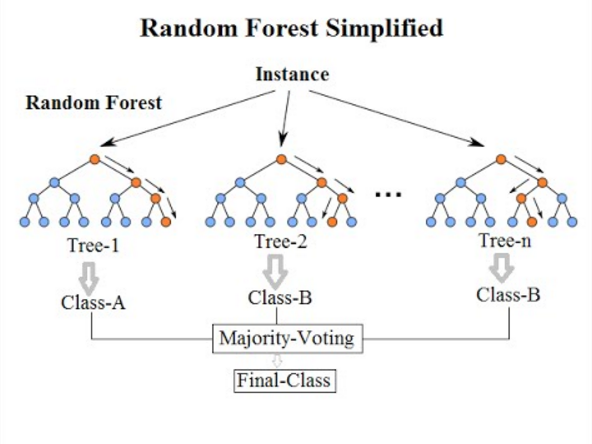
7. Classification aléatoire des forêts
Pour en venir au dernier algorithme de classification de cette liste, la forêt aléatoire n'est qu'une extension de l'algorithme d'arbre de décision. Une forêt aléatoire est une méthode d'apprentissage d'ensemble avec plusieurs arbres de décision. Il fonctionne de la même manière que celui des arbres de décision.
La source
L'algorithme de forêt aléatoire est une avancée de l'algorithme d'arbre de décision existant, qui souffre d'un problème majeur de « surajustement ». Il est également considéré comme plus rapide et plus précis par rapport à l'algorithme d'arbre de décision.
Lisez aussi : Idées et sujets de projets d'apprentissage automatique
Conclusion
Ainsi, dans cet article sur les méthodes d'apprentissage automatique pour la classification, nous avons compris les bases de la classification et de l'apprentissage supervisé, les types et les métriques d'évaluation des modèles de classification et enfin, un résumé de tous les modèles de classification les plus couramment utilisés. Machine Learning.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le programme Executive PG d'IIIT-B & upGrad en apprentissage automatique et IA , conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT -B Statut d'anciens élèves, 5+ projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Q1. Quels algorithmes sont les plus utilisés en machine learning ?
L'apprentissage automatique utilise de nombreux algorithmes différents, qui peuvent être classés en trois grandes catégories : les algorithmes d'apprentissage supervisé, les algorithmes d'apprentissage non supervisé et les algorithmes d'apprentissage par renforcement. Maintenant, pour affiner et nommer certains des algorithmes les plus couramment utilisés, ceux qui doivent être mentionnés sont la régression linéaire, la régression logistique, SVM, les arbres de décision, l'algorithme de forêt aléatoire, kNN, la théorie de Naive Bayes, K-Means, la réduction de dimensionnalité, et des algorithmes d'amplification de gradient. Les algorithmes XGBoost, GBM, LightGBM et CatBoost méritent une mention spéciale dans les algorithmes d'amplification de gradient. Ces algorithmes peuvent être appliqués pour résoudre presque tous les types de problèmes de données.
Q2. Qu'est-ce que la classification et la régression dans l'apprentissage automatique ?
Les algorithmes de classification et de régression sont largement utilisés dans l'apprentissage automatique. Cependant, il existe de nombreuses différences entre eux, qui déterminent en fin de compte leur utilisation ou leur objectif. La principale différence est que, tandis que les algorithmes de classification sont utilisés pour classer ou prédire des valeurs discrètes telles que homme-femme ou vrai-faux, les algorithmes de régression sont utilisés pour prévoir des valeurs continues non discrètes telles que le salaire, l'âge, le prix, etc. Arbres de décision, la forêt aléatoire, le Kernel SVM et la régression logistique sont parmi les algorithmes de classification les plus courants, tandis que la régression linéaire simple et multiple, la régression vectorielle de support, la régression polynomiale et la régression par arbre de décision sont parmi les algorithmes de régression les plus populaires utilisés dans l'apprentissage automatique.
Q3. Quels sont les prérequis pour apprendre le machine learning ?
Pour commencer avec l'apprentissage automatique, vous n'avez pas besoin d'être un mathématicien compétent ou un programmeur expert. Cependant, étant donné l'immensité du domaine, cela peut sembler intimidant lorsque vous êtes sur le point de commencer votre parcours d'apprentissage automatique. Dans de tels cas, connaître les conditions préalables peut vous aider à démarrer en douceur. Les prérequis sont essentiellement les compétences de base que vous devez acquérir pour comprendre les concepts d'apprentissage automatique. Donc, avant tout, assurez-vous d'apprendre à coder avec Python. Ensuite, une compréhension de base des statistiques et des mathématiques, en particulier de l'algèbre linéaire et du calcul multivariable, sera un avantage supplémentaire.