
Comment choisir une méthode de sélection de fonctionnalités pour l'apprentissage automatique
Publié: 2021-06-22Table des matières
Présentation de la sélection des fonctionnalités
De nombreuses fonctionnalités sont utilisées par un modèle d'apprentissage automatique, dont seules quelques-unes sont importantes. La précision du modèle est réduite si des fonctionnalités inutiles sont utilisées pour former un modèle de données. De plus, il y a une augmentation de la complexité du modèle et une diminution de la capacité de généralisation résultant en un modèle biaisé. Le dicton "parfois moins c'est mieux" va bien avec le concept d'apprentissage automatique. Le problème a été rencontré par de nombreux utilisateurs où ils ont du mal à identifier l'ensemble de fonctionnalités pertinentes à partir de leurs données et à ignorer tous les ensembles de fonctionnalités non pertinentes. Les caractéristiques les moins importantes sont nommées de manière à ne pas contribuer à la variable cible.
Par conséquent, l'un des processus importants est la sélection de fonctionnalités dans l'apprentissage automatique . L'objectif est de sélectionner le meilleur ensemble de fonctionnalités possible pour le développement d'un modèle d'apprentissage automatique. La sélection des fonctionnalités a un impact énorme sur les performances du modèle. Parallèlement au nettoyage des données, la sélection des fonctionnalités doit être la première étape de la conception d'un modèle.
La sélection des fonctionnalités dans Machine Learning peut être résumée comme suit
- Sélection automatique ou manuelle des caractéristiques qui contribuent le plus à la variable de prédiction ou à la sortie.
- La présence de caractéristiques non pertinentes peut entraîner une diminution de la précision du modèle car il apprendra à partir de caractéristiques non pertinentes.
Avantages de la sélection des fonctionnalités
- Réduit le surajustement des données : un nombre inférieur de données entraîne une moindre redondance. Par conséquent, il y a moins de chances de prendre des décisions sur le bruit.
- Améliore la précision du modèle : avec moins de risques de données trompeuses, la précision du modèle est augmentée.
- Le temps de formation est réduit : la suppression des fonctionnalités non pertinentes réduit la complexité de l'algorithme car seuls moins de points de données sont présents. Par conséquent, les algorithmes s'entraînent plus rapidement.
- La complexité du modèle est réduite avec une meilleure interprétation des données.
Méthodes supervisées et non supervisées de sélection de fonctionnalités
L'objectif principal des algorithmes de sélection de caractéristiques est de sélectionner un ensemble de meilleures caractéristiques pour le développement du modèle. Les méthodes de sélection de caractéristiques dans l'apprentissage automatique peuvent être classées en méthodes supervisées et non supervisées.
- Méthode supervisée : la méthode supervisée est utilisée pour la sélection de caractéristiques à partir de données étiquetées et également utilisée pour la classification des caractéristiques pertinentes. Par conséquent, il y a une efficacité accrue des modèles qui sont construits.
- Méthode non supervisée : cette méthode de sélection des caractéristiques est utilisée pour les données non étiquetées.
Liste des méthodes sous méthodes supervisées
Les méthodes supervisées de sélection de caractéristiques dans l'apprentissage automatique peuvent être classées en

1. Méthodes d'emballage
Ce type d' algorithme de sélection de caractéristiques évalue le processus de performance des caractéristiques sur la base des résultats de l'algorithme. Également connu sous le nom d'algorithme glouton, il forme l'algorithme en utilisant un sous-ensemble de fonctionnalités de manière itérative. Les critères d'arrêt sont généralement définis par la personne qui entraîne l'algorithme. L'ajout et la suppression d'entités dans le modèle s'effectuent en fonction de la formation préalable du modèle. Tout type d'algorithme d'apprentissage peut être appliqué dans cette stratégie de recherche. Les modèles sont plus précis que les méthodes de filtrage.
