
Comment mon site Web piloté par API m'aide à parcourir le monde
Publié: 2022-03-10(Ceci est un article sponsorisé.) Récemment, j'ai décidé de reconstruire mon site Web personnel, car il avait six ans et avait l'air - poliment parlant - un peu "obsolète". L'objectif était d'inclure des informations sur moi-même, un blog, une liste de mes projets parallèles récents et des événements à venir.
Comme je travaille de temps en temps avec des clients, il y avait une chose dont je ne voulais pas m'occuper : les bases de données ! Auparavant, je construisais des sites WordPress pour tous ceux qui le voulaient. La partie programmation était généralement amusante pour moi, mais les versions, le déplacement des bases de données vers différents environnements et la publication proprement dite étaient toujours ennuyeuses. Les fournisseurs d'hébergement bon marché n'offrent que des interfaces Web médiocres pour configurer les bases de données MySQL et un accès FTP pour télécharger des fichiers était toujours le pire. Je ne voulais pas m'en occuper pour mon site personnel.
Donc, les exigences que j'avais pour la refonte étaient:
- Une pile technologique à jour basée sur JavaScript et les technologies frontales.
- Une solution de gestion de contenu pour éditer du contenu de n'importe où.
- Un site performant avec des résultats rapides.
Dans cet article, je veux vous montrer ce que j'ai construit et comment mon site Web s'est étonnamment avéré être mon compagnon quotidien.
Définir un modèle de contenu
Publier des choses sur le Web semble être facile. Choisissez un système de gestion de contenu (CMS) qui fournit un éditeur WYSIWYG (Ce que vous voyez est ce que vous obtenez ) pour chaque page nécessaire et tous les éditeurs peuvent gérer le contenu facilement. C'est ça, non ?
Après avoir créé plusieurs sites Web clients, allant de petits cafés à des startups en pleine croissance, j'ai compris que le saint éditeur WYSIWYG n'est pas toujours la solution miracle que nous recherchons tous. Ces interfaces visent à faciliter la création de sites Web, mais voici le point :
Construire des sites Web n'est pas facile
Pour créer et modifier le contenu d'un site Web sans le casser constamment, vous devez avoir une connaissance intime du HTML et comprendre au moins un tout petit peu le CSS. Ce n'est pas quelque chose que vous pouvez attendre de vos éditeurs.
J'ai vu d'horribles mises en page complexes construites avec des éditeurs WYSIWYG et je ne peux pas commencer à nommer toutes les situations où tout s'effondre parce que le système est trop fragile. Ces situations conduisent à des bagarres et à un malaise où toutes les parties se blâment pour quelque chose qui était inévitable. J'ai toujours essayé d'éviter ces situations et de créer des environnements confortables et stables pour les éditeurs afin d'éviter les e-mails en colère criant : « Au secours ! Tout est cassé."
Le contenu structuré vous évite des problèmes
J'ai appris assez rapidement que les gens cassent rarement les choses lorsque je divise tout le contenu du site Web nécessaire en plusieurs morceaux, chacun lié les uns aux autres sans penser à aucune représentation. Dans WordPress, cela peut être réalisé en utilisant des types de publication personnalisés. Chaque type de message personnalisé peut inclure plusieurs propriétés avec leur propre champ de texte facile à saisir. J'ai complètement enterré le concept de la pensée en pages .
Mon travail consistait à connecter les éléments de contenu et à créer des pages Web à partir de ces blocs de contenu. Cela signifiait que les éditeurs ne pouvaient apporter que peu de modifications visuelles, voire aucune, sur leurs sites Web. Ils étaient responsables du contenu et uniquement du contenu. Les changements visuels devaient être faits par moi - tout le monde ne pouvait pas styliser le site, et nous pouvions éviter un environnement fragile. Ce concept ressemblait à un excellent compromis et était généralement bien accueilli.
Plus tard, j'ai découvert que ce que je faisais était de définir un modèle de contenu. Rachel Lovinger définit, dans son excellent article « Content Modelling : A Master Skill », un modèle de contenu comme suit :
« Un modèle de contenu documente tous les différents types de contenu que vous aurez pour un projet donné. Il contient des définitions détaillées des éléments de chaque type de contenu et de leurs relations les uns avec les autres.
Commencer par la modélisation de contenu a bien fonctionné pour la plupart des clients, sauf un.
« Stefan, je ne définis pas votre schéma de base de données ! »
L'idée de ce projet unique était de créer un site Web massif qui devrait créer beaucoup de trafic organique en fournissant des tonnes de contenu - dans toutes les variantes affichées sur plusieurs pages et endroits différents. J'ai organisé une réunion pour discuter de notre stratégie pour aborder ce projet.
Je voulais définir toutes les pages et les modèles de contenu qui devraient être inclus. Peu importe le petit widget ou la barre latérale que le client avait en tête, je voulais qu'il soit clairement défini. Mon objectif était de créer une structure de contenu solide qui permette de fournir une interface facile à utiliser pour les éditeurs et fournit des données réutilisables pour l'afficher dans n'importe quel format imaginable.
Il s'est avéré que l'idée de ce projet n'était pas très claire, et je n'ai pas pu obtenir de réponses à toutes mes questions. Le chef de projet n'a pas compris que nous devions commencer par une modélisation de contenu appropriée (et non par la conception et le développement). Pour lui, ce n'était qu'une tonne de pages. Le contenu dupliqué et les énormes zones de texte pour ajouter une quantité massive de texte ne semblaient pas être un problème. Dans son esprit, les questions que j'avais sur la structure étaient techniques, et ils ne devraient pas avoir à s'en soucier. Pour faire court, je n'ai pas fait le projet.
L'important est que la modélisation de contenu ne concerne pas les bases de données.
Il s'agit de rendre votre contenu accessible et pérenne. Si vous ne pouvez pas définir les besoins de votre contenu au lancement du projet, il sera très difficile, voire impossible, de le réutiliser plus tard.
Une modélisation de contenu appropriée est la clé des sites Web actuels et futurs.
Contenu : un CMS sans tête
Il était clair que je voulais suivre une bonne modélisation de contenu pour mon site également. Cependant, il y avait encore une chose. Je ne voulais pas m'occuper de la couche de stockage pour créer mon nouveau site Web, j'ai donc décidé d'utiliser Contentful, un CMS sans tête, sur lequel (avertissement complet !) Je travaille actuellement. "Headless" signifie que ce service propose une interface web pour gérer le contenu dans le cloud et il fournit une API qui me restituera mes données au format JSON. Le choix de ce CMS m'a aidé à être productif tout de suite car j'avais une API disponible en quelques minutes et je n'avais pas à faire face à une configuration d'infrastructure. Contentful fournit également un plan gratuit qui est parfait pour les petits projets, comme mon site Web personnel.
Un exemple de requête pour obtenir tous les articles de blog ressemble à ceci :
<a href="https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post">https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post</a>Et la réponse, dans une version abrégée, ressemble à ceci :
{ "sys": { "type": "Array" }, "total": 7, "skip": 0, "limit": 100, "items": [ { "sys": { "space": {...}, "id": "455OEfg1KUskygWUiKwmkc", "type": "Entry", "createdAt": "2016-07-29T11:53:52.596Z", "updatedAt": "2016-11-09T21:07:19.118Z", "revision": 12, "contentType": {...}, "locale": "en-US" }, "fields": { "title": "How to React to Changing Environments Using matchMedia", "excerpt": "...", "slug": "how-to-react-to-changing-environments-using-match-media", "author": [...], "body": "...", "date": "2014-12-26T00:00+02:00", "comments": true, "externalUrl": "https://4waisenkinder.de/blog/2014/12/26/handle-environment-changes-via-window-dot-matchmedia/" }, {...}, {...}, {...}, {...}, {...}, {...} ] } }La grande partie de Contentful est qu'il est excellent pour la modélisation de contenu, ce dont j'avais besoin. À l'aide de l'interface Web fournie, je peux définir rapidement tous les éléments de contenu nécessaires. La définition d'un modèle de contenu particulier dans Contentful est appelée un type de contenu. Une grande chose à souligner ici est la possibilité de modéliser les relations entre les éléments de contenu. Par exemple, je peux facilement connecter un auteur avec un article de blog. Cela peut aboutir à des arborescences de données structurées, qui sont parfaites pour être réutilisées pour divers cas d'utilisation.
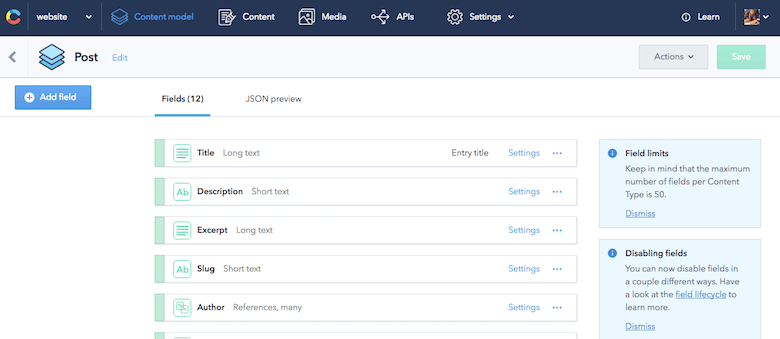
J'ai donc configuré mon modèle de contenu sans penser aux pages que je pourrais vouloir créer à l'avenir.
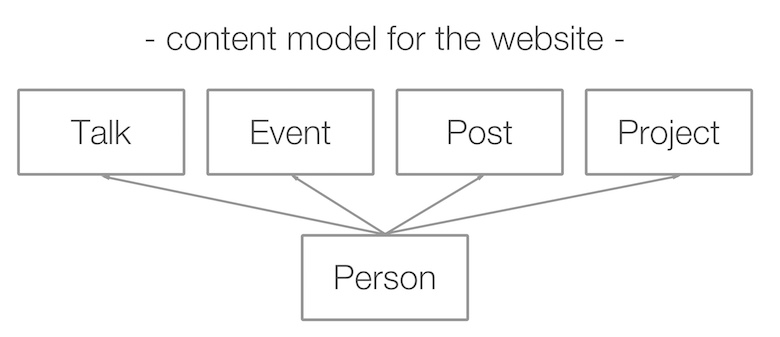
L'étape suivante consistait à déterminer ce que je voulais faire avec ces données. J'ai demandé à un designer que je connaissais et il a proposé une page d'index du site Web avec la structure suivante.
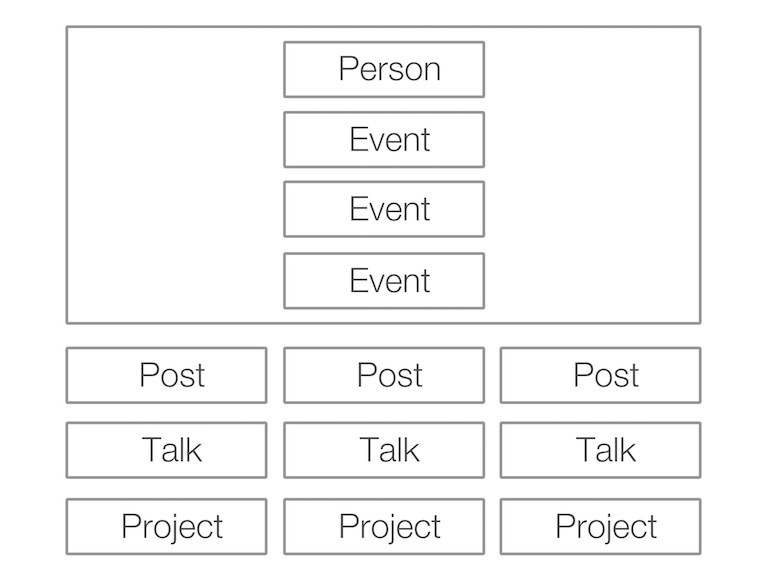
Rendu des pages HTML à l'aide de Node.js
Maintenant est venu la partie délicate. Jusqu'à présent, je n'avais pas à m'occuper du stockage et des bases de données, ce qui était une grande réussite pour moi. Alors, comment puis-je créer mon site Web alors que je n'ai qu'une API disponible ?
Ma première approche était l'approche do-it-yourself. J'ai commencé à écrire un simple script Node.js qui récupèrerait les données et en restituerait du HTML.
Le rendu initial de tous les fichiers HTML a répondu à l'une de mes principales exigences. Le HTML statique peut être servi très rapidement.
Alors, regardons le script que j'ai utilisé.
'use strict'; const contentful = require('contentful'); const template = require('lodash.template'); const fs = require('fs'); // create contentful client with particular credentials const client = contentful.createClient({ space: 'your_space_id', accessToken: 'your_token' }); // cache templates to not read // them over and over again const TEMPLATES = { index : template(fs.readFileSync(`${__dirname}/templates/index.html`)) }; // fetch all the data Promise.all([ // get posts client.getEntries({content_type: 'content_type_post_id'}), // get events client.getEntries({content_type: 'content_type_event_id'}), // get projects client.getEntries({content_type: 'content_type_project_id'}), // get talk client.getEntries({content_type: 'content_type_talk_id'}), // get specific person client.getEntries({'sys.id': 'person_id'}) ]) .then(([posts, events, projects, talks, persons]) => { const renderedHTML = TEMPLATES.index({ posts, events, projects, talks, person : persons.items[0] }) fs.writeFileSync(`${__dirname}/build/index.html`, renderedHTML); console.log('Rendered HTML'); }) .catch(console.error); <!doctype html> <html lang="en"> <head> <!-- ... --> </head> <body> <!-- ... --> <h2>Posts</h2> <ul> <% posts.items.forEach( function( talk ) { %> <li><%- talk.fields.title %> <% }) %> </ul> <!-- ... --> </body> </html>Cela a bien fonctionné. Je pouvais créer le site Web souhaité de manière totalement flexible, en prenant toutes les décisions concernant la structure et les fonctionnalités des fichiers. Le rendu de différents types de pages avec des ensembles de données complètement différents n'a posé aucun problème. Tous ceux qui se sont battus contre les règles et la structure d'un CMS existant livré avec le rendu HTML savent qu'une liberté totale peut être une excellente chose. Surtout, lorsque le modèle de données devient plus complexe au fil du temps, y compris de nombreuses relations, la flexibilité est payante.
Dans ce script Node.js, un client Contentful SDK est créé et toutes les données sont récupérées à l'aide de la méthode client getEntries . Toutes les méthodes fournies par le client sont basées sur des promesses, ce qui permet d'éviter facilement les rappels profondément imbriqués. Pour les modèles, j'ai décidé d'utiliser le moteur de modèles de lodash. Enfin, pour la lecture et l'écriture de fichiers, Node.js propose le module natif fs , qui est ensuite utilisé pour lire les modèles et écrire le HTML rendu.
Cependant, il y avait un inconvénient à cette approche; c'était très dépouillé. Même lorsque cette méthode était complètement flexible, on avait l'impression de réinventer la roue. Ce que je construisais était essentiellement un générateur de site statique, et il y en a déjà beaucoup. Il était temps de tout recommencer.
Opter pour un véritable générateur de site statique
Les célèbres générateurs de sites statiques, par exemple, Jekyll ou Middleman, traitent généralement des fichiers Markdown qui seront rendus au format HTML. Les éditeurs travaillent avec ceux-ci et le site Web est construit à l'aide d'une commande CLI. Cette approche échouait cependant à l'une de mes exigences initiales. Je voulais pouvoir modifier le site où que je sois, sans compter sur des fichiers stockés sur mon ordinateur privé.
Ma première idée était de rendre ces fichiers Markdown en utilisant l'API. Bien que cela aurait fonctionné, cela ne semblait pas juste. Le rendu des fichiers Markdown pour les transformer en HTML plus tard était encore deux étapes n'offrant pas un gros avantage par rapport à ma solution initiale.

Heureusement, il existe des intégrations Contentful, par exemple Metalsmith et Middleman. J'ai choisi Metalsmith pour ce projet, car il est écrit dans Node.js et je ne voulais pas introduire de dépendance Ruby.
Metalsmith transforme les fichiers d'un dossier source et les restitue dans un dossier de destination. Ces fichiers ne doivent pas nécessairement être des fichiers Markdown. Vous pouvez également l'utiliser pour transpiler Sass ou optimiser vos images. Il n'y a pas de limites et c'est vraiment flexible.
En utilisant l'intégration Contentful, j'ai pu définir certains fichiers source qui ont été pris comme fichiers de configuration et j'ai ensuite pu récupérer tout ce dont j'avais besoin à partir de l'API.
--- title: Blog contentful: content_type: content_type_id entry_filename_pattern: ${ fields.slug } entry_template: article.html order: '-fields.date' filter: include: 5 layout: blog.html description: >- Recent articles by Stefan Judis. --- Cet exemple de configuration restitue la zone de publication de blog avec un fichier blog.html parent, y compris la réponse de la demande d'API, mais restitue également plusieurs pages enfants à l'aide du modèle article.html . Les noms de fichiers pour les pages enfants sont définis via entry_filename_pattern .
Comme vous le voyez, avec quelque chose comme ça, je peux facilement créer mes pages. Cette configuration a parfaitement fonctionné pour garantir que toutes les pages dépendaient de l'API.
Connectez le service à votre projet
La seule partie manquante était de connecter le site au service CMS et de le restituer lorsqu'un contenu était modifié. La solution à ce problème — les webhooks, que vous connaissez peut-être déjà si vous utilisez des services comme GitHub.
Les webhooks sont des requêtes effectuées par un logiciel en tant que service à un point de terminaison préalablement défini qui vous avertit que quelque chose s'est produit. GitHub, par exemple, peut vous renvoyer un ping lorsque quelqu'un a ouvert une demande d'extraction dans l'un de vos dépôts. Concernant la gestion de contenu, on peut appliquer ici le même principe. Chaque fois que quelque chose se passe avec le contenu, envoyez un ping à un point de terminaison et faites en sorte qu'un environnement particulier y réagisse. Dans notre cas, cela signifierait restituer le HTML à l'aide de metalsmith.
Pour accepter les webhooks, j'ai également opté pour une solution JavaScript. L'hébergeur de mon choix (Uberspace) permet d'installer Node.js et d'utiliser JavaScript côté serveur.
const http = require('http'); const exec = require('child_process').exec; const server = http.createServer((req, res) => { res.setHeader('Content-Type', 'text/plain'); // check for secret header // to not open up this endpoint for everybody if (req.headers.secret === 'YOUR_SECRET') { res.end('ok'); // wait for the CDN to // invalidate the data setTimeout(() => { // execute command exec('npm start', { cwd: __dirname }, (error) => { if (error) { return console.log(error); } console.log('Rebuilt success'); }); }, 1000 * 120 ); } else { res.end('Not allowed'); } }); console.log('Started server at 8000'); server.listen(8000); Ce script démarre un serveur HTTP simple sur le port 8000. Il vérifie les demandes entrantes pour un en-tête approprié pour s'assurer qu'il s'agit du webhook de Contentful. Si la demande est confirmée en tant que webhook, la commande prédéfinie npm start est exécutée pour restituer toutes les pages HTML. Vous pourriez vous demander pourquoi il y a un délai d'attente en place. Cela est nécessaire pour suspendre les actions pendant un moment jusqu'à ce que les données dans le cloud soient invalidées car les données stockées sont servies à partir d'un CDN.
Selon votre environnement, ce serveur HTTP peut ne pas être accessible à Internet. Mon site est servi à l'aide d'un serveur apache, j'ai donc dû ajouter une règle de réécriture interne pour rendre le serveur de nœud en cours d'exécution accessible à Internet.
# add node endpoint to enable webhooks RewriteRule ^rerender/(.*) https://localhost:8000/$1 [P]API-First et données structurées : meilleurs amis pour toujours
À ce stade, je pouvais gérer toutes mes données dans le cloud et mon site Web réagirait en conséquence après les modifications.
Répétition partout
Être sur la route est une partie importante de ma vie, il était donc nécessaire d'avoir des informations, telles que l'emplacement d'un lieu donné ou l'hôtel que j'ai réservé, à portée de main - généralement stockées dans une feuille de calcul Google. Désormais, les informations étaient réparties sur une feuille de calcul, plusieurs e-mails, mon calendrier, ainsi que sur mon site Web.
J'ai dû admettre que j'ai créé beaucoup de duplication de données dans mon flux quotidien.
Le moment des données structurées
Je rêvais d'une source unique de vérité (de préférence sur mon téléphone) pour voir rapidement quels événements se préparaient, mais aussi obtenir des informations supplémentaires sur les hôtels et les lieux. Les événements répertoriés sur mon site Web ne contenaient pas toutes les informations à ce stade, mais il est très facile d'ajouter de nouveaux champs à un type de contenu dans Contentful. J'ai donc ajouté les champs nécessaires au type de contenu "Événement".
Mettre ces informations dans le CMS de mon site Web n'a jamais été mon intention, car elles ne devraient pas être affichées en ligne, mais les avoir accessibles via une API m'a fait réaliser que je pouvais maintenant faire des choses complètement différentes avec ces données.
Construire une application native avec JavaScript
La création d'applications pour mobile est un sujet depuis des années maintenant, et il existe plusieurs approches pour cela. Les applications Web progressives (PWA) sont un sujet particulièrement brûlant ces jours-ci. À l'aide de Service Workers et d'un manifeste d'application Web, il est possible de créer des expériences complètes de type application, allant d'une icône d'écran d'accueil à un comportement hors ligne géré à l'aide de technologies Web.
Il y a un inconvénient à mentionner. Les Progressive Web Apps sont en plein essor, mais elles ne sont pas encore tout à fait là. Les Service Workers, par exemple, ne sont pas pris en charge sur Safari aujourd'hui et seulement "à l'étude" du côté d'Apple jusqu'à présent. C'était une rupture pour moi car je voulais aussi avoir une application hors ligne sur iPhone.
J'ai donc cherché des alternatives. Un de mes amis était vraiment intéressé par NativeScript et n'arrêtait pas de me parler de cette technologie relativement nouvelle. NativeScript est un framework open source permettant de créer des applications mobiles véritablement natives avec JavaScript, j'ai donc décidé de l'essayer.
Apprendre à connaître NativeScript
La configuration de NativeScript prend un certain temps car vous devez installer beaucoup de choses à développer pour les environnements mobiles natifs. Vous serez guidé tout au long du processus d'installation lorsque vous installerez l'outil de ligne de commande NativeScript pour la première fois à l'aide de npm install nativescript -g .
Ensuite, vous pouvez utiliser des commandes d'échafaudage pour configurer de nouveaux projets : tns create MyNewApp
Cependant, ce n'est pas ce que j'ai fait. Je scannais la documentation et je suis tombé sur un exemple d'application de gestion des courses construite en NativeScript. J'ai donc pris cette application, creusé dans le code et l'ai modifiée étape par étape, en l'adaptant à mes besoins.
Je ne veux pas plonger trop profondément dans le processus, mais pour construire une liste avec toutes les informations que je voulais, cela n'a pas pris longtemps.
NativeScript fonctionne très bien avec Angular 2, que je ne voulais pas essayer cette fois car découvrir NativeScript lui-même semblait assez grand. Dans NativeScript, vous devez écrire "Vues". Chaque vue se compose d'un fichier XML définissant la mise en page de base et de JavaScript et CSS facultatifs. Tous ces éléments sont définis dans un dossier par vue.
Le rendu d'une liste simple peut être réalisé avec un modèle XML comme celui-ci :
<!-- call JavaScript function when ready --> <Page loaded="loaded"> <ActionBar title="All Travels" /> <!-- make it scrollable when going too big --> <ScrollView> <!-- iterate over the entries in context --> <ListView items="{{ entries }}"> <ListView.itemTemplate> <Label text="{{ fields.name }}" textWrap="true" class="headline"/> </ListView.itemTemplate> </ListView> </ScrollView> </Page> La première chose qui se passe ici est de définir un élément de page. À l'intérieur de cette page, j'ai défini une ActionBar pour lui donner le look Android classique ainsi qu'un titre approprié. Construire des choses pour des environnements natifs peut parfois être un peu délicat. Par exemple, pour obtenir un comportement de défilement fonctionnel, vous devez utiliser un "ScrollView". La dernière chose à faire est ensuite de parcourir simplement mes événements à l'aide d'un ListView . Dans l'ensemble, c'était assez simple!
Mais d'où viennent ces entrées qui sont utilisées dans la vue ? Il s'avère qu'il existe un objet de contexte partagé qui peut être utilisé pour cela. Lors de la lecture du XML de la vue, vous avez peut-être déjà remarqué que la page a un ensemble d'attributs loaded . En définissant cet attribut, je dis à la vue d'appeler une fonction JavaScript particulière lorsque la page est chargée.
Cette fonction JavaScript est définie dans le fichier JS dépendant. Il peut être rendu accessible en l'exportant simplement à l'aide exports.something . Pour ajouter la liaison de données, tout ce que nous avons à faire est de définir un nouvel Observable sur la propriété de page bindingContext . Les observables dans NativeScript émettent des événements propertyChange qui sont nécessaires pour réagir aux changements de données à l'intérieur des 'vues, mais vous n'avez pas à vous en soucier, car cela fonctionne hors de la boîte.
const context = new Observable({ entries: null}); const fetchModule = require('fetch'); // export loaded to be called from // List.xml when everything is loaded exports.loaded = (args) => { const page = args.object; page.bindingContext = context; fetchModule.fetch( `https://cdn.contentful.com/spaces/${config.space}/entries?access_token=${config.cda.token}&content_type=event&order=fields.start`, { method: "GET", headers: { 'Content-Type': 'application/json' } } ) .then(response => response.json()) .then(response => context.set('entries', response.items)); } La dernière chose est de récupérer les données et de les définir dans le contexte. Cela peut être fait en utilisant le module de fetch NativeScript. Ici, vous pouvez voir le résultat.
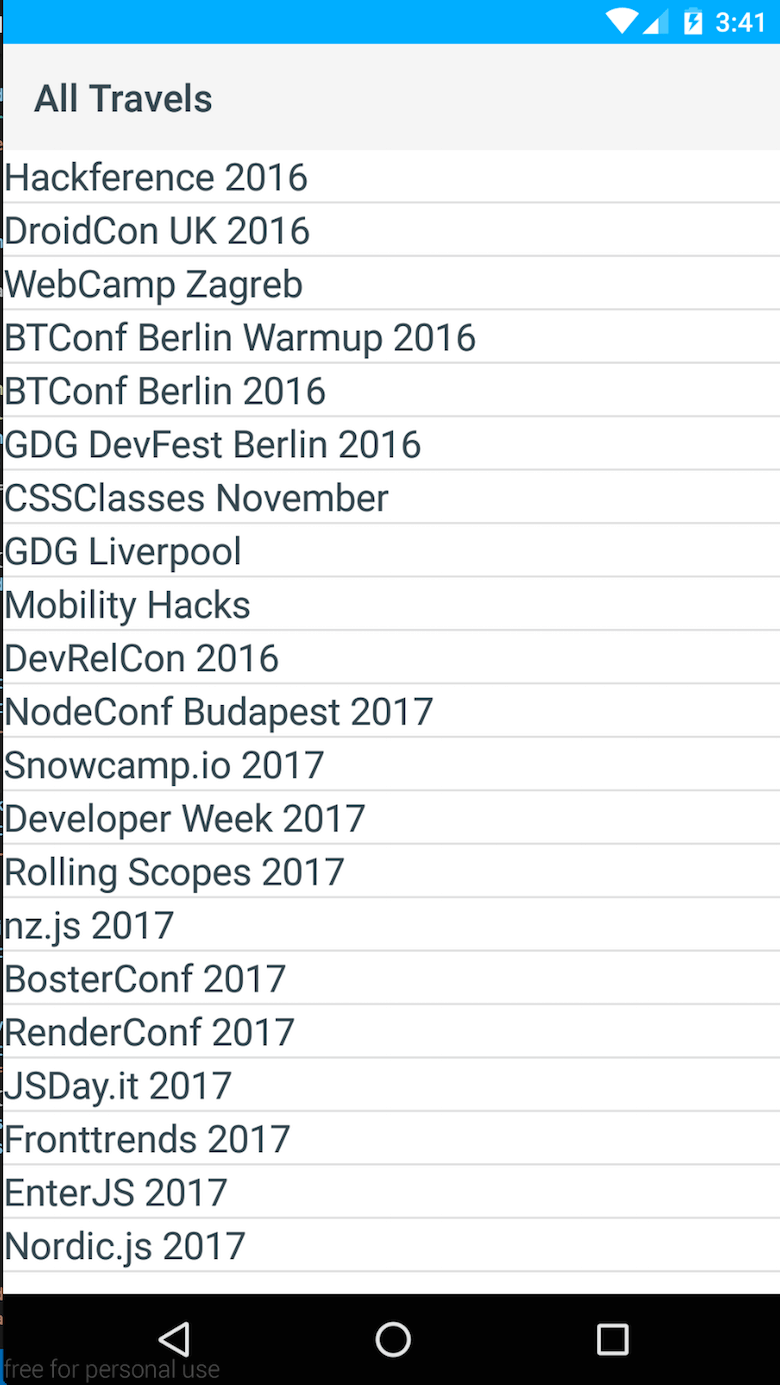
Ainsi, comme vous pouvez le constater, la création d'une liste simple à l'aide de NativeScript n'est pas vraiment difficile. Plus tard, j'ai étendu l'application avec une autre vue ainsi que des fonctionnalités supplémentaires pour ouvrir des adresses données dans Google Maps et des vues Web pour consulter les sites Web de l'événement.
Une chose à souligner ici est que NativeScript est encore assez nouveau, ce qui signifie que les plugins trouvés sur npm n'ont généralement pas beaucoup de téléchargements ou d'étoiles sur GitHub. Cela m'a irrité au début, mais j'ai utilisé plusieurs composants natifs (nativescript-floatingactionbutton, nativescript-advanced-webview et nativescript-pulltorefresh) qui m'ont aidé à obtenir une expérience native et tout a parfaitement fonctionné.
Vous pouvez voir le résultat amélioré ici :
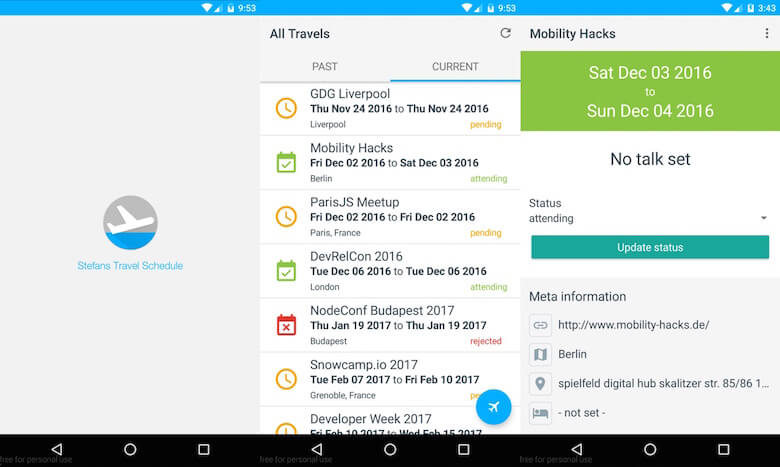
Plus je mettais de fonctionnalités dans cette application, plus je l'aimais et plus je l'utilisais. La meilleure partie est que je pourrais me débarrasser de la duplication des données, gérer les données au même endroit tout en étant suffisamment flexible pour les afficher pour divers cas d'utilisation.
Les pages sont hier : Vive le contenu structuré !
La construction de cette application m'a montré une fois de plus que le principe d'avoir des données au format page appartient au passé. Nous ne savons pas où iront nos données — nous devons être prêts pour un nombre illimité de cas d'utilisation.
Avec le recul, ce que j'ai réalisé est:
- Avoir un système de gestion de contenu dans le cloud
- Ne pas avoir à gérer la maintenance de la base de données
- Une pile technologique JavaScript complète
- Avoir un site web statique efficace
- Avoir une application Android pour accéder à mon contenu à tout moment et partout
Et la partie la plus importante :
Avoir mon contenu structuré et accessible m'a aidé à améliorer mon quotidien.
Ce cas d'utilisation peut vous sembler trivial en ce moment, mais quand vous pensez aux produits que vous construisez chaque jour, il y a toujours plus de cas d'utilisation pour votre contenu sur différentes plateformes. Aujourd'hui, nous acceptons que les appareils mobiles dépassent enfin les environnements de bureau de la vieille école, mais des plates-formes comme les voitures, les montres et même les réfrigérateurs attendent déjà leur projecteur. Je ne peux même pas penser aux cas d'utilisation qui viendront.
Essayons donc d'être prêts et de mettre du contenu structuré au milieu, car à la fin, il ne s'agit pas de schémas de base de données - il s'agit de construire pour l'avenir.
Lectures complémentaires sur SmashingMag :
- Web Scraping avec Node.js
- Naviguer avec Sails.js : un framework de style MVC pour Node.js
- 40 icônes de voyage pour embellir vos créations
- Une introduction détaillée à Webpack