Les techniques utilisées dans les méthodes Wrapper sont :
- Sélection vers l' avant : le processus de sélection vers l'avant est un processus itératif dans lequel de nouvelles fonctionnalités qui améliorent le modèle sont ajoutées après chaque itération. Cela commence avec un ensemble vide de fonctionnalités. L'itération continue et s'arrête jusqu'à ce qu'une fonctionnalité soit ajoutée qui n'améliore pas davantage les performances du modèle.
- Sélection/élimination en amont : le processus est un processus itératif qui commence par toutes les fonctionnalités. Après chaque itération, les caractéristiques les moins significatives sont retirées de l'ensemble des caractéristiques initiales. Le critère d'arrêt de l'itération est lorsque les performances du modèle ne s'améliorent plus avec la suppression de la fonctionnalité. Ces algorithmes sont implémentés dans le package mlxtend.
- Élimination bidirectionnelle : les deux méthodes de sélection vers l'avant et la technique d'élimination vers l'arrière sont appliquées simultanément dans la méthode d'élimination bidirectionnelle pour atteindre une solution unique.
- Sélection exhaustive des fonctionnalités : elle est également connue sous le nom d'approche par force brute pour l'évaluation des sous-ensembles de fonctionnalités. Un ensemble de sous-ensembles possibles est créé et un algorithme d'apprentissage est construit pour chaque sous-ensemble. Ce sous-ensemble est choisi dont le modèle donne les meilleures performances.
- Élimination récursive des caractéristiques (RFE) : la méthode est qualifiée de gourmande car elle sélectionne les caractéristiques en considérant de manière récursive l'ensemble de caractéristiques de plus en plus petit. Un ensemble initial de caractéristiques est utilisé pour former l'estimateur et leur importance est obtenue à l'aide de feature_importance_attribute. Il est ensuite suivi de la suppression des fonctionnalités les moins importantes, ne laissant que le nombre requis de fonctionnalités. Les algorithmes sont implémentés dans le package scikit-learn.
Figure 4 : Exemple de code montrant la technique d'élimination des caractéristiques récursives
2. Méthodes embarquées
Les méthodes de sélection de caractéristiques intégrées dans l'apprentissage automatique présentent un certain avantage par rapport aux méthodes de filtrage et d'encapsulation en incluant l'interaction des caractéristiques et en maintenant également un coût de calcul raisonnable. Les techniques utilisées dans les méthodes embarquées sont :
- Régularisation : Le surajustement des données est évité par le modèle en ajoutant une pénalité aux paramètres du modèle. Des coefficients sont ajoutés avec la pénalité qui fait que certains coefficients sont nuls. Par conséquent, les entités qui ont un coefficient nul sont supprimées de l'ensemble d'entités. L'approche de sélection des caractéristiques utilise Lasso (régularisation L1) et les filets élastiques (régularisation L1 et L2).
- SMLR (Sparse Multinomial Logistic Regression) : L'algorithme implémente une régularisation parcimonieuse par ARD a priori (Détermination automatique de la pertinence) pour la régression logistique multinationale classique. Cette régularisation estime l'importance de chaque caractéristique et élague les dimensions qui ne sont pas utiles pour la prédiction. L'implémentation de l'algorithme se fait dans SMLR.
- ARD (Automatic Relevance Determination Regression) : l'algorithme déplace les coefficients de pondération vers zéro et est basé sur une régression bayésienne de la crête. L'algorithme peut être implémenté dans scikit-learn.
- Importance de la forêt aléatoire : cet algorithme de sélection de caractéristiques est une agrégation d'un nombre spécifié d'arbres. Les stratégies basées sur les arbres dans cet algorithme se classent sur la base de l'augmentation de l'impureté d'un nœud ou de la diminution de l'impureté (impureté de Gini). La fin des arbres est constituée des nœuds avec la plus faible diminution d'impureté et le début des arbres est constitué des nœuds avec la plus grande diminution d'impureté. Par conséquent, des fonctionnalités importantes peuvent être sélectionnées en élaguant l'arbre sous un nœud particulier.
3. Méthodes de filtrage
Les méthodes sont appliquées au cours des étapes de prétraitement. Les méthodes sont assez rapides et peu coûteuses et fonctionnent mieux pour supprimer les fonctionnalités dupliquées, corrélées et redondantes. Au lieu d'appliquer des méthodes d'apprentissage supervisé, l'importance des fonctionnalités est évaluée en fonction de leurs caractéristiques inhérentes. Le coût de calcul de l'algorithme est moindre par rapport aux méthodes wrapper de sélection de caractéristiques. Cependant, si suffisamment de données ne sont pas présentes pour dériver la corrélation statistique entre les caractéristiques, les résultats peuvent être pires que les méthodes wrapper. Par conséquent, les algorithmes sont utilisés sur des données de grande dimension, ce qui entraînerait un coût de calcul plus élevé si des méthodes d'encapsulation devaient être appliquées.

Les techniques utilisées dans les méthodes Filter sont :
- Gain d'informations : le gain d'informations fait référence à la quantité d'informations obtenues à partir des caractéristiques pour identifier la valeur cible. Il mesure ensuite la réduction des valeurs d'entropie. Le gain d'informations de chaque attribut est calculé en tenant compte des valeurs cibles pour la sélection des fonctionnalités.
- Test du chi carré : La méthode du chi carré (X 2 ) est généralement utilisée pour tester la relation entre deux variables catégorielles. Le test est utilisé pour identifier s'il existe une différence significative entre les valeurs observées de différents attributs de l'ensemble de données et sa valeur attendue. Une hypothèse nulle indique qu'il n'y a pas d'association entre deux variables.
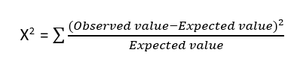
La source
La formule du test du chi carré
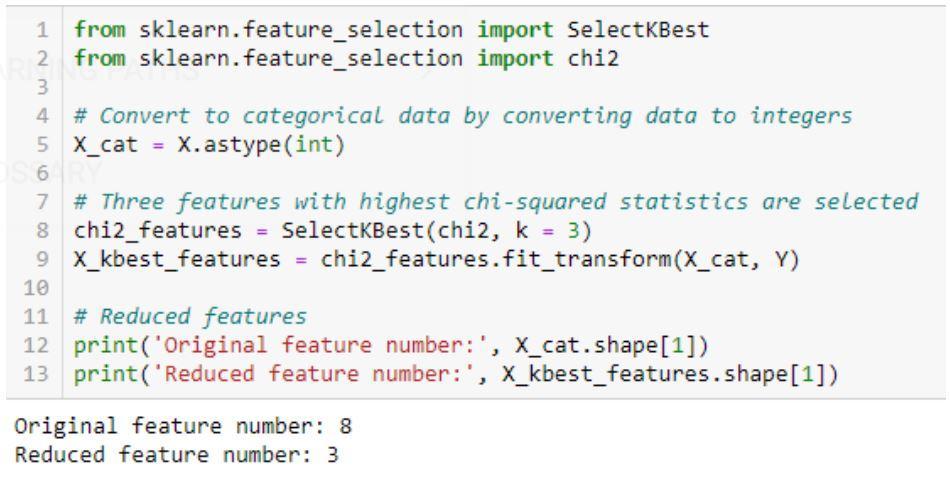
Implémentation de l'algorithme Chi-Squared : sklearn, scipy
Un exemple de code pour le test Chi-carré
La source
- CFS (Correlation-based feature selection) : La méthode suit « Implémentation de CFS (Correlation-based feature selection): scikit-feature
Rejoignez les cours AI & ML en ligne des meilleures universités du monde - Masters, Executive Post Graduate Programs et Advanced Certificate Program in ML & AI pour accélérer votre carrière.
- FCBF (filtre basé sur la corrélation rapide) : par rapport aux méthodes mentionnées ci-dessus de Relief et CFS, la méthode FCBF est plus rapide et plus efficace. Initialement, le calcul de l'incertitude symétrique est effectué pour toutes les caractéristiques. À l'aide de ces critères, les fonctionnalités sont ensuite triées et les fonctionnalités redondantes sont supprimées.
Incertitude symétrique = le gain d'information de x | y divisé par la somme de leurs entropies. Mise en place du FCBF : skfeature
- Score de Fischer : le ratio de Fischer (FIR) est défini comme la distance entre les moyennes d'échantillon pour chaque classe par caractéristique divisée par leurs variances. Chaque caractéristique est sélectionnée indépendamment en fonction de ses scores selon le critère de Fisher. Cela conduit à un ensemble de fonctionnalités sous-optimal. Un score de Fisher plus élevé indique une caractéristique mieux sélectionnée.
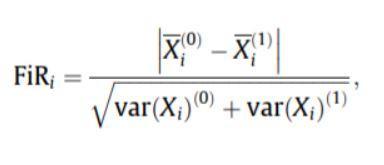
La source
La formule du score de Fischer
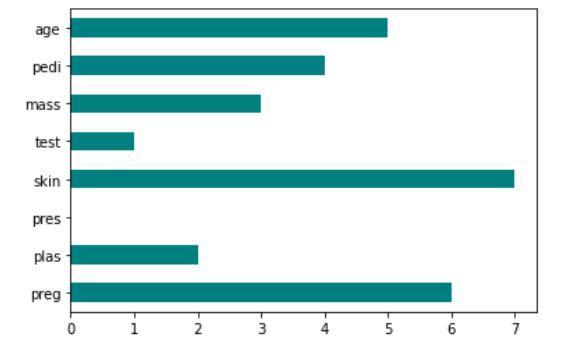
Implémentation du score de Fisher : scikit-feature
La sortie du code montrant la technique du score de Fisher
La source
Coefficient de corrélation de Pearson : Il s'agit d'une mesure de quantification de l'association entre les deux variables continues. Les valeurs du coefficient de corrélation vont de -1 à 1 ce qui définit le sens de la relation entre les variables.
- Seuil de variance : les entités dont la variance n'atteint pas le seuil spécifique sont supprimées. Les caractéristiques ayant une variance nulle sont supprimées par cette méthode. L'hypothèse considérée est que les caractéristiques de variance plus élevée sont susceptibles de contenir plus d'informations.
Figure 15 : Exemple de code montrant la mise en œuvre du seuil de variance
- Différence moyenne absolue (MAD) : La méthode calcule la moyenne absolue
différence par rapport à la valeur moyenne.
Un exemple de code et sa sortie montrant l'implémentation de la différence absolue moyenne (MAD)
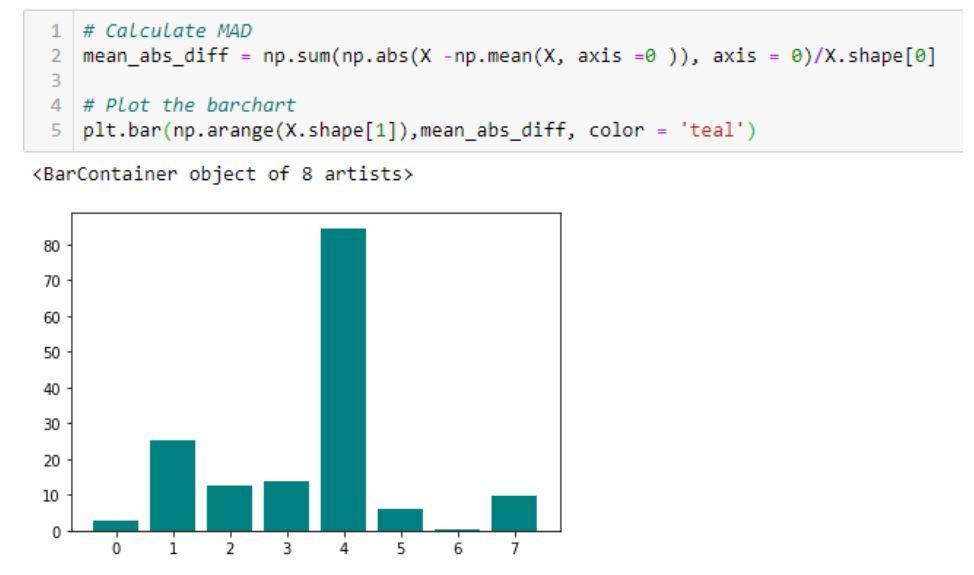
La source
- Taux de dispersion : Le taux de dispersion est défini comme le rapport de la moyenne arithmétique (AM) à celle de la moyenne géométrique (GM) pour une caractéristique donnée. Sa valeur varie de +1 à ∞ lorsque AM ≥ GM pour une caractéristique donnée.
Un taux de dispersion plus élevé implique une valeur de Ri plus élevée et donc une caractéristique plus pertinente. A l'inverse, lorsque Ri est proche de 1, cela indique une caractéristique de faible pertinence.
- Dépendance mutuelle : La méthode est utilisée pour mesurer la dépendance mutuelle entre deux variables. Les informations obtenues à partir d'une variable peuvent être utilisées pour obtenir des informations pour l'autre variable.
- Score laplacien : les données d'une même classe sont souvent proches les unes des autres. L'importance d'une caractéristique peut être évaluée par son pouvoir de préservation de la localité. Le score laplacien pour chaque caractéristique est calculé. Les plus petites valeurs déterminent les dimensions importantes. Implémentation du score laplacien : scikit-feature.
Conclusion
La sélection des fonctionnalités dans le processus d'apprentissage automatique peut être résumée comme l'une des étapes importantes vers le développement de tout modèle d'apprentissage automatique. Le processus de l'algorithme de sélection des caractéristiques conduit à la réduction de la dimensionnalité des données avec la suppression des caractéristiques qui ne sont pas pertinentes ou importantes pour le modèle considéré. Des fonctionnalités pertinentes pourraient accélérer le temps de formation des modèles, ce qui se traduirait par des performances élevées.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le programme Executive PG d'IIIT-B & upGrad en apprentissage automatique et IA, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT -B Statut d'anciens élèves, 5+ projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
En quoi la méthode du filtre est-elle différente de la méthode du wrapper ?
La méthode wrapper permet de mesurer l'utilité des fonctionnalités en fonction des performances du classifieur. La méthode du filtre, quant à elle, évalue les qualités intrinsèques des caractéristiques à l'aide de statistiques univariées plutôt que de performances de validation croisée, ce qui implique qu'elles jugent de la pertinence des caractéristiques. Par conséquent, la méthode wrapper est plus efficace car elle optimise les performances du classifieur. Cependant, en raison des processus d'apprentissage répétés et de la validation croisée, la technique du wrapper est plus coûteuse en calcul que la méthode du filtre.
Qu'est-ce que la sélection directe séquentielle dans l'apprentissage automatique ?
C'est une sorte de sélection séquentielle de fonctionnalités, bien que ce soit beaucoup plus coûteux que la sélection de filtres. Il s'agit d'une technique de recherche gourmande qui sélectionne de manière itérative les fonctionnalités en fonction des performances du classifieur afin de découvrir le sous-ensemble de fonctionnalités idéal. Il commence par un sous-ensemble de fonctionnalités vide et continue d'ajouter une fonctionnalité à chaque tour. Cette fonctionnalité est choisie parmi un ensemble de toutes les fonctionnalités qui ne sont pas dans notre sous-ensemble de fonctionnalités, et c'est celle qui donne les meilleures performances de classificateur lorsqu'elle est combinée avec les autres.
Quelles sont les limites de l'utilisation de la méthode de filtrage pour la sélection des fonctionnalités ?
L'approche par filtre est moins coûteuse en termes de calcul que les méthodes de sélection d'éléments wrapper et intégrés, mais elle présente certains inconvénients. Dans le cas des approches univariées, cette stratégie ignore fréquemment l'interdépendance des caractéristiques lors de la sélection des caractéristiques et évalue chaque caractéristique indépendamment. Par rapport aux deux autres méthodes de sélection de fonctionnalités, cela peut parfois entraîner de mauvaises performances de calcul